Salut Je m'appelle Vadim Madison, je dirige le développement de la plateforme système Avito. À propos de la façon dont nous, dans l'entreprise, passons d'une architecture monolithique à une architecture de microservices, cela a été dit plus d'une fois. Il est temps de partager comment nous avons transformé notre infrastructure afin de tirer le meilleur parti des microservices et de ne pas nous y perdre. Comment PaaS nous aide ici, comment nous avons simplifié le déploiement et réduit la création d'un microservice à un seul clic - lisez la suite. Tout ce que j'écris ci-dessous n'est pas entièrement implémenté dans Avito, en partie comment nous développons notre plateforme.
(Et à la fin de cet article, je parlerai de l'opportunité de participer à un séminaire de trois jours d'un expert en architecture de microservices Chris Richardson).

Comment nous sommes arrivés aux microservices
Avito est l'une des plus grandes petites annonces au monde, elle publie plus de 15 millions de nouvelles annonces par jour. Notre backend accepte plus de 20 000 requêtes par seconde. Nous avons maintenant plusieurs centaines de microservices.
Nous construisons une architecture de microservices depuis plusieurs années. Comment exactement - nos collègues ont parlé en détail dans notre section sur RIT ++ 2017. Au CodeFest 2017 (voir la vidéo ), Sergey Orlov et Mikhail Prokopchuk ont expliqué en détail pourquoi nous avions besoin de la transition vers les microservices et quel rôle Kubernetes a joué ici. Eh bien, maintenant nous faisons tout pour minimiser les coûts de mise à l'échelle inhérents à une telle architecture.
Au départ, nous n'avions pas créé un écosystème qui nous aiderait de manière globale dans le développement et le lancement de microservices. Ils ont simplement collecté des solutions open source sensées, les ont lancées à la maison et ont suggéré au développeur de les gérer. En conséquence, il s'est rendu dans une douzaine d'endroits (tableaux de bord, services internes), après quoi il est devenu plus fort dans le désir de couper le code à l'ancienne, dans un monolithe. La couleur verte sur les diagrammes ci-dessous indique ce que le développeur fait d'une manière ou d'une autre de ses propres mains, la couleur jaune indique l'automatisation.
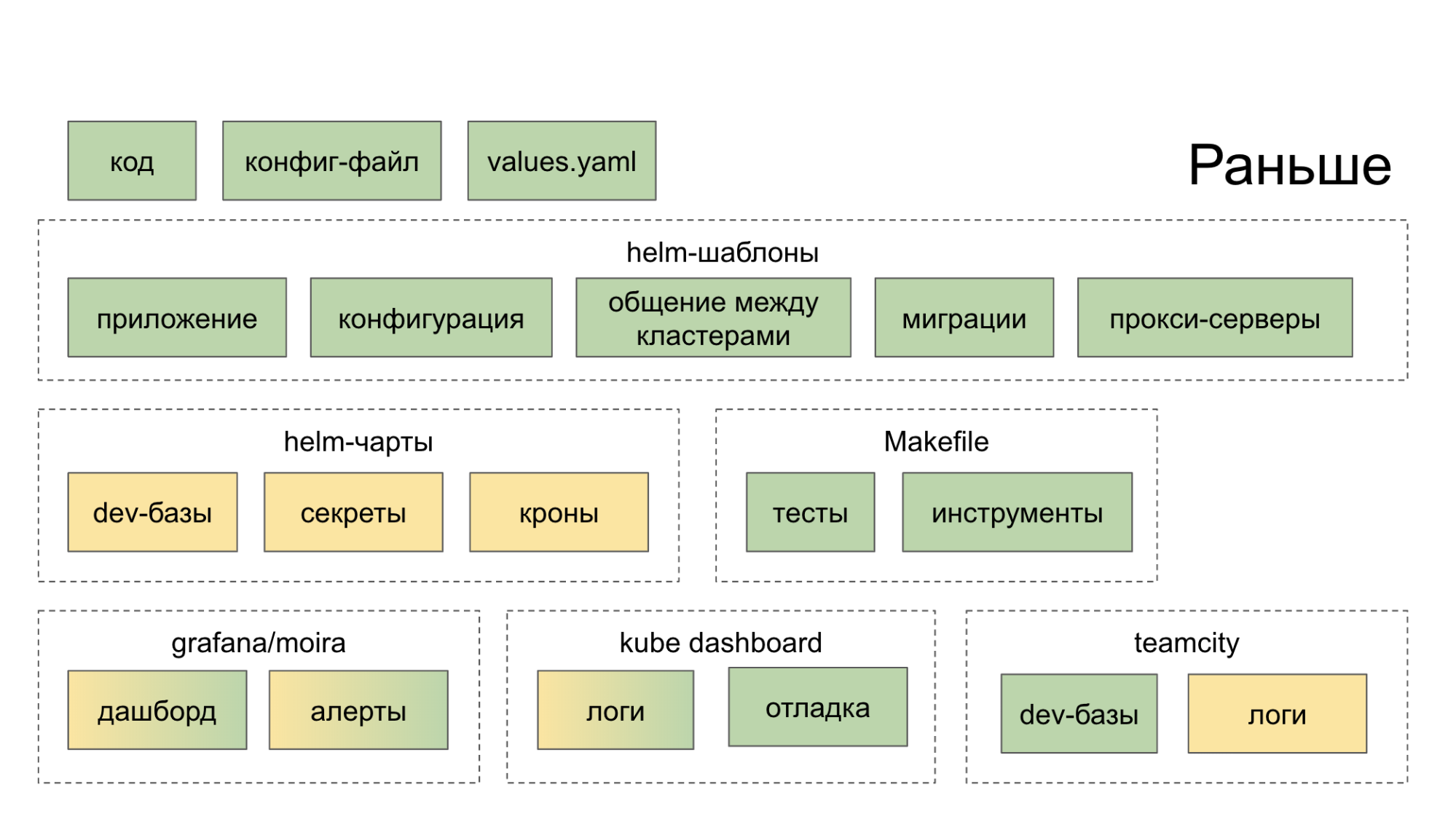
Désormais, dans l'utilitaire CLI PaaS, une équipe crée un nouveau service et deux autres ajoutent une nouvelle base de données et se déploient sur Stage.
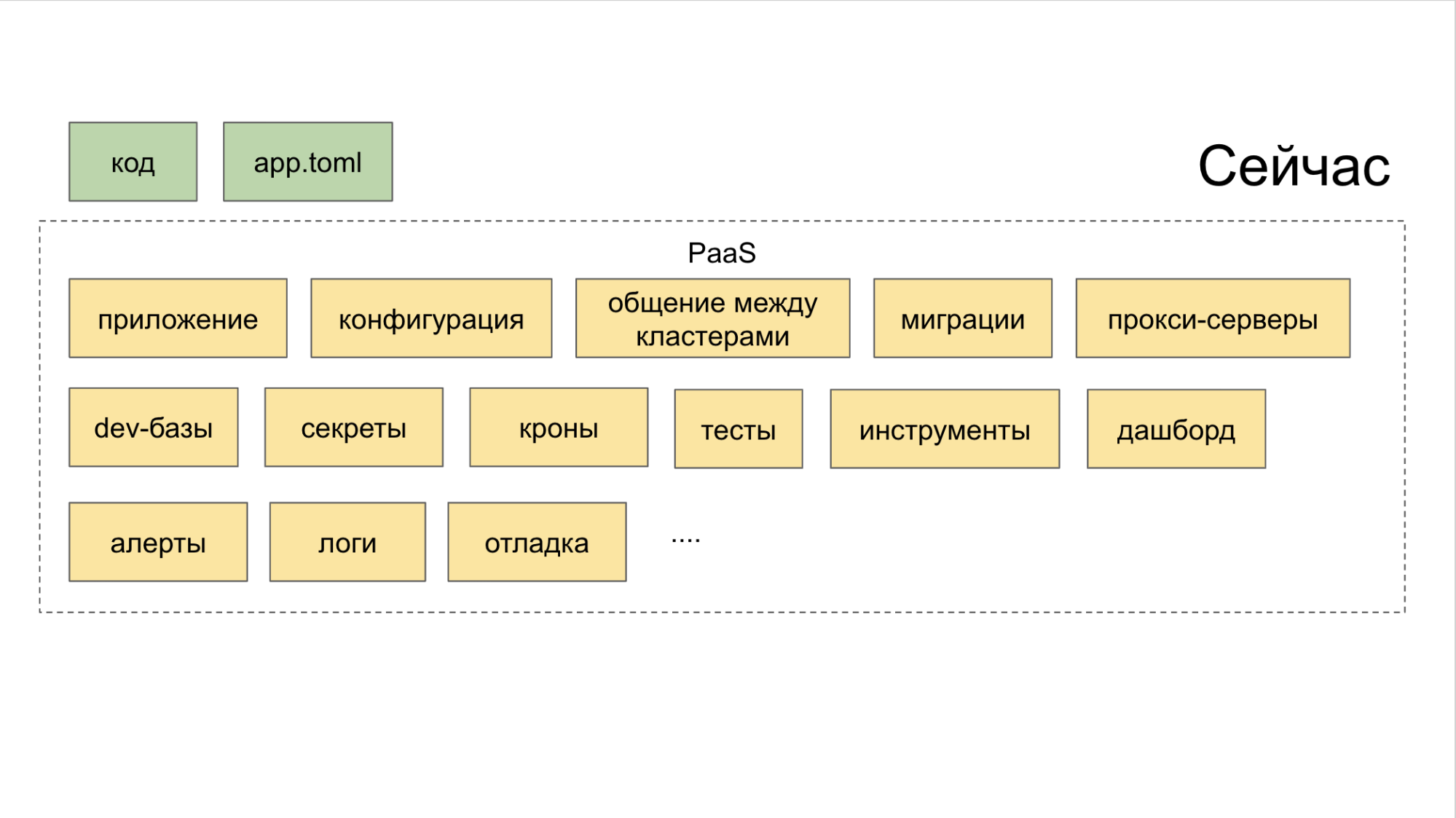
Comment surmonter l'ère de la "fragmentation des microservices"
Avec une architecture monolithique, pour des raisons de cohérence des changements dans le produit, les développeurs ont été contraints de comprendre ce qui se passait avec leurs voisins. Lorsque vous travaillez sur la nouvelle architecture, les contextes de service ne dépendent plus les uns des autres.
De plus, pour que l'architecture de microservice soit efficace, de nombreux processus doivent être mis en place, à savoir:
• l'exploitation forestière;
• traçage des requêtes (Jaeger);
• agrégation d'erreurs (Sentry);
• statuts, messages, événements de Kubernetes (Event Stream Processing);
• limite de course / disjoncteur (vous pouvez utiliser Hystrix);
• contrôle de la connectivité des services (nous utilisons Netramesh);
• surveillance (Grafana);
• assemblage (TeamCity);
• communication et notification (Slack, email);
• suivi des tâches; (Jira)
• compilation de la documentation.
Pour que le système évolue, il ne perd pas son intégrité et reste efficace, nous avons repensé l'organisation du travail des microservices dans Avito.
Comment nous gérons les microservices
La conduite d'une «politique de parti» unifiée parmi les nombreux micro-services qu'Avito aide à:
- division de l'infrastructure en couches;
- Concept de plate-forme en tant que service (PaaS);
- surveillance de tout ce qui se passe avec les microservices.
Les couches d'abstraction d'infrastructure comprennent trois couches. Allons du haut vers le bas.
A. Maillage supérieur. Au début, nous avons essayé Istio, mais il s'est avéré qu'il utilise trop de ressources, ce qui est trop cher sur nos volumes. Par conséquent, l'ingénieur senior de l'équipe d'architecture Alexander Lukyanchenko a développé sa propre solution - Netramesh (disponible en Open Source), que nous utilisons maintenant en production et qui consomme plusieurs fois moins de ressources qu'Istio (mais ne fait pas tout ce dont Istio se vante).
B. Moyen - Kubernetes. Nous y déployons et exploitons des microservices.
C. Inférieur - métal nu. Nous n'utilisons pas de nuages et des choses comme OpenStack, mais nous nous asseyons entièrement sur du métal nu.
Toutes les couches sont combinées par PaaS. Et cette plate-forme, à son tour, se compose de trois parties.
Générateurs contrôlés via l'utilitaire CLI. C'est elle qui aide le développeur à créer un microservice de la bonne manière et avec un minimum d'effort.
II. Collecteur combiné avec contrôle de tous les outils via un tableau de bord commun.
III. Dépôt . Il interfère avec les planificateurs qui définissent automatiquement des déclencheurs pour les actions importantes. Grâce à un tel système, aucune tâche n'est manquée simplement parce que quelqu'un a oublié de mettre une tâche dans Jira. Pour cela, nous utilisons un outil interne appelé Atlas.

La mise en œuvre des microservices dans Avito est également réalisée selon un schéma unique, ce qui simplifie leur contrôle à chaque étape de développement et de sortie.
Fonctionnement du pipeline de développement de microservices standard
De manière générale, la chaîne de création de microservices est la suivante:
CLI-push → Intégration continue → Bake → Déployer → Tests artificiels → Tests Canary → Squeeze Testing → Production → Service.
Nous le parcourons exactement dans cette séquence.
CLI-push
• Création d'un microservice .
Nous avons longtemps lutté pour apprendre à chaque développeur comment créer des microservices. Y compris écrit dans Confluence des instructions détaillées. Mais les schémas ont changé et complété. Conclusion - un goulot d'étranglement s'est formé au début du voyage: il a fallu beaucoup plus de temps pour démarrer les microservices que ce qui était autorisé, et malgré tout, lors de leur création, des problèmes se sont souvent posés.
Au final, nous avons construit un simple utilitaire CLI qui automatise les étapes de base lors de la création d'un microservice. En fait, il remplace le premier push git. Voilà ce qu'elle fait.
- Crée un service selon le modèle - pas à pas, en mode "assistant". Nous avons des modèles pour les principaux langages de programmation dans le backend Avito: PHP, Golang et Python.
- Sur une commande, il déploie l'environnement pour le développement local sur une machine spécifique - Le Minikube monte, les graphiques Helm sont automatiquement générés et exécutés dans les kubernetes locaux.
- Connecte la base de données souhaitée. Le développeur n'a pas besoin de connaître l'IP, le login et le mot de passe pour accéder à la base de données dont il a besoin - au moins localement, au moins en phase, au moins en production. De plus, la base de données est déployée immédiatement dans une configuration à tolérance de pannes et avec équilibrage.
- Il effectue lui-même un montage en direct. Disons qu'un développeur a corrigé quelque chose dans un microservice via son IDE. L'utilitaire voit les changements dans le système de fichiers et, en fonction d'eux, réassemble l'application (pour Golang) et redémarre. Pour PHP, nous transmettons simplement le répertoire à l'intérieur du cube et le live-reload est obtenu «automatiquement».
- Génère des autotests. Sous forme de disques, mais tout à fait adapté à l'utilisation.
• Déployer le microservice .
C'était un peu morne de déployer un microservice auparavant. Obligatoire requis:
Dockerfile.
II. Config.
III. Un graphique Helm, qui est lui-même volumineux et comprend:
- les cartes elles-mêmes;
- modèles;
- des valeurs spécifiques prenant en compte différents environnements.
Nous nous sommes débarrassés de la douleur de refaire les manifestes Kubernetes, et maintenant ils sont générés automatiquement. Mais surtout, ils ont simplifié le déploiement à la limite. À partir de maintenant, nous avons un Dockerfile, et le développeur écrit toute la configuration dans un seul fichier app.toml court.
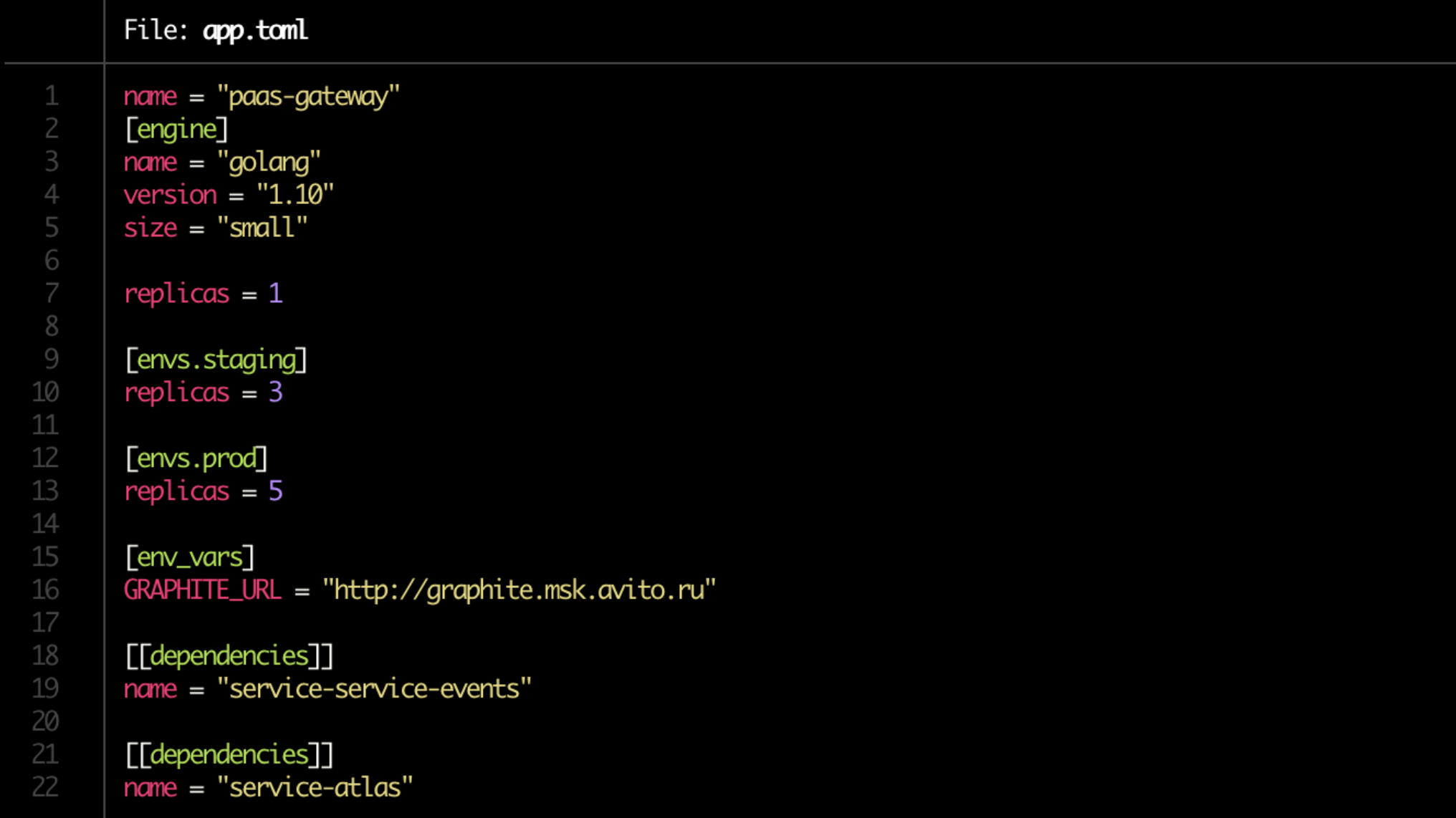
Oui, et dans l'app.toml lui-même, c'est maintenant les affaires pendant une minute. Nous écrivons où à combien de copies du service élever (sur le serveur de développement, sur la mise en scène, sur la production), indiquent ses dépendances. Notez la taille de la ligne = "petite" dans le bloc [moteur]. Il s'agit de la limite qui sera allouée au service via Kubernetes.
De plus, sur la base de la configuration, tous les graphiques Helm nécessaires sont générés automatiquement et des connexions aux bases de données sont créées.
• Validation de base. Ces contrôles sont également automatisés.
Besoin de suivre:
- existe-t-il un Dockerfile;
- existe-t-il app.toml;
- s'il existe une documentation;
- si la dépendance est en règle;
- sont les règles des alertes définies.
Dernier point: le propriétaire du service lui-même indique les métriques de produit à surveiller.
• Préparation de la documentation.
Encore un problème. Il semble être le plus évident, mais en même temps un record «souvent oublié», et donc un maillon vulnérable de la chaîne.
Il est nécessaire que la documentation se trouve sous chaque microservice. Les blocs suivants y sont inclus.
I. Brève description du service . Juste quelques phrases sur ce qu'il fait et ce dont il a besoin.
II. Lien vers le diagramme d'architecture . Il est important de le consulter rapidement pour comprendre, par exemple, si vous utilisez Redis pour la mise en cache ou comme magasin de données principal en mode persistant. À Avito, jusqu'à présent, c'est un lien vers Confluence.
III. Runbook . Un petit guide pour lancer le service et les subtilités de sa gestion.
IV. FAQ , où il serait bon d'anticiper les problèmes que vos collègues peuvent rencontrer lorsqu'ils travaillent avec le service.
V. Description des points finaux pour l'API . Si vous n’avez soudainement pas indiqué votre destination, vous serez certainement payé par des collègues dont les microservices sont liés aux vôtres. Maintenant, nous utilisons Swagger pour cela et notre solution appelée brief.
VI. Les étiquettes Ou des marqueurs qui indiquent à quel produit, fonctionnalité, unité structurelle de l'entreprise appartient le service. Ils aident à comprendre rapidement, par exemple, si vous ne voyez pas la fonctionnalité que vos collègues ont déployée il y a une semaine pour la même unité commerciale.
VII. Le ou les propriétaires du service . Dans la plupart des cas, il - ou eux - peut être déterminé automatiquement à l'aide de PaaS, mais pour l'assurance, nous demandons au développeur de les spécifier manuellement.
Enfin, il est recommandé de consulter la documentation, comme pour la révision de code.
Intégration continue
- Préparation des référentiels.
- Création d'un pipeline dans TeamCity.
- Définition des droits.
- Recherchez les propriétaires de services. Il existe un schéma hybride - marquage manuel et automatisation minimale de PaaS. Un schéma entièrement automatique ne parvient pas à transférer des services en soutien à une autre équipe de développement, ou, par exemple, si un développeur de services quitte.
- Enregistrement du service dans Atlas (voir ci-dessus). Avec tous ses propriétaires et dépendances.
- Vérifiez les migrations. Nous vérifions s'il y en a parmi eux potentiellement dangereux. Par exemple, dans l'un d'eux, une table alterne apparaît ou quelque chose d'autre qui peut perturber la compatibilité du schéma de données entre les différentes versions du service. Ensuite, la migration n'est pas effectuée, mais mise dans un abonnement - PaaS devrait signaler au propriétaire du service quand il devient sûr de l'utiliser.
Cuire
La prochaine étape est le conditionnement des services avant le déploiement.
- Générez l'application. Selon les classiques - dans l'image Docker.
- Génération de graphiques Helm pour le service lui-même et les ressources associées. Y compris pour les bases de données et le cache. Ils sont créés automatiquement conformément à la configuration app.toml qui a été générée à l'étape CLI-push.
- Création de tickets pour que les administrateurs ouvrent les ports (si nécessaire).
- Test unitaire et calcul de la couverture du code . Si la couverture du code est inférieure à une valeur de seuil donnée, alors, très probablement, le service échouera davantage - à déployer. S'il est sur le point d'être autorisé, un coefficient de «pessimisation» sera attribué au service: alors, en l'absence d'amélioration de l'indicateur dans le temps, le développeur recevra une notification indiquant qu'il n'y a pas de progrès de la part des tests (et il faut faire quelque chose avec cela).
- Prise en compte des limitations de mémoire et de CPU . Nous écrivons principalement des microservices à Golang et les exécutons dans Kubernetes. De là, il y a une subtilité associée à la particularité du langage Golang: par défaut, tous les noyaux de la machine sont utilisés au démarrage, si vous ne définissez pas explicitement la variable GOMAXPROCS et lorsque plusieurs de ces services sont lancés sur la même machine, ils commencent à se disputer les ressources, interférant les uns avec les autres. Les graphiques ci-dessous montrent comment le temps d'exécution change si vous exécutez l'application sans concurrence et dans la course aux ressources. (La source des graphiques est ici ).

Délai d'exécution, moins c'est mieux. Maximum: 643 ms; Minimum: 42 ms. La photo est cliquable.
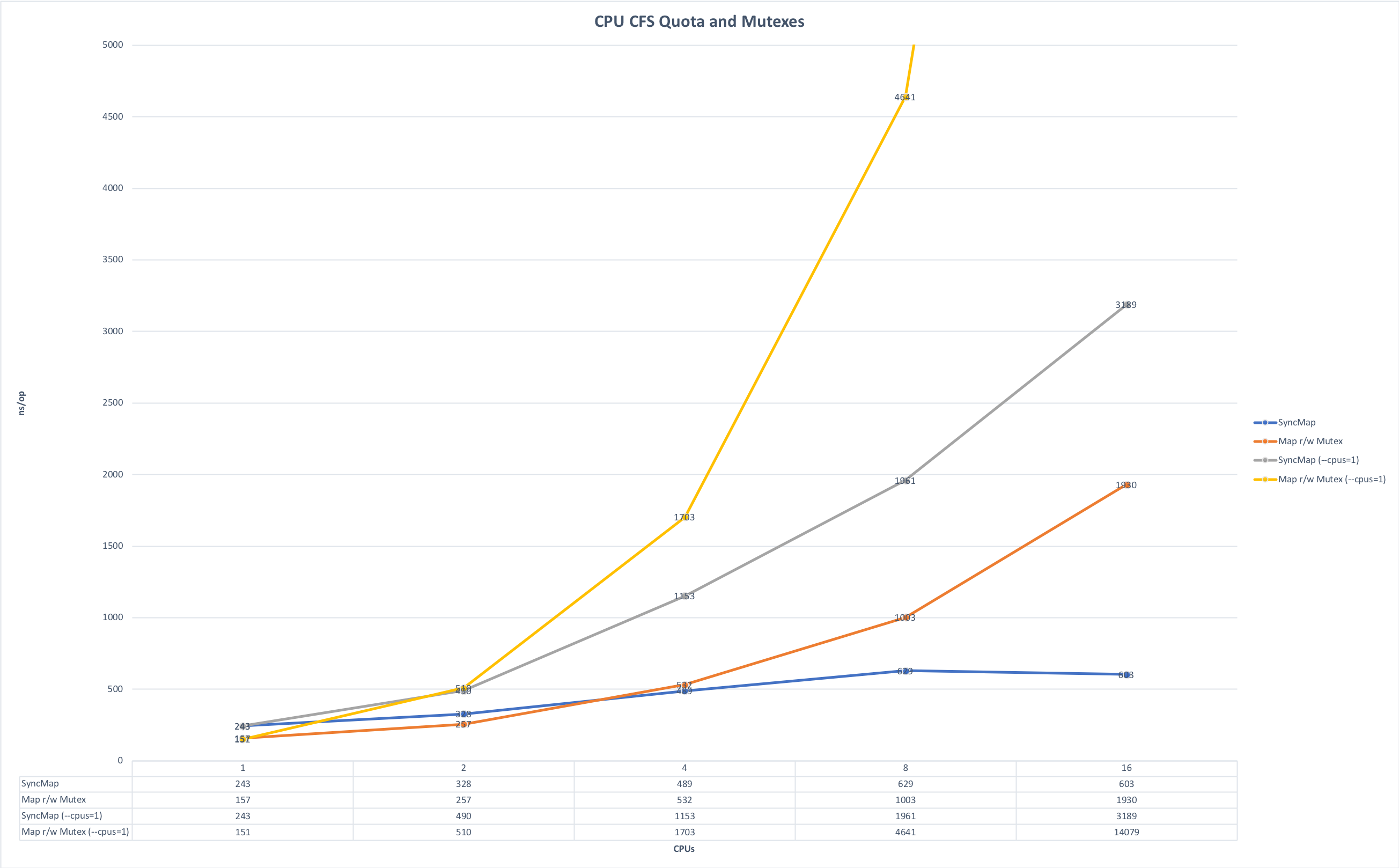
Temps pour la chirurgie, moins c'est mieux. Maximum: 14091 ns, Minimum: 151 ns. La photo est cliquable.
Au stade de la préparation de l'assemblage, vous pouvez définir cette variable explicitement ou vous pouvez utiliser la bibliothèque automaxprocs des gars d'Uber.
Déployer
• Vérification des conventions. Avant de commencer à fournir des assemblys de service aux environnements prévus, vous devez vérifier les éléments suivants:
- Points de terminaison API.
- Conformité du schéma des points de terminaison des réponses API.
- Format de journal.
- Définition d'en-têtes pour les demandes de service (Netramesh le fait maintenant)
- Définition du jeton propriétaire lors de l'envoi de messages vers le bus (bus d'événements). Cela est nécessaire pour suivre la connectivité des services via le bus. Vous pouvez envoyer des données idempotentes au bus qui n'augmente pas la connectivité des services (ce qui est bien), ainsi que des données commerciales qui améliorent la connectivité des services (ce qui est très mauvais!). Et au moment où cette connectivité devient un problème, comprendre qui écrit et lit le bus permet de bien répartir les services.
Bien qu'il n'y ait pas beaucoup de conventions à Avito, mais leur bassin s'élargit. Plus ces accords se présentent sous la forme d'une commande compréhensible et pratique, plus il est facile de maintenir la cohérence entre les microservices.
Tests synthétiques
• Test en boucle fermée. Pour lui, nous utilisons maintenant l'open source Hoverfly.io . Tout d'abord, il enregistre la charge réelle sur le service, puis - juste en boucle fermée - il émule.
• Test de charge. Nous essayons d'amener tous les services à des performances optimales. Et toutes les versions de chaque service doivent être soumises à des tests de résistance - afin que nous puissions comprendre les performances actuelles du service et la différence avec les versions précédentes du même service. Si après une mise à jour de service, ses performances ont diminué d'une fois et demie, c'est un signal clair pour ses propriétaires: vous devez creuser dans le code et corriger la situation.
Nous nous appuyons sur les données collectées, par exemple, afin d'implémenter correctement la mise à l'échelle automatique et, en fin de compte, nous comprenons généralement à quel point le service est évolutif.
Lors des tests de résistance, nous vérifions si la consommation des ressources respecte les limites fixées. Et nous nous concentrons principalement sur les extrêmes.
a) Nous regardons la charge totale.
- Trop petit - très probablement quelque chose ne fonctionne pas du tout si la charge tombe soudainement plusieurs fois.
- Trop grand - une optimisation est requise.
b) Nous examinons la coupure par RPS.
Nous examinons ici la différence entre la version actuelle et la précédente et le nombre total. Par exemple, si un service produit 100 rps, alors il est mal écrit ou c'est sa spécificité, mais en tout cas, c'est l'occasion de regarder de très près le service.
Si RPS, au contraire, est trop, alors peut-être une sorte de bogue et certains points de terminaison ont cessé d'exécuter la charge utile, mais une sorte de return true; déclenché return true;
Tests canaris
Une fois les tests synthétiques réussis, nous exécutons le microservice sur un petit nombre d'utilisateurs. Nous commençons prudemment, avec une infime fraction de l'audience estimée du service - moins de 0,1%. À ce stade, il est très important que les mesures techniques et de produit correctes soient établies dans la surveillance afin qu'elles montrent le problème dans le service le plus rapidement possible. Le temps minimum pour un test canari est de 5 minutes, le principal est de 2 heures. Pour les services complexes, nous réglons l'heure en mode manuel.
Nous analysons:
- métriques spécifiques au langage, en particulier les travailleurs php-fpm;
- erreurs dans Sentry;
- statuts des réponses;
- temps de réponse (temps de réponse), précis et moyen;
- latence;
- exceptions, traitées et non transformées;
- métriques alimentaires.
Test de compression
Le test de compression est également appelé test d'extrusion. Le nom de la technique a été introduit dans Netflix. Son essence est qu'au début, nous remplissons une instance de trafic réel à l'état de défaillance et définissons ainsi sa limite. Ensuite, ajoutez une autre instance et chargez ce couple - à nouveau au maximum; on voit leur plafond et leur delta avec le premier "squeeze". Et donc nous connectons une instance par étape et calculons le modèle des changements.
Les données de test par «extrusion» affluent également vers la base métrique générale, où nous les enrichissons avec des résultats de charge artificielle, ou même les remplaçons par des «synthétiques».
La production
• Mise à l'échelle. En déployant le service à la production, nous suivons son évolution. Dans ce cas, la surveillance uniquement des indicateurs CPU, selon notre expérience, est inefficace. La mise à l'échelle automatique avec l'analyse comparative RPS dans sa forme pure fonctionne, mais uniquement pour certains services, par exemple le streaming en ligne. Nous examinons donc principalement les mesures de produit spécifiques à l'application.
Par conséquent, lors de la mise à l'échelle, nous analysons:
- Indicateurs CPU et RAM,
- le nombre de demandes dans la file d'attente,
- temps de réponse
- prévisions basées sur des données historiques.
Lors de la mise à l'échelle d'un service, il est également important de surveiller ses dépendances afin qu'il ne se produise pas que nous soyons le premier service de la chaîne de mise à l'échelle et que ceux auxquels il se réfère tombent sous la charge. Pour établir une charge acceptable pour l'ensemble du pool de services, nous examinons les données historiques du service dépendant «le plus proche» (basé sur une combinaison de CPU et de RAM et de mesures spécifiques à l'application) et les comparons avec les données historiques du service d'initialisation, et ainsi de suite tout au long de la «chaîne de dépendance» ", De haut en bas.
Le service
Une fois le microservice mis en service, nous pouvons y suspendre des déclencheurs.
Voici des situations typiques dans lesquelles des déclencheurs se déclenchent.
- Migrations potentiellement dangereuses détectées.
- Des mises à jour de sécurité ont été publiées.
- Le service lui-même n'a pas été mis à jour depuis longtemps.
- La charge sur le service a considérablement diminué ou l'une de ses mesures de produit est au-delà de la plage normale.
- Le service a cessé de répondre aux nouvelles exigences de la plate-forme.
Certains déclencheurs sont responsables de la stabilité du travail, certains en fonction de la maintenance du système - par exemple, certains services n'ont pas été déployés depuis longtemps et son image de base a cessé de passer les contrôles de sécurité.
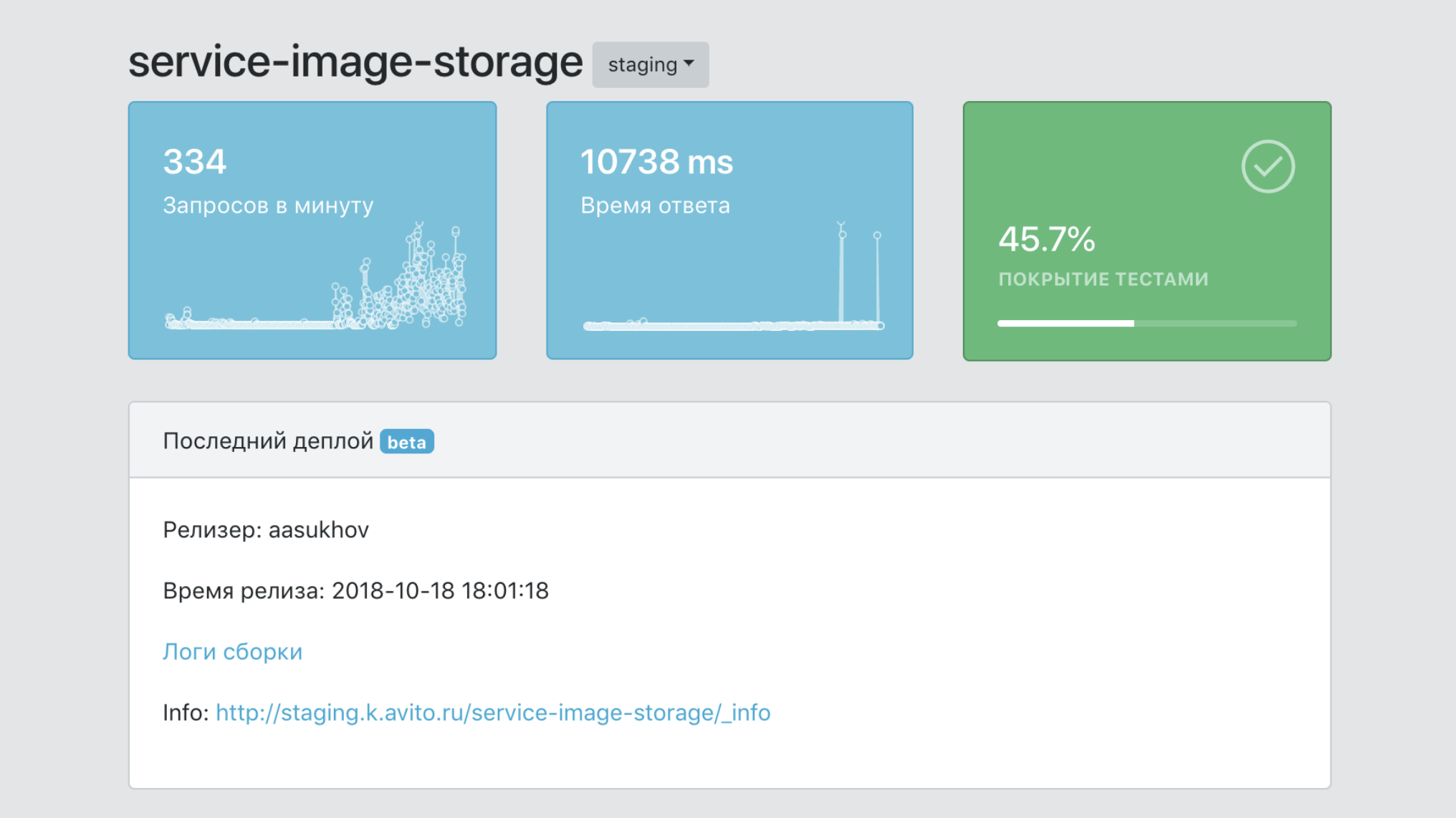
Tableau de bord
En bref, le tableau de bord est le panneau de contrôle de l'ensemble de notre PaaS.
- Un seul point d'information sur un service, avec des données sur sa couverture par les tests, le nombre de ses images, le nombre de copies de production, les versions, etc.
- Un outil de filtrage des données par services et labels (marqueurs d'appartenance aux business units, fonctionnalité produit, etc.)
- Moyens d'intégration avec des outils d'infrastructure pour le traçage, la journalisation, la surveillance.
- Une documentation de point de service unique.
- Un point de vue unique sur tous les événements de service.
Total
Avant l'introduction de la PaaS, un nouveau développeur pourrait passer plusieurs semaines à trier tous les outils nécessaires pour lancer un microservice en production: Kubernetes, Helm, nos fonctionnalités internes TeamCity, établir une connexion aux bases de données et aux caches sous une forme tolérante aux pannes, etc. Il faut maintenant quelques heures pour lire le démarrage rapide et effectuer le service lui-même.
J'ai fait un rapport sur ce sujet pour HighLoad ++ 2018, vous pouvez regarder la vidéo et la présentation .
Piste bonus pour ceux qui ont lu jusqu'au bout
À Avito, nous organiserons une formation interne de trois jours pour les développeurs de Chris Richardson , un expert en architecture de microservices. Nous voulons donner l'opportunité d'y participer à l'un des lecteurs de cet article. Voici un programme de formation.
La formation se tiendra du 5 au 7 août à Moscou. Ce sont des jours ouvrables qui seront entièrement occupés. Le déjeuner et la formation auront lieu dans nos bureaux, et le participant choisi paiera lui-même le voyage et l'hébergement.
Vous pouvez demander à participer à ce formulaire Google . De vous - la réponse à la question de savoir pourquoi exactement vous devez assister à la formation et des informations sur la façon de vous contacter. Répondez en anglais, car Chris choisira le participant qui se rendra à la formation.
Nous annoncerons le nom du participant à la formation en tant que mise à jour de cet article sur les réseaux sociaux d'Avito pour les développeurs (AvitoTech sur Facebook , Vkontakte , Twitter ) au plus tard le 19 juillet.
UPD, 19/07: Nous avons reçu des dizaines de candidatures. Chris les a examinés et a choisi un participant: avec nos collègues, Andrei Igumnov ira étudier. Félicitations!