Bonjour à tous. Mon équipe chez Tinkoff construit des systèmes de recommandation. Si vous êtes satisfait de votre cashback mensuel, alors c'est notre affaire. Nous avons également construit un système de recommandations d'offres spéciales de partenaires et sommes engagés dans des collections individuelles d'histoires dans l'application Tinkoff. Et nous aimons participer à des compétitions d'apprentissage automatique pour nous maintenir en forme.
Sur Boosters.pro pendant deux mois du 18 février au 18 avril, un concours a été organisé pour construire un système de recommandation sur les données réelles de l'un des plus grands cinémas en ligne russes Okko . Les organisateurs visaient à améliorer le système de recommandation existant. Pour le moment, la compétition est disponible en mode bac à sable , dans lequel vous pouvez tester vos approches et perfectionner vos compétences dans la construction de systèmes de recommandation.
Description des données
L'accès au contenu dans Okko se fait via l'application sur le téléviseur ou le smartphone, ou via l'interface web. Le contenu peut être loué®, acheté (P) ou consulté par abonnement (S). L'organisateur du concours a fourni des données sur les vues pendant N jours (N> 60), en outre, des informations sur les notes et les signets ajoutés étaient disponibles. Il convient de garder à l'esprit un détail important: si l'utilisateur a regardé un film plusieurs fois ou plusieurs épisodes de la série, seules la date de la dernière transaction et le temps total passé par unité de contenu seront enregistrés sur la tablette.
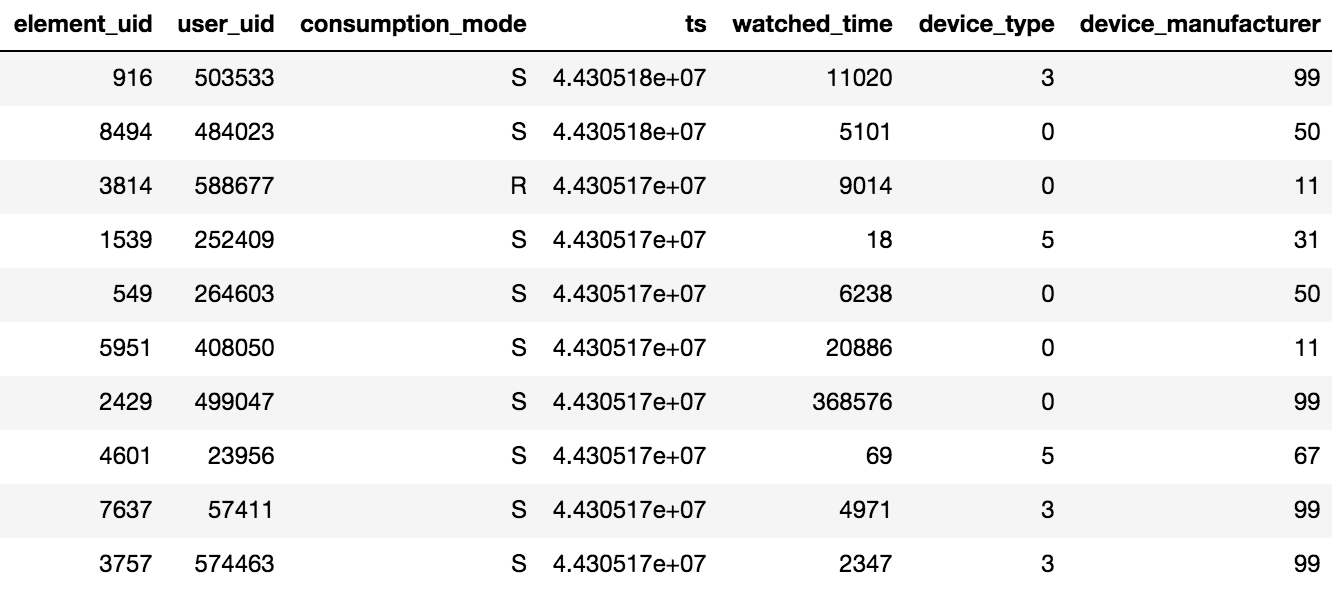
Environ 10 millions de transactions, 450 000 notations et 950 000 faits de signets pour 500 000 utilisateurs ont été fournis.
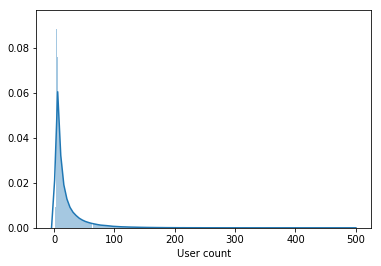
L'échantillon contient non seulement des utilisateurs actifs, mais aussi des utilisateurs qui ont regardé quelques films pendant toute la période.
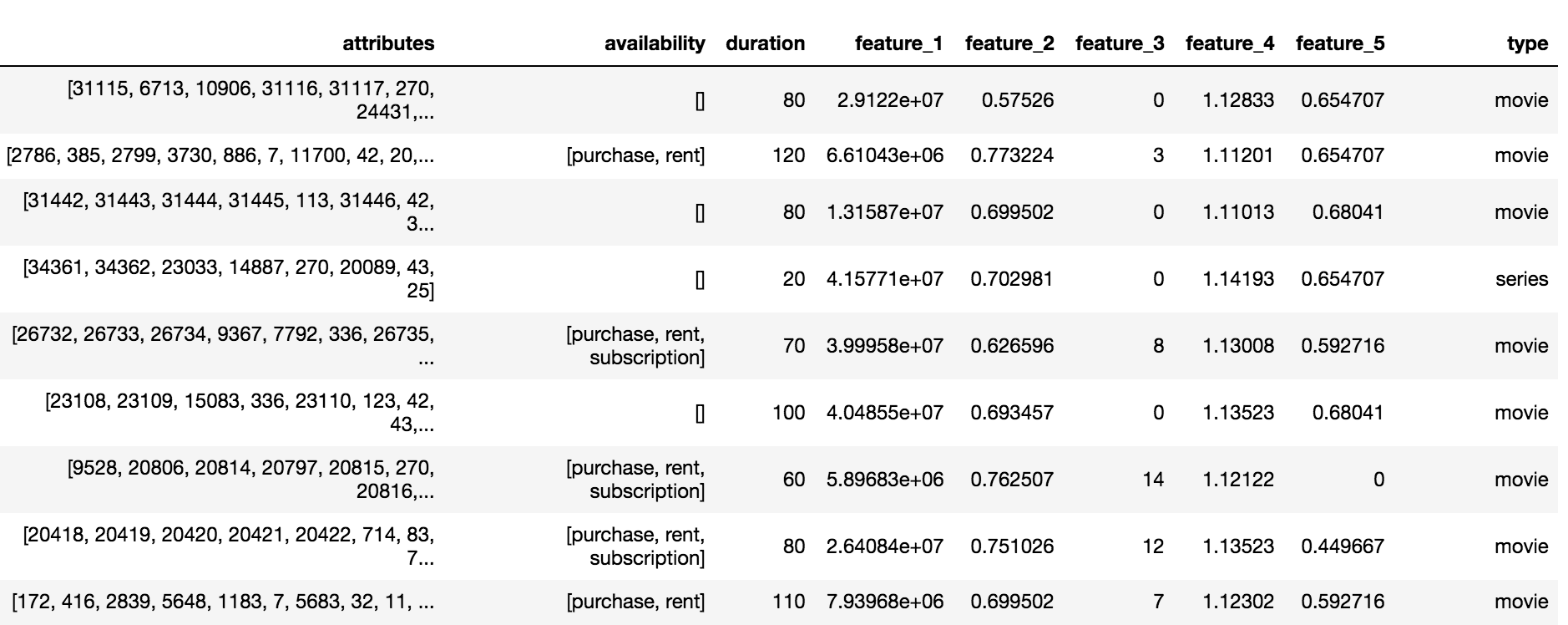
Le catalogue Okko contient trois types de contenus: films (film), séries (séries) et films en série (multipart_movie), soit un total de 10 200 objets. Pour chaque objet, un ensemble d'attributs et d'attributs anonymisés (fonctionnalité_1, ..., fonctionnalité_5), la disponibilité et la durée de l'abonnement, de la location ou de l'achat étaient disponibles.
Variable cible et métrique
La tâche exigeait de prévoir une grande quantité de contenu que l'utilisateur consommerait au cours des 60 prochains jours. On pense qu'un utilisateur consommera du contenu s'il:
- Achetez ou louez
- Regardez plus de la moitié du film par abonnement
- Regardez plus d'un tiers de la série par abonnement
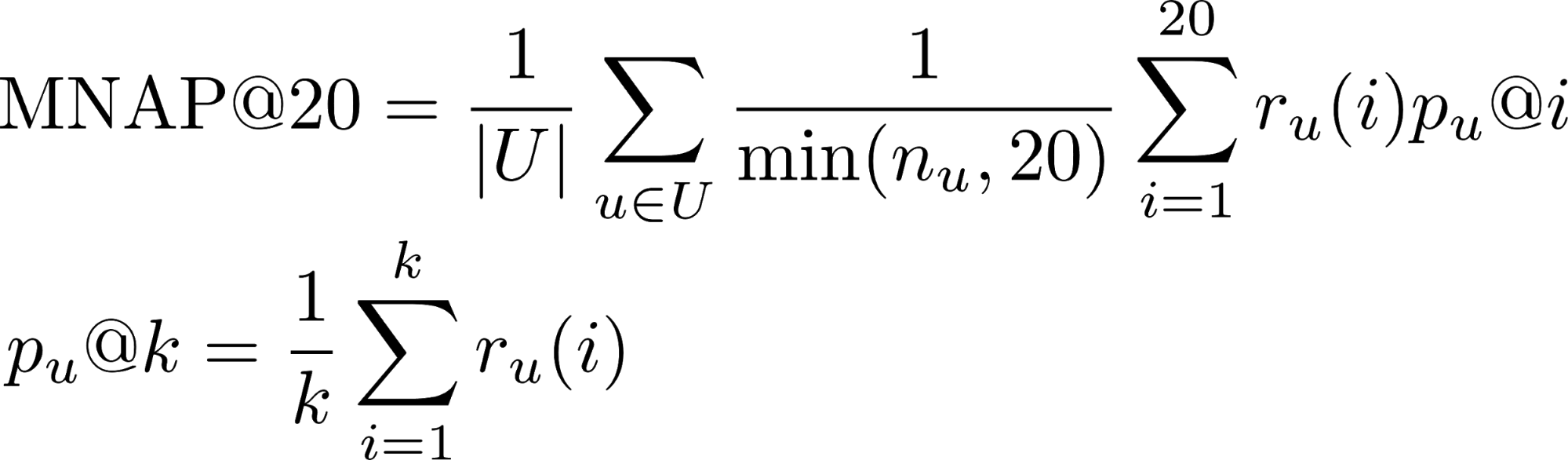
- r_u (i) - si l'utilisateur u a consommé le contenu qui lui a été prédit à la place i (1 ou 0)
- n_u - le nombre d'éléments consommés par l'utilisateur pendant la période de test
- U - de nombreux utilisateurs de test
Vous pouvez en savoir plus sur les mesures de la tâche de classement dans ce post .
La plupart des utilisateurs regardent des films jusqu'à la fin, donc la part de la classe positive sur les transactions est de 65%. La qualité de l'algorithme a été évaluée à l'aide d'un sous-ensemble de 50 000 utilisateurs de l'échantillon présenté.
Évaluation globale
La décision de la concurrence a commencé par l'agrégation de toutes les interactions des utilisateurs avec le contenu dans une seule échelle de notation. On a supposé que si l'utilisateur achetait le contenu, cela signifiait un intérêt maximum. Le film est plus court que la série, donc pour visualiser la série dans son ensemble, vous devez donner plus de points. Par conséquent, la note globale a été établie selon les règles suivantes:
- Partage de film * 5
- Séries télévisées Partager * 10
- [Signet du film] * 0,5
- [Mise en signet de la série] * 1,5
- [Achat / location de contenu] * 15
- Évaluation + 2
Modèle de premier niveau
Les organisateurs ont fourni une solution de base basée sur un filtrage collaboratif avec des échelles Tf-IDF. En ajoutant tous les types d'interactions à la note globale, en augmentant le nombre de voisins les plus proches de 20 à 150 et en remplaçant Tf-IDF par des poids BM25, on a éliminé environ 0,03 sur LB (Leader Board).
Inspiré par le post de l'équipe qui a pris la 3ème place au RecSys Challenge 2018 , j'ai choisi le modèle LightFM avec perte WARP comme deuxième modèle de base. LightFM avec des paramètres hyper sélectionnés: learning_rate, no_components, item_alpha, user_alpha, max_sampled a donné 0,033 sur LB.

La validation du modèle a été effectuée à temps: les 80% des premières interactions sont tombées dans le train, les 20% restants en validation. Pour une soumission sur LB, un modèle a été formé sur l'ensemble de données avec des paramètres sélectionnés pour validation.
Mélange de modèles
À l'étape précédente, il s'est avéré construire deux bases de référence solides, de plus, leurs recommandations ont recoupé en moyenne 60% du contenu recommandé. S'il existe deux modèles forts et en même temps faiblement corrélés, leur mélange est une étape raisonnable.
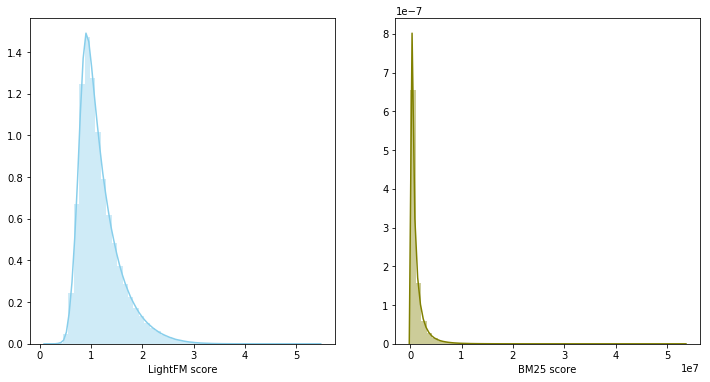
Dans ce cas, les scores du modèle appartiennent à différentes distributions et ont des échelles différentes, il a donc été décidé d'utiliser la somme des rangs pour combiner les deux modèles. Le mélange de modèles a donné 0,0347 sur LB.

Modèle de deuxième niveau
Les systèmes de recommandation utilisent souvent une approche à deux niveaux pour construire des modèles: tout d'abord, les meilleurs candidats sont sélectionnés par un simple modèle de premier niveau, puis le sommet sélectionné est reclassé par un modèle plus complexe avec l'ajout d'un grand nombre de fonctionnalités.

L'ensemble de données a été divisé dans le temps en parties de formation et de validation. Une sélection de recommandations a été collectée pour la partie validation pour chaque utilisateur, consistant à combiner les 200 premières prévisions de modèles de premier niveau à l'exception des films déjà regardés. En outre, il était nécessaire d'apprendre au modèle à réorganiser le sommet résultant pour chaque utilisateur. Le problème a été formulé en termes de classification binaire. Une paire (utilisateur, contenu) n'appartient à la classe positive que si l'utilisateur a consommé le contenu pendant la période de validation. En tant que modèle de second niveau, le renforcement du gradient a été utilisé, à savoir le package LightGBM.
Signes
Les modèles de premier niveau pour les paires (utilisateur, contenu) évaluent la pertinence sous la forme d'une vitesse, triant qui, par ordre décroissant, vous permet d'obtenir un classement. Le modèle formé sur les signes de rang et de vitesse, ainsi que les signes du catalogue de contenu, ont mis 0,0359 sur LB.
À partir de la forme de distribution de la première des fonctionnalités anonymisées, il a été conclu que c'est la date à laquelle le film est apparu dans le catalogue.Par conséquent, le modèle a été fortement recyclé pour cette fonctionnalité avec le schéma de validation sélectionné. La suppression d'une caractéristique de l'échantillon a donné une augmentation de LB à 0,0367
Le modèle LightFM, en plus de prédire la pertinence du contenu pour l'utilisateur, renvoie deux vecteurs: le biais d'élément et le biais d'utilisateur, qui sont en corrélation avec le degré de popularité du contenu et le nombre de films visionnés par l'utilisateur, respectivement. L'ajout de signes a augmenté la vitesse sur LB à 0,0388 .
Vous pouvez attribuer un classement à une paire (utilisateur, contenu) avant ou après la suppression des films déjà regardés. Les changements de méthode à ce dernier ont entraîné une augmentation du LB à 0,0395 .
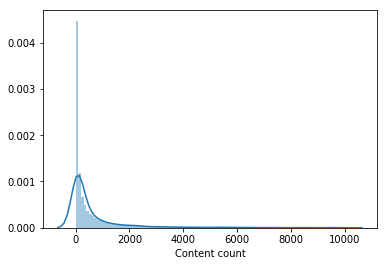
Presque personne n'a regardé une partie importante du catalogue de films. Le contenu regardé par moins de 100 utilisateurs a été supprimé de l'échantillon pour la formation d'un modèle de deuxième niveau, ce qui a réduit le catalogue de moitié. La suppression du contenu impopulaire a rendu la sélection des modèles de premier niveau plus pertinente et ce n'est qu'après que le vecteur d'utilisateurs de LightFM a amélioré la vitesse de validation et a donné une augmentation de LB à 0,0429 .
De plus, un signe a été ajouté - l'utilisateur a ajouté le signet au livre, mais n'a pas regardé la période du train, ce qui a augmenté la vitesse sur LB à 0,0447 . De plus, des panneaux indiquant la date de la première et de la dernière transaction ont été ajoutés, ils ont augmenté la vitesse à 0,0457 sur LB.

Nous considérerons ce modèle comme définitif. Les signes les plus importants étaient des signes de modèles de premier niveau et des signes anonymisés du catalogue de contenu.
Les fonctionnalités suivantes ne sont pas passées au modèle final:
- nombre de signets + part du contenu consulté des signets - 0,0453 LB
- le nombre de films achetés 0,0451 LB
Mais lors de la fusion avec le modèle final, ils ont assommé 0,0465 sur LB. Inspirés par le résultat du mélange, les modèles suivants ont été formés séparément:
- avec différentes fractions de l'échantillon d'apprentissage pour le modèle de premier niveau. La répartition de 90% / 10% a donné une augmentation, contrairement à la répartition de 95% / 5% et 70% / 30%.
- avec une méthode d'agrégation de notation modifiée.
- avec l'ajout de films impopulaires à l'ensemble de formation pour un modèle de deuxième niveau. Pour chaque unité de contenu, une compilation de 1000 utilisateurs a été compilée.
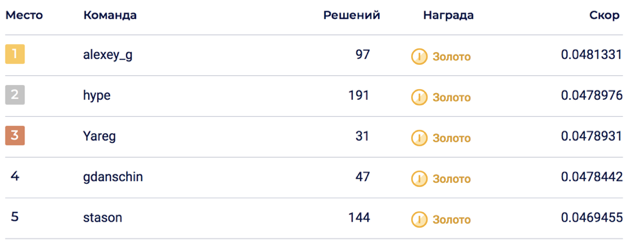
Le mélange final de 6 modèles a permis d'atteindre 0,0469678 sur LB, ce qui correspondait à la 5e place.

Sur la partie privée, un bouleversement s'est produit, qui a jeté la solution à la 2e place. Je pense que la solution s'est avérée durable grâce au mélange d'un grand nombre de modèles.
Pas entré
Dans le processus de résolution de la compétition, de nombreux signes ont été générés qui semblaient définitivement entrer, mais hélas. Signes et approches les plus fiables:
- Attributs de contenu anonyme. On ne savait pas avec certitude ce qu'ils contenaient, mais tous les participants au concours pensaient qu'ils contenaient des informations sur les acteurs, les réalisateurs, les compositeurs ... Dans ma décision, j'ai essayé de les ajouter sous plusieurs formats: les plus populaires en tant que personnages binaires, disposer une matrice de contenu à l'aide de LightFM et BigARTM, puis extrayez les vecteurs et ajoutez-les au modèle de deuxième niveau.
- Vecteurs de contenu du modèle LigthFM dans le modèle de deuxième niveau.
- Attributs des appareils à partir desquels l'utilisateur a visualisé le contenu.
- Réduire le poids du contenu populaire pour un modèle de deuxième niveau.
- La proportion de films / émissions de télévision par rapport au nombre total de contenus visionnés.
- Classement des métriques de CatBoost.
Faits intéressants sur la compétition
- La solution Top1 s'est avérée pire que le modèle de produit okko 0,048 vs 0,062. Il convient de garder à l'esprit que le modèle de produit était déjà lancé au moment de l'échantillonnage.
- Environ une semaine après le début de la compétition, l'ensemble de données a été modifié, pour ceux qui ont participé depuis le tout début, ils ont ajouté 30 soumissions, qui ont brûlé de manière inattendue après la fusion des équipes.
- La validation n'était pas toujours en corrélation avec LB, ce qui indiquait un bouleversement possible.
Code de décision
La solution est disponible sur github sous la forme de deux ordinateurs portables jupyter: agrégation de notes, modèles de formation des premier et deuxième niveaux.
Une solution de 3e place est également disponible sur github .
La décision des organisateurs
Au lieu de mille mots, j'attache les principales fonctionnalités des organisateurs.
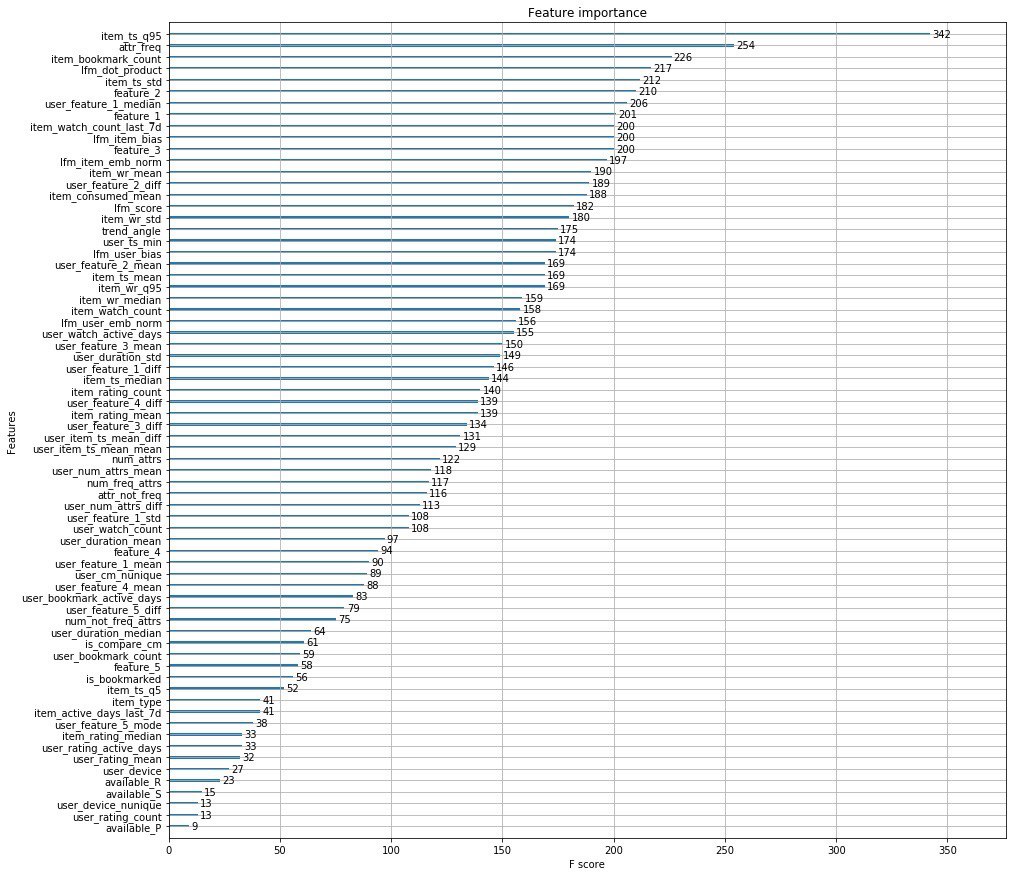
De plus, les gars d'Okko ont publié un article dans lequel ils parlent des étapes de développement de leur moteur de recommandation.
PS ici, vous pouvez voir les performances au Data Fest 6 sur cette solution au problème.