
Si l'un de vos projets utilise les données stockées dans la base de données Azhurov, il est fort possible que vous ayez la possibilité d'utiliser la recherche de données à l'aide de la recherche Azure. Vous pouvez rechercher non seulement par des bases de données (Azure Cosmos DB, Azure SQL Database, SQL Server hébergé dans une machine virtuelle Azure), mais également par Blob (Azure Blob Storage, Azure Table Storage).
La recherche a un tarif gratuit, qui vous permet de créer jusqu'à trois index d'une taille totale allant jusqu'à 50 Mo. Le tarif gratuit n'a pas de capacité d'équilibrage de charge, mais il est tout à fait adapté à une utilisation.
Gérer la recherche m'a semblé assez simple (bien que ce ne soit pas toujours évident). Il existe 3 types d'objets: source de données, index et indexeur. L'objet principal, peut-être, est l'index. C'est lui qui est responsable de la recherche et de ce qu'il faut chercher exactement. La source de données est une connexion de données et l'indexeur est un travail qui met à jour les données d'index.
L'interface utilisateur du portail vous permet d'importer des données et de créer les trois objets. L'occasion se présentera au passage et ajoutera des capacités cognitives à la recherche. Si la base de données SQL est dans l'abonnement, vous pouvez la sélectionner lors de la création de la source de données. Bien que le mot de passe pour une raison quelconque, vous devez toujours entrer. Si vous souhaitez utiliser Cosmos DB, vous devrez entrer la chaîne de connexion manuellement. N'oubliez pas d'indiquer dans la ligne et la base de données, en ajoutant à la fin de la ligne Base de données = YOUR_BASE_NAME
Après avoir choisi une source de données, vous serez invité à utiliser les capacités de recherche cognitive. L'ensemble des compétences par défaut est encore assez petit: vous pouvez définir la langue, extraire les noms, les noms d'organisations, les lieux et les phrases clés. Il existe également une opportunité intéressante pour déterminer la nature du texte des émotions positives ou négatives à l'aide de la détection des sentiments. Cette compétence devrait être pratique à utiliser avec les avis sur les produits dans les magasins en ligne. Il est possible de créer votre propre compétence en utilisant la description de l'API.
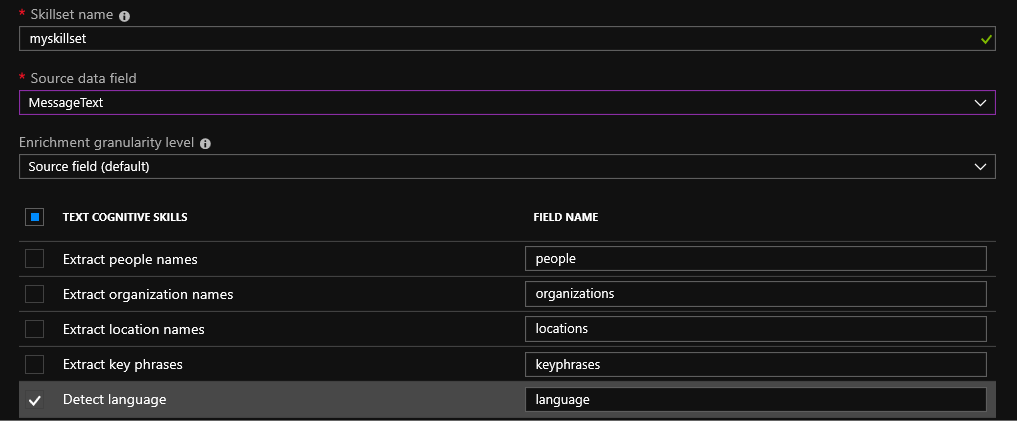
Pour les fichiers téléchargés sur blob, l'OCR (Optical Character Recognition) est possible. La reconnaissance des textes manuscrits (jusqu'à présent uniquement en anglais) et imprimés est possible. Grâce aux services cognitifs, il est possible d'identifier divers objets sur la photo. Par exemple, des lieux célèbres ou des célébrités.
L'étape suivante consiste à créer un index. La seule option pour le mode de recherche ce jour-là est «analyse d'InfixMatching»
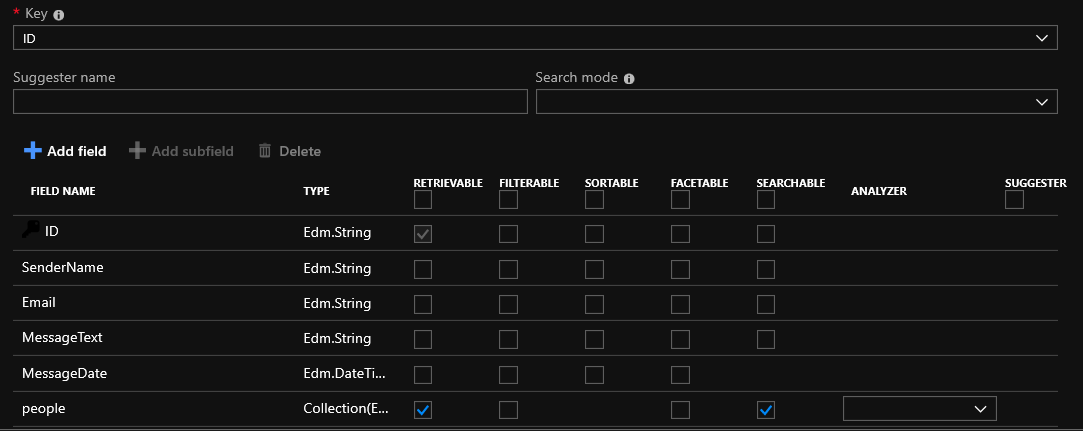
À ce stade, vous pouvez cocher les cases en regard des champs de votre table ou ajouter un nouveau champ à l'index. Au cas où, j'expliquerai les possibilités des champs:
Récupérable - le champ sera présent dans les résultats de la recherche
Filtrable - la valeur du champ peut être filtrée
Triable - vous pouvez trier le résultat par ce champ
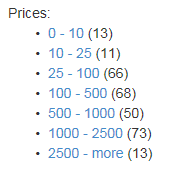
Facetable - une sorte de regroupement selon certaines caractéristiques. Par exemple, en utilisant l'expression facet = listPrice, valeurs: 10 | 25 | 100 | 500 | 1000 | 2500, vous pouvez obtenir la répartition suivante des résultats en groupes
Recherche - ce champ recherchera
Le champ Analyseur suggère de choisir un analyseur pour différentes langues. 2 versions sont utilisées - Lucene et Microsoft . Afin de comprendre quelle est la différence, vous devez comprendre quelle est la différence entre les deux termes suivants:
Le stamming est le processus de recherche de la base d'un mot pour un mot source donné. Tige (anglais) - tige, tige, origine. La tige utilise des algorithmes. Tronque souvent les mots en supprimant les suffixes et les terminaisons, obtenant ainsi la base du mot.
La lemmatisation est le processus de réduction d'une forme verbale en lemme - sa forme normale (vocabulaire). Le lemme est la forme canonique et fondamentale du mot. La lemmatisation utilise une recherche par dictionnaire contenant diverses formes de mots.
L'analyseur Lucene utilise le stemming. L'analyseur Microsoft utilise la lemmatisation.
Par défaut, si rien n'est sélectionné, Lucene est utilisé. Mais si vous recherchez des données dans une langue particulière, il est sans aucun doute préférable d'utiliser un analyseur pour cette langue.
Suggestion - vous permet de donner des indices avec des documents contenant le texte saisi en utilisant les premières lettres de la recherche.
Si vous utilisez le probester dans Azure Search dans l'application cliente, vous aurez 2 options pour l'utiliser: l' invite elle-même ou la saisie semi - automatique . En bref, l'invite suggère complètement la ligne entière du champ de table et la saisie semi-automatique ne propose que de compléter un mot ou une expression à partir de quelques mots. Le meilleur article sur les différences entre les modes d'invite et de saisie semi-automatique est décrit dans l'article suivant: La saisie semi - automatique dans Azure Search maintenant en aperçu public Cet article a des gifs très visuels.
Au stade de la création de l' indexeur, vous devez spécifier une colonne de filigrane élevé . Il s'agit d'un champ qui change chaque fois qu'un enregistrement est modifié. Il s'agit généralement d'un champ contenant la date de la dernière modification ou d'un champ _ts dans Cosmos DB. Pendant l'indexation, si la valeur du champ est modifiée, l'index changera également.
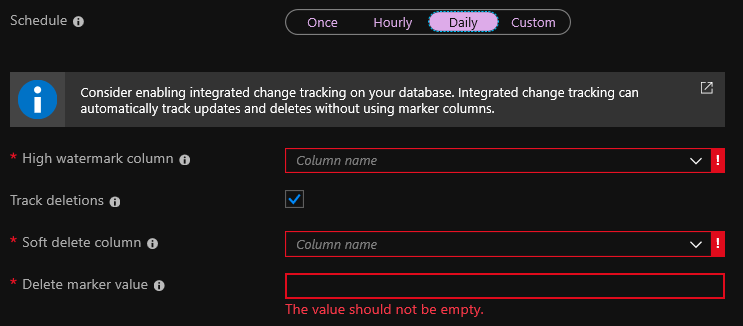
La suppression des pistes est une option pour supprimer automatiquement les entrées de l'index. Mais pour cela, vous devez avoir configuré la suppression logicielle dans votre base de données. Si vous utilisez la suppression logicielle, lorsque vous supprimez un enregistrement, il n'est pas supprimé, mais simplement marqué comme supprimé. L'option standard consiste à ajouter le champ isDeleted à la base de données et à le définir sur true si l'enregistrement est supprimé.
Alternativement, chaque fois que vous supprimez une entrée de la base de données, vous pouvez envoyer une demande de suppression de la recherche à l'API Azure Search. Dans ce cas, la case à cocher Suppressions de trak peut être omise. Mais je n'aime pas vraiment cette option, car si la demande de suppression ne fonctionne pas, l'enregistrement restera dans l'index. Quant à moi, il n'y a pas assez de possibilité de reconstruire complètement l'indice une fois dans une certaine période de temps.
Malgré toute la commodité du portail, après la création, vous pouvez ajouter de nouveaux champs à l'index, mais vous ne pouvez pas modifier les champs existants. Que faire si vous devez changer quelque chose? Vous pouvez recréer l'index. Supprimez celui existant et créez-en un nouveau contenant les modifications nécessaires. Utiliser le portail pour ce faire est une tâche plutôt morne. J'utilise l'API à ces fins. En utilisant une application comme Postman, vous pouvez obtenir l'index JSON et l'utiliser pour écrire une demande de création d'index. Il suffit de faire de petites modifications (par exemple, supprimez les champs système "@ odata.context" et "@ odata.etag").
Pour travailler avec l'API, vous devez retirer la clé du portail, qui doit être ajoutée à l'en-tête de chaque demande d'API. La clé est prise ici:
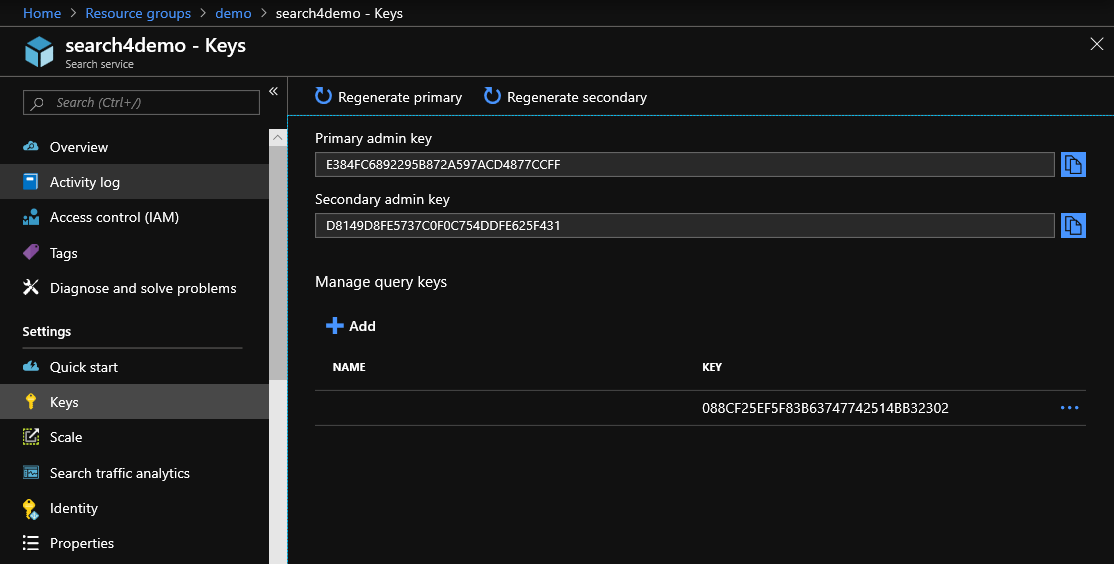
Une requête pour obtenir des données d'index est:
GET https://[service name].search.windows.net/indexes/[index name]?api-version=[api-version]
api-key: [admin key] doit être ajoutée à l'en-tête api-key: [admin key]
La création d'un index est possible à l'aide de l'une des deux requêtes suivantes:
POST https://[servicename].search.windows.net/indexes?api-version=[api-version] Content-Type: application/json api-key: [admin key]
ou
PUT https://[servicename].search.windows.net/indexes/[index name]?api-version=[api-version]
Dans le corps, vous devez spécifier JSON avec le contenu de l'index. La dernière version pour le moment est le 2019-05-06, et avant qu'elle ne soit utilisée longtemps 2017-11-11
Grâce à l'API, vous pouvez utiliser certaines fonctionnalités de recherche qui ne sont pas disponibles sur le portail.
Afin de donner la priorité à certains champs dans la recherche, vous pouvez utiliser des profils de notation .
Le JSON suivant ajouté à la demande donne au champ "titre" un double avantage sur le champ "info":
"scoringProfiles": [ { "name": "profileForTitle", "document": { "weights": { "title": 2, “info": 1 } } ]
En plus de la possibilité de donner la priorité à certains champs à l'aide de poids, il est possible d'utiliser certaines fonctions prédéfinies: fraîcheur, amplitude, distance et étiquette.
La fraîcheur est utilisée uniquement avec les champs DateTime et vous permet d'afficher les derniers enregistrements dans la recherche. La magnitude est utilisée avec les champs int et double. Eh bien et en conséquence, cette fonction est bonne à utiliser avec les champs stockant les prix, le nombre de téléchargements et d'autres informations numériques. La distance est utilisée uniquement avec des champs tels que Edm.GeographyPoint et est augmentée dans une recherche par distance à partir d'un emplacement spécifique. Si balise est spécifiée comme type de fonction, les documents contenant des balises qui apparaissent dans la chaîne de recherche seront générés lors de la recherche.
L'une des options les plus populaires consiste à récupérer les derniers documents dans une recherche comme celle-ci:
"scoringProfiles": [{ "name":"newDocs", "functions": [ { "type": "freshness", "fieldName": "documentDate", "boost": 10, "interpolation": "quadratic", "freshness": { "boostingDuration": "P7D" } } ] } ]
Les documents dont le champ documentDate contient la date des sept derniers jours ("P7D") seront relevés.
Après avoir créé un profil de notation, vous pouvez spécifier son nom dans les demandes. Ce n'est que dans ce cas que les champs nécessaires seront relevés lors de la recherche.
En savoir plus dans la documentation officielle: ajouter des profils de score à un index Azure Search
Politique de détection des modifications de données
L'API fournit un peu plus de fonctionnalités pour la source de données. Comme vous pouvez le lire ci-dessus, lors de la création d'une source de données, vous pouvez spécifier un champ permettant de déterminer si les données ont changé. Sous la forme de JSON, cela ressemble à ceci:
"dataChangeDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.HighWaterMarkChangeDetectionPolicy", "highWaterMarkColumnName" : "[a rowversion or last_updated column name]" } soft delete policy: "dataDeletionDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" }
Si vous utilisez SQL Server et que votre base de données prend en charge le suivi des modifications, les enregistrements supprimés peuvent être supprimés automatiquement de l'index. La spécification de highWaterMarkColumnName dans ce cas n'est pas requise. Il suffit de spécifier SqlIntegratedChangeTrackingPolicy au lieu de HighWaterMarkChangeDetectionPolicy
"dataChangeDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.SqlIntegratedChangeTrackingPolicy" }
C'est très pratique. Mais il y a des nuances qui ne permettent pas de profiter pleinement de cette fonctionnalité.
Tout d'abord, SqlIntegratedChangeTrackingPolicy ne peut pas être utilisé avec des vues. Deuxièmement, la table ne doit pas avoir de clés primaires composites. Il va sans dire que la version de SQL Server doit être plus ou moins nouvelle. Enfin, le suivi des modifications doit être activé pour la base de données et les tables utilisées par la recherche. Pour la base de données, il s'allume comme ceci:
ALTER DATABASE AdventureWorks2012 SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON)
Et pour la table comme celle-ci:
ALTER TABLE Person.Contact ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)
Mais ce n'est pas tout. Il est fortement recommandé d'activer l'isolement de capture instantanée pour la base.
ALTER DATABASE AdventureWorks2012 SET ALLOW_SNAPSHOT_ISOLATION ON;
En plus de danser avec un tambourin lors de l'installation de Change Traking pour la base de données pour moi, l'inconvénient est l'impossibilité d'utiliser les vues. Donc je dois toujours utiliser HighWaterMarkChangeDetectionPolicy
Recherche de données
Par défaut, la recherche Azure utilise une syntaxe de requête simple . Cela peut ne pas paraître surprenant, mais c'est assez simple:
wifi + luxe recherche les mots wifi et luxe en même temps
"hôtel de luxe" cherche la phrase
wifi | le luxe recherche le mot wifi ou le mot luxe
wifi –luxury recherche les textes avec le mot wifi mais sans le mot luxe
lux recherche des mots commençant par lux
Il est possible de combiner des règles de recherche à l'aide de parenthèses. Par exemple, la règle motel + (wifi | luxe) recherche le mot motel et le mot wifi ou le mot luxe
C'est bien qu'Azure Search puisse utiliser la syntaxe Lucene . Pour l'utiliser, il est nécessaire d'ajouter queryType = full à la requête de recherche
La différence entre Azure et la syntaxe Lucene classique ne réside qu'en l'absence de plage.
Ainsi, dans Azure Search, vous ne pouvez pas: mod_date:[20020101 TO 20030101]
Mais dans Azure Search, vous pouvez utiliser $ filter avec la syntaxe ODATA . Voici un exemple de filtre:
{ "name": "Scott", "filter": "(age ge 25 and and lt 50) or surname eq 'Guthrie'" }
Les filtres peuvent également être utilisés avec une syntaxe de requête simple.
Dans Lucene, la logique «ou» est implémentée en utilisant OR ou ||
Les deux valeurs peuvent être trouvées en spécifiant l'instruction «and» avec: AND , && or +
Pour "non", vous pouvez utiliser l'une des options suivantes: NON,! ou -
L'instruction «not» a une caractéristique commune à la fois à la syntaxe simple et à Lucene. Son comportement dépend du mode de recherche, qui peut être défini à la fois dans searchMode = all et dans searchMode = any (cette valeur est utilisée par défaut). Dans n'importe quel mode, la recherche de wifi-luxe trouvera des documents avec le mot wifi ou des documents sans le mot luxe. Dans le mode tout, par la même demande, il trouvera des quais avec le mot wifi et simultanément sans le mot luxe.
Voyons quelques fonctionnalités intéressantes de Lucene.
La recherche floue vous permet de rechercher des mots qui diffèrent de la recherche par une ou plusieurs lettres. Autrement dit, il aide à faire face aux fautes de frappe. Par exemple, une recherche de "blue ~" ou "blue ~ 1" vous renverra avec "blue" et "blues" et même "glue". Mais en même temps, une recherche de "business ~ analyst" signifie business ou analyst
La proximité vous permet de rechercher des mots à proximité. Par exemple, "hotel airport" ~ 5 trouvera les mots "hotel" et "airport" qui sont situés dans le texte à 5 mots l'un de l'autre.
L'amplification des termes vous permet de définir la priorité d'un mot dans la recherche. Exemple: "rock ^ 2 electronic" recherche les mots rock et electronic, mais les entrées avec le mot rock dans la recherche seront affichées ci-dessus.
Expressions régulières - utilisation d'expressions régulières. Tout ici est conforme à la documentation officielle de Lucene regex. Vous pouvez la retrouver par le lien suivant . Lors de la recherche, des expressions régulières doivent être placées entre les barres obliques "/". Par exemple, comme ceci: / [mh] otel /
Si votre chaîne de recherche contient des caractères spéciaux, ils doivent être échappés avec une barre oblique inverse. Exemples de caractères à échapper: + - && ||! () {} [] ^ "~ *?: \ /
La recherche peut être effectuée à l'aide d'une demande GET. L'exemple officiel est le suivant:
GET /indexes/hotels/docs?search=category:budget AND \"recently renovated\"^3&searchMode=all&api-version=2019-05-06&querytype=full
Mais vous pouvez utiliser une requête POST avec body. Encore une fois, un exemple officiel:
POST /indexes/hotels/docs/search?api-version=2019-05-06 { "search": "category:budget AND \"recently renovated\"^3", "queryType": "full", "searchMode": "all" }
Si vous utilisez une demande GET ou POST avec le type de données application / x-www-form-urlencoded, vous devez coder les caractères non sécurisés et réservés.
Symboles /?: @ = & sont réservés
Les caractères `` <> #% {} | \ ^ ~ [] ne sont pas sûrs.
Par exemple, le symbole # deviendra% 23 et le symbole? devient% 3F
Quelques liens pour les développeurs.
Si .NET est un développeur, vous pouvez utiliser le package Microsoft.Azure.Search NuGet . De plus, il existe des exemples dans NodeJS et Java .
Un exemple d'une application simple sur .NET Core que vous pouvez trouver ici ASP.NET Core Azure search sample