Habituellement, les performances sont comprises comme le nombre d'opérations pour un certain intervalle de temps, et plus elles sont nombreuses, mieux c'est. Mais une telle définition, et l'approche dans son ensemble, a peu d'applicabilité au front-end, car chaque utilisateur aura son propre «front-end». C'est de cela que je veux parler, de ce qui se passe «là-bas», avec l'utilisateur, de l'autre côté, en réalité, et non sur votre MacBook.
En plus de cela, je vais essayer de considérer brièvement les règles générales d'optimisation du code et quelques erreurs qui méritent une attention particulière. Je vais également vous parler d'un
outil qui aide non seulement au profilage, mais recueille également un ensemble de mesures de base sur les performances de votre application (et j'espère que vous lirez cet article jusqu'à la fin).
Tout d'abord, nous déterminerons ce que sont les performances frontales, puis nous passerons à la façon de les mesurer. Donc, comme je l'ai dit, nous ne mesurerons pas quelques ops / sec, nous avons besoin de données réelles qui pourraient répondre à la question de ce qui se passe exactement avec notre projet à chaque étape de son travail. Pour ce faire, nous avons besoin de l'ensemble de mesures suivant:
- vitesse de téléchargement;
- heure du premier rendu et interactivité (Time To Interactive);
- vitesse de réaction aux actions de l'utilisateur;
- FPS pour le défilement et les animations;
- initialisation de l'application;
- si vous avez un SPA, vous devez mesurer le temps passé à changer d’itinéraire;
- mémoire et consommation de trafic;
- et ... assez pour l'instant.
Ce sont toutes des métriques de base, sans lesquelles il est impossible de comprendre ce qui se passe exactement sur le front-end. Et pas seulement à l'avant, mais en réalité, avec l'utilisateur final. Mais pour commencer à collecter ces mesures, vous devez d'abord apprendre à les mesurer, alors rappelons quelles méthodes existent pour l'analyse des performances.
La première chose à commencer est bien sûr l'API Performance. À savoir,
performance.timing , à travers lequel vous pouvez savoir combien de temps il a fallu à un utilisateur pour ouvrir votre projet. Mais l'API Performance ne couvre qu'une partie de la métrique, le reste devra être mesuré par nous-mêmes, et pour cela nous avons les outils suivants:
À ce moment-là, j'ai réalisé que vous devez voir un outil qui combinera les avantages de ce qui précède et, si possible, n'a aucun inconvénient. Il y avait donc
PerfKeeper .
Perfkeeper
- Contrôle total sur le début et la fin.
- Vous pouvez envoyer au serveur.
- Il s'affiche dans la console.
- Prend en charge DevTools -> Performance -> Timing utilisateur.
- Il y a un regroupement.
- Il existe un codage couleur (ainsi que des unités de mesure, c'est-à-dire que vous pouvez mesurer non seulement le temps).
- Prend en charge les extensions.
Maintenant, je n'écrirai pas l'API ici, je n'ai pas écrit de
documentation pour cela, et l'article ne traite pas de cela, mais je vais continuer sur la façon de collecter des statistiques.
Vitesse de téléchargement des pages
Comme je l'ai déjà dit, vous pouvez connaître la vitesse de téléchargement à partir de
performance.timing , qui vous permettra de connaître le cycle complet depuis le début du chargement de la page (temps pour résoudre DNS, installation de HTTP Handshake, traitement de la demande) et jusqu'à ce que la page soit entièrement chargée (DomReady et OnLoad):
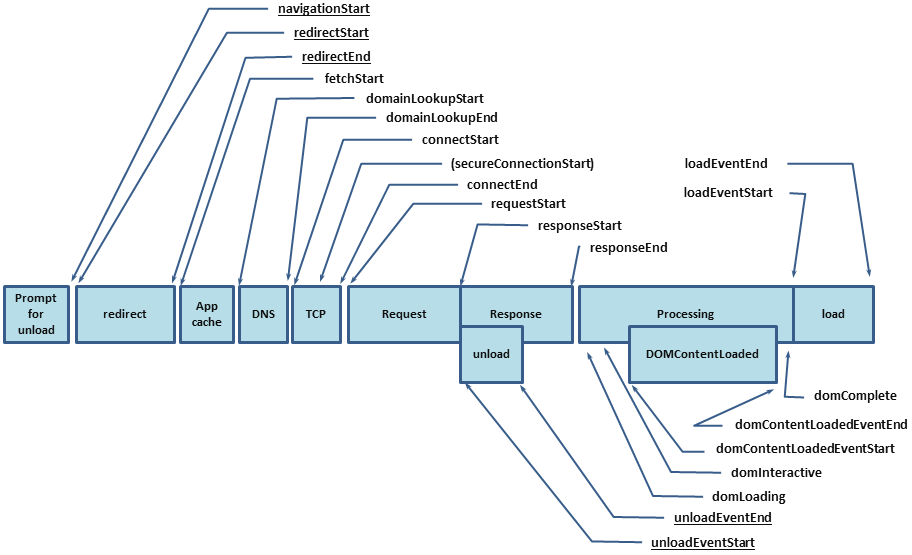
Par conséquent, vous devez obtenir l'ensemble de métriques suivant:
Un exemple de l'extension de navigation pour @ perf-tools / keeper .Mais cela ne suffit pas, nous n'avons obtenu que les valeurs de base et nous ne savons toujours pas exactement ce qui a pris autant de temps. Et pour le savoir, vous devez également remplir des métriques HTML.
Comme je l'ai déjà dit, je vais montrer des exemples en utilisant
PerfKeeper , donc la première chose à faire est en ligne dans
<hed/> PerfKeeper lui-même (2,5 Ko) et plus loin:

En conséquence, vous verrez une telle beauté dans la console:
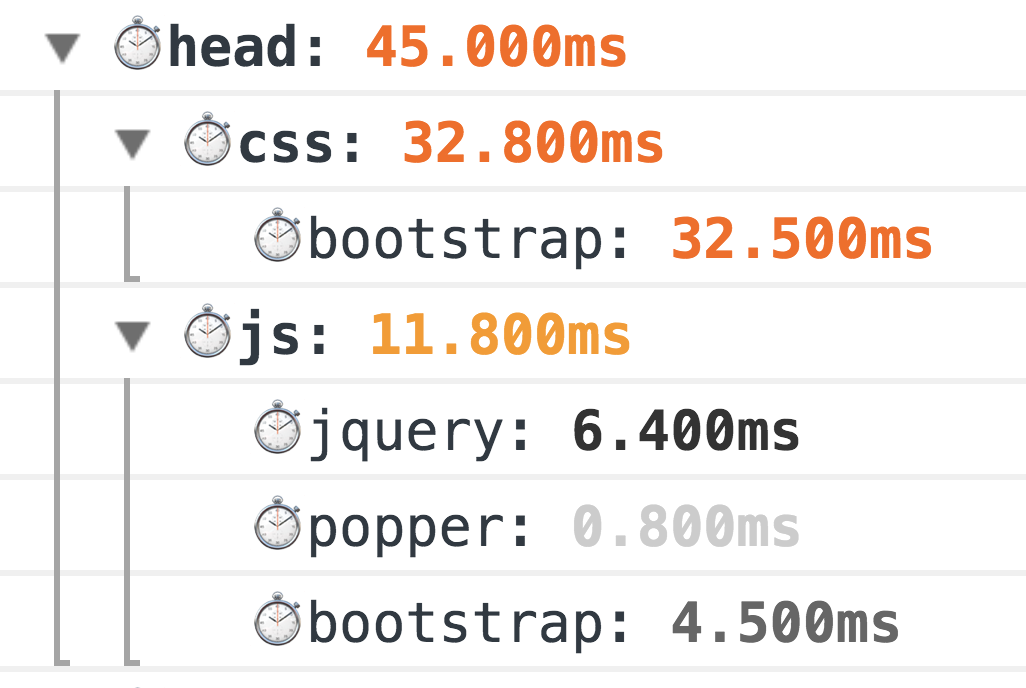
Il s'agit d'une méthode de mesure grand-père classique, 100% fonctionne. Mais le monde ne reste pas immobile, et pour des mesures plus précises, nous avons maintenant l'
API Resource Timing (et si les ressources sont sur un domaine
Timing-Allow-Origin séparé pour vous aider).
Et ici, il vaut la peine de parler des erreurs classiques lors du chargement initial de la page, à savoir:
- manque de GZip et HTTP / 2 (oui, c'est encore courant);
- utilisation déraisonnable des polices (parfois une police n'est connectée que pour un seul en-tête ou même un numéro de téléphone dans le pied de page 0_o);
- Bundles CSS / JS trop génériques.
Comment optimiser le chargement des pages:
- utiliser Brotli (ou même SDCH) au lieu de GZip, activer HTTP / 2;
- Ne collectez que le CSS nécessaire (critique) et n'oubliez pas CSSO ;
- minimiser la taille du bundle JS en séparant le bundle CORE minimum et charger le reste à la demande, c'est-à-dire asynchrone;
- charger JS et CSS en mode non bloquant, en créant dynamiquement
/> <sript src="..."/> , idéalement charger JS après le contenu principal; - utilisez SVG au lieu de PNG, et s'il est combiné avec JS, il supprimera le XML redondant (par exemple, comme font-awesome );
- utilisez le chargement paresseux pour les images et les iframes (en plus de cela, le support natif apparaîtra dans un proche avenir).
Temps de premier rendu et interactivité (TTI)
L'étape suivante après le chargement est le moment où l'utilisateur a vu le résultat et l'interface est passée en mode interactif. Pour cela, nous avons besoin de
Performance Paint Timing et de
PerformanceObserver .
La première est simple, nous appelons
performance.getEntriesByType('paint') et nous obtenons deux mesures:
- first-paint - le premier rendu;
- premier-contentful-paint - et le premier rendu complet.
 Un exemple de l'extension de peinture pour @ perf-tools / keeper .
Un exemple de l'extension de peinture pour @ perf-tools / keeper .Mais avec la prochaine métrique, Time To Interactive, c'est un peu plus intéressant. Il n'y a aucun moyen exact de déterminer quand votre application est devenue interactive, c'est-à-dire accessible à l'utilisateur, mais cela peut être indirectement compris par l'absence de
tâches longues :
 Un exemple de l'extension de performances pour @ perf-tools / keeper .
Un exemple de l'extension de performances pour @ perf-tools / keeper .En plus de ces mesures de base, votre mesure de préparation des applications est également nécessaire, c'est-à-dire quelque part dans votre code devrait ressembler à ceci:
Import { system } from '@perf-tools/keeper'; export function applicationBoot(el, data) { const app = new Application(el, data);
Taux de réponse aux actions des utilisateurs
Il y a un énorme champ pour les métriques et elles sont très individuelles, donc je vais parler de deux de base qui conviennent à tout projet, à savoir:
premier événement - l'heure du premier événement, par exemple, le premier clic (en divisant où l'utilisateur a poussé), cette métrique est particulièrement pertinente pour tous les types de résultats de recherche, une liste de produits, des flux d'actualités, etc. Avec lui, vous pouvez contrôler la façon dont le temps de réaction et le flux utilisateur de vos actions (changements dans: conception / nouvelles fonctionnalités / optimisations, etc.) changent
 Un exemple de l'extension de performances pour @ perf-tools / keeper .latence
Un exemple de l'extension de performances pour @ perf-tools / keeper .latence - délai lors du traitement de certains événements, par exemple:
click ,
input ,
submit ,
scroll , etc.
Pour mesurer le retard, accrochez simplement le gestionnaire d'événements sur la
window avec
capture = true et utilisez
requestAnimationFrame calculer la différence, ce sera le délai:
window.addEventListener(eventType, ({target}) => { const start = now(); requestAnimationFrame(() => { const latency = now() - start; if (latency >= minLatency) {
 Un exemple de l'extension de performance pour @ perf-tools / keeper fonctionnant lorsqu'un nombre de Fibonacci est calculé sur un clic.
Un exemple de l'extension de performance pour @ perf-tools / keeper fonctionnant lorsqu'un nombre de Fibonacci est calculé sur un clic.FPS lors du défilement et de l'animation
C'est la métrique la plus intéressante, elle est généralement mesurée via
requestAnimationFrame , et si vous avez besoin de faire une mesure FPS constante, alors le
FPSMeter classique fera l'affaire (bien qu'il soit trop optimiste). Mais cela ne fonctionne pas du tout si vous devez mesurer la fluidité du défilement de la page, car il a besoin d'un échauffement. Et puis je suis tombé sur une manière très
intéressante .
Ingénieusement, en fait, nous créons juste un div transparent (1x1px), lui ajoutons une
transition: left 300ms linear et
transition: left 300ms linear d'un coin à un autre, et pendant qu'il
requestAnimationFrame , via
requestAnimationFrame vérifions sa vraie gauche, et si la nouvelle longueur diffère de la précédente, puis augmentez le nombre d'images rendues (sinon nous avons un tirage FPS).
Et ce n'est pas tout, si vous utilisez FF, il y a simplement
mozPaintCount , qui est responsable du nombre d'images rendues, c'est-à-dire nous nous souvenons de «FAIRE» et, à la fin de la
transitionend nous calculons la différence.
Total, sans aucun échauffement, nous savons avec certitude si le navigateur a redessiné le cadre ou non.
Ils promettent bientôt une API normale:
http://wicg.imtqy.com/frame-timing/Un exemple de l'extension fps pour @ perf-tools / keeper .Optimisation du défilement:
- la chose la plus simple est de ne rien faire sur le défilement, ou de retarder l'exécution via
requestAnimationFrame , ou même requestIdleCallback ; - utilisez très soigneusement les
pointer-events: none , l'activer et le désactiver peut avoir l'effet inverse, il est donc préférable de mener une expérience A / B en utilisant pointer-events et sans; - n'oubliez pas les listes virtualisées, presque tous les moteurs View ont maintenant de tels composants, mais encore une fois, faites attention, les éléments d'une telle liste doivent être aussi simples que possible, ou utilisez des "mannequins" qui seront remplacés par de vrais éléments une fois le défilement terminé. Si vous écrivez une liste virtualisée vous-même, alors pas de code HTML interne et n'oubliez pas le recyclage DOM (c'est quand vous ne créez pas d'éléments DOM pour chaque éternuement, mais les réutilisez).
Initialisation de l'application
Il n'y a qu'une seule règle: les détails pour que vous puissiez répondre exactement au temps exact écoulé depuis l'initialisation de l'application jusqu'au lancement final. Par conséquent, vous devriez obtenir au moins les mesures suivantes:
- combien de temps il a fallu pour résoudre chaque dépendance;
- le temps de recevoir et de préparer les données pour la demande;
- application de rendu avec détails par blocs.
C'est-à-dire à la sortie, vous devriez obtenir de telles métriques par lesquelles vous pouvez suivre avec précision la phase exacte de votre retrait.
Exemple de travailLa console 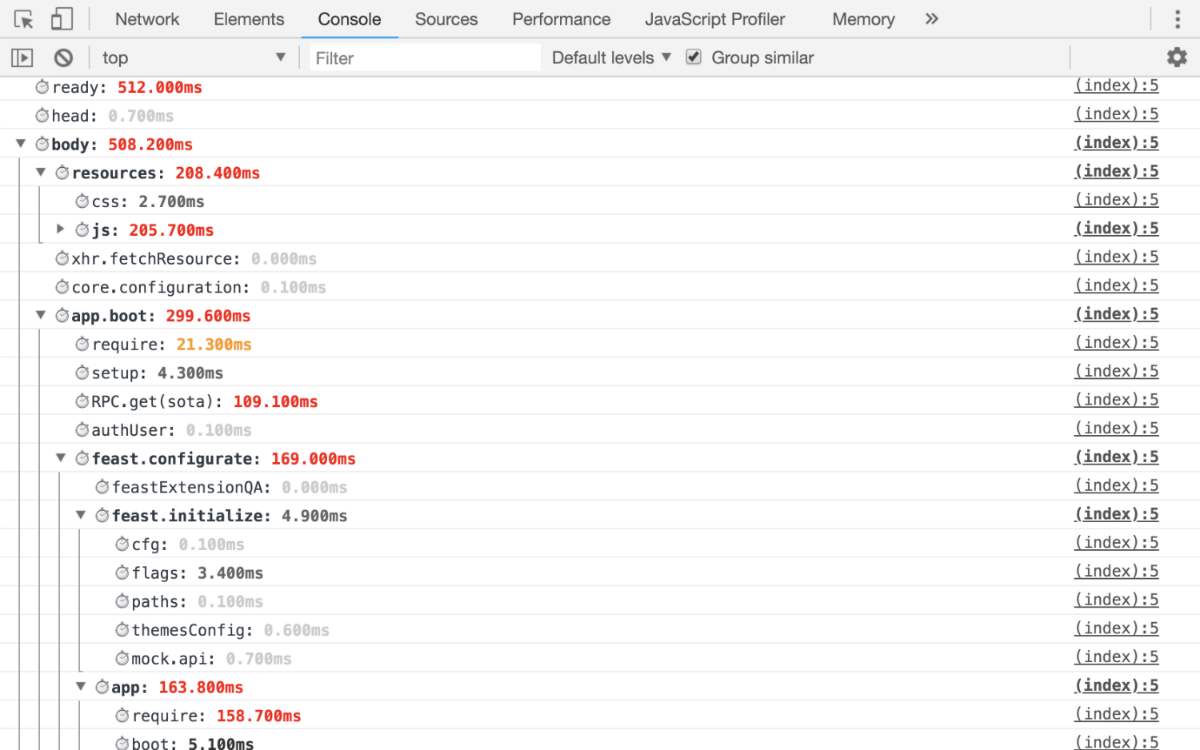 Calendrier utilisateur
Calendrier utilisateur 
Si vous avez un SPA, vous devez mesurer le temps de routage
Premièrement, il devrait y avoir une métrique générale pour évaluer les performances (temps de transit sur l'itinéraire) dans son ensemble, mais il est également nécessaire d'avoir une métrique pour chaque itinéraire (par exemple, nous avons une «Liste de threads», «Lecture d'un thread», «Recherche», etc. d.), la métrique elle-même doit être divisée en métriques:
- Réception de données (avec ventilation de celles-ci)
- Rendu
- Application totale
- Blocs (par exemple, chez nous, ce sera: "Colonne de gauche" (alias "Liste des dossiers"), "Barre de recherche intelligente", "Liste des lettres" et autres)
Sans tout cela, il est impossible de comprendre où les problèmes commencent, nous avons donc de nombreux modules prêts à l'emploi (par exemple, le même module pour XHR a
startTime et
endTime , qui sont automatiquement enregistrés).
Mais ces mesures ne suffisent pas à évaluer correctement ce qui se passe. Ils sont trop généraux car nous parlons de SPA, alors vous avez certainement une sorte de cache d'exécution (afin de ne pas retourner sur le serveur si vous y êtes déjà allé), donc nos métriques sont divisées en routage avec et sans cache. Pourtant, spécifiquement dans notre cas, nous divisons la métrique par le nombre d'entités qu'elle contient. En d'autres termes, vous ne pouvez pas ajouter la vue "Thread" avec 1, 5, 10 ou 100+ lettres dans une métrique, donc si vous avez une liste affichée, vous devez sélectionner des points d'arrêt et séparer davantage la métrique.
Mémoire et consommation de trafic
Commençons par la mémoire . Et nous attendons ici une grosse déception. Pour le moment, il n'y a qu'une mémoire de performance non standardisée (Chrome uniquement), ce qui donne des chiffres ridiculement bas. Mais encore faut-il les mesurer et regarder comment l'application "coule" dans le temps:
Un exemple d'extension de mémoire pour @ perf-tools / keeperTrafic Pour compter le trafic, vous aurez besoin de
Timing-Allow-Origin (si les ressources sont situées dans un domaine séparé) et de l'
API Resource Timing , cela vous aidera non seulement à calculer le trafic, mais aussi à le détailler:
- quel protocole est utilisé (HTTP / 1, HTTP / 2, etc.);
- types de ressources chargées;
- combien de temps il a fallu pour les télécharger;
- De plus, vous pouvez comprendre si la ressource est chargée sur le réseau ou prise dans le cache.
Un exemple de l'extension de ressource pour @ perf-tools / keeper .Qu'est-ce qui donne le trafic?
- La chose la plus importante est qu'elle vous permet de voir l'image réelle, et pas comme d'habitude avec CSS + JS et au-delà, comment cette «image» change au fil du temps.
- Ensuite, vous pouvez analyser ce qui est exactement chargé, diviser les ressources en groupes, etc.
- Dans quelle mesure la mise en cache fonctionne-t-elle pour vous?
- Y a-t-il des anomalies, par exemple, après 15 minutes de fonctionnement, par exemple, le code est entré en récursivité et charge indéfiniment certaines ressources, la surveillance du trafic y contribuera.
Eh bien, un rapport de rattrapage de mon collègue
Igor Druzhinin sur ce sujet:
Evaluer la qualité de l'application - surveiller la consommation de traficAnalytique
Nous avons mis en place les métriques, et puis quoi? Et puis ils doivent être envoyés quelque part. Et ici, soit vous récupérez du
graphite , soit, pour commencer, vous pouvez utiliser
Google Analytics ou similaire pour l'agrégation de données à des fins personnelles.
Et n'oubliez pas, il ne suffit pas d'obtenir un graphique, pour toutes les mesures importantes, il devrait y avoir des centiles qui vous permettent de comprendre, par exemple, quel pourcentage de l'audience le projet charge pour <1s, <2s, <3s, <5s, 5s +, etc.
Écrire un code performant
Au début, je voulais écrire quelque chose de significatif ici, ils disent utiliser WebWorker, n'oubliez pas
requestIdleCallback ou quelque chose d'exotique, par exemple, via Runtime Cache via les onglets du navigateur à l'aide de SharedWorker ou ServiceWorker (qui ne concerne pas uniquement la mise en cache, si cela). Mais tout cela est très abstrait et de nombreux sujets sont battus à l'impossibilité, alors écrivez simplement ce qui suit:
- Couvrez initialement votre code avec des métriques qui mesureront ses performances.
- Ne croyez pas les repères avec jsperf. La grande majorité d'entre eux sont mal écrits et simplement sortis de leur contexte. La meilleure référence est la véritable métrique du projet, selon laquelle vous verrez l'effet de vos actions.
- N'oubliez pas la perception de la productivité, ou plutôt la loi Weber-Fechner. À savoir, si vous avez commencé l'optimisation, ne déployez pas les modifications jusqu'à ce qu'elles s'améliorent d'au moins 20%, sinon les utilisateurs ne le remarqueront tout simplement pas. La loi fonctionne également en sens inverse.
- Craignez les habitués, surtout ceux générés. Ils peuvent non seulement bloquer le navigateur, mais également obtenir XSS, c'est pourquoi dans notre messagerie, il est interdit d'analyser HTML en les utilisant, uniquement via un contournement DOM.
- Vous n'avez pas besoin d'utiliser des tableaux pour entrer une valeur dans l'un ou l'autre groupe, pour cela il y a un
object ou un Set (par exemple, successSteps.includes(currentStep) nécessaire successSteps.hasOwnProperty(currentStep) ), O (1) est tout. - L'expression "l'optimisation prématurée est la racine de tous les maux" ne concerne pas l'écriture de tout ce que vous voulez. Si vous savez le mieux, écrivez de manière optimale.
Je vais écrire quelques paragraphes sur le code et son optimisationDOM Très souvent, j'entends «Le problème dans les DOM» - cela, bien sûr, est vrai, mais étant donné que presque tout le monde a maintenant une abstraction à ce sujet. C'est elle qui devient le goulot d'étranglement, ou plutôt votre code, qui est responsable de la formation de la vision et de la logique métier.
Mais si nous parlons du DOM, par exemple, au lieu de supprimer un fragment du DOM, il vaut mieux le cacher ou le détacher. Si vous devez toujours supprimer, effectuez cette opération dans
requestIdleCallback (si possible), ou divisez le processus de destruction en deux phases: synchrone et asynchrone.
Je vais faire une réservation tout de suite, utilisez cette approche à bon escient, sinon vous pouvez vous tirer un genou.
Nous utilisons également une autre technique intéressante sur les listes, par exemple, la «Liste des fils». L'essence de la technique est qu'au lieu d'une «liste» globale et de la mise à jour de ses données, nous générons une «liste de threads» pour chaque «dossier». Par conséquent, lorsque l'utilisateur navigue entre les "Dossiers", une liste est supprimée du DOM (non supprimée) et l'autre est mise à jour partiellement ou pas du tout. Et pas tous, comme c'est le cas avec la "liste unique".
Tout cela donne une réponse instantanée aux actions des utilisateurs.
Math Nous supprimons facilement tous les calculs dans Worker ou WebAssembly, cela fonctionne depuis longtemps.
Transpilers . Oh, beaucoup ne pensent même pas que le code qu’ils écrivent passe par le transpilateur. Oui, ils le connaissent, mais c'est tout. Mais en quoi se transforme-t-il, ils ne s'en soucient plus. En effet, dans DevTools, ils voient le résultat de la carte source.
Par conséquent, étudiez les outils que vous utilisez, par exemple, le même babel dans la
cour de récréation a la possibilité de voir dans quoi il génère du code en fonction des préréglages sélectionnés, il suffit de regarder le même
yeild , d'
await ou
for of .
Les subtilités de la langue . Encore moins de gens connaissent le monomorphisme du code, ou bien pourquoi bind est lent et ... vous utilisez enfin
handleEvent !
Données et prélecture . Moins de demandes, plus de mise en cache. De plus, très souvent nous utilisons la technique de la «prévoyance», c'est quand en arrière plan nous chargeons des données. Par exemple, après avoir rendu la «liste de threads», nous commençons à charger N threads non lus dans le «dossier» actuel, de sorte que lorsque vous cliquez dessus, l'utilisateur passe immédiatement en «lecture» plutôt qu'en un autre «chargeur». Nous utilisons une technique similaire non seulement pour les données, mais aussi pour JS. Par exemple, «Écrire une lettre» est un énorme ensemble (à cause de l'éditeur), et toutes les personnes n'écrivent pas des lettres à la fois, nous le chargeons donc en arrière-plan, une fois l'application initialisée.
Louders Je ne sais pas pourquoi, mais je n'ai pas vu d'articles qui enseignaient comment ne pas faire un chargeur, mais plutôt pris au moins une présentation du "futur" React, dans lequel beaucoup de temps était consacré à ce problème dans Suspense. Mais après tout, l'application idéale est sans chargeurs, nous essayons depuis longtemps dans le Mail de ne la montrer qu'en cas d'urgence.
En général, nous avons une telle politique, il n'y a pas de données, il n'y a pas de vue, il n'y a rien pour dessiner une semi-interface, d'abord on charge les données et ensuite seulement "dessine". C'est pourquoi nous utilisons la «prévoyance» de l'endroit où l'utilisateur va aller et charger ces données afin que l'utilisateur ne voie pas le chargeur. De plus, notre couche de données, qui est persistante, aide beaucoup dans cette tâche. si vous avez demandé "Thread" quelque part à un endroit, alors la prochaine fois que vous demanderez à un autre ou au même endroit, il n'y aura pas de demande, nous prendrons les données de Runtime Cache (plus précisément, un lien vers les données). Et donc dans tout, les collections de threads ne sont que des liens vers des données.
Mais si vous décidez toujours de faire un chargeur, alors n'oubliez pas les règles de base qui rendront votre chargeur moins ennuyeux:
- pas besoin de montrer le chargeur immédiatement, au moment de l'envoi de la demande, il devrait y avoir un délai d'au moins 300-500 ms avant le show;
- Après avoir reçu les données, vous n'avez pas besoin de retirer brusquement le chargeur, là encore il devrait y avoir un délai.
Ces règles simples sont nécessaires pour que le chargeur n'apparaisse que sur les demandes lourdes et ne «clignote» pas à la fin. Mais le plus important, le meilleur chargeur est un chargeur qui n'est pas apparu.
Merci pour votre attention, c'est tout, mesurer, analyser et utiliser
PerfKeeper (
exemple Live ), ainsi que
mon github et
twitter , en cas de questions!