Les images JPEG se trouvent partout dans notre vie numérique, mais derrière cette couverture de sensibilisation se trouvent des algorithmes qui éliminent les détails qui ne sont pas perçus par l'œil humain. Le résultat est la plus haute qualité visuelle avec la plus petite taille de fichier - mais comment tout cela fonctionne-t-il exactement? Voyons ce que nos yeux ne voient pas exactement!

Il est facile de prendre pour acquis la possibilité d'envoyer une photo à un ami, sans se soucier de l'appareil, du navigateur ou du système d'exploitation qu'il utilise, mais cela n'a pas toujours été le cas. Au début des années 80, les ordinateurs savaient comment stocker et afficher des images numériques, mais il y avait de nombreuses idées concurrentes sur la meilleure façon de procéder. Il était impossible d'envoyer simplement une image d'un ordinateur à un autre et d'espérer que tout fonctionne.
Pour résoudre ce problème, en 1986, un comité d'experts du monde entier a été constitué sous le nom de «Joint Photographic Experts Group (JPEG)», sur la base de la collaboration de l'Organisation internationale de normalisation (ISO) et de la Commission électrotechnique internationale (CEI) ) - deux organisations internationales de normalisation, dont le siège est situé à Genève (Suisse).
Un groupe de personnes appelé JPEG a créé la norme de compression d'image numérique JPEG en 1992. Toute personne utilisant Internet était susceptible de rencontrer des images encodées JPEG. Il s'agit de la méthode la plus courante pour encoder, envoyer et stocker des images. Des pages Web aux e-mails et aux réseaux sociaux, JPEG est utilisé des milliards de fois par jour - presque chaque fois que nous regardons une image en ligne ou l'envoyons. Sans JPEG, le Web serait moins dynamique, plus lent et il y aurait probablement moins de photos de chats!
Cet article explique comment décoder une image JPEG. En d'autres termes, sur ce qui est nécessaire pour convertir les données compressées stockées sur un ordinateur en une image qui apparaît à l'écran. Cela vaut la peine de le savoir, non seulement parce qu'il est important pour comprendre la technologie que nous utilisons quotidiennement, mais aussi parce que lors de la divulgation des niveaux de compression, nous comprenons mieux la perception et la vision, ainsi que les détails auxquels nos yeux sont les plus sensibles.
De plus, jouer avec des images de cette manière est très intéressant.
Regarder à l'intérieur d'un jpeg
Sur un ordinateur, tout est stocké sous la forme d'une séquence de nombres binaires. En règle générale, ces bits, zéros et uns sont regroupés en huit, constituant des octets. Lorsque vous ouvrez une image JPEG sur un ordinateur, quelque chose (navigateur, système d'exploitation, autre chose) devrait décoder les octets, restaurant l'image originale sous la forme d'une liste de couleurs pouvant être affichées.
Si vous téléchargez cette jolie
photo de chat et l'ouvrez dans un éditeur de texte, vous verrez un tas de personnages incohérents.
 Ici, j'utilise Notepad ++ pour examiner le contenu d'un fichier, car les éditeurs de texte normaux tels que le Bloc-notes de Windows corrompent le binaire après l'enregistrement et ne satisfont plus le format JPEG.
Ici, j'utilise Notepad ++ pour examiner le contenu d'un fichier, car les éditeurs de texte normaux tels que le Bloc-notes de Windows corrompent le binaire après l'enregistrement et ne satisfont plus le format JPEG.Lorsque vous ouvrez une image dans un éditeur de texte, vous confondez l'ordinateur, tout comme vous confondez votre cerveau lorsque vous vous frottez les yeux et commencez à voir des taches colorées!
Ces taches que vous voyez sont appelées
phosphènes et ne sont pas le résultat d'une exposition à un stimulus lumineux ou à des hallucinations générées par l'esprit. Ils se produisent parce que votre cerveau croit que tout signal électrique dans les nerfs optiques transmet des informations sur la lumière. Le cerveau a besoin de faire de telles hypothèses, car il est impossible de savoir si le signal est sonore, visuel ou autre. Tous les nerfs du corps transmettent exactement les mêmes impulsions électriques. En appuyant sur les yeux, vous envoyez des signaux qui ne sont pas visuels, mais activez les récepteurs de l'œil que votre cerveau interprète - dans ce cas, de manière incorrecte - comme quelque chose de visuel. Vous pouvez littéralement voir la pression!
C'est drôle de penser à combien les ordinateurs ressemblent à un cerveau, mais c'est aussi une analogie utile qui illustre à quel point la signification des données - transmises à travers le corps par les nerfs, ou stockées sur un ordinateur - dépend de leur interprétation. Toutes les données binaires se composent de zéros et de uns, composants de base qui peuvent transmettre des informations de toute nature. Votre ordinateur devine souvent comment les interpréter à l'aide d'indications, telles que des extensions de fichier. Et maintenant, nous le forçons à les interpréter comme du texte, car c'est ce que l'éditeur de texte attend.
Pour comprendre comment décoder le JPEG, nous devons voir les signaux originaux eux-mêmes - les données binaires. Cela peut être fait en utilisant l'éditeur hexadécimal ou directement sur la
page Web de l'article original ! Il y a une image, à côté de laquelle dans la zone de texte sont tous ses octets (sauf l'en-tête), présentés sous forme décimale. Vous pouvez les modifier et le script se recodera et produira une nouvelle image à la volée.

Vous pouvez apprendre beaucoup en jouant avec cet éditeur. Par exemple, pouvez-vous dire dans quel ordre les pixels sont stockés?
Dans cet exemple, il est étrange que la modification de certains nombres n'affecte pas du tout l'image, mais, par exemple, si vous remplacez le nombre 17 par 0 dans la première ligne, la photo ira complètement mal!

D'autres changements, par exemple, le remplacement de 7 sur la ligne 1988 par le nombre 254 change la couleur, mais seulement des pixels suivants.

Le plus étrange est peut-être que certains nombres changent non seulement la couleur, mais aussi la forme de l'image. Changez 70 sur la ligne 12 en 2 et regardez la rangée du haut de l'image pour voir ce que je veux dire.

Et peu importe l'image JPEG que vous utilisez, vous trouverez toujours ces séquences d'échecs cryptiques lors de l'édition d'octets.
Lorsque vous jouez avec l'éditeur, il est difficile de comprendre comment la photo est recréée à partir de ces octets, car la compression JPEG se compose de trois technologies différentes qui sont appliquées séquentiellement à travers les niveaux. Nous étudierons chacun d'eux séparément pour révéler le comportement mystérieux que nous observons.
Trois niveaux de compression JPEG:- Sous-échantillonnage des couleurs .
- Transformation cosinus discrète et discrétisation .
- Longueurs des séries d'encodage , Delta et Huffman
Pour que vous puissiez imaginer l'échelle de compression, veuillez noter que l'image ci-dessus représente 79 819 nombres, soit environ 79 Ko. Si nous le stockions sans compression, pour chaque pixel, trois nombres seraient nécessaires - pour les composantes rouge, verte et bleue. Ce serait 917 700 numéros, soit environ. 917 Kb. En raison de la compression JPEG, le fichier résultant a diminué de plus de 10 fois!
En fait, cette image peut être compressée beaucoup plus fortement. Ci-dessous, deux images côte à côte - la photo de droite a été réduite à 16 Ko, soit 57 fois plus petite que la version non compressée!

Si vous regardez attentivement, vous verrez que ces images ne sont pas identiques. Les deux sont des images avec compression JPEG, mais celle de droite est beaucoup plus petite en volume. Cela semble également un peu pire (regardez les carrés des couleurs de fond). Par conséquent, JPEG est également appelé compression avec perte; lors de la compression, l'image change et perd certains détails.
1. Sous-échantillonnage des couleurs
Voici une image utilisant uniquement le premier niveau de compression.
 (Version interactive - dans l'article original ). La suppression d'un numéro détruit toutes les couleurs. Cependant, si vous supprimez exactement six nombres, cela n'affecte pratiquement pas l'image.
(Version interactive - dans l'article original ). La suppression d'un numéro détruit toutes les couleurs. Cependant, si vous supprimez exactement six nombres, cela n'affecte pratiquement pas l'image.Désormais, les chiffres sont un peu plus faciles à déchiffrer. Il s'agit d'une liste de couleurs presque simple, dans laquelle chaque octet change exactement d'un pixel, mais en même temps, il fait déjà la moitié de la taille d'une image non compressée (qui occuperait environ 300 Ko dans une taille si réduite). Devinez pourquoi?
Vous pouvez voir que ces nombres ne désignent pas les composants standard rouge, vert et bleu, car si nous remplaçons tous les nombres par des zéros, nous obtenons une image verte (et non blanche).

En effet, ces octets indiquent Y (luminosité),

Cb (bleuissement relatif),

et Cr (rougeur relative).

Pourquoi ne pas utiliser RVB? En effet, c'est ainsi que fonctionnent la plupart des écrans modernes. Votre moniteur peut afficher n'importe quelle couleur, y compris le rouge, le vert et le bleu avec des intensités différentes pour chaque pixel. Le blanc est obtenu en activant les trois à pleine luminosité, et le noir - en les désactivant.
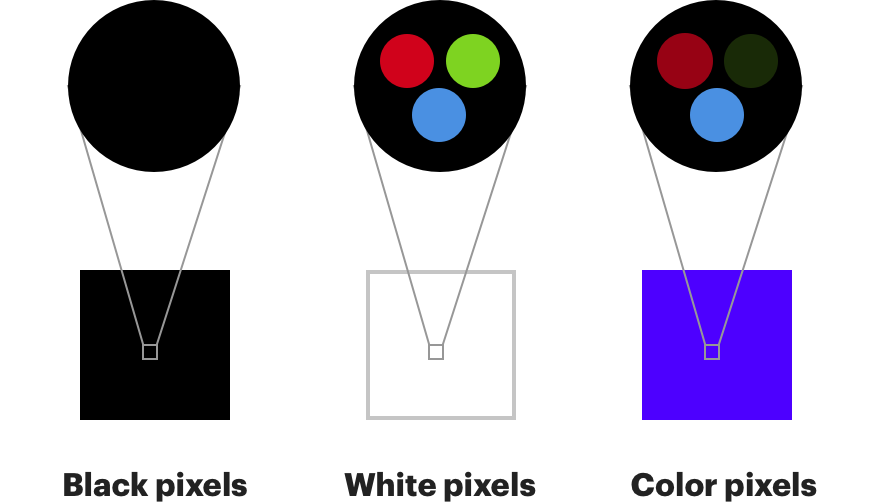
Il est également très similaire au travail de l'œil humain. Les récepteurs de couleur de nos yeux sont appelés «
cônes » et sont divisés en trois types, chacun étant plus sensible au rouge, au vert ou au bleu [les cônes de type S sont sensibles en bleu-violet (S de l'anglais Short - shortwave spectre), de type M - en vert-jaune (M de l'anglais. Onde moyenne à moyenne) et de type L - dans les parties jaune-rouge (L de l'anglais. Onde longue - longue) du spectre. La présence de ces trois types de cônes (et de bâtonnets sensibles dans la partie vert émeraude du spectre) donne une vision des couleurs à une personne. / env. trad.].
Les bâtonnets , un autre type de photorécepteur à nos yeux, ne peuvent capturer que les changements de luminosité, mais ils sont beaucoup plus sensibles. À nos yeux, il y a environ 120 millions de bâtonnets et seulement 6 millions de cônes.
Par conséquent, nos yeux remarquent bien mieux les changements de luminosité que les changements de couleur. Si vous séparez la couleur de la luminosité, vous pouvez supprimer un peu de couleur et personne ne remarquera rien. Le sous-échantillonnage des couleurs est le processus de représentation des composantes de couleur d'une image à une résolution inférieure à celle des composantes de luminosité. Dans l'exemple ci-dessus, chaque pixel a exactement un composant Y, et chaque groupe individuel de quatre pixels a exactement un composant Cb et un Cr. Par conséquent, l'image contient quatre fois moins d'informations sur les couleurs que l'original.
L'espace colorimétrique YCbCr est utilisé non seulement en JPEG. Il a été initialement inventé en 1938 pour les émissions de télévision. Tout le monde n'a pas de téléviseur couleur, donc la séparation de la couleur et de la luminosité a permis à tout le monde de recevoir le même signal, et les téléviseurs sans couleur n'utilisaient que le composant de luminosité.
Par conséquent, la suppression d'un numéro de l'éditeur détruit complètement toutes les couleurs. Les composants sont stockés sous la forme YYYY Cb Cr (en fait, pas nécessairement dans cet ordre - l'ordre de stockage est spécifié dans l'en-tête du fichier). La suppression du premier nombre entraînera le fait que la première valeur Cb sera perçue comme Y, Cr comme Cb, et dans l'ensemble un effet domino se produira, changeant toutes les couleurs de l'image.
La spécification JPEG ne vous oblige pas à utiliser YCbCr. Mais dans la plupart des fichiers, il est utilisé car il donne des images de meilleure qualité après sous-échantillonnage par rapport au RVB. Mais vous n'avez pas à me croire sur parole. Voyez par vous-même dans le tableau ci-dessous à quoi ressemblera le sous-échantillonnage de chaque composant individuel en RVB et en YCbCr.

(Version interactive - dans l'article
original ).
La suppression du bleu n'est pas aussi visible que le rouge ou le vert. C'est à cause des six millions de cônes dans vos yeux, environ 64% sont sensibles au rouge, 32% au vert et 2% au bleu.
Le sous-échantillonnage de la composante Y (en bas à gauche) est mieux vu. On remarque même un léger changement.
La conversion d'une image de RVB en YCbCr ne réduit pas la taille du fichier, mais facilite la recherche de détails moins visibles qui peuvent être supprimés. La compression avec perte se produit dans la deuxième étape. Il est basé sur l'idée de représenter les données sous une forme plus compressible.
2. Transformation cosinus discrète et discrétisation
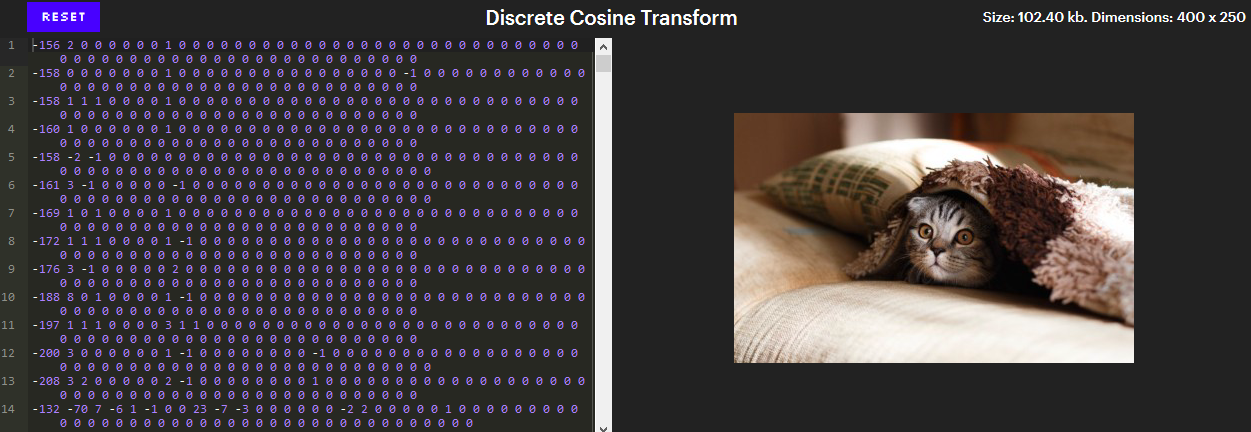
Ce niveau de compression détermine pour l'essentiel l'essence du JPEG. Après avoir converti les couleurs en YCbCr, les composants sont compressés séparément, nous pouvons donc nous concentrer uniquement sur le composant Y. Et voici à quoi ressemblent les octets du composant Y après l'application de ce niveau.
 (Version interactive - dans l'article original ).
(Version interactive - dans l'article original ). Dans la version interactive, cliquer sur un pixel fait défiler l'éditeur jusqu'à la ligne qui l'indique. Essayez de supprimer des numéros de la fin ou d'ajouter quelques zéros à un numéro spécifique.
À première vue, cela ressemble à une très mauvaise compression. Il y a 100 000 pixels dans l'image et 102 400 nombres sont nécessaires pour indiquer leur luminosité (composantes Y) - c'est pire que de ne rien compresser du tout!
Cependant, notez que la plupart de ces nombres sont nuls. De plus, tous ces zéros à la fin des lignes peuvent être supprimés sans changer l'image. Il reste environ 26 000 numéros, et c'est presque 4 fois moins!
À ce niveau est le secret des modèles d'échecs. Contrairement à d'autres effets que nous avons vus, l'apparition de ces motifs n'est pas un problème. Ce sont les éléments constitutifs de toute l'image. Chaque ligne de l'éditeur contient exactement 64 nombres, des coefficients de transformation discrète en cosinus (DCT) correspondant à des intensités de 64 motifs uniques.
Ces motifs sont formés sur la base du graphique cosinus. En voici quelques uns:
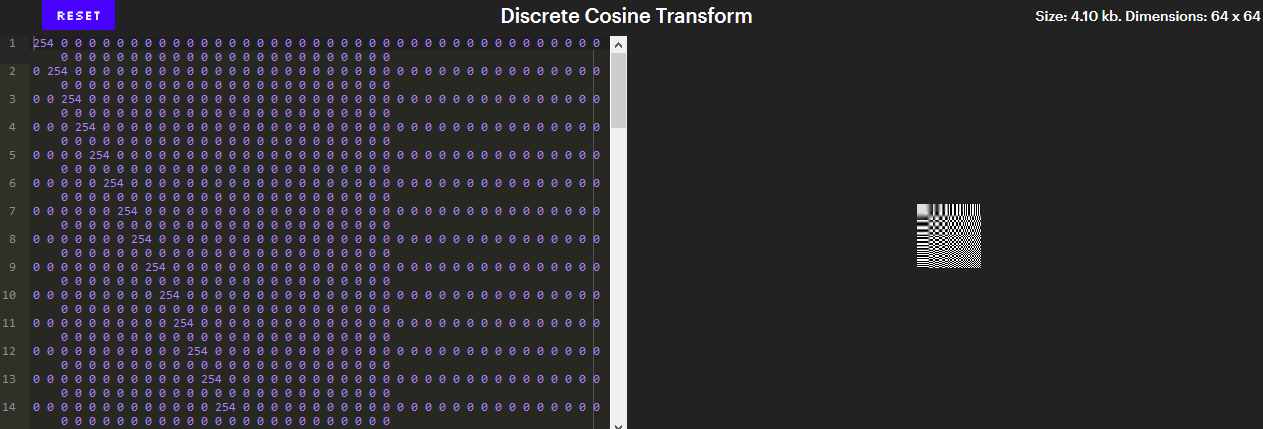
 8 sur 64 cotes
8 sur 64 cotesCi-dessous, une image montrant les 64 modèles.
 (Version interactive - dans l'article original ).
(Version interactive - dans l'article original ).Ces motifs sont d'une importance particulière car ils constituent la base d'images 8x8. Si vous n'êtes pas familier avec l'algèbre linéaire, cela signifie que n'importe quelle image 8x8 peut être obtenue à partir de ces 64 motifs. Le DCT est le processus de division des images en blocs 8x8 et de conversion de chaque bloc en une combinaison de ces 64 coefficients.
Le fait que n'importe quelle image puisse être composée de 64 motifs spécifiques semble magique. Cependant, cela revient à dire que n'importe quel endroit sur Terre peut être décrit par deux nombres - latitude et longitude [indiquant les hémisphères / env. trad.]. Nous considérons souvent la surface de la Terre en deux dimensions, nous n'avons donc besoin que de deux nombres. Une image 8x8 a 64 dimensions, nous avons donc besoin de 64 nombres.
On ne sait pas encore en quoi cela nous aide dans le sens de la compression. Si nous avons besoin de 64 nombres pour représenter une image 8x8, pourquoi serait-ce mieux que de simplement stocker 64 composants de luminance? Nous le faisons pour la même raison que nous avons transformé trois nombres RVB en trois nombres YCbCr: cela nous permet de supprimer les détails invisibles.
Il est difficile de voir exactement quels détails sont supprimés à ce stade, car JPEG applique le DCT aux blocs 8x8. Cependant, personne ne nous interdit de l'appliquer à l'ensemble du tableau. Voici à quoi ressemble DCT dans le composant Y lorsqu'il est appliqué à l'image entière:
De la fin, vous pouvez supprimer plus de 60 000 numéros sans pratiquement aucun changement notable dans la photo.

Cependant, notez que si nous réinitialisons les cinq premiers chiffres, la différence sera évidente.

Les chiffres au début indiquent des changements de basse fréquence dans l'image, et nos yeux les captent mieux. Les nombres proches de la fin indiquent des changements dans les hautes fréquences qui sont plus difficiles à remarquer. Pour «voir ce qui n'est pas visible à l'œil», nous pouvons isoler ces parties haute fréquence en remettant à zéro les 5000 premiers nombres.

Nous voyons toutes les zones de l'image dans lesquelles le plus grand changement se produit d'un pixel à l'autre. Les yeux du chat, sa moustache, sa couverture éponge et ses ombres dans le coin inférieur gauche ressortent. Vous pouvez aller plus loin en effaçant les 10 000 premiers numéros:

20 000:

40 000:

60 000:

Ces parties haute fréquence sont en jpeg et suppriment pendant la phase de compression. La conversion des couleurs en coefficients DCT est sans perte. Les pertes sont générées à l'étape de discrétisation, où les valeurs haute fréquence ou proches de zéro sont supprimées. Lorsque vous diminuez la qualité de l'enregistrement JPEG, le programme augmente le seuil du nombre de valeurs supprimées, ce qui réduit la taille du fichier, mais rend l'image plus pixélisée. Par conséquent, l'image de la première section, qui était 57 fois plus petite, ressemblait à ceci. Chaque bloc 8x8 semblait avoir un nombre beaucoup plus faible de coefficients DCT par rapport à une meilleure version.
Vous pouvez créer un effet sympa comme la diffusion progressive d'images. Vous pouvez afficher une image floue, qui devient plus détaillée à mesure que de plus en plus de coefficients sont téléchargés.
Ici, juste pour le plaisir, ce qui se passe lorsque vous utilisez seulement 24 000 numéros:

Ou juste 5000:

Très flou, mais comme reconnaissable!
3. Codage des longueurs de série, delta et Huffman
Jusqu'à présent, toutes les étapes de compression se sont accompagnées de pertes. La dernière étape, au contraire, se déroule sans perte. Il ne supprime pas les informations, mais réduit considérablement la taille du fichier.
Comment pouvez-vous compresser quelque chose sans jeter d'informations? Imaginez comment nous décririons un simple rectangle noir 700 x 437.
JPEG utilise 5000 numéros pour cela, mais un bien meilleur résultat peut être obtenu. Pouvez-vous imaginer un schéma de codage décrivant une telle image avec le moins d'octets possible?
Le schéma minimal que je pourrais utiliser utilise quatre: trois pour indiquer la couleur, et le quatrième - combien de pixels ont cette couleur. L'idée de représenter des valeurs répétées d'une telle manière compressée est appelée codage de longueur en série. Il n'a aucune perte, car nous pouvons restaurer les données encodées dans leur forme d'origine.
La taille d'un fichier JPEG avec un rectangle noir est beaucoup plus grande que 4 octets - n'oubliez pas qu'au niveau DCT, la compression est appliquée à des blocs de 8x8 pixels. Par conséquent, au moins nous avons besoin d'un coefficient DCT pour chaque 64 pixels. Nous en avons besoin car au lieu de stocker un seul coefficient DCT suivi de 63 zéros, le codage des longueurs de la série nous permet de stocker un nombre et d'indiquer que «tous les autres sont des zéros».
Le codage delta est une technique dans laquelle chaque octet contient une différence par rapport à une certaine valeur, plutôt qu'une valeur absolue. Par conséquent, la modification de certains octets modifie la couleur de tous les autres pixels. Par exemple, au lieu de stocker
12 13 14 14 14 13 13 14
12, , , . - :
12 1 1 0 0 -1 0 1
, . - , .
Le codage delta est l'une des rares techniques utilisées en dehors des blocs 8x8. Sur les 64 coefficients DCT, l'un est simplement une fonction d'onde constante (couleur unie). Il représente la luminosité moyenne de chaque bloc pour les composants de luminance, ou le bleuissement moyen pour les composants Cb, etc. La première valeur de chaque bloc DCT est appelée valeur DC, et chaque valeur DC subit un codage delta par rapport aux précédentes. Par conséquent, une modification de la luminosité du premier bloc affectera tous les blocs.Le dernier mystère demeure: comment le changement singulier gâche-t-il complètement le tableau? Jusqu'à présent, les niveaux de compression n'avaient pas de telles propriétés. La réponse réside dans l'en-tête JPEG. Les 500 premiers octets contiennent des métadonnées sur l'image - largeur, hauteur, etc., et jusqu'à présent, nous n'avons pas travaillé avec eux.(, ) JPEG. , , , . , , , , , .
, . JPEG , . . « », – . – 255 196. .
. – 15- 1 12.

, , . . , 1 , , 00000001, , .
, . – , , . , :
234 115
, , . , :
11101010 01110011
, , . , , (111010), 58 , (10011), 19, (0011), 3.
. , . ,
.
, , – JPEG . , , . Facebook , .
– . , . .
: JPEG? :
- () .
- 88, .
- , 88.
- , ( ).
- YCbCr RGB.
- !
! , – , JPEG . , , . , , JPEG, , . , - , , ( , ).
, , , .