À ce jour, le service Bitrix24 n'a pas des centaines de gigabits de trafic, il n'y a pas une énorme flotte de serveurs (bien qu'il y en ait beaucoup, bien sûr, des serveurs existants). Mais pour de nombreux clients, c'est le principal outil de travail en entreprise, c'est une véritable application critique pour l'entreprise. Par conséquent, tomber - enfin, pas question. Mais que se passe-t-il si la chute se produit, mais le service se «rebelle» si rapidement que personne ne remarque rien? Et comment gérez-vous la mise en œuvre du basculement sans perdre en qualité de travail et en nombre de clients? Alexander Demidov, directeur des services cloud Bitrix24, a expliqué à notre blog comment le système de sauvegarde a évolué au cours des 7 années d'existence du produit.

«Sous forme de SaaS, nous avons lancé Bitrix24 il y a 7 ans. La principale difficulté, probablement, était la suivante: avant son lancement en public sous forme de SaaS, ce produit existait simplement sous la forme d'une solution en boîte. Les clients nous l'ont acheté, l'ont placé sur leurs serveurs, ont créé un portail d'entreprise - une solution commune pour la communication avec les employés, le stockage de fichiers, la gestion des tâches, le CRM, c'est tout. Et en 2012, nous avons décidé que nous voulions le lancer en tant que SaaS, en l'administrant nous-mêmes, en offrant une tolérance aux pannes et une fiabilité. Nous avons acquis de l'expérience dans le processus, car jusque-là nous ne l'avions tout simplement pas - nous n'étions que des fabricants de logiciels, pas des prestataires de services.
Lors du lancement du service, nous avons compris que la chose la plus importante est d'assurer la tolérance aux pannes, la fiabilité et la disponibilité constante du service, car si vous avez un simple site web régulier, un magasin par exemple, et qu'il vous est tombé et ment une heure - vous seul souffrez, vous perdez des commandes , vous perdez des clients, mais pour votre client lui-même - pour lui, ce n'est pas très critique. Il était bouleversé, bien sûr, mais est allé acheter sur un autre site. Et s'il s'agit d'une application à laquelle tous travaillent au sein de l'entreprise, aux communications, aux solutions est liée, alors le plus important est de gagner la confiance des utilisateurs, c'est-à-dire de ne pas les laisser tomber et de ne pas tomber. Parce que tout le travail peut se lever si quelque chose à l'intérieur ne fonctionne pas.
Bitrix.24 en tant que SaaS
Le premier prototype que nous avons assemblé un an avant le lancement public, en 2011. Réuni dans environ une semaine, regardé, tordu - il travaillait même. Autrement dit, il était possible d'entrer dans le formulaire, d'y saisir le nom du portail, un nouveau portail se déroulait, une base d'utilisateurs était en cours de création. Nous l'avons examiné, évalué le produit en principe, l'avons désactivé et l'avons finalisé un an plus tard. Parce que nous avions une grosse tâche: nous ne voulions pas créer deux bases de code différentes, nous ne voulions pas prendre en charge un produit en boîte séparé, des solutions cloud distinctes - nous voulions faire tout cela dans le même code.

Une application web typique à cette époque est un serveur sur lequel un code php est en cours d'exécution, la base mysql, des fichiers sont téléchargés, des documents, des images sont mis dans le téléchargement papa - eh bien, tout fonctionne. Hélas, il est impossible d'exécuter un service Web extrêmement durable à ce sujet. Le cache distribué n'y est pas pris en charge, la réplication de la base de données n'est pas prise en charge.
Nous avons formulé les exigences: cette capacité à être située à différents endroits, à prendre en charge la réplication, idéalement à être située dans différents centres de données géographiquement répartis. Séparez la logique du produit et, en fait, le stockage des données. Dynamiquement pouvoir évoluer en fonction de la charge, généralement faire de la statique. De ces considérations, en fait, il y avait des exigences pour le produit, que nous venons de développer au cours de l'année. Pendant ce temps, dans une plate-forme qui s'est avérée unifiée - pour les solutions en boîte, pour notre propre service - nous avons pris en charge les choses dont nous avions besoin. Prise en charge de la réplication mysql au niveau du produit lui-même: c'est-à-dire que le développeur qui écrit le code ne pense pas à la façon dont ses requêtes seront distribuées, il utilise notre API, et nous pouvons distribuer correctement les requêtes d'écriture et de lecture entre les maîtres et les esclaves.
Nous avons pris en charge au niveau du produit divers magasins d'objets cloud: stockage Google, amazon s3, - plus, prise en charge de la pile ouverte rapide. Par conséquent, cela était pratique pour nous en tant que service et pour les développeurs qui travaillent avec une solution en boîte: s'ils utilisent simplement notre API pour le travail, ils ne pensent pas où le fichier sera enregistré, soit localement sur le système de fichiers, soit dans le stockage de fichiers objet. .
En conséquence, nous avons immédiatement décidé de réserver au niveau d'un centre de données complet. En 2012, nous avons lancé complètement dans Amazon AWS, car nous avions déjà de l'expérience avec cette plate-forme - notre propre site Web y était hébergé. Nous avons été attirés par le fait que dans chaque région d'Amazon il y a plusieurs zones d'accès - en fait, dans leur terminologie, plusieurs centres de données plus ou moins indépendants les uns des autres et nous permettent de réserver au niveau d'un centre de données entier: si il échoue soudainement, les bases de données maître-maître sont répliquées, les serveurs d'applications Web sont réservés et la statique est déplacée vers le stockage d'objets s3. La charge est équilibrée - à cette époque le coude amazonien, mais un peu plus tard, nous sommes arrivés à nos propres équilibreurs, car nous avions besoin d'une logique plus complexe.
Ce qu'ils voulaient, ils l'ont obtenu ...
Toutes les choses de base que nous voulions fournir - la tolérance aux pannes des serveurs eux-mêmes, les applications Web, les bases de données - tout fonctionnait bien. Le scénario le plus simple: si certaines applications Web échouent, alors tout est simple - elles sont désactivées de la balance.

L'équilibreur de machine (alors c'était un elbe amazonien) qui a fait planter la machine elle-même marquée comme malsaine, a désactivé la distribution de charge sur eux. L'autoscaling amazonien a fonctionné: lorsque la charge a augmenté, de nouvelles voitures ont été ajoutées au groupe d'autoscaling, la charge a été distribuée aux nouvelles voitures - tout allait bien. Avec nos équilibreurs, la logique est à peu près la même: si quelque chose arrive au serveur d'applications, nous en supprimons les demandes, jetons ces machines, en démarrons de nouvelles et continuons à travailler. Le schéma pour toutes ces années a un peu changé, mais continue de fonctionner: il est simple, compréhensible, et cela ne pose aucun problème.
Nous travaillons partout dans le monde, la charge de pointe des clients est complètement différente et, dans le bon sens, nous devrions être en mesure d'effectuer à tout moment certains travaux de maintenance avec tous les composants de notre système - de manière invisible pour les clients. Par conséquent, nous avons la possibilité d'arrêter la base de données du travail, en redistribuant la charge sur le deuxième centre de données.
Comment ça marche? - Nous transférons le trafic vers un centre de données opérationnel - s'il s'agit d'un accident dans un centre de données, puis complètement, si c'est notre travail prévu avec une base donnée, alors nous faisons partie du trafic desservant ces clients, basculons vers un deuxième centre de données, il s'arrête réplication. Si vous avez besoin de nouvelles machines pour les applications Web, car la charge sur le deuxième centre de données a augmenté, elles démarrent automatiquement. Nous terminons le travail, la réplication est restaurée et nous renvoyons la totalité de la charge. Si nous devons refléter certains travaux dans le deuxième contrôleur de domaine, par exemple, installer des mises à jour système ou modifier les paramètres dans la deuxième base de données, alors, en général, nous répétons la même chose, juste dans l'autre sens. Et s'il s'agit d'un accident, nous faisons tout en un rien de temps: dans le système de surveillance, nous utilisons le mécanisme des gestionnaires d'événements. Si plusieurs vérifications fonctionnent pour nous et que l'état devient critique, alors ce gestionnaire est lancé, un gestionnaire qui peut exécuter telle ou telle logique. Pour chaque base de données, nous avons enregistré quel serveur est le basculement pour elle, et où vous devez changer le trafic s'il n'est pas disponible. Nous - comme cela s'est développé historiquement - utilisons sous une forme ou une autre nagios ou l'une de ses fourchettes. En principe, des mécanismes similaires existent dans presque tous les systèmes de surveillance, nous n'utilisons pas encore quelque chose de plus compliqué, mais peut-être qu'un jour nous le ferons. Maintenant, la surveillance est déclenchée par l'inaccessibilité et a la possibilité de changer quelque chose.
Avons-nous tout réservé?
Nous avons de nombreux clients des États-Unis, de nombreux clients d'Europe, de nombreux clients plus proches de l'Est - le Japon, Singapour, etc. Bien sûr, une énorme proportion de clients en Russie. Autrement dit, le travail est loin d'être dans une seule région. Les utilisateurs veulent une réponse rapide, il y a des exigences pour observer les différentes lois locales, et dans chaque région, nous réservons pour deux centres de données, en plus il y a quelques services supplémentaires qui, encore une fois, sont pratiques à placer dans une région - pour les clients qui sont dans ce travail régional. Les gestionnaires REST, les serveurs d'autorisation, ils sont moins critiques pour le client dans son ensemble, vous pouvez basculer entre eux avec un petit délai acceptable, mais vous ne voulez pas inventer des vélos, comment les surveiller et quoi en faire. Par conséquent, nous essayons au maximum d'utiliser les solutions existantes, et non de développer une certaine compétence dans des produits supplémentaires. Et quelque part, nous utilisons trivialement la commutation au niveau du DNS et nous déterminons la vivacité du service avec les mêmes DNS. Amazon a un service Route 53, mais ce n'est pas seulement le DNS dans lequel vous pouvez tout enregistrer, c'est beaucoup plus flexible et pratique. Grâce à lui, vous pouvez créer des services géo-distribués avec des géolocalisations, lorsque vous l'utilisez pour déterminer d'où vient le client et leur donner certains enregistrements - avec lui, vous pouvez créer des architectures de basculement. Les mêmes vérifications de l'état sont configurées dans Route 53 lui-même, vous spécifiez des points de terminaison qui sont surveillés, définissez des métriques et spécifiez les protocoles qui déterminent la vivacité du service - tcp, http, https; définir la fréquence des vérifications qui déterminent si le service est en direct ou non. Et dans le DNS lui-même, vous prescrivez ce qui sera principal, ce qui sera secondaire, où basculer si le contrôle de santé à l'intérieur de la route 53 est déclenché. Tout cela peut être fait avec d'autres outils, mais ce qui est plus pratique - nous le configurons une fois, puis ne pensons pas à comment nous vérifions, comment nous changeons: tout fonctionne par lui-même.
Le premier «mais» : comment et comment réserver la route 53 elle-même? Cela arrive-t-il si quelque chose lui arrive? Heureusement, nous n'avons jamais marché sur ce râteau, mais encore une fois, devant moi, je vais avoir une histoire pourquoi nous pensions que nous devions encore réserver. Ici, nous posons la paille à l'avance. Plusieurs fois par jour, nous effectuons un déchargement complet de toutes les zones que nous avons sur la route 53. L'API d'Amazon vous permet de les soumettre en toute sécurité à JSON, et nous avons créé plusieurs serveurs redondants où nous le convertissons, le téléchargeons sous forme de configurations et, grosso modo, avons une configuration de sauvegarde. Dans ce cas, nous pouvons le déployer rapidement manuellement, nous ne perdrons pas les données des paramètres DNS.
Le second «mais» : qu'est-ce qui n'est pas réservé sur cette photo? L'équilibreur lui-même! Nous avons simplifié la répartition des clients par région. Nous avons des domaines bitrix24.ru, bitrix24.com, .de - il existe maintenant 13 domaines différents qui fonctionnent dans des zones très différentes. Nous en sommes arrivés à ce qui suit: chaque région a ses propres équilibreurs. Il est plus pratique de distribuer par région, selon l'endroit où se trouve la charge de pointe sur le réseau. S'il s'agit d'un échec au niveau d'un équilibreur, il est simplement mis hors service et supprimé du DNS. Si un problème se produit avec un groupe d'équilibreurs, ils sont réservés sur d'autres sites, et la commutation entre eux se fait en utilisant la même route53, car en raison d'un court ttl, la commutation se produit pendant un maximum de 2, 3, 5 minutes.
Le troisième «mais» : qu'est-ce qui n'a pas encore été réservé? S3, à droite. Nous, en plaçant les fichiers stockés par les utilisateurs dans s3, avons sincèrement cru qu'il s'agissait d'un perçage d'armure et qu'il n'était pas nécessaire de réserver quoi que ce soit là-bas. Mais l'histoire montre ce qui se passe différemment. En général, Amazon décrit S3 comme un service fondamental, car Amazon utilise lui-même S3 pour stocker des images de machines, des configurations, des images AMI, des instantanés ... Et si s3 se bloque, comme cela s'est produit au cours de ces 7 années, combien de bitrix24 nous avons utilisé, il est suivi par un fan tire un tas de tout - inaccessibilité de démarrage des machines virtuelles, dysfonctionnement api et ainsi de suite.
Et S3 peut tomber - c'est arrivé une fois. Par conséquent, nous sommes arrivés au schéma suivant: il y a quelques années, il n'y avait pas de stockage public d'objets sérieux en Russie, et nous envisagions la possibilité de faire quelque chose de notre propre ... Heureusement, nous n'avons pas commencé à le faire, car nous creuserions cet examen que nous n'avons pas posséder, et l'aurait probablement fait. Maintenant, Mail.ru a des stockages compatibles s3, Yandex l'a, et un certain nombre de fournisseurs l'ont toujours. En conséquence, nous sommes arrivés à la conclusion que nous voulons avoir, d'une part, une sauvegarde, et d'autre part, la possibilité de travailler avec des copies locales. Pour une région russe particulière, nous utilisons le service Mail.ru Hotbox, qui est compatible api avec s3. Nous n'avons eu besoin d'aucune modification sérieuse du code à l'intérieur de l'application, et nous avons fait le mécanisme suivant: en s3 il y a des déclencheurs qui fonctionnent sur la création / suppression d'objets, Amazon a un service comme Lambda - c'est du code en cours d'exécution sans serveur qui s'exécutera juste lorsque certains déclencheurs sont déclenchés.
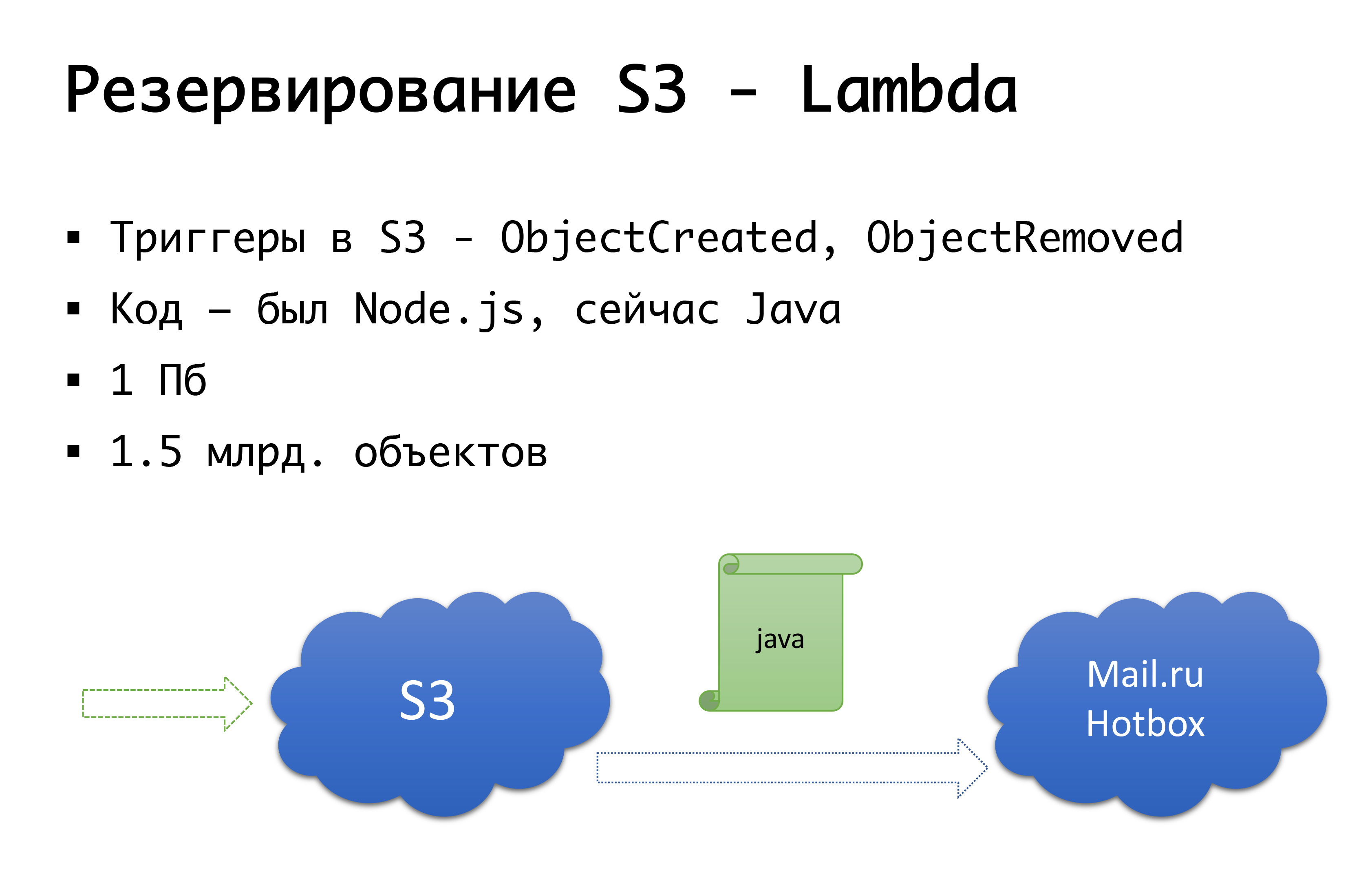
Nous l'avons fait très simplement: si notre déclencheur se déclenche, nous exécutons le code qui copiera l'objet dans le référentiel Mail.ru. Pour commencer à travailler pleinement avec des copies locales de données, nous avons également besoin d'une synchronisation inverse, afin que les clients situés dans le segment russe puissent travailler avec un stockage plus proche d'eux. Mail est sur le point de terminer les déclencheurs dans son référentiel - il sera possible d'effectuer une synchronisation inverse déjà au niveau de l'infrastructure, mais pour l'instant nous le faisons au niveau de notre propre code. Si nous voyons que le client a placé une sorte de fichier, alors à notre niveau de code, nous mettons l'événement dans la file d'attente, le traitons et effectuons la réplication inverse. Pourquoi est-ce mauvais: si nous avons une sorte de travail avec nos objets en dehors de notre produit, c'est-à-dire par des moyens externes, nous n'en tiendrons pas compte. Par conséquent, nous attendons la fin lorsque les déclencheurs apparaissent au niveau du stockage afin que, peu importe d'où nous exécutons le code, l'objet qui nous est envoyé soit copié dans l'autre sens.
Au niveau du code, pour chaque client, les deux référentiels sont enregistrés: l'un est considéré comme le principal, l'autre est la sauvegarde. Si tout va bien, nous travaillons avec le stockage le plus proche de nous: nos clients qui sont chez Amazon, ils travaillent avec S3, et ceux qui travaillent en Russie, ils travaillent avec Hotbox. Si la case à cocher fonctionne, le basculement doit se connecter à nous et nous basculerons les clients vers un autre stockage. Nous pouvons définir ce drapeau indépendamment par région et pouvons les changer d'avant en arrière. Dans la pratique, nous ne l'avons pas encore utilisé, mais nous avons envisagé ce mécanisme et nous pensons qu'un jour nous aurons besoin et utiliser ce même commutateur. Une fois que c'est déjà arrivé.
Oh, et votre Amazone s'est échappée ...
En avril, c'est l'anniversaire du début des écluses des télégrammes en Russie. Amazon est le fournisseur le plus touché. Et, malheureusement, les entreprises russes qui ont travaillé dans le monde entier ont souffert davantage.
Si l'entreprise est mondiale et que la Russie est un très petit segment, 3-5% - enfin, d'une manière ou d'une autre, vous pouvez en faire don.
S'il s'agit d'une entreprise purement russe - je suis sûr que vous devez vous localiser localement - eh bien, c'est juste que les utilisateurs eux-mêmes seront pratiques, confortables, il y aura moins de risques.
Et si c'est une entreprise qui travaille dans le monde entier et qui a des parts à peu près égales de clients de Russie et quelque part dans le monde? La connectivité des segments est importante et ils doivent de toute façon fonctionner ensemble.
Fin mars 2018, Roskomnadzor a envoyé une lettre aux plus grands opérateurs déclarant qu'ils prévoyaient de bloquer plusieurs millions d'ip Amazon afin de bloquer ... le messager Zello. Grâce à ces mêmes fournisseurs - ils ont réussi à divulguer la lettre à tout le monde, et il était entendu que la connectivité avec Amazon pourrait s'effondrer. C'était vendredi, nous avons couru vers les collègues de servers.ru dans la panique, avec les mots: "Amis, nous avons besoin de plusieurs serveurs qui ne seront pas en Russie, pas en Amazonie, mais, par exemple, quelque part à Amsterdam", afin d'être en mesure de mettre au moins notre propre vpn et proxy là-bas pour certains points de terminaison que nous ne pouvons pas influencer du tout, par exemple les terminaux du même s3 - nous ne pouvons pas essayer de créer un nouveau service et d'obtenir un autre ip, nous vous devez encore y arriver. En quelques jours, nous avons installé ces serveurs, les avons élevés et, en général, nous avons préparé le démarrage des écluses. Il est curieux que l'ILV, en regardant le battage médiatique et la panique suscitée, ait déclaré: "Non, nous ne bloquerons rien maintenant." (Mais c'est exactement jusqu'au moment où ils ont commencé à bloquer les télégrammes.) Après avoir configuré les options de contournement et réalisé qu'ils n'étaient pas entrés dans la serrure, nous n'avons néanmoins pas démantelé le tout. Donc, juste au cas où.

Et en 2019, nous vivons toujours dans des conditions d'écluses. J'ai regardé hier soir: environ un million d'ip continuent d'être bloqués. Certes, Amazon a presque complètement débloqué, au sommet a atteint 20 millions d'adresses ... En général, la réalité est que la connectivité, une bonne connectivité - ce n'est peut-être pas. Tout d'un coup. Ce n'est peut-être pas pour des raisons techniques - incendies, excavatrices, tout ça. Ou, comme nous l'avons vu, pas entièrement technique. Par conséquent, quelqu'un de grand et de grand, avec son propre AS-kami, peut probablement le diriger d'autres manières - la connexion directe et d'autres choses sont déjà au niveau l2. Mais dans une version simple, tout comme nous ou même plus petite, vous pouvez, au cas où, avoir une redondance au niveau des serveurs élevés ailleurs, configuré à l'avance vpn, proxy, avec la possibilité de changer rapidement de configuration dans les segments que vous avez une connectivité critique . Cela nous a été utile plus d'une fois, lorsque les verrous Amazon ont commencé, nous avons laissé passer le trafic S3 dans le pire des cas, mais progressivement tout s'est mal passé.
Et comment réserver ... l'ensemble du prestataire?
Maintenant, nous n'avons aucun scénario en cas de défaillance de l'ensemble de l'Amazonie. Nous avons un scénario similaire pour la Russie. En Russie, nous avons été hébergés par un fournisseur, à partir duquel nous avons choisi d'avoir plusieurs sites. Et il y a un an, nous avons rencontré un problème: même s'il s'agit de deux centres de données, il peut déjà y avoir des problèmes au niveau de la configuration réseau du fournisseur qui affecteront de toute façon les deux centres de données. Et nous pouvons obtenir l'inaccessibilité sur les deux sites. Bien sûr, c'est ce qui s'est produit. Nous avons finalement redéfini l'architecture à l'intérieur. Cela n'a pas beaucoup changé, mais pour la Russie, nous avons maintenant deux sites, qui ne sont pas un fournisseur, mais deux différents. Si l'un d'eux échoue, nous pouvons passer à un autre.
Hypothétiquement, nous envisageons pour Amazon de réserver au niveau d'un autre fournisseur; peut-être Google, peut-être quelqu'un d'autre ... Mais jusqu'à présent, nous avons observé dans la pratique que si Amazon se bloque au même niveau de zone de disponibilité, les plantages au niveau d'une région entière sont assez rares. Par conséquent, nous avons théoriquement l'idée que, peut-être, nous ferons une réserve «Amazon n'est pas Amazon», mais en pratique cela n'existe pas encore.
Quelques mots sur l'automatisation
Avez-vous toujours besoin d'automatisation? Il convient de rappeler l'effet Dunning-Krueger. Sur l'axe des x, nos connaissances et notre expérience, que nous acquérons, et sur l'axe des y - la confiance dans nos actions. Au début, nous ne savons rien et nous ne sommes pas du tout sûrs. Ensuite, nous savons un peu et devenons méga-confiants - c'est ce qu'on appelle le «pic de stupidité», est bien illustré par l'image «démence et courage». De plus, nous avons déjà appris un peu et sommes prêts à entrer dans la bataille. Ensuite, nous marchons sur un râteau méga-sérieux, tombons dans une vallée de désespoir quand nous semblons savoir quelque chose, mais en fait, nous ne savons pas grand-chose. Ensuite, à mesure que vous acquérez de l'expérience, nous devenons plus confiants.
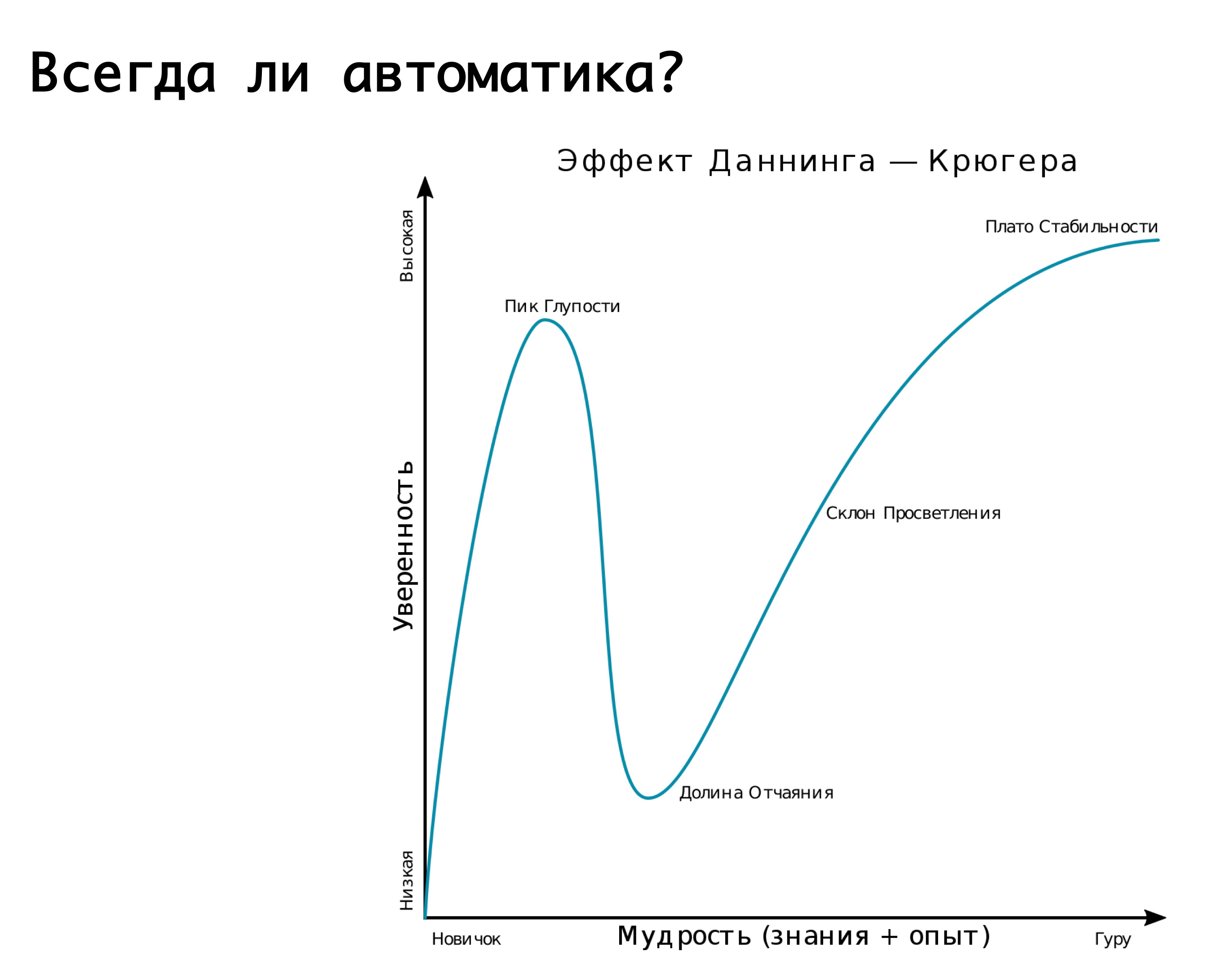
Notre logique de basculement automatique vers un accident ou un autre est très bien décrite par ce graphique.
Nous avons commencé - nous ne savions rien, presque tout le travail a été fait manuellement. Ensuite, nous avons réalisé que tout pouvait être suspendu automatiquement et, comme, dormir paisiblement. Et soudain, nous montons sur le méga-râteau: nous avons déclenché de faux positifs, et nous inversons le trafic quand, dans le bon sens, cela n'en valait pas la peine. Par conséquent, la réplication ou autre chose se brise - c'est la vallée même du désespoir. Et puis nous arrivons à la compréhension que tout doit être traité avec sagesse. Autrement dit, il est logique de s'appuyer sur l'automatisation, offrant la possibilité de fausses alarmes. Mais!
si les conséquences peuvent être dévastatrices, il est préférable de le confier au quart de travail en service, aux ingénieurs de service qui s'assureront qu'ils ont vraiment un accident et effectueront les actions nécessaires manuellement ...Conclusion
7 , , - , — -, , , , — — . - , , , . — , , — . , - — s3, , . , , - - . . , , — : , — ? , - , , - «, ».
Un compromis raisonnable entre le perfectionnisme et les forces réelles, le temps, l'argent que vous pouvez dépenser pour le plan que vous aurez éventuellement.Ce texte est une version complétée et développée du rapport d'Alexander Demidov lors de la conférence Uptime day 4 .