
Chaque service, dont les utilisateurs peuvent créer leur propre contenu (UGC - Content généré par l'utilisateur), est obligé non seulement de résoudre des problèmes commerciaux, mais aussi de mettre de l'ordre dans UGC. Une modération de contenu médiocre ou de mauvaise qualité au final peut réduire l'attractivité du service pour les utilisateurs, jusqu'à la fin de son travail.
Aujourd'hui, nous allons vous parler de la synergie entre Yula et Odnoklassniki, ce qui nous aide à modérer efficacement les annonces sur Yule.
La synergie en général est très utile, et dans le monde moderne, lorsque la technologie et les tendances changent très rapidement, elle peut devenir une bouée de sauvetage. Pourquoi consacrer des ressources et du temps rares à l'invention de ce que vous avez déjà été inventé et évoqué?
Nous avons pensé la même chose lorsque nous avons été confrontés au défi de modérer le contenu généré par les utilisateurs - images, texte et liens. Nos utilisateurs téléchargent des millions d'unités de contenu sur Yula chaque jour, et sans traitement automatique, la modération manuelle de toutes ces données n'est pas du tout réaliste.
Par conséquent, nous avons profité de la plate-forme de modération déjà préparée, que nos collègues d'Odnoklassniki avaient alors surnommée «presque parfaite».
Pourquoi camarades de classe?
Chaque jour, des dizaines de millions d'utilisateurs viennent sur le réseau social pour publier des milliards d'unités de contenu: des photos aux vidéos et aux textes. La plateforme de modération d'Odnoklassniki permet de vérifier de très grandes quantités de données et de lutter contre les spammeurs et les bots.
L'équipe de modération OK a acquis beaucoup d'expérience, car elle améliore son outil depuis 12 ans. Il est important qu'ils puissent non seulement partager leurs solutions toutes faites, mais également configurer l'architecture de leur plateforme pour nos tâches spécifiques.

Par souci de concision, nous appellerons simplement la plate-forme de modération OK «plate-forme».
Comment ça marche
Entre Yula et Odnoklassniki, l'échange de données est établi via
Apache Kafka .
Pourquoi avons-nous choisi cet outil:
- À Yulia, toutes les annonces sont post-modérées, donc au départ, une réponse synchrone n'était pas requise.
- Si un paragraphe féroce se produit et que Yula ou Odnoklassniki seront inaccessibles, y compris en raison de certaines charges de pointe, les données de Kafka ne disparaîtront nulle part et pourront être lues plus tard.
- La plateforme a déjà été intégrée à Kafka, donc la plupart des problèmes de sécurité ont été résolus.
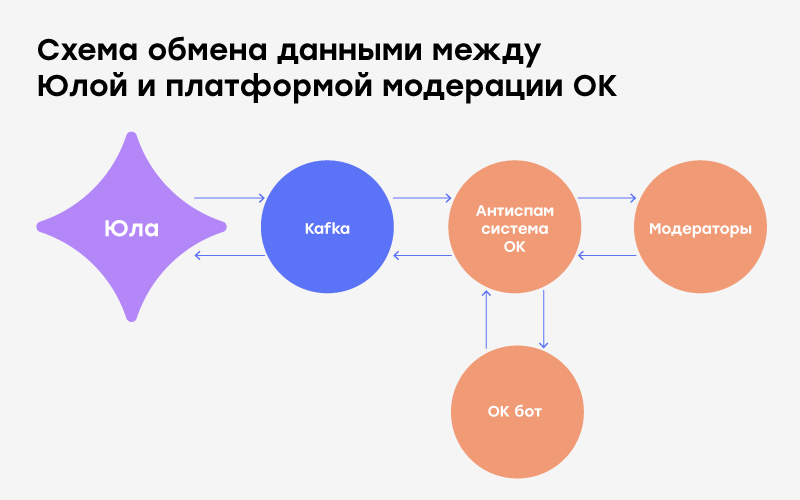
Pour chaque annonce créée ou modifiée par l'utilisateur dans Yule, JSON est généré avec des données, qui sont mises dans Kafka pour une modération ultérieure. Depuis Kafka, les annonces sont téléchargées sur la plateforme, où les décisions sont prises automatiquement ou manuellement. Les mauvaises annonces sont bloquées pour une raison, et celles pour lesquelles la plate-forme n'a trouvé aucune violation sont signalées comme "bonnes". Ensuite, toutes les décisions sont renvoyées à Yula et appliquées dans le service.
En conséquence, pour Yula, tout se résume à des actions simples: envoyer une annonce sur la plateforme Odnoklassniki et récupérer la résolution «ok», ou pourquoi pas «ok».
Traitement automatique
Qu'arrive-t-il à une annonce une fois qu'elle arrive sur la plateforme? Chaque annonce est divisée en plusieurs entités:
- nom
- description
- des photos
- catégorie et sous-catégorie de l'annonce sélectionnées par l'utilisateur,
- le prix.

Ensuite, pour chaque entité, la plateforme se clusterise pour trouver des doublons. De plus, le texte et les photos sont regroupés de différentes manières.
Les textes avant la mise en cluster sont normalisés pour effacer les caractères spéciaux, les lettres modifiées et autres ordures. Les données reçues sont divisées en N-grammes, chacun étant haché. Le résultat est un grand nombre de hachages uniques. La similitude entre les textes est considérée
comme Jacquard entre les deux ensembles résultants. Si la similitude est supérieure au seuil, alors les textes sont collés ensemble dans un groupe. Pour accélérer la recherche de clusters similaires, le hachage MinHash et sensible à la localité sont utilisés.
Diverses options de collage d'images ont été inventées pour les photos, de la comparaison des images pHash à la recherche de doublons à l'aide d'un réseau neuronal.
Cette dernière méthode est la plus "dure". Pour former le modèle, de tels triplets d'images (N, A, P) ont été sélectionnés dans lesquels N ne ressemble pas à A, et P - ressemble à A (est un demi-double). Ensuite, le réseau neuronal a appris à rendre A et P aussi proches que possible, et A et N autant que possible. Cela se traduit par moins de faux positifs par rapport à l'intégration simple à partir d'un réseau pré-formé.
Lorsqu'un réseau de neurones reçoit des images en entrée, il génère un vecteur à N (128) dimensions pour chacun d'eux et une demande est effectuée pour évaluer la proximité de l'image. Ensuite, un seuil est calculé à partir duquel les images proches sont considérées comme des doublons.
Le modèle peut habilement trouver des spammeurs qui photographient spécifiquement le même produit sous différents angles afin de contourner la comparaison pHash.

 Un exemple de photos de spam collées par un réseau de neurones en tant que doublons.
Un exemple de photos de spam collées par un réseau de neurones en tant que doublons.Au stade final, les annonces en double sont recherchées simultanément dans le texte et l'image.
Si deux annonces ou plus sont bloquées dans un cluster, le système démarre un blocage automatique qui, selon certains algorithmes, sélectionne les doublons à supprimer et ceux à laisser. Par exemple, si deux utilisateurs ont les mêmes photos dans une annonce, le système bloquera une annonce plus récente.
Après la création, tous les clusters passent par une série de filtres automatiques. Chaque filtre attribue un score au cluster: avec quelle probabilité contient-il la menace identifiée par ce filtre.
Par exemple, le système analyse la description de l'annonce et sélectionne des catégories potentielles pour celle-ci. Il prend ensuite celle qui a la probabilité la plus élevée et la compare à la catégorie indiquée par le créateur de l'annonce. S'ils ne correspondent pas, l'annonce est bloquée pour la mauvaise catégorie. Et puisque nous sommes gentils et honnêtes, nous disons directement à l'utilisateur quelle catégorie il doit choisir pour que l'annonce passe la modération.
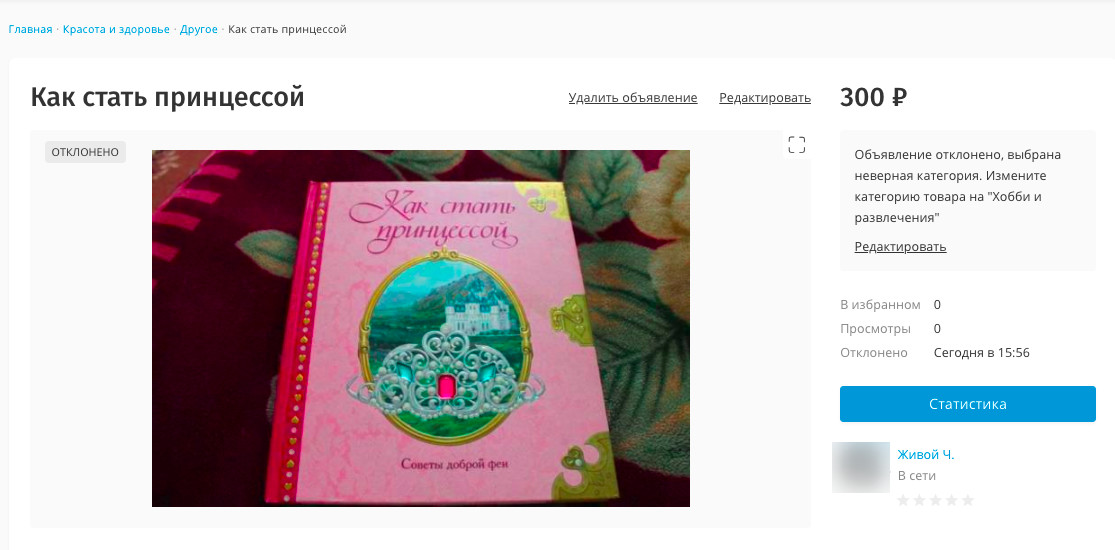 Bloquer la notification pour la mauvaise catégorie.
Bloquer la notification pour la mauvaise catégorie.Dans notre plate-forme, l'apprentissage automatique se sent comme à la maison. Par exemple, avec son aide, nous recherchons des produits interdits dans la Fédération de Russie dans les noms et les descriptions. Et les modèles de réseaux de neurones «regardent» méticuleusement les images pour les URL, les textes des spammeurs, les téléphones et les mêmes «interdits».
Pour les cas où ils essaient de vendre des marchandises interdites en se déguisant en quelque chose de légal, et en même temps, il n'y a pas de texte dans le nom ou la description, nous utilisons le marquage d'image. Pour chaque image peut être apposée jusqu'à 11 mille étiquettes différentes qui décrivent ce qui est sur l'image.
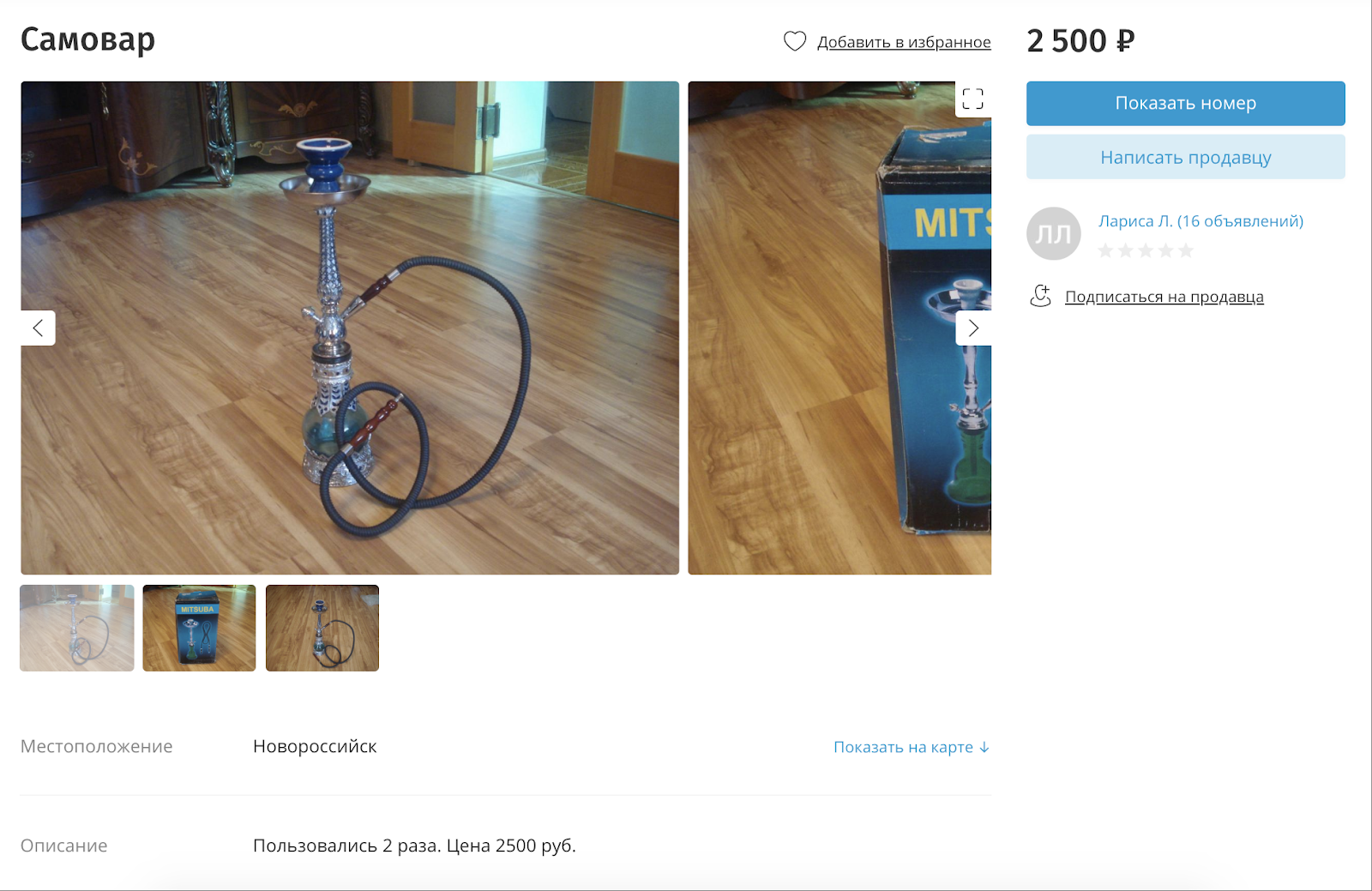 Ils essaient de vendre un narguilé, le déguisant en samovar.
Ils essaient de vendre un narguilé, le déguisant en samovar.En parallèle avec des filtres complexes, simples, résolvant des tâches évidentes liées au travail de texte:
- antimat;
- Détecteur d'URL et de numéro de téléphone;
- mention des messageries instantanées et autres contacts;
- prix bas;
- des annonces qui ne vendent rien, etc.
Aujourd'hui, chaque annonce passe au tamis fin de plus de 50 filtres automatiques qui essaient de trouver quelque chose de mauvais dans l'annonce.
Si aucun des détecteurs n'a fonctionné, une réponse est envoyée à Yulu indiquant que l'annonce est «très probablement» terminée. Nous utilisons cette réponse à la maison, et les utilisateurs qui s'abonnent au vendeur reçoivent une notification concernant l'apparition d'un nouveau produit.
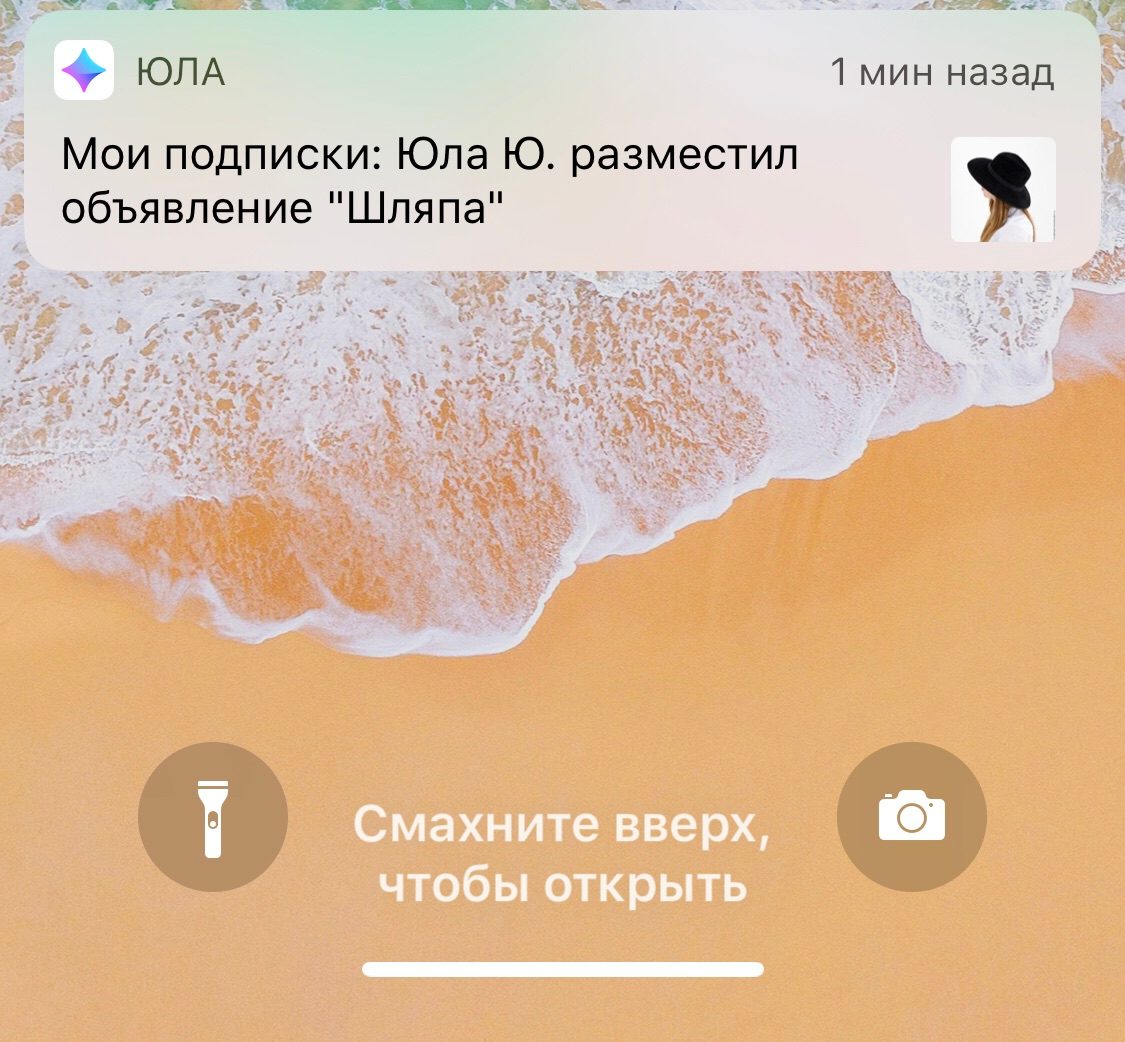 Notification que le vendeur a un nouveau produit.
Notification que le vendeur a un nouveau produit.Par conséquent, chaque annonce «est envahie» de métadonnées, dont certaines sont générées lors de la création de l'annonce (adresse IP de l'auteur, agent utilisateur, plate-forme, géolocalisation, etc.), et le reste est le score donné par chaque filtre.
Files d'attente publicitaires
Lorsqu'une annonce arrive sur la plateforme, le système la place dans l'une des files d'attente. Chaque file d'attente est formée à l'aide d'une formule mathématique qui combine des métadonnées publicitaires de manière à détecter une sorte de mauvais modèle.
Par exemple, vous pouvez créer une file d'attente d'annonces dans la catégorie "Téléphones portables" à partir d'utilisateurs de Yula supposément de Saint-Pétersbourg, mais en même temps de leurs adresses IP de Moscou ou d'autres villes.
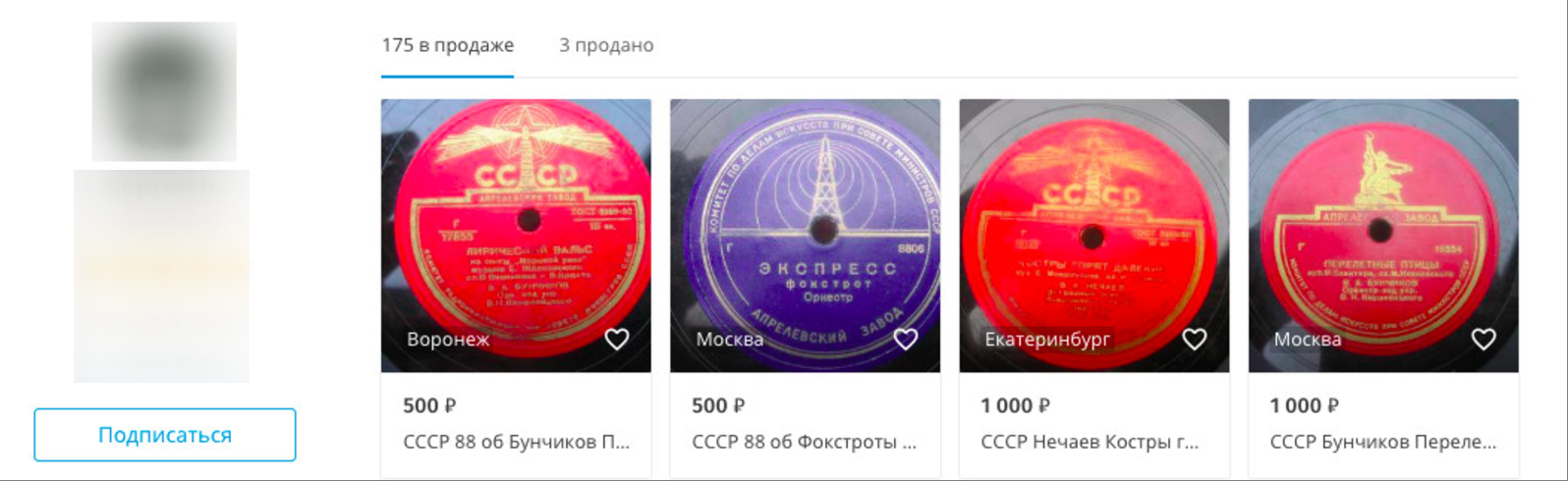 Un exemple d'annonces publiées par un utilisateur dans différentes villes.
Un exemple d'annonces publiées par un utilisateur dans différentes villes.Ou, vous pouvez créer des files d'attente en fonction des points que le réseau de neurones attribue aux annonces, en les plaçant par ordre décroissant.
Chaque ligne, selon sa formule, attribue un score final à l'annonce. Ensuite, vous pouvez agir de différentes manières:
- spécifier une valeur seuil à laquelle l'annonce recevra un certain type de blocage;
- toutes les annonces de la file d'attente doivent être envoyées aux modérateurs pour examen manuel;
- ou combinez les options précédentes: spécifiez le seuil de blocage automatique et envoyez aux modérateurs les annonces qui n'ont pas atteint ce seuil.

Pourquoi ces lignes sont-elles nécessaires? Disons qu'un utilisateur a téléchargé une photo d'une arme à feu. Le réseau neuronal lui attribue un score de 95 à 100 et avec une précision de 99% détermine ce que l'arme est dans l'image. Mais si la valeur du score est inférieure à 95%, la précision du modèle commence à décliner (c'est une caractéristique des modèles de réseau neuronal).
En conséquence, une file d'attente est formée sur la base du modèle de score, et les annonces reçues de 95 à 100 sont automatiquement bloquées en tant que «marchandises interdites». Les annonces avec des points inférieurs à 95 sont envoyées aux modérateurs pour traitement manuel.
 Beretta au chocolat avec cartouches. Uniquement pour la modération manuelle! :)
Beretta au chocolat avec cartouches. Uniquement pour la modération manuelle! :)Modération manuelle
Début 2019, environ 94% de toutes les annonces de Yule sont modérées automatiquement.

Si la plate-forme ne peut pas décider d'annonces, les envoie pour modération manuelle. Les camarades de classe ont développé leur propre outil: les tâches des modérateurs affichent immédiatement toutes les informations nécessaires pour prendre une décision rapide - la publicité est appropriée ou doit être bloquée avec une indication de la raison.
Et pour que la modération manuelle ne nuise pas à la qualité de service, le travail des personnes est constamment surveillé. Par exemple, dans le flux de tâches, le modérateur affiche des «pièges» - des annonces pour lesquelles il existe déjà des solutions toutes faites. Si la décision du modérateur ne coïncide pas avec la décision prête, une erreur est comptée pour le modérateur.
Le modérateur moyen passe 10 secondes pour vérifier une annonce. De plus, le nombre d'erreurs ne dépasse pas 0,5% de toutes les annonces testées.
Modération folklorique
Des collègues d'Odnoklassniki sont allés encore plus loin, ont profité de "l'aide de la salle": ils ont écrit un jeu d'application pour le réseau social dans lequel vous pouvez rapidement baliser une grande quantité de données, mettant en évidence un mauvais signe, - Modérateur Odnoklassnikov (
https://ok.ru/app/ modérateur ). Un bon moyen de profiter de l'aide des utilisateurs OK qui essaient de rendre le contenu plus agréable.
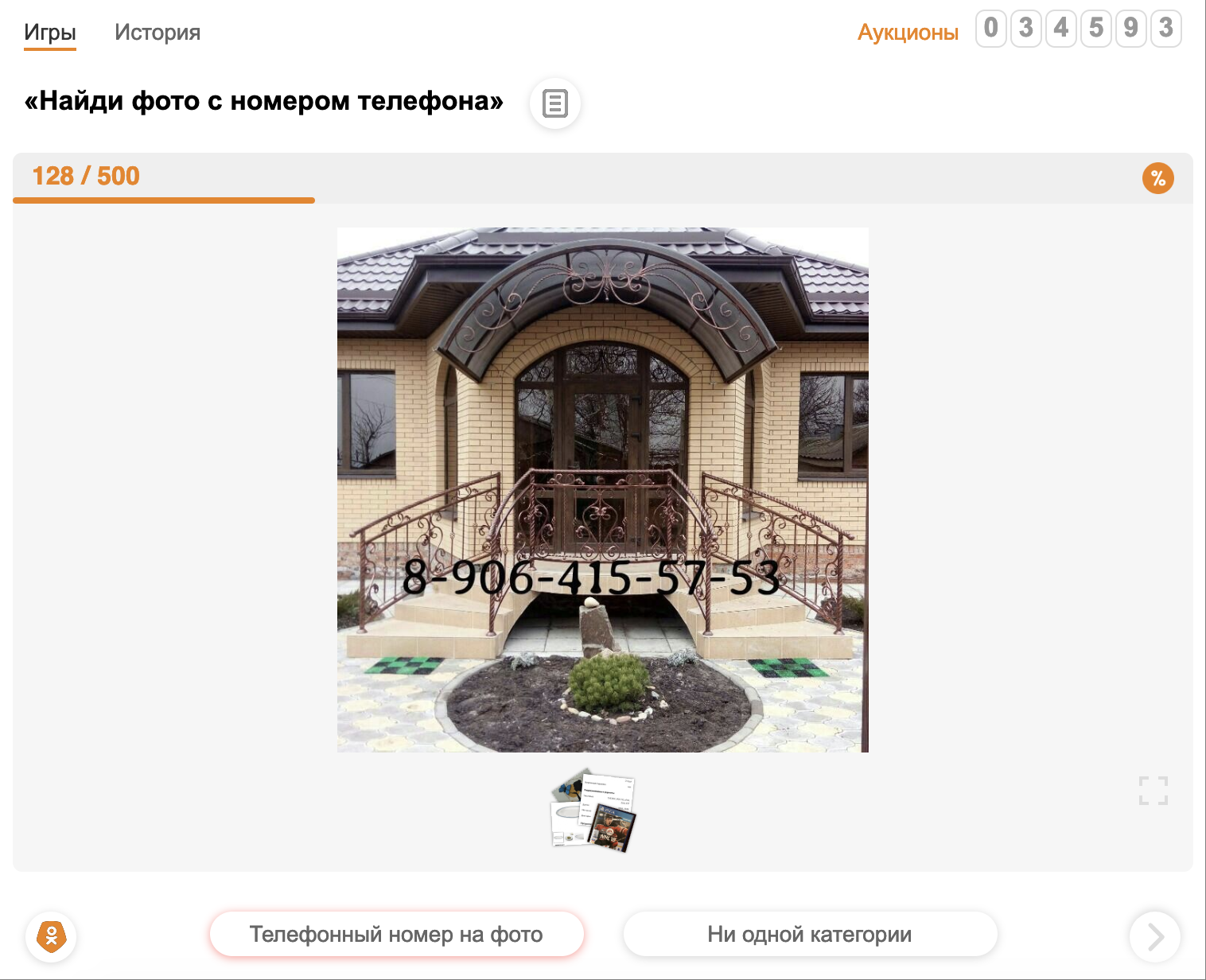 Un jeu dans lequel les utilisateurs marquent des photos qui ont un numéro de téléphone.
Un jeu dans lequel les utilisateurs marquent des photos qui ont un numéro de téléphone.Toute file d'attente d'annonces de la plate-forme peut être redirigée vers le jeu Odnoklassniki Moderator. Tout ce que les utilisateurs du jeu marquent, va ensuite aux modérateurs internes pour vérification. Ce schéma vous permet de bloquer les annonces pour lesquelles aucun filtre n'a encore été créé et de créer simultanément des exemples d'apprentissage.
Stockage des résultats de modération
Nous enregistrons toutes les décisions prises pendant la modération, afin que plus tard nous ne traitions pas les annonces qui ont déjà pris une décision.
Les annonces génèrent des millions de clusters quotidiennement. Au fil du temps, chaque cluster reçoit une note «bonne» ou «mauvaise». Chaque nouvelle annonce ou son édition, tombant dans le cluster avec une marque, reçoit automatiquement la résolution du cluster lui-même. Environ 20 000 de ces résolutions automatiques par jour.
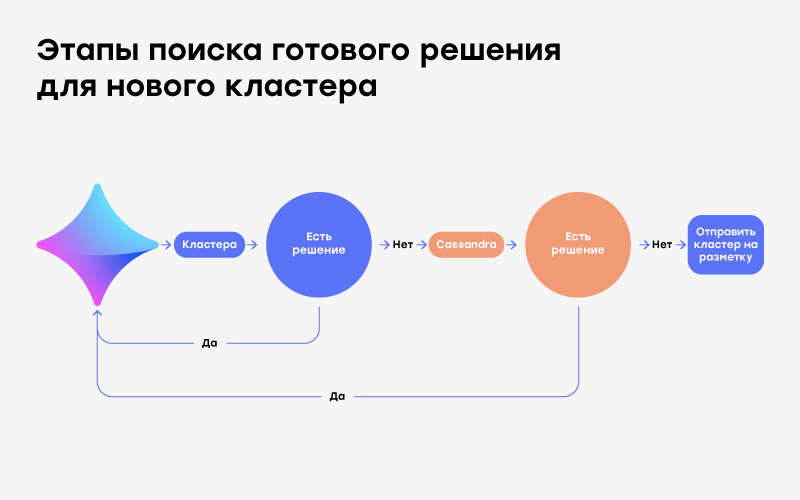
Si le cluster ne reçoit pas de nouvelles déclarations, il est supprimé de la mémoire et son hachage et sa solution sont écrits dans Apache Cassandra.
Lorsque la plateforme reçoit une nouvelle annonce, elle essaie d'abord de trouver un cluster similaire parmi ceux déjà créés et de prendre une décision. S'il n'y a pas un tel cluster, la plate-forme va à Cassandra et y cherche. Vous l'avez trouvé? Génial, applique la solution au cluster et l'envoie à Yula. En moyenne, 70 000 de ces décisions «répétées» sont recrutées, soit 8% du total.
Pour résumer
Nous utilisons la plateforme de modération Odnoklassniki depuis deux ans et demi. Nous aimons les résultats:
- Nous modérons automatiquement 94% de toutes les annonces par jour.
- Le coût de modération d'une publicité est passé de 2 roubles à 7 kopecks.
- Grâce à l'outil fini, ils ont oublié les problèmes de gestion des modérateurs.
- 2,5 fois augmenté le nombre d'annonces traitées manuellement avec le même nombre de modérateurs et le même budget. La qualité de la modération manuelle a également augmenté grâce au contrôle automatisé et fluctue autour de 0,5% des erreurs.
- Filtrez rapidement les nouveaux types de spam.
- Connectez rapidement de nouvelles unités de Yula Vertical à la modération. Depuis 2017, des verticales de l'immobilier, de l'emploi et de l'automobile sont apparues à Yule.