Bonjour, je crée des applications pour le SGBD
Tarantool - il s'agit d'une plateforme développée par Mail.ru Group qui combine un SGBD hautes performances et un serveur d'applications à Lua. La vitesse élevée des solutions basées sur Tarantool est obtenue, en particulier, en prenant en charge le mode SGBD en mémoire et la possibilité d'exécuter la logique d'application métier dans un espace d'adressage unique avec des données. Cela garantit la persistance des données à l'aide des transactions ACID (un journal WAL est conservé sur le disque). Tarantool a un support de réplication et de partitionnement intégré. À partir de la version 2.1, les requêtes SQL sont prises en charge. Tarantool est open source et sous licence BSD simplifiée. Il existe également une version commerciale d'entreprise.
 Ressentez le pouvoir! (... aka profitez de la performance)
Ressentez le pouvoir! (... aka profitez de la performance)Tout cela fait de Tarantool une plate-forme attrayante pour créer des applications de base de données très chargées. Dans de telles applications, la réplication des données devient souvent nécessaire.
Comme mentionné ci-dessus, Tarantool a une réplication de données intégrée. Le principe de son travail est l'exécution séquentielle sur des répliques de toutes les transactions contenues dans le journal de l'assistant (WAL). Typiquement, une telle réplication (nous l'appellerons
bas niveau ci
- dessous) est utilisée pour fournir une tolérance aux pannes de l'application et / ou pour répartir la charge de lecture entre les nœuds du cluster.
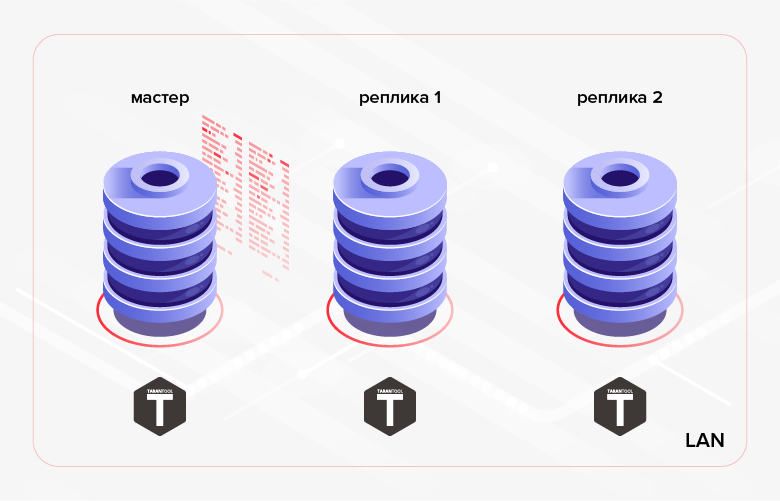 Fig. 1. Réplication au sein du cluster
Fig. 1. Réplication au sein du clusterUn exemple de scénario alternatif est le transfert de données créées dans une base de données vers une autre base de données pour traitement / surveillance. Dans ce dernier cas, une solution plus pratique peut être d'utiliser la réplication de
haut niveau - réplication des données au niveau de la logique métier de l'application. C'est-à-dire Nous n'utilisons pas de solution prête à l'emploi intégrée au SGBD, mais nous implémentons nous-mêmes la réplication dans l'application que nous développons. Cette approche présente à la fois des avantages et des inconvénients. Nous listons les avantages.
1. Économisez du trafic:
- vous ne pouvez pas transférer toutes les données, mais seulement une partie de celles-ci (par exemple, vous ne pouvez transférer que certaines tables, certaines de leurs colonnes ou enregistrements qui répondent à un certain critère);
- contrairement à la réplication de bas niveau, qui est effectuée en continu en mode asynchrone (implémenté dans la version actuelle de Tarantool - 1.10) ou synchrone (à implémenter dans les futures versions de Tarantool), la réplication de haut niveau peut être effectuée par sessions (c'est-à-dire que l'application effectue d'abord la synchronisation des données - session d'échange données, puis il y a une pause dans la réplication, après quoi la prochaine session d'échange a lieu, etc.);
- si l'enregistrement a changé plusieurs fois, vous ne pouvez transférer que sa dernière version (contrairement à la réplication de bas niveau, dans laquelle toutes les modifications apportées à l'assistant seront lues séquentiellement sur les répliques).
2. La mise en œuvre de l'échange via HTTP ne pose aucune difficulté, ce qui vous permet de synchroniser des bases de données distantes.
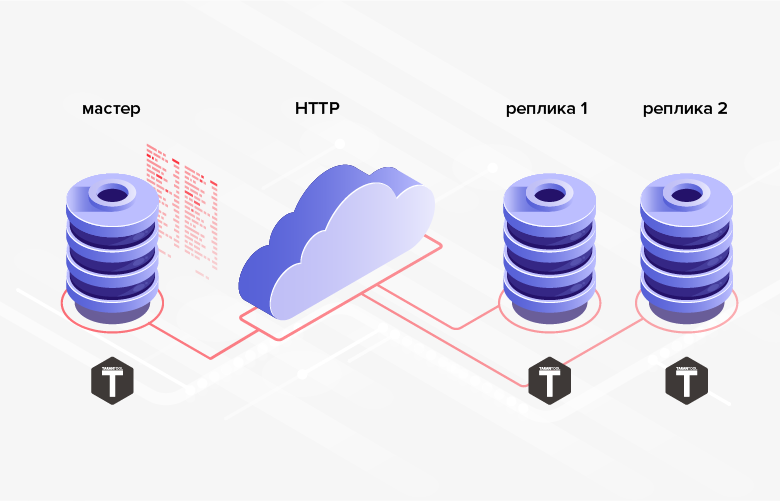 Fig. 2. Réplication HTTP
Fig. 2. Réplication HTTP3. Les structures de base de données entre lesquelles les données sont transmises ne doivent pas être les mêmes (en outre, dans le cas général, il est même possible d'utiliser différents SGBD, langages de programmation, plates-formes, etc.).
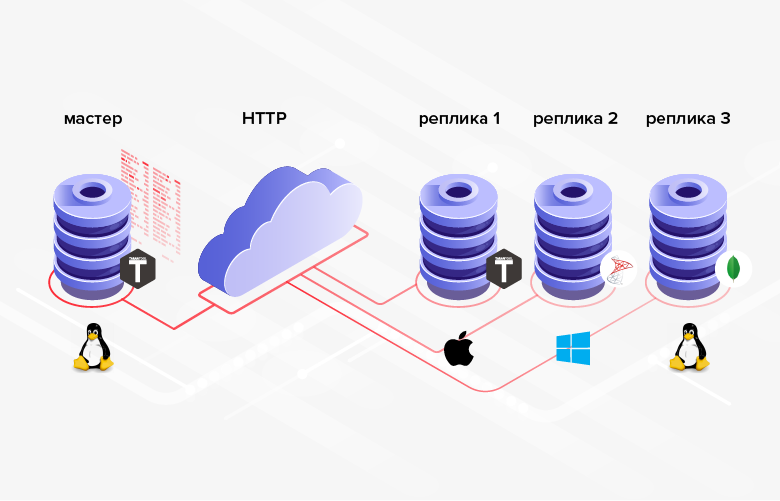 Fig. 3. Réplication dans des systèmes hétérogènes
Fig. 3. Réplication dans des systèmes hétérogènesL'inconvénient est qu'en moyenne, la programmation est plus compliquée / plus chère que la configuration, et au lieu de configurer la fonctionnalité intégrée, vous devrez implémenter la vôtre.
Si dans votre situation, les avantages ci-dessus jouent un rôle décisif (ou sont une condition nécessaire), il est alors judicieux d'utiliser la réplication de haut niveau. Examinons plusieurs façons d'implémenter la réplication de données de haut niveau dans le SGBD Tarantool.
Minimisation du trafic
Ainsi, l'un des avantages de la réplication de haut niveau est la réduction du trafic. Pour que cet avantage se manifeste pleinement, il est nécessaire de minimiser la quantité de données transmises lors de chaque session d'échange. Bien entendu, il ne faut pas oublier qu'à la fin de la session le récepteur de données doit être synchronisé avec la source (au moins pour la partie des données impliquée dans la réplication).
Comment minimiser la quantité de données transférées lors de la réplication de haut niveau? La solution "au front" peut être la sélection des données par date-heure. Pour ce faire, vous pouvez utiliser le champ date-heure déjà dans le tableau (le cas échéant). Par exemple, un document «ordre» peut avoir un champ «temps requis pour l'exécution de l'ordre» -
delivery_time . Le problème avec cette solution est que les valeurs de ce champ ne doivent pas nécessairement être dans la séquence correspondant à la création des commandes. Ainsi, nous ne pouvons pas nous souvenir de la valeur maximale du champ
delivery_time transmise lors de la session d'échange précédente, et lors de la session d'échange suivante, sélectionnez tous les enregistrements avec une valeur plus élevée du champ
delivery_time . Dans l'intervalle entre les sessions d'échange, des enregistrements avec une valeur plus petite du champ
delivery_time peuvent être ajoutés. De plus, la commande pourrait subir des modifications, ce qui n'affectait néanmoins pas le champ
delivery_time . Dans les deux cas, les modifications ne seront pas transmises de la source au récepteur. Pour résoudre ces problèmes, nous devrons transmettre des données "en chevauchement". C'est-à-dire au cours de chaque session d'échange, nous transférerons toutes les données avec une valeur de champ
delivery_time qui dépasse un certain point dans le passé (par exemple, N heures à partir du moment actuel). Cependant, il est évident que pour les grands systèmes, cette approche est très redondante et peut réduire les économies de trafic que nous visons. De plus, la table transmise peut ne pas avoir de champ date-heure.
Une autre solution, plus complexe en termes de mise en œuvre, consiste à accuser réception des données. Dans ce cas, à chaque session d'échange, toutes les données sont transmises, dont la réception n'est pas confirmée par le destinataire. Pour l'implémentation, vous devez ajouter une colonne booléenne à la table source (par exemple,
is_transferred ). Si le destinataire confirme la réception de l'enregistrement, le champ correspondant est défini sur
true , après quoi l'enregistrement n'est plus impliqué dans les échanges. Cette option de mise en œuvre présente les inconvénients suivants. Tout d'abord, pour chaque enregistrement transféré, il est nécessaire de générer et d'envoyer une confirmation. En gros, cela peut être comparable à doubler la quantité de données transférées et à doubler le nombre de voyages aller-retour. Deuxièmement, il n'est pas possible d'envoyer le même enregistrement à plusieurs récepteurs (le premier récepteur confirmera la réception pour lui-même et pour tout le monde).
La méthode, dépourvue des inconvénients ci-dessus, consiste à ajouter des colonnes au tableau à transmettre pour suivre les modifications de ses lignes. Une telle colonne peut être de type date-heure et doit être définie / mise à jour par l'application pour l'heure actuelle à chaque fois en ajoutant / changeant des enregistrements (atomiquement avec en ajoutant / changeant). À titre d'exemple, appelons la colonne
update_time . Après avoir enregistré la valeur maximale du champ de cette colonne pour les enregistrements transférés, nous pouvons démarrer la prochaine session d'échange à partir de cette valeur (sélectionnez les enregistrements dont la valeur du champ
update_time dépasse la valeur précédemment enregistrée). Le problème avec cette dernière approche est que les changements de données peuvent se produire en mode batch. Par conséquent, les valeurs de champ dans la colonne
update_time ne pas être uniques. Par conséquent, cette colonne ne peut pas être utilisée pour la sortie de données par lots (page). Pour la sortie des données page par page, il sera nécessaire d'inventer des mécanismes supplémentaires susceptibles d'avoir une très faible efficacité (par exemple, extraire de la base de données tous les enregistrements avec
update_time au-dessus de la valeur spécifiée et émettre un certain nombre d'enregistrements, en commençant à un certain décalage par rapport au début de l'échantillon).
Vous pouvez augmenter l'efficacité du transfert de données en améliorant légèrement l'approche précédente. Pour ce faire, nous utiliserons un type entier (entier long) comme valeurs des champs de colonne pour suivre les modifications.
row_ver colonne
row_ver . La valeur de champ de cette colonne doit toujours être définie / mise à jour chaque fois qu'un enregistrement est créé / modifié. Mais dans ce cas, le champ sera attribué non pas la date-heure actuelle, mais la valeur d'un compteur augmentée d'une unité. Par conséquent, la colonne
row_ver contiendra des valeurs uniques et peut être utilisée non seulement pour sortir des données «delta» (données ajoutées / modifiées après la fin de la session d'échange précédente), mais aussi pour une pagination simple et efficace.
La dernière méthode proposée pour minimiser la quantité de données transférées dans le cadre d'une réplication de haut niveau me semble la plus optimale et la plus universelle. Arrêtons-nous dessus plus en détail.
Transfert de données à l'aide du compteur de version de ligne
Implémentation serveur / maître
Dans MS SQL Server, pour implémenter cette approche, il existe un type de colonne spécial -
rowversion . Chaque base de données a un compteur, qui augmente d'une unité chaque fois que vous ajoutez / modifiez un enregistrement dans une table qui a une colonne de type
rowversion . La valeur de ce compteur est automatiquement affectée au champ de cette colonne dans l'enregistrement ajouté / modifié. Tarantool DBMS n'a pas de mécanisme intégré similaire. Cependant, dans Tarantool, il n'est pas difficile de l'implémenter manuellement. Considérez comment cela se fait.
Tout d'abord, un peu de terminologie: les tables de Tarantool sont appelées espace et les enregistrements sont appelés tuple. Dans Tarantool, vous pouvez créer des séquences. Les séquences ne sont rien de plus que des générateurs nommés de valeurs ordonnées d'entiers. C'est-à-dire c'est exactement ce dont nous avons besoin pour nos besoins. Ci-dessous, nous allons créer une telle séquence.
Avant d'effectuer une opération de base de données dans Tarantool, vous devez exécuter la commande suivante:
box.cfg{}
Par conséquent, Tarantool commencera à écrire des instantanés et un journal des transactions dans le répertoire actuel.
Créez une séquence
row_version :
box.schema.sequence.create('row_version', { if_not_exists = true })
L'option
if_not_exists permet d'exécuter le script de création plusieurs fois: si l'objet existe, Tarantool n'essaiera pas de le recréer. Cette option sera utilisée dans toutes les commandes DDL suivantes.
Créons un espace pour un exemple.
box.schema.space.create('goods', { format = { { name = 'id', type = 'unsigned' }, { name = 'name', type = 'string' }, { name = 'code', type = 'unsigned' }, { name = 'row_ver', type = 'unsigned' } }, if_not_exists = true })
Ici, nous définissons le nom de l'espace (
goods ), les noms des champs et leurs types.
Les champs d'incrémentation automatique de Tarantool sont également créés à l'aide de séquences. Créez une clé primaire à incrémentation automatique pour le champ
id :
box.schema.sequence.create('goods_id', { if_not_exists = true }) box.space.goods:create_index('primary', { parts = { 'id' }, sequence = 'goods_id', unique = true, type = 'HASH', if_not_exists = true })
Tarantool prend en charge plusieurs types d'index. Le plus souvent, des index des types TREE et HASH sont utilisés, qui sont basés sur les structures correspondant au nom. TREE est le type d'index le plus polyvalent. Il vous permet de récupérer des données de manière ordonnée. Mais pour le choix de l'égalité, HASH est plus adapté. En conséquence, il est conseillé d'utiliser HASH pour la clé primaire (ce que nous avons fait).
Pour utiliser la colonne
row_ver pour transmettre des données modifiées, vous devez lier les valeurs de séquence
row_ver aux champs de cette colonne. Mais contrairement à la clé primaire, la valeur du champ dans la colonne
row_ver doit augmenter d'une
row_ver , non seulement lors de l'ajout de nouveaux enregistrements, mais également lors de la modification des enregistrements existants. Pour ce faire, vous pouvez utiliser des déclencheurs. Tarantool a deux types de déclencheurs pour les espaces:
before_replace et
on_replace . Les déclencheurs sont déclenchés chaque fois que les données de l'espace sont modifiées (pour chaque tuple affecté par les modifications, la fonction de déclenchement est déclenchée). Contrairement à
on_replace , les déclencheurs
before_replace vous permettent de modifier les données du tuple pour lequel le déclencheur est exécuté. En conséquence, le dernier type de déclencheurs nous convient.
box.space.goods:before_replace(function(old, new) return box.tuple.new({new[1], new[2], new[3], box.sequence.row_version:next()}) end)
Ce déclencheur remplace la valeur du champ
row_ver du tuple stocké par la
row_version séquence
row_version suivante.
Afin de pouvoir extraire des données de l'espace
goods sur la colonne
row_ver , créez un index:
box.space.goods:create_index('row_ver', { parts = { 'row_ver' }, unique = true, type = 'TREE', if_not_exists = true })
Le type d'index est un arbre (
TREE ), car nous devons récupérer les données dans l'ordre croissant des valeurs dans la colonne
row_ver .
Ajoutez des données à l'espace:
box.space.goods:insert{nil, 'pen', 123} box.space.goods:insert{nil, 'pencil', 321} box.space.goods:insert{nil, 'brush', 100} box.space.goods:insert{nil, 'watercolour', 456} box.space.goods:insert{nil, 'album', 101} box.space.goods:insert{nil, 'notebook', 800} box.space.goods:insert{nil, 'rubber', 531} box.space.goods:insert{nil, 'ruler', 135}
Parce que le premier champ est un compteur d'incrémentation automatique, nous passons nil à la place. Tarantool remplacera automatiquement la valeur suivante. De même, vous pouvez passer nil comme valeur des champs dans la colonne
row_ver - ou ne pas spécifier la valeur du tout, car cette colonne prend la dernière position dans l'espace.
Vérifiez le résultat de l'insert:
tarantool> box.space.goods:select()
Comme vous pouvez le voir, le premier et le dernier champ ont été remplis automatiquement. Maintenant, il sera facile d'écrire une fonction pour paginer le déchargement des
goods :
local page_size = 5 local function get_goods(row_ver) local index = box.space.goods.index.row_ver local goods = {} local counter = 0 for _, tuple in index:pairs(row_ver, { iterator = 'GT' }) do local obj = tuple:tomap({ names_only = true }) table.insert(goods, obj) counter = counter + 1 if counter >= page_size then break end end return goods end
La fonction prend en paramètre la valeur
row_ver du dernier enregistrement reçu (0 pour le premier appel) et renvoie le prochain lot de données modifiées (s'il y en a un, sinon un tableau vide).
La récupération des données dans Tarantool se fait via des index. La fonction
get_goods utilise l'
row_ver index
row_ver pour récupérer les données modifiées. Le type d'itérateur est GT (supérieur à, supérieur à). Cela signifie que l'itérateur parcourra séquentiellement les valeurs d'index à partir de la valeur suivante après la clé transmise.
L'itérateur renvoie les tuples. Afin de pouvoir ultérieurement transférer des données via HTTP, il est nécessaire de convertir les tuples en une structure pratique pour une sérialisation ultérieure. Dans l'exemple, la fonction
tomap standard est utilisée pour cela. Au lieu d'utiliser
tomap vous pouvez écrire votre propre fonction. Par exemple, nous pourrions vouloir renommer le champ de
name , ne pas passer le champ de
code et ajouter le champ de
comment :
local function unflatten_goods(tuple) local obj = {} obj.id = tuple.id obj.goods_name = tuple.name obj.comment = 'some comment' obj.row_ver = tuple.row_ver return obj end
La taille de page des données de sortie (le nombre d'enregistrements dans une partie) est déterminée par la variable
page_size . Dans l'exemple, la valeur de
page_size est 5. Dans un programme réel, la taille de la page est généralement plus importante. Cela dépend de la taille moyenne du tuple spatial. La taille de page optimale peut être sélectionnée empiriquement en mesurant le temps de transfert des données. Plus la page est grande, plus le nombre d'allers-retours entre les côtés émetteur et récepteur est faible. Vous pouvez donc réduire le temps total de téléchargement des modifications. Cependant, si la taille de la page est trop grande, nous prendrons trop de temps au serveur pour sérialiser la sélection. Par conséquent, il peut y avoir des retards dans le traitement des autres demandes qui sont parvenues au serveur. Le paramètre
page_size peut être chargé à partir du fichier de configuration. Pour chaque espace transmis, vous pouvez définir votre propre valeur. Cependant, pour la plupart des espaces, la valeur par défaut (par exemple, 100) peut convenir.
get_goods fonction
get_goods dans le module. Créez un fichier repl.lua contenant la description de la variable
page_size et la fonction
get_goods . À la fin du fichier, ajoutez la fonction d'exportation:
return { get_goods = get_goods }
Pour charger le module, exécutez:
tarantool> repl = require('repl')
get_goods fonction
get_goods :
tarantool> repl.get_goods(0)
Prenez la valeur du champ
row_ver de la dernière ligne et appelez à nouveau la fonction:
tarantool> repl.get_goods(5)
Et encore:
tarantool> repl.get_goods(8)
Comme vous pouvez le voir, avec cette utilisation, la fonction page par page renvoie tous les enregistrements de l'espace
goods . La dernière page est suivie d'une sélection vide.
Nous apporterons des modifications à l'espace:
box.space.goods:update(4, {{'=', 6, 'copybook'}}) box.space.goods:insert{nil, 'clip', 234} box.space.goods:insert{nil, 'folder', 432}
Nous avons modifié la valeur du champ de
name pour un enregistrement et ajouté deux nouveaux enregistrements.
Répétez le dernier appel de fonction:
tarantool> repl.get_goods(8)
La fonction a renvoyé les enregistrements modifiés et ajoutés. Ainsi, la fonction
get_goods permet d'obtenir des données qui ont changé depuis son dernier appel, qui est la base de la méthode de réplication considérée.
Nous laissons la sortie des résultats via HTTP sous forme de JSON au-delà de la portée de cet article. Vous pouvez en lire plus ici:
https://habr.com/ru/company/mailru/blog/272141/Réalisation de la partie client / esclave
Considérez à quoi ressemble la mise en œuvre du côté récepteur. Créez un espace côté réception pour stocker les données téléchargées:
box.schema.space.create('goods', { format = { { name = 'id', type = 'unsigned' }, { name = 'name', type = 'string' }, { name = 'code', type = 'unsigned' } }, if_not_exists = true }) box.space.goods:create_index('primary', { parts = { 'id' }, sequence = 'goods_id', unique = true, type = 'HASH', if_not_exists = true })
La structure de l'espace ressemble à la structure de l'espace dans la source. Mais comme nous
row_ver pas transférer les données reçues ailleurs, la colonne
row_ver est
row_ver dans l'espace du récepteur. Dans le champ
id seront inscrits les identifiants de la source. Par conséquent, côté récepteur, il n'est pas nécessaire de l'incrémenter automatiquement.
De plus, nous avons besoin d'un espace pour enregistrer les valeurs
row_ver :
box.schema.space.create('row_ver', { format = { { name = 'space_name', type = 'string' }, { name = 'value', type = 'string' } }, if_not_exists = true }) box.space.row_ver:create_index('primary', { parts = { 'space_name' }, unique = true, type = 'HASH', if_not_exists = true })
Pour chaque espace chargé (champ
space_name ), nous enregistrerons ici la dernière valeur chargée
row_ver (
value champ). La clé primaire est la colonne
space_name .
Créons une fonction pour charger les données de l'espace
goods via HTTP. Pour ce faire, nous avons besoin d'une bibliothèque qui implémente un client HTTP. La ligne suivante charge la bibliothèque et instancie le client HTTP:
local http_client = require('http.client').new()
Nous avons également besoin d'une bibliothèque pour la désérialisation json:
local json = require('json')
Cela suffit pour créer une fonction de chargement des données:
local function load_data(url, row_ver) local url = ('%s?rowVer=%s'):format(url, tostring(row_ver)) local body = nil local data = http_client:request('GET', url, body, { keepalive_idle = 1, keepalive_interval = 1 }) return json.decode(data.body) end
La fonction exécute une requête HTTP à l'URL, lui transmet
row_ver comme paramètre et renvoie le résultat désérialisé de la requête.
La fonction de sauvegarde des données reçues est la suivante:
local function save_goods(goods) local n = #goods box.atomic(function() for i = 1, n do local obj = goods[i] box.space.goods:put( obj.id, obj.name, obj.code) end end) end
Le cycle de stockage des données dans l'espace
goods est placé dans une transaction (la fonction
box.atomic est utilisée pour cela) afin de réduire le nombre d'opérations sur disque.
Enfin, la fonction de synchronisation des
goods spatiaux locaux avec la source peut être implémentée comme suit:
local function sync_goods() local tuple = box.space.row_ver:get('goods') local row_ver = tuple and tuple.value or 0
Tout d'abord, nous lisons la valeur
row_ver précédemment enregistrée pour l'espace des
goods . S'il est absent (la première session d'échange), alors nous prenons zéro comme
row_ver . Ensuite, dans la boucle, nous paginons les données modifiées de la source vers l'URL spécifiée. À chaque itération, nous enregistrons les données reçues dans l'espace local correspondant et
row_ver jour la valeur
row_ver (dans l'
row_ver row_ver et dans la variable
row_ver ) - nous prenons la valeur
row_ver de la dernière ligne des données chargées.
Pour se protéger contre les boucles accidentelles (en cas d'erreur dans le programme), la
while peut être remplacée par
for :
for _ = 1, max_req do ...
Grâce à la fonction
sync_goods , les
goods dans le récepteur contiendront les dernières versions de tous les enregistrements d'espace
goods dans la source.
De toute évidence, la suppression des données ne peut pas être diffusée de cette manière. Si un tel besoin existe, vous pouvez utiliser la marque de suppression. Ajoutez le champ booléen
is_deleted espace des
goods et utilisez la suppression logique au lieu de supprimer physiquement l'enregistrement - définissez la valeur du champ
is_deleted sur
true . Parfois, au lieu du champ booléen
is_deleted ,
is_deleted plus pratique d'utiliser le champ
deleted , qui stocke la date-heure de la suppression logique de l'enregistrement. Après avoir effectué une suppression logique, l'enregistrement marqué pour suppression sera transféré de la source au récepteur (selon la logique décrite ci-dessus).
La séquence
row_ver peut être utilisée pour transférer des données depuis d'autres espaces: il n'est pas nécessaire de créer une séquence distincte pour chaque espace transmis.
Nous avons examiné un moyen efficace de réplication de données de haut niveau dans les applications utilisant le SGBD Tarantool.
Conclusions
- Tarantool DBMS est un produit attrayant et prometteur pour la création d'applications très chargées.
- La réplication de haut niveau offre une approche plus flexible du transfert de données par rapport à la réplication de bas niveau.
- La méthode de réplication de haut niveau envisagée dans l'article permet de minimiser la quantité de données transmises en transférant uniquement les enregistrements qui ont changé depuis la dernière session d'échange.