Les applications Web sont désormais largement utilisées et HTTP est la part du lion de tous les protocoles de transport. En étudiant les nuances du développement d'applications Web, la plupart d'entre elles accordent très peu d'attention au système d'exploitation sur lequel ces applications s'exécutent. La séparation du développement (Dev) et de l'exploitation (Ops) n'a fait qu'empirer les choses. Mais avec la propagation de la culture DevOps, les développeurs commencent à assumer la responsabilité du lancement de leurs applications dans le cloud, il est donc très utile pour eux de se familiariser avec le backend du système d'exploitation. Cela est particulièrement utile si vous essayez de déployer un système pour des milliers ou des dizaines de milliers de connexions simultanées.
Les limitations des services Web sont très similaires à celles des autres applications. Qu'il s'agisse d'équilibreurs de charge ou de serveurs de bases de données, toutes ces applications ont des problèmes similaires dans un environnement hautes performances. Comprendre ces limitations fondamentales et comment les surmonter en général vous aidera à évaluer les performances et l'évolutivité de vos applications Web.
J'écris cette série d'articles en réponse aux questions de jeunes développeurs qui souhaitent devenir des architectes système bien informés. Il est impossible de comprendre clairement les méthodes d'optimisation des applications Linux sans plonger dans les bases de leur fonctionnement au niveau du système d'exploitation. Bien qu'il existe de nombreux types d'applications, dans cette série, je souhaite explorer les applications réseau, pas celles de bureau telles qu'un navigateur ou un éditeur de texte. Ce matériel est destiné aux développeurs et architectes qui souhaitent comprendre comment fonctionnent les programmes Linux ou Unix et comment les structurer pour des performances élevées.
Linux est un système d'exploitation
serveur , et le plus souvent, vos applications s'exécutent sur ce système d'exploitation particulier. Bien que je dise «Linux», la plupart du temps, vous pouvez supposer en toute sécurité que tous les systèmes d'exploitation de type Unix sont destinés. Cependant, je n'ai pas testé le code d'accompagnement sur d'autres systèmes. Donc, si vous êtes intéressé par FreeBSD ou OpenBSD, le résultat peut varier. Lorsque j'essaie quelque chose de spécifique à Linux, je le signale.
Bien que vous puissiez utiliser ces connaissances pour créer une application à partir de zéro, et qu'elle sera parfaitement optimisée, il vaut mieux ne pas le faire. Si vous écrivez un nouveau serveur Web en C ou C ++ pour l'application métier de votre organisation, cela peut être votre dernier jour de travail. Cependant, la connaissance de la structure de ces applications aidera à sélectionner les programmes existants. Vous pouvez comparer des systèmes basés sur des processus avec des systèmes basés sur des threads et des événements. Vous comprendrez et comprendrez pourquoi Nginx fonctionne mieux que Apache httpd, pourquoi une application Python basée sur Tornado peut servir plus d'utilisateurs qu'une application Python basée sur Django.
ZeroHTTPd: outil d'apprentissage
ZeroHTTPd est un serveur Web que j'ai écrit à partir de zéro en C comme outil de formation. Il n'a pas de dépendances externes, y compris l'accès à Redis. Nous exécutons nos propres routines Redis. Voir ci-dessous pour plus de détails.
Bien que nous puissions discuter de la théorie pendant longtemps, il n'y a rien de mieux que d'écrire du code, de l'exécuter et de comparer toutes les architectures de serveurs. C'est la méthode la plus évidente. Par conséquent, nous allons écrire un simple serveur Web ZeroHTTPd en utilisant chaque modèle: basé sur les processus, les threads et les événements. Vérifions chacun de ces serveurs et voyons comment ils fonctionnent par rapport aux autres. ZeroHTTPd est implémenté dans un seul fichier C. Le serveur basé sur les
événements comprend
uthash , une excellente implémentation de table de hachage
livrée dans un seul fichier d'en-tête. Dans d'autres cas, il n'y a pas de dépendances, afin de ne pas compliquer le projet.
Il y a beaucoup de commentaires dans le code pour aider à le trier. Étant un simple serveur Web en quelques lignes de code, ZeroHTTPd est également un cadre de développement Web minimal. Il a des fonctionnalités limitées, mais il est capable de produire des fichiers statiques et des pages «dynamiques» très simples. Je dois dire que ZeroHTTPd est bien adapté pour apprendre à créer des applications Linux hautes performances. Dans l'ensemble, la plupart des services Web attendent les demandes, les vérifient et les traitent. C'est exactement ce que fera ZeroHTTPd. Ceci est un outil d'apprentissage, pas un outil de production. Il n'est pas bon dans la gestion des erreurs et a peu de chances de se vanter des meilleures pratiques de sécurité (oh oui, j'ai utilisé
strcpy ) ou des tours abstrus de C. Mais j'espère qu'il fait bien son travail.
 Page d'accueil ZeroHTTPd. Il peut produire différents types de fichiers, y compris des images
Page d'accueil ZeroHTTPd. Il peut produire différents types de fichiers, y compris des imagesDemande de livre d'or
Les applications Web modernes ne sont généralement pas limitées aux fichiers statiques. Ils ont des interactions complexes avec diverses bases de données, caches, etc. Par conséquent, nous allons créer une application Web simple appelée «Livre d'or», où les visiteurs laissent des entrées sous leur nom. Le livre d'or enregistre les entrées laissées précédemment. Il y a aussi un compteur de visiteurs au bas de la page.
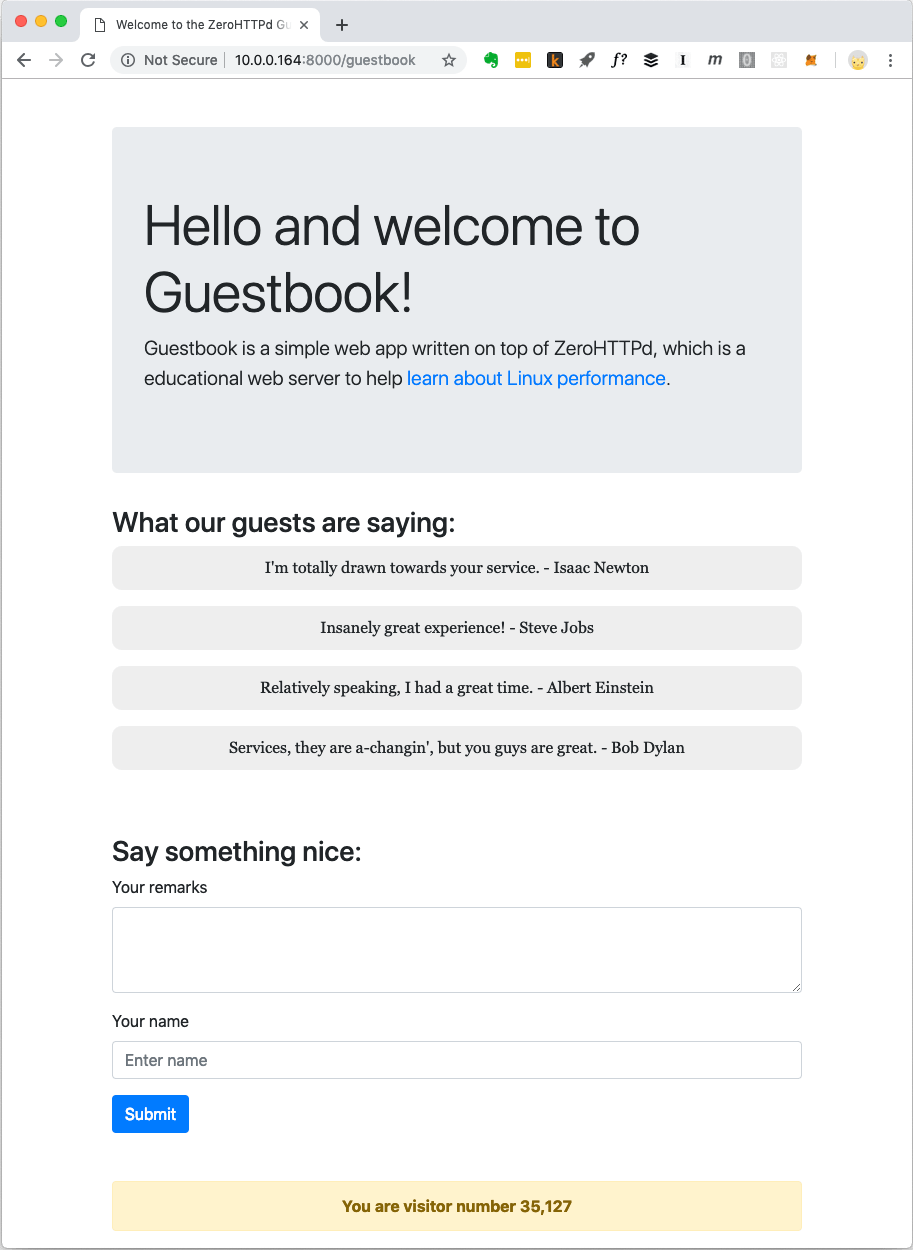 Application Web du livre d'or ZeroHTTPd
Application Web du livre d'or ZeroHTTPdLe compteur des visiteurs et les entrées du livre d'or sont stockés dans Redis. Pour la communication avec Redis, des procédures propres sont implémentées, elles sont indépendantes d'une bibliothèque externe. Je ne suis pas un grand fan du développement de code local lorsqu'il existe des solutions accessibles au public et bien testées. Mais l'objectif de ZeroHTTPd est d'étudier les performances de Linux et l'accès aux services externes, tout en servant les requêtes HTTP affecte sérieusement les performances. Nous devons contrôler entièrement les communications avec Redis dans chacune de nos architectures de serveurs. Dans une architecture, nous utilisons des appels de blocage, dans d'autres, nous utilisons des procédures basées sur des événements. L'utilisation d'une bibliothèque cliente Redis externe ne donnera pas un tel contrôle. De plus, notre petit client Redis n'effectue que quelques fonctions (obtention, définition et augmentation d'une clé; obtention et ajout à un tableau). De plus, le protocole Redis est exceptionnellement élégant et simple. Il n'a même pas besoin d'être spécialement enseigné. Le fait que le protocole effectue tout le travail en une centaine de lignes de code indique à quel point il est bien pensé.
La figure suivante montre l'application lorsque le client (navigateur) demande
/guestbookURL .
 Le mécanisme de l'application du livre d'or
Le mécanisme de l'application du livre d'orLorsque vous devez créer une page de livre d'or, il y a un appel au système de fichiers pour lire le modèle en mémoire et trois appels réseau à Redis. Le fichier modèle contient la plupart du contenu HTML de la page dans la capture d'écran ci-dessus. Il existe également des espaces réservés spéciaux pour la partie dynamique du contenu: enregistrements et compteur de visiteurs. Nous les obtenons de Redis, les insérons sur la page et donnons au client un contenu complet. Un troisième appel à Redis peut être évité car Redis renvoie une nouvelle valeur de clé lorsqu'il est incrémenté. Cependant, pour notre serveur avec une architecture basée sur des événements asynchrones, de nombreux appels réseau sont un bon test à des fins de formation. Ainsi, nous rejetons la valeur de retour de Redis sur le nombre de visiteurs et la demandons dans un appel séparé.
Architectures de serveurs ZeroHTTPd
Nous construisons sept versions de ZeroHTTPd avec les mêmes fonctionnalités mais des architectures différentes:
- Itératif
- Serveur Fork (un processus enfant par demande)
- Serveur de pré-fork (processus de pré-bifurcation)
- Serveur avec threads (un thread par demande)
- Serveur avec pré-threading
- Architecture basée sur
poll()
- Architecture d'Epoll
Nous mesurons les performances de chaque architecture en chargeant le serveur avec des requêtes HTTP. Mais lorsque l'on compare des architectures avec un haut degré de parallélisme, le nombre de requêtes augmente. Nous testons trois fois et considérons la moyenne.
Méthodologie de test
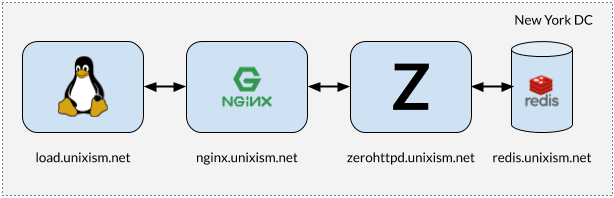 Installation pour tester les contraintes ZeroHTTPd
Installation pour tester les contraintes ZeroHTTPdIl est important que lors des tests, tous les composants ne fonctionnent pas sur la même machine. Dans ce cas, le système d'exploitation entraîne une surcharge de planification supplémentaire, car les composants sont en concurrence pour le processeur. La mesure de la surcharge du système d'exploitation de chacune des architectures de serveur sélectionnées est l'un des objectifs les plus importants de cet exercice. L'ajout de plus de variables sera préjudiciable au processus. Par conséquent, le paramètre de la figure ci-dessus fonctionne mieux.
Ce que fait chacun de ces serveurs
- load.unixism.net: ici, nous exécutons
ab , l'utilitaire Apache Benchmark. Il génère la charge nécessaire pour tester nos architectures de serveurs.
- nginx.unixism.net: parfois nous voulons exécuter plus d'une instance d'un programme serveur. Pour cela, le serveur Nginx avec les paramètres appropriés fonctionne comme un équilibreur de charge provenant de ab vers nos processus serveur.
- zerohttpd.unixism.net: nous exécutons ici nos programmes serveurs sur sept architectures différentes, une à la fois.
- redis.unixism.net: le démon Redis s'exécute sur ce serveur, où les entrées sont stockées dans le livre d'or et le compteur des visiteurs.
Tous les serveurs fonctionnent sur un seul cœur de processeur. L'idée est d'évaluer les performances maximales de chaque architecture. Étant donné que tous les programmes de serveur sont testés sur le même matériel, il s'agit du niveau de base pour les comparer. Ma configuration de test se compose de serveurs virtuels loués à Digital Ocean.
Que mesurons-nous?
Vous pouvez mesurer différents indicateurs. Nous évaluons les performances de chaque architecture dans cette configuration, en chargeant les serveurs avec des requêtes à différents niveaux de simultanéité: la charge passe de 20 à 15 000 utilisateurs simultanés.
Résultats des tests
Le diagramme suivant montre les performances des serveurs sur différentes architectures à différents niveaux de concurrence. L'axe des y est le nombre de requêtes par seconde, l'axe des x est les connexions parallèles.
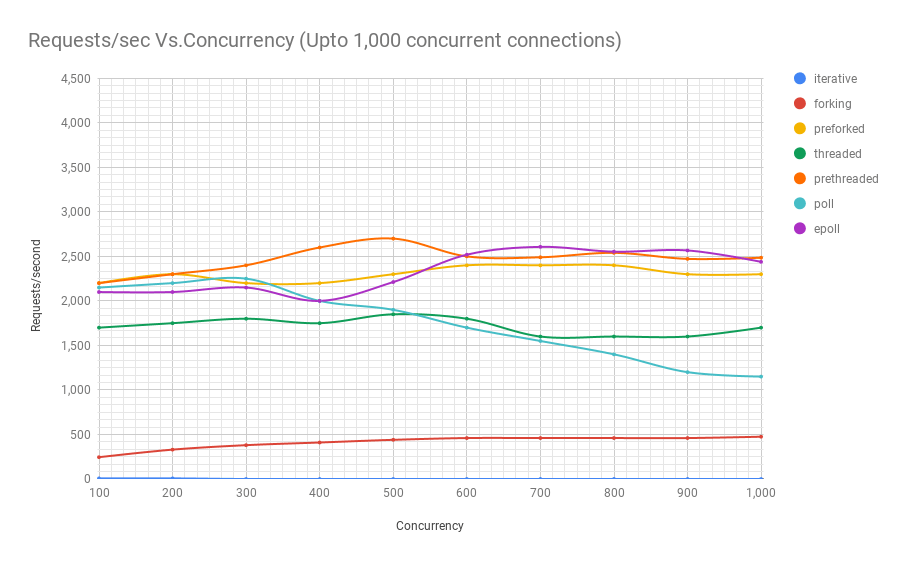
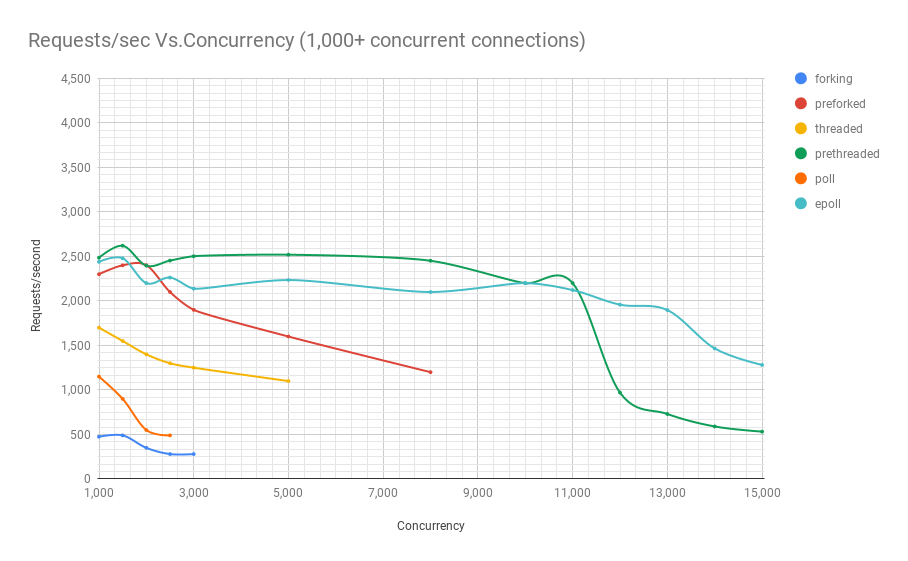
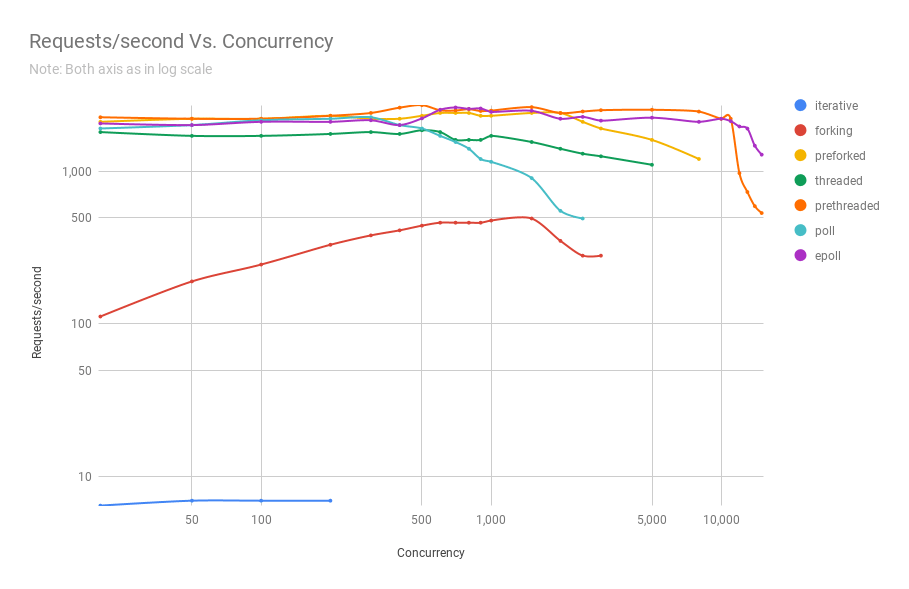
Voici un tableau avec les résultats.
Il ressort du graphique et du tableau qu'au-dessus de 8 000 demandes simultanées, il ne nous reste que deux joueurs: pre-fork et epoll. Au fur et à mesure que la charge augmente, le serveur basé sur les sondages fonctionne moins bien que le streaming. L'architecture de pré-threading est en concurrence avec epoll: cela prouve à quel point le noyau Linux planifie un grand nombre de threads.
Code source ZeroHTTPd
Le code source de ZeroHTTPd est
ici . Chaque architecture a un répertoire distinct.
ZeroHTTPd
│
├── 01_iterative
│ ├── main.c
├── 02_forking
│ ├── main.c
├── 03_preforking
│ ├── main.c
├── 04_threading
│ ├── main.c
├── 05_prethreading
│ ├── main.c
├── 06_poll
│ ├── main.c
├── 07_epoll
│ └── main.c
├── Makefile
├── public
│ ├── index.html
│ └── tux.png
└── modèles
└── livre d'or
└── index.html En plus de sept répertoires pour toutes les architectures, il y en a deux autres dans le répertoire de niveau supérieur: public et modèles. Le premier contient le fichier index.html et l'image de la première capture d'écran. D'autres fichiers et dossiers peuvent y être placés et ZeroHTTPd devrait émettre ces fichiers statiques sans problème. Si le chemin d'accès dans le navigateur correspond au chemin d'accès dans le dossier public, ZeroHTTPd recherche le fichier index.html dans ce répertoire. Le contenu du livre d'or est généré dynamiquement. Il n'a que la page principale et son contenu est basé sur le fichier 'templates / guestbook / index.html'. ZeroHTTPd ajoute facilement des pages dynamiques pour l'expansion. L'idée est que les utilisateurs peuvent ajouter des modèles à ce répertoire et étendre ZeroHTTPd selon les besoins.
Pour créer les sept serveurs, exécutez
make all partir du répertoire de niveau supérieur - et toutes les versions apparaîtront dans ce répertoire. Les exécutables recherchent les répertoires public et templates dans le répertoire d'où ils s'exécutent.
API Linux
Pour comprendre les informations de cette série d'articles, il n'est pas nécessaire de bien connaître l'API Linux. Cependant, je recommande de lire plus sur ce sujet, il existe de nombreuses ressources de référence sur le Web. Bien que nous couvrirons plusieurs catégories d'API Linux, nous nous concentrerons principalement sur les processus, les threads, les événements et la pile réseau. En plus des livres et des articles sur l'API Linux, je recommande également de lire le mana pour les appels système et les fonctions de bibliothèque utilisées.
Performance et évolutivité
Une note sur les performances et l'évolutivité. Théoriquement, il n'y a aucun lien entre eux. Vous disposez peut-être d'un service Web qui fonctionne très bien, avec un temps de réponse de quelques millisecondes, mais il n'est pas du tout évolutif. De même, il peut y avoir une application Web mal exécutée qui prend quelques secondes pour répondre, mais elle évolue à des dizaines pour gérer des dizaines de milliers d'utilisateurs simultanés. Cependant, la combinaison de hautes performances et d'évolutivité est une combinaison très puissante. Les applications hautes performances utilisent généralement les ressources de manière économique et servent ainsi efficacement plus d'utilisateurs simultanés sur le serveur, ce qui réduit les coûts.
Tâches CPU et E / S
Enfin, il existe toujours deux types de tâches possibles en informatique: pour les E / S et le CPU. La réception de requêtes via Internet (E / S réseau), la maintenance des fichiers (E / S réseau et disque), la communication avec la base de données (E / S réseau et disque) sont toutes des actions d'E / S. Certaines requêtes de base de données peuvent charger un peu le CPU (tri, calcul de la moyenne d'un million de résultats, etc.). La plupart des applications Web sont limitées par le nombre maximal d'E / S possibles, et le processeur est rarement utilisé à pleine capacité. Lorsque vous voyez que certains processeurs utilisent beaucoup de processeurs, c'est probablement un signe de mauvaise architecture d'application. Cela peut signifier que les ressources CPU sont dépensées pour le contrôle de processus et la commutation de contexte - et ce n'est pas entièrement utile. Si vous faites quelque chose comme le traitement d'image, la conversion audio ou l'apprentissage automatique, l'application nécessite de puissantes ressources CPU. Mais pour la plupart des applications, ce n'est pas le cas.
En savoir plus sur les architectures de serveurs
- Partie I. Architecture itérative
- Partie II Serveurs Fork
- Partie III. Serveurs pré-fork
- Partie IV Serveurs avec threads
- Partie V. Serveurs avec pré-création de threads
- Partie VI. Architecture basée sur les sondages
- Partie VII. Architecture d'Epoll