HighLoad ++ existe depuis longtemps et nous parlons de travailler régulièrement avec PostgreSQL. Mais les développeurs ont toujours les mêmes problèmes de mois en mois, d'année en année. Lorsque dans les petites entreprises sans DBA dans l'État, il y a des erreurs dans le travail avec les bases de données, cela n'est pas surprenant. Les grandes entreprises ont également besoin de bases de données et même avec des processus débogués, des erreurs se produisent toujours et les bases de données tombent. Peu importe la taille de l'entreprise - des erreurs se produisent toujours, des bases de données se bloquent périodiquement, se bloquent.

Bien sûr, cela ne vous arrivera jamais, mais vérifier la liste de contrôle n'est pas difficile, et il peut être très décent de sauver les nerfs futurs. Sous le chat, nous allons répertorier les principales erreurs typiques que les développeurs commettent lorsqu'ils travaillent avec PostgreSQL, voir pourquoi nous n'avons pas besoin de le faire et découvrir comment.
À propos de l'orateur: Alexey Lesovsky a commencé en tant qu'administrateur système Linux. Des tâches de virtualisation et de surveillance des systèmes sont progressivement venues à PostgreSQL. Maintenant PostgreSQL DBA dans
Data Egret , une société de conseil qui travaille avec de nombreux projets différents et voit de nombreux exemples de problèmes récurrents. Ceci est un
lien vers la présentation du rapport à HighLoad ++ 2018.
D'où viennent les problèmes
Pour vous échauffer, quelques histoires sur la façon dont les erreurs se produisent.
Historique 1. Caractéristiques
L'un des problèmes est de savoir quelles fonctionnalités l'entreprise utilise lorsqu'elle travaille avec PostgreSQL. Tout commence simplement: PostgreSQL, jeux de données, requêtes simples avec JOIN. Nous prenons les données, faisons SELECT - tout est simple.
Ensuite, nous commençons à utiliser les fonctionnalités supplémentaires de PostgreSQL, ajouter de nouvelles fonctions, extensions. La fonctionnalité s'agrandit. Nous connectons la réplication en streaming, le sharding. Divers utilitaires et kits de carrosserie apparaissent autour - pgbouncer, pgpool, patroni. Quelque chose comme ça.

Chaque mot-clé est la raison pour laquelle une erreur apparaît.
Historique 2. Stockage de données
La façon dont nous stockons les données est également une source d'erreurs.
Lorsque le projet est apparu pour la première fois, il contenait pas mal de données et de tableaux. De simples requêtes suffisent pour recevoir et enregistrer des données. Mais il y a de plus en plus de tableaux. Les données sont sélectionnées à différents endroits, des JOIN apparaissent. Les requêtes sont compliquées et incluent des constructions CTE, SUBQUERY, IN, LATERAL. Faire une erreur et écrire une requête courbe devient beaucoup plus facile.
Et ce n'est que la pointe de l'iceberg - quelque part sur le côté, il peut y avoir 400 autres tables, partitions, à partir desquelles des données sont également lues occasionnellement.
Histoire 3. Cycle de vie
L'histoire de la façon dont le produit est suivi. Les données doivent toujours être stockées quelque part, il y a donc toujours une base de données. Comment se développe une base de données lorsqu'un produit se développe?
D'une part, il y a des
développeurs qui sont occupés avec les langages de programmation. Ils rédigent leurs applications et développent des compétences dans le domaine du développement logiciel, sans prêter attention aux services. Souvent, ils ne sont pas intéressés par le fonctionnement de Kafka ou PostgreSQL - ils développent de nouvelles fonctionnalités dans leur application, et ils ne se soucient pas du reste.
 Admins, d'
Admins, d' autre part. Ils génèrent de nouvelles instances Amazon sur Bare-metal et sont occupés à l'automatisation: ils configurent des déploiements pour bien faire fonctionner la mise en page et configurent pour que les services interagissent bien entre eux.

Il y a une situation où il n'y a pas de temps ou de désir pour un réglage fin des composants, ainsi que de la base de données. Les bases de données fonctionnent avec des configurations par défaut, puis elles les oublient complètement - "ça marche, ne le touchez pas".
En conséquence, les râteaux sont dispersés à divers endroits, qui volent de temps en temps dans le front des développeurs. Dans cet article, nous essaierons de rassembler tous ces râteaux dans un hangar afin que vous les connaissiez et que lorsque vous travaillez avec PostgreSQL, ne les attaquez pas.
Planification et suivi
Tout d'abord, imaginez que nous avons un nouveau projet - c'est toujours un développement actif, des tests d'hypothèses et la mise en œuvre de nouvelles fonctionnalités. Au moment où l'application vient d'apparaître et se développe, elle a peu de trafic, d'utilisateurs et de clients, et elles génèrent toutes de petites quantités de données. La base de données contient des requêtes simples qui sont traitées rapidement. Pas besoin de faire glisser de grandes quantités de données, il n'y a aucun problème.
Mais il y a plus d'utilisateurs, le trafic arrive: de nouvelles données apparaissent, les bases de données se développent et les anciennes requêtes cessent de fonctionner. Il est nécessaire de compléter les index, de réécrire et d'optimiser les requêtes. Il y a des problèmes de performances. Tout cela conduit à des alertes à 4 heures du matin, au stress des administrateurs et au mécontentement de la direction.
Qu'est-ce qui ne va pas?
D'après mon expérience, le plus souvent, il n'y a pas assez de disques.
Le premier exemple . Nous ouvrons le calendrier de surveillance de l'utilisation du disque et nous constatons que l'
espace libre sur le disque est épuisé .
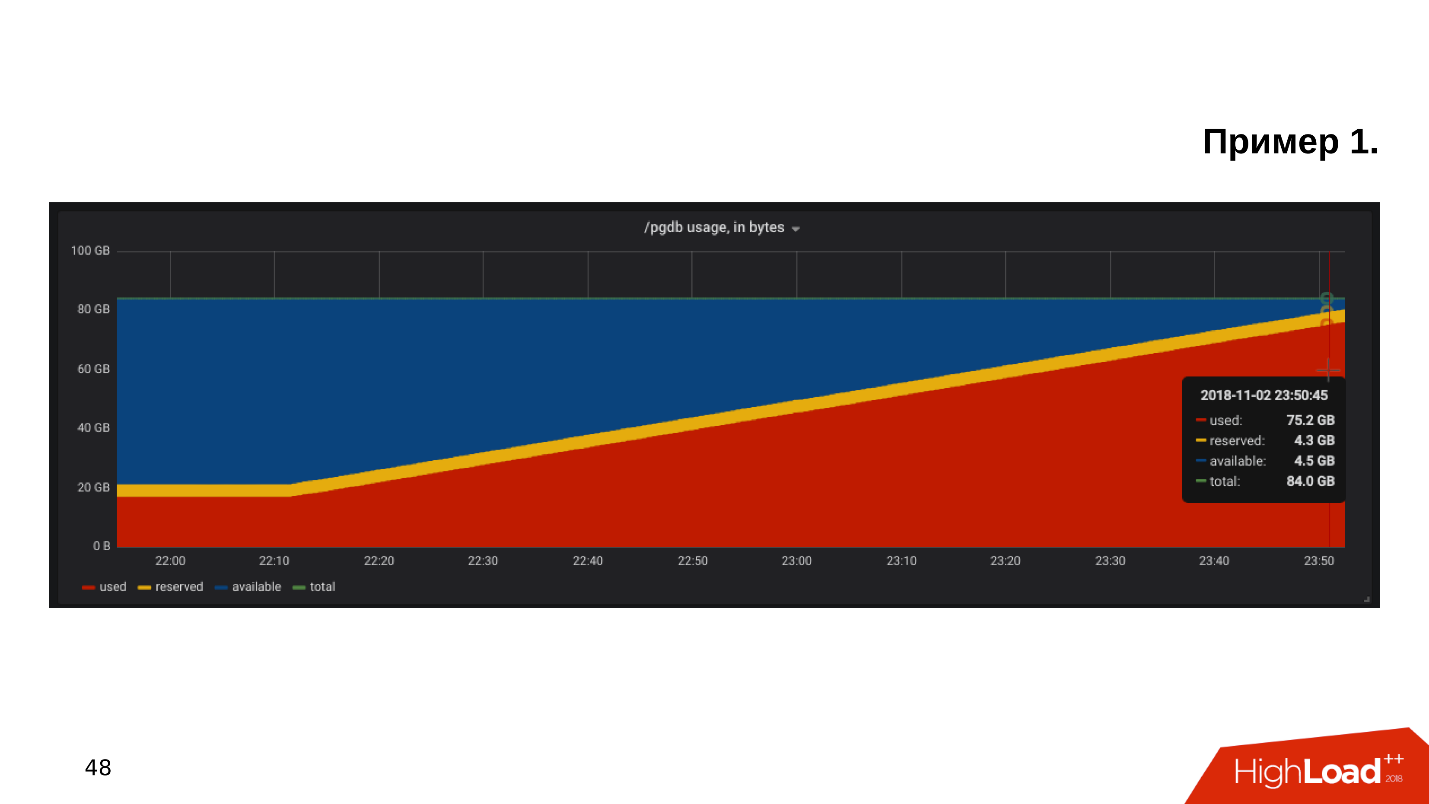
Nous regardons combien d'espace et ce qui est consommé - il s'avère qu'il existe un répertoire pg_xlog:
$ du -csh -t 100M /pgdb/9.6/main/* 15G /pgdb/9.6/main/base 58G /pgdb/9.6/main/pg_xlog 72G
Les administrateurs de base de données savent généralement ce qu'est ce répertoire, et ils n'y touchent pas - il existe et existe. Mais le développeur, surtout s'il regarde la mise en scène, se gratte la tête et pense:
- Une sorte de journaux ... Supprimons pg_xlog!Supprime le répertoire, la base de données cesse de fonctionner . Vous devez immédiatement rechercher sur Google comment augmenter la base de données après avoir supprimé les journaux de transactions.
 Deuxième exemple
Deuxième exemple . Encore une fois, nous ouvrons la surveillance et constatons qu'il n'y a pas assez d'espace. Cette fois, l'endroit est occupé par une sorte de base.
$ du -csh -t 100M /pgdb/9.6/main/* 70G /pgdb/9.6/main/base 2G /pgdb/9.6/main/pg_xlog 72G
Nous recherchons quelle base de données occupe le plus d'espace, quelles tables et quels index.

Il s'avère qu'il s'agit d'un tableau avec des journaux historiques. Nous n'avons jamais eu besoin de journaux historiques. Ils sont écrits juste au cas où, et sans le problème de l'endroit, personne ne les regarderait jusqu'à la seconde venue:
- Nettoyons tout ce qui mm ... plus ancien qu'octobre!Faites une demande de mise à jour, exécutez-la, cela fonctionnera et supprimera certaines des lignes.
=# DELETE FROM history_log -# WHERE created_at < «2018-10-01»; DELETE 165517399 Time: 585478.451 ms
La requête s'exécute pendant 10 minutes, mais la table occupe toujours la même quantité d'espace.
PostgreSQL supprime les lignes de la table - tout est correct, mais il ne renvoie pas la place au système d'exploitation. Ce comportement de PostgreSQL est inconnu de la plupart des développeurs et peut être très surprenant.
Le troisième exemple . Par exemple, ORM a fait une demande intéressante. Habituellement, tout le monde accuse ORM de faire de «mauvaises» requêtes qui lisent quelques tableaux.
Supposons qu'il existe plusieurs opérations JOIN qui lisent des tables en parallèle dans plusieurs threads. PostgreSQL peut paralléliser les opérations de données et lire les tableaux dans plusieurs threads. Mais, étant donné que nous avons plusieurs serveurs d'applications, cette requête lit toutes les tables plusieurs milliers de fois par seconde. Il s'avère que le serveur de base de données est surchargé, les disques ne peuvent pas faire face, et tout cela conduit à une erreur
502 Bad Gateway du backend - la base de données n'est pas disponible.
Mais ce n'est pas tout. Vous pouvez rappeler d'autres fonctionnalités de PostgerSQL.
- Freins des processus d'arrière-plan du SGBD - PostgreSQL a toutes sortes de points de contrôle, de vides et de réplication.
- Frais généraux de virtualisation . Lorsque la base de données s'exécute sur une machine virtuelle, sur le même morceau de fer, il y a également des machines virtuelles sur le côté, et elles peuvent entrer en conflit sur les ressources.
- Le stockage est du fabricant chinois NoName , dont les performances dépendent de la lune en Capricorne ou de la position de Saturne, et il n'y a aucun moyen de comprendre pourquoi cela fonctionne de cette façon. La base souffre.
- La configuration par défaut . C'est mon sujet préféré: le client dit que sa base de données ralentit - vous regardez, et il a une configuration par défaut. Le fait est que la configuration PostgreSQL par défaut est conçue pour fonctionner sur la théière la plus faible . La base est lancée, ça marche, mais quand ça marche déjà sur du matériel de milieu de gamme, alors cette config ne suffit pas, il faut la régler.
Le plus souvent, PostgreSQL manque d'espace disque ou de performances disque. Heureusement, avec des processeurs, de la mémoire et un réseau, en règle générale, tout est plus ou moins en ordre.
Comment être Besoin de surveillance et de planification! Cela semble évident, mais pour une raison quelconque, dans la plupart des cas, personne ne planifie une base, et la surveillance ne couvre pas tout ce qui doit être surveillé pendant le fonctionnement de PostgreSQL. Il existe un ensemble de règles claires, avec lesquelles tout fonctionnera bien, et non "au hasard".
Planification
Hébergez la base de données sur un SSD sans hésitation . Les SSD sont depuis longtemps devenus fiables, stables et productifs. Les modèles SSD d'entreprise existent depuis des années.
Planifiez toujours un schéma de données . N'écrivez pas dans la base de données que vous doutez de ce qui est nécessaire - garanti de ne pas être nécessaire. Un exemple simple est un tableau légèrement modifié d'un de nos clients.

Il s'agit d'une table de journal dans laquelle se trouve une colonne de données de type json. Relativement parlant, vous pouvez écrire n'importe quoi dans cette colonne. Le dernier enregistrement de ce tableau montre que les journaux occupent 8 Mo. PostgreSQL n'a aucun problème à stocker des enregistrements de cette longueur. PostgreSQL a un très bon stockage qui mâche de tels enregistrements.
Mais le problème est que lorsque les serveurs d'applications lisent les données de cette table, ils obstrueront facilement la totalité de la bande passante du réseau, et d'autres demandes en souffriront. C'est le problème de la planification d'un schéma de données.
Utilisez le partitionnement pour tout indice d'une histoire qui doit être stockée pendant plus de deux ans . Le partitionnement semble parfois compliqué - vous devez vous soucier des déclencheurs, des fonctions qui créeront des partitions. Dans les nouvelles versions de PostgreSQL, la situation est meilleure et maintenant la configuration du partitionnement est beaucoup plus simple - une fois terminée, et fonctionne.
Dans l'exemple considéré de suppression de données en 10 minutes,
DELETE peut être remplacé par
DROP TABLE - une telle opération dans des circonstances similaires ne prendra que quelques millisecondes.
Lorsque les données sont triées par partition, la partition est supprimée littéralement en quelques millisecondes et le système d'exploitation prend le relais immédiatement. La gestion des données historiques est plus facile, plus facile et plus sûre.
Suivi
La surveillance est un grand sujet distinct, mais du point de vue de la base de données, il existe des recommandations qui peuvent s'inscrire dans une section de l'article.
Par défaut, de nombreux systèmes de surveillance assurent la surveillance des processeurs, de la mémoire, du réseau, de l'espace disque, mais, en règle générale,
aucun périphérique de disque n'est disponible . Des informations sur la charge des disques, la bande passante actuellement présente sur les disques et la valeur de latence doivent toujours être ajoutées à la surveillance. Cela vous aidera à évaluer rapidement la façon dont les disques sont chargés.
Il existe de nombreuses options de surveillance PostgreSQL, il y en a pour tous les goûts. Voici quelques points qui doivent être présents.
- Clients connectés . Il est nécessaire de surveiller les statuts avec lesquels ils travaillent, de trouver rapidement les clients "nuisibles" qui endommagent la base de données et de les désactiver.
- Erreurs Il est nécessaire de surveiller les erreurs afin de contrôler le bon fonctionnement de la base de données: aucune erreur - grande, des erreurs sont apparues - une raison de regarder les journaux et de commencer à comprendre ce qui ne va pas.
- Demandes (déclarations) . Nous surveillons les caractéristiques quantitatives et qualitatives des demandes afin d'évaluer approximativement si nous avons des demandes lentes, longues ou gourmandes en ressources.
Pour plus d'informations, consultez le rapport
«PostgreSQL Monitoring Basics» avec HighLoad ++ Siberia et la page
Monitoring du PostgreSQL Wiki.
Lorsque nous avons tout planifié et que nous nous «sommes couverts» avec le suivi, nous pouvons encore rencontrer des problèmes.
Mise à l'échelle
En règle générale, le développeur voit la ligne de base de données dans la configuration. Il n'est pas particulièrement intéressé par la façon dont il est organisé en interne - comment fonctionne le point de contrôle, la réplication, le planificateur. Le développeur a déjà quelque chose à faire - à faire il y a beaucoup de choses intéressantes qu'il veut essayer.
"Donnez-moi l'adresse de la base, puis moi-même." © Développeur anonyme.
L'ignorance du sujet entraîne des conséquences assez intéressantes lorsque le développeur commence à écrire des requêtes qui fonctionnent dans cette base de données. Les fantasmes lors de l'écriture de requêtes donnent parfois des effets étonnants.
Il existe deux types de transactions.
Les transactions OLTP sont rapides, courtes et légères qui prennent des fractions de milliseconde. Ils fonctionnent très rapidement, et ils sont nombreux.
OLAP - requêtes analytiques - lentes, longues, lourdes, lisent de grands tableaux de tableaux et lisent des statistiques.
Au cours des 2-3 dernières années, l'abréviation
HTAP sonne souvent - Transaction hybride / Traitement analytique ou traitement
transactionnel-analytique hybride . Si vous n'avez pas le temps de penser à la mise à l'échelle et à la diversité des requêtes OLAP et OLTP, vous pouvez dire: «Nous avons HTAP!» Mais l'expérience et la douleur des erreurs montrent qu'après tout, différents types de requêtes doivent vivre séparément les uns des autres, car les longues requêtes OLAP bloquent les requêtes OLTP légères.
Nous arrivons donc à la question de savoir comment faire évoluer PostgreSQL afin de répartir la charge, et tout le monde était satisfait.
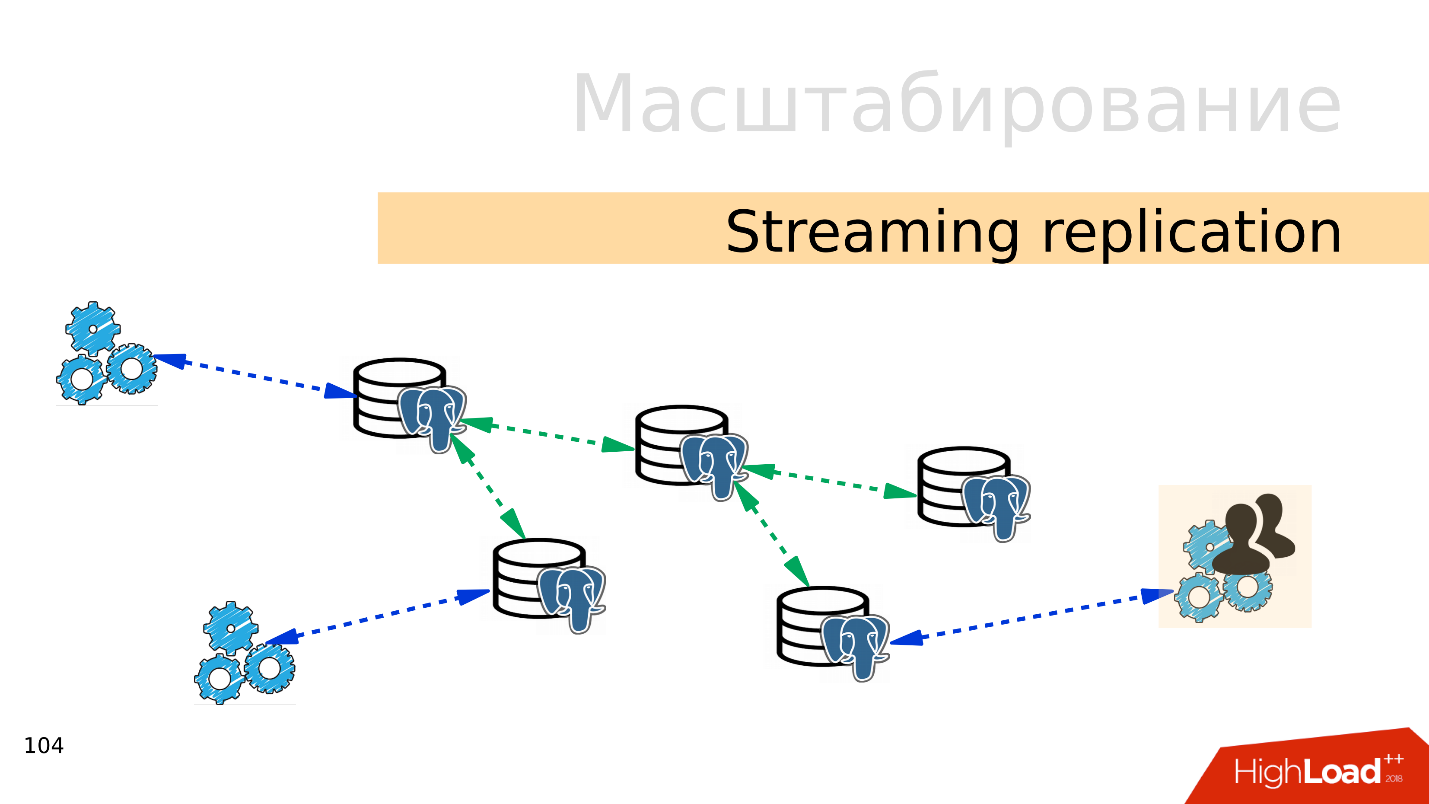
Réplication en streaming . L'option la plus simple est
la réplication en streaming . Lorsque l'application fonctionne avec la base de données, nous connectons plusieurs répliques à cette base de données et distribuons la charge. L'enregistrement va toujours à la base principale et la lecture aux répliques. Cette méthode vous permet d'évoluer très largement.
De plus, vous pouvez connecter plus de répliques à des répliques individuelles et obtenir une
réplication en cascade . Des groupes d'utilisateurs ou des applications distincts qui, par exemple, lisent des analyses, peuvent être déplacés vers une réplique distincte.
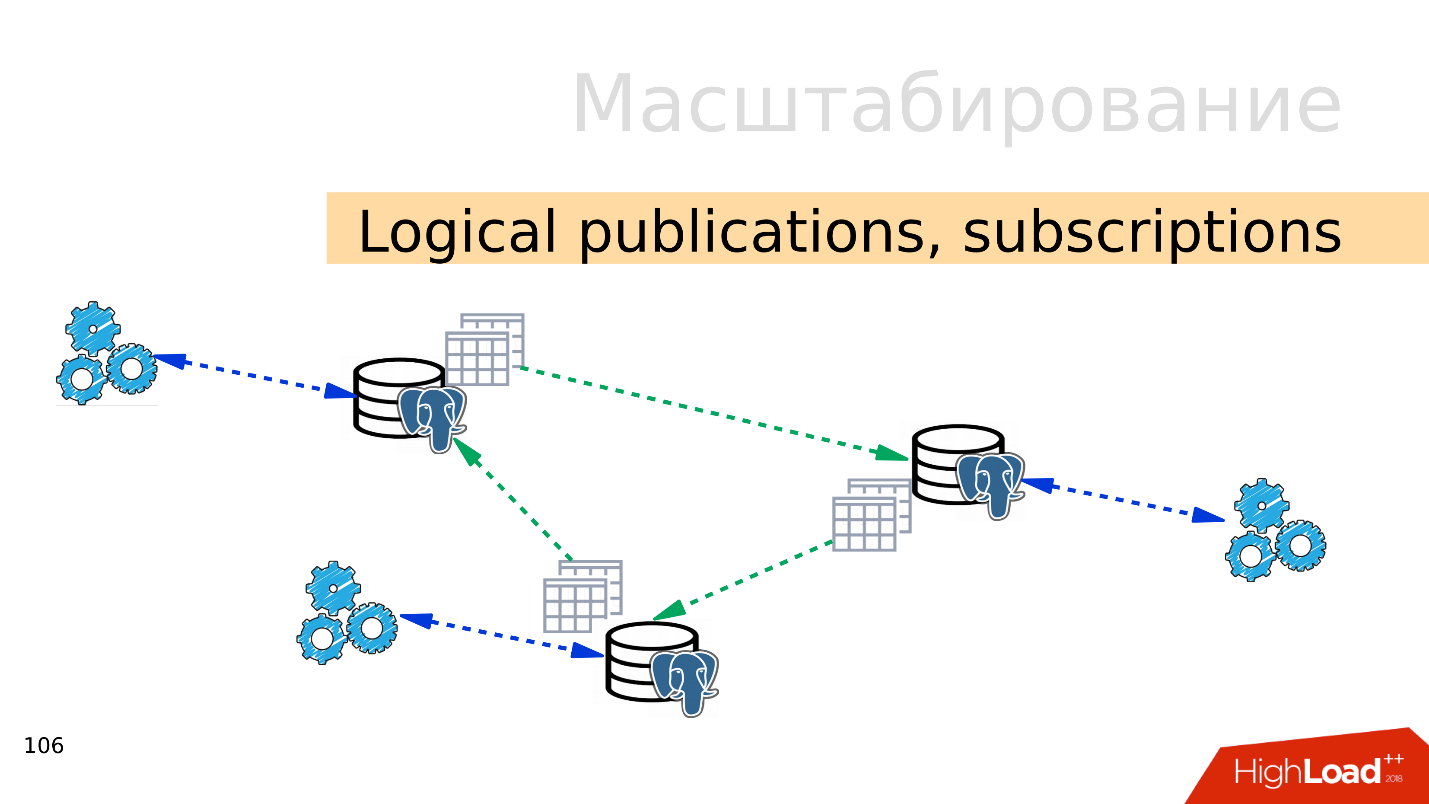
 Publications logiques, abonnements
Publications logiques, abonnements - le mécanisme des publications logiques et des abonnements implique la présence de plusieurs serveurs PostgreSQL indépendants avec des bases de données et des ensembles de tables distincts. Ces ensembles de tables peuvent être connectés aux bases de données voisines, ils seront visibles par les applications qui peuvent les utiliser normalement. Autrement dit, toutes les modifications qui se produisent dans la source sont répliquées sur la base de destination et y sont visibles. Fonctionne très bien avec PostgreSQL 10.
 Tables étrangères, partitionnement déclaratif - partitionnement déclaratif et tables externes
Tables étrangères, partitionnement déclaratif - partitionnement déclaratif et tables externes . Vous pouvez prendre plusieurs PostgreSQL et y créer plusieurs ensembles de tables qui stockeront les plages de données souhaitées. Il peut s'agir de données pour une année spécifique ou de données collectées sur n'importe quelle plage.
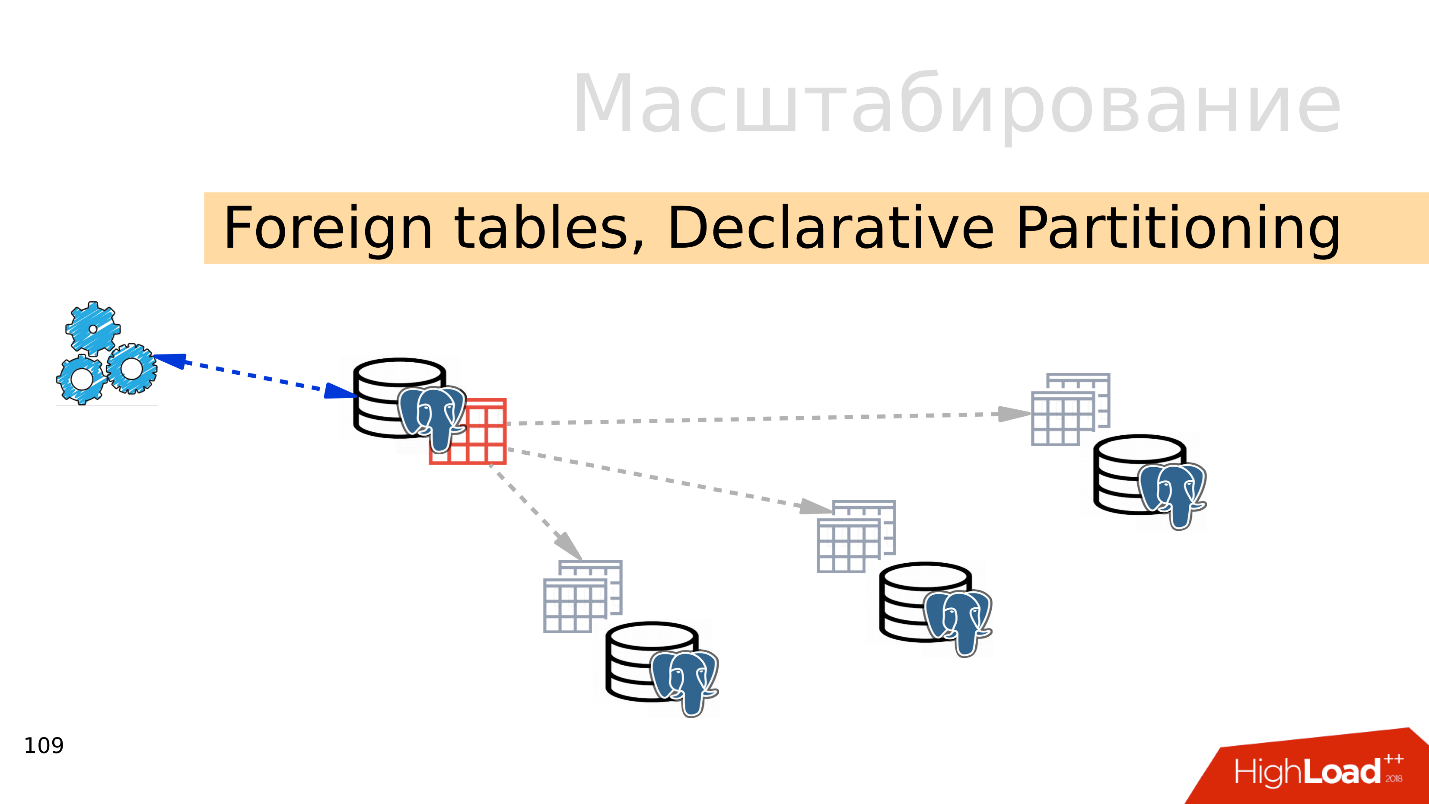
En utilisant le mécanisme des tables externes, vous pouvez combiner toutes ces bases de données sous la forme d'une table partitionnée dans un PostgreSQL séparé. Une application peut déjà fonctionner avec cette table partitionnée, mais en fait, elle lira les données des partitions distantes. Lorsque les volumes de données dépassent les capacités d'un seul serveur, il s'agit d'un partage.

Tout cela peut être combiné dans des configurations de diffusion, pour proposer différentes topologies de réplication PostgreSQL, mais comment tout cela fonctionne et comment le gérer fait l'objet d'un rapport séparé.
Par où commencer?
L'option la plus simple est la
réplication . La première étape consiste à répartir la charge de lecture et d'écriture. Autrement dit, écrivez au maître et lisez à partir de répliques. Nous adaptons donc la charge et effectuons la lecture à partir de l'assistant. De plus, n'oubliez pas les analystes. Les requêtes analytiques fonctionnent depuis longtemps, elles ont besoin d'une réplique distincte avec des paramètres distincts afin que les longues requêtes analytiques ne puissent pas interférer avec le reste.
La prochaine étape consiste à
équilibrer . Nous avons toujours la même ligne dans la configuration sur laquelle le développeur opère. Il a besoin d'un endroit où il pourra écrire et lire. Il y a plusieurs options ici.
L'idéal est d'implémenter l'équilibrage
au niveau de l'application , lorsque l'application elle-même sait où lire les données et sait comment choisir une réplique. Supposons qu'un solde de compte soit toujours nécessaire à jour et qu'il doive être lu par le maître, et que l'image du produit ou les informations le concernant puissent être lues avec un certain retard et effectuées à partir d'une réplique.
- DNS Round Robin , à mon avis, n'est pas une implémentation très pratique, car parfois cela fonctionne longtemps et ne donne pas le temps nécessaire lors du changement de rôle d'assistant entre les serveurs en cas de basculement.
- Une option plus intéressante consiste à utiliser Keepalived et HAProxy . Les adresses virtuelles pour le maître et l'ensemble de répliques sont lancées entre les serveurs HAProxy et HAProxy équilibre déjà le trafic.
- Patroni, DCS en conjonction avec quelque chose comme ZooKeeper, etcd, Consul - l'option la plus intéressante, à mon avis. Autrement dit, la découverte de service est responsable de l'information qui est le maître maintenant et qui est la réplique. Patroni gère un cluster de PostgreSQL, effectue la commutation - si la topologie a changé, ces informations apparaîtront dans la découverte de service et les applications pourront rapidement découvrir la topologie actuelle.
Et il existe des nuances avec la réplication, dont la plus courante est le
retard de réplication . Vous pouvez le faire comme GitLab, et lorsque le décalage s'accumule, laissez simplement tomber la base. Mais nous avons un suivi complet - nous l'examinons et constatons de longues transactions.
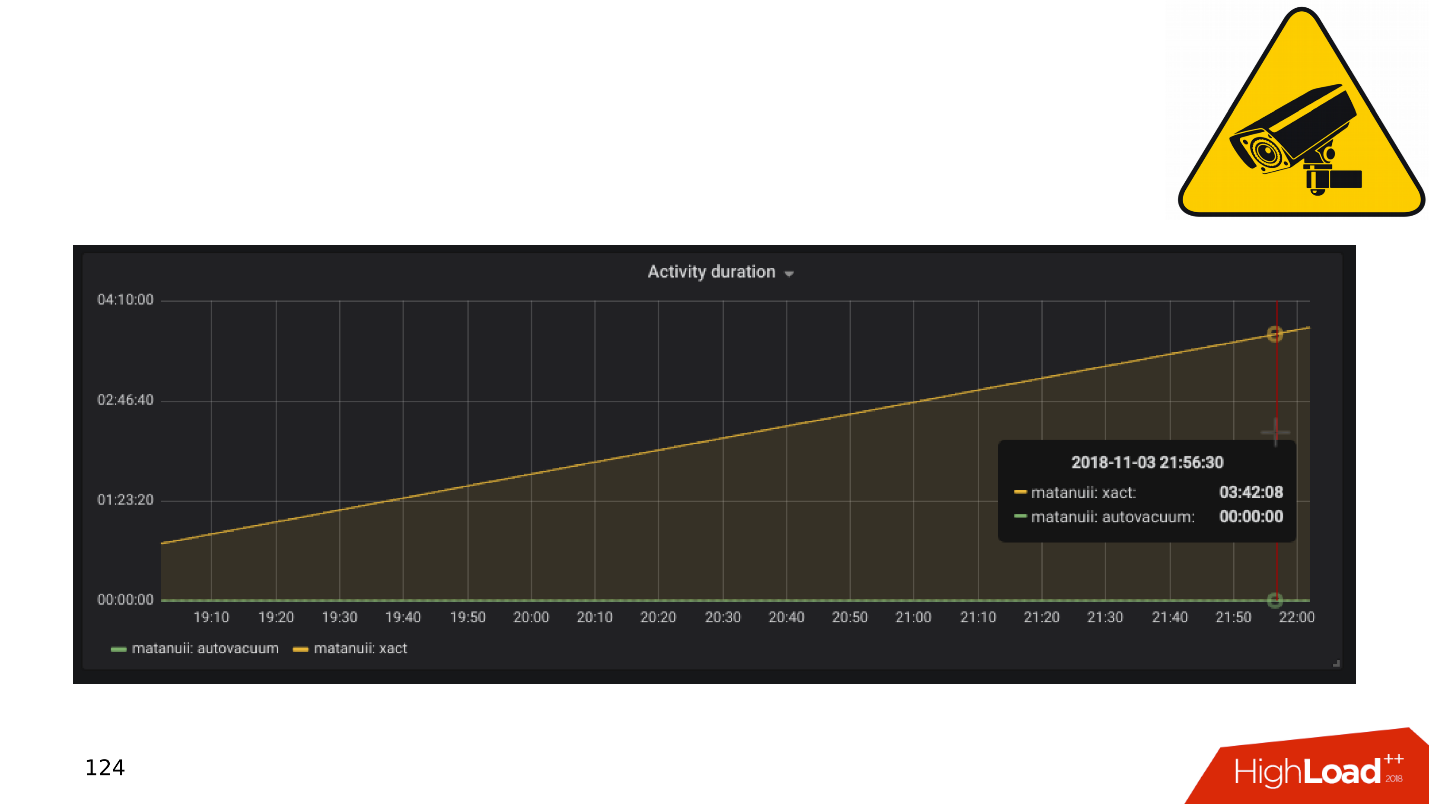
Applications et transactions SGBD
En général, les transactions lentes et inactives entraînent:
- diminution de la productivité - pas à un spasmodique pointu, mais lisse;
- verrous et blocages , car les transactions longues maintiennent des verrous sur les lignes et empêchent les autres transactions de fonctionner;
- 50 * Erreurs HTTP sur le backend , erreurs d'interface ou ailleurs.
Examinons un peu la théorie sur la façon dont ces problèmes se posent et pourquoi le mécanisme des transactions longues et inactives est nuisible.
PostgreSQL a MVCC - relativement parlant, un moteur de base de données. Il permet aux clients de travailler de manière compétitive avec les données sans interférer les uns avec les autres: les lecteurs n'interfèrent pas avec les lecteurs et les écrivains n'interfèrent pas avec les écrivains. Bien sûr, il y a quelques exceptions, mais dans ce cas, elles ne sont pas importantes.
Il s'avère que dans la base de données pour une ligne, il peut y avoir plusieurs versions pour différentes transactions. Les clients se connectent, la base de données leur donne des instantanés de données et au sein de ces instantanés, différentes versions de la même ligne peuvent exister. Par conséquent, dans le cycle de vie de la base de données, les transactions sont décalées, se remplacent mutuellement et des versions de lignes apparaissent dont personne n'a besoin.
Il y a donc un
besoin pour un collecteur d'ordures - l'aspirateur automatique . Les transactions longues existent et empêchent l'aspiration automatique de nettoyer les versions de ligne inutiles. Ces données indésirables commencent à errer de la mémoire au disque, du disque à la mémoire. Pour stocker ces déchets, les ressources CPU et mémoire sont gaspillées.
Plus la transaction est longue, plus les performances sont indésirables et moindres.
Du point de vue de "Qui est à blâmer?", L'application est à blâmer pour l'apparition de longues transactions. Si la base de données existe seule, les transactions longues et sans effet ne seront prises nulle part. En pratique, il existe les options suivantes pour l'apparition de transactions inactives.
"Allons à une source externe .
" L'application ouvre une transaction, fait quelque chose dans la base de données, puis décide de se tourner vers une source externe, par exemple Memcached ou Redis, dans l'espoir qu'elle reviendra ensuite dans la base de données, continuera à travailler et fermera la transaction. Mais si une erreur se produit dans la source externe, l'application se bloque et la transaction reste fermée jusqu'à ce que quelqu'un la remarque et la tue.
Aucune gestion d'erreur . D'un autre côté, il peut y avoir un problème de gestion des erreurs. Lorsque, à nouveau, l'application a ouvert une transaction, a résolu un problème dans la base de données, est retournée à l'exécution de code, a effectué certaines fonctions et calculs, afin de continuer à travailler dans la transaction et de la fermer. Lorsque sur ces calculs, l'application a été interrompue avec une erreur, le code est revenu au début du cycle et la transaction est à nouveau restée confidentielle.
Le facteur humain . Par exemple, l'administrateur, le développeur, l'analyste, travaille dans certains pgAdmin ou dans DBeaver - a ouvert une transaction, y fait quelque chose. Puis la personne a été distraite, elle est passée à une autre tâche, puis à la troisième, a oublié la transaction, est partie pour le week-end, et la transaction continue de se bloquer. Les performances de base en souffrent.
Voyons quoi faire dans ces cas.
- Nous avons une surveillance; en conséquence, nous avons besoin d' alertes dans la surveillance . Toute transaction qui se bloque pendant plus d'une heure et ne fait rien est une occasion de voir d'où elle vient et de comprendre ce qui ne va pas.
- L'étape suivante consiste à tirer ces transactions via la tâche dans la couronne (pg_terminate_backend (pid)) ou à configurer dans la configuration PostgreSQL. Des seuils de 10 à 30 minutes sont nécessaires, après quoi les transactions sont automatiquement terminées.
- Refactorisation d'application . Bien sûr, vous devez savoir d'où viennent les transactions inactives, pourquoi elles se produisent et éliminer ces endroits.
Évitez les transactions longues à tout prix, car elles affectent considérablement les performances de la base de données.
Tout devient encore plus intéressant lorsque des tâches en attente apparaissent, par exemple, vous devez calculer soigneusement les unités. Et nous arrivons à la question de la construction de vélos.
Construction de vélos
Sujet douloureux. Les entreprises du côté des applications doivent effectuer un traitement en arrière-plan des événements. Par exemple, pour calculer des agrégats: minimum, maximum, valeur moyenne, envoyer des notifications aux utilisateurs, émettre des factures aux clients, configurer un compte d'utilisateur après l'enregistrement ou vous inscrire dans les services voisins - effectuez un traitement différé.
L'essence de ces tâches est la même - elles sont reportées pour plus tard. Des tables apparaissent dans la base de données qui exécutent simplement les files d'attente.

Voici l'identifiant de la tâche, l'heure à laquelle la tâche a été créée, sa mise à jour, le gestionnaire qui l'a prise, le nombre de tentatives à effectuer. Si vous avez une table qui ressemble même à distance à celle-ci, vous disposez de
files d'attente auto-écrites .
Tout cela fonctionne bien jusqu'à ce que de longues transactions apparaissent. Après cela, les
tables qui fonctionnent avec les files d'attente gonflent de taille . De nouveaux travaux sont ajoutés tout le temps, les anciens sont supprimés, les mises à jour se produisent - un tableau avec un enregistrement intensif est obtenu. Il doit être nettoyé régulièrement des versions obsolètes des chaînes afin que les performances ne souffrent pas.
Le temps de traitement s'allonge - une longue transaction verrouille les versions obsolètes des rangées ou empêche l'aspirateur de les nettoyer. Lorsque la taille du tableau augmente, le temps de traitement augmente également, car vous devez lire de nombreuses pages avec des ordures. Le temps augmente et la
file d'attente cesse à un moment donné de fonctionner .
Voici un exemple du haut de l'un de nos clients, qui avait une file d'attente. Toutes les demandes sont uniquement liées à la file d'attente.

Faites attention au temps d'exécution de ces requêtes - toutes sauf une fonctionnent pendant plus de vingt secondes.
Pour résoudre ces problèmes,
Skytools PgQ , un gestionnaire de files d'attente pour PostgreSQL, a été inventé il y a longtemps. Ne réinventez pas votre vélo - prenez PgQ, installez-le une fois et oubliez les lignes.
Certes, il a également des fonctionnalités. Skytools PgQ a
peu de documentation . Après avoir lu la page officielle, on a l'impression qu'il n'a rien compris. Le sentiment grandit lorsque vous essayez de faire quelque chose. Tout fonctionne, mais
son fonctionnement n'est pas clair . Une sorte de magie Jedi. Mais beaucoup d'informations peuvent être trouvées dans les
listes de diffusion . Ce n'est pas un format très pratique, mais il y a beaucoup de choses intéressantes, et vous devrez lire ces feuilles.
Malgré les inconvénients, Skytools PgQ fonctionne sur le principe de «configurer et oublier». , , , . PgQ , . PgQ , .
, - — , . .
PgQ. , PostgreSQL, , , PgQ . , .
, . , , , - , , , . , , , alter.
auto-failover — PostgreSQL - , , . , auto-failover.
Split-brain . PostgreSQL , , — . , . PostgreSQL fencing, Kubernets . - , . Split-brain.

. GitHub Split-brain, .
Cascade failover . , . , .
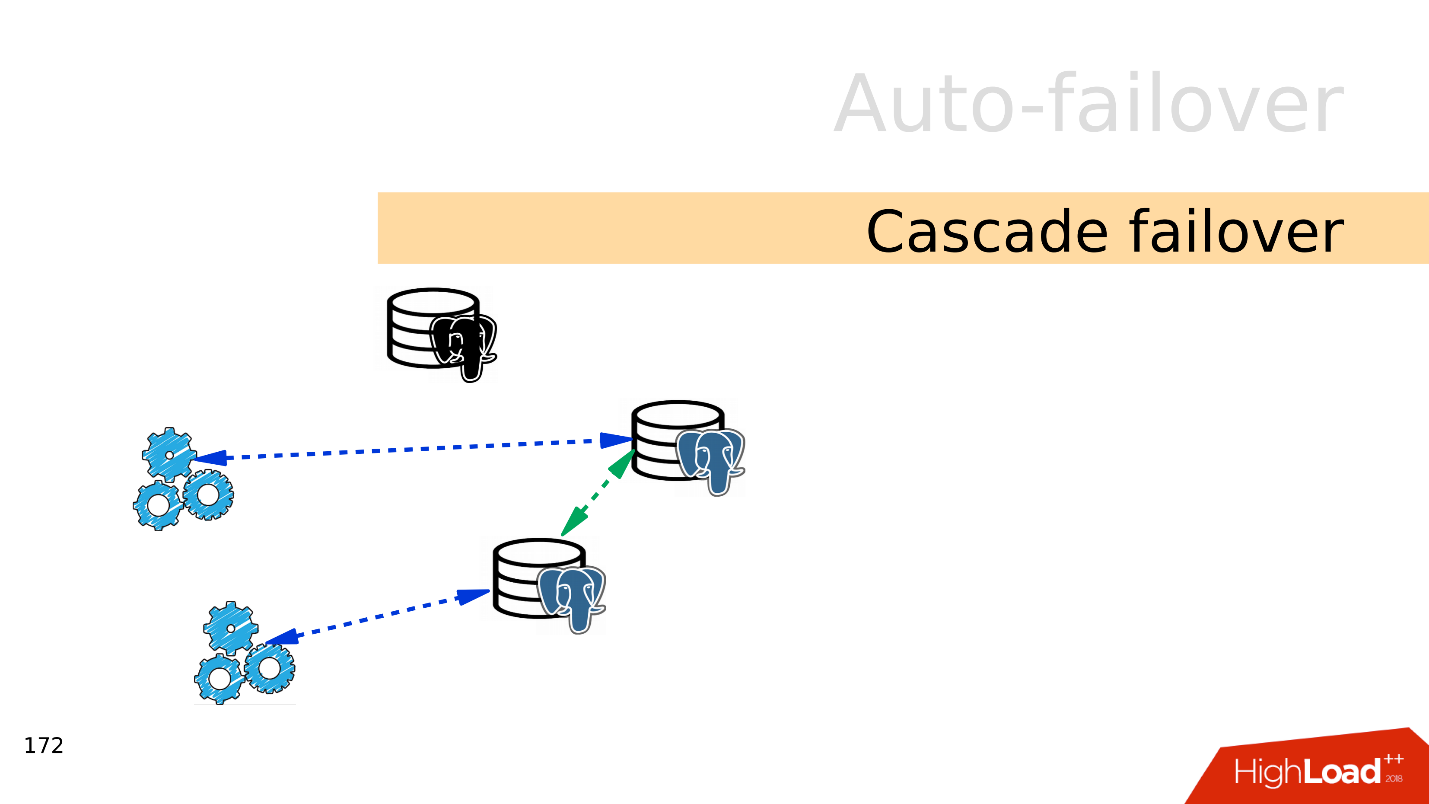
, . , .
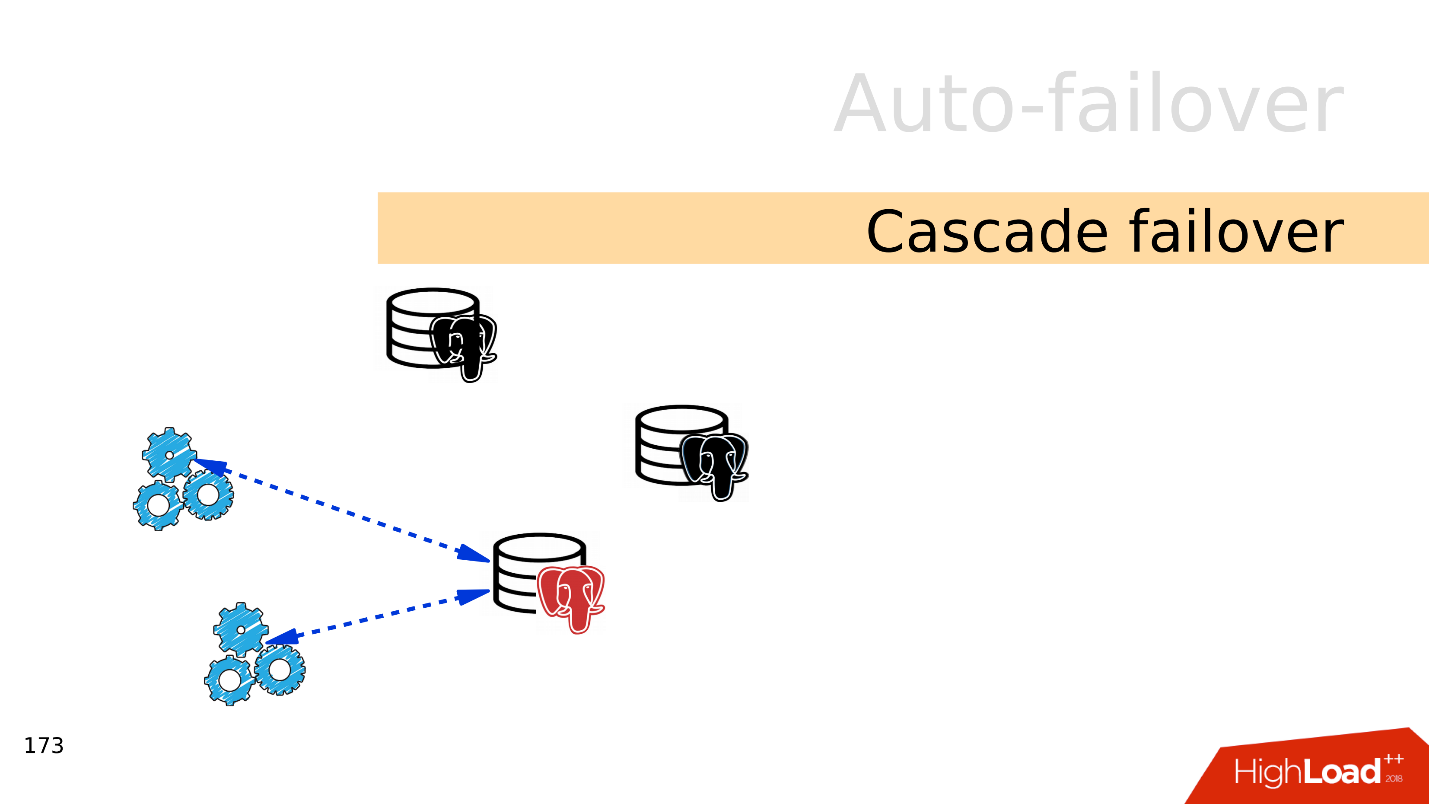
— failover.
auto-failover, .
Bash — , . , , . - , , . .
Ansible playbooks — bash- . , , .
Patroni — , , auto-failover, , service discovery.
PAF —
Pacemaker . auto-failover PostgreSQL, Pacemaker.
Stolon . Kubernetes, . Stolon Patroni, .
Docker Kubernetes . , .
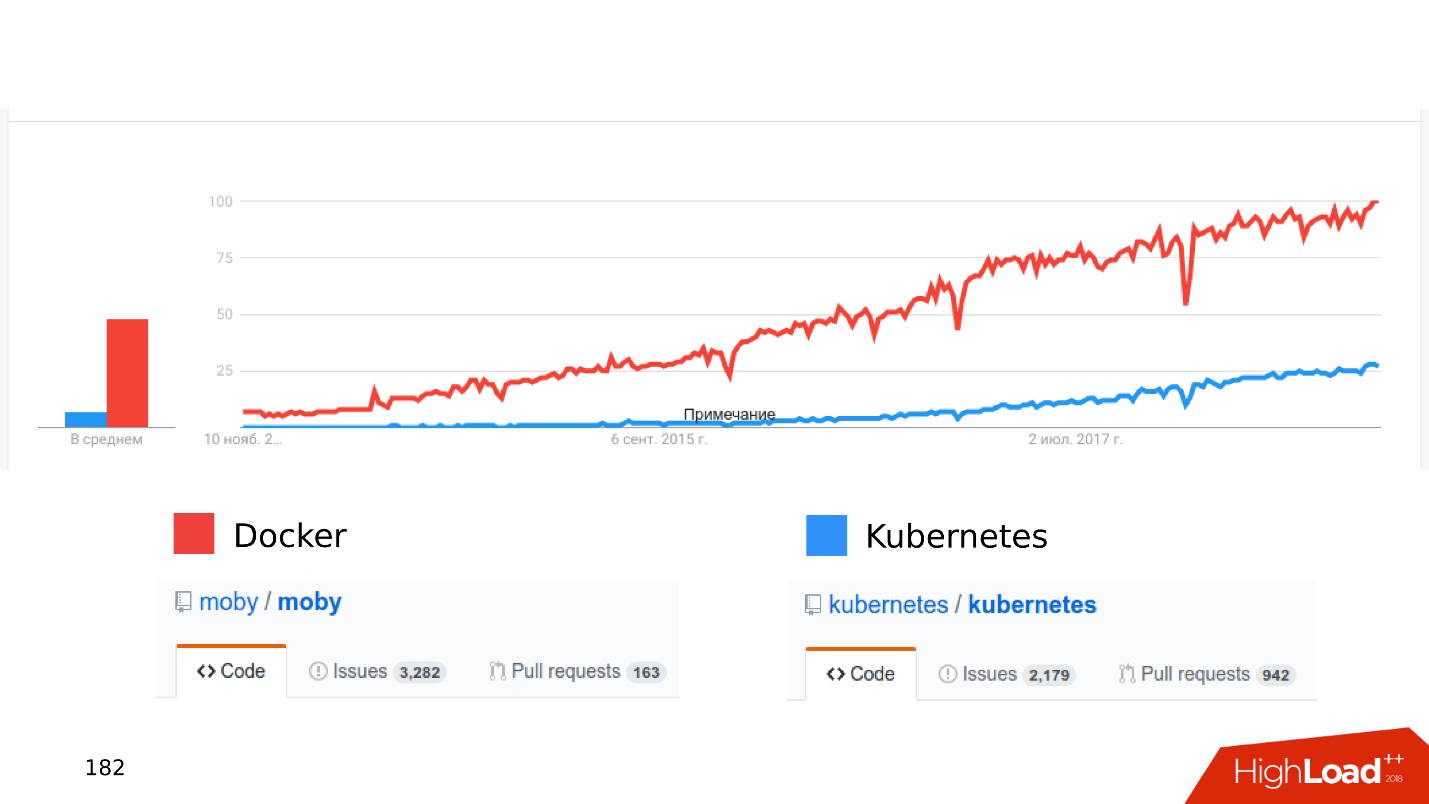
, .
« Kubernetes...» .
— stateful , - . O?? . Open Source: CEPH, GlusterFS, LinStor DRBD. , , , .
—
. , Kubernetes, CEPH. — . , .
- , .
- latency . latency — .
- . Kubernetes , - . , shared storage Kubernetes, . - .
, Kubernetes Docker staging dev- . , , Kubernetes .
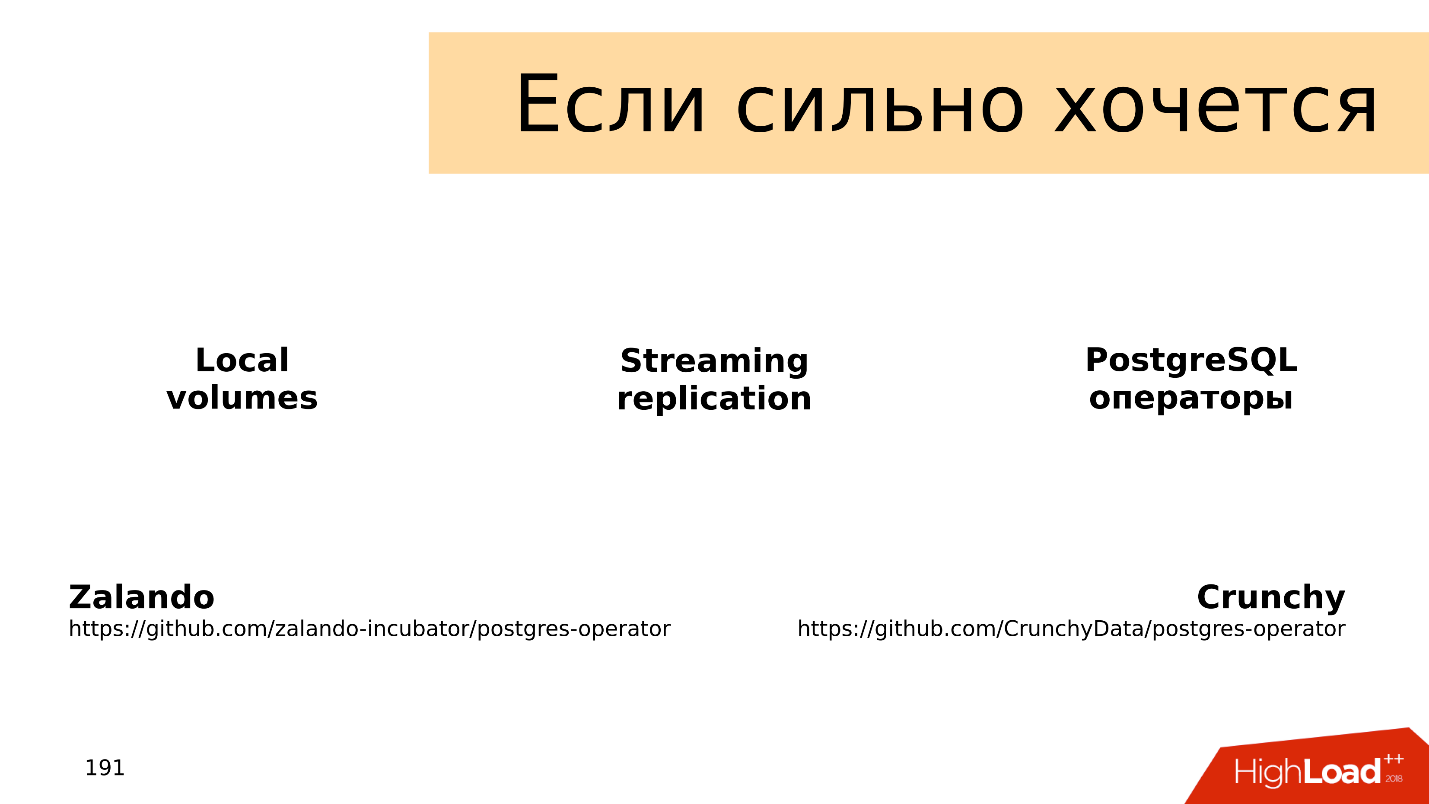
,
local volumes — ,
streaming replication — ,
PostgreSQL- , — , . :
Zalando Crunchy .
, . issues pull requests. , , .
Résumé
SSD — , .
. JSON 8 — , .
, . PostgreSQL, .
— Postgres is ready . . PostgreSQL , . :
streaming replication; publications, subscriptions; foreign Tables; declarative partitioning .
. , .
-, , —
. . , Skytools PgQ!
Kubernetes, local volumes, streaming replication PostgreSQL . - , , .
. , 24 25 HighLoad++ Siberia , , . 38 — !