Sentiment de mort, solitude, en même temps, soif de vie folle ... Vous pourriez penser que nous avons décidé de donner une conférence sur l'expressionnisme et de vous plonger dans le travail de Munch. Mais non. Vous passez par toutes ces étapes au moment où vous voyez que votre dette technique va bientôt pousser votre entreprise dans l'abîme de la crise.

Depuis 8 ans, l'équipe informatique de Dodo Pizza est passée de 2 développeurs desservant un pays à 80 personnes desservant 12 pays. Il y a trois ans, j'ai rejoint Dodo Pizza en tant que Chief Agile Officer et j'ai commencé à aider les équipes à créer des processus et à mettre en œuvre des pratiques d'ingénierie. Souvent, ces implémentations étaient trop lentes. De plus, il a été constaté que lorsque plusieurs équipes travaillent sur le même produit, il est difficile de les amener à maintenir un code de haute qualité.
Nous avons poursuivi le développement des fonctions métiers, reportant la perfection technique du code pour plus tard. Nous étions donc pris au piège. Une énorme dette technique nous a pris le poing, mais ne l'a pas écrasé, mais seulement, d'un coup de doigts, a jeté notre entreprise dans l'abîme de la crise. En 2018, l'équipe marketing a lancé une campagne publicitaire massive, nous n'avons pas pu supporter la charge et sommes tombés. Honte, honte et honte. Mais pendant la crise, nous avons réalisé que nous pouvions travailler plusieurs fois plus efficacement. La crise nous a obligés à mettre en œuvre rapidement les pratiques d'ingénierie les plus connues et à révolutionner les processus.
Contexte
Dodo Pizza est une entreprise cyborg qui vend des pizzas . Notre entreprise est basée sur la plateforme Dodo IS, qui gère tous les processus commerciaux: réception des commandes, préparation des pizzas, gestion des stocks, gestion des personnes (gestion) et bien plus encore. En seulement 8 ans, nous sommes passés de 2 développeurs desservant une pizzeria à plus de 80 développeurs desservant 498 pizzerias dans 12 pays.
Il y a trois ans, Dodo IS était un monolithe contenant 1 million de lignes de code. Il y avait une petite couverture avec les tests unitaires, il n'y avait aucun test API / UI. La qualité du code lui-même était décevante. Tout le monde était au courant, ou du moins l'a deviné. Dans les rêves d'un avenir meilleur, nous avons divisé le monolithe en une douzaine de services et réécrit les parties les plus dégoûtantes du système. Nous avons même dessiné un schéma de l'architecture «future», mais franchement, nous n'avons rien fait pour nous en rapprocher.
Plus l'équipe s'est développée, plus nous avons souffert de l'absence d'un processus clair et de pratiques d'ingénierie. Les versions sont devenues de plus en plus nombreuses, car les six équipes de développement ont simultanément effectué des changements dans différentes branches. Lorsque les équipes ont fusionné leurs modifications dans une même branche, nous avons parfois perdu jusqu'à 4 heures à essayer de résoudre les conflits de fusion. Il n'y avait pas de test de régression automatique et avec chaque version, nous passions de plus en plus de temps sur la régression manuelle.
La merde arrive
En 2018, l'équipe marketing a lancé notre première campagne de publicité télévisée fédérale avec un budget de 100 millions de roubles. Ce fut un grand événement pour Dodo Pizza. L'équipe informatique était également bien préparée pour la campagne. Nous avons automatisé et simplifié notre déploiement - maintenant avec un seul bouton dans TeamCity, nous pourrions déployer un monolithe dans 12 pays. À l'aide de tests de performances, nous avons effectué une analyse de vulnérabilité. Nous avons fait de notre mieux, mais nous avons tout de même foiré.
La campagne publicitaire était incroyable. Nous avons reçu de 100 à 300 commandes par minute. C'étaient de bonnes nouvelles. La mauvaise nouvelle: Dodo IS n'a pas pu supporter une telle charge et est décédé. Nous avons atteint la limite de la mise à l'échelle verticale et ne pouvions plus traiter les commandes. Le système a redémarré toutes les 3 heures. Chaque minute d'arrêt nous a coûté des dizaines de milliers de roubles, sans compter la perte de respect des clients en colère.
Lorsque je suis arrivé chez Dodo Pizza il y a trois ans, j'ai immédiatement commencé à mettre en œuvre des pratiques d'ingénierie. La plupart des équipes ont adopté la programmation par paires, les tests unitaires et DDD assez rapidement. Mais tout n'était pas si simple. J'ai dû surmonter la résistance des développeurs, des produits et de l'équipe de support.
Contrairement aux idées de pratiques d'ingénierie, au début, tout le monde n'était pas favorable à l'idée d'équipes techniques. Les développeurs ont l'habitude de penser qu'une équipe concentrée sur un composant écrit le meilleur code. Il n'était pas clair comment combiner le développement rapide des fonctions commerciales avec la refonte massive attendue depuis longtemps d'un système complexe. De plus, ce flux infini de bogues nécessitait constamment de l'attention ... Nous ne publions le produit qu'une fois par semaine, et chaque version prenait beaucoup de temps, elle nécessitait une énorme quantité de régression manuelle et un support pour les tests d'interface utilisateur. J'ai essayé de le réparer, mais le changement de processus était trop lent et fragmenté.
L'histoire de la chute et de la montée
Etat initial: architecture monolithique
Dans la poursuite de la vitesse de développement des fonctions métiers, nous n'avons pas toujours bien réfléchi aux solutions techniques. Affecté par un manque d'expérience. Nous avions une application monolithique avec une seule base de données contenant toutes les données de tous les composants en un seul endroit. Tracker, comptabilité, site Web, API pour les pages de destination - tous les composants du système fonctionnaient avec une seule base de données, ce qui était un goulot d'étranglement.
Histoire vraie
L'architecture monolithique est bonne pour commencer, car elle est simple. Mais il ne peut pas supporter une charge élevée, étant le seul point de défaillance. Une fois que tous nos restaurants en Russie ont cessé d'accepter les commandes en raison d'un article de blog. Comment cela a-t-il pu arriver?
Notre PDG, Fedor, a publié un article sur son blog. Ce poste a rapidement gagné en popularité. Le blog de Fedor possède un compteur indiquant le nombre de pizzerias dans notre réseau et le revenu total de toutes les pizzerias. Chaque fois que quelqu'un lisait le blog de Fedor, le serveur Web envoyait une demande à la base de données principale pour calculer les revenus. Ces demandes ont tellement surchargé la base de données qu'elle a cessé de répondre aux demandes de la caisse du restaurant. Nous avons rapidement résolu le problème, mais c'était l'un des nombreux signes que notre architecture n'était pas en mesure de répondre aux besoins de l'entreprise et devait être repensée. Cependant, nous avons continué à ignorer ces signes.
Crash précoce en 2017
14 février. Pour les amateurs de félicitations du 14 février, nous faisons une pizza spéciale - Pepperoni en forme de coeur. Je me souviendrai toujours du 14 février 2017, car ce jour-là, lorsque toutes les pizzerias fonctionnaient à pleine charge, Dodo IS a commencé à tomber. Chaque pizzeria dispose de 4 à 5 comprimés pour la gestion de la production: pour quel ordre la pizzeria roule la pâte, met les ingrédients, cuit ou l'envoie pour livraison. À cette époque, le nombre de pizzerias atteignait 150+, chaque tablette était mise à jour plusieurs fois par minute. Toutes ces requêtes ont créé une charge si énorme sur la base de données qu'elle a cessé de résister et a commencé à échouer. Dodo IS est décédé lors des pics de ventes. Mais il y avait une saison des Fêtes chargée à venir: 23 février, 8 mars, 1er et 9 mai. Pendant ces vacances, nous nous attendions à une croissance encore plus importante des commandes.
Le jour de ta mort . Connaissant nos plans de croissance et la limite de charge que nous pouvons supporter, nous avons découvert combien de temps nous pouvons rester en vie. La date estimée d'Armageddon était attendue dans environ six mois: en août - septembre 2017. Comment c'est de vivre, en connaissant la date de votre décès?
Arrêtez le développement des fonctions pendant un an. Avec le PDG Fedor, nous avons dû prendre une décision difficile. Peut-être l'une des décisions les plus difficiles de l'histoire de l'entreprise. Au cours de la prochaine année, nous n'avons créé qu'une seule fonctionnalité commerciale. Le reste du temps, les équipes ont remboursé la dette technique. Cette dette nous a coûté très cher - plus de 100 millions de roubles uniquement pour les salaires des développeurs.
Quelques améliorations après un an
Au cours de l'année, nous avons considérablement augmenté:
- Nous avons automatisé et accéléré le processus de déploiement à 4-5 heures
- Enfin, nous avons commencé à voir le monolithe: le tracker et les cartes TV ont été déplacés vers un service séparé avec sa propre base de données
- Nous avons commencé à séparer la caisse de livraison - le deuxième composant qui a créé une charge élevée
- Réécriture du système d'authentification des utilisateurs et des appareils
Il semblerait que nous pourrions être fiers de nous. Mais devant nous était une énorme déception.
Échec lors de la campagne de publicité fédérale. Seconde crise de confiance
La dette technique est facile à accumuler, mais très difficile à rembourser. Il est peu probable que vous puissiez comprendre à l'avance combien cela vous coûtera.
Malgré le fait que nous ayons lutté avec un arriéré technique pendant une année entière, nous n'étions pas prêts pour une campagne de marketing de masse et nous avons encore foiré devant notre entreprise. La confiance que nous avons gagnée goutte à goutte a disparu.
Sous le poids de la campagne fédérale de marketing, nous nous sommes de nouveau allongés. Le système s'est de nouveau écrasé et a redémarré toutes les 3 heures. Notre entreprise perdait des dizaines de millions de roubles.

Grâce à la crise, nous avons appris que dans des conditions extrêmes, nous pouvons travailler plusieurs fois plus efficacement. Nous sommes libérés 20 fois par jour. Tous ont travaillé en une seule équipe, en se concentrant sur un seul objectif. Pendant les deux semaines de crise, nous avons fait ce que nous avions peur de commencer à faire plus tôt, croyant que cela prendrait des mois de travail. Réception asynchrone des commandes, désactivation des commandes, tests de résistance, nettoyage des journaux - ce n'est qu'une petite partie de ce que nous avons fait. Nous voulions continuer à travailler tout aussi efficacement, mais sans heures supplémentaires et sans stress.
Leçons apprises
Après la rétrospective, nous avons complètement réorganisé nos processus. Nous avons pris LeSS comme base et l'avons complété par des pratiques d'ingénierie. Au cours des prochains mois, nous avons fait une percée dans l'introduction de pratiques d'ingénierie. Sur la base de LeSS, nous avons implémenté et continuons à utiliser:
- Carnet de produit unique
- Commandes entièrement inter-fonctionnelles et inter-composants
- Programmation par paires et mob
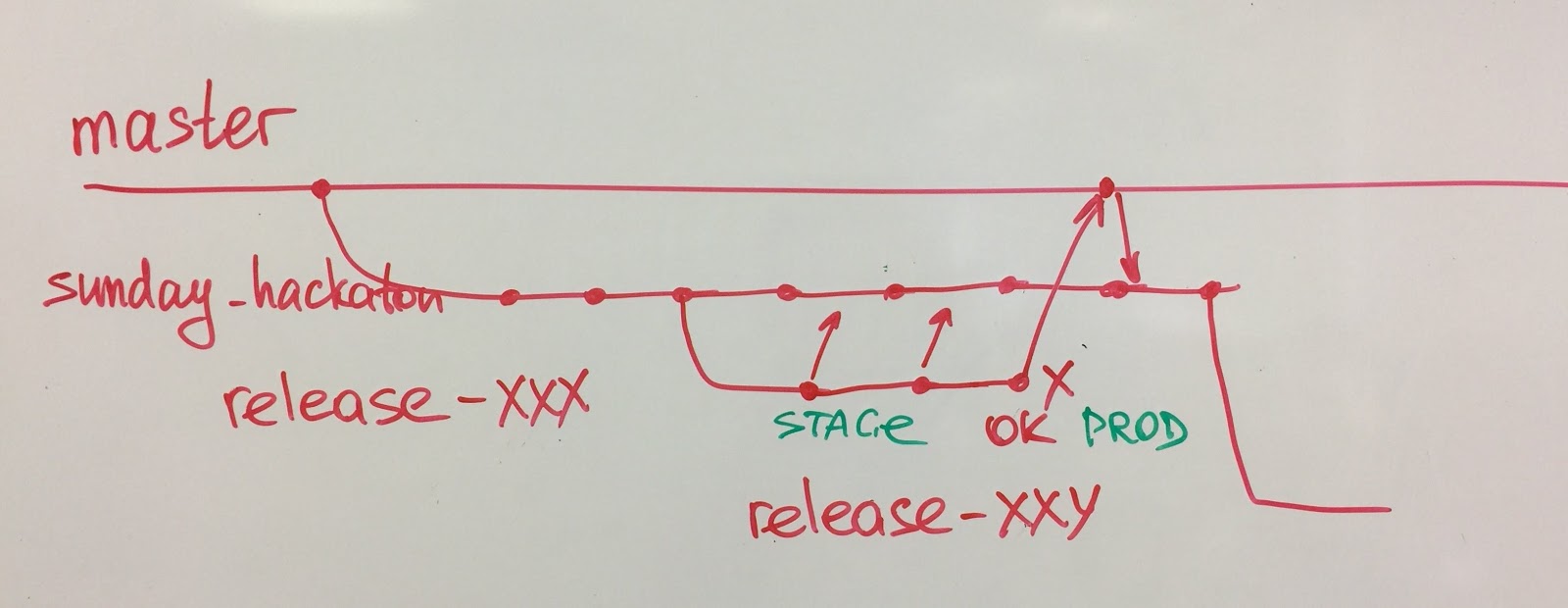
- True Continuous Integration (CI) - Intégration de code avec 12 équipes dans une branche
- Travail simplifié avec les succursales (développement basé sur le tronc)
- Versions fréquentes: déploiement continu pour microservices, version quotidienne pour monolith
- Refus d'une équipe QA distincte, les experts QA font partie de l'équipe de développement
6 pratiques que nous avons choisies après la crise:
1. Le pouvoir de la concentration. Avant la crise, chaque équipe travaillait sur sa propre dette et se spécialisait dans son domaine. Pendant la crise, les équipes n'avaient pas de tâches spécifiques, elles avaient un gros objectif difficile. Par exemple, une application mobile et une API doivent traiter 300 commandes par minute, quoi qu'il arrive. L'équipe prend l'objectif et pense indépendamment comment l'atteindre. L'équipe formule elle-même les hypothèses et les teste rapidement sur la prod. Les équipes ne veulent pas être de simples codeurs, elles veulent résoudre des problèmes.
Le pouvoir de concentration se manifeste dans des tâches complexes. Par exemple, pendant la crise, nous avons créé des tests de résistance, malgré le fait que nous n'avions aucune expérience. Nous avons également rendu la logique de réception de la commande asynchrone. Nous y avons longuement réfléchi et discuté, et il nous a semblé que c'est une tâche très difficile, qui peut prendre beaucoup de temps. Mais il s'est avéré que l'équipe est tout à fait capable de le faire en 2 semaines, si elle n'est pas distraite et se concentre complètement sur le problème.
2. Hackathons internes. Nous avons réalisé le 500 erreurs Hackathon. Toutes les équipes ont effacé les journaux et supprimé les causes de 500 erreurs sur le site et dans l'API. L'objectif était de garder les journaux propres. Lorsque les journaux sont propres, les nouvelles erreurs sont clairement visibles, vous pouvez facilement définir des seuils pour les alertes.
Les bogues sont un autre exemple de hackathon. Auparavant, nous avions un arriéré complet de bogues, certains d'entre eux traînant depuis de nombreuses années. Ils ne semblaient jamais finir. Et chaque jour de nouveaux apparaissaient. Nous avons combiné le travail sur les bugs et les éléments de backlog habituels.
Politique #Zerobugspolicy.- Si le bogue est dans le backlog depuis plus de 3 mois, supprimez-le. Il était resté là depuis des lustres et personne n'est mort.
- Évaluez la douleur que les bogues restants causent aux clients. Ne laissez que les bogues qui rendent la vie difficile à un grand groupe d'utilisateurs.
- Organisez un hackathon interne pour les bugs. Nous l'avons fait en quelques sprints. Chaque sprint, chaque équipe a pris plusieurs erreurs et les a corrigées. Après 2-3 sprints, nous avions un carnet de commandes propre. Vous pouvez maintenant entrer #zerobugspolicy.
- #zerobugspolicy. Si le bogue pénètre dans le backlog, il sera définitivement corrigé. Tout bogue dans le backlog a une priorité plus élevée que tout autre élément de backlog. Mais pour entrer dans le backlog, le bug doit être sérieux. Soit cela fait un tort irréparable, soit affecte un grand nombre d'utilisateurs.
3. Des équipes de projet à une équipe stable. Il y avait une histoire drôle avec les équipes de projet. Pendant la crise, nous avons formé des équipes d'experts composées des personnes les plus qualifiées pour cette tâche. Après la fin de la crise, les équipes ont décidé de poursuivre cette pratique. Malgré le fait que je n'aimais pas du tout cette idée, nous avons essayé. En seulement 2 semaines (un sprint), dans la rétrospective suivante, les équipes ont abandonné cette pratique (cette décision m'a fait plaisir). Si une équipe manque de compétences, elle peut progressivement apprendre. Mais l'esprit d'équipe, le soutien et l'entraide prennent beaucoup de temps, il faut des mois. Les équipes de projet à court terme sont constamment au stade de formation et d'assaut. Vous pouvez tolérer cela pendant plusieurs semaines, mais vous ne pourrez pas travailler de cette façon tout le temps.
4. Pas de régression manuelle. Nous nous sommes fixé pour objectif de nous débarrasser des régressions manuelles. Il nous a fallu un an et demi pour l'atteindre. Mais avoir un objectif ambitieux à long terme vous fait penser aux étapes menant à l'objectif.
Nous l'avons fait en 3 étapes.- Automatisation du chemin critique.
En juin 2017, nous avons formé une équipe QA. La tâche de l'équipe était d'automatiser la régression des fonctionnalités les plus critiques de Dodo IS - la réception et la production des commandes. Au cours des 6 prochains mois, une nouvelle équipe AQ de 4 personnes a couvert toutes les fonctionnalités critiques du système avec des tests automatiques. Les développeurs de l'équipe de fonctionnalités ont activement aidé l'équipe QA. Ensemble, nous avons écrit un langage de domaine (DSL) beau et compréhensible, qui était compris même par les clients. Parallèlement aux tests de bout en bout, les développeurs ont pondéré le code avec des tests unitaires. Certains nouveaux composants ont été repensés à l'aide de TDD. Après cela, nous avons dissous l'équipe QA. D'anciens membres de l'équipe QA ont rejoint les équipes travaillant sur les fonctionnalités métier afin de transférer l'expérience de développement et de prise en charge des autotests aux équipes. - Mode ombre.
Ayant des autotests, pendant 5 versions, nous avons effectué une régression manuelle en mode ombre. Les équipes ne se sont appuyées que sur des tests automatiques, mais lorsque l'équipe a décidé qu'elle était prête à être publiée, nous avons lancé une régression manuelle pour vérifier si nos autotests avaient manqué des erreurs. Nous avons suivi le nombre d'erreurs détectées manuellement et non détectées par les tests automatiques. Après 5 versions, nous avons analysé les données et décidé que nous pouvions faire confiance à nos tests automatiques. Aucune erreur majeure n'a été manquée. - Refus de régression manuelle.
Lorsque nous avons eu suffisamment de tests pour commencer à leur faire confiance, nous avons complètement abandonné les tests manuels. Plus nous écrivons de tests, plus nous leur faisons confiance. Mais cela ne s'est produit qu'un an et demi après que nous ayons commencé à automatiser les tests de régression.
5. Les tests de résistance font partie de la régression. Pendant la crise, nous avons rédigé des tests de résistance. Ce fut une expérience complètement nouvelle pour nous. Cependant, en seulement 2 semaines, nous avons pu créer quelque chose à l'aide des outils Visual Studio. Nous les avons utilisées, notamment pour générer une charge artificielle sur le serveur, afin de trouver des limites de performances. Par exemple, si la charge organique sur la prod est de 100 commandes / min, nous avons ajouté 50 autres commandes / min en utilisant nos tests pour voir si le système est capable de gérer la charge accrue.
L'année suivante, nous avons réécrit les tests de résistance avec une équipe PerformanceLab expérimentée. Aujourd'hui, ces tests s'exécutent chaque semaine et fournissent un retour rapide aux équipes de développement.
 6. Pratiques d'ingénierie.
6. Pratiques d'ingénierie. Toutes nos équipes utilisent la programmation par paires. Je considère la programmation en binôme comme l'une des pratiques les plus simples mais les plus puissantes. Si vous ne savez pas par quelle technique d'ingénierie commencer, je recommande la programmation par paires.
Résultats
Le principal résultat pour nous a été un bouleversement. Nous nous sommes réveillés et avons commencé à jouer. La crise nous a aidés à voir notre potentiel maximum. Nous avons vu que nous pouvons travailler plusieurs fois plus efficacement et atteindre rapidement nos objectifs. Mais pour cela, il est nécessaire de changer la façon habituelle de travailler. Nous n'avons plus peur des expériences audacieuses.
À la suite de ces expériences au cours de la dernière année, nous avons considérablement amélioré la qualité et la stabilité du Dodo IS. Si pendant les vacances de printemps 2018 nos pizzerias ne pouvaient pas fonctionner à cause de Dodo IS, alors en 2019, avec une augmentation de 300 à 498 pizzerias, Dodo IS fonctionne parfaitement. Nous avons calmement survécu au pic des ventes de la nouvelle année, lors de la deuxième campagne marketing et des vacances de printemps.
Pour la première fois depuis longtemps, nous sommes confiants dans la qualité du système et pouvons nous permettre de dormir profondément la nuit. .
, . - . .
:
- - -
- /
- Continuous Integration – 12
- Subject Matter Expert
- QA, QA
- (#Zerobugspolicy)
- Stop the Line
, . , , .
- .
- ,
- – .
- ,
- , . , , .
- . , ,
. , . , . , .
, LeSS. .. ., Product Owner', -.., Scrum-, . ., : , . , . , .