
Les ingénieurs DevOps et SRE ont probablement entendu parler de Prometheus plus d'une fois.
Prometheus a été créé à SoundCloud en 2012 et est depuis devenu la norme pour les systèmes de surveillance . Il a un code source complètement ouvert, il fournit des dizaines d'exportateurs différents avec lesquels vous pouvez configurer la surveillance de l'ensemble de l'infrastructure en quelques minutes .
Prometheus a une valeur évidente et est déjà utilisé par des innovateurs de l'industrie comme DigitalOcean ou Docker dans le cadre d'un système de surveillance complet.
Qu'est-ce que Prométhée?
Pourquoi est-il nécessaire?
En quoi est-il différent des autres systèmes?
Si vous ne savez rien du tout sur Prométhée ou souhaitez mieux le comprendre, son écosystème et toutes ses interactions, cet article est fait pour vous .
Nous avons divisé ce guide en 3 parties, comme nous l'avons fait avec InfluxDB .
- Vient d'abord un aperçu complet de Prometheus , de son écosystème et des aspects clés de la technologie en évolution rapide.
- Ensuite, des explications sur les termes techniques de Prometheus sont fournies. Si vous ne savez pas ce que sont les métriques, les étiquettes, les instances ou les exportateurs, vous êtes ici.
- Enfin, nous décrivons divers scénarios du monde réel pour l'utilisation de Prometheus . Ici, vous serez inspiré par des exemples d'entreprises prospères.
Partie I. Qu'est-ce que Prométhée?
Prometheus est une base de données de séries chronologiques. Si vous ne savez pas ce qu'est une base de données de séries chronologiques, lisez la première partie du manuel InfluxDB .
Mais Prometheus n'est pas seulement une base de données de séries chronologiques.
Vous pouvez y attacher un écosystème complet d'outils pour étendre les fonctionnalités.
Prometheus surveille une grande variété de systèmes : serveurs, bases de données, machines virtuelles individuelles et presque tout.
Pour ce faire, Prometheus gratte périodiquement ses cibles .
Qu'est-ce que le grattage?
Prometheus récupère les métriques via des appels HTTP vers des points de terminaison spécifiques spécifiés dans la configuration Prometheus.
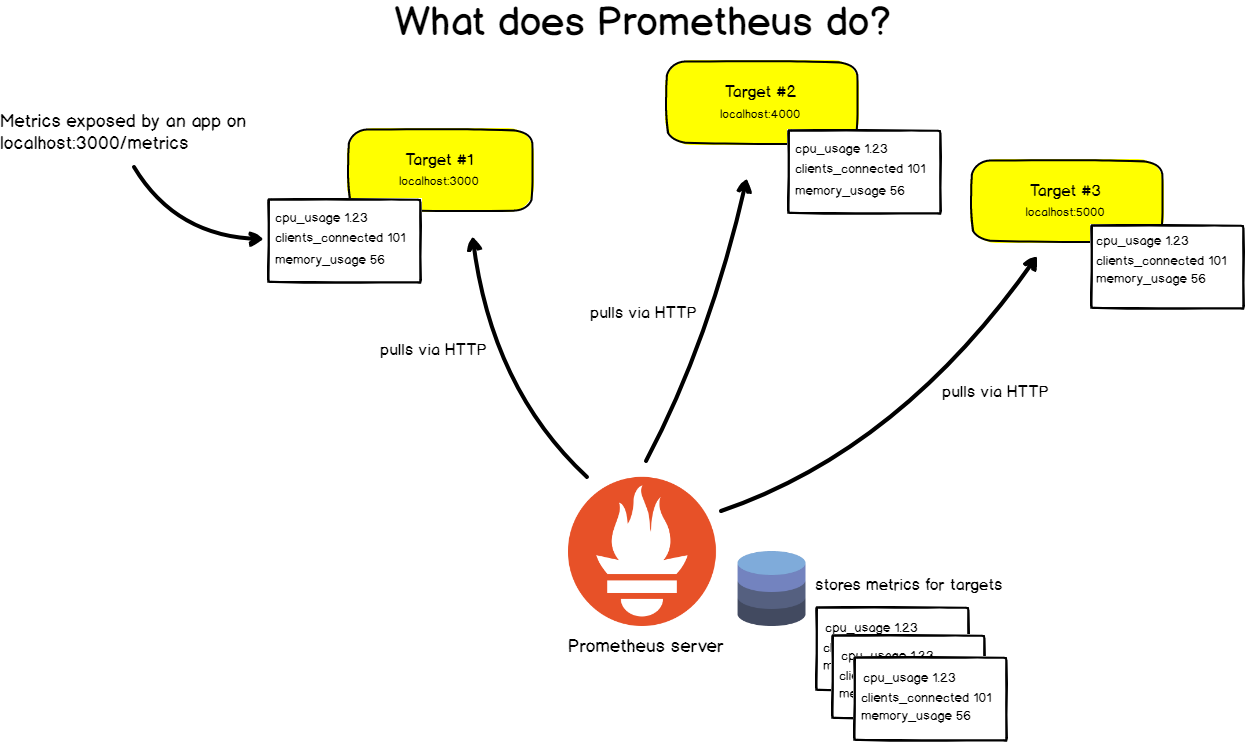
Prenons, par exemple, l'application Web située sur http: // localhost: 3000 . L'application transmet des métriques au format texte à une URL. Disons http: // localhost: 3000 / metrics .
À cette adresse, Prometheus récupère les données de la cible à des intervalles spécifiques.
1. Comment fonctionne Prométhée?
Comme nous l'avons dit, Prometheus se compose d'une grande variété de composants.
Tout d'abord, vous en avez besoin pour extraire des métriques de vos systèmes. Il existe différentes manières:
- L'instrumentation de l' application, c'est-à-dire que votre application fournira des mesures compatibles avec Prometheus à l'URL spécifiée. Prométhée l'identifiera comme la cible et la supprimera à l'intervalle spécifié.
- Utilisation d' exportateurs prêts à l'emploi . Prometheus possède une collection d'exportateurs pour les technologies existantes. Par exemple, des exportateurs prêts à l'emploi pour surveiller les machines Linux ( Node Exporter ), pour les bases de données courantes ( SQL Exporter ou MongoDB Exporter ), et même pour les équilibreurs de charge HTTP (par exemple, HAProxy Exporter ).
- Utilisation de Pushgateway . Parfois, les applications ou les tâches ne fournissent pas de métriques directement. Ils peuvent ne pas être conçus pour cela (par exemple, les travaux par lots) ou vous-même avez décidé de ne pas fournir de métriques directement via l'application.
Comme vous l'avez déjà compris, Prometheus collecte elle-même les données (sauf dans les rares cas où nous utilisons Pushgateway).
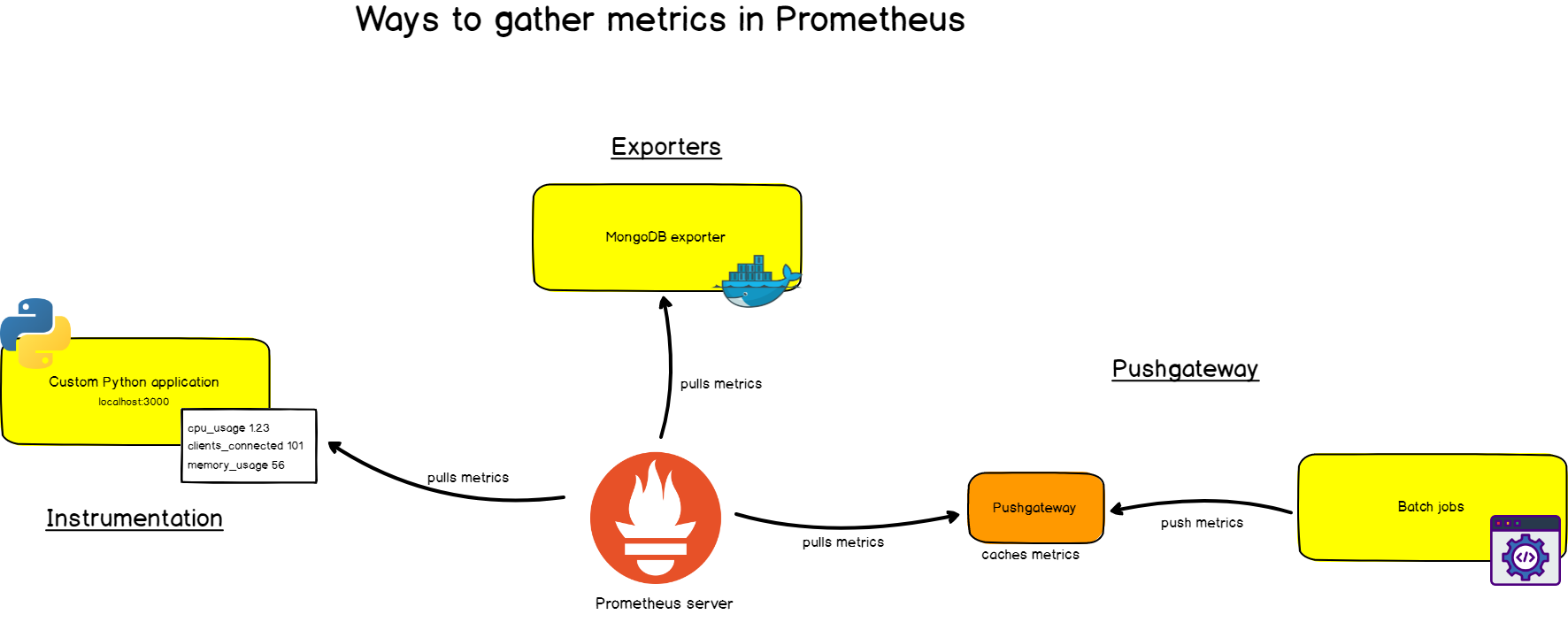
Qu'est-ce que cela signifie?
Pourquoi est-ce nécessaire?
2. Collection vs envoi
Prometheus a une différence notable par rapport aux autres bases de données de séries chronologiques: il scanne activement les cibles pour en obtenir des métriques .
InfluxDB, par exemple, fonctionne différemment: vous lui envoyez directement des données .
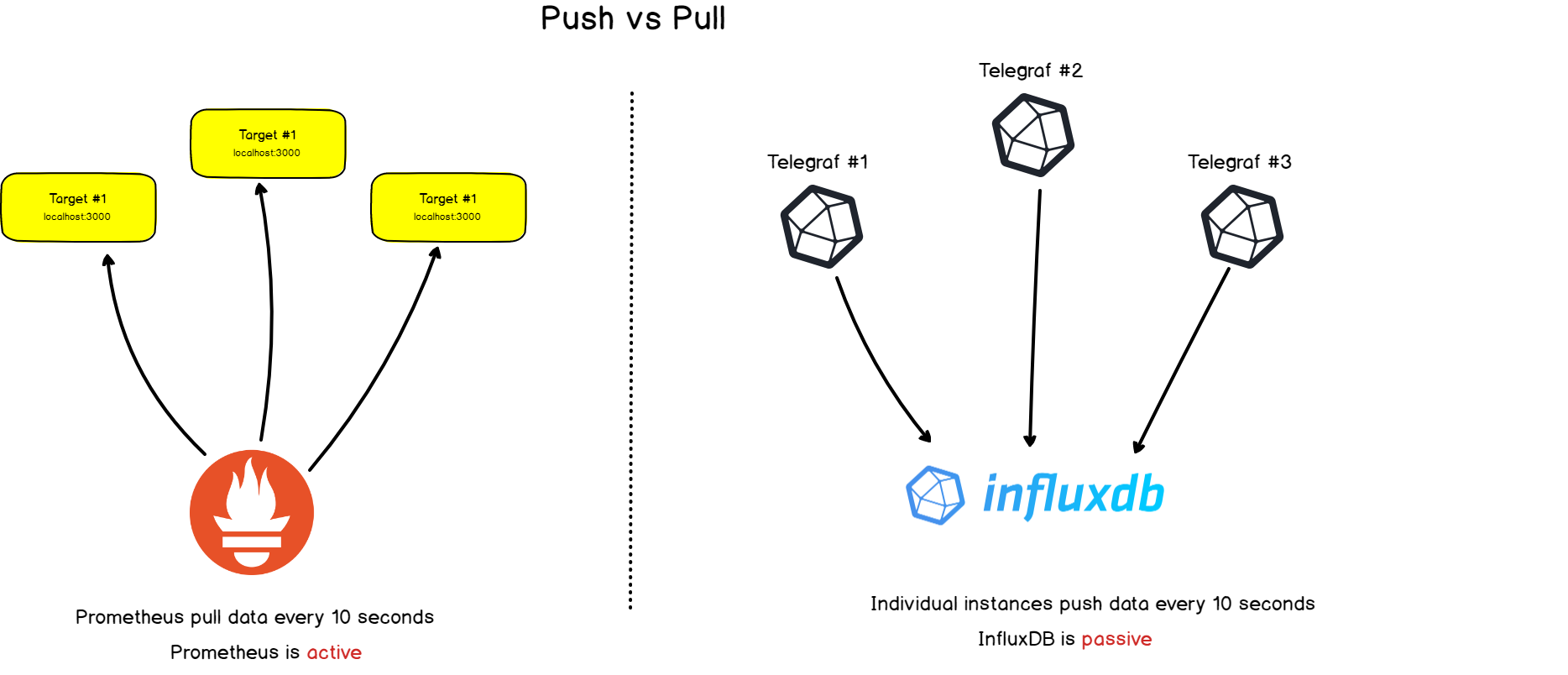
Les deux approches ont leurs avantages et leurs inconvénients. Sur la base de la documentation disponible, nous avons compilé une liste de raisons pour lesquelles les créateurs de Prometheus ont choisi cette architecture:
- Contrôle centralisé . Si Prometheus envoie des demandes aux cibles, nous effectuons toute la configuration du côté Prometheus, pas les systèmes individuels.
Prométhée décide où et à quelle fréquence gratter.
Si les objets eux-mêmes envoient des données, il y a un risque que ces données soient trop nombreuses et que le serveur tombe en panne. Lorsque le système collecte des données, vous pouvez contrôler la fréquence de collecte et créer plusieurs configurations de grattage pour sélectionner une fréquence différente pour différents objets .
- Prometheus stocke des métriques agrégées .
Ceci est un ajout à la première partie où nous avons discuté du rôle de Prométhée.
Prometheus n'est pas basé sur des événements et est très différent des autres bases de données de séries chronologiques. Il n'intercepte pas les événements individuels avec une référence à l'heure (par exemple, les pannes de service), mais recueille des métriques pré-agrégées sur vos services .
Plus précisément, le service Web n'envoie pas de message d'erreur 404 et un message avec la cause de l'erreur. Un message est envoyé indiquant que le service a reçu un message d'erreur 404 au cours des cinq dernières minutes.
Il s'agit de la principale différence entre les bases de données de séries chronologiques qui collectent des métriques agrégées et celles qui collectent des métriques brutes.
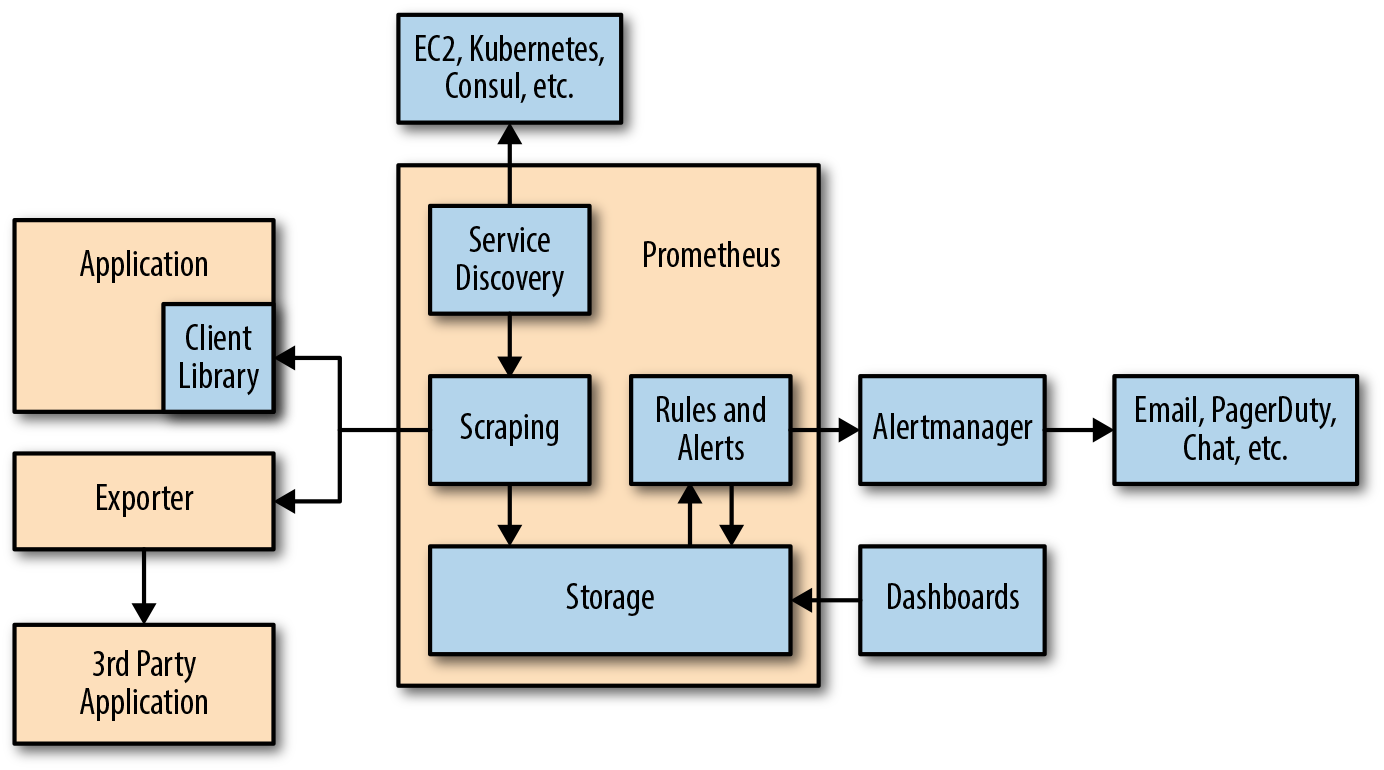
3. Écosystème Prometheus développé
Essentiellement, Prometheus est une base de données de séries chronologiques.
Mais lorsque vous travaillez avec de telles bases de données, vous devez souvent visualiser les données, les analyser et configurer des alertes pour elles.
Prometheus prend en charge les outils suivants qui étendent ses fonctionnalités:
- Alertmanager . Prometheus envoie des alertes à Alertmanager en fonction de règles personnalisées définies dans les fichiers de configuration. De là, ils peuvent être exportés vers différents points de terminaison (par exemple, Pagerduty ou Slack).
- Visualisation des données . Comme Grafana, vous pouvez visualiser les séries chronologiques directement dans l'interface utilisateur Web de Prometheus. Vous pouvez filtrer les données et créer des revues spécifiques de ce qui se passe dans différentes cibles.
- Découverte de service . Prometheus détecte dynamiquement les cibles et gratte automatiquement les nouvelles cibles sur demande. Cela est particulièrement pratique si vous travaillez avec des conteneurs qui modifient dynamiquement les adresses en fonction de la demande.

Partie II Concepts de Prométhée
Comme dans le manuel InfluxDB, nous expliquerons en détail les termes techniques liés à Prometheus.
1. Modèle de données de valeur-clé
Avant de passer aux outils Prometheus, il est important de bien comprendre ce modèle de données.
Prometheus fonctionne avec des paires clé-valeur . La clé décrit ce que nous mesurons et la valeur stocke la valeur réelle sous forme de nombre.
N'oubliez pas: Prometheus n'est pas conçu pour stocker des informations brutes, telles que du texte brut. Il stocke des métriques agrégées sur une période de temps.
Dans ce cas, la clé est appelée métrique . Il s'agit, par exemple, de la vitesse du processeur ou de l'utilisation de la mémoire.
Mais que se passe-t-il si vous avez besoin de plus de détails sur la mesure?
Par exemple, le processeur a 4 cœurs et nous avons besoin de 4 mesures distinctes?
Et ici, les raccourcis viennent à la rescousse. Les raccourcis fournissent plus d'informations sur les mesures en ajoutant des champs supplémentaires. Par exemple, vous décrivez non seulement la vitesse du processeur, mais la vitesse d'un cœur sur une adresse IP spécifique.
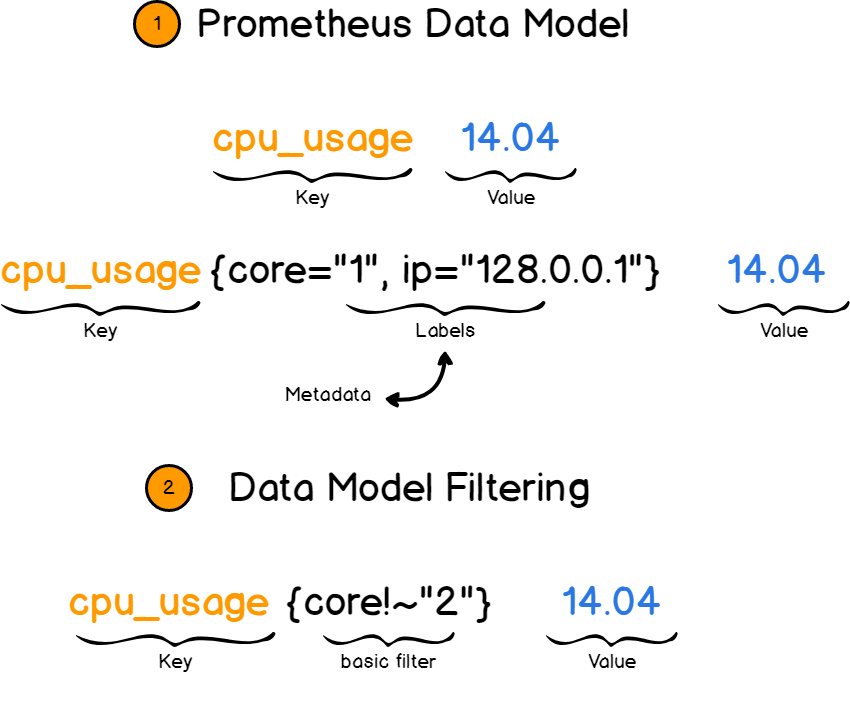
Ensuite, vous pouvez filtrer les métriques par étiquettes et afficher uniquement les informations dont vous avez besoin.
2. Types de métriques
Lors de la surveillance avec Prometheus, les mesures peuvent être décrites de quatre manières. Il vaut mieux le lire jusqu'au bout, car il y a des pièges ici.
Comptoir
Il s'agit probablement du type de mesure le plus simple. Le compteur, comme son nom l'indique, compte les éléments pendant un certain temps .
Si vous souhaitez compter, par exemple, les erreurs HTTP sur les serveurs ou visiter un site Web, utilisez un compteur .
Et logiquement, bien sûr, le compteur ne peut qu'augmenter ou mettre à zéro le nombre , il n'est donc pas adapté aux valeurs qui peuvent diminuer, ou aux valeurs négatives.
Avec son aide, il est particulièrement pratique de considérer le nombre d'occurrences d'un certain événement sur une période de temps, c'est-à-dire le taux de changement de la métrique dans le temps.
Et si vous avez besoin de mesurer, disons, la mémoire utilisée pendant une certaine période?
Cette valeur peut diminuer. Comment le compter avec Prométhée?
Mètres
Rencontrez les compteurs!
Les compteurs traitent des valeurs qui peuvent diminuer avec le temps . Ils peuvent être comparés aux thermomètres - si vous regardez le thermomètre, nous verrons la température actuelle.
Mais si les compteurs peuvent augmenter et diminuer et prendre des valeurs positives et négatives, alors il s'avère qu'ils sont meilleurs que les compteurs?
Les compteurs sont donc inutiles?
Au début, je le pensais. Puisqu'ils peuvent tout faire, utilisons-les partout. Est-ce logique?
Mais non.
Les compteurs sont idéaux pour mesurer la valeur métrique actuelle, qui peut diminuer avec le temps.
C'est là que se trouvent les pièges mêmes: le compteur ne montre pas le développement de la métrique sur une période de temps. À l'aide de compteurs, vous pouvez manquer des changements métriques irréguliers au fil du temps .
Pourquoi? Voici ce que / u / justinDavidow dit :
«Le compteur montre la valeur moyenne du compteur delta pour une unité sur une période de temps.
Le compteur prend en compte chaque unité utilisée (s'il s'agit d'un processeur, puis des opérations, des cycles ou des ticks), puis vous pouvez choisir les indicateurs pour quelle période vous avez besoin.
Si vous utilisez un lecteur, la fréquence d'échantillonnage doit être précise. Si la fréquence diffère d'au moins quelques microsecondes, la valeur ne sera pas fiable. "Ceci est encore plus visible sous une charge élevée, où le temps entre les mesures augmente de façon exponentielle, car le planificateur du système n'a pas le temps de prêter attention à l'application de surveillance."
Si le système envoie des métriques toutes les 5 secondes et que Prometheus élimine la cible toutes les 15, certaines métriques peuvent être perdues au cours du processus. Si vous effectuez des calculs supplémentaires avec ces mesures, la précision des résultats sera encore plus faible.
Au comptoir, chaque valeur est agrégée. Lorsque Prométhée le récupère, il se rend compte que la valeur a été envoyée à un certain intervalle.
Maintenant, ne vous trompez pas.
Graphique à barres
Un histogramme est un type de métrique plus complexe. Il fournit des informations supplémentaires. Par exemple, la somme des mesures et leur nombre.
Les valeurs sont collectées dans une zone avec une limite supérieure personnalisée. Par conséquent, un histogramme peut:
- Calculez les valeurs moyennes , c'est-à-dire la somme des valeurs divisée par le nombre de valeurs.
- Calculez les mesures relatives des valeurs , et cela est très pratique si vous avez besoin de savoir combien de valeurs dans une certaine zone correspondent aux critères spécifiés. Cela est particulièrement utile si vous devez suivre les proportions ou définir des indicateurs de qualité.
Dans le monde réel, j'aimerais recevoir une alerte si 20% de mes serveurs ont une réponse de plus de 300 ms ou une réponse de serveur de plus de 300 ms plus de 20% du temps.
Si vous avez affaire à des proportions, vous avez besoin d'histogrammes .
Résumé
Les tableaux de bord sont des histogrammes avancés . Ils montrent également la somme et le nombre de mesures, ainsi que les quantiles pour la période en mouvement .
Les quantiles, le cas échéant, divisent la densité de probabilité en segments de probabilité égale.
Alors: graphiques à barres ou résumés?
Tout dépend de l' intention .
Les histogrammes combinent des valeurs sur une période de temps, fournissant la quantité et la quantité grâce auxquelles vous pouvez suivre le développement d'une métrique particulière.
Les résumés, d'autre part, montrent des quantiles sur une période en mouvement (c'est-à-dire un développement continu dans le temps).
Ceci est particulièrement pratique si vous avez besoin de connaître une valeur qui représente 95% des valeurs enregistrées sur une période.
3. Tâches et instances
Compte tenu des progrès récents des architectures distribuées et de la popularité des solutions basées sur le cloud, il est peu probable que vous utilisiez un seul serveur fonctionnant seul.
Les serveurs sont répliqués et distribués dans le monde entier.
Pour illustrer cela, regardons l'architecture classique de deux serveurs HAProxy qui redistribuent la charge sur neuf serveurs Web principaux ( non, non, pas de piles Stackoverflow ) .
Dans cet exemple réel, nous suivrons le nombre d'erreurs HTTP renvoyées par les serveurs Web .
Dans Prometheus, un serveur Web est appelé une instance . La tâche consistera à mesurer le nombre d'erreurs HTTP sur toutes les instances.
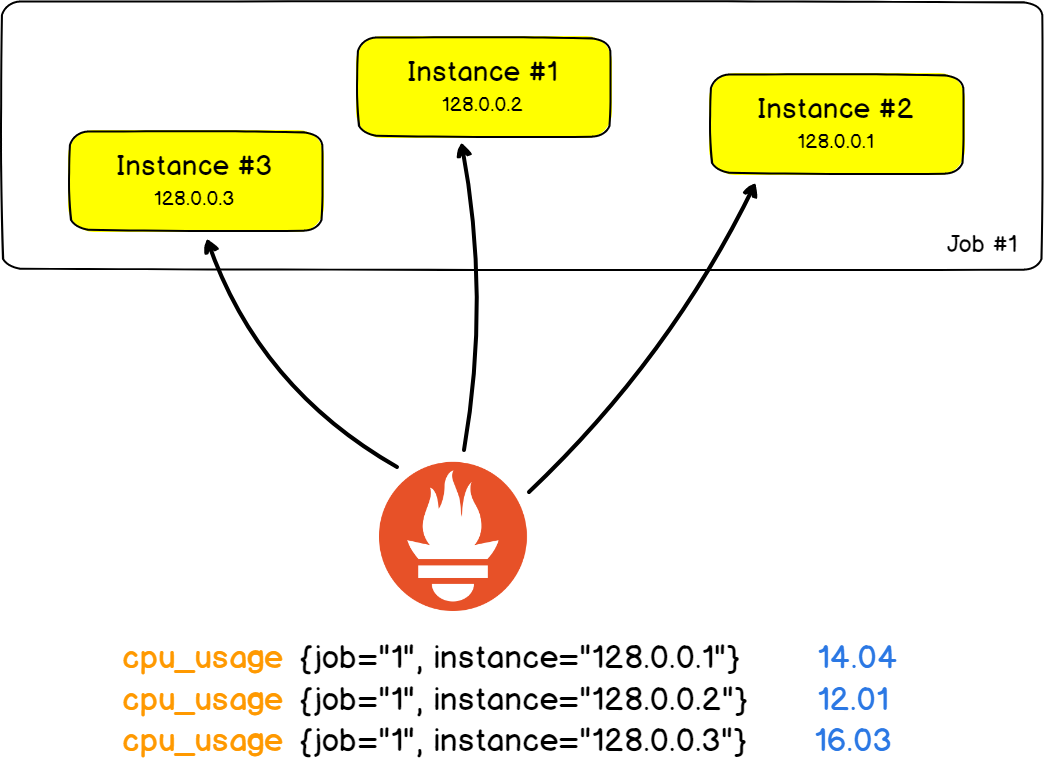
La beauté est que les tâches et les instances sont des champs dans les étiquettes, et vous pouvez filtrer les résultats par une instance ou une tâche spécifique.
Est-ce pratique?
4. PromQL
Si vous utilisez des bases de données basées sur InfluxDB, vous connaissez probablement déjà InfluxQL . Ou utilisez SQL dans TimescaleDB .
Prometheus possède également son propre langage d'interrogation et de récupération des données des serveurs: PromQL .
Comme nous le savons déjà, les données sont présentées sous forme de paires clé-valeur. PromQL utilise la même syntaxe et renvoie des résultats en tant que vecteurs.
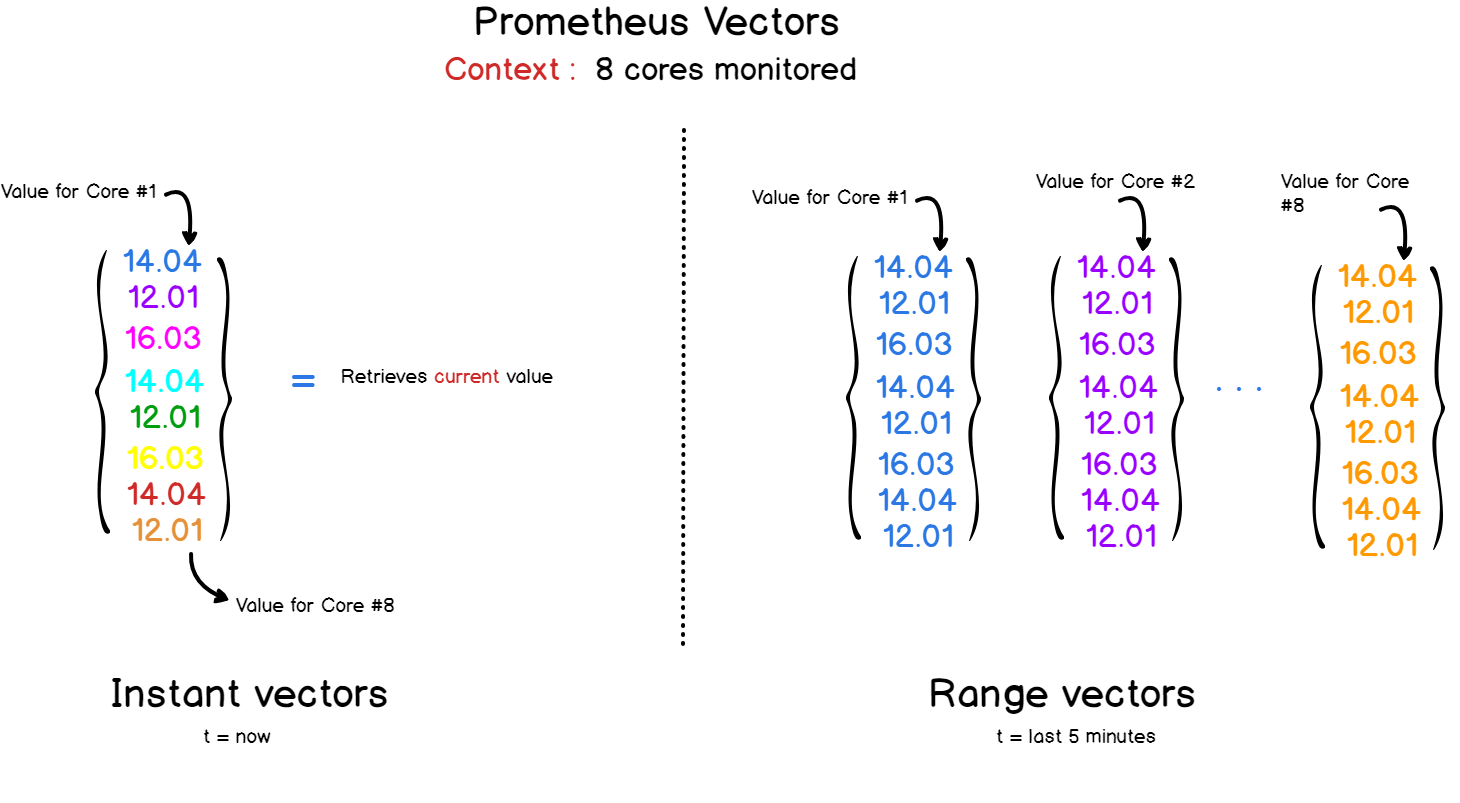
Quel genre de vecteurs?
Il existe deux types de vecteurs dans Prométhée et PromQL:
- Des vecteurs instantanés qui représentent toutes les métriques par le dernier horodatage.
- Vecteurs avec une plage de temps : si vous avez besoin de regarder le développement d'une métrique dans le temps, vous pouvez spécifier une plage de temps dans une demande à Prometheus. En conséquence, vous obtiendrez un vecteur qui combine toutes les valeurs enregistrées pour la période sélectionnée.
L'API PromQL fournit un ensemble de fonctions pour les opérations avec des données dans les requêtes.
Vous pouvez trier les valeurs, leur appliquer des fonctions mathématiques (par exemple, calculer des dérivées ou des exposants) et même faire des prédictions (par exemple, en utilisant le modèle Holt-Winters).
5. Instrumentation
L'instrumentation est une autre partie importante de Prométhée. Vous instrumentez les applications avant d'en extraire des données.
Dans Prometheus, l'instrumentation signifie l'ajout de bibliothèques clientes à l'application pour fournir des métriques Prometheus.
L'instrumentation est disponible pour la plupart des langages de programmation courants: par exemple, Python, Java, Ruby, Go et même Node ou C # .
En substance, vous créez des objets de mémoire (par exemple, des compteurs ou des compteurs) qui augmenteront ou diminueront dynamiquement la valeur.
Ensuite, vous choisissez où fournir les métriques. Prometheus les récupérera à partir de là et les enregistrera dans leur base de données de séries chronologiques.
6. Exportateurs
Dans les applications que vous avez écrites, il est très pratique de personnaliser les mesures fournies et de les modifier au fil du temps à l'aide de l'instrumentation.
Pour les applications, serveurs et bases de données bien connus, Prometheus propose des exportateurs avec lesquels vous pouvez surveiller les cibles .
Ces exportateurs sont généralement représentés sous forme d'images Docker et sont faciles à personnaliser. Ils fournissent un ensemble de mesures prédéfinies et des tableaux de bord souvent prêts à l'emploi avec lesquels vous pouvez configurer la surveillance en quelques minutes.
Exemples d'exportateurs:
- Exportateurs de bases de données: pour les bases de données MongoDB, les serveurs SQL et MySQL.
- Exportateurs HTTP : pour les serveurs HAProxy, Apache ou NGINX.
- Exportateurs Unix : les performances du système peuvent être surveillées à l'aide des exportateurs de nœuds intégrés, qui fournissent toutes les métriques du système sans configuration supplémentaire.
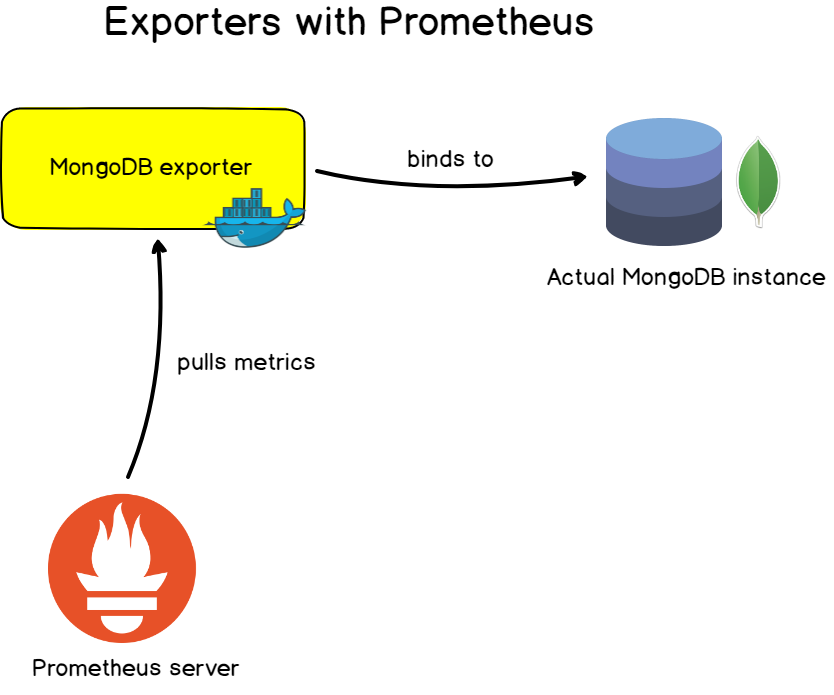
Quelques mots sur la compatibilité mutuelle
La plupart des bases de données de séries chronologiques prennent en charge l'interopérabilité de leurs systèmes.
Prometheus n'est pas le seul système de surveillance avec ses exigences métriques. Par exemple, InfluxDB (via Telegraf), CollectD , StatsD et Nagios ont également leurs propres normes.
Par conséquent, pour l'interaction de différents systèmes, des exportateurs sont créés. Même si Telegraf n'envoie pas les métriques au format accepté par Prometheus, Telegraf peut envoyer ces métriques à l'exportateur InfluxDB, d'où Prometheus les récupérera ensuite.
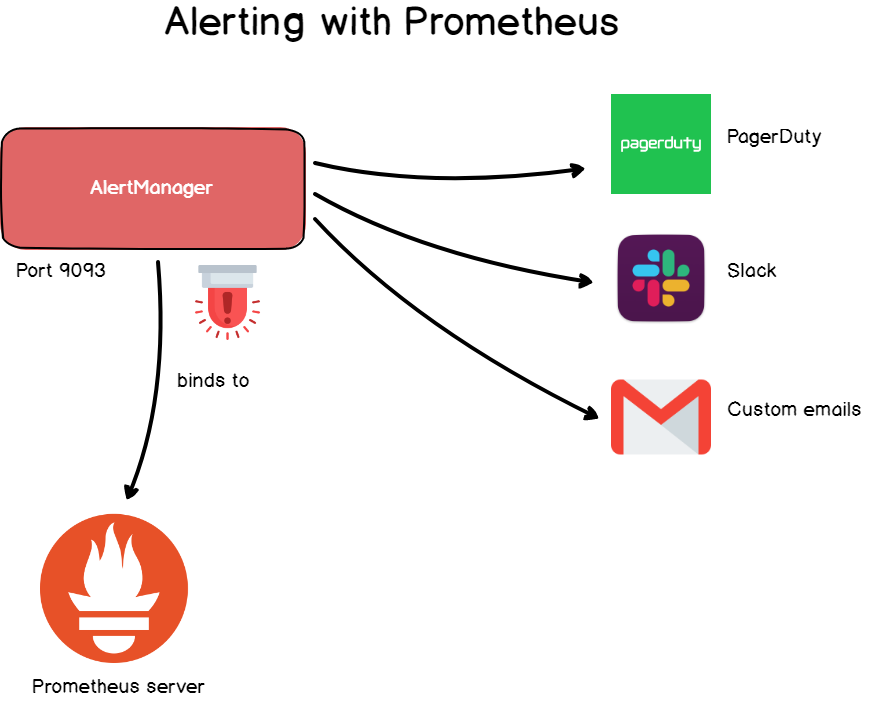
7. Alertes
Lorsque vous travaillez avec des bases de données de séries chronologiques, vous avez besoin de la rétroaction des données, et les gestionnaires d'alerte en sont responsables.
À Grafana, les alertes sont courantes, mais elles sont également disponibles dans Prometheus via le gestionnaire d'alertes.
Alert Manager est un outil distinct qui rejoint Prometheus et lance des sirènes personnalisées .
Les alertes sont définies dans le fichier de configuration et définissent un ensemble de règles pour les métriques. Si la conformité à la règle se produit dans la série chronologique, une alerte est déclenchée et envoyée aux destinataires spécifiés.
Comme dans Grafana, vous pouvez spécifier l'adresse e-mail, le webhook Slack, PagerDuty et les objets HTTP personnalisés en tant que destinataire.
Partie III. Exemples de Prométhée

Et, bien sûr, chaque guide devrait avoir des exemples pratiques . Comme j'aime à le dire, la technologie n'est pas une fin en soi et doit remplir une tâche spécifique.
Nous en parlerons.
1. DevOps
Avec tous ces exportateurs pour différents systèmes, bases de données et serveurs, il est évident que Prometheus est principalement destiné à l' industrie DevOps .
Nous savons qu'il existe de nombreux fournisseurs concurrents et des solutions personnalisées dans ce domaine.
Prometheus est parfait pour DevOps.
L'installation et l'exécution des instances ne nécessitent presque aucun effort et vous pouvez facilement activer et configurer n'importe quel outil auxiliaire.
En détectant des cibles - par exemple, via un exportateur de fichiers - c'est une excellente solution pour les piles où les conteneurs et les architectures distribuées sont largement utilisés.
Dans un environnement où les instances sont constamment créées et supprimées, aucune pile DevOps ne peut se passer de la découverte de service .
2. Santé
Aujourd'hui, les solutions de surveillance sont nécessaires non seulement en informatique. Ils sont également utilisés dans les grandes industries qui fournissent des architectures de soins de santé flexibles et évolutives.
La demande augmente et les architectures informatiques doivent s'y conformer. Si vous ne disposez pas d'un outil fiable pour surveiller l'ensemble de l'infrastructure, vous courez le risque de graves interruptions de service . Déjà dans le secteur de la santé, un tel danger doit définitivement être minimisé.
Cet exemple a été abordé sur opensource.com dans l'article suivant .
3. Services financiers
Le dernier exemple a été donné lors de la conférence InfoQ, qui a discuté de l'utilisation de Prométhée dans les institutions financières.
Jamie Christian et Alan Strader montrent comment ils utilisent Prometheus pour surveiller leur infrastructure à Northern Trust. Très instructif, je vous conseille de regarder.
Partie X. Et ensuite?

Il est temps de passer de la théorie à la pratique .
Aujourd'hui, vous vous êtes familiarisé avec les bases de Prometheus, avez appris quelles fonctions il remplit, avec quels outils et systèmes il fonctionne et quels termes il utilise.
Vous disposez maintenant de tout ce dont vous avez besoin pour créer votre solution de surveillance .
Pour commencer avec Prometheus, étudiez tous les exportateurs disponibles .
Installez ensuite les outils nécessaires, créez votre premier tableau de bord - et c'est parti!
Si vous avez besoin d'inspiration, lisez mon article sur la façon de surveiller une machine Linux avec Prometheus et Grafana . Il y a des instructions pour configurer les outils et le premier tableau de bord.
J'espère que vous avez appris quelque chose de nouveau.
Si vous avez un sujet pour mon prochain article, partagez-le.
Restez avec bonheur!