D'importants travaux scientifiques de 2012 ont transformé le domaine des logiciels de reconnaissance d'images

Aujourd'hui, je peux, par exemple, ouvrir Google Photos, écrire «plage» et voir un tas de mes photos des différentes plages que j'ai visitées au cours de la dernière décennie. Et je n'ai jamais signé mes photos - Google reconnaît les plages sur celles-ci en fonction de leur contenu. Cette fonctionnalité apparemment ennuyeuse est basée sur une technologie appelée «réseau neuronal convolutionnel profond», qui permet aux programmes de comprendre les images à l'aide d'une méthode complexe qui n'était pas disponible pour les technologies des générations précédentes.
Ces dernières années, les chercheurs ont découvert que la précision des logiciels s'améliore à mesure qu'ils construisent des réseaux neuronaux (NS) plus profonds et les forment sur des ensembles de données de plus en plus grands. Cela a créé un besoin insatiable de puissance de calcul et a enrichi les fabricants de GPU tels que Nvidia et AMD. Il y a quelques années, Google a développé ses propres puces spéciales pour l'Assemblée nationale, tandis que d'autres entreprises tentent de la suivre.
Chez Tesla, par exemple, Andrei Karpati, un expert du deep learning, a été nommé à la tête du projet Autopilot. Maintenant, le constructeur automobile développe sa propre puce pour accélérer le travail de la NS dans les futures versions du pilote automatique. Ou prenez Apple: les puces A11 et A12, centrales des derniers iPhones, ont un "
processeur neuronal " Neural Engine qui accélère le NS et permet aux applications de reconnaissance d'image et de voix de mieux fonctionner.
Les experts que j'ai interviewés pour cet article suivent le début du boom de l'apprentissage en profondeur pour un travail spécifique: AlexNet, du nom de l'auteur principal, Alex Krizhevsky. «Je crois que 2012 a été une année marquante lorsque le travail d'AlexNet est sorti», a déclaré Sean Gerrish, expert en défense et auteur du livre «
How Smart Cars Think ».
Jusqu'en 2012, les réseaux de neurones profonds (GNS) étaient un peu un remous dans le monde de la région de Moscou. Mais Krizhevsky et ses collègues de l'Université de Toronto ont ensuite participé au prestigieux concours de reconnaissance d'image, et leur programme a dépassé de façon spectaculaire en précision tout ce qui a été développé avant lui. Presque instantanément, STS est devenu la technologie de pointe en matière de reconnaissance d'image. D'autres chercheurs utilisant cette technologie ont rapidement démontré de nouvelles améliorations de la précision de reconnaissance.
Dans cet article, nous allons approfondir l'apprentissage en profondeur. Je vais expliquer ce qu'est NS, comment ils sont formés et pourquoi ils ont besoin de telles ressources informatiques. Et puis je vais expliquer pourquoi un certain type de NS - les réseaux de convolution profonde - comprennent si bien les images. Ne vous inquiétez pas, il y aura beaucoup de photos.
Un exemple simple avec un neurone
Le concept de «réseau neuronal» peut vous sembler vague, alors commençons par un exemple simple. Supposons que vous vouliez que l'Assemblée nationale décide de conduire une voiture en fonction des feux de circulation verts, jaunes et rouges. NS peut résoudre ce problème avec un seul neurone.

Un neurone reçoit des données d'entrée (1 - activé, 0 - désactivé), multiplie par le poids approprié et additionne toutes les valeurs des poids. Ensuite, le neurone ajoute un décalage qui définit la valeur de seuil pour "l'activation" du neurone. Dans ce cas, si la sortie est positive, nous pensons que le neurone s'est activé - et vice versa. Le neurone équivaut à l'inégalité "vert - rouge - 0,5> 0". Si cela s'avère vrai - c'est-à-dire que le vert est allumé et que le rouge n'est pas allumé - alors la voiture devrait partir.
Dans la vraie NS, les neurones artificiels font un autre pas. En additionnant une entrée pondérée et en ajoutant un décalage, le neurone utilise une fonction d'activation non linéaire. Souvent utilisée est une sigmoïde, une fonction en forme de S, donnant toujours une valeur de 0 à 1.
L'utilisation de la fonction d'activation ne changera pas le résultat de notre modèle de feu de signalisation simple (nous avons juste besoin d'utiliser une valeur de seuil de 0,5, pas de 0). Mais la non-linéarité des fonctions d'activation est nécessaire pour que les NS modélisent des fonctions plus complexes. Sans la fonction d'activation, chaque NS arbitrairement complexe est réduit à une combinaison linéaire de données d'entrée. Une fonction linéaire ne peut pas simuler des phénomènes complexes dans le monde réel. La fonction d'activation non linéaire permet au NS d'approximer
n'importe quelle fonction mathématique .
Exemple de réseau
Bien sûr, il existe de nombreuses façons d'approximer une fonction. NS se démarque par le fait que nous savons les «former» à l'aide d'une petite algèbre, d'un tas de données et d'une mer de puissance de calcul. Au lieu que le programmeur développe directement NS pour une tâche spécifique, nous pouvons créer un logiciel qui commence par un NS assez général, étudie un tas d'exemples balisés, puis modifie le NS afin qu'il donne l'étiquette correcte pour autant d'exemples que possible. On s'attend à ce que la NS finale résume les données et produise les étiquettes correctes pour les exemples qui n'étaient pas auparavant dans la base de données.
Le processus menant à cet objectif a commencé bien avant AlexNet. En 1986, un trio de chercheurs a publié un
ouvrage de référence sur la rétropropagation, une technologie qui a contribué à faire de l'apprentissage mathématique de SN complexes une réalité.
Pour imaginer comment fonctionne la rétropropagation, regardons une simple NS décrite par Michael Nielsen dans son excellent
manuel GO en ligne . Le but du réseau est de traiter l'image d'un nombre manuscrit dans une résolution de 28x28 pixels et de déterminer correctement si le nombre 0, 1, 2, etc. est écrit.
Chaque image est de 28 * 28 = 784 quantités d'entrée, dont chacune est un nombre réel de 0 à 1, indiquant combien le pixel est clair ou sombre. Nielsen a créé l'AN de ce type:
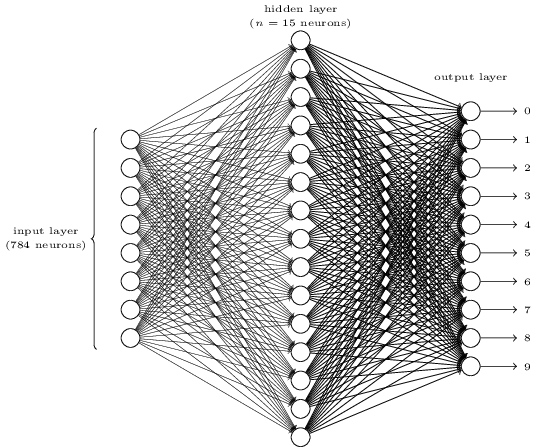
Chaque cercle au centre et dans la colonne de droite est un neurone similaire à celui que nous avons examiné dans la section précédente. Chaque neurone prend une moyenne pondérée de l'entrée, ajoute un décalage et applique une fonction d'activation. Les cercles de gauche ne sont pas des neurones, ils représentent les données d'entrée du réseau. Et bien que l'image ne montre que 8 cercles d'entrée, en fait, il y en a 784 - un pour chaque pixel.
Chacun des 10 neurones de droite doit «déclencher» son propre numéro: le premier doit s'allumer lorsqu'un 0 manuscrit est entré (et seulement dans ce cas), le second lorsque le réseau voit un 1 manuscrit (et seulement lui), et ainsi de suite.
Chaque neurone perçoit l'entrée de chaque neurone de la couche précédente. Ainsi, chacun des 15 neurones du milieu reçoit 784 valeurs d'entrée. Chacun de ces 15 neurones a un paramètre de poids pour chacune des 784 valeurs d'entrée. Cela signifie que seule cette couche a 15 * 784 = 11 760 paramètres de poids. De même, la couche de sortie contient 10 neurones, chacun recevant une entrée des 15 neurones de la couche intermédiaire, ce qui ajoute 15 * 10 = 150 paramètres de poids supplémentaires. De plus, le réseau possède 25 variables de déplacement - une pour chacun des 25 neurones.
Formation au réseau de neurones
Le but de la formation est d'affiner ces 11 935 paramètres afin de maximiser la probabilité que le neurone de sortie souhaité - et seulement lui - soit activé lorsque les réseaux donnent une image d'un chiffre manuscrit. Nous pouvons le faire avec l'ensemble d'images bien connu MNIST, où il y a 60 000 images marquées avec une résolution de 28x28 pixels.
 160 images sur 60 000 de l'ensemble MNIST
160 images sur 60 000 de l'ensemble MNISTNielsen montre comment former un réseau en utilisant 74 lignes de code Python standard - sans aucune bibliothèque pour MO. L'apprentissage commence par le choix de valeurs aléatoires pour chacun de ces 11 935 paramètres, poids et décalages. Ensuite, le programme passe par des exemples d'images, en passant par deux étapes avec chacune d'elles:
- L'étape de propagation directe calcule la sortie du réseau sur la base de l'image d'entrée et des paramètres actuels.
- L'étape de rétropropagation calcule l'écart du résultat par rapport aux données de sortie correctes et modifie les paramètres du réseau afin d'améliorer légèrement son efficacité dans cette image.
Un exemple. Disons que le réseau a reçu l'image suivante:
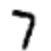
S'il est bien calibré, alors la broche «7» devrait aller à 1, et les neuf autres conclusions devraient aller à 0. Mais, disons qu'à la place, le réseau à la sortie «0» donne une valeur de 0,8. C'est trop! L'algorithme d'apprentissage modifie les poids d'entrée du neurone responsable de «0» afin qu'il se rapproche de 0 lors du prochain traitement de cette image.
Pour cela, l'algorithme de rétropropagation calcule un gradient d'erreur pour chaque poids d'entrée. Il s'agit d'une mesure de la façon dont l'erreur de sortie changera pour un changement donné de poids d'entrée. Ensuite, l'algorithme utilise le gradient pour décider de la quantité à modifier pour chaque poids d'entrée - plus le gradient est grand, plus le changement est fort.
En d'autres termes, le processus de formation «forme» les neurones de la couche de sortie à prêter moins d'attention aux entrées (neurones de la couche intermédiaire) qui les poussent à la mauvaise réponse, et plus aux entrées qui poussent dans la bonne direction.
L'algorithme répète cette étape pour tous les autres neurones de sortie. Il réduit les poids d'entrée pour les neurones "1", "2", "3", "4", "5", "6", "8" et "9" (mais pas "7") afin d'abaisser la valeur de ceux-ci neurones de sortie. Plus la valeur de sortie est élevée, plus le gradient de l'erreur de sortie est important par rapport au poids d'entrée - et plus son poids diminue.
Et vice versa, l'algorithme augmente le poids des données d'entrée pour la sortie "7", ce qui fait que le neurone produira une valeur plus élevée la prochaine fois qu'on lui donnera cette image. Encore une fois, les entrées avec des valeurs plus élevées augmenteront davantage les poids, ce qui fera que le neurone de sortie «7» accordera plus d'attention à ces entrées la prochaine fois.
Ensuite, l'algorithme devrait effectuer les mêmes calculs pour la couche intermédiaire: modifiez chaque poids d'entrée dans une direction qui réduira les erreurs de réseau - encore une fois, en rapprochant la sortie «7» de 1, et le reste à 0. Mais chaque neurone intermédiaire a une connexion avec tous les 10 jours de congé, ce qui complique les choses sous deux aspects.
Premièrement, le gradient d'erreur pour chaque neurone moyen dépend non seulement de la valeur d'entrée, mais également des gradients d'erreur dans la couche suivante. L'algorithme est appelé rétropropagation car les gradients d'erreur des couches ultérieures du réseau se propagent dans la direction opposée et sont utilisés pour calculer les gradients dans les couches précédentes.
De plus, chaque neurone intermédiaire est une entrée pour les dix jours de congé. Par conséquent, l'algorithme d'apprentissage doit calculer le gradient d'erreur, qui reflète la façon dont un changement dans un certain poids d'entrée affecte l'erreur moyenne pour toutes les sorties.
La rétropropagation est un algorithme de montée d'une colline: chaque passe rapproche les valeurs de sortie des valeurs correctes pour une image donnée, mais seulement d'un peu. Plus l'algorithme examine d'exemples, plus il grimpe la colline vers l'ensemble optimal de paramètres qui classent correctement le nombre maximal d'exemples d'entraînement. Pour atteindre une grande précision, des milliers d'exemples sont nécessaires, et l'algorithme peut avoir besoin de parcourir chaque image dans cet ensemble des dizaines de fois avant que son efficacité ne cesse de croître.
Nielsen montre comment implémenter ces 74 lignes en python. Étonnamment, un réseau formé avec un programme aussi simple peut reconnaître plus de 95% des numéros manuscrits de la base de données MNIST. Grâce à des améliorations supplémentaires, un simple réseau à deux couches peut reconnaître plus de 98% des nombres.
Percée AlexNet
Vous pourriez penser que le développement du thème de la rétropropagation était censé avoir lieu dans les années 1980 et donner lieu à des progrès rapides au sein du ministère de la Défense basé sur l'Assemblée nationale - mais cela ne s'est pas produit. Dans les années 1990 et au début des années 2000, certaines personnes travaillaient sur cette technologie, mais l'intérêt pour l'Assemblée nationale n'a pris de l'ampleur qu'au début des années 2010.
Cela peut être retracé au
concours ImageNet , un concours annuel de MO organisé par Stanford Fay Fay Lee, un spécialiste des TI. Chaque année, les concurrents reçoivent le même ensemble de plus d'un million d'images pour la formation, chacune étant manuellement étiquetée dans des catégories de plus de 1000 - de «camion de pompier» et «champignon» à «guépard». Le logiciel des participants est jugé sur la possibilité de classer d'autres images qui n'étaient pas dans l'ensemble. Un programme peut donner quelques suppositions, et son travail est considéré comme réussi si au moins l'une des cinq premières suppositions correspond à la note donnée par une personne.
La compétition a commencé en 2010 et les NS profondes n'y ont pas joué un grand rôle au cours des deux premières années. Les meilleures équipes ont utilisé différentes techniques de MO et ont obtenu des résultats assez moyens. En 2010, l'équipe a gagné avec un pourcentage d'erreurs égal à 28. En 2011 - avec une erreur de 25%.
Et puis est venu 2012. Une équipe de l'Université de Toronto a fait une
offre - plus tard surnommée AlexNet en l'honneur de l'auteur principal, Alex Krizhevsky - et a laissé les rivaux loin derrière. À l'aide de NS profonds, l'équipe a atteint un taux d'erreur de 16%. Pour le concurrent le plus proche, ce chiffre était de 26.
Le NS décrit dans l'article pour la reconnaissance de l'écriture manuscrite a deux couches, 25 neurones et près de 12 000 paramètres. AlexNet était beaucoup plus grand et plus complexe: huit couches entraînées, 650 000 neurones et 60 millions de paramètres.
Une puissance de traitement énorme est requise pour former des NS de cette taille, et AlexNet a été conçu pour tirer parti de la parallélisation massive disponible avec les GPU modernes. Les chercheurs ont compris comment diviser le travail de formation du réseau en deux GPU, ce qui a doublé la puissance. Et pourtant, malgré l'optimisation serrée, la formation réseau a pris 5-6 jours sur le matériel disponible en 2012 (sur une paire de Nvidia GTX 580 avec 3 Go de mémoire).
Il est utile d'étudier des exemples des résultats d'AlexNet pour comprendre la gravité de cette percée. Voici une image d'un article scientifique qui montre des exemples d'images et les cinq premières suppositions du réseau par leur classification:

AlexNet a pu reconnaître la tique dans la première image, bien qu'il n'y ait qu'une petite forme dans le coin. Le logiciel a non seulement correctement identifié le léopard, mais a également donné d'autres options proches - un jaguar, un guépard, un léopard des neiges, un Mau égyptien. AlexNet a étiqueté la photo de charme comme "agaric". Juste "champignon" était la deuxième version du réseau.
Les "erreurs" d'AlexNet sont également impressionnantes. Elle a marqué la photo avec un Dalmatien debout derrière un tas de cerises comme «Dalmatien», bien que l'étiquette officielle soit «cerise». AlexNet a reconnu qu'il y avait une sorte de baie sur la photo - parmi les cinq premières options étaient «raisins» et «sureau» - il n'a tout simplement pas reconnu la cerise. Sur une photo d'un lémurien de Madagascar assis sur un arbre, AlexNet a donné une liste de petits mammifères vivant sur des arbres. Je pense que beaucoup de gens (y compris moi-même) auraient mis la mauvaise signature ici.
La qualité du travail était impressionnante et a démontré que le logiciel est capable de reconnaître des objets ordinaires dans un large éventail d'orientations et d'environnements. Le GNS est rapidement devenu la technique la plus populaire pour la reconnaissance d'image, et depuis lors, le monde de MO ne l'a pas abandonnée.
«Dans le sillage du succès de la méthode basée sur GO 2012, la plupart des concurrents de 2013 sont passés à des réseaux neuronaux convolutionnels profonds», ont
écrit les sponsors d'ImageNet. Au cours des années suivantes, cette tendance s'est poursuivie et les gagnants ont ensuite travaillé sur la base de technologies de base, appliquées pour la première fois par l'équipe AlexNet. En 2017, les concurrents, utilisant des NS plus profondes, ont sérieusement réduit le taux d'erreur à moins de trois. Compte tenu de la complexité de la tâche, les ordinateurs ont dans une certaine mesure appris à la résoudre mieux que de nombreuses personnes.
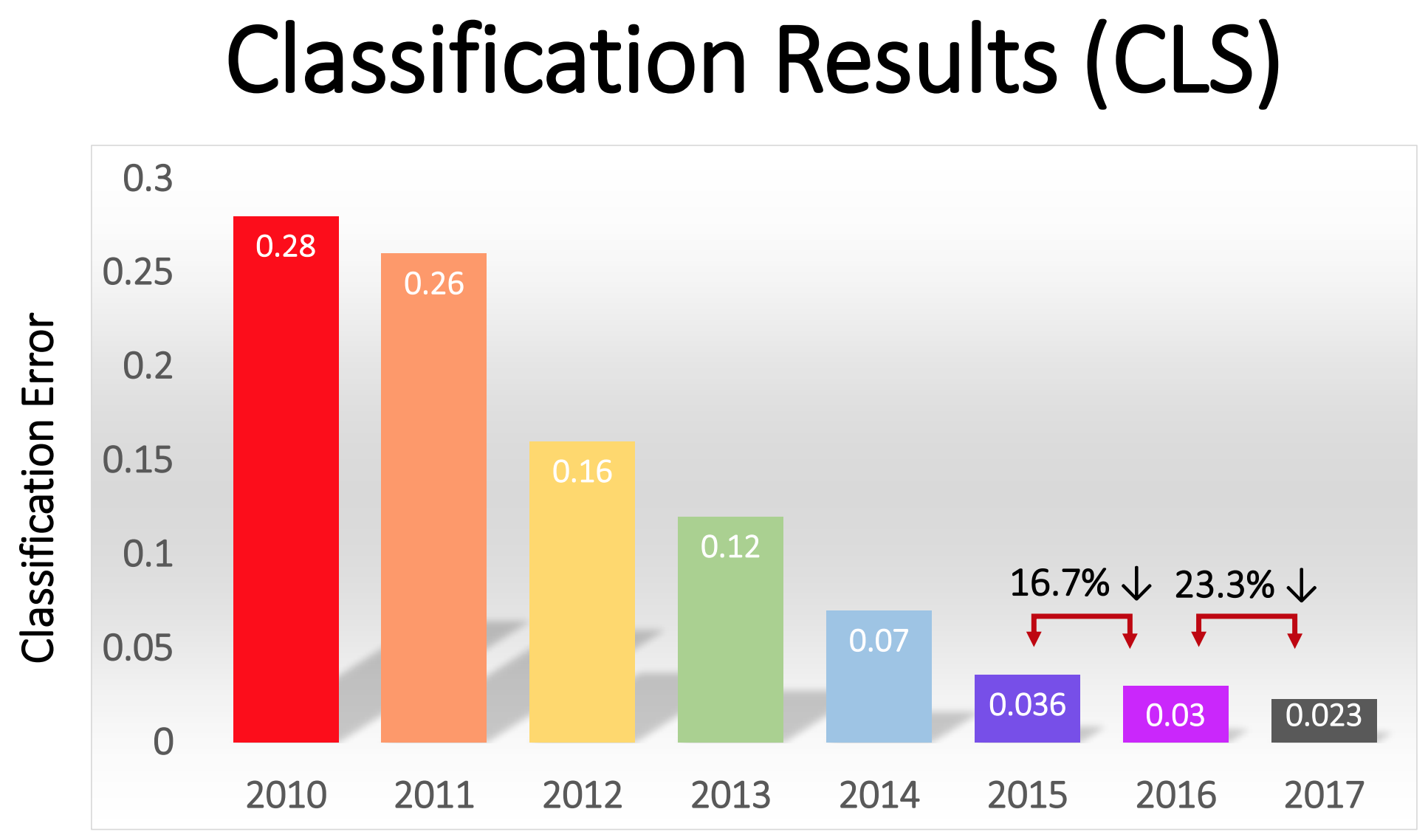 Le pourcentage d'erreurs dans la classification des images au cours des différentes années
Le pourcentage d'erreurs dans la classification des images au cours des différentes annéesRéseaux de convolution: un concept
Techniquement, AlexNet était un NS convolutionnel. Dans cette section, j'expliquerai ce que fait le réseau neuronal convolutif (SNA), et pourquoi cette technologie est devenue d'une importance cruciale pour les algorithmes de reconnaissance de formes modernes.
Le réseau simple discuté précédemment pour la reconnaissance de l'écriture manuscrite était complètement connecté: chaque neurone de la première couche était une entrée pour chaque neurone de la deuxième couche. Une telle structure fonctionne assez bien sur des tâches simples avec reconnaissance des nombres dans les images 28x28 pixels. Mais cela ne se modifie pas bien.
Dans la base de données de chiffres manuscrits du MNIST, tous les caractères sont centrés. Cela simplifie considérablement l'apprentissage, car, disons, les sept auront toujours plusieurs pixels sombres en haut et à droite, et le coin inférieur gauche est toujours blanc. Zéro aura presque toujours une tache blanche au milieu et des pixels sombres sur les bords. Un réseau simple et entièrement connecté peut reconnaître de tels modèles assez facilement.
Mais supposons que vous vouliez créer un NS capable de reconnaître des nombres qui peuvent être situés n'importe où sur une image plus grande. Un réseau entièrement connecté ne fonctionnera pas aussi bien avec cette tâche, car il n'a pas de moyen efficace de reconnaître des fonctionnalités similaires dans des formulaires situés dans différentes parties de l'image. Si, dans votre jeu de données d'entraînement, la plupart des sept sont situés dans le coin supérieur gauche, votre réseau reconnaîtra mieux les sept dans le coin supérieur gauche que dans toute autre partie de l'image.
Théoriquement, ce problème peut être résolu en s'assurant que votre jeu possède de nombreux exemples de chaque chiffre dans chacune des positions possibles. Mais en pratique, ce sera un énorme gaspillage de ressources. Avec l'augmentation de la taille de l'image et de la profondeur du réseau, le nombre de liens - et le nombre de paramètres de poids - augmentera de manière explosive. Vous aurez besoin de beaucoup plus d'images d'entraînement (et de puissance de calcul) pour obtenir une précision adéquate.
Lorsqu'un réseau de neurones apprend à reconnaître une forme située à un endroit d'une image, il doit être capable d'appliquer ces connaissances pour reconnaître la même forme dans d'autres parties de l'image. SNA fournit une solution élégante à ce problème."C'est comme si vous preniez un pochoir et le fixiez à tous les endroits de l'image", a déclaré le chercheur en IA Jai Teng. - Vous avez un pochoir avec une photo d'un chien, et vous le fixez d'abord dans le coin supérieur droit de l'image pour voir s'il y a un chien là-bas? Sinon, vous déplacez un peu le pochoir. Et donc pour l'image entière. Peu importe où est l'image du chien. Le pochoir correspondra à elle. Vous n'avez pas besoin que chaque partie du réseau apprenne sa propre classification des chiens. »Imaginez que nous prenions une grande image et la divisions en carrés de 28 x 28 pixels. Ensuite, nous pourrons alimenter chaque carré d'un réseau entièrement connecté qui reconnaît l'écriture que nous avons étudiée auparavant. Si la sortie "7" est déclenchée dans au moins un des carrés, ce sera un signe qu'il y a un sept dans l'image entière. C'est exactement ce que font les réseaux convolutifs.Fonctionnement des réseaux convolutionnels dans AlexNet
Dans les réseaux convolutifs, ces «pochoirs» sont appelés détecteurs de caractéristiques et la zone qu'ils étudient est connue sous le nom de champ récepteur. Les vrais détecteurs de caractéristiques fonctionnent avec des champs beaucoup plus petits qu'un carré avec un côté de 28 pixels. Dans AlexNet, les détecteurs de caractéristiques de la première couche convolutive fonctionnaient avec un champ récepteur de 11 x 11 pixels. Dans les couches suivantes, les champs récepteurs avaient une largeur de 3 à 5 unités.Au cours de la traversée, le détecteur de signes de l'image d'entrée produit une carte des signes: un réseau bidimensionnel, sur lequel on note la force d'activation du détecteur dans différentes parties de l'image. Les couches convolutives ont généralement plus d'un détecteur, et chacune d'elles scanne l'image à la recherche de motifs différents. AlexNet avait 96 détecteurs de fonctionnalités sur la première couche, distribuant 96 cartes de fonctionnalités. Pour mieux comprendre cela, considérez une représentation visuelle des modèles étudiés par chacun des 96 détecteurs de première couche AlexNet après avoir formé le réseau. Il existe des détecteurs à la recherche de lignes horizontales ou verticales, de transitions du clair au sombre, de motifs d'échecs et de nombreuses autres formes.Une image en couleur est généralement représentée comme une carte de pixels avec trois nombres pour chaque pixel: la valeur du rouge, du vert et du bleu. La première couche d'AlexNet prend cette vue et la transforme en vue utilisant 96 nombres. Chaque «pixel» de cette image a 96 valeurs, une pour chaque détecteur de caractéristiques.Dans cet exemple, la première des 96 valeurs indique si un point de l'image correspond à ce modèle:
Pour mieux comprendre cela, considérez une représentation visuelle des modèles étudiés par chacun des 96 détecteurs de première couche AlexNet après avoir formé le réseau. Il existe des détecteurs à la recherche de lignes horizontales ou verticales, de transitions du clair au sombre, de motifs d'échecs et de nombreuses autres formes.Une image en couleur est généralement représentée comme une carte de pixels avec trois nombres pour chaque pixel: la valeur du rouge, du vert et du bleu. La première couche d'AlexNet prend cette vue et la transforme en vue utilisant 96 nombres. Chaque «pixel» de cette image a 96 valeurs, une pour chaque détecteur de caractéristiques.Dans cet exemple, la première des 96 valeurs indique si un point de l'image correspond à ce modèle: La deuxième valeur indique si un point d'image coïncide avec un tel motif:
La deuxième valeur indique si un point d'image coïncide avec un tel motif: La troisième valeur indique si un point d'image coïncide avec un tel motif:
La troisième valeur indique si un point d'image coïncide avec un tel motif: Et ainsi de suite pour 93 détecteurs d'entités dans la première couche AlexNet. La première couche produit une nouvelle représentation de l'image, où chaque pixel est un vecteur en 96 dimensions (j'expliquerai plus tard que cette représentation est réduite de 4 fois).Il s'agit de la première couche d'AlexNet. Ensuite, il y a quatre autres couches convolutives, chacune prenant la sortie de la précédente comme entrée.Comme nous l'avons vu, la première couche révèle des motifs de base, tels que des lignes horizontales et verticales, des transitions de la lumière à l'obscurité et des courbes. Le deuxième niveau les utilise comme élément de base pour reconnaître des formes légèrement plus complexes. Par exemple, la deuxième couche pourrait avoir un détecteur d'entités qui trouve des cercles en utilisant une combinaison des sorties des détecteurs d'entités de la première couche qui trouvent des courbes. La troisième couche trouve des formes encore plus complexes en combinant les fonctionnalités de la deuxième couche. Les quatrième et cinquième trouvent des motifs encore plus complexes.Les chercheurs Matthew Zeiler et Rob Fergus ont publié un excellent travail en 2014 , qui fournit des moyens très utiles pour visualiser les modèles reconnus par un réseau neuronal à cinq couches similaire à ImageNet.Dans le diaporama suivant tiré de leur travail, chaque image, sauf la première, a deux moitiés. Sur la droite, vous verrez des exemples de vignettes qui ont fortement activé un détecteur de fonction particulier. Ils sont collectés en neuf - et chaque groupe correspond à son propre détecteur. À gauche, une carte montrant exactement quels pixels de cette miniature sont les plus responsables de la correspondance. Cela est particulièrement évident sur la cinquième couche, car il existe des détecteurs de caractéristiques qui réagissent fortement aux chiens, aux logos, aux roues, etc.
Et ainsi de suite pour 93 détecteurs d'entités dans la première couche AlexNet. La première couche produit une nouvelle représentation de l'image, où chaque pixel est un vecteur en 96 dimensions (j'expliquerai plus tard que cette représentation est réduite de 4 fois).Il s'agit de la première couche d'AlexNet. Ensuite, il y a quatre autres couches convolutives, chacune prenant la sortie de la précédente comme entrée.Comme nous l'avons vu, la première couche révèle des motifs de base, tels que des lignes horizontales et verticales, des transitions de la lumière à l'obscurité et des courbes. Le deuxième niveau les utilise comme élément de base pour reconnaître des formes légèrement plus complexes. Par exemple, la deuxième couche pourrait avoir un détecteur d'entités qui trouve des cercles en utilisant une combinaison des sorties des détecteurs d'entités de la première couche qui trouvent des courbes. La troisième couche trouve des formes encore plus complexes en combinant les fonctionnalités de la deuxième couche. Les quatrième et cinquième trouvent des motifs encore plus complexes.Les chercheurs Matthew Zeiler et Rob Fergus ont publié un excellent travail en 2014 , qui fournit des moyens très utiles pour visualiser les modèles reconnus par un réseau neuronal à cinq couches similaire à ImageNet.Dans le diaporama suivant tiré de leur travail, chaque image, sauf la première, a deux moitiés. Sur la droite, vous verrez des exemples de vignettes qui ont fortement activé un détecteur de fonction particulier. Ils sont collectés en neuf - et chaque groupe correspond à son propre détecteur. À gauche, une carte montrant exactement quels pixels de cette miniature sont les plus responsables de la correspondance. Cela est particulièrement évident sur la cinquième couche, car il existe des détecteurs de caractéristiques qui réagissent fortement aux chiens, aux logos, aux roues, etc. La première couche - motifs et formes simples. La
La première couche - motifs et formes simples. La deuxième couche - de petites structures commencent à apparaître. Les
deuxième couche - de petites structures commencent à apparaître. Les détecteurs d'entités sur la troisième couche peuvent reconnaître des formes plus complexes, telles que des roues de voiture, des nids d'abeilles et même des silhouettes de personnes
détecteurs d'entités sur la troisième couche peuvent reconnaître des formes plus complexes, telles que des roues de voiture, des nids d'abeilles et même des silhouettes de personnes La quatrième couche est capable de distinguer des formes complexes, telles que les visages de chiens ou les pattes d'oiseaux.
La quatrième couche est capable de distinguer des formes complexes, telles que les visages de chiens ou les pattes d'oiseaux. La cinquième couche peut reconnaître des formes très complexes.En regardant les images, vous pouvez voir comment chaque couche suivante est capable de reconnaître des motifs de plus en plus complexes. La première couche reconnaît des motifs simples qui ne ressemblent à rien. Le second reconnaît les textures et les formes simples. Par la troisième couche, des formes reconnaissables telles que des roues et des sphères rouge-orange (tomates, coccinelles, autre chose) deviennent visibles.Dans la première couche, le côté du champ récepteur est de 11 et dans les derniers, de trois à cinq. Mais rappelez-vous que les calques ultérieurs reconnaissent les cartes d'entités générées par les calques antérieurs, de sorte que chacun de leurs «pixels» désigne plusieurs pixels de l'image d'origine. Par conséquent, le champ récepteur de chaque couche comprend une partie plus grande de la première image que les couches précédentes. C'est en partie la raison pour laquelle les miniatures dans les calques ultérieurs semblent plus complexes que dans les précédentes.La cinquième, dernière couche du réseau est capable de reconnaître une gamme impressionnante d'éléments. Par exemple, regardez cette image que j'ai sélectionnée dans le coin supérieur droit de l'image correspondant au cinquième calque:
La cinquième couche peut reconnaître des formes très complexes.En regardant les images, vous pouvez voir comment chaque couche suivante est capable de reconnaître des motifs de plus en plus complexes. La première couche reconnaît des motifs simples qui ne ressemblent à rien. Le second reconnaît les textures et les formes simples. Par la troisième couche, des formes reconnaissables telles que des roues et des sphères rouge-orange (tomates, coccinelles, autre chose) deviennent visibles.Dans la première couche, le côté du champ récepteur est de 11 et dans les derniers, de trois à cinq. Mais rappelez-vous que les calques ultérieurs reconnaissent les cartes d'entités générées par les calques antérieurs, de sorte que chacun de leurs «pixels» désigne plusieurs pixels de l'image d'origine. Par conséquent, le champ récepteur de chaque couche comprend une partie plus grande de la première image que les couches précédentes. C'est en partie la raison pour laquelle les miniatures dans les calques ultérieurs semblent plus complexes que dans les précédentes.La cinquième, dernière couche du réseau est capable de reconnaître une gamme impressionnante d'éléments. Par exemple, regardez cette image que j'ai sélectionnée dans le coin supérieur droit de l'image correspondant au cinquième calque: Les neuf images sur la droite peuvent ne pas se ressembler. Mais si vous regardez les neuf cartes thermiques sur la gauche, vous verrez que ce détecteur de fonctionnalité ne se concentre pas sur les objets au premier plan des photos. Au lieu de cela, il se concentre sur l'herbe à l'arrière-plan de chacun d'eux!De toute évidence, un détecteur d'herbe est utile si l'une des catégories que vous essayez d'identifier est «herbe», mais il peut être utile pour de nombreuses autres catégories. Après cinq couches convolutives, AlexNet a trois couches complètement connectées, comme notre réseau pour la reconnaissance de l'écriture manuscrite. Ces couches examinent chacune des cartes d'entités émises par cinq couches convolutives, essayant de classer l'image dans l'une des 1000 catégories possibles.Donc, s'il y a de l'herbe en arrière-plan, alors avec une forte probabilité, il y aura un animal sauvage dans l'image. En revanche, s'il y a de l'herbe à l'arrière-plan, il est moins probable qu'il s'agisse d'une image de mobilier dans la maison. Ces détecteurs de caractéristiques de la cinquième couche et d'autres fournissent une tonne d'informations sur le contenu probable de la photo. Les dernières couches du réseau synthétisent ces informations afin de fournir une estimation factuelle de ce qui est généralement représenté sur l'image.
Les neuf images sur la droite peuvent ne pas se ressembler. Mais si vous regardez les neuf cartes thermiques sur la gauche, vous verrez que ce détecteur de fonctionnalité ne se concentre pas sur les objets au premier plan des photos. Au lieu de cela, il se concentre sur l'herbe à l'arrière-plan de chacun d'eux!De toute évidence, un détecteur d'herbe est utile si l'une des catégories que vous essayez d'identifier est «herbe», mais il peut être utile pour de nombreuses autres catégories. Après cinq couches convolutives, AlexNet a trois couches complètement connectées, comme notre réseau pour la reconnaissance de l'écriture manuscrite. Ces couches examinent chacune des cartes d'entités émises par cinq couches convolutives, essayant de classer l'image dans l'une des 1000 catégories possibles.Donc, s'il y a de l'herbe en arrière-plan, alors avec une forte probabilité, il y aura un animal sauvage dans l'image. En revanche, s'il y a de l'herbe à l'arrière-plan, il est moins probable qu'il s'agisse d'une image de mobilier dans la maison. Ces détecteurs de caractéristiques de la cinquième couche et d'autres fournissent une tonne d'informations sur le contenu probable de la photo. Les dernières couches du réseau synthétisent ces informations afin de fournir une estimation factuelle de ce qui est généralement représenté sur l'image.Ce qui rend les couches convolutives différentes: les poids d'entrée communs
Nous avons vu que les détecteurs de caractéristiques sur les couches convolutives montrent une reconnaissance de formes impressionnante, mais jusqu'à présent, je n'ai pas expliqué comment les réseaux convolutifs fonctionnent réellement.La couche convolutionnelle (SS) est constituée de neurones. Ils, comme tous les neurones, prennent une moyenne pondérée à l'entrée et utilisent la fonction d'activation. Les paramètres sont entraînés à l'aide de techniques de rétropropagation.Mais, contrairement aux NS précédents, le SS n'est pas entièrement connecté. Chaque neurone reçoit l'entrée d'une petite fraction des neurones de la couche précédente. Et, surtout, les neurones de réseau convolutionnels ont des poids d'entrée communs.Examinons plus en détail le premier neurone du premier AlexNet SS. Le champ récepteur de cette couche mesure 11x11 pixels, de sorte que le premier neurone examine un carré de 11x11 pixels dans un coin de l'image. Ce neurone reçoit une entrée de ces 121 pixels, et chaque pixel a trois valeurs - rouge, vert et bleu. Par conséquent, en général, le neurone a 363 paramètres d'entrée. Comme tout neurone, celui-ci prend une moyenne pondérée de 363 paramètres, et leur applique une fonction d'activation. Et, comme les paramètres d'entrée sont 363, les paramètres de poids ont également besoin de 363.Le deuxième neurone de la première couche est similaire au premier. Il étudie également les carrés de 11x11 pixels, mais son champ récepteur est décalé de quatre pixels par rapport au premier. Les deux champs ont un chevauchement de 7 pixels, de sorte que le réseau ne perd pas de vue les motifs intéressants qui sont tombés à la jonction de deux carrés. Le deuxième neurone prend également 363 paramètres décrivant le carré 11x11, multiplie chacun d'eux en poids, ajoute et applique la fonction d'activation.Mais au lieu d'utiliser un ensemble distinct de 363 poids, le deuxième neurone utilise les mêmes poids que le premier. Le pixel supérieur gauche du premier neurone utilise les mêmes poids que le pixel supérieur gauche du second. Par conséquent, les deux neurones recherchent le même schéma; leurs champs récepteurs sont simplement décalés de 4 pixels les uns par rapport aux autres.Naturellement, il y a plus de deux neurones: dans le réseau 55x55, il y a 3025 neurones. Chacun d'eux utilise le même ensemble de 363 poids que les deux premiers. Ensemble, tous les neurones forment un détecteur de caractéristiques qui "scanne" l'image pour le motif souhaité, qui peut être situé n'importe où.N'oubliez pas que la première couche AlexNet possède 96 détecteurs de caractéristiques. Les 3025 neurones que je viens de mentionner constituent l'un de ces 96 détecteurs. Chacun des 95 restants est un groupe distinct de 3025 neurones. Chaque groupe de 3025 neurones utilise un ensemble commun de 363 poids - cependant, pour chacun des 95 groupes, il possède le sien.Les HF sont formés en utilisant la même rétropropagation que celle utilisée pour les réseaux entièrement connectés, mais la structure convolutionnelle rend le processus d'apprentissage plus efficace et efficient."L'utilisation de la convolution aide vraiment - les paramètres peuvent être réutilisés", a déclaré Sean Gerrish, un expert en défense et autorisation. Cela réduit considérablement le nombre de poids d'entrée que le réseau doit apprendre, ce qui lui permet de produire de meilleurs résultats avec moins d'exemples de formation.L'apprentissage d'une partie de l'image permet une meilleure reconnaissance du même motif dans d'autres parties de l'image. Cela permet au réseau d'atteindre des performances élevées sur un nombre beaucoup plus faible d'exemples de formation.Les gens ont rapidement réalisé la puissance des réseaux convolutionnels profonds.
Le travail d'AlexNet est devenu une sensation dans la communauté universitaire de la région de Moscou, mais son importance a été rapidement comprise dans l'industrie informatique. Google était particulièrement intéressé par elle.
En 2013, Google a acquis une startup fondée par les auteurs AlexNet. La société a utilisé cette technologie pour ajouter une nouvelle fonction de recherche de photos à Google Photos. "Nous avons pris la recherche avancée et l'avons mise en service un peu plus de six mois plus tard", a écrit Chuck Rosenberg de Google.
Pendant ce temps, en 2013, il a été décrit comment Google utilise GSS pour reconnaître les adresses des photos de Google Street View. «Notre système nous a aidés à extraire près de 100 millions d'adresses physiques de ces images», ont écrit les auteurs.
Les chercheurs ont découvert que l'efficacité de la NS augmente avec la profondeur. "Nous avons constaté que l'efficacité de cette approche augmente avec la profondeur du SCN, et la plus profonde des architectures que nous avons formées donne les meilleurs résultats", a écrit l'équipe de Google Street View. «Nos expériences suggèrent que des architectures plus profondes peuvent produire une plus grande précision, mais avec un ralentissement de l'efficacité.»
Ainsi, après AlexNet, les réseaux ont commencé à s'approfondir. L'équipe Google a fait une offre au concours en 2014 - deux ans seulement après la victoire d'AlexNet en 2012. Elle était également basée sur un SNA profond, mais Goolge a utilisé un réseau beaucoup plus profond de 22 couches pour atteindre un taux d'erreur de 6,7% - il s'agit d'une amélioration majeure par rapport aux 16% d'AlexNet.
Mais en même temps, les réseaux plus profonds ne fonctionnaient mieux qu'avec des ensembles de données de formation plus importants. Par conséquent, Gerrish affirme que l'ensemble de données ImageNet et la concurrence ont joué un rôle majeur dans le succès du SCN. Rappelons qu'au concours ImageNet, les participants reçoivent un million d'images et sont invités à les trier en 1 000 catégories.
"Si vous avez un million d'images pour la formation, alors chaque classe comprend 1 000 images", a déclaré Gerrish. Sans un si grand ensemble de données, at-il dit, "vous auriez trop d'options pour former le réseau".
Ces dernières années, les experts se concentrent de plus en plus sur la collecte d'une énorme quantité de données pour former des réseaux plus profonds et plus précis. C'est pourquoi les entreprises développant des voitures robotisées se concentrent sur la circulation sur les routes publiques - des images et des vidéos de ces voyages sont envoyées au siège social et utilisées pour former les entreprises NS.
Boom du Deep Learning
La découverte du fait que des réseaux plus profonds et des ensembles de données plus importants peuvent améliorer les performances de NS a créé une soif insatiable de puissance de calcul toujours plus grande. L'une des principales composantes du succès d'AlexNet était l'idée que la formation matricielle est utilisée dans la formation NS, qui peut être effectuée efficacement sur des GPU bien parallélisables.
"Les NS sont bien parallélisés", a déclaré Jai Ten, un chercheur de MO. Les cartes graphiques - fournissant une puissance de traitement parallèle énorme pour les jeux vidéo - se sont avérées utiles pour les NS.
"La partie centrale du travail du GPU, la multiplication très rapide de la matrice, s'est avérée être la partie centrale du travail de l'Assemblée nationale", a déclaré Ten.
Tout cela a été un succès pour les principaux fabricants de GPU, Nvidia et AMD. Les deux sociétés ont développé de nouvelles puces spécialement adaptées aux besoins de l'application MO, et maintenant les applications AI sont responsables d'une partie importante des ventes de GPU de ces sociétés.
En 2016, Google a annoncé la création d'une puce spéciale, la Tensor Processing Unit (TPU), conçue pour fonctionner à l'Assemblée nationale. "Bien que Google envisageait la possibilité de créer des circuits intégrés à usage spécial (ASIC) en 2006, cette situation est devenue urgente en 2013", a
écrit un représentant de l'entreprise l'année dernière. «C'est alors que nous avons réalisé que les besoins croissants de l'Assemblée nationale en matière de puissance de calcul pourraient nous obliger à doubler le nombre de centres de données dont nous disposons.»
Au début, seuls les propres services de Google avaient accès aux TPU, mais plus tard, la société a permis à tout le monde d'utiliser cette technologie via une plate-forme de cloud computing.
Bien sûr, Google n'est pas la seule entreprise à travailler sur des puces IA. Quelques exemples: dans les dernières versions des puces iPhone,
il existe un «noyau neuronal» optimisé pour les opérations avec le NS. Intel
développe sa propre gamme de puces optimisées pour GO. Tesla a récemment
annoncé le rejet des puces de Nvidia au profit de ses propres puces NS. On dit également qu'Amazon
travaille sur ses puces AI.
Pourquoi les réseaux de neurones profonds sont difficiles à comprendre
J'ai expliqué comment fonctionnent les réseaux de neurones, mais je n'ai pas expliqué pourquoi ils fonctionnent si bien. On ne sait pas exactement comment l'immense quantité de calculs matriciels permet à un système informatique de distinguer un jaguar d'un guépard, et du sureau de groseille.
La qualité la plus remarquable de l'Assemblée nationale est peut-être le contraire. La convolution permet au NS de comprendre la césure - ils peuvent dire si l'image du coin supérieur droit de l'image est similaire à l'image du coin supérieur gauche d'une autre image.
Mais en même temps, le SCN n'a aucune idée de la géométrie. Ils ne peuvent pas reconnaître la similitude des deux images si elles sont tournées à 45 degrés ou doublées. SNA n'essaie pas de comprendre la structure tridimensionnelle des objets et ne peut pas prendre en compte différentes conditions d'éclairage.
Mais en même temps, les NS peuvent reconnaître des photos de chiens prises de face et de côté, et peu importe si le chien occupe une petite partie de l'image, ou une grande. Comment font-ils? Il s'avère que s'il y a suffisamment de données, une approche statistique avec dénombrement direct peut faire face à la tâche. Le SCN n'est pas conçu pour «imaginer» à quoi ressemblerait une image particulière sous un angle différent ou dans des conditions différentes, mais avec un nombre suffisant d'exemples étiquetés, il peut apprendre toutes les variations possibles de l'image par simple répétition.
Il est prouvé que le système visuel des personnes fonctionne de manière similaire. Regardez quelques images - étudiez d'abord attentivement la première, puis ouvrez la seconde.
 Première photo
Première photoLe créateur de l'image a pris la photo de quelqu'un et a tourné les yeux et la bouche à l'envers. L'image semble relativement normale lorsque vous la regardez à l'envers, car le système visuel humain est habitué à voir les yeux et la bouche dans cette position. Mais si vous regardez l'image dans la bonne orientation, vous pouvez immédiatement voir que le visage est étrangement déformé.
Cela suggère que le système visuel humain est basé sur les mêmes techniques de reconnaissance de formes brutes que le NS. Si nous regardons quelque chose qui est presque toujours visible dans une seule orientation - l'œil humain - nous pouvons le reconnaître beaucoup mieux dans son orientation normale.
Les NS reconnaissent bien les images en utilisant tout le contexte disponible sur celles-ci. Par exemple, les voitures roulent généralement sur les routes. Les robes sont généralement portées sur le corps d'une femme ou suspendues dans un placard. Les avions sont généralement abattus contre le ciel ou ils gouvernent sur la piste. Personne n'enseigne spécifiquement aux NS ces corrélations, mais avec un nombre suffisant d'exemples étiquetés, le réseau lui-même peut les apprendre.
En 2015, des chercheurs de Google ont tenté de mieux comprendre les NS, en les «faisant reculer». Au lieu d'utiliser des images pour la formation des NS, ils ont utilisé des NS formés pour changer les images. Par exemple, ils ont commencé avec une image contenant du bruit aléatoire, puis l'ont progressivement modifiée pour qu'elle active fortement l'un des neurones de sortie de la NS - en fait, ils ont demandé à la NS de «dessiner» l'une des catégories qu'il a appris à reconnaître. Dans un cas intéressant, ils ont forcé la NS à générer des images qui activent la NS, entraînés à reconnaître les haltères.

"Bien sûr, il y a des haltères ici, mais pas une seule image des haltères ne semble complète sans la présence d'un corps musculaire musclé les soulevant", ont écrit des chercheurs de Google.
À première vue, cela semble étrange, mais en réalité, il n'est pas si différent de ce que font les gens. Si nous voyons un petit objet flou sur l'image, nous cherchons un indice dans son environnement pour comprendre ce qui peut s'y passer. Les gens, évidemment, parlent des images différemment, en utilisant une compréhension conceptuelle complexe du monde qui les entoure. Mais en fin de compte, le STS reconnaît bien les images, car elles tirent pleinement parti du contexte entier représenté sur elles, et ce n'est pas très différent de la façon dont les gens le font.