
Le 14 mai, alors que Trump s'apprêtait à lancer tous les chiens sur Huawei, je me suis assis paisiblement à Shenzhen sur le Huawei STW 2019 - une grande conférence pour 1000 participants - qui comprenait des rapports de
Philip Wong , vice-président de la recherche TSMC sur les perspectives de l'informatique non von Neumann architectures, et Heng Liao, boursier Huawei, scientifique en chef Huawei 2012 Lab, sur le développement d'une nouvelle architecture de processeurs tenseurs et de neuroprocesseurs. TSMC, si vous le savez, fabrique des accélérateurs neuronaux pour Apple et Huawei en utilisant la technologie 7 nm (que
peu de gens possèdent ), et Huawei est prêt à concurrencer Google et NVIDIA en termes de neuroprocesseurs.
Google en Chine est interdit, je n'ai pas pris la peine de mettre un VPN sur la tablette, j'ai donc
patriquement utilisé Yandex afin de voir quelle est la situation avec d'autres fabricants de fer similaire, et ce qui se passe généralement. En général, j'ai observé la situation, mais ce n'est qu'après ces rapports que j'ai réalisé à quel point la révolution se préparait à grande échelle dans les entrailles des entreprises et le silence des salles scientifiques.
L'an dernier seulement, plus de 3 milliards de dollars ont été investis dans le sujet. Google a depuis longtemps déclaré que les réseaux de neurones sont un domaine stratégique et construit activement leur support matériel et logiciel. NVIDIA, sentant que le trône est stupéfiant, fait des efforts fantastiques dans les bibliothèques d'accélération des réseaux neuronaux et le nouveau matériel. Intel a dépensé 0,8 milliard d'euros en 2016 pour acheter deux sociétés impliquées dans l'accélération matérielle des réseaux de neurones. Et cela malgré le fait que les principaux achats n'aient pas encore commencé, et que le nombre de joueurs a dépassé la cinquantaine et croît rapidement.
TPU, VPU, IPU, DPU, NPU, RPU, NNP - qu'est-ce que tout cela signifie et qui va gagner? Essayons de le comprendre. Peu importe - Bienvenue au chat!
Avertissement: L' auteur a dû réécrire complètement les algorithmes de traitement vidéo pour une implémentation efficace sur ASIC, et les clients ont fait du prototypage sur FPGA, donc il y a une idée de la profondeur de la différence dans les architectures. Cependant, l'auteur n'a pas travaillé directement avec le fer récemment. Mais il prévoit qu'il devra se plonger dans.
Contexte des problèmes
Le nombre de calculs requis augmente rapidement, les gens aimeraient prendre plus de couches, plus d'options d'architecture, jouer plus activement avec les hyperparamètres, mais ... cela dépend des performances. Dans le même temps, par exemple, avec la croissance de la productivité des bons vieux processeurs - gros problèmes. Toutes les bonnes choses ont une fin: la loi de Moore, comme vous le savez, s'épuise et le taux de croissance des performances du processeur chute:
Calculs des performances réelles des opérations entières sur SPECint par rapport au VAX11-780 , ci-après souvent une échelle logarithmiqueSi du milieu des années 80 au milieu des années 2000 - dans les années bénies de l'âge d'or des ordinateurs - la croissance a été en moyenne de 52% par an, ces dernières années, elle est tombée à 3% par an. Et c'est un problème (une traduction d'un récent article du patriarche John Hennessey sur les problèmes et les perspectives de l'architecture moderne
était sur Habré ).
Il existe de nombreuses raisons, par exemple, la fréquence des processeurs a cessé de croître:
Il est devenu plus difficile de réduire la taille des transistors. Le dernier malheur qui réduit considérablement les performances (y compris les performances des processeurs déjà sortis) est (roulement de tambour) ... à droite, la sécurité.
La fusion ,
Spectre et d'
autres vulnérabilités causent d'énormes dommages au taux de croissance de la puissance de traitement du processeur (
un exemple de désactivation de l'hyperthreading (!)). Le sujet est devenu populaire et de nouvelles vulnérabilités de ce type sont trouvées
presque tous les mois . Et c'est une sorte de cauchemar, car ça fait mal en termes de performances.
Dans le même temps, le développement de nombreux algorithmes est fermement lié à la croissance familière de la puissance du processeur. Par exemple, de nombreux chercheurs ne se préoccupent pas aujourd'hui de la vitesse des algorithmes - ils trouveront quelque chose. Et ce serait bien lors de l'apprentissage - les réseaux deviennent grands et «difficiles» à utiliser. Cela est particulièrement évident dans la vidéo, pour laquelle la plupart des approches, en principe, ne sont pas applicables à grande vitesse. Et ils n'ont souvent de sens qu'en temps réel. C'est aussi un problème.
De même, de nouvelles normes de compression sont en cours d'élaboration qui suggèrent une augmentation de la puissance du décodeur. Et si la puissance du processeur n'augmente pas? L'ancienne génération se souvient des problèmes rencontrés dans les années 2000 lors de la lecture de vidéos haute définition dans le tout nouveau
H.264 sur des ordinateurs plus anciens. Oui, la qualité était meilleure avec une taille plus petite, mais sur les scènes rapides, l'image pendait ou le son était déchiré. Je dois communiquer avec les développeurs du nouveau
VVC / H.266 (une sortie est prévue pour l'année prochaine). Vous ne les envierez pas.
Alors, que nous prépare le siècle à venir à la lumière de la diminution du taux de croissance des performances du processeur appliqué aux réseaux de neurones?
CPU
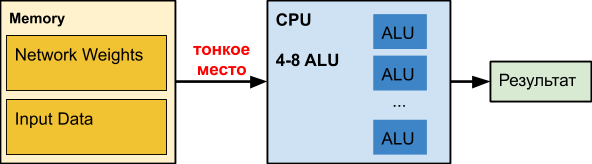
Un
processeur ordinaire est un grand concasseur perfectionné depuis des décennies. Hélas, pour d'autres tâches.
Lorsque nous travaillons avec des réseaux de neurones, en particulier les réseaux profonds, notre réseau lui-même peut occuper des centaines de mégaoctets. Par exemple, les besoins en mémoire des réseaux de
détection d'objets sont les suivants:
D'après notre expérience, les coefficients d'un réseau neuronal profond pour le traitement
des bordures translucides peuvent occuper 150-200 Mo. Des collègues du réseau neuronal déterminent l'âge et le sexe de la taille des coefficients de l'ordre de 50 Mo. Et pendant l'optimisation pour la version mobile de précision réduite - environ 25 Mo (float32⇒float16).
Dans le même temps, le graphique de retard lors de l'accès à la mémoire en fonction de la taille des données est distribué
approximativement comme ceci (l'échelle horizontale est logarithmique):
C'est-à-dire avec une augmentation du volume de données de plus de 16 Mo, le retard augmente de 50 fois ou plus, ce qui affecte fatalement les performances. En fait, la plupart du temps, le CPU, lorsqu'il travaille avec des réseaux de neurones profonds, attend
bêtement les données.
Les données d'Intel sur l'accélération de divers réseaux sont intéressantes, où, en fait, l'accélération ne se produit que lorsque le réseau devient petit (par exemple, à la suite de la quantification des poids), afin de commencer au moins partiellement à entrer dans le cache avec les données traitées. Notez que le cache d'un CPU moderne consomme jusqu'à la moitié de l'énergie du processeur. Dans le cas des réseaux neuronaux lourds, il est inefficace et fonctionne comme un appareil de chauffage excessivement cher.
Pour les adhérents des réseaux de neurones sur le CPUSelon nos tests internes, même
Intel OpenVINO perd l'implémentation de la matrice de multiplication matricielle + NNPACK sur de nombreuses architectures de réseaux (en particulier sur les architectures simples où la bande passante est importante pour le traitement des données en temps réel en mode monothread). Un tel scénario est pertinent pour divers classificateurs d'objets dans l'image (où le réseau de neurones doit être exécuté un grand nombre de fois - 50 à 100 en termes de nombre d'objets dans l'image) et la surcharge de démarrage d'OpenVINO devient déraisonnablement élevée.
Avantages:- «Tout le monde l'a» et est généralement inactif, c'est-à-dire prix d' entrée relativement bas pour la facturation et la mise en œuvre.
- Il existe des réseaux non CV distincts qui s'intègrent bien sur le CPU, les collègues appellent, par exemple, Wide & Deep et GNMT.
Moins:- Le processeur est inefficace lorsque vous travaillez avec des réseaux de neurones profonds (lorsque le nombre de couches réseau et la taille des données d'entrée sont importants), tout fonctionne douloureusement lentement.
GPU

Le sujet est bien connu, nous décrivons donc brièvement l'essentiel. Dans le cas des réseaux de neurones, le
GPU a un avantage de performance significatif dans les tâches massivement parallèles:
Faites attention à la façon dont le
Xeon Phi 7290 à 72 cœurs
est recuit, tandis que le «bleu» est également le serveur Xeon, c'est-à-dire Intel n'abandonne pas si facilement, ce qui sera discuté ci-dessous. Mais plus important encore, la mémoire des cartes vidéo a été initialement conçue pour des performances environ 5 fois supérieures. Dans les réseaux de neurones, le calcul avec des données est extrêmement simple. Quelques actions élémentaires, et nous avons besoin de nouvelles données. Par conséquent, la vitesse d'accès aux données est critique pour le fonctionnement efficace d'un réseau neuronal. Une mémoire haute vitesse «à bord» du GPU et un système de gestion du cache plus flexible que sur le CPU peuvent résoudre ce problème:
Tim Detmers soutient la revue intéressante
«Quels GPU obtenir pour le Deep Learning: mon expérience et mes conseils pour l'utilisation des GPU dans le Deep Learning» depuis plusieurs années maintenant. Il est clair que Tesla et Titans gouvernent la formation, bien que la différence d'architectures puisse provoquer des explosions intéressantes, par exemple dans le cas de réseaux de neurones récurrents (et le leader en général est TPU, note pour l'avenir):
Cependant, il existe un graphique de performance extrêmement utile pour le dollar, où sur le cheval
RTX (probablement en raison de
leurs cœurs Tensor ), si vous avez suffisamment de mémoire pour cela, bien sûr:
Bien sûr, le coût de l'informatique est important. La deuxième place de la première note et la dernière de la seconde -
Tesla V100 est vendue pour 700 mille roubles, comme 10 ordinateurs «ordinaires» (+ le commutateur Infiniband cher, si vous voulez vous entraîner sur plusieurs nœuds). Vrai V100 et fonctionne pour dix. Les gens sont prêts à payer trop cher pour une accélération tangible de l'apprentissage.
Total, résumez!
Avantages:- Cardinal - 10-100 fois - accélération par rapport au CPU.
- Extrêmement efficace pour la formation (et un peu moins efficace pour l'utilisation).
Moins:- Le coût des cartes vidéo haut de gamme (qui ont suffisamment de mémoire pour former de grands réseaux) dépasse le coût du reste de l'ordinateur ...
FPGA
 Le FPGA
Le FPGA est déjà plus intéressant. Il s'agit d'un réseau de plusieurs millions de blocs programmables, que nous pouvons également interconnecter par programmation. Le réseau et les blocs
ressemblent à ceci (le goulot d'étranglement est le goulot d'étranglement, faites attention, encore une fois devant la mémoire de la puce, mais c'est plus facile, ce qui sera décrit ci-dessous):
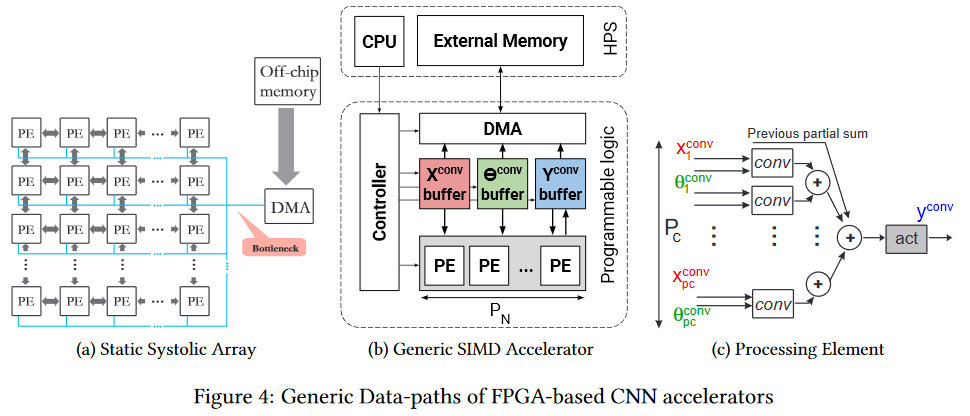
Naturellement, il est logique d'utiliser FPGA déjà au stade de l'utilisation d'un réseau neuronal (dans la plupart des cas, il n'y a pas assez de mémoire pour la formation). De plus, le sujet de l'exécution sur FPGA a maintenant commencé à se développer activement. Par exemple, voici le
cadre fpgaConvNet , qui peut accélérer considérablement l'utilisation de CNN sur les FPGA et réduire la consommation d'énergie.
Le principal avantage du FPGA est que nous pouvons stocker le réseau directement dans les cellules, c'est-à-dire une tache mince sous la forme de centaines de mégaoctets des mêmes données transférées 25 fois par seconde (pour la vidéo) dans la même direction disparaît comme par magie. Cela permet une vitesse d'horloge inférieure et l'absence de caches au lieu de performances inférieures pour obtenir une augmentation notable. Oui, et réduit considérablement la consommation d'énergie pour le
réchauffement climatique par unité de calcul.
Intel a rejoint activement le processus en lançant l'
an dernier l'
OpenVINO Toolkit dans l'open source, qui inclut le
Deep Learning Deployment Toolkit (qui fait partie d'
OpenCV ). De plus, les performances des FPGA sur différentes grilles semblent assez intéressantes, et l'avantage des FPGA par rapport aux GPU (bien que les GPU intégrés Intel) est assez important:
Ce qui réchauffe particulièrement l'âme de l'auteur - Les FPS sont comparés, c'est-à-dire images par seconde est la mesure la plus pratique pour la vidéo. Étant donné qu'Intel a acheté
Altera , le deuxième acteur du marché des FPGA, en 2015, le graphique donne matière à réflexion.
Et, évidemment, la barrière d'entrée à de telles architectures est plus élevée, donc un certain temps doit s'écouler avant que des outils pratiques apparaissent qui prennent efficacement en compte l'architecture FPGA fondamentalement différente. Mais sous-estimer le potentiel de la technologie n'en vaut pas la peine. Elle enduit douloureusement de nombreux endroits minces.
Enfin, nous soulignons que la
programmation des FPGA est un art distinct. En tant que tel, le programme n'y est pas exécuté et tous les calculs sont effectués en termes de flux de données, de retards de flux (qui affectent les performances) et de portes utilisées (qui font toujours défaut). Par conséquent, afin de commencer une programmation efficace, vous devez
changer complètement
votre propre firmware (dans le réseau neuronal qui se trouve entre vos oreilles). Avec une bonne efficacité, cela n'est pas du tout obtenu. Cependant, les nouveaux cadres cacheront bientôt la différence externe aux chercheurs.
Avantages:- Exécution réseau potentiellement plus rapide.
- Consommation d'énergie nettement inférieure à celle du CPU et du GPU (ceci est particulièrement important pour les solutions mobiles).
Inconvénients:- Généralement, ils aident à accélérer l'exécution; la formation sur eux, contrairement au GPU, est nettement moins pratique.
- Programmation plus complexe par rapport aux options précédentes.
- Sensiblement moins de spécialistes.
ASIC

Vient ensuite l'
ASIC , qui est l'abréviation de Application-Specific Integrated Circuit, c'est-à-dire circuit intégré pour notre tâche. Par exemple, réaliser un réseau neuronal en fer. Cependant, la plupart des nœuds de calcul peuvent fonctionner en parallèle. En fait, seules les dépendances de données et l'informatique inégale à différents niveaux du réseau peuvent nous empêcher d'utiliser constamment toutes les ALU qui fonctionnent.
Peut-être que l'extraction de crypto-monnaie a fait la plus grande publicité ASIC parmi le grand public ces dernières années. Au tout début, l'exploitation minière sur le CPU était assez rentable, plus tard j'ai dû acheter un GPU, puis un FPGA, puis des ASIC spécialisés, car les gens (lire - le marché) ont mûri pour des commandes dans lesquelles leur production est devenue rentable.
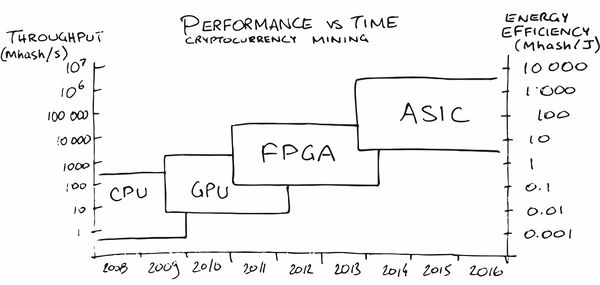
Dans notre région, des
services sont également apparus (naturellement!)
Qui aident à mettre un réseau de neurones sur le fer avec les caractéristiques nécessaires pour la consommation d'énergie, le FPS et le prix. Magiquement, d'accord!
MAIS! Nous perdons la personnalisation du réseau. Et, bien sûr, les gens y pensent aussi. Par exemple, voici un article avec le dicton: «
Une architecture reconfigurable peut-elle battre ASIC en tant qu'accélérateur CNN? » («Une architecture configurable peut-elle battre ASIC comme un accélérateur CNN?»). Il y a suffisamment de travail sur ce sujet, car la question n'est pas vide. Le principal inconvénient de l'ASIC est qu'après avoir converti le réseau en matériel, il devient difficile pour nous de le changer. Ils sont plus avantageux dans les cas où nous avons déjà besoin d'un réseau qui fonctionne bien avec des millions de puces avec une faible consommation d'énergie et des performances élevées. Et cette situation se développe progressivement sur le marché des voitures à pilote automatique, par exemple. Ou dans des caméras de surveillance. Ou dans les chambres des aspirateurs robotiques. Ou dans les chambres d'un réfrigérateur domestique. Ou dans une chambre de cafetière.
Ou dans la chambre en fer. Eh bien, vous comprenez l'idée, en
bref !
Il est important que dans la production de masse, la puce soit bon marché, fonctionne rapidement et consomme un minimum d'énergie.
Avantages:- Le coût de puce le plus bas par rapport à toutes les solutions précédentes.
- Consommation électrique la plus faible par unité de fonctionnement.
- Assez grande vitesse (y compris, si vous le souhaitez, un record).
Inconvénients:- Capacité très limitée de mettre à jour le réseau et la logique.
- Coût de développement le plus élevé par rapport à toutes les solutions précédentes.
- L'utilisation de l'ASIC est rentable principalement pour les grandes séries.
TPU
Rappelez-vous que lorsque vous travaillez avec des réseaux, il y a deux tâches - la formation et l'exécution (inférence). Si les FPGA / ASIC sont principalement axés sur l'accélération de l'exécution (y compris certains réseaux fixes), alors TPU (Tensor Processing Unit ou tensor processors) est soit une accélération d'apprentissage basée sur le matériel, soit une accélération relativement universelle d'un réseau arbitraire. Le nom est beau, d'accord, bien qu'en fait, des
tenseurs de rang 2 avec une unité de multiplication mixte (MXU) connectée à la mémoire à large bande passante (HBM) soient toujours utilisés. Ci-dessous, le schéma d'architecture de TPU Google 2e et 3e version:
TPU Google
En général, Google a fait une publicité pour le nom du TPU, révélant des développements internes en 2017:
Ils ont commencé les travaux préliminaires sur les processeurs spécialisés pour les réseaux de neurones avec leurs mots en 2006, en 2013, ils ont créé un projet avec un bon financement, et en 2015, ils ont commencé à travailler avec les premières puces qui ont beaucoup aidé les réseaux de neurones pour le service cloud de Google Translate et plus encore. Et ce fut, nous le soulignons, l'accélération du réseau. Un avantage important pour les centres de données est une efficacité énergétique TPU supérieure de deux ordres de grandeur par rapport aux processeurs (graphique pour TPU v1):
De plus, en règle générale, par rapport au GPU, les
performances du réseau sont 10 à 30 fois meilleures pour le mieux:
La différence est même 10 fois significative. Il est clair que la différence avec le GPU 20-30 fois détermine le développement de cette zone.
Et, heureusement, Google n'est pas le seul.
TPU Huawei
Aujourd'hui, Huawei, qui souffre depuis longtemps, a également commencé à développer le TPU il y a plusieurs années sous le nom de Huawei Ascend, et en deux versions à la fois - pour les centres de données (comme Google) et pour les appareils mobiles (ce que Google a également commencé à faire récemment). Si vous croyez aux matériaux de Huawei, ils ont dépassé le nouveau Google TPU v3 par FP16 2,5 fois et NVIDIA V100 2 fois:

Comme d'habitude, une bonne question: comment se comportera cette puce sur des tâches réelles. Pour sur le graphique, comme vous pouvez le voir, les performances de pointe. De plus, Google TPU v3 est bon à bien des égards car il peut fonctionner efficacement dans des clusters de 1024 processeurs. Huawei a également annoncé des clusters de serveurs pour l'Ascend 910, mais il n'y a pas de détails. En général, les ingénieurs de Huawei se sont montrés extrêmement compétents au cours des 10 dernières années, et il y a toutes les chances que des performances de pointe 2,8 fois supérieures à celles de Google TPU v3, associées à la dernière technologie de processus à 7 nm, soient utilisées dans le cas.
La mémoire et le bus de données sont essentiels pour les performances, et la diapositive montre qu'une attention considérable a été accordée à ces composants (y compris la vitesse de communication avec la mémoire beaucoup plus rapide que celle du GPU):
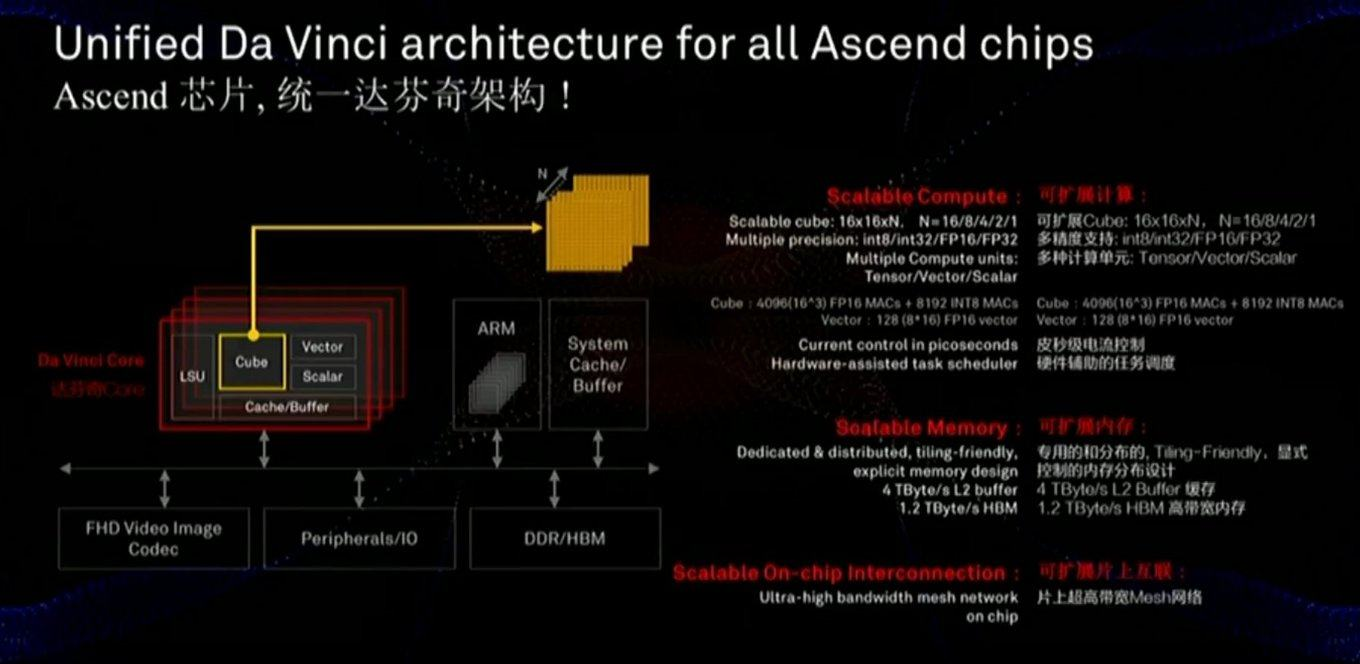
La puce utilise également une approche légèrement différente - pas des échelles MXU 128x128 bidimensionnelles, mais des calculs dans un cube tridimensionnel d'une taille plus petite 16x16xN, où N = {16.8,4,2,1}. Par conséquent, la question clé est de savoir dans quelle mesure elle reposera sur l'accélération réelle de réseaux spécifiques (par exemple, les calculs dans un cube conviennent aux images). En outre, une étude approfondie de la diapositive montre que, contrairement à Google, la puce intègre immédiatement le travail avec la vidéo FullHD compressée. Pour l'auteur, cela semble
très encourageant!
Comme mentionné ci-dessus, dans la même ligne, les processeurs sont développés pour les appareils mobiles pour lesquels l'efficacité énergétique est critique et sur lesquels le réseau sera principalement exécuté (c'est-à-dire séparément - processeurs pour l'apprentissage cloud et séparément - pour l'exécution): et avec ce paramètre, tout Cela semble bien en comparaison avec NVIDIA au moins (notez qu'ils n'ont pas apporté de comparaison avec Google, cependant, Google ne donne pas de TPU cloud à ses mains). Et leurs puces mobiles concurrenceront les processeurs d'Apple, de Google et d'autres sociétés, mais il est trop tôt pour faire le point ici.On voit clairement que les nouvelles puces Nano, Tiny et Lite devraient être encore meilleures. Il devient clair
et avec ce paramètre, tout Cela semble bien en comparaison avec NVIDIA au moins (notez qu'ils n'ont pas apporté de comparaison avec Google, cependant, Google ne donne pas de TPU cloud à ses mains). Et leurs puces mobiles concurrenceront les processeurs d'Apple, de Google et d'autres sociétés, mais il est trop tôt pour faire le point ici.On voit clairement que les nouvelles puces Nano, Tiny et Lite devraient être encore meilleures. Il devient clair pourquoi Trump avait peur pourquoi de nombreux fabricants examinent attentivement les succès de Huawei (qui a surpassé toutes les sociétés sidérurgiques américaines en termes de revenus, y compris Intel en 2018).Réseaux profonds analogiques
Comme vous le savez, la technologie évolue souvent dans une spirale, lorsque les approches anciennes et oubliées deviennent pertinentes dans un nouveau cycle.Quelque chose de similaire pourrait très bien arriver aux réseaux de neurones. Vous avez peut-être entendu dire qu'une fois les opérations de multiplication et d'addition effectuées par des tubes électroniques et des transistors (par exemple, la conversion des espaces colorimétriques - une multiplication typique des matrices - se faisait dans chaque téléviseur couleur jusqu'au milieu des années 90)? Une bonne question s'est posée: si notre réseau de neurones est relativement résistant aux calculs inexacts à l'intérieur, que faire si nous convertissons ces calculs sous forme analogique? Nous obtenons immédiatement une accélération notable des calculs et une réduction potentiellement spectaculaire de la consommation d'énergie pour une opération: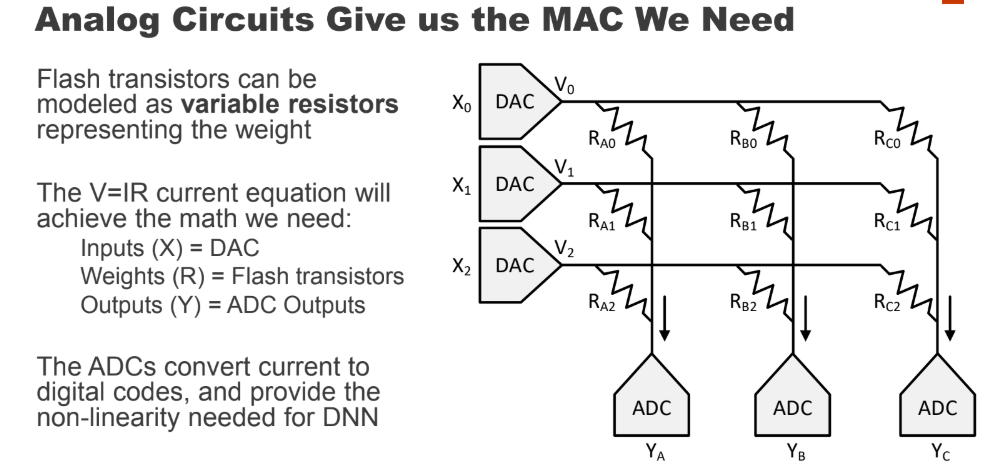
Cependant, la direction potentielle du calcul analogique semble
extrêmement intéressante.
La seule chose qui brouille, c'est que c'est IBM,
qui a déjà déposé des dizaines de brevets sur le sujet . Selon l'expérience, en raison des particularités de la culture d'entreprise, elles coopèrent relativement faiblement avec d'autres entreprises et, possédant certaines technologies, sont plus susceptibles de ralentir son développement entre autres que de la partager efficacement. Par exemple, IBM a refusé à un moment donné d'accorder une licence de compression arithmétique pour JPEG au comité
ISO , malgré le fait que dans le projet de norme, il y avait une option avec compression arithmétique. En conséquence, JPEG a pris vie avec la compression Huffman et 10 à 15% pire qu'il ne pouvait. La même situation était avec les normes de compression vidéo. Et l'industrie n'est massivement passée à la compression arithmétique dans les codecs que lorsque 5 brevets IBM ont expiré 12 ans plus tard ... Espérons qu'IBM sera plus enclin à coopérer cette fois, et, en conséquence, nous
souhaitons un maximum de succès dans le domaine à tous ceux qui ne sont pas associés à IBM , l'avantage de
ces personnes et de ces entreprises est considérable .
Si cela fonctionne,
ce sera une révolution dans l'utilisation des réseaux de neurones et une révolution dans de nombreux domaines de l'informatique.Divers autres lettres
En général, le thème de l'accélération des réseaux de neurones est devenu à la mode, toutes les grandes entreprises et des dizaines de startups y sont impliquées, et
au moins 5 d'entre elles ont attiré plus de 100 millions de dollars d' investissements au début de 2018. Au total, en 2017, 1,5 Mds $ ont été investis dans des startups liées au développement de puces. Malgré le fait que les investisseurs n'aient pas remarqué les fabricants de puces pendant 15 bonnes années (car il n'y avait rien à y attraper dans le contexte des géants). En général - il y a maintenant une réelle chance pour une petite révolution du fer. De plus, il est extrêmement difficile de prédire quelle architecture gagnera, le besoin de révolution a mûri et les possibilités d'augmenter la productivité sont grandes. La situation révolutionnaire classique a mûri:
Moore ne peut plus et
Dean n'est pas encore prêt.
Eh bien, puisque la loi de marché la plus importante - être différente, il y a beaucoup de nouvelles lettres, par exemple:
- Neural Processing Unit ( NPU ) - Un neuroprocesseur, parfois magnifiquement - une puce neuromorphique - de manière générale, le nom général d'un accélérateur de réseaux de neurones, appelés puces Samsung , Huawei et plus sur la liste ...
Ci-après dans cette section, principalement des diapositives de présentations d'entreprise seront données à titre d'exemples d' auto-noms technologiques
Il est clair qu'une comparaison directe est problématique, mais voici quelques données intéressantes comparant les puces aux neuroprocesseurs d'Apple et de Huawei, produites par le TSMC mentionné au début. On peut voir que la concurrence est rude, la nouvelle génération montre une augmentation de productivité de 2 à 8 fois et la complexité des processus technologiques:
- Processeur de réseau neuronal (NNP) - Processeur de réseau neuronal.
C'est le nom de sa famille de puces, par exemple Intel (à l'origine c'était la société Nervana Systems , qu'Intel a achetée en 2016 pour 400 millions de dollars +). Cependant, dans les articles et les livres, le nom NNP est également assez courant.
- Intelligence Processing Unit (IPU) - un processeur intelligent - le nom des puces promues par Graphcore (soit dit en passant, qui a déjà reçu un investissement de 310 millions de dollars).
Il produit des cartes spéciales pour ordinateurs, mais destinées à la formation de réseaux de neurones, avec des performances de formation RNN 180 à 240 fois supérieures à celles du NVIDIA P100.
- Dataflow Processing Unit (DPU) - processeur de traitement de données - le nom est promu par WAVE Computing , qui a déjà reçu un investissement de 203 millions de dollars. Il produit environ les mêmes accélérateurs que Graphcore:
Puisqu'ils ont reçu 100 millions de moins, ils déclarent que la formation n'est que 25 fois plus rapide que sur le GPU (bien qu'ils promettent que ce sera 1000 fois bientôt). Voyons voir ...
- Unité de traitement de la vision ( VPU ) - Processeur de vision par ordinateur:
Le terme est utilisé dans les produits de plusieurs sociétés, par exemple, Myriad X VPU de Movidius (également acheté par Intel en 2016).
- L'un des concurrents d'IBM (qui, rappelons-le, utilise le terme RPU ) - Mythic - propose Analog DNN , qui stocke également le réseau dans la puce et une exécution relativement rapide. Jusqu'à présent, ils n'ont que des promesses, bien que sérieuses :
Et cela ne répertorie que les zones les plus importantes dans le développement desquelles des centaines de millions ont été investis (ce qui est important dans le développement du fer).
En général, comme on le voit, toutes les fleurs fleurissent rapidement. Progressivement, les entreprises digéreront des milliards de dollars d'investissements (il faut généralement 1,5 à 3 ans pour produire des puces), la poussière se déposera, le leader deviendra clair, les gagnants écriront, comme d'habitude, une histoire, et le nom de la technologie la plus performante du marché sera généralement accepté. Cela s'est déjà produit plus d'une fois («IBM PC», «Smartphone», «Xerox», etc.).
Quelques mots sur la comparaison correcte
Comme déjà indiqué ci-dessus, comparer correctement les performances des réseaux de neurones n'est pas facile. C'est exactement pourquoi Google publie un graphique dans lequel TPU v1 fabrique le NVIDIA V100. NVIDIA, voyant une telle honte, publie un calendrier où Google TPU v1 perd le V100. (Alors!) Google publie le tableau suivant, où le V100 perd sur Google TPU v2 & v3. Et enfin, Huawei est le calendrier où tout le monde perd sur le Huawei Ascend, mais le V100 est meilleur que TPU v3. Cirque, en bref. Ce qui est caractéristique -
chaque graphique
a sa propre vérité!
Les causes profondes de la situation sont claires:
- Vous pouvez mesurer la vitesse d'apprentissage ou la vitesse d'exécution (selon ce qui est le plus pratique).
- Il est possible de mesurer différents réseaux de neurones, car la vitesse d'exécution / d'apprentissage de différents réseaux de neurones sur des architectures spécifiques peut différer considérablement en raison de l'architecture du réseau et de la quantité de données requises.
- Et vous pouvez mesurer les performances maximales de l'accélérateur (peut-être le plus abstrait de tous les ci-dessus).
Afin de mettre les choses en ordre dans ce zoo, le test
MLPerf est apparu , qui a maintenant la version 0.5 disponible, c'est-à-dire il est en train de développer une méthodologie de comparaison, qui devrait être présentée à la première version au
3ème trimestre de cette année :
Étant donné que les auteurs sont l'un des principaux contributeurs de TensorFlow, il y a toutes les chances de savoir quelle est la meilleure façon de s'entraîner et éventuellement de l'utiliser (car la version mobile de TF sera très probablement également incluse dans ce test au fil du temps).
Récemment, l’organisation internationale
IEEE , qui publie la troisième partie de la littérature technique mondiale sur la radioélectronique, les ordinateurs et le génie électrique, a
interdit à Huawei le
visage d’un enfant et a rapidement
annulé l’ interdiction. Huawei n'est pas encore dans le classement MLPerf
actuel , tandis que Huawei TPU est un concurrent sérieux des cartes Google TPU et NVIDIA (c'est-à-dire qu'en plus des politiques, il y a des raisons économiques d'ignorer Huawei, franchement). Avec un intérêt non dissimulé, nous suivrons l'évolution des événements!
Tout au paradis! Plus près des nuages!
Et comme il s'agissait de formation, il vaut la peine de dire quelques mots sur ses spécificités:
- Avec le départ généralisé de la recherche sur les réseaux de neurones profonds (avec des dizaines et des centaines de couches qui déchirent vraiment tout le monde), il a fallu broyer des centaines de mégaoctets de coefficients, ce qui a immédiatement rendu inefficaces tous les caches de processeur des générations précédentes. Dans le même temps, l'ImageNet classique discute d' une stricte corrélation entre la taille du réseau et sa précision (plus la valeur est élevée, meilleure est la droite, plus le réseau est grand, l'axe horizontal est logarithmique):
- Le processus de calcul à l'intérieur du réseau neuronal suit un schéma fixe, c'est-à-dire où toutes les «ramifications» et «transitions» (en termes du siècle dernier) auront lieu dans la grande majorité des cas est précisément connue à l'avance, ce qui laisse l'exécution spéculative des instructions sans travail, ce qui augmente auparavant de manière significative la productivité:
Cela rend les mécanismes de prédiction superscalaire entassés pour la ramification et les précalculs des décennies précédentes d' amélioration du processeur inefficaces (cette partie de la puce, malheureusement, contribue également au réchauffement climatique plutôt comme DNN sur le cache DNN).
- De plus, l'entraînement des réseaux de neurones est relativement faiblement mis à l'échelle horizontalement . C'est-à-dire nous ne pouvons pas prendre 1000 ordinateurs puissants et obtenir une accélération d'apprentissage 1000 fois. Et même à 100, nous ne pouvons pas (du moins jusqu'à ce que le problème théorique de la détérioration de la qualité de la formation sur une grande taille du lot soit résolu). En général, il est assez difficile pour nous de distribuer quelque chose sur plusieurs ordinateurs, car dès que la vitesse d'accès à la mémoire unifiée dans laquelle se trouve le réseau diminue, la vitesse de son apprentissage chute de façon catastrophique. Par conséquent, si un chercheur a accès gratuitement à 1000 ordinateurs puissants, il les prendra certainement tous bientôt, mais très probablement (s'il n'y a pas d'infinibande + RDMA), il y aura de nombreux réseaux de neurones avec différents paramètres hyper. C'est-à-dire la durée totale de la formation ne sera que plusieurs fois inférieure à celle d'un seul ordinateur. Là, il est possible de jouer avec les tailles du lot, la formation continue et d'autres nouvelles technologies à la mode, mais la principale conclusion est oui, avec une augmentation du nombre d'ordinateurs, l'efficacité du travail et la probabilité d'obtenir un résultat augmenteront, mais pas de manière linéaire. Et aujourd'hui, le temps d'un chercheur en science des données est cher et souvent si vous pouvez dépenser beaucoup de voitures (bien que déraisonnable), mais obtenez une accélération - cela est fait (voir l'exemple avec 1, 2 et 4 V100 chers dans les nuages juste en dessous).
Exactement ces points expliquent pourquoi tant de gens se sont précipités vers le développement de fer spécialisé pour les réseaux de neurones profonds. Et pourquoi ont-ils obtenu leurs milliards. Il y a vraiment de la lumière visible au bout du tunnel et pas seulement Graphcore (qui, rappelons-le, 240 fois l'entraînement RNN accéléré).
Par exemple, les messieurs d'IBM Research
sont optimistes quant au développement de puces spéciales qui augmenteront l'efficacité des calculs d'un ordre de grandeur après 5 ans (et après 10 ans de 2 ordres de grandeur, atteignant une augmentation de 1000 fois par rapport au niveau de 2016 sur ce graphique, bien que , en efficacité par watt, mais la puissance de base augmentera également):
Tout cela signifie l'apparition de pièces de fer, dont la formation sera relativement rapide, mais qui coûtera cher, ce qui conduit naturellement à l'idée de partager le temps d'utilisation de cette pièce de fer coûteuse entre les chercheurs. Et cette idée nous conduit aujourd'hui non moins naturellement au cloud computing. Et la transition de l'apprentissage vers les nuages se poursuit depuis longtemps.
Notez que maintenant la formation des mêmes modèles peut différer dans le temps d'un ordre de grandeur de différents services cloud. Amazon mène en tête et Colab gratuit de Google vient en dernier. Veuillez noter comment le résultat du nombre de V100 change parmi les leaders - une augmentation du nombre de cartes de 4 fois (!) Augmente la productivité de moins d'un tiers (!!!) du bleu au violet, et Google a encore moins:
Il semble que dans les années à venir, la différence atteindra deux ordres de grandeur. Seigneur! Cuisiner de l'argent! Nous rendrons à l'amiable des investissements de plusieurs milliards aux investisseurs les plus performants ...
Bref
Essayons de résumer les points clés de la tablette:
Quelques mots sur l'accélération logicielle
En toute justice, nous mentionnons qu'aujourd'hui le grand sujet est l'accélération logicielle de l'exécution et de la formation des réseaux de neurones profonds. L'exécution peut être considérablement accélérée principalement en raison de la soi-disant quantification du réseau. Peut-être est-ce d'abord parce que la plage de poids utilisée n'est pas si grande et qu'il est souvent possible de grossir les poids d'une valeur à virgule flottante de 4 octets à un entier de 1 octet (et, se souvenant des succès d'IBM, encore plus fort). Deuxièmement, le réseau formé dans son ensemble est assez résistant au bruit de calcul et la précision de la transition vers
int8 diminue légèrement. Dans le même temps, malgré le fait que le nombre d'opérations peut même augmenter (en raison de la mise à l'échelle lors du calcul), le fait que le réseau est réduit de 4 fois et peut être considéré comme des opérations vectorielles rapides augmente considérablement la vitesse globale d'exécution. Ceci est particulièrement important pour les applications mobiles, mais cela fonctionne également dans les nuages (un exemple d'exécution accélérée dans les nuages Amazon):
Il existe d'autres façons d'
accélérer algorithmiquement l'
exécution du réseau et encore plus de façons d'
accélérer l'apprentissage . Cependant, ce sont de grands sujets distincts sur lesquels pas cette fois.
Au lieu d'une conclusion
Dans ses conférences, l'investisseur et auteur
Tony Ceba en donne un magnifique exemple: en 2000, le supercalculateur n ° 1 d'une capacité de 1 téraflops occupait 150 mètres carrés, coûtait 46 millions de dollars et consommait 850 kW:
15 ans plus tard, le GPU NVIDIA avec une performance de 2,3 téraflops (2 fois plus) tient dans la main, coûte 59 $ (une amélioration d'environ un million de fois) et consomme 15 watts (une amélioration de 56 mille fois):
En mars de cette année,
Google a introduit les pods TPU , qui sont en fait des superordinateurs refroidis par liquide basés sur TPU v3, dont la principale caractéristique est qu'ils peuvent fonctionner ensemble dans des systèmes de 1024 TPU. Ils ont l'air assez impressionnants:
Les données exactes ne sont pas données, mais il est dit que le système est comparable aux Top-5 supercalculateurs dans le monde. TPU Pod peut considérablement augmenter la vitesse d'apprentissage des réseaux de neurones. Pour augmenter la vitesse d'interaction, les TPU sont connectés par des lignes à grande vitesse dans une structure toroïdale:

Il semble qu'après 15 ans, ce neuroprocesseur deux fois plus puissant pourra également tenir dans votre main, comme le
processeur Skynet (vous
devez admettre, c'est quelque chose de similaire):
Tiré de la version réalisatrice du film "Terminator 2"Compte tenu du taux actuel d'amélioration des accélérateurs matériels des réseaux de neurones profonds et de l'exemple ci-dessus, cela est tout à fait réel. Il y a toutes les chances en quelques années de prendre une puce avec une performance comme le TPU Pod d'aujourd'hui.
Soit dit en passant, il est amusant que dans le film, les fabricants de puces (apparemment, imaginant où le réseau d'auto-formation pourrait mener) aient désactivé le recyclage par défaut. De manière caractéristique, le
T-800 lui
- même ne pouvait pas activer le mode de formation et fonctionnait en mode d'inférence (voir la
version de mise en scène plus
longue ). De plus, son
processeur neural-net était avancé et lors de l'activation du recyclage, il pouvait utiliser les données précédemment accumulées pour mettre à jour le modèle. Pas mal pour 1991.
Ce texte a été commencé dans le chaud 13 millionième Shenzhen. Je me suis assis dans l'un des 27 000 taxis électriques de la ville et j'ai regardé avec grand intérêt les 4 écrans à cristaux liquides de la voiture. Un petit - parmi les appareils devant le conducteur, deux - au centre dans le tableau de bord et le dernier - translucide - dans le rétroviseur, combiné avec un DVR, une caméra de vidéosurveillance et un androïde à bord (à en juger par la ligne supérieure avec le niveau de charge et de communication avec le réseau). Il affichait les données du conducteur (de qui se plaindre, le cas échéant), de nouvelles prévisions météorologiques et il semblait y avoir un lien avec la flotte de taxis. Le conducteur ne connaissait pas l'anglais et n'a pas réussi à l'interroger sur ses impressions sur la machine électrique. Par conséquent, il a appuyé paresseusement sur la pédale, déplaçant légèrement la voiture dans un embouteillage. Et j'ai regardé la fenêtre avec un look futuriste avec intérêt - les Chinois dans leurs vestes conduisaient du travail sur des scooters électriques et des monowheels ... et je me demandais à quoi tout cela ressemblerait dans 15 ans ...
En fait, déjà aujourd'hui, le rétroviseur, utilisant les données de la caméra du DVR et l'
accélération matérielle des réseaux de neurones , est tout à fait capable de contrôler la voiture dans la circulation et de tracer la route. Dans l'après-midi, au moins). Après 15 ans, le système sera clairement non seulement capable de conduire une voiture, mais sera également ravi de me fournir les caractéristiques des véhicules électriques chinois frais. En russe, naturellement (en option: anglais, chinois ... albanais, enfin). Le chauffeur ici est superflu, mal formé, un maillon.
Seigneur!
EXTRÊMEMENT INTÉRESSANT 15 ans nous attendent!
Restez à l'écoute!
Je reviens! )))
 UPD:
UPD: Les commentaires les plus intéressants:
À propos de la quantification et de l'accélération des calculs sur FPGA
Commentaires @Mirn
Sur FPGA, non seulement l'arithmétique de la précision arbitraire est disponible, mais aussi l'enfer d'une capacité importante pour enregistrer et traiter des données de bits arbitraires. Par exemple, il y a trop de coefficients dans les ennuyeux MobileNetV2 W et B et vous pouvez les quantifier sans trop de perte de précision à seulement 16 bits, ou vous devrez vous recycler. Mais si vous regardez à l'intérieur et collectez des statistiques sur les canaux et les couches, vous pouvez voir que les 16 bits sont utilisés uniquement à l'entrée des premiers coefficients de 1000 W, les autres ont 8-11 bits, dont seulement 2-3 bits et signes les plus significatifs sont vraiment importants, et des statistiques sur l'utilisation des canaux de sorte qu'il existe de nombreux canaux où généralement des zéros, ou de petites valeurs, ou des canaux où presque toutes les valeurs sont de 8 à 11 bits, c'est-à-dire il est possible de clouer l'exposant dans les ongles au moment de la compilation et de ne pas le stocker, c'est-à-dire en fait, il est possible de stocker dans la mémoire ROM non pas des valeurs 16 bits mais 4 bits, et vous pouvez même stocker l'intégralité du réseau neuronal sur des FPGA bon marché sans beaucoup de perte de précision (moins de 1%), et également traiter à des vitesses allant jusqu'à des dizaines de milliers de FPS avec une latence de sorte que nous obtenons immédiatement une réponse du réseau neuronal Comment se termine la réception de la trame.
À propos de la quantification: mon idée est que si à un certain nombre d'étapes de calcul de W, les coefficients pour le canal n ° 0 ne changent que de +50 à -50, alors il est logique de compresser le bitness à 7, et si de -123 à +124 par exemple, puis à 8 (y compris le signe )Quoi qu'il en soit, à l'intérieur du FPGA, tous les canaux sont calculés en parallèle par cycle, et ces blocs de mémoire de 7, 8, etc. sont combinés en un grand morceau parallèle de mémoire ROM avec une taille de bits de l'ordre de plusieurs dizaines de milliers de bits. Et bien plus encore, si leurs bits de poids faible n'affectent pas fortement le résultat ou la précision, ils s'inclinent également en place.
(, , ), RTL , , . GCC AVX256 bitperfect ( FPGA ) FPS ( W B, ).
W fc , .. -100 +100 +10000 255 9 ( ).
! parce que dephwise .
u-law ( ! ).
, , 6, , .
( ). — , FixedPoint dot product — Fractional part, — , , fc .
À propos de la compilation automatique optimale des modèles sur GPU, FPGA, ASIC et autres matérielsCommentaire de @BigPack
- TVM ( tvm.ai/about), ( Keras) . , — «»- (bare metal, ISA, FPGA .) edge computing. TVM HLS TVM FPGA. HLS FPGA «» , ( ) FPGA , GPU/TPU .
PS FPGA transparent hardware ( — open-source hardware), , ( «» ) . -. , FPGA —
A propos de l'annonce des innovations dans l'architecture FPGA, l'utilisation de Microsoft FPGA et l'optimisation automatique des réseaux de neuronesGrands commentaires @ Brak0delFPGA, 2019 , . — . / dsp-
Xilinx Achronix , DDR.
, , , FPGA ASIC-. FPGA : , ASIC , FPGA - . C'est-à-dire - . , ASIC-, , . , FPGA , ASIC.
, CPU, FPGA , , .
, GPU , FPGA , : , - , GPU , , , - ( , , , , FPGA , GPU ,
). , FPGA , , , ASIC-.
Microsoft (
Catapult v.2 ), FPGA-. , FPGA. () .
FPGA
Ristretto Deephi , , Deephi FPGA. , , , .
FPGA .
À propos de l'économie du développement FPGA par rapport à ASICCommentaire de @Mirn
, FPGA :
, ASIC.
:
FPGA
( ), ( , , IP 30-50 5 ).
, 10 ( ), 5*(N+1)
, , — 10 , , 120*N
( , — )
: (120+50+5)*N, 5 880
ASIC
( 2 )
(3-4 )
ASIC « » — : ,
, ( ), , — , .
: — , , .
( MiT — , , , )
, , 10 3-5 , ( — , , — , — ) , : .
! ! . NEC SONY (c , 10-15 , )
: FPGA ASIC.
Remerciements:
- . .. ,
- , , ,
- , , ,
- , , , , , , , , , , , , !