Rappelons que l'Elastic Stack est basé sur la base de données non relationnelle Elasticsearch, l'interface Web Kibana et les collecteurs de données (le plus célèbre Logstash, divers Beats, APM et autres). L'un des ajouts intéressants à l'ensemble de la pile de produits répertoriés est l'analyse des données à l'aide d'algorithmes d'apprentissage automatique. Dans l'article, nous comprenons ce que sont ces algorithmes. Nous demandons un chat.
L'apprentissage automatique est une fonctionnalité payante du shareware Elastic Stack et fait partie du X-Pack. Pour commencer à l'utiliser, il suffit après l'activation d'activer la période d'essai de 30 jours. Une fois la période d'essai expirée, vous pouvez demander une assistance pour son extension ou acheter un abonnement. Le coût de l'abonnement est calculé non pas à partir de la quantité de données, mais à partir du nombre de nœuds utilisés. Non, la quantité de données affecte, bien sûr, le nombre de nœuds requis, mais cette approche de licence est toujours plus humaine par rapport au budget de l'entreprise. S'il n'y a pas besoin de hautes performances - vous pouvez économiser.
ML dans Elastic Stack est écrit en C ++ et fonctionne en dehors de la JVM, qui exécute Elasticsearch lui-même. Autrement dit, le processus (qui, soit dit en passant, est appelé autodétection) consomme tout ce que la JVM n'avale pas. Sur le stand de démonstration, ce n'est pas si critique, mais dans un environnement productif, il est important de mettre en évidence des nœuds séparés pour les tâches ML.
Les algorithmes d'apprentissage automatique sont divisés en deux catégories -
avec et
sans professeur . Dans Elastic Stack, l'algorithme appartient à la catégorie «pas d'enseignant».
Ce lien vous permet de voir l'appareil mathématique des algorithmes d'apprentissage automatique.
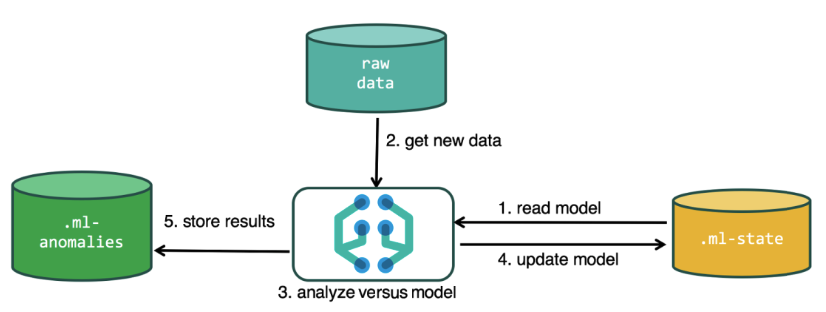
Pour effectuer l'analyse, l'algorithme d'apprentissage automatique utilise les données stockées dans les index Elasticsearch. Vous pouvez créer des tâches pour l'analyse à la fois à partir de l'interface Kibana et via l'API. Si vous le faites via Kibana, il n'est pas nécessaire de savoir certaines choses. Par exemple, des index supplémentaires que l'algorithme utilise dans le processus.
Index supplémentaires utilisés dans le processus d'analyse.ml-state - informations sur les modèles statistiques (paramètres d'analyse);
.ml-anomalies- * - résultats du travail des algorithmes ML;
.ml-notifications - paramètres de notification basés sur les résultats d'analyse.
La structure de données de la base de données Elasticsearch est constituée d'index et de documents qui y sont stockés. S'il est comparé à une base de données relationnelle, alors l'index peut être comparé au schéma de base de données et à un document avec une entrée dans le tableau. Cette comparaison est conditionnelle et fournie pour simplifier la compréhension d'autres informations pour ceux qui ont seulement entendu parler d'Elasticsearch.
La même fonctionnalité est disponible via l'API que via l'interface Web.Par conséquent, pour plus de clarté et de compréhension des concepts, nous allons montrer comment configurer via Kibana. Il y a une section Machine Learning dans le menu à gauche où vous pouvez créer un nouveau travail. Dans l'interface Kibana, cela ressemble à l'image ci-dessous. Nous allons maintenant analyser chaque type de tâche et montrer les types d'analyse qui peuvent être construits ici.
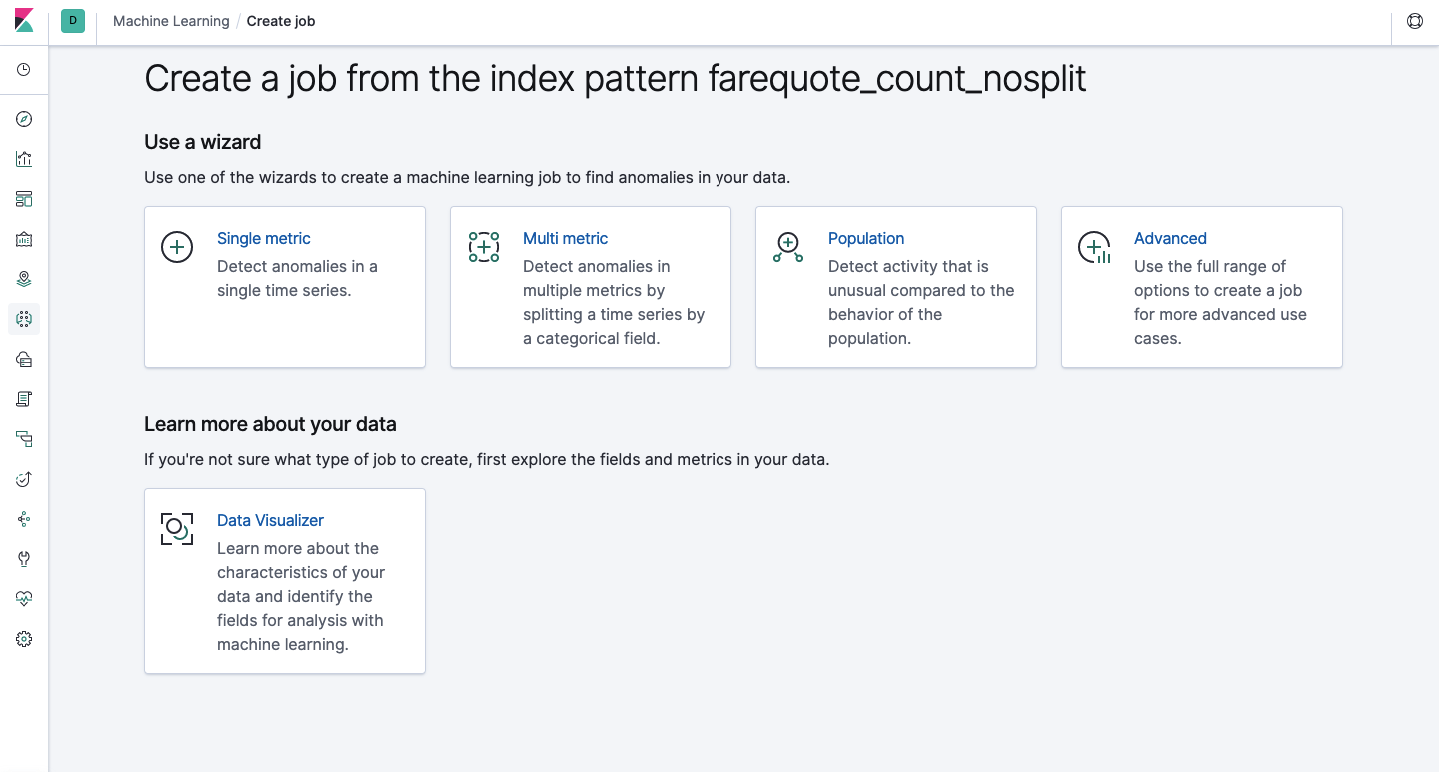
Single Metric - analyse d'une métrique, Multi Metric - analyse de deux métriques ou plus. Dans les deux cas, chaque métrique est analysée dans un environnement isolé, c'est-à-dire l'algorithme ne prend pas en compte le comportement des métriques analysées en parallèle comme cela peut sembler dans le cas du multi métrique. Pour effectuer le calcul en tenant compte de la corrélation de différentes métriques, vous pouvez appliquer l'analyse de la population. Et Advanced est un réglage fin des algorithmes avec des options supplémentaires pour certaines tâches.
Métrique unique
L'analyse des changements dans une seule métrique est la chose la plus simple que vous puissiez faire ici. Après avoir cliqué sur Create Job, l'algorithme recherchera les anomalies.
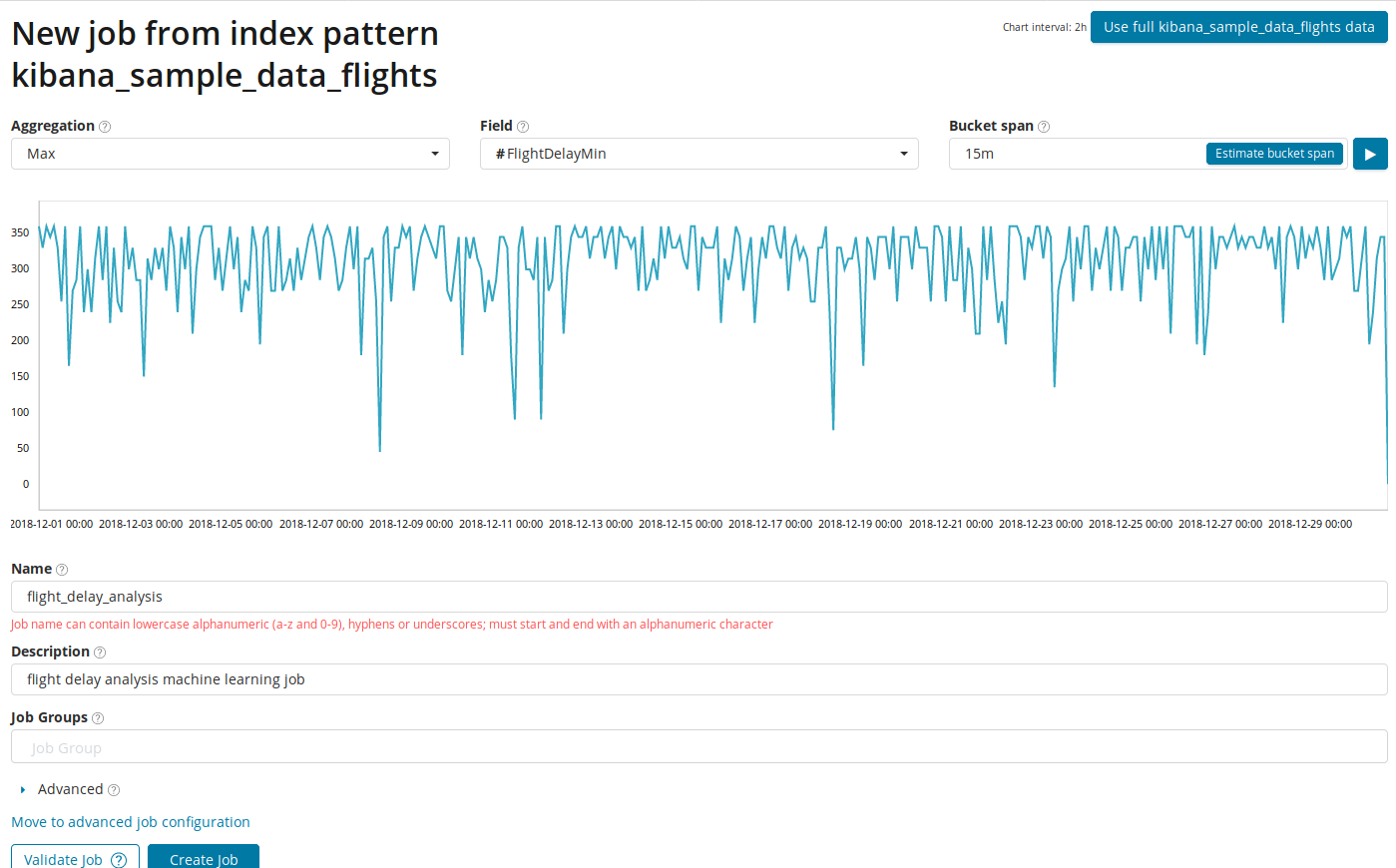
Dans le champ
Agrégation , vous pouvez choisir une approche pour rechercher des anomalies. Par exemple, avec
Min, les valeurs anormales seront considérées comme inférieures à la normale. Il y a
Max, Hign Mean, Low, Mean, Distinct et d'autres. La description de toutes les fonctions peut être trouvée
ici .
Le champ Champ indique le champ numérique du document par lequel nous analyserons.
Dans le champ
Bucket span , la granularité des intervalles sur la chronologie sur lesquels l'analyse sera effectuée. Vous pouvez faire confiance à l'automatisation ou choisir manuellement. L'image ci-dessous montre un exemple de granularité trop faible - vous pouvez ignorer l'anomalie. En utilisant ce paramètre, vous pouvez modifier la sensibilité de l'algorithme aux anomalies.

La durée des données collectées est un élément clé qui affecte l'efficacité de l'analyse. Dans l'analyse, l'algorithme détermine les intervalles de répétition, calcule l'intervalle de confiance (lignes de base) et identifie les anomalies - écarts atypiques par rapport au comportement habituel de la métrique. Par exemple:
Baselines avec une petite étendue de données:
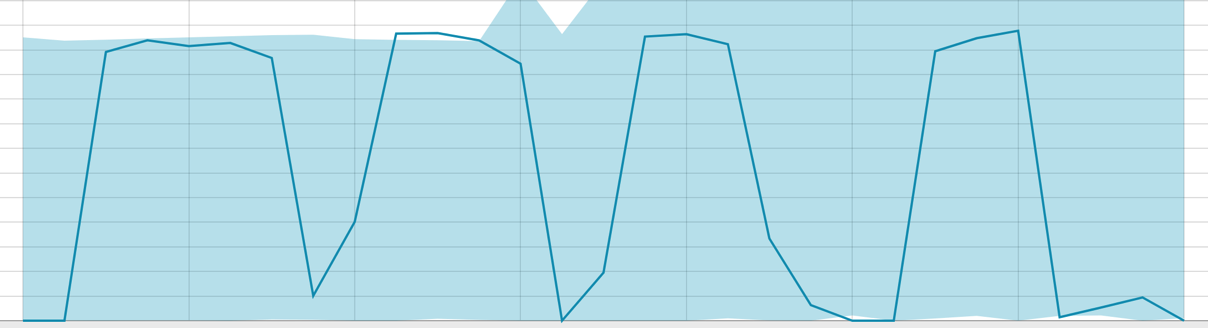
Lorsque l'algorithme a quelque chose à apprendre, la ligne de base ressemble à ceci:
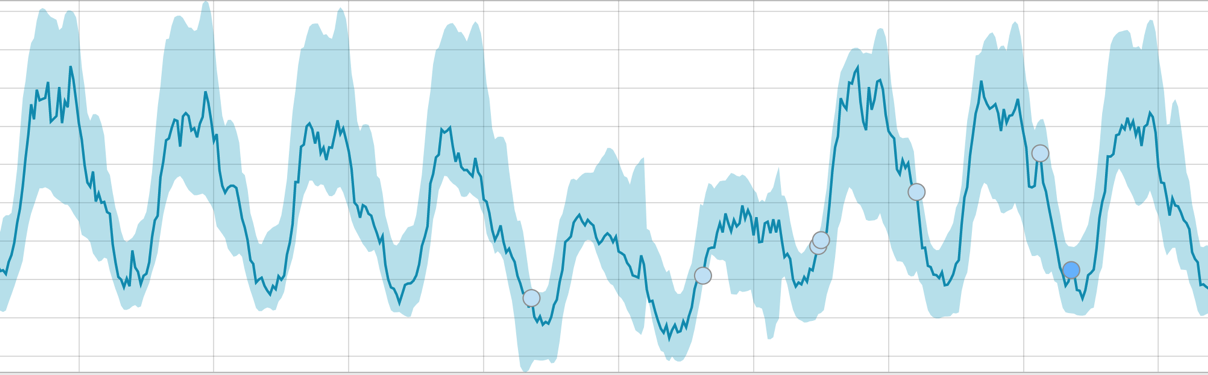
Après le démarrage de la tâche, l'algorithme détermine les écarts anormaux par rapport à la norme et les classe par la probabilité de l'anomalie (la couleur de l'étiquette correspondante est indiquée entre parenthèses):
Avertissement (cyan): moins de 25
Mineur (jaune): 25-50
Majeur (orange): 50-75
Critique (rouge): 75-100
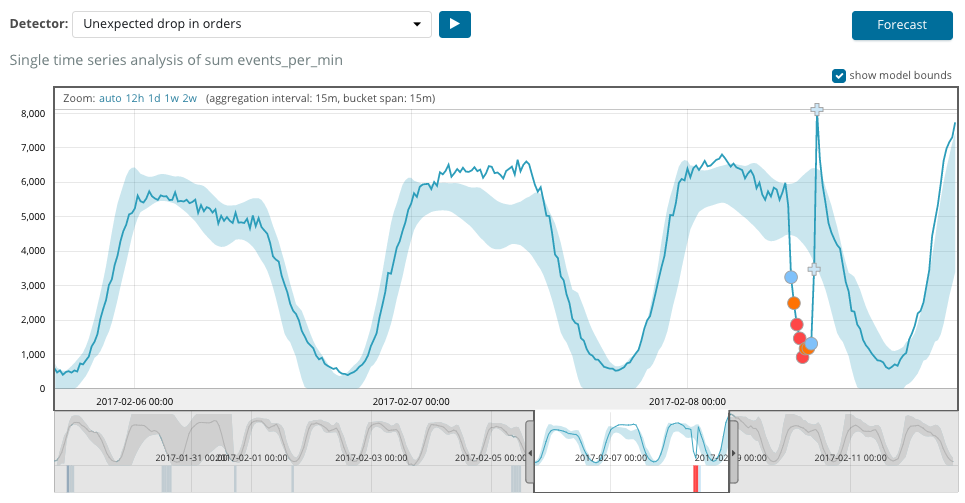
Le graphique ci-dessous montre un exemple d'anomalies trouvées.
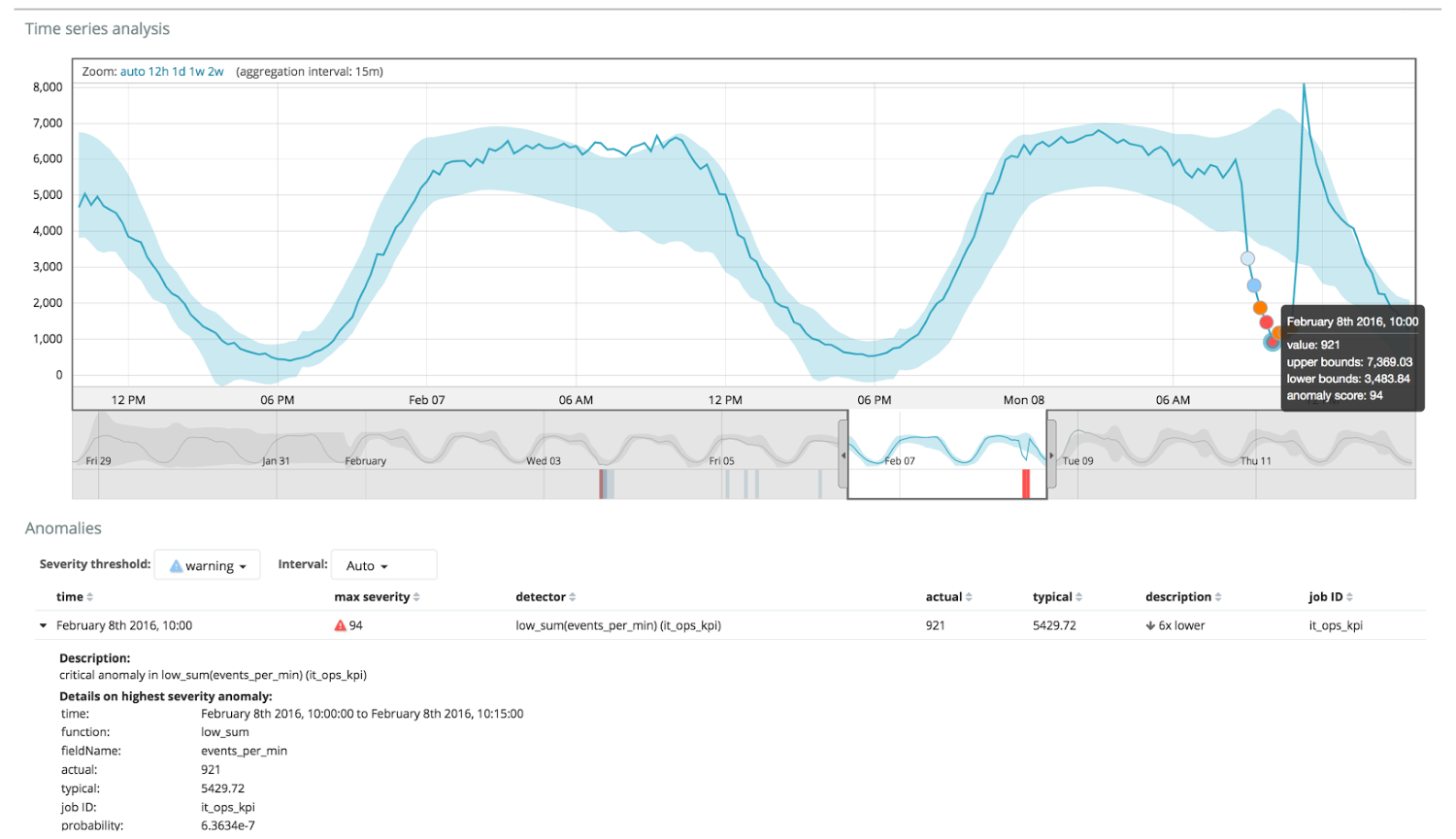
Ici, vous pouvez voir le nombre 94, qui indique la probabilité d'une anomalie. Il est clair que puisque la valeur est proche de 100, cela signifie une anomalie. La colonne sous le graphique montre une probabilité désobligeante de 0,000063634% de l'apparition de la valeur métrique à cet endroit.
En plus de rechercher des anomalies dans Kibana, vous pouvez exécuter des prévisions. Cela se fait de manière élémentaire et à partir de la même vue avec des anomalies - le bouton
Prévision dans le coin supérieur droit.

Les prévisions sont basées sur un maximum de 8 semaines à l'avance. Même si vous le voulez vraiment, vous ne pouvez plus par conception.
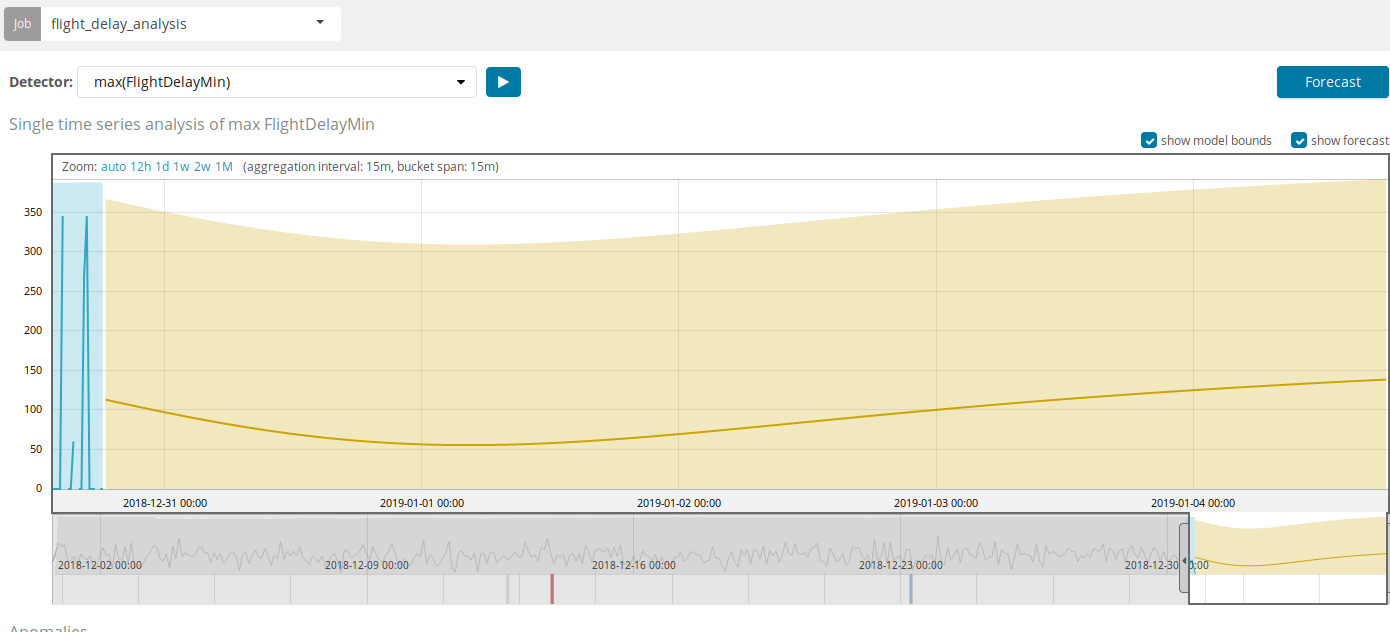
Dans certaines situations, les prévisions seront très utiles, par exemple, lorsque la charge utilisateur sur l'infrastructure est surveillée.
Multi métrique
Nous passons à la prochaine fonctionnalité ML dans Elastic Stack - l'analyse de plusieurs métriques dans un bundle. Mais cela ne signifie pas que la dépendance d'une métrique à une autre sera analysée. C'est la même chose que Single Metric avec seulement beaucoup de métriques sur un écran pour une comparaison facile des effets de l'une sur l'autre. Nous parlerons de l'analyse de la dépendance d'une métrique à l'autre dans la partie de la population.
Après avoir cliqué sur le carré avec Multi Metric, une fenêtre de paramètres apparaîtra. Nous y reviendrons plus en détail.
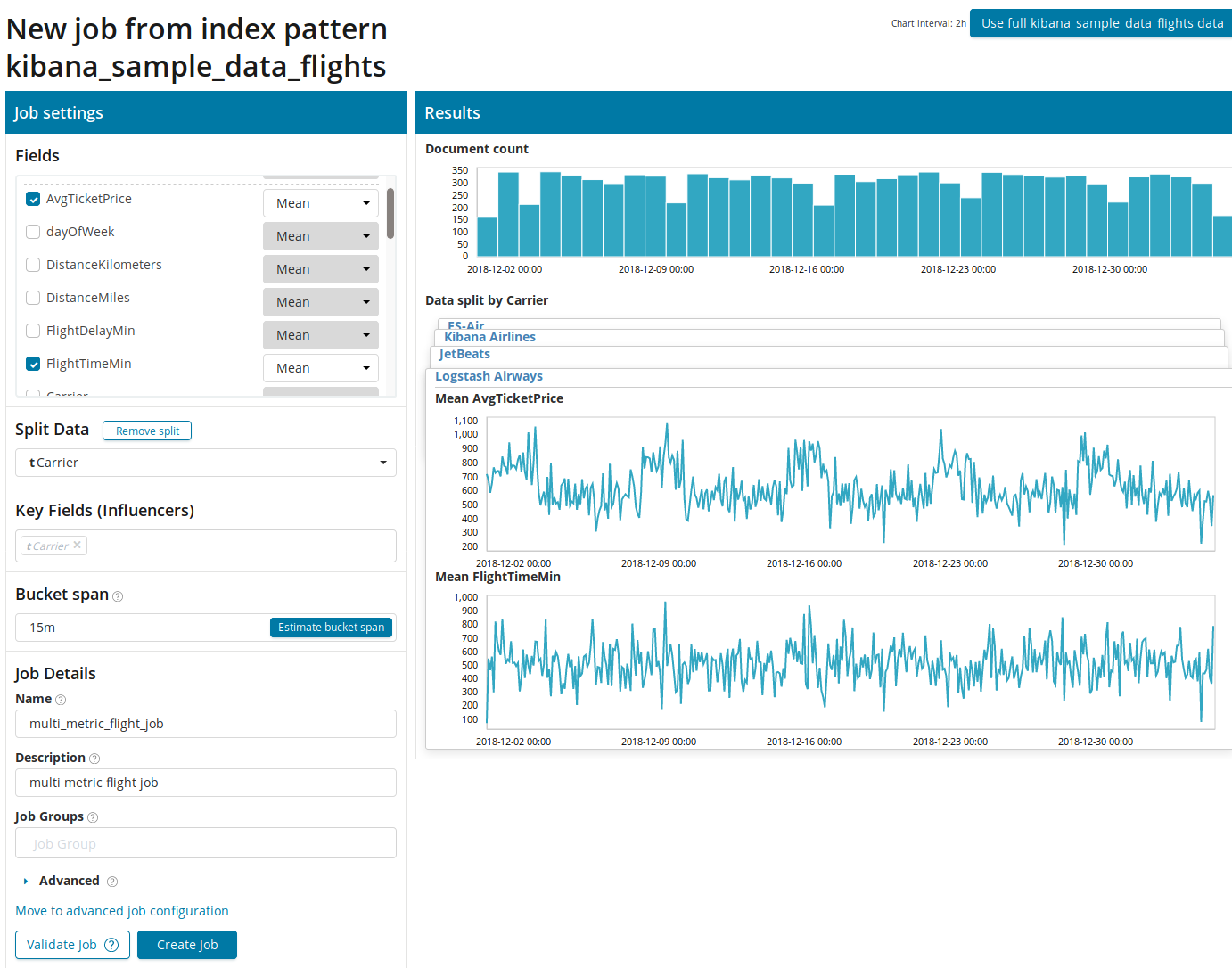
Vous devez d'abord sélectionner les champs pour l'analyse et l'agrégation des données sur eux. Les options d'agrégation ici sont les mêmes que pour la métrique simple (
Max, Moyenne Hign, Basse, Moyenne, Distincte et autres). De plus, les données sont éventuellement divisées en l'un des champs (champ
Split Data ). Dans l'exemple, nous l'avons fait en utilisant le champ
OriginAirportID . Notez que le graphique des mesures à droite est maintenant présenté sous forme de graphiques multiples.
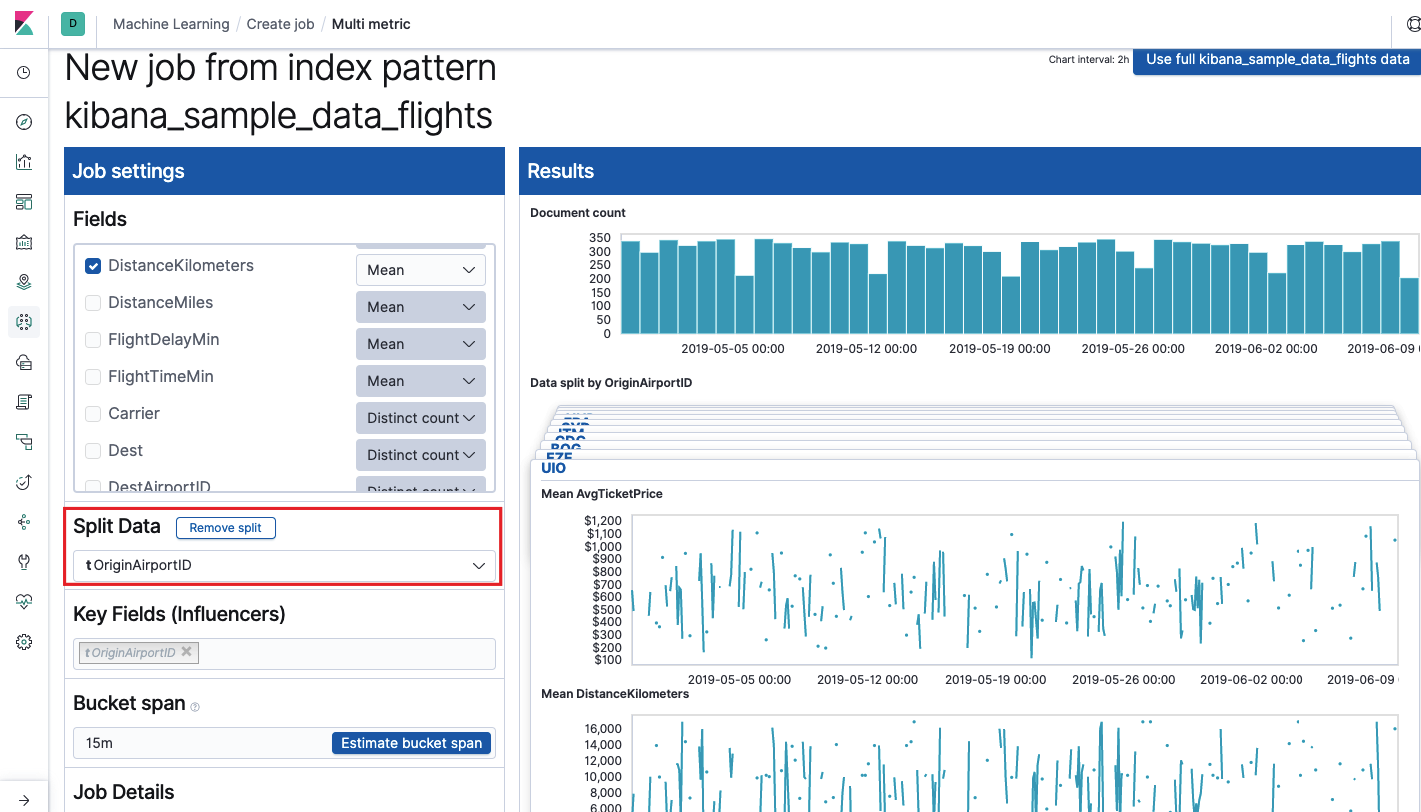
Le
champ Key Fields (Influencers) affecte directement les anomalies trouvées. Par défaut, il y aura toujours au moins une valeur et vous pouvez en ajouter d'autres. L'algorithme prendra en compte l'influence de ces champs dans l'analyse et montrera les valeurs les plus «influentes».
Après le lancement, l'image suivante apparaîtra dans l'interface Kibana.
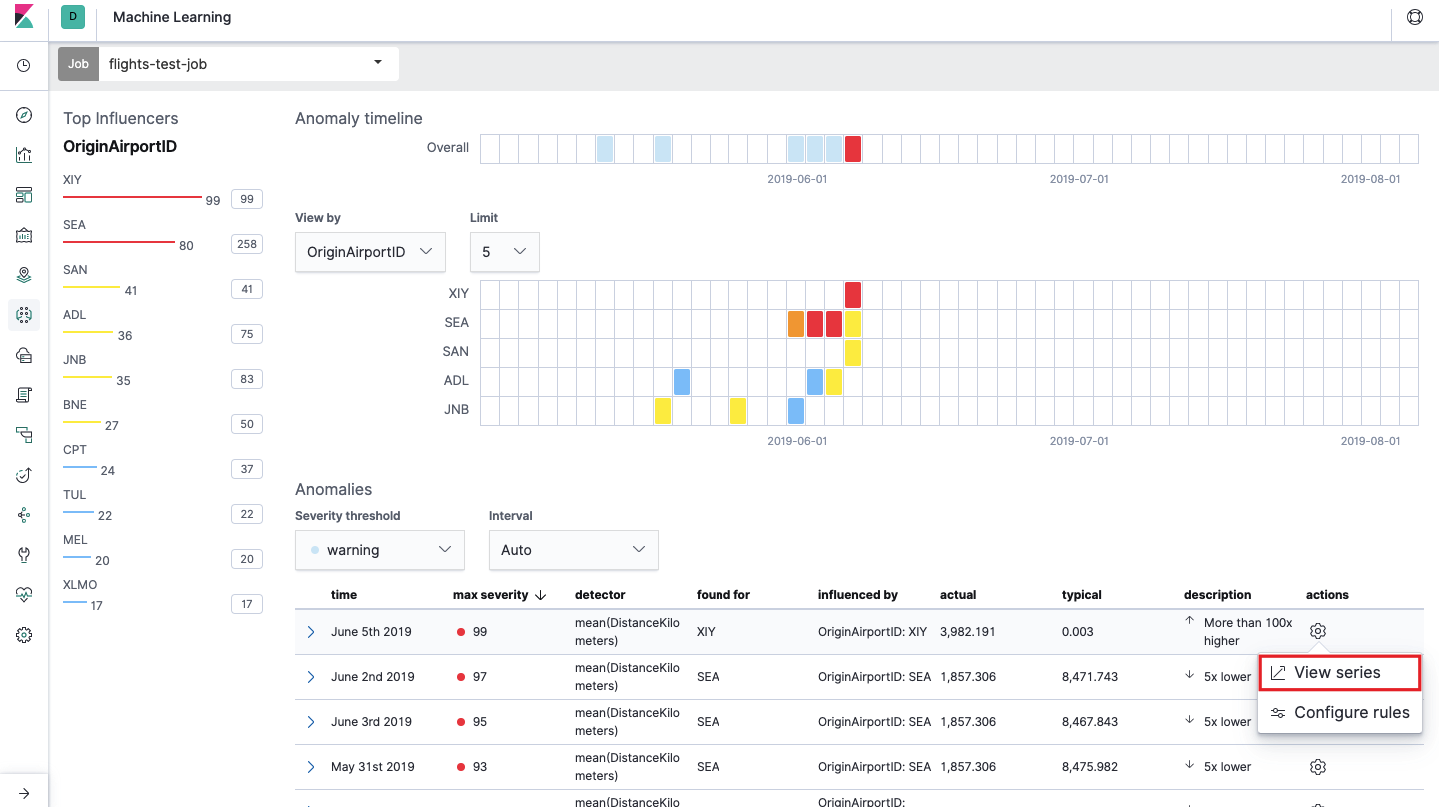
C'est ce qu'on appelle carte thermique des anomalies pour chaque valeur du champ
OriginAirportID que nous avons spécifié dans les
données fractionnées . Comme pour la métrique simple, la couleur indique le niveau de déviation anormale. Il est commode de faire une analyse similaire, par exemple, sur les postes de travail pour suivre ceux où il y a étrangement beaucoup d'autorisations, etc. Nous avons déjà écrit
sur les événements suspects dans EventLog Windows , qui peuvent également être collectés et analysés ici.
Sous la carte thermique se trouve une liste des anomalies, à partir de chacune, vous pouvez accéder à la vue métrique unique pour une analyse détaillée.
Population
Pour rechercher des anomalies parmi les corrélations entre différentes métriques, Elastic Stack dispose d'une analyse de population spécialisée. C'est à l'aide de celui-ci que vous pouvez rechercher des valeurs anormales dans les performances d'un serveur par rapport à d'autres avec, par exemple, une augmentation du nombre de requêtes vers le système cible.
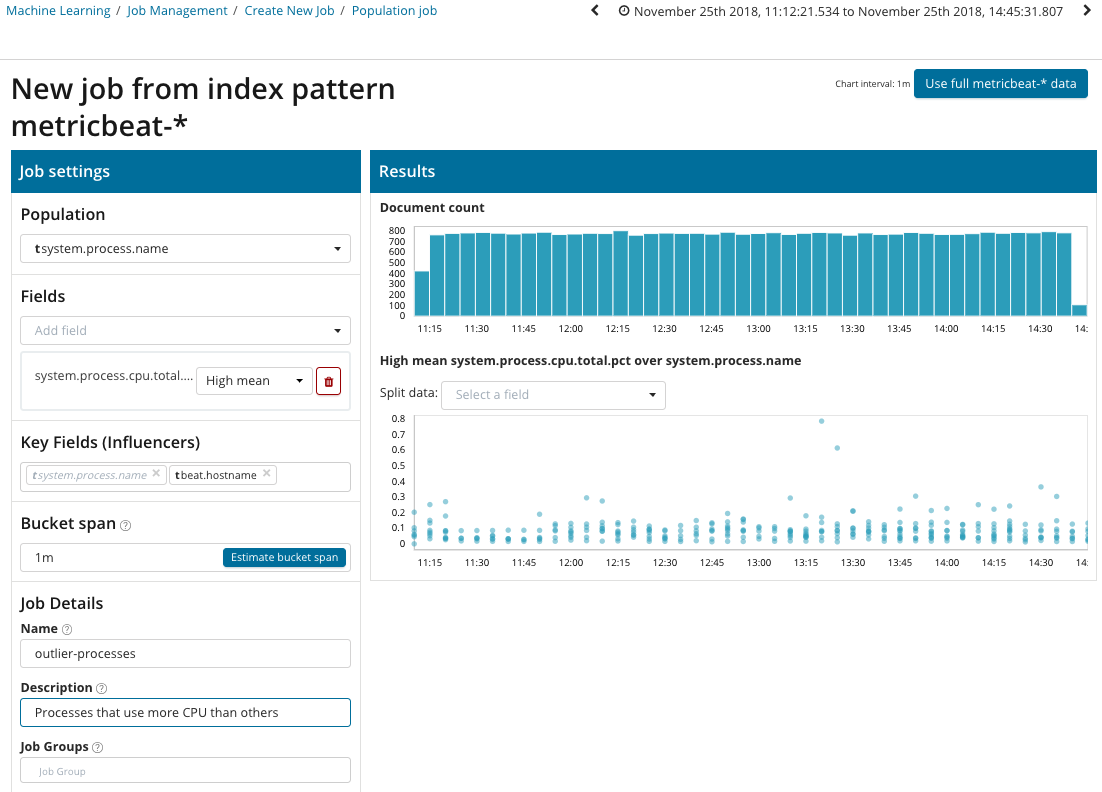
Dans cette illustration, le champ Population indique la valeur à laquelle les mesures analysées se rapporteront. C'est le nom du processus. En conséquence, nous verrons comment le chargement du processeur par chacun des processus s'est influencé les uns les autres.
Veuillez noter que le graphique des données analysées est différent des cas avec une seule métrique et plusieurs métriques. Cela se fait à Kibana par conception pour une meilleure perception de la distribution des valeurs des données analysées.

Le graphique montre que le processus de
stress (en passant, généré par un utilitaire spécial) sur le serveur
poipu s'est comporté de manière anormale , ce qui a influencé (ou s'est avéré être un influenceur) la survenue de cette anomalie.
Avancé
Analytique affinée. Avec Advanced Analysis, des paramètres supplémentaires apparaissent dans Kibana. Après avoir cliqué sur le menu de création sur la vignette Avancé, une telle fenêtre à onglets apparaît. L'onglet
Détails du travail a été délibérément ignoré, les paramètres de base ne sont pas directement liés aux paramètres d'analyse.
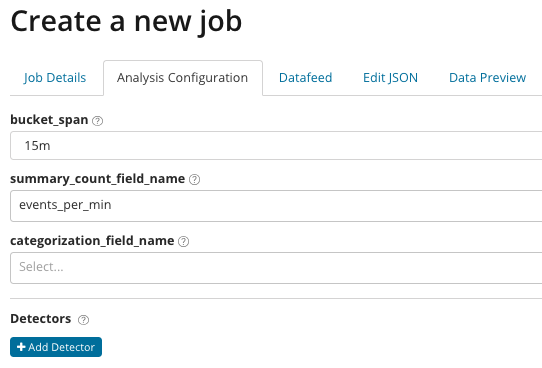
Dans
summary_count_field_name, vous pouvez éventuellement spécifier le nom du champ à partir des documents contenant des valeurs agrégées. Dans cet exemple, le nombre d'événements par minute. Le
categorization_field_name indique le nom de la valeur de champ du document, qui contient une sorte de valeur de variable. En masquant ce champ, vous pouvez diviser les données analysées en sous-ensembles. Faites attention au bouton
Ajouter un détecteur dans l'illustration précédente. Ci-dessous le résultat du clic sur ce bouton.

Voici un bloc de paramètres supplémentaires pour configurer le détecteur d'anomalie pour une tâche spécifique. Nous prévoyons d'analyser des cas d'utilisation spécifiques (notamment pour la sécurité) dans les articles suivants. Pour un exemple,
regardez l' un des cas démontés. Il est associé à la recherche de valeurs apparaissant rarement et est implémenté
par la fonction rare .
Dans le champ de
fonction , vous pouvez sélectionner une fonction spécifique pour rechercher des anomalies. En plus de
rares , il existe quelques fonctions intéressantes -
time_of_day et time_of_week . Ils identifient des anomalies dans le comportement des mesures au cours de la journée ou de la semaine, respectivement. Les autres fonctions d'analyse se
trouvent dans la documentation .
Le nom de
champ indique le champ du document qui sera analysé.
By_field_name peut être utilisé pour séparer les résultats d'analyse pour chaque valeur individuelle du champ de document spécifié ici. Si vous remplissez
over_field_name, vous obtenez l'analyse de la population, que nous avons examinée ci-dessus. Si vous spécifiez une valeur dans
partition_field_name , alors sur ce champ de document, des lignes de base individuelles pour chaque valeur seront calculées (par exemple, le nom du serveur ou le processus sur le serveur peut jouer le rôle de la valeur). Dans
exclude_frequent, vous pouvez sélectionner
tout ou
aucun , ce qui signifie l'exclusion (ou l'inclusion) des valeurs de champ de document fréquemment rencontrées.
Dans l'article que nous avons essayé de donner l'idée la plus concise sur les possibilités d'apprentissage automatique dans Elastic Stack, il y a encore beaucoup de détails dans les coulisses. Dites-nous dans les commentaires quels cas vous avez réussi à résoudre avec l'aide d'Elastic Stack et pour quelles tâches vous l'utilisez. Pour nous contacter, vous pouvez utiliser des messages personnels sur Habré ou le
formulaire de feedback sur le site .