J'attire votre attention sur une traduction du rapport d'Alexander Kuzmenko (depuis avril de cette année, il travaille officiellement en tant que développeur du compilateur Haxe) sur les changements dans le langage Haxe qui se sont produits depuis la sortie de Haxe 3.4.

Plus de deux ans et demi se sont écoulés depuis la sortie de Haxe 3.4. Pendant ce temps, 7 patchs, 5 versions de prévisualisation de Haxe 4 et 2 candidats à la sortie de Haxe 4. Ce fut un long chemin vers la nouvelle version et elle est presque prête ( environ 20 problèmes restent à résoudre).

Alexander a remercié la communauté Haxe pour avoir signalé des bugs, pour leur désir de participer au développement du langage. Grâce au projet haxe-evolution , des choses comme les suivantes apparaîtront dans Haxe 4:
- balisage en ligne
- fonctions intégrées à l'emplacement de l'appel
- fonctions fléchées

En outre, dans le cadre de ce projet, des discussions sont en cours sur des innovations possibles telles que: Promesses , polymorphic this et types par défaut (paramètres de type par défaut).
Ensuite, Alexander a parlé des changements dans la syntaxe de la langue .

Le premier est la nouvelle syntaxe pour décrire la syntaxe des types de fonction. L'ancienne syntaxe était un peu étrange.
Haxe est un langage de programmation multi-paradigmes, il a toujours pris en charge les fonctions de première classe, mais la syntaxe pour décrire les types de fonctions a été héritée d'un langage fonctionnel (et diffère de celle adoptée dans d'autres paradigmes). Et les programmeurs habitués à la programmation fonctionnelle attendent des fonctions avec cette syntaxe pour prendre en charge le curry automatique. Mais à Haxe, ce n'est pas le cas.
Le principal inconvénient de l'ancienne syntaxe, selon Alexander, est l'incapacité à déterminer les noms des arguments, c'est pourquoi vous devez écrire de longs commentaires d'annotation avec une description des arguments.
Mais nous avons maintenant une nouvelle syntaxe pour décrire les types de fonctions (qui, soit dit en passant, a été ajoutée au langage dans le cadre de l'initiative haxe-evolution), où une telle opportunité existe (bien que ce soit facultatif, mais recommandé). La nouvelle syntaxe est plus facile à lire et peut même être considérée comme faisant partie de la documentation du code.
Un autre inconvénient de l'ancienne syntaxe pour décrire les types de fonction était son incohérence - la nécessité de spécifier le type d'arguments de la fonction même lorsque la fonction n'accepte aucun argument: Void->Void (cette fonction ne prend aucun argument et ne renvoie rien).
Dans la nouvelle syntaxe, cela est implémenté plus élégamment: ()->Void

Le second est les fonctions fléchées ou expressions lambda - une forme abrégée pour décrire les fonctions anonymes. La communauté demande depuis longtemps de les ajouter à la langue, et finalement c'est arrivé!
Dans ces fonctions, au lieu du mot-clé de return , la séquence de caractères -> (d'où le nom de la syntaxe est "fonction flèche").
Dans la nouvelle syntaxe, il reste possible de définir les types d'arguments (puisque le système d'inférence de type automatique ne peut pas toujours le faire comme le veut le programmeur, par exemple, le compilateur peut décider d'utiliser Float au lieu de Int ).
La seule limitation de la nouvelle syntaxe est l'impossibilité de définir explicitement le type de retour. Si nécessaire, vous avez le choix d'utiliser l'ancienne syntaxe ou d'utiliser la syntaxe de type de contrôle dans le corps de la fonction, qui indiquera au compilateur le type de retour.

Les fonctions fléchées n'ont pas de représentation spéciale dans l'arbre de syntaxe; elles sont traitées de la même manière que les fonctions anonymes classiques. La séquence -> est remplacée par le mot clé return .

Le troisième changement - final maintenant devenu un mot-clé (dans Haxe 3, final était l'une des balises META intégrées au compilateur).
Si vous l'appliquez à une classe, il en interdira l'héritage, il en va de même pour les interfaces. L'application du qualificatif final à une méthode de classe empêchera son remplacement dans les classes enfants.
Cependant, dans Haxe, il y avait un moyen de contourner les restrictions imposées par le mot-clé final - vous pouvez utiliser la balise meta @:hack pour cela (mais cela ne devrait être fait que si cela est absolument nécessaire).
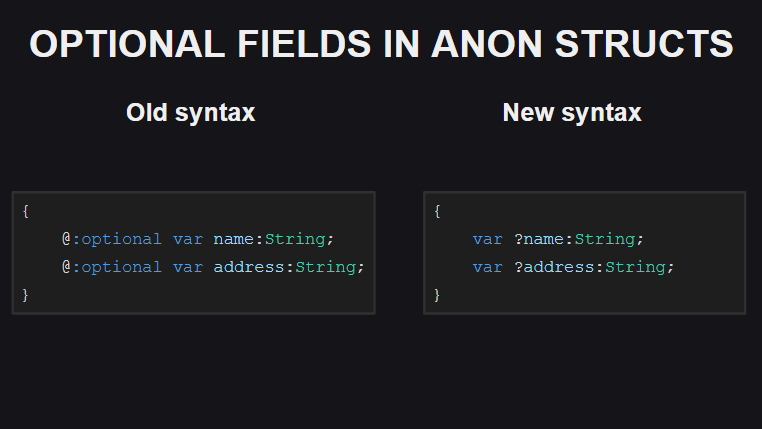
Le quatrième changement est un moyen de déclarer des champs facultatifs dans des structures anonymes. Auparavant, la balise Meta @:optional était utilisée pour cela, il suffit maintenant d'ajouter un point d'interrogation devant le nom du champ.

Cinquièmement, les énumérations abstraites sont devenues un membre à part entière de la famille de types Haxe, et au lieu de la balise meta @:enum mot clé @:enum est maintenant utilisé pour les déclarer.
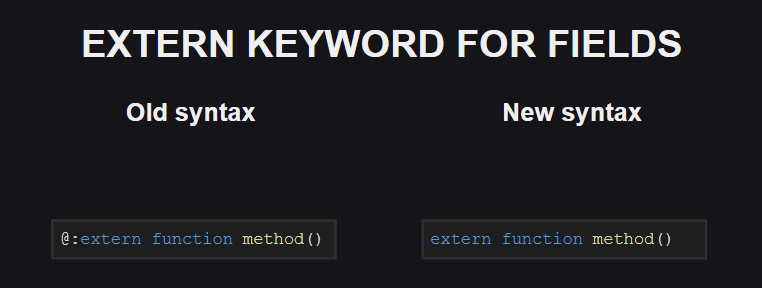
Une modification similaire a affecté la balise @:extern .

Septième est une nouvelle syntaxe d'intersection de type qui reflète mieux l'essence des structures en expansion.
La même nouvelle syntaxe est utilisée pour limiter les contraintes des paramètres de type; elle transmet plus précisément les restrictions imposées à un type. Pour une personne qui ne connaît pas Haxe, l'ancienne syntaxe MyClass<T:(Type1, Type2)> peut être perçue comme une exigence pour que le type du paramètre T soit Type1 ou Type2 . La nouvelle syntaxe nous dit explicitement que T doit être à la fois Type1 et Type2 en même temps.
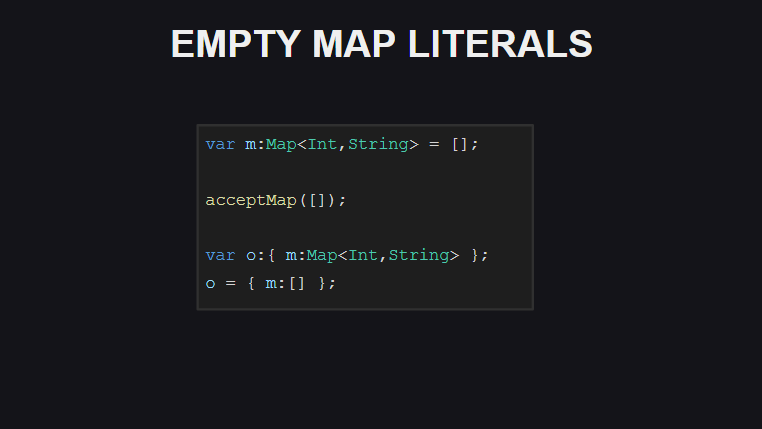
Le huitième est la possibilité d'utiliser [] pour déclarer un conteneur Map vide (cependant, si vous ne spécifiez pas explicitement le type de la variable, le compilateur affichera le type sous forme de tableau dans ce cas).
Après avoir parlé des changements de syntaxe, passons à la description des nouvelles fonctions du langage .
Commençons par les nouveaux itérateurs valeur-clé
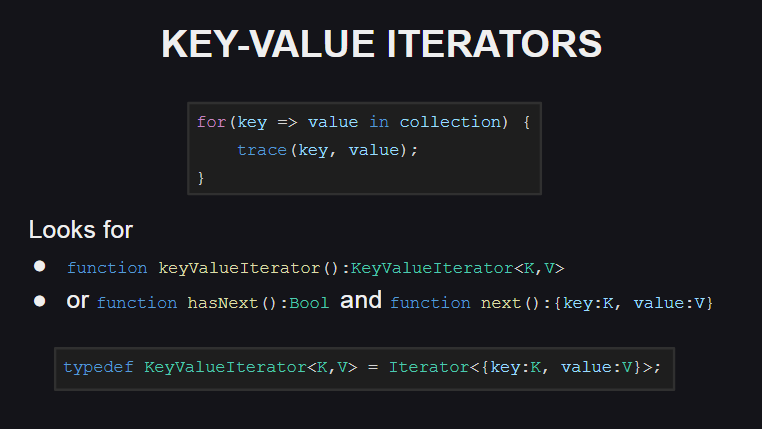
Une nouvelle syntaxe a été ajoutée pour leur utilisation.
Pour prendre en charge de tels itérateurs, le type doit implémenter la méthode keyValueIterator():KeyValueIterator<K, V> ou les méthodes hasNext():Bool et next():{key:K, value:V} . Dans le même temps, le type KeyValueIterator<K, V> est synonyme d'un itérateur régulier dans la structure anonyme Iterator<{key:K, value:V}> .
Les itérateurs de valeur-clé sont implémentés pour certains types à partir de la bibliothèque standard Haxe ( String , Map , DynamicAccess ), et des travaux sont également en cours pour les implémenter pour les tableaux.
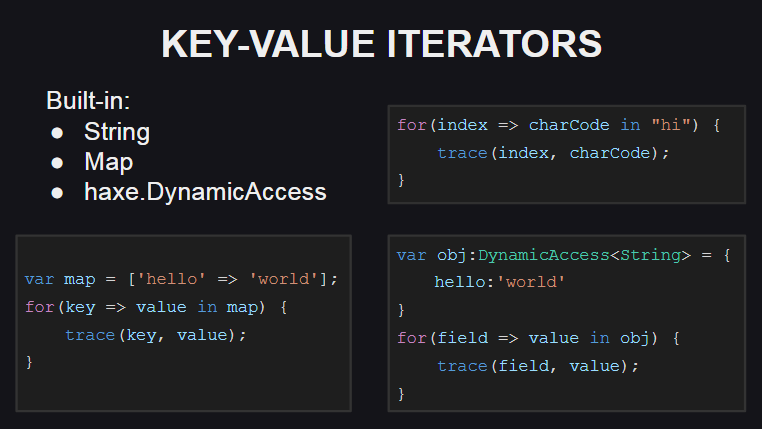
Pour les chaînes, l'index de caractères dans la chaîne est utilisé comme clé et le code de caractère à l'index donné est utilisé comme valeur (si le caractère lui-même est nécessaire, alors la méthode String.fromCharCode() peut être utilisée).
Pour le conteneur Map , le nouvel itérateur fonctionne de la même manière que l'ancienne méthode d'itération, c'est-à-dire qu'il reçoit un tableau de clés dans le conteneur et le traverse, en demandant des valeurs pour chacune des clés.
Pour DynamicAccess (un wrapper pour les objets anonymes), l'itérateur fonctionne en utilisant la réflexion (pour obtenir une liste des champs d'un objet à l'aide de la méthode Reflect.fields() et pour obtenir les valeurs de champ par leurs noms à l'aide de la méthode Reflect.field() ).

Haxe 4 utilise un nouvel interpréteur de macros, "eval". Simon Krajewski, l'auteur de l'interprète, l'a décrit en détail dans le blog officiel de Haxe , ainsi que dans son rapport d'avancement de l'année dernière .
Les principaux changements dans le travail de l'interprète:
- il est plusieurs fois plus rapide que l'ancien macro interprète (4 fois en moyenne)
- prend en charge le débogage interactif (auparavant, pour les macros, seule la sortie de la console pouvait être utilisée)
- il est utilisé pour exécuter le compilateur en mode interprète (auparavant neko était utilisé pour cela. Par ailleurs, eval surpasse également neko en vitesse).

La prise en charge Unicode pour toutes les plates-formes (à l'exception de neko) est l'un des plus grands changements dans Haxe 4. Simon en a parlé en détail l'année dernière . Mais voici un bref aperçu de l'état actuel de la prise en charge des chaînes Unicode dans Haxe:
- pour Lua, PHP, Python et eval (interpréteur de macros), la prise en charge unicode complète est implémentée (encodage UTF8)
- pour les autres plateformes (JavaScript, C #, Java, Flash, HashLink et C ++), le codage UTF16 est utilisé.
Ainsi, les lignes dans Haxe fonctionnent de la même manière pour les caractères inclus dans le plan multilingue principal , mais pour les caractères en dehors de ce plan (par exemple, pour les emoji), le code de travail avec les lignes peut produire des résultats différents selon la plate-forme (mais c'est encore mieux, que la situation que nous avons dans Haxe 3, lorsque chaque plate-forme avait son propre comportement).

Pour les chaînes codées Unicode (à la fois en UTF8 et UTF16), des itérateurs spéciaux ont été ajoutés à la bibliothèque standard de Haxe qui fonctionnent également sur TOUTES les plates-formes pour tous les caractères (à la fois dans le plan principal multilingue et au-delà):
haxe.iterators.StringIteratorUnicode haxe.iterators.StringKeyValueIteratorUnicode

Étant donné que la mise en œuvre des chaînes varie d'une plateforme à l'autre, il est nécessaire de garder à l'esprit certaines des nuances de leur travail. En UTF16, chaque caractère prend 2 octets, donc l'accès à un caractère dans une chaîne par index est rapide, mais uniquement dans le plan principal multilingue. En revanche, en UTF8, tous les caractères sont pris en charge, mais cela se fait au prix d'une recherche lente d'un caractère dans une chaîne (car les caractères peuvent occuper différents nombres d'octets en mémoire, accéder à un caractère par index nécessite une itération à travers la ligne à chaque fois depuis le tout début). Par conséquent, lorsque vous travaillez avec de grandes chaînes en Lua et PHP, vous devez garder à l'esprit que l'accès à un caractère arbitraire fonctionne assez lentement (également sur ces plateformes, la longueur de la chaîne est à nouveau calculée à chaque fois).
Cependant, bien que la prise en charge complète d'Unicode soit déclarée pour Python, cette restriction ne s'applique pas car les lignes qu'il contient sont implémentées de manière légèrement différente: pour les caractères dans le plan multilingue principal, il utilise le codage UTF16 et pour les caractères plus larges (3 et plus d'octets) Python utilise UTF32.
Des optimisations supplémentaires sont implémentées pour l'interpréteur de macros eval: la chaîne «sait» si elle contient des caractères Unicode. Dans le cas où il ne contient pas de tels caractères, la chaîne est interprétée comme constituée de caractères ASCII (où chaque caractère prend 1 octet). L'accès séquentiel par index dans eval est également optimisé: la position du dernier caractère accédé est mise en cache dans la ligne. Donc, si vous vous tournez d'abord vers le 10e caractère de la chaîne, puis lorsque vous vous tournerez vers le 20e caractère, eval le recherchera non pas au tout début de la ligne, mais à partir du 10e. De plus, la longueur de chaîne dans eval est mise en cache, c'est-à-dire qu'elle est calculée uniquement lors de la première demande.
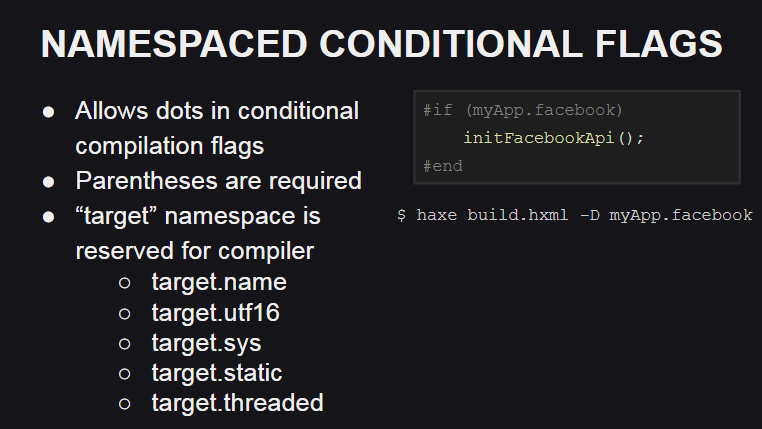
Haxe 4 introduit la prise en charge des espaces de noms pour les drapeaux de compilation, qui peuvent être utiles, par exemple, pour organiser le code lors de l'écriture de bibliothèques personnalisées.
En outre, un espace de noms réservé pour les indicateurs de compilation est apparu - target , qui est utilisé par le compilateur pour décrire la plate-forme cible et son comportement:
target.name - nom de la plateforme (js, cpp, php, etc.)target.utf16 - indique que le support Unicode est implémenté en utilisant UTF16target.sys - indique si les classes du package sys sont disponibles (par exemple, pour travailler avec le système de fichiers)target.static - indique si la plate-forme est statique (sur les plates-formes statiques, les types de base Int , Float et Bool ne peuvent pas avoir la valeur null comme valeur)target.threaded - indique si la plateforme prend en charge le multithreading
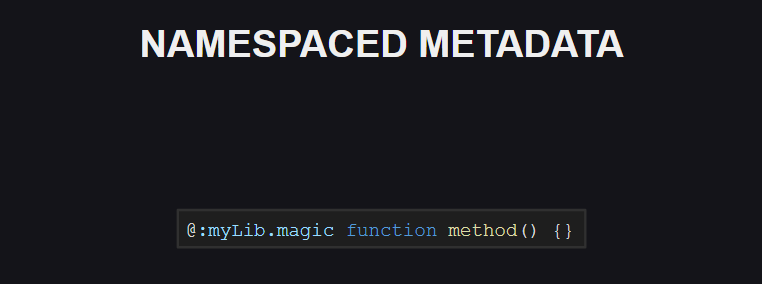
De même, le support d'espace de noms pour les balises META est apparu. Jusqu'à présent, il n'y a pas d'espaces de noms réservés pour les balises META dans la langue, mais la situation pourrait changer à l'avenir.

Le type ReadOnlyArray ajouté à la bibliothèque standard Haxe - une abstraction sur un tableau normal, dans laquelle les méthodes ne sont disponibles que pour lire les données du tableau.

Une autre innovation dans la langue concerne les champs finaux et les variables locales.
Si final utilisé à la place du mot-clé var lors de la déclaration d'un champ de classe ou d'une variable locale, cela signifie que le champ ou la variable donné ne peut pas être réaffecté (si le compilateur essaie de le faire, il générera une erreur). Mais en même temps, son état peut être changé, donc le champ ou la variable finale n'est pas une constante.
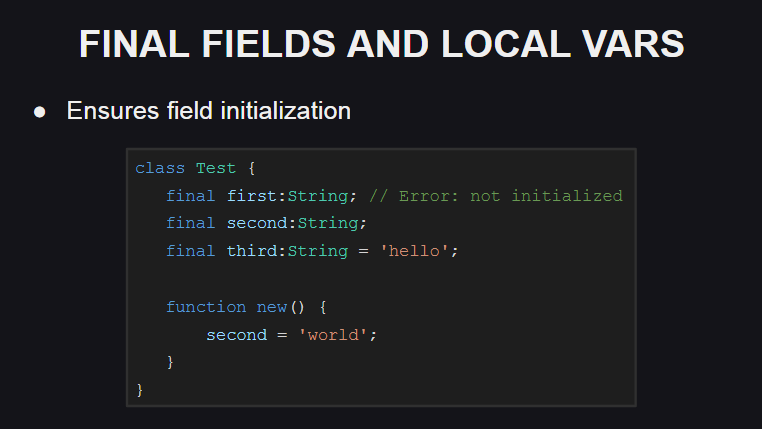
Les valeurs des champs finaux doivent être initialisées soit lors de leur déclaration, soit dans le constructeur, sinon le compilateur lèvera une erreur.

HashLink est une nouvelle plate-forme avec sa propre machine virtuelle, créée spécifiquement pour Haxe. HashLink prend en charge la soi-disant «double compilation» - le code peut être compilé soit en bytecode (qui est très rapide, accélère le processus de débogage des applications développées), soit en C-code (qui se caractérise par des performances accrues). Nicholas a dédié HashLink à plusieurs articles du blog Haxe et a également parlé de lui lors de la conférence de Seattle l' an dernier . La technologie HashLink est utilisée dans des jeux populaires comme Dead Cells et Northgard.

Une autre nouvelle fonctionnalité intéressante de Haxe 4 est la sécurité Null, qui est encore au stade expérimental (en raison de faux positifs et de contrôles de sécurité de code insuffisants).
Qu'est-ce que la sécurité nulle? Si votre fonction ne déclare pas explicitement qu'elle peut accepter null comme valeurs de paramètre, alors lorsque vous essayez de lui passer null , le compilateur lèvera l'erreur correspondante. De plus, pour les paramètres de fonction qui peuvent prendre null comme valeur, le compilateur vous demandera d'écrire du code supplémentaire pour vérifier et gérer de tels cas.
Cette fonctionnalité est désactivée par défaut, mais elle n'affecte pas la vitesse d'exécution du code (si vous l'activez néanmoins), car les vérifications décrites ne sont effectuées qu'au stade de la compilation. Il peut être activé pour tout le code, ainsi que progressivement pour des champs, des classes et des packages individuels (fournissant ainsi une transition progressive vers un code plus sécurisé). Vous pouvez utiliser des balises META et des macros spéciales pour cela.
Les modes dans lesquels la sécurité Null peut fonctionner sont: Strict (le plus strict), Loose (le mode par défaut) et Off (utilisé pour désactiver les vérifications pour les packages et types individuels).

Pour la fonction illustrée sur la diapositive, le contrôle de sécurité Null est activé. Nous voyons que cette fonction a un paramètre facultatif s , c'est-à-dire que nous pouvons lui passer null comme valeur de paramètre. Lorsque vous essayez de compiler du code avec une telle fonction, le compilateur produira un certain nombre d'erreurs:
- en essayant d'accéder à un champ de l'objet
s (car il peut être null ) - lorsque vous essayez d'affecter une variable str, qui, comme nous le voyons, ne devrait pas être
null (sinon nous aurions dû la déclarer non pas comme String , mais comme Null<String> ) - en essayant de renvoyer un objet
s partir d'une fonction (puisque la fonction ne doit pas retourner null )
Comment corriger ces erreurs?
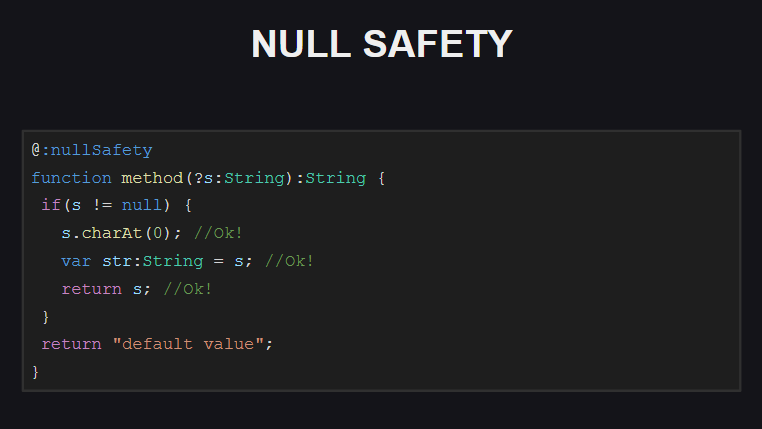
Nous avons juste besoin d'ajouter la vérification null au code (à l'intérieur du bloc avec la vérification null , le compilateur "sait" que s ne peut pas être null et peut être utilisé en toute sécurité avec lui), et aussi s'assurer que la fonction ne retourne pas null !

De plus, lors de la vérification de la sécurité Null, le compilateur prend en compte l'ordre dans lequel les programmes sont exécutés. Par exemple, si après avoir vérifié la valeur du paramètre s à null pour terminer la fonction (ou lever une exception), le compilateur «saura» qu'après une telle vérification, le paramètre s ne peut plus être null et qu'il peut être utilisé en toute sécurité.

Si le compilateur active le mode strict de vérifications de la sécurité Null, il nécessitera des vérifications supplémentaires pour null dans les cas où entre la vérification initiale de la valeur pour null et une tentative d'accès au champ de l'objet, tout code a été exécuté qui pourrait le mettre à null .
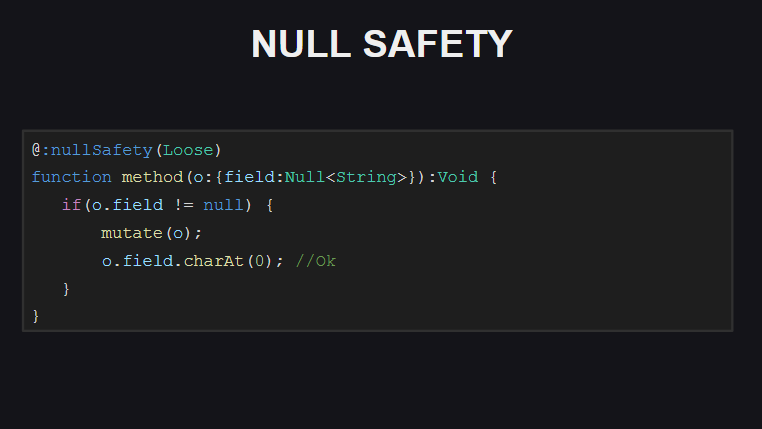
En mode Loose (utilisé par défaut), le compilateur n'exige pas de telles vérifications (au fait, ce comportement est également utilisé par défaut dans TypeScript).

En outre, lorsque les vérifications de la sécurité Null sont activées, le compilateur vérifie si les champs des classes sont initialisés (directement lorsqu'ils sont déclarés ou dans le constructeur). Sinon, le compilateur générera des erreurs en essayant de passer un objet d'une telle classe, ainsi qu'en essayant d'appeler des méthodes sur de tels objets, jusqu'à ce que tous les champs de l'objet soient initialisés. Ces vérifications peuvent être désactivées pour les champs individuels de la classe en les marquant avec la balise @:nullSafety(Off)
Alexander a parlé davantage de la sécurité Null à Haxe en octobre dernier .

Haxe 4 a introduit la possibilité de générer des classes ES6 pour JavaScript; il est activé en utilisant l'indicateur de compilation js-es=6 .
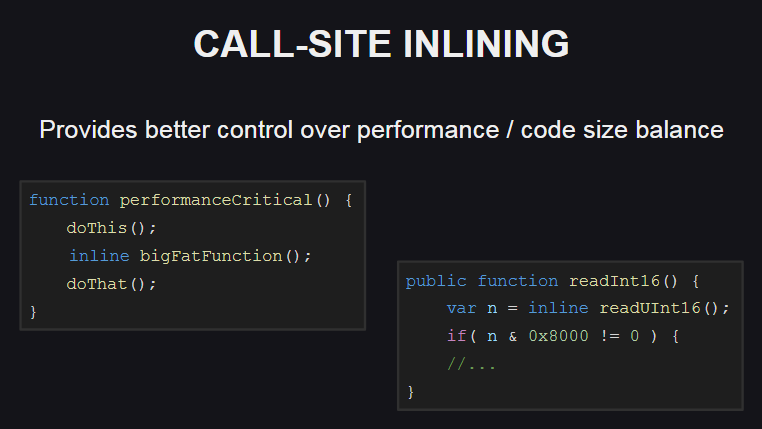
L'incorporation de fonctions à l'endroit d'un appel (alignement du site d'appel) offre plus d'options pour contrôler l'équilibre entre les performances et la taille du code. Cette fonctionnalité est également utilisée dans la bibliothèque standard Haxe.
Comment est-elle? Il vous permet d'incorporer le corps de la fonction (à l'aide du inline ) uniquement aux endroits où il est nécessaire d'assurer des performances élevées (par exemple, si nécessaire, appelez une méthode suffisamment volumineuse dans la boucle), tandis qu'à d'autres endroits, le corps de la fonction n'est pas incorporé. Par conséquent, la taille du code généré sera légèrement augmentée.
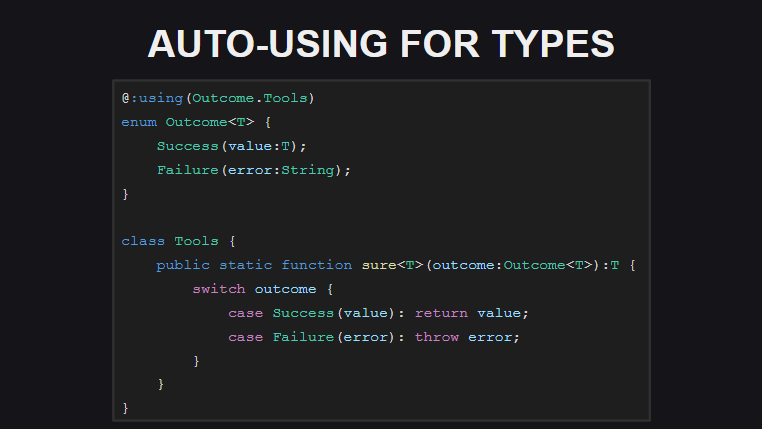
L'utilisation automatique (extensions automatiques pour les types) signifie que maintenant pour les types, vous pouvez déclarer des extensions statiques à l'endroit de la déclaration de type. Cela élimine le besoin d'utiliser la construction de using type; chaque fois using type; dans chaque module où le type et les méthodes d'extension sont utilisés. Pour le moment, ce type d'extension n'est implémenté que pour les transferts, mais dans la version finale (et dans les versions nocturnes), il peut être utilisé non seulement pour les transferts.

Dans Haxe 4, il sera possible de redéfinir l'opérateur d'accès aux champs d'un objet pour les types abstraits (uniquement pour les champs qui n'existent pas dans le type). Pour ce faire, utilisez des méthodes marquées avec la balise meta @:op(ab) .

Le balisage intégré est une autre fonctionnalité expérimentale de Haxe. Le code de balisage intégré n'est pas traité par le compilateur comme un document xml - le compilateur le voit comme une chaîne enveloppée dans la balise Meta @:markup . .
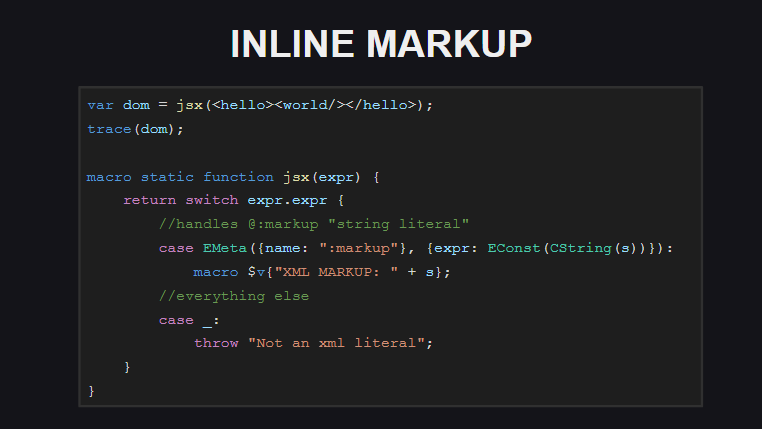
-, - @:markup , .

( untyped ). . , , Js.build() - @:markup , <js> , js-.

Haxe 4 - - , — .

. , . , Int , , C.
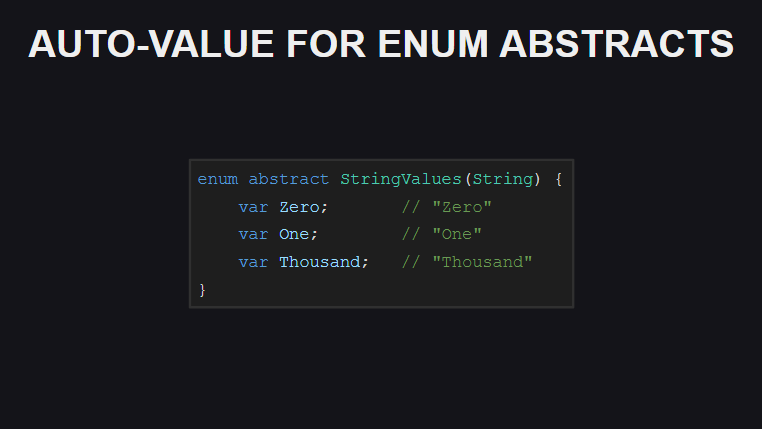
— .
:

JVM- JDK, Java-. . .

, async / await yield . ( C#, ). Haxe github.

Haxe , . ( ) . , .

API . , , API .
Haxe 4 !