
Les moteurs de recherche n'ont pas beaucoup de logique, c'est un fait. Mais ils essaient. Et les spécialistes du référencement essaient en réponse - ils essaient d'atteindre la pertinence maximale des pages, basée sur des suppositions et des expérimentations.
Google s'est récemment réjoui d'un nouveau facteur de classement - Neural Matching. Nous avons lu que les experts écrivent à ce sujet et avons collecté quelques astuces qui vous aideront à rédiger des textes plus pertinents pour les demandes.
Et au fait, NM n'est pas LSI pour vous, c'est un peu plus compliqué.
En septembre 2018, Danny Sullivan a tweeté qu'au cours des derniers mois, Google avait utilisé la méthode AI Neural Matching pour mieux associer les mots aux concepts. Cet algorithme a influencé les résultats de 30% des demandes dans le monde.

Nous n'étions pas pressés d'écrire sur le nouvel algorithme, nous attendions les clarifications de Google et des recherches dans ce domaine. Mais les choses sont toujours là - la plupart des commentateurs montrent les mêmes captures d'écran et parlent de la transition de la recherche par mots à la recherche par intention. Ils font également référence au modèle de correspondance de pertinence profonde (DRMM) .
Essayons de déterminer quel type d'animal est cette correspondance neuronale et comment adapter le contenu du site pour cela.
Exemples de correspondance neuronale
Danny Sullivan décrit ce qu'est le Neural Matching. Il a donné un exemple d'émission de la question «pourquoi mon téléviseur semble-t-il étrange». L'utilisateur saisit une telle requête lorsqu'il ne sait pas encore quel est l'effet du feuilleton. Mais Google, grâce au nouvel algorithme, sait exactement ce dont vous avez besoin:

En russe, une histoire similaire:

Un autre exemple. Vous avez rencontré un "bel" insecte dans l'appartement et vous n'avez aucune idée de son nom:

Nous allons sur Google, saisissons un ensemble de fonctionnalités et en première position, nous obtenons la réponse pertinente:

L'implémentation de Neural Matching est due au fait que les utilisateurs ne savent pas toujours ce qu'ils recherchent et ne formulent pas toujours correctement les demandes. Danny Sullivan a montré plusieurs de ces «fausses» requêtes:

La tâche de Neural Matching est de déterminer la véritable intention de recherche (intention) et de produire les résultats corrects.

Pour déterminer l'intention, pas des mots séparés sont utilisés, mais des essences et des relations entre eux. Voyez comment cela fonctionne - sur l'exemple des requêtes «s'enivrer quoi faire» et «s'enivrer la nuit».
Chaque demande contient la même entité - "got ivre". Mais le combiner avec l'essence de "du jour au lendemain" signale au moteur de recherche que l'utilisateur veut dire trop manger. Et l'essence de «que faire» est très probablement associée à l'intoxication.

Comment Google définit-il l'intention - la sémantique est-elle similaire? Le moteur de recherche compare la fréquence à laquelle les entités combinées dans la demande sont trouvées côte à côte sur les pages. De plus, les statistiques sur les demandes sont prises en compte (les utilisateurs qui saisissent la demande "se saoulent la nuit" cliquent plus souvent sur des articles concernant spécifiquement la suralimentation).
Un autre exemple. L'utilisateur entre la phrase «mettre des fenêtres». C'est juste la «mauvaise» demande dont Danny Sullivan parle. Google comprend qu'une personne par «mettre» signifie autre chose qu'une simple installation de fenêtres, et affiche en HAUT les résultats qui sont corrects de son point de vue:
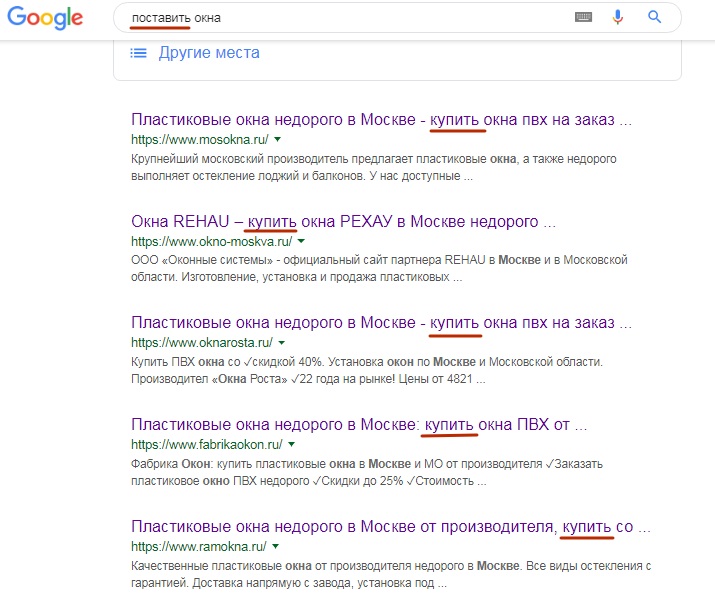
Dans ce cas, une seule page du TOP-6 contient le mot «livrer» (au sens de «fournisseur de fenêtres», et non «installer Windows vous-même»). Sur les pages restantes du TOP-6, il n'y a pas un mot «put», ni même des mots racines. Bien que des résultats comme "Comment installer Windows vous-même", etc., soient déjà mélangés ci-dessous.
Cela conduit à une conclusion apparemment paradoxale: pour occuper des positions élevées dans de nombreux mots, il n'est pas nécessaire de saturer des textes avec une sémantique similaire à une requête de recherche. La pertinence du contenu est évaluée par un ensemble d'entités (phrases marqueurs), qui sont très susceptibles de satisfaire l'intention de recherche.
Cela change l'approche de l'écriture des textes SEO: auparavant, les clés étaient le point de référence, maintenant les besoins du public.
Classement de pertinence des documents et correspondance neuronale - Comment cela affectera-t-il le référencement?
Roger Montti a suggéré dans un article pour Search Engine Journal que l'algorithme Neural Matching pourrait fonctionner sur la base de la méthode de classement par pertinence des documents (DRR). La méthode est décrite dans l'article « Classement de pertinence approfondie utilisant des interactions document-requête améliorées » publié sur Google AI.
L'essence de la méthode de RRC est que pour déterminer la pertinence d'un document, son texte est utilisé exclusivement. D'autres facteurs - liens, ancres, mentions, référencement sur la page - n'ont pas d'importance.
Quoi, les liens ne sont plus nécessaires du tout? Pas vraiment comme ça. Le classement selon la méthode DRR décrite fait partie de l'algorithme de classement général. Dans un premier temps, l'émission est formée en tenant compte de tous les facteurs de classement (liens, clés, «mobilité», géolocalisation, etc.). Ainsi, le moteur de recherche élimine le contenu de base et identifie les sites de bonne réputation. À la deuxième étape, la RRC entre dans le travail - parmi les meilleurs résultats, il sélectionne les plus pertinents (mais ne prend en compte que le texte).
En pratique, cela peut ressembler à ceci. Il existe deux sites: un très réputé et jeune. Le jeune site contient un super contenu qui n'a pas d'analogues dans la niche, plein de détails et de détails. Mais comme il y a plus de liens vers un site faisant autorité, sa page prend la première position et la page d'un jeune site prend la dixième. Et ici, la RRC entre en service - le moteur de recherche scanne les textes et se rend compte que le contenu du jeune site est plus significatif que celui d'un site faisant autorité. La conséquence est le déplacement du site jeune vers une position plus élevée.
Comment faire du contenu sous Neural Matching
Que Neural Matching fonctionne sur la base de la RRC ou non n'est pas si important. Il est important que l’intention de recherche soit «motivée» ici. Pas de longs "footcloths", pas la densité des mots-clés, pas la synonymisation.

Avant de créer du contenu, décidez:
- pour qui est-il (il vaut mieux faire des recherches, faire des portraits d'utilisateurs et écrire pour eux);
- pourquoi est-il nécessaire (quelle tâche ferme-t-il);
- qu'est-ce que les concurrents n'ont pas (quelle valeur cela apporte).
Pour accroître la pertinence des textes, en plus des requêtes de base, utilisez des entités étroitement liées. Si le texte est écrit par un expert, ces entités figureront très probablement dans le texte. C’est un autre problème lorsque le rédacteur reçoit des savoirs traditionnels - dans ce cas, il est nécessaire de déterminer les entités et de les indiquer dans la tâche.
Examinons les méthodes de collecte des entités en utilisant l'exemple d'une catégorie de la boutique en ligne «Générateurs d'essence».
1. Recherche de questions / réponses
Vous pouvez identifier les besoins des utilisateurs à l'aide de forums, de commentaires sur des articles de blog et de discussions sur les réseaux sociaux. Tout fonctionne. Mais il est plus facile d’aller à Answers@Mail.ru (ou à son homologue occidental - Quora ), de saisir une requête de recherche, de parcourir les questions et de mettre en évidence les entités associées aux clés principales.
À la demande des "générateurs d'essence" mail.ru émet 1624 questions. Nous parcourons la liste et sélectionnons les entités qui caractérisent les besoins du public cible.


Après avoir sélectionné les entités, nous pensons quel contenu leur convient. Par exemple, la consommation d'essence par heure et les méthodes d'utilisation du générateur (pour le soudage, pour une chaudière, pour l'éclairage, etc.) doivent être indiquées dans la description des produits spécifiques. Dans la description de la rubrique «Générateurs d'essence», vous pouvez décrire brièvement en quoi les générateurs d'essence diffèrent du gaz, de l'onduleur, etc. Un problème avec le fonctionnement des générateurs est décrit dans l'article du blog.
Le traitement des questions dans les services d'AQ est laborieux, mais il vous permet de mettre en évidence les besoins réels du public, que vous n'auriez peut-être pas devinés.
Vous pouvez essayer de simplifier le travail en utilisant la fonction Répondre à la fonction publique . Il recueille des questions, des comparaisons et diverses formulations qui se produisent sur le réseau avec l'occurrence d'une phrase donnée.

Le seul inconvénient est le service en anglais. La traduction de la phrase souhaitée résout partiellement le problème. Mais dans le segment commercial, il convient de rappeler les particularités des marchés (ce qui inquiète les Indiens peut être inutile aux Russes).
2. Analyse des phrases d'association
Sous les résultats de la recherche, le bloc «Ensemble avec ... souvent recherché» s'affiche - les phrases que le moteur de recherche associe lui-même à la phrase d'origine («générateurs d'essence») sont collectées ici.

L'analyse des phrases d'association vous permet d'identifier les entités liées: 5 kW, 3 kW, 10 kW, onduleur, 1 kW.
Reste à réfléchir à la manière de les inclure dans le contenu. Par exemple, dans la description de la colonne «générateurs à essence», il convient de dire à quelles fins des générateurs de puissance différente (1, 3, 5, 10 kW) et de type (onduleur, conventionnel, etc.) conviennent.
Si vous avez beaucoup de demandes initiales, collectez manuellement les associations pendant une longue période - utilisez l' analyseur .
3. Analyse des conseils de recherche
Les conseils sont une autre source pour faire correspondre des entités liées.

Nous reconstituons la liste des entités collectées auprès des associations: avec autorun, diesel, 380 volts, silencieux. Ce sont des mots qui caractérisent bien les problèmes des utilisateurs.
Il existe également un analyseur pour collecter les indices.
En principe, les méthodes discutées suffisent à se faire une idée des besoins du public. Mais si vous souhaitez approfondir la sémantique, voici deux méthodes facultatives.
4. Sélection de quasi-synonymes
Les quasi-synonymes (associations sémantiques) sont des mots qui ont un sens proche, mais qui ne sont pas interchangeables dans différents contextes. Par exemple, les mots «générateur» et «générateur automatique» sont synonymes dans le texte sur les pièces détachées automobiles, mais ils ne le seront pas dans le texte sur les types de générateurs.
Les quasi-synonymes sont déterminés en fonction de la fréquence de leur occurrence dans les textes. Pour résoudre ce problème, il existe un service RusVectōrēs (section «Mots similaires»). Saisissez le mot d'intérêt, marquez tous les modèles et parties de discours disponibles et lancez la recherche.

En conséquence, vous obtiendrez les 10 associés les plus significatifs pour chaque modèle de recherche. Les utiliser aveuglément dans la formation des savoirs traditionnels n'en vaut pas la peine - il y aura beaucoup de «déchets» ici (l'analyse des associations basées sur les données des moteurs de recherche est toujours préférable). Néanmoins, vous pouvez identifier des mots intéressants. Par exemple, on voit que les mots «générateur de gaz», «onduleur», «générateur de gaz», «contacteur», etc. sont associés au mot «générateur».
5. Analyser les textes des concurrents
Pour identifier les besoins du public, cette méthode n'est pas la meilleure. Premièrement, on ne sait pas quand le contenu a été créé sur les sites Web des concurrents (pendant ce temps, les préférences de recherche pourraient changer). Deuxièmement, rien ne garantit que les concurrents ont soigneusement analysé les problèmes du public et créé des textes à partir de ceux-ci.
D'un autre côté, si vous utilisez cette méthode comme auxiliaire, il y a une chance d'identifier les entités que vous pourriez manquer.
Ainsi, nous entrons la requête principale «générateurs d'essence» dans la recherche, copions les textes pertinents des sites vers le TOP-10 et sélectionnons la sémantique à l'aide d' Advego :

Nous complétons la liste des entités concernées: 4 temps, urgence, autonome, sans interruption, pour chalet d'été, pour nature, etc.
Assembler le tout et obtenir un savoir traditionnel optimisé pour la correspondance neuronale.
TK for lyrics: faites Neural Matching, pas LSI
Une fois les entités pertinentes collectées, vous devez écrire le texte. Mais il ne suffit pas de simplement spécifier les clés et une liste de synonymes et de mots associés dans le mandat, comme cela se fait généralement lors de la commande de textes LSI .

Exemple de savoirs traditionnels pour le texte LSI
Sur la base de ces savoirs traditionnels - simplement avec une liste de mots - des textes parfois assez étranges sont obtenus.
Une pratique courante chez les rédacteurs est d'écrire un texte, puis de ne saisir que les mots donnés. C'est plus facile, car vous n'avez pas besoin d'interrompre la sélection et l'insertion de mots dans le processus de composition du texte. Mais de telles insertions peuvent briser - et souvent briser - la logique et le style du texte.
Le texte sous Neural Matching concerne les utilisateurs et leurs besoins, pas les clés et les mots. Par conséquent, des fonctionnalités purement marketing apparaissent dans TK: descriptions des consommateurs et leurs motivations. Les clés et les mots plus s'affichent en arrière-plan - ils sont utilisés comme marqueurs et non comme éléments obligatoires. Leur place est occupée par les besoins d'information du public.

Exemple de savoirs traditionnels sous Neural Matching
Ces savoirs traditionnels permettent à l'auteur de comprendre clairement à qui s'adresse le texte, pourquoi et dans quelles circonstances il sera lu. Un tel savoir traditionnel n'épelle pas seulement les mots à utiliser, mais donne des instructions - sur quoi écrire pour utiliser ces mots.
Neural Matching, lors de l'optimisation des pages de recherche, déplace l'accent de la mécanique purement SEO vers le marketing. En fait, cette tendance est observée depuis plusieurs années. Neural Matching n'est qu'une étape de plus vers l'optimisation des moteurs de recherche à visage humain.
L'optimisation du contenu pour Neural Matching prend du temps et demande beaucoup de travail. Il est beaucoup plus facile de déposer des clés de l'AX dans TK, d'analyser plus de mots et de dire au rédacteur: "Écrivez pour les gens". Mais avec le développement de l'intelligence artificielle, cette approche sera de moins en moins efficace.