Gestion efficace et fiable des clusters à toute échelle avec Tupperware

Aujourd'hui, lors de la conférence Systems @Scale, nous avons présenté Tupperware, notre système de gestion de cluster qui orchestre les conteneurs sur des millions de serveurs, où presque tous nos services fonctionnent. Nous avons lancé Tupperware pour la première fois en 2011 et depuis, notre infrastructure est passée d' un centre de données à 15 centres de données géo-distribués . Pendant tout ce temps, Tupperware ne s'est pas arrêté et s'est développé avec nous. Nous vous indiquerons dans quelles situations Tupperware fournit une gestion de cluster de première classe, y compris une prise en charge pratique des services avec état, un panneau de contrôle unique pour tous les centres de données et la possibilité de répartir l'alimentation entre les services en temps réel. Et nous partagerons les leçons que nous avons apprises lors du développement de notre infrastructure.
Tupperware effectue diverses tâches. Les développeurs d'applications l'utilisent pour fournir et gérer des applications. Il emballe le code et les dépendances d'application dans une image et le livre aux serveurs sous forme de conteneurs. Les conteneurs assurent l'isolement entre les applications sur le même serveur afin que les développeurs soient occupés par la logique d'application et ne réfléchissent pas à la façon de trouver des serveurs ou de contrôler les mises à jour. Tupperware surveille également les performances du serveur et s’il détecte une panne, il transfère les conteneurs du serveur problématique.
Les ingénieurs de planification des capacités utilisent Tupperware pour répartir les capacités des serveurs en équipes en fonction du budget et des contraintes. Ils l'utilisent également pour améliorer l'utilisation du serveur. Les opérateurs de centres de données se tournent vers Tupperware pour répartir correctement les conteneurs entre les centres de données et arrêter ou déplacer les conteneurs pendant la maintenance. Pour cette raison, la maintenance des serveurs, des réseaux et des équipements nécessite une implication humaine minimale.
Architecture Tupperware
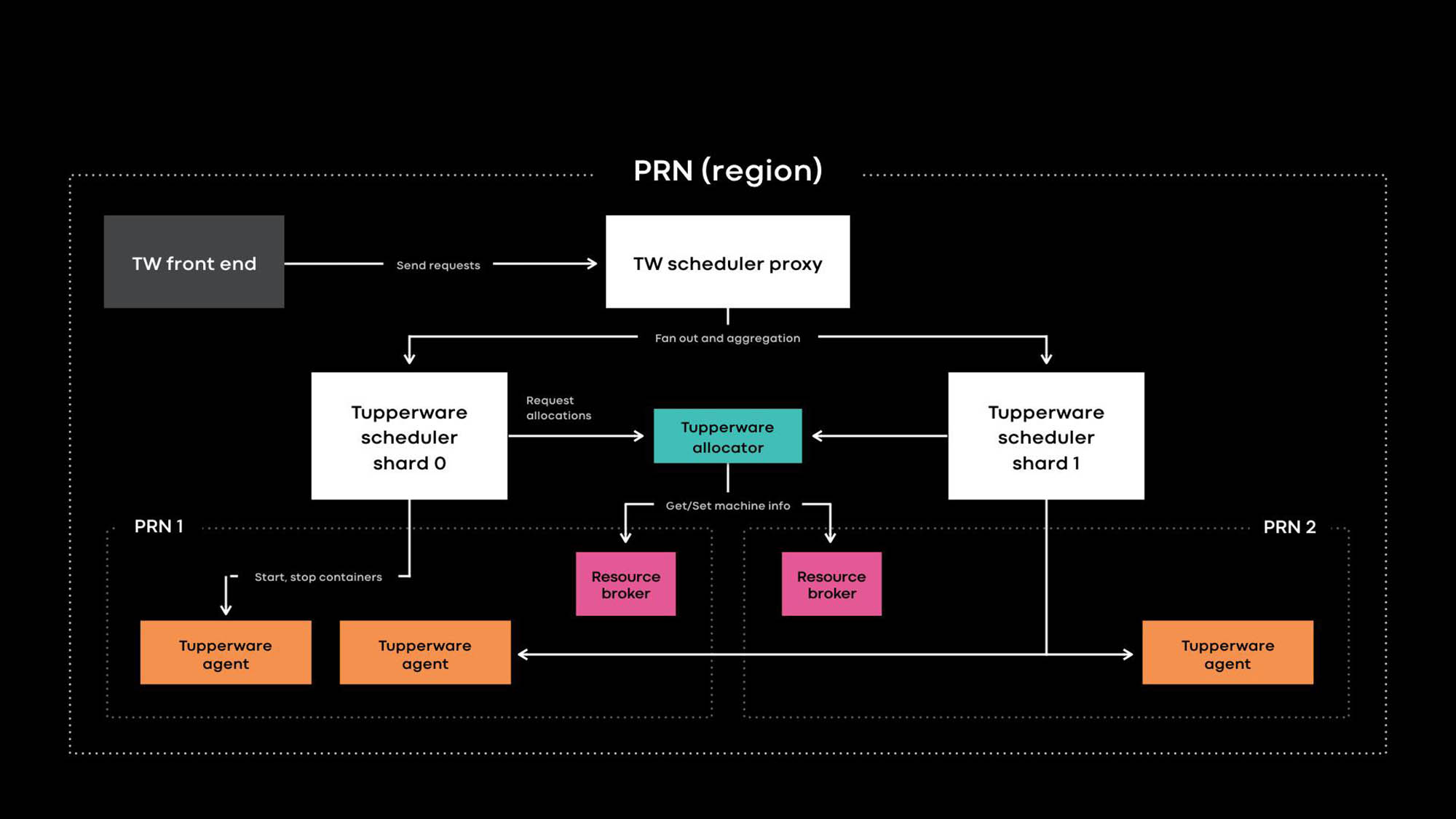
Architecture Tupperware PRN est l'une des régions de nos centres de données. La région se compose de plusieurs bâtiments de centres de données (PRN1 et PRN2) situés à proximité. Nous prévoyons de créer un panneau de contrôle qui gérera tous les serveurs dans une région.
Les développeurs d'applications fournissent des services sous forme de travaux Tupperware. Une tâche se compose de plusieurs conteneurs, et tous exécutent généralement le même code d'application.
Tupperware est responsable de l'approvisionnement des conteneurs et de la gestion du cycle de vie. Il se compose de plusieurs composants:
- Le Tupperware Frontend fournit une API pour l'interface utilisateur, la CLI et d'autres outils d'automatisation à travers lesquels vous pouvez interagir avec Tupperware. Ils cachent toute la structure interne aux propriétaires d'emplois Tupperware.
- Le planificateur Tupperware est le panneau de contrôle chargé de gérer le conteneur et le cycle de vie des travaux. Il est déployé aux niveaux régional et mondial, où un planificateur régional gère les serveurs dans une région et un planificateur global gère les serveurs de différentes régions. Le planificateur est divisé en fragments, et chaque fragment contrôle un ensemble de tâches.
- Le proxy du planificateur dans Tupperware masque le partage interne et fournit un panneau de contrôle unifié pratique pour les utilisateurs de Tupperware.
- Le distributeur Tupperware attribue des conteneurs aux serveurs. Le planificateur est responsable de l'arrêt, du démarrage, de la mise à jour et de l'échec des conteneurs. Actuellement, un seul distributeur peut gérer une région entière sans se diviser en fragments. (Notez la différence de terminologie. Par exemple, le planificateur dans Tupperware correspond au panneau de commande dans Kubernetes , et le distributeur Tupperware est appelé le planificateur dans Kubernetes.)
- Le courtier de ressources stocke la source de vérité pour les événements de serveur et de service. Nous exécutons un courtier de ressources pour chaque centre de données et il stocke toutes les informations du serveur dans ce centre de données. Un courtier en ressources et un système de gestion de capacité, ou système d'allocation de ressources, décident dynamiquement quelle alimentation du planificateur contrôle quel serveur. Le service de vérification de l'intégrité surveille les serveurs et stocke des données sur leur intégrité dans le courtier de ressources. Si le serveur a des problèmes ou a besoin de maintenance, le courtier en ressources demande au distributeur et au planificateur d'arrêter les conteneurs ou de les transférer vers d'autres serveurs.
- Tupperware Agent est un démon exécuté sur chaque serveur qui prépare et supprime les conteneurs. Les applications fonctionnent à l'intérieur du conteneur, ce qui leur donne plus d'isolement et de reproductibilité. Lors de la conférence Systems @Scale de l'année dernière, nous avons déjà décrit comment les conteneurs Tupperware individuels sont créés à l'aide d'images, btrfs, cgroupv2 et systemd.
Caractéristiques distinctives de Tupperware
Tupperware est très similaire à d'autres systèmes de gestion de cluster, tels que Kubernetes et Mesos , mais il existe quelques différences:
- Prise en charge native des services avec état.
- Un panneau de contrôle unique pour les serveurs de différents centres de données pour automatiser la livraison des conteneurs en fonction de l'intention, des clusters de déclassement et de la maintenance.
- Séparation claire du panneau de commande pour le zoom.
- Des calculs flexibles vous permettent de répartir la puissance entre les services en temps réel.
Nous avons conçu ces fonctionnalités intéressantes pour prendre en charge une variété d'applications sans état et avec état dans un immense parc de serveurs partagés mondial.
Prise en charge native des services avec état.
Tupperware gère de nombreux services critiques avec état qui stockent des données de produit persistantes pour Facebook, Instagram, Messenger et WhatsApp. Il peut s'agir de grandes paires clé-valeur (par exemple, ZippyDB ) et de magasins de données de surveillance (par exemple, ODS Gorilla et Scuba ). Il n'est pas facile de maintenir des services avec état, car le système doit garantir que les livraisons de conteneurs peuvent résister à des pannes à grande échelle, y compris une panne de courant ou une panne de courant. Bien que les méthodes conventionnelles, telles que la distribution de conteneurs sur plusieurs domaines de défaillance, conviennent bien aux services sans état, les services avec état nécessitent un support supplémentaire.
Par exemple, si à la suite d'une panne de serveur, une réplique de la base de données devient indisponible, est-il nécessaire d'autoriser la maintenance automatique qui mettra à jour les noyaux sur 50 serveurs à partir d'un pool de 10 millièmes? Cela dépend de la situation. Si sur l'un de ces 50 serveurs il existe une autre réplique de la même base de données, il vaut mieux attendre et ne pas perdre 2 répliques à la fois. Afin de prendre des décisions dynamiques concernant la maintenance et l'intégrité du système, vous avez besoin d'informations sur la réplication des données internes et la logique de localisation de chaque service avec état.
L'interface TaskControl permet aux services avec état d'influencer les décisions qui affectent la disponibilité des données. À l'aide de cette interface, le planificateur informe les applications externes des opérations de conteneur (redémarrage, mise à jour, migration, maintenance). Le service Stateful implémente un contrôleur qui indique à Tupperware quand chaque opération peut être effectuée en toute sécurité, et ces opérations peuvent être échangées ou temporairement retardées. Dans l'exemple ci-dessus, le contrôleur de base de données peut demander à Tupperware de mettre à niveau 49 des 50 serveurs, mais ne pas toucher un serveur spécifique (X) jusqu'à présent. Par conséquent, si la période de mise à jour du noyau passe et que la base de données ne peut toujours pas restaurer la réplique problématique, Tupperware mettra toujours à niveau le serveur X.

De nombreux services avec état dans Tupperware n'utilisent pas TaskControl directement, mais via ShardManager, une plate-forme commune pour créer des services avec état sur Facebook. Avec Tupperware, les développeurs peuvent indiquer leur intention sur la façon dont les conteneurs doivent être distribués dans les centres de données. Avec ShardManager, les développeurs indiquent leur intention de répartir les fragments de données entre les conteneurs. ShardManager est conscient de l'hébergement de données et de la réplication de ses applications et interagit avec Tupperware via l'interface TaskControl pour planifier les opérations de conteneur sans implication directe de l'application. Cette intégration simplifie considérablement la gestion des services avec état, mais TaskControl est capable de plus. Par exemple, notre niveau Web étendu est sans état et utilise TaskControl pour ajuster dynamiquement la vitesse des mises à jour dans les conteneurs. Par conséquent, le niveau Web peut effectuer rapidement plusieurs versions logicielles par jour sans compromettre la disponibilité.
Gestion des serveurs dans les centres de données
Lorsque Tupperware est apparu pour la première fois en 2011, un planificateur distinct contrôlait chaque cluster de serveurs. Ensuite, le cluster Facebook était un groupe de racks de serveurs connectés à un commutateur réseau, et le centre de données contenait plusieurs clusters. Le planificateur pouvait gérer les serveurs dans un seul cluster, c'est-à-dire que la tâche ne pouvait pas s'étendre à plusieurs clusters. Notre infrastructure grandissait, nous radions de plus en plus de clusters. Étant donné que Tupperware n'a pas pu transférer la tâche du cluster déclassé vers d'autres clusters sans modifications, il a fallu beaucoup d'efforts et une coordination minutieuse entre les développeurs d'applications et les opérateurs de centres de données. Ce processus a entraîné un gaspillage de ressources lorsque les serveurs ont été inactifs pendant des mois en raison de la procédure de mise hors service.
Nous avons créé un courtier en ressources pour résoudre le problème des clusters de déclassement et coordonner d'autres types de tâches de maintenance. Le courtier en ressources surveille toutes les informations physiques associées au serveur et décide dynamiquement quel planificateur gère chaque serveur. La liaison dynamique des serveurs aux planificateurs permet au planificateur de gérer les serveurs dans différents centres de données. Étant donné que le travail Tupperware n'est plus limité à un seul cluster, les utilisateurs Tupperware peuvent spécifier la façon dont les conteneurs doivent être répartis sur les domaines de défaillance. Par exemple, un développeur peut déclarer son intention (par exemple: «exécuter ma tâche sur 2 domaines de défaillance dans la région PRN») sans spécifier de zones de disponibilité spécifiques. Tupperware lui-même trouvera les bons serveurs pour concrétiser cette intention même dans le cas de la mise hors service d'un cluster ou d'un service.
Mise à l'échelle pour prendre en charge l'ensemble du système mondial
Historiquement, notre infrastructure a été divisée en centaines de pools de serveurs dédiés pour les équipes individuelles. En raison de la fragmentation et du manque de normes, nous avions des coûts de transaction élevés et les serveurs inactifs étaient à nouveau plus difficiles à utiliser. Lors de la conférence Systems @Scale de l’ année dernière, nous avons introduit Infrastructure as a Service (IaaS) , qui devrait intégrer notre infrastructure dans une grande flotte de serveurs unifiés. Mais une flotte de serveurs unique a ses propres difficultés. Il doit répondre à certaines exigences:
- Évolutivité. Notre infrastructure s'est développée avec l'ajout de centres de données dans chaque région. Les serveurs sont devenus plus petits et plus économes en énergie, donc dans chaque région il y en a beaucoup plus. Par conséquent, un seul planificateur pour une région ne peut pas gérer le nombre de conteneurs pouvant être exécutés sur des centaines de milliers de serveurs dans chaque région.
- Fiabilité Même si l'échelle de l'ordonnanceur peut être ainsi augmentée, en raison de la grande portée de l'ordonnanceur, le risque d'erreurs sera plus élevé et la région entière du conteneur peut devenir ingérable.
- Tolérance aux pannes. En cas de défaillance majeure de l'infrastructure (par exemple, en raison d'une panne de réseau ou d'une panne de courant, les serveurs sur lesquels le planificateur s'exécute échoueront), seule une partie des serveurs de la région aura des conséquences négatives.
- Facilité d'utilisation. Il peut sembler que vous devez exécuter plusieurs planificateurs indépendants dans une même région. Mais en termes de commodité, un point d'entrée unique dans un pool commun dans la région simplifie la gestion des capacités et des tâches.
Nous avons divisé le planificateur en fragments pour résoudre les problèmes de prise en charge d'un grand pool partagé. Chaque fragment de planificateur gère son ensemble de tâches dans la région, ce qui réduit le risque associé au planificateur. À mesure que le pool total augmente, nous pouvons ajouter plus de fragments de planificateur. Pour les utilisateurs Tupperware, les fragments et les planificateurs de proxy ressemblent à un panneau de contrôle. Ils n'ont pas à travailler avec un tas de fragments qui orchestrent les tâches. Les fragments du planificateur sont fondamentalement différents des planificateurs de cluster que nous avons utilisés auparavant, lorsque le panneau de contrôle était divisé sans séparation statique du pool de serveurs commun selon la topologie du réseau.
Amélioration de l'utilisation avec l'informatique élastique
Plus notre infrastructure est grande, plus il est important d'utiliser efficacement nos serveurs pour optimiser les coûts d'infrastructure et réduire la charge. Il existe deux façons d'améliorer l'utilisation du serveur:
- Informatique flexible - réduisez l'échelle des services en ligne pendant les heures calmes et utilisez les serveurs libérés pour les charges hors ligne, par exemple, pour l'apprentissage automatique et les tâches MapReduce.
- Charge excessive - hébergez les services en ligne et les charges de travail par lots sur les mêmes serveurs afin que les chargements par lots soient exécutés avec une faible priorité.
Le goulot d'étranglement dans nos centres de données est la consommation d'énergie . Par conséquent, nous préférons les petits serveurs éconergétiques qui, ensemble, fournissent plus de puissance de traitement. Malheureusement, sur les petits serveurs avec une petite quantité de ressources processeur et de mémoire, un chargement excessif est moins efficace. Bien sûr, nous pouvons placer plusieurs conteneurs de petits services sur un petit serveur économe en énergie qui consomment peu de ressources processeur et de mémoire, mais les grands services auront de faibles performances dans cette situation. Par conséquent, nous conseillons aux développeurs de nos grands services de les optimiser afin qu'ils utilisent l'ensemble du serveur.
Fondamentalement, nous améliorons l'utilisation avec l'informatique élastique. L'intensité d'utilisation de bon nombre de nos grands services, par exemple, les flux d'actualités, les fonctionnalités de message et le niveau Web frontal, dépend de l'heure de la journée. Nous réduisons intentionnellement l'échelle des services en ligne pendant les heures calmes et utilisons les serveurs libérés pour les charges hors ligne, par exemple, pour les tâches d'apprentissage automatique et de MapReduce.
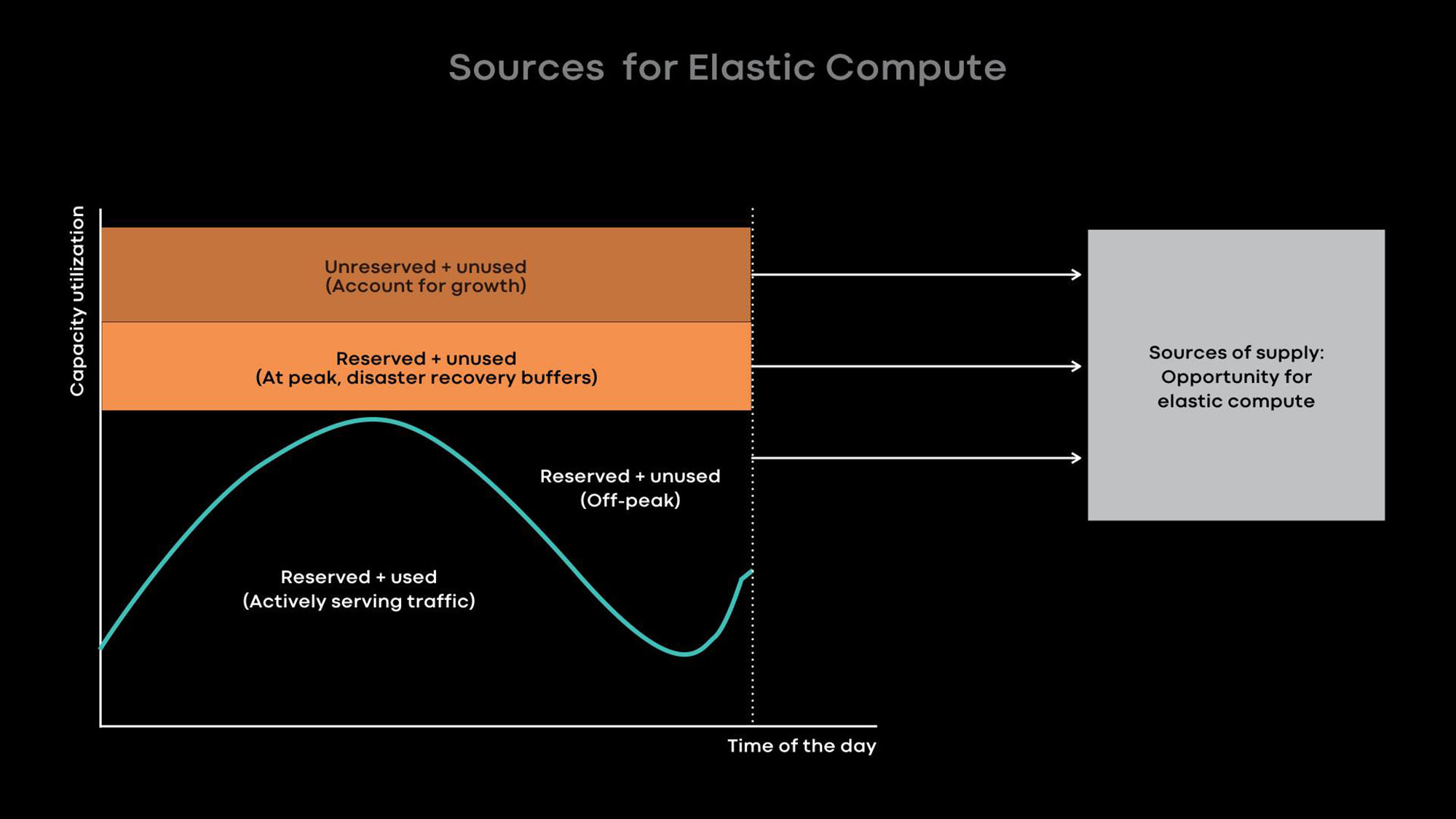
Par expérience, nous savons qu'il est préférable de fournir des serveurs entiers en tant qu'unités de puissance élastique, car les grands services sont à la fois les principaux donateurs et les principaux consommateurs d'énergie élastique, et ils sont optimisés pour l'utilisation de serveurs entiers. Lorsque le serveur est libéré du service en ligne pendant les heures calmes, le courtier de ressources donne le serveur au planificateur pour une utilisation temporaire afin qu'il exécute des charges hors ligne sur celui-ci. Si un pic de charge se produit dans un service en ligne, le courtier en ressources rappelle rapidement le serveur prêté et, avec le planificateur, le renvoie au service en ligne.
Leçons apprises et plans futurs
Au cours des 8 dernières années, nous avons développé Tupperware pour suivre le développement rapide de Facebook. Nous parlons de ce que nous avons appris et espérons que cela aidera les autres à gérer des infrastructures à croissance rapide:
- Configurez des communications flexibles entre le panneau de contrôle et les serveurs qu'il gère. Cette flexibilité permet au panneau de contrôle de gérer les serveurs dans différents centres de données, permet d'automatiser le déclassement et la maintenance des clusters et fournit une distribution dynamique de l'énergie à l'aide d'une informatique flexible.
- Avec un seul panneau de contrôle dans la région, il devient plus pratique de travailler avec des tâches et plus facile à gérer une grande flotte commune de serveurs. Veuillez noter que le panneau de commande prend en charge un seul point d'entrée, même si sa structure interne est divisée pour des raisons d'échelle ou de tolérance aux pannes.
- À l'aide du modèle de plug-in, le panneau de commande peut notifier les applications externes des opérations de conteneur à venir. De plus, les services avec état peuvent utiliser l'interface du plugin pour configurer la gestion des conteneurs. En utilisant ce modèle de plug-in, le panneau de commande offre une simplicité et sert efficacement de nombreux services avec état différents.
- Nous pensons que l'informatique élastique, dans laquelle nous prenons des serveurs entiers pour des travaux par lots, l'apprentissage automatique et d'autres services non urgents des services des donateurs, est le meilleur moyen d'augmenter l'efficacité de l'utilisation de petits serveurs éconergétiques.
Nous commençons tout juste à mettre en œuvre un parc de serveurs commun mondial unique . Maintenant, environ 20% de nos serveurs sont dans le pool commun. Pour atteindre 100%, vous devez résoudre de nombreux problèmes, notamment la prise en charge d'un pool commun pour les systèmes de stockage, l'automatisation de la maintenance, la gestion des exigences de différents clients, l'amélioration de l'utilisation du serveur et l'amélioration de la prise en charge des charges de travail d'apprentissage automatique. Nous avons hâte de nous attaquer à ces tâches et de partager nos succès.