Mon nom est Marko et j'ai donné une conférence à
Gophercon Russie cette année sur un type d'index très intéressant appelé "index bitmap". Je voulais le partager avec la communauté, non seulement au format vidéo, mais aussi en tant qu'article. C'est une version anglaise et vous pouvez lire le russe
ici . Profitez-en!

Des documents supplémentaires, des diapositives et tout le code source peuvent être trouvés ici:
http://bit.ly/bitmapindexeshttps://github.com/mkevac/gopherconrussia2019Enregistrement vidéo original:
Commençons!
Présentation

Aujourd'hui, je vais parler de
- Quels sont les index.
- Qu'est-ce qu'un index bitmap;
- Où il est utilisé. Pourquoi il n'est pas utilisé là où il n'est pas utilisé.
- Nous allons voir une implémentation simple dans Go et ensuite essayer le compilateur.
- Ensuite, nous allons examiner une implémentation un peu moins simple, mais sensiblement plus rapide dans l'assemblage Go.
- Et après cela, je vais aborder les "problèmes" des index bitmap un par un.
- Et enfin, nous verrons quelles sont les solutions existantes.
Quels sont donc les index?
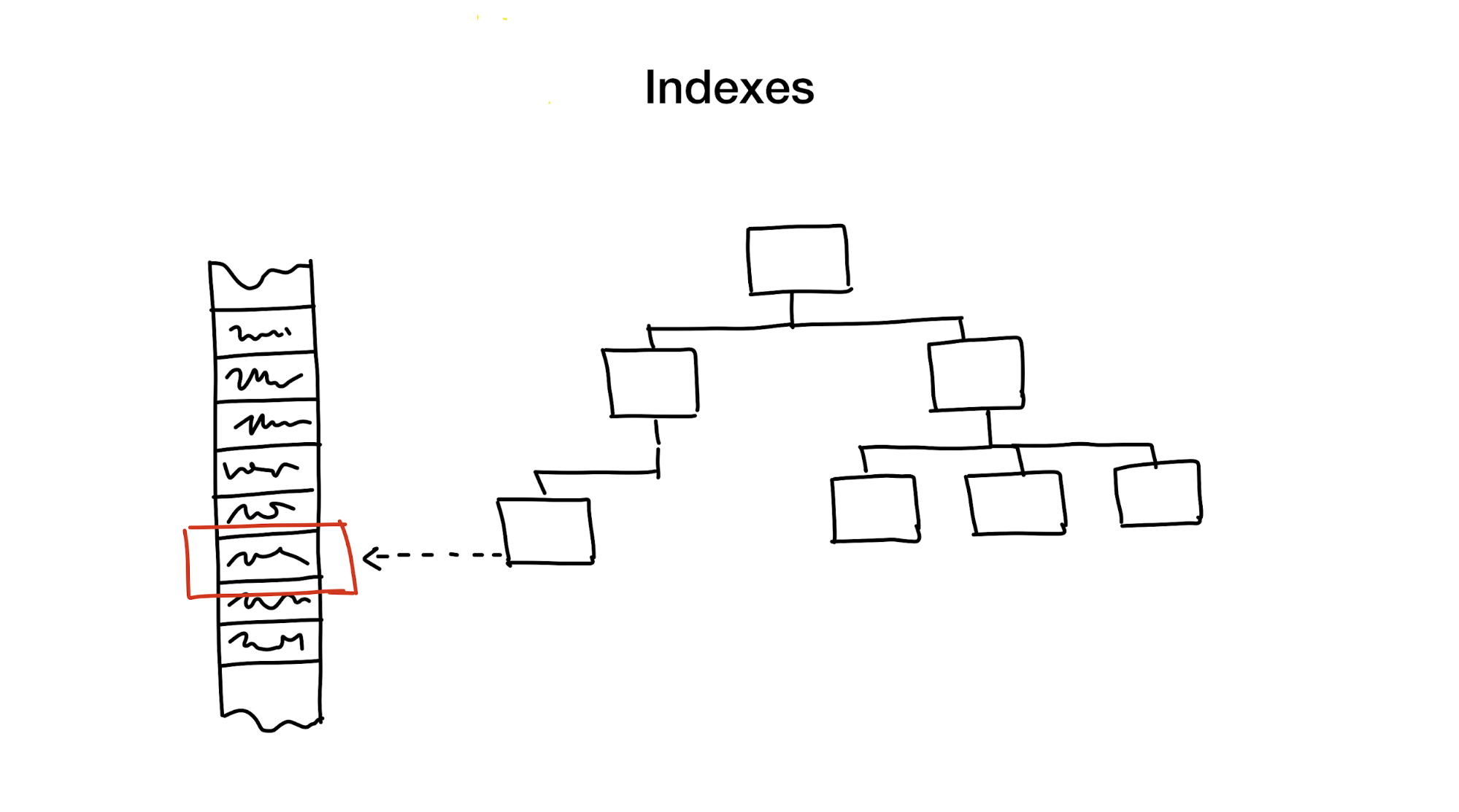
Un index est une structure de données distincte qui est mise à jour en plus des données principales, utilisée pour accélérer les demandes de recherche. Sans index, la recherche impliquerait de parcourir toutes les données (dans un processus également appelé «analyse complète») et ce processus a une complexité algorithmique linéaire. Mais les bases de données contiennent généralement d'énormes quantités de données, de sorte que la complexité linéaire est trop lente. Idéalement, nous souhaiterions atteindre des vitesses de complexité logarithmique voire constante.
Il s'agit d'un sujet énorme et complexe impliquant de nombreux compromis, mais en revenant sur des décennies de mise en œuvre de bases de données et de recherche, je dirais qu'il n'y a que quelques approches couramment utilisées:

Tout d'abord, réduit la zone de recherche en coupant la zone entière en parties plus petites, hiérarchiquement.
Généralement, cela est réalisé en utilisant des arbres. C'est comme avoir des boîtes de boîtes dans votre garde-robe. Chaque boîte contient des matériaux qui sont ensuite triés dans des boîtes plus petites, chacune pour une utilisation spécifique. Si nous avons besoin de matériel, nous ferions mieux de chercher la case intitulée "matériel" au lieu d'une case intitulée "cookies".
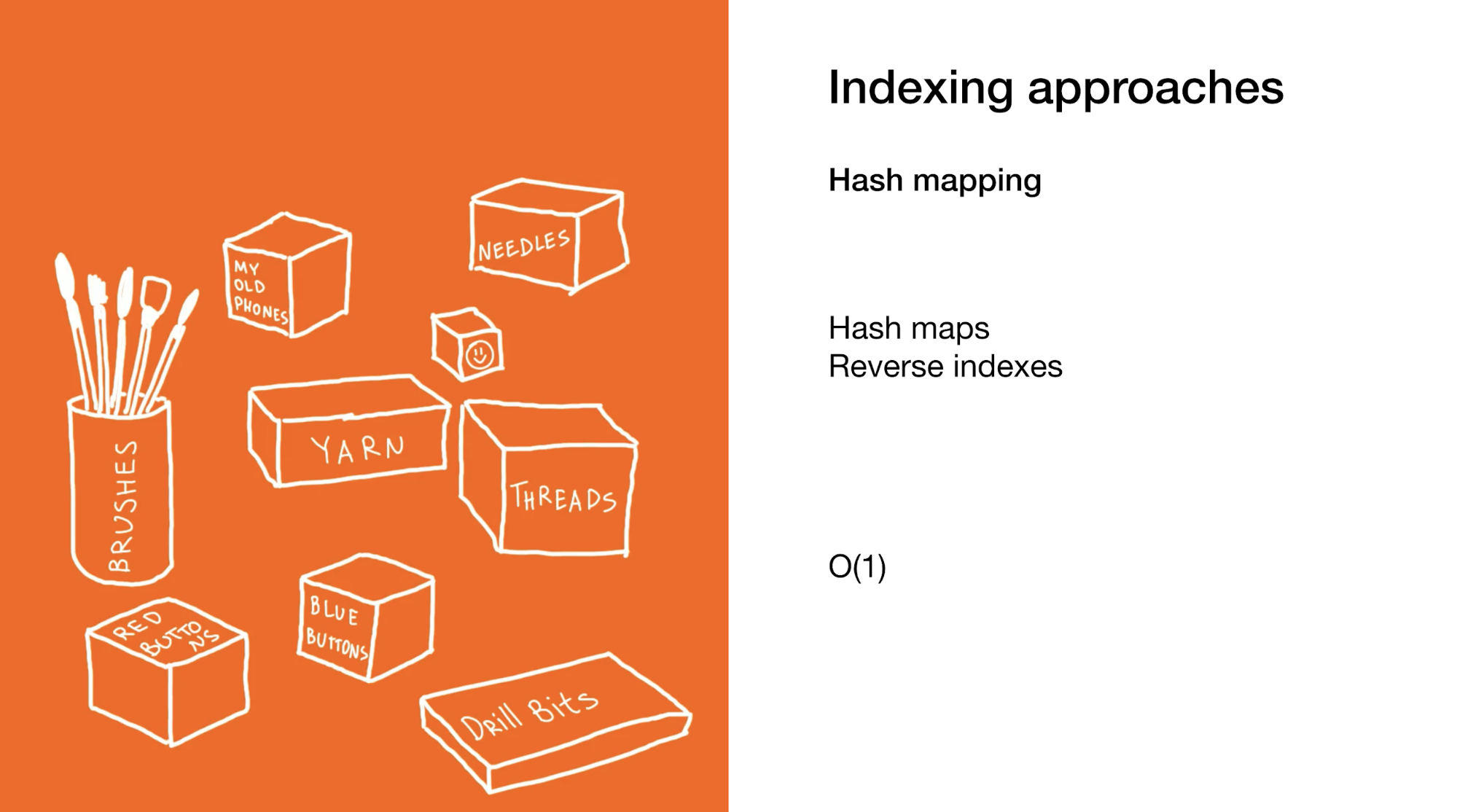
La seconde consiste à localiser instantanément un élément ou un groupe d'éléments spécifique comme dans les cartes de hachage ou les index inversés. L'utilisation de cartes de hachage est similaire à l'exemple précédent, mais vous utilisez de nombreuses petites boîtes qui ne contiennent pas de boîtes elles-mêmes, mais plutôt des éléments finaux.

La troisième approche supprime la nécessité de rechercher du tout comme dans les filtres à fleurs ou les filtres à coucou. Les filtres Bloom peuvent vous donner une réponse tout de suite et vous faire gagner du temps autrement consacré à la recherche.
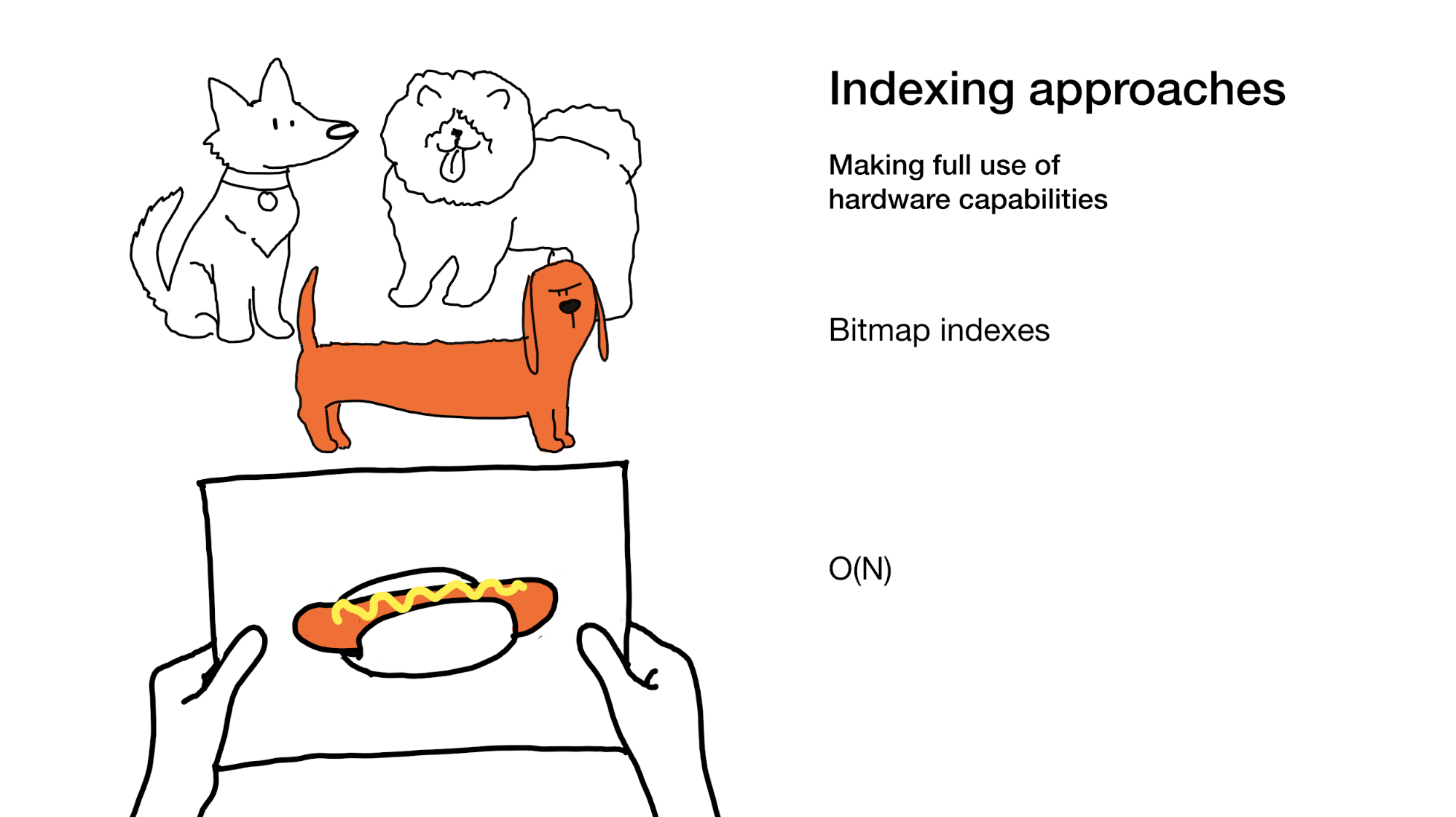
Le dernier accélère la recherche en faisant un meilleur usage de nos capacités matérielles comme dans les index bitmap. Les indices bitmap impliquent parfois de parcourir l'intégralité de l'index, oui, mais cela se fait de manière très efficace.
Comme je l'ai déjà dit, la recherche a une tonne de compromis, nous utilisons donc souvent plusieurs approches pour améliorer encore plus la vitesse ou pour couvrir tous nos types de recherche potentiels.
Aujourd'hui, je voudrais parler d'une de ces approches qui est moins connue: les index bitmap.
Mais qui suis-je pour parler de ce sujet?
Je suis chef d'équipe chez Badoo (vous connaissez peut-être une autre de nos marques: Bumble). Nous avons plus de 400 millions d'utilisateurs dans le monde et beaucoup de fonctionnalités que nous avons impliquent de rechercher la meilleure correspondance pour vous! Pour ces tâches, nous utilisons des services sur mesure qui utilisent des index bitmap, entre autres.
Maintenant, qu'est-ce qu'un index bitmap?
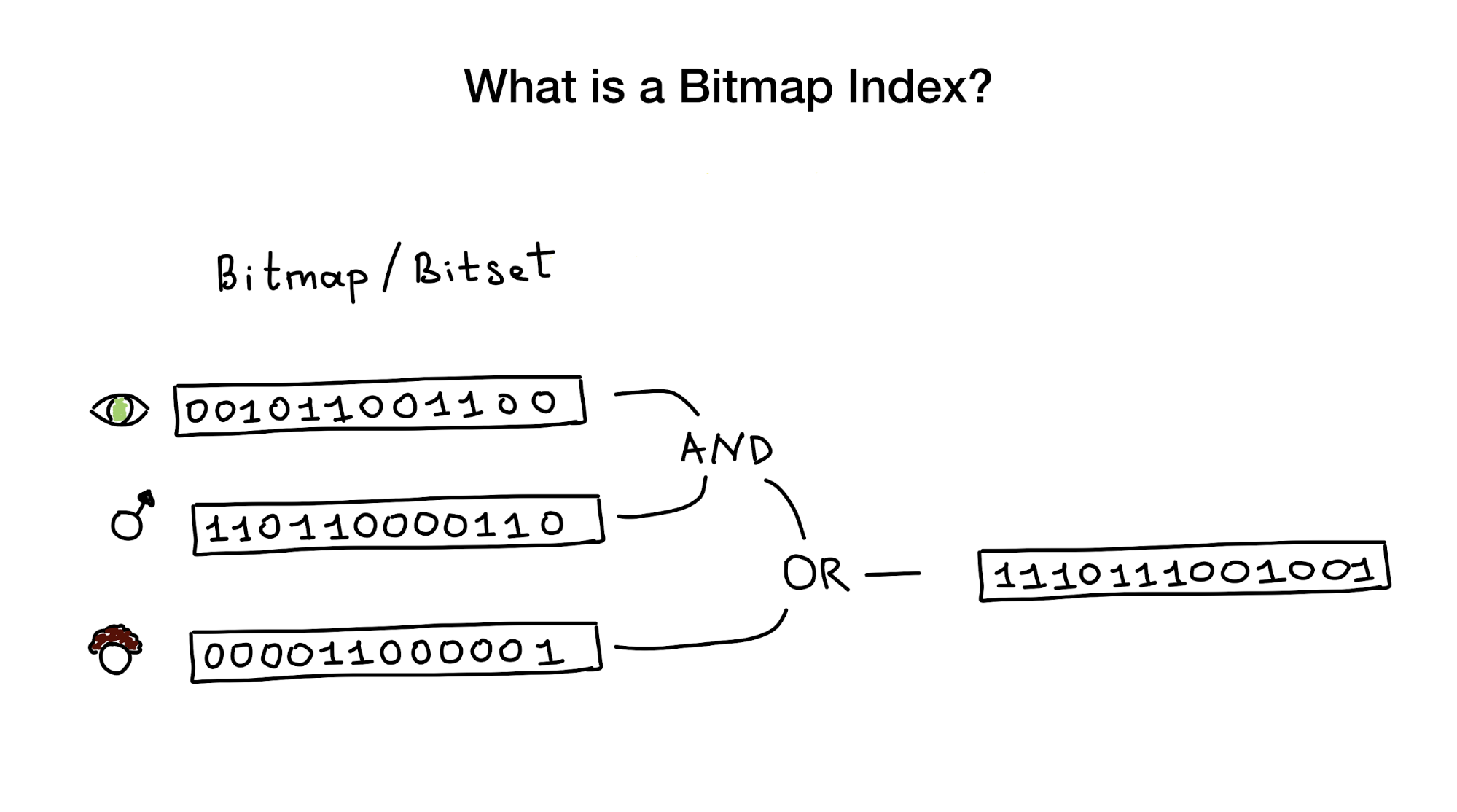
Comme leur nom l'indique, les index Bitmap utilisent des bitmaps aka bitsets pour implémenter l'index de recherche. D'un point de vue à vol d'oiseau, cet index se compose d'une ou plusieurs images bitmap qui représentent des entités (par exemple, des personnes) et leurs paramètres (par exemple, l'âge ou la couleur des yeux) et un algorithme pour répondre aux requêtes de recherche en utilisant des opérations au niveau du bit comme ET, OU, NON, etc. .

Les index bitmap sont considérés comme très utiles et très performants si vous avez une recherche qui doit combiner des requêtes par plusieurs colonnes avec une faible cardinalité (peut-être la couleur des yeux ou l'état matrimonial) par rapport à quelque chose comme la distance au centre-ville qui a une cardinalité infinie.
Mais plus tard dans l'article, je montrerai que les index bitmap fonctionnent même avec des colonnes à cardinalité élevée.
Regardons l'exemple le plus simple d'un index bitmap ...

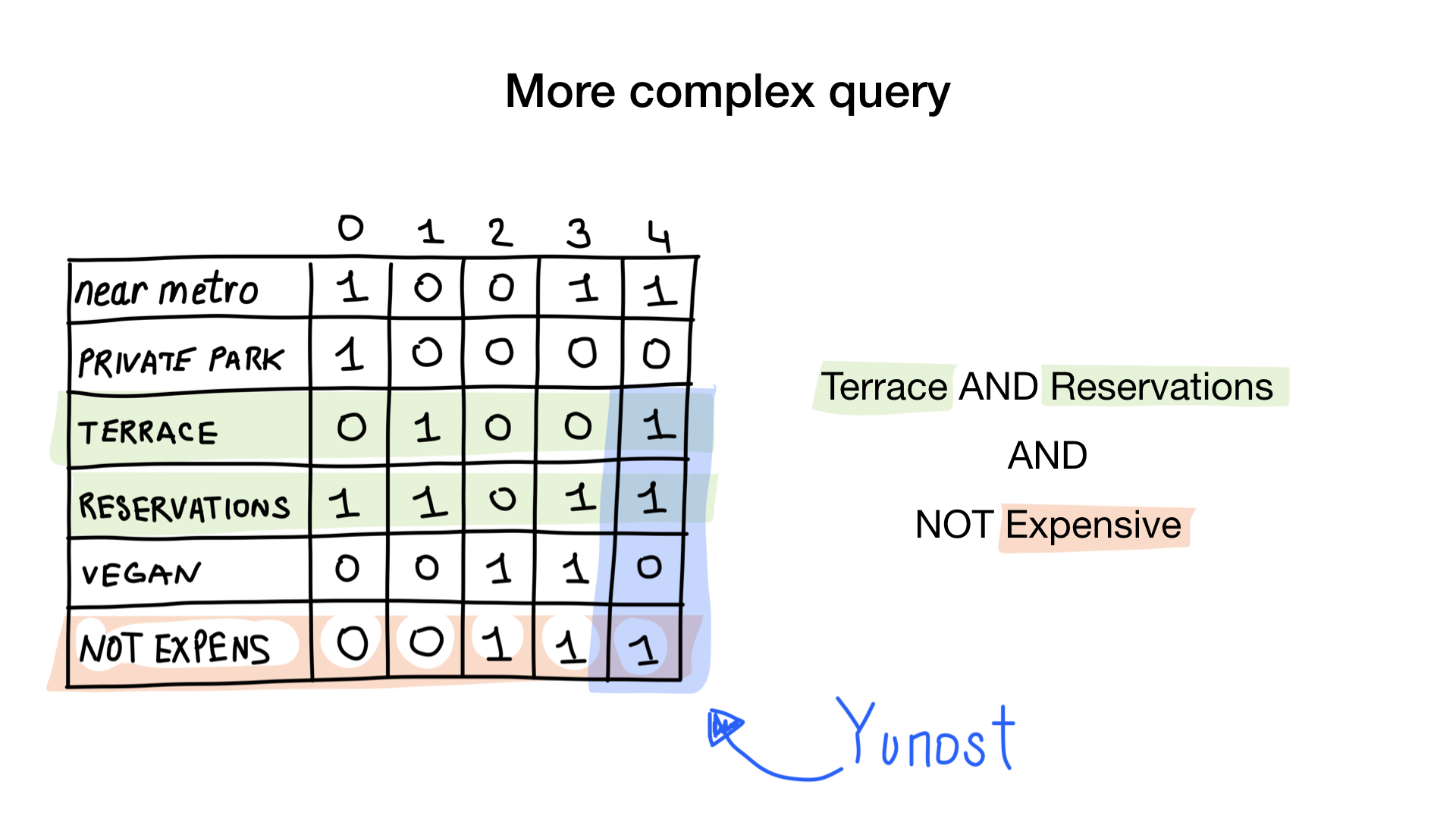
Imaginez que nous avons une liste de restaurants de Moscou avec des caractéristiques binaires:
- près du métro
- dispose d'un parking privé
- a une terrasse
- accepte les réservations
- végétalien
- cher
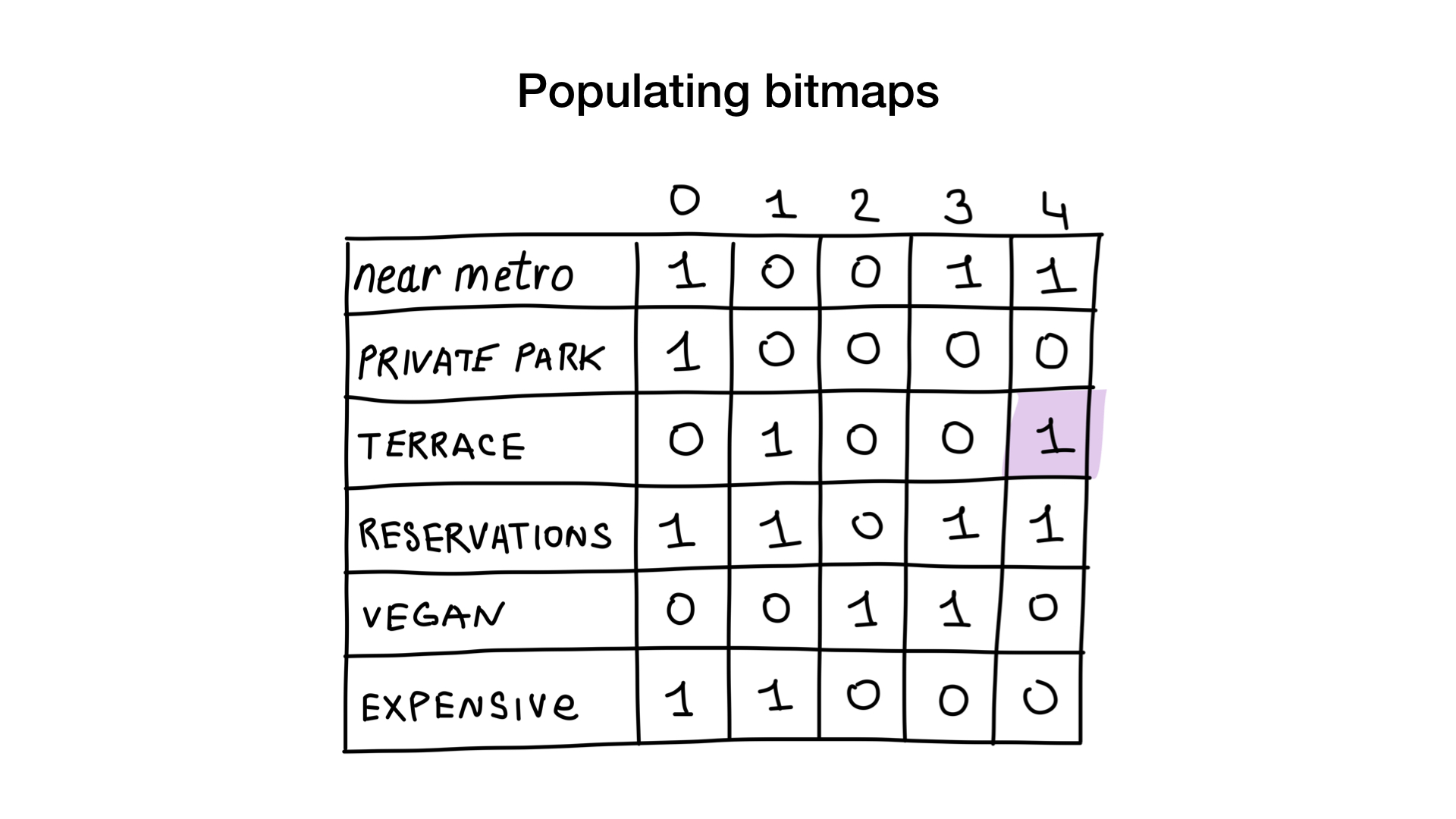
Donnons à chaque restaurant un index à partir de 0 et allouons 6 bitmaps (un pour chaque caractéristique). Ensuite, nous remplirions ces bitmaps selon que le restaurant a ou non une caractéristique spécifique. Si le restaurant numéro 4 a la terrasse, alors le bit numéro 4 dans le bitmap "terrasse" sera mis à 1 (0 sinon).

Nous avons maintenant l'index bitmap le plus simple possible que nous pouvons utiliser pour répondre à des questions comme
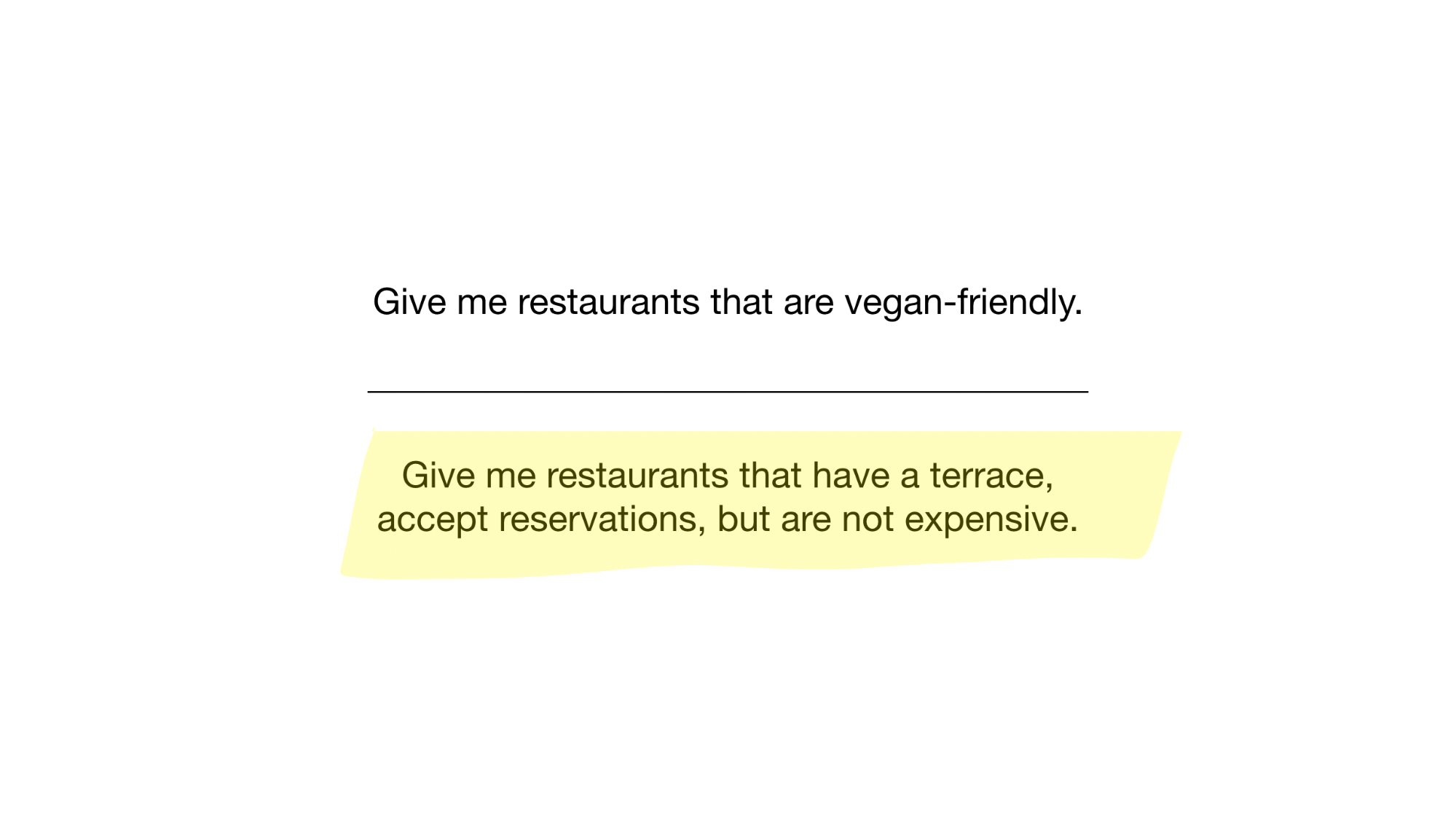
- Donnez-moi des restaurants végétaliens
- Donnez-moi des restaurants avec terrasse qui acceptent les réservations, mais ne sont pas chers


Comment? Voyons voir. La première question est simple. Nous prenons simplement le bitmap "vegan-friendly" et retournons tous les index qui ont un bit défini.

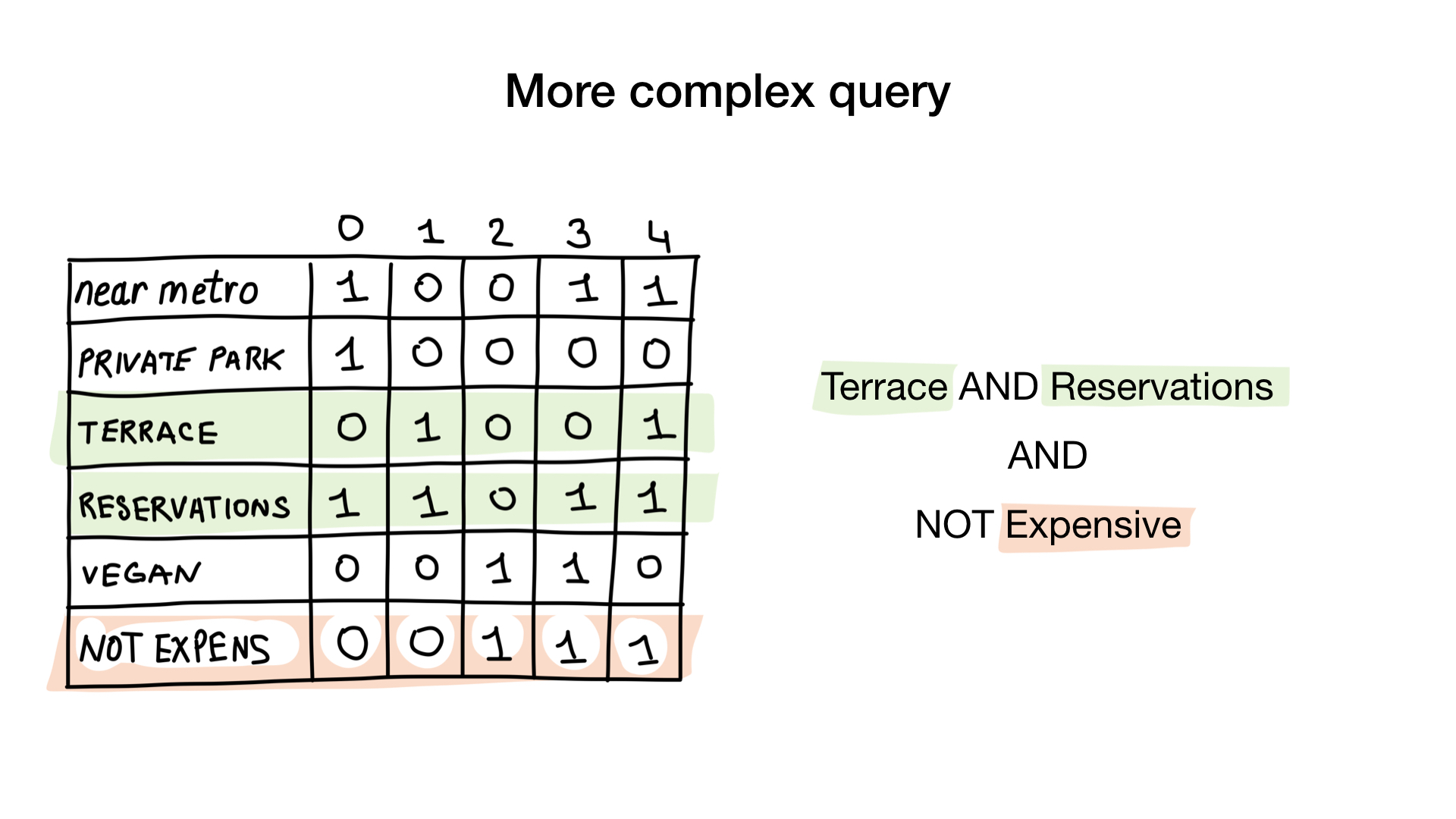
La deuxième question est légèrement plus compliquée. Nous utiliserons l'opération au niveau du bit NON sur le bitmap «cher» pour obtenir des restaurants non chers, ET avec le bitmap «accepter la réservation» et ET avec «a le bitmap en terrasse». Le bitmap résultant sera composé de restaurants qui ont toutes ces caractéristiques que nous voulions. Nous voyons ici que seul Yunost possède toutes ces caractéristiques.
Cela peut sembler un peu théorique, mais ne vous inquiétez pas, nous verrons le code sous peu.
Où les index bitmap sont utilisés

Si vous google "bitmap index", 90% des résultats pointeront vers Oracle DB qui a des index bitmap de base. Mais, sûrement, d'autres SGBD utilisent également des index bitmap, n'est-ce pas? Non, en fait, ils ne le font pas. Passons en revue les suspects habituels un par un.


- Mais il y a un nouveau garçon sur le bloc: Pilosa. Pilosa est un nouveau SGBD écrit en Go (notez qu'il n'y a pas de R, ce n'est pas relationnel) qui base tout sur des index bitmap. Et nous parlerons de Pilosa plus tard.
Implémentation en cours
Mais pourquoi? Pourquoi les index bitmap sont-ils si rarement utilisés? Avant de répondre à cette question, je voudrais vous guider à travers l'implémentation de base de l'index bitmap dans Go.

Le bitmap est représenté comme un morceau de mémoire. Dans Go, utilisons une tranche d'octets pour cela.
Nous avons un bitmap par caractéristique de restaurant. Chaque bit dans un bitmap représente si un restaurant particulier a cette caractéristique ou non.

Nous aurions besoin de deux fonctions d'assistance. L'un est utilisé pour remplir le bitmap de manière aléatoire, mais avec une probabilité spécifiée d'avoir la caractéristique. Par exemple, je pense qu'il y a très peu de restaurants qui n'acceptent pas les réservations et environ 20% sont végétaliens.
Une autre fonction nous donnera la liste des restaurants à partir d'un bitmap.


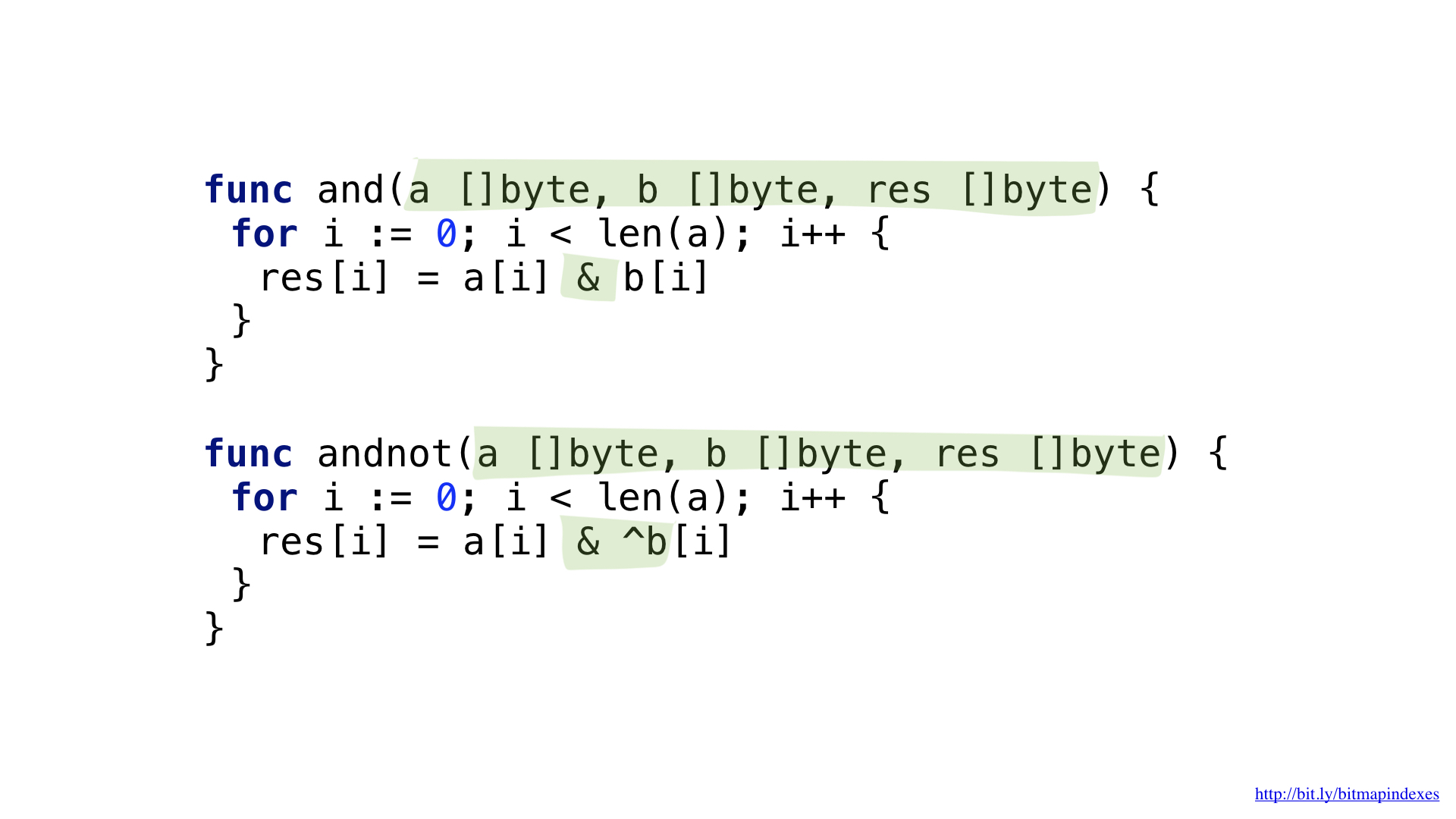
Afin de répondre à la question «donnez-moi des restaurants avec terrasse qui acceptent les réservations mais ne sont pas chers», nous aurions besoin de deux opérations: NON et ET.
Nous pouvons légèrement simplifier le code en introduisant une opération complexe ET NON.
Nous avons les fonctions pour chacun d'eux. Les deux fonctions passent par nos tranches en prenant les éléments correspondants de chacune, en effectuant l'opération et en écrivant le résultat dans la tranche résultante.
Et maintenant, nous pouvons utiliser nos bitmaps et nos fonctions pour obtenir la réponse.

Les performances ne sont pas si bonnes ici même si nos fonctions sont vraiment simples et nous avons beaucoup économisé sur les allocations en ne retournant pas de nouvelle tranche à chaque appel de fonction.
Après un profilage avec pprof, j'ai remarqué que le compilateur go manquait l'une des optimisations très basiques: la fonction inline.
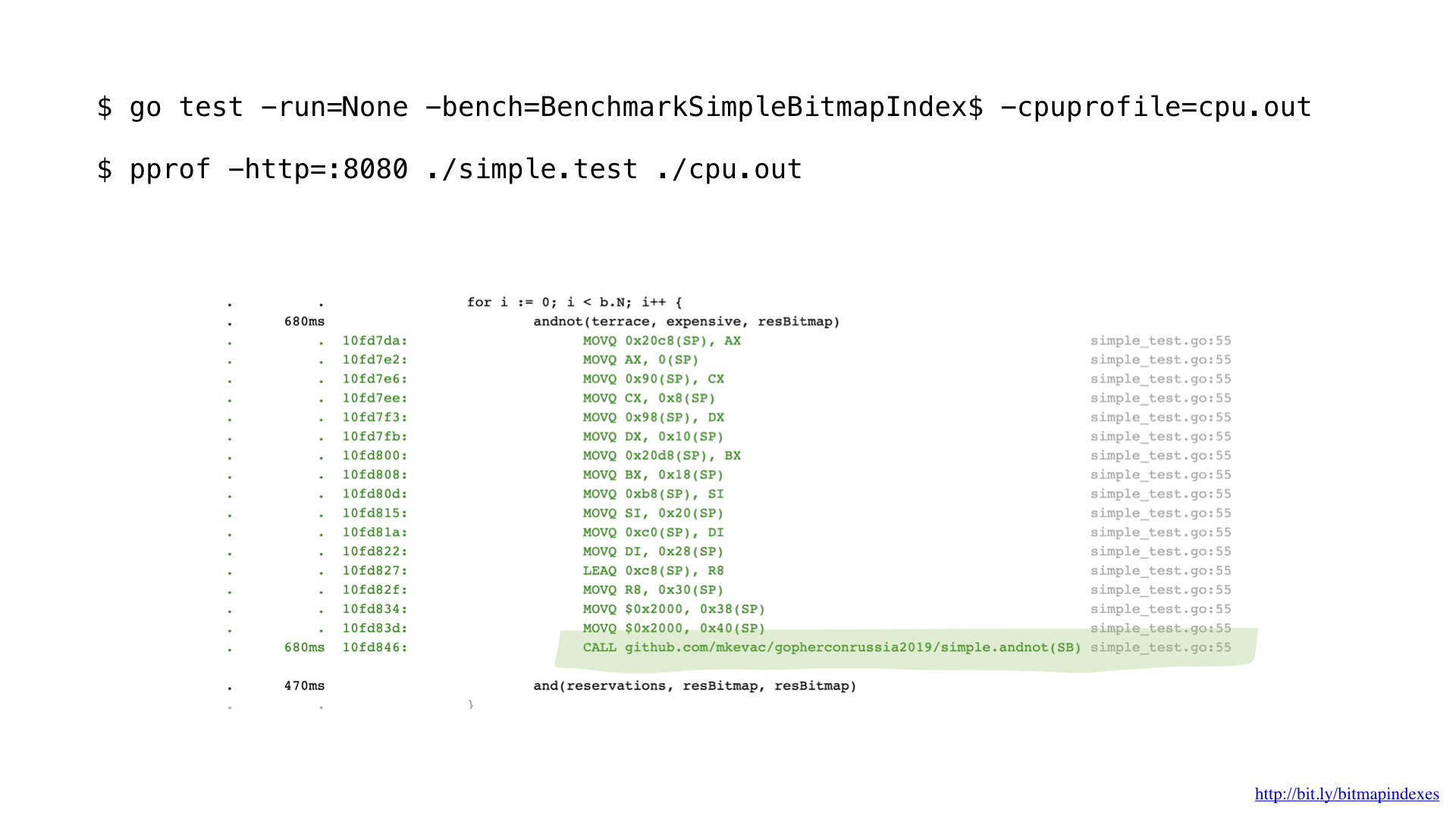
Vous voyez, le compilateur Go a pathologiquement peur des boucles à travers les tranches et refuse de mettre en ligne toute fonction qui en a.
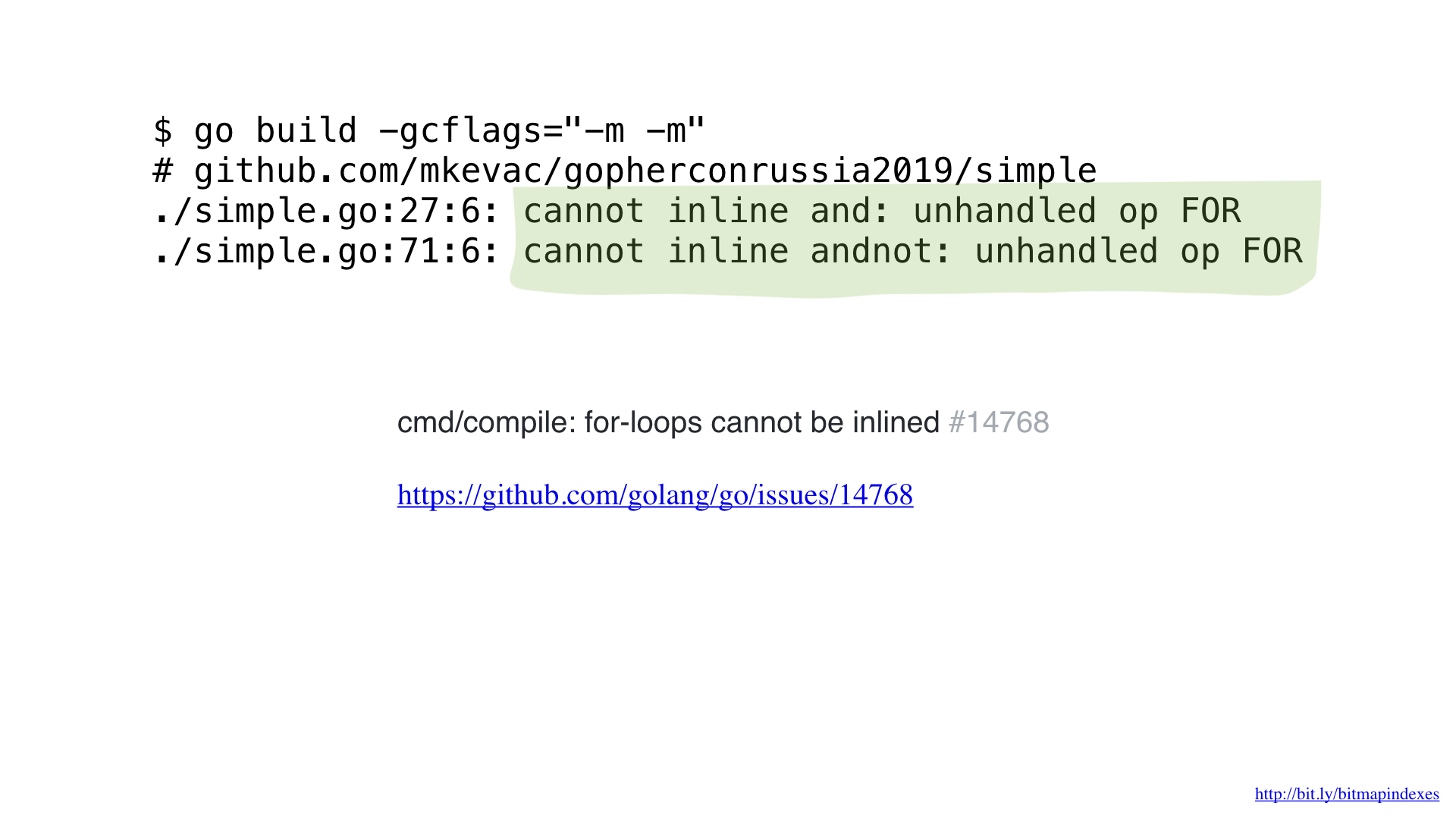
Mais je n'ai pas peur d'eux et je peux tromper le compilateur en utilisant goto pour ma boucle.


Comme vous pouvez le voir, l'inlining nous a permis d'économiser environ 2 microsecondes. Pas mal!

Un autre goulot d'étranglement est facile à repérer lorsque vous examinez de plus près la sortie de l'assemblage. Le compilateur Go a inclus des vérifications de plage dans notre boucle. Go est un langage sûr et le compilateur a peur que mes trois bitmaps aient des longueurs différentes et qu'il y ait un débordement de tampon.
Calmes le compilateur et montrons-lui que tous mes bitmaps sont de la même longueur. Pour ce faire, nous pouvons ajouter une simple vérification au début de la fonction.
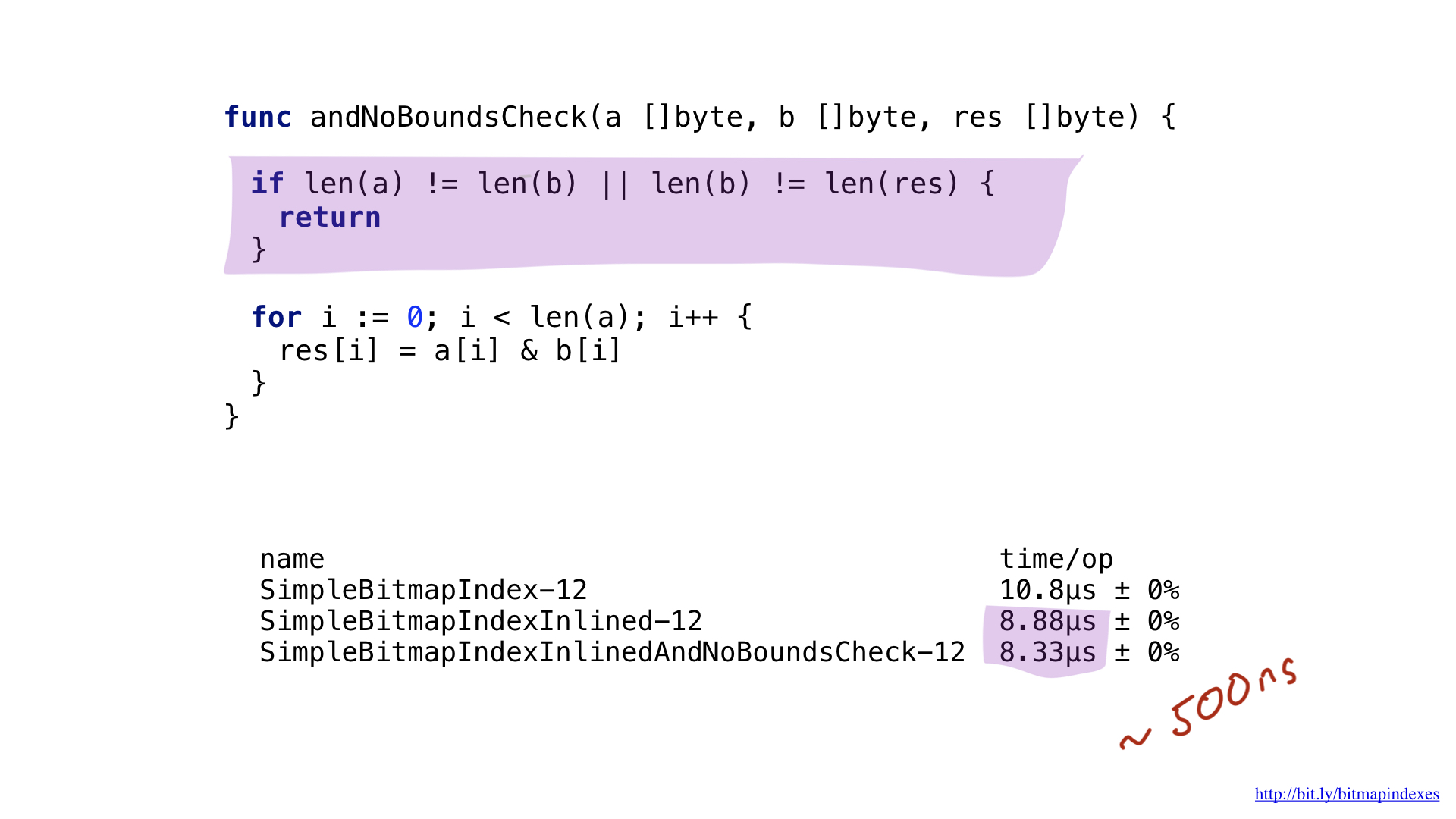
Avec cette vérification, le compilateur go sautera volontiers les vérifications de plage et nous économiserons quelques nanosecondes.
Mise en œuvre en montage
Très bien, nous avons donc réussi à réduire un peu plus les performances grâce à notre implémentation simple, mais ce résultat est bien pire que ce qui est possible avec le matériel actuel.
Vous voyez, ce que nous faisons sont des opérations binaires très basiques et nos processeurs sont très efficaces avec celles-ci.
Malheureusement, nous alimentons notre CPU avec de très petits morceaux de travail. Notre fonction fait des opérations octet par octet. Nous pouvons facilement modifier notre implémentation pour qu'elle fonctionne avec des blocs de 8 octets en utilisant des tranches d'uint64.

Comme vous pouvez le voir ici, nous avons gagné environ 8 fois les performances pour une taille de lot de 8 fois, donc les gains de performances sont à peu près linéaires.
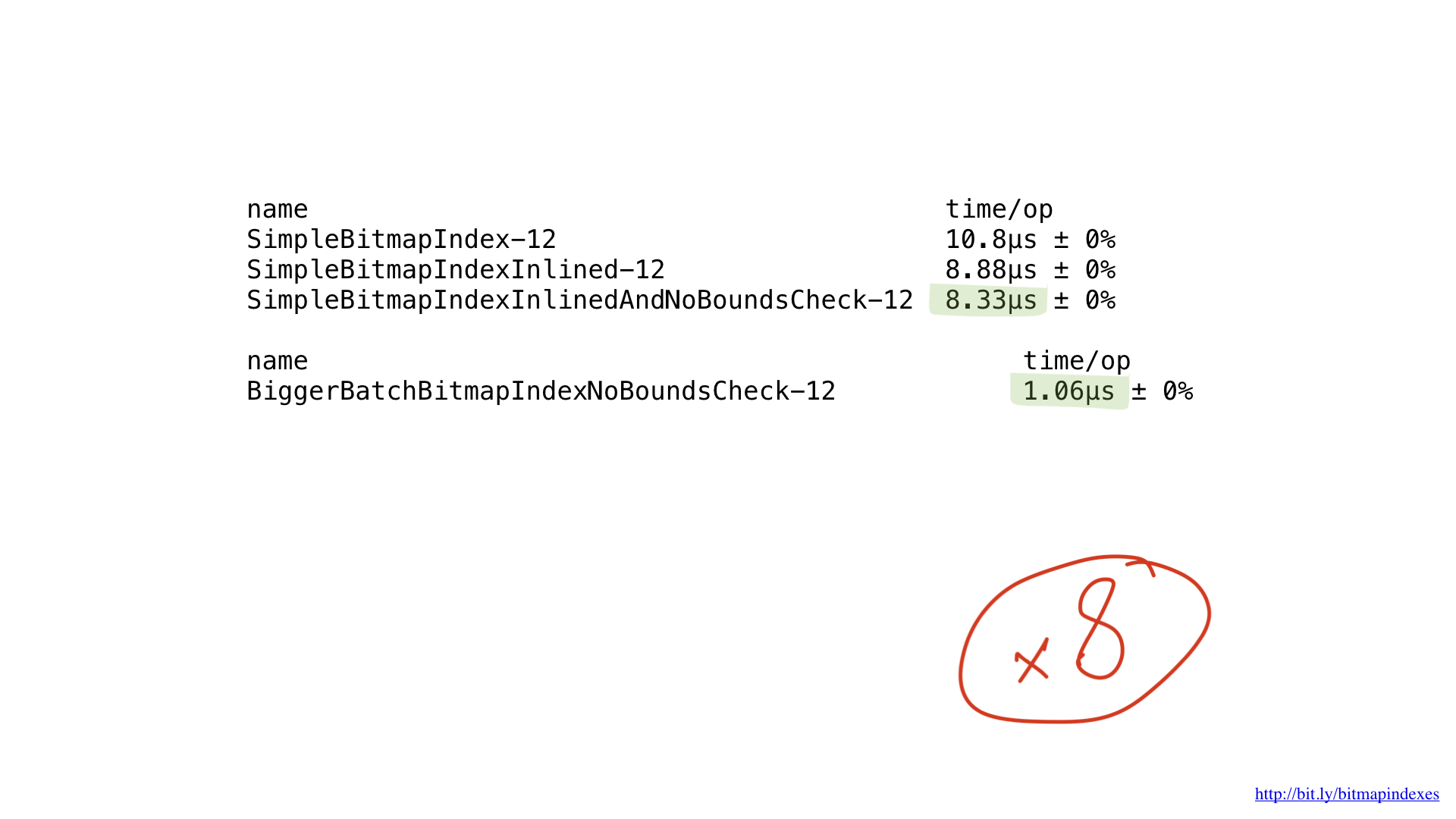

Mais ce n'est pas la fin de la route. Nos processeurs ont la capacité de fonctionner avec des blocs de 16 octets, 32 octets et même avec des blocs de 64 octets. Ces opérations sont appelées SIMD (Single Instruction Multiple Data) et le processus d'utilisation de telles opérations CPU est appelé vectorisation.
Malheureusement, le compilateur Go n'est pas très bon avec la vectorisation. Et la seule chose que nous pouvons faire de nos jours pour vectoriser notre code est d'utiliser l'assemblage Go et d'ajouter nous-mêmes ces instructions SIMD.

L'assemblage de go est une étrange bête. On pourrait penser que l'assemblage est quelque chose qui est lié à l'architecture pour laquelle vous écrivez, mais l'assemblage de Go ressemble plus à IRL (langage de représentation intermédiaire): il est indépendant de la plate-forme. Il y a quelques années, Rob Pike a fait un discours étonnant à ce sujet.
De plus, Go utilise un format plan9 inhabituel qui est différent des formats AT&T et Intel.

Il est sûr de dire qu'écrire du code d'assemblage Go n'est pas amusant.
Heureusement pour nous, il existe déjà deux outils de niveau supérieur pour vous aider à écrire l'assemblage Go: PeachPy et avo. Les deux génèrent un assemblage go à partir d'un code de niveau supérieur écrit respectivement en Python et Go.

Ces outils simplifient des choses comme l'allocation de registres et les boucles et, dans l'ensemble, réduisent la complexité d'entrer dans le domaine de la programmation d'assemblage pour Go.
Nous utiliserons l'évitement pour ce message afin que nos programmes ressemblent presque au code Go ordinaire.

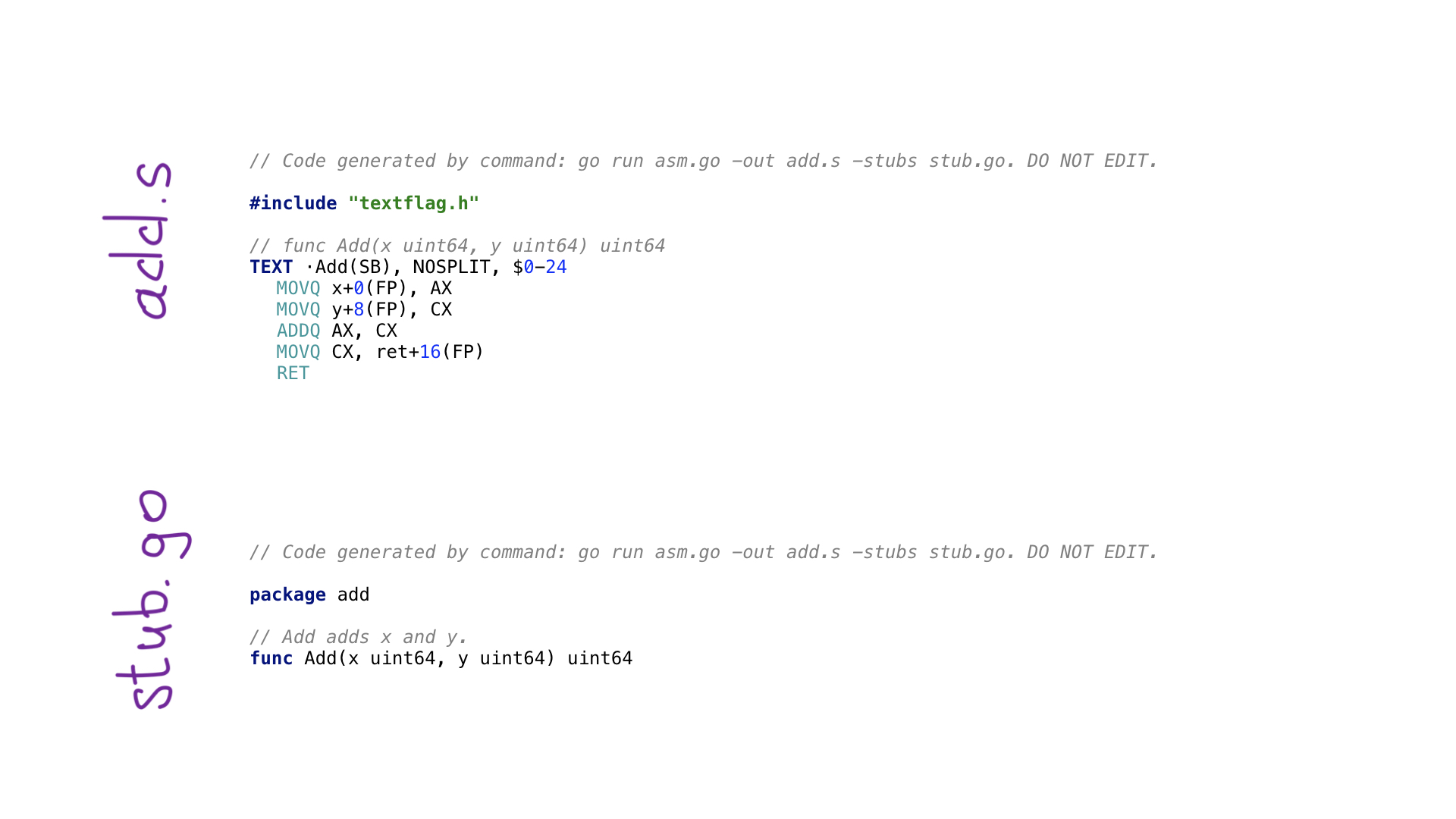
Ceci est l'exemple le plus simple d'un programme avo. Nous avons une fonction main () qui définit une fonction appelée Add () qui ajoute deux nombres. Il existe des fonctions d'aide pour obtenir les paramètres par nom et pour obtenir l'un des registres généraux disponibles. Il existe des fonctions pour chaque opération d'assemblage comme ADDQ ici, et il existe des fonctions d'assistance pour enregistrer le résultat d'un registre dans la valeur résultante.

L'appel à go generate exécutera ce programme avo et deux fichiers seront créés
- add.s avec le code d'assembly généré
- stub.go avec des en-têtes de fonction nécessaires pour connecter notre code go et assembly
Maintenant que nous avons vu ce que fait avo, regardons nos fonctions. J'ai implémenté des versions scalaires et SIMD (vectorielles) de nos fonctions.
Voyons à quoi ressemble la version scalaire en premier.

Comme dans un exemple précédent, nous pouvons demander un registre général et en évitant de nous en donner le bon qui soit disponible. Nous n'avons pas besoin de suivre les décalages en octets pour nos arguments, en évitant cela pour nous.

Auparavant, nous sommes passés de boucles à l'utilisation de goto pour des raisons de performances et pour tromper le compilateur go. Ici, nous utilisons goto (sauts) et étiquettes dès le début car les boucles sont des constructions de niveau supérieur. Au montage, nous n'avons que des sauts.

L'autre code devrait être assez clair. Nous émulons la boucle avec des sauts et des étiquettes, prenons une petite partie de nos données de nos deux bitmaps, les combinons en utilisant l'une des opérations au niveau du bit et insérons le résultat dans le bitmap résultant.

C'est un code asm résultant que nous obtenons. Nous n'avons pas eu à calculer les décalages et les tailles (en vert), nous n'avons pas eu à traiter de registres spécifiques (en rouge).
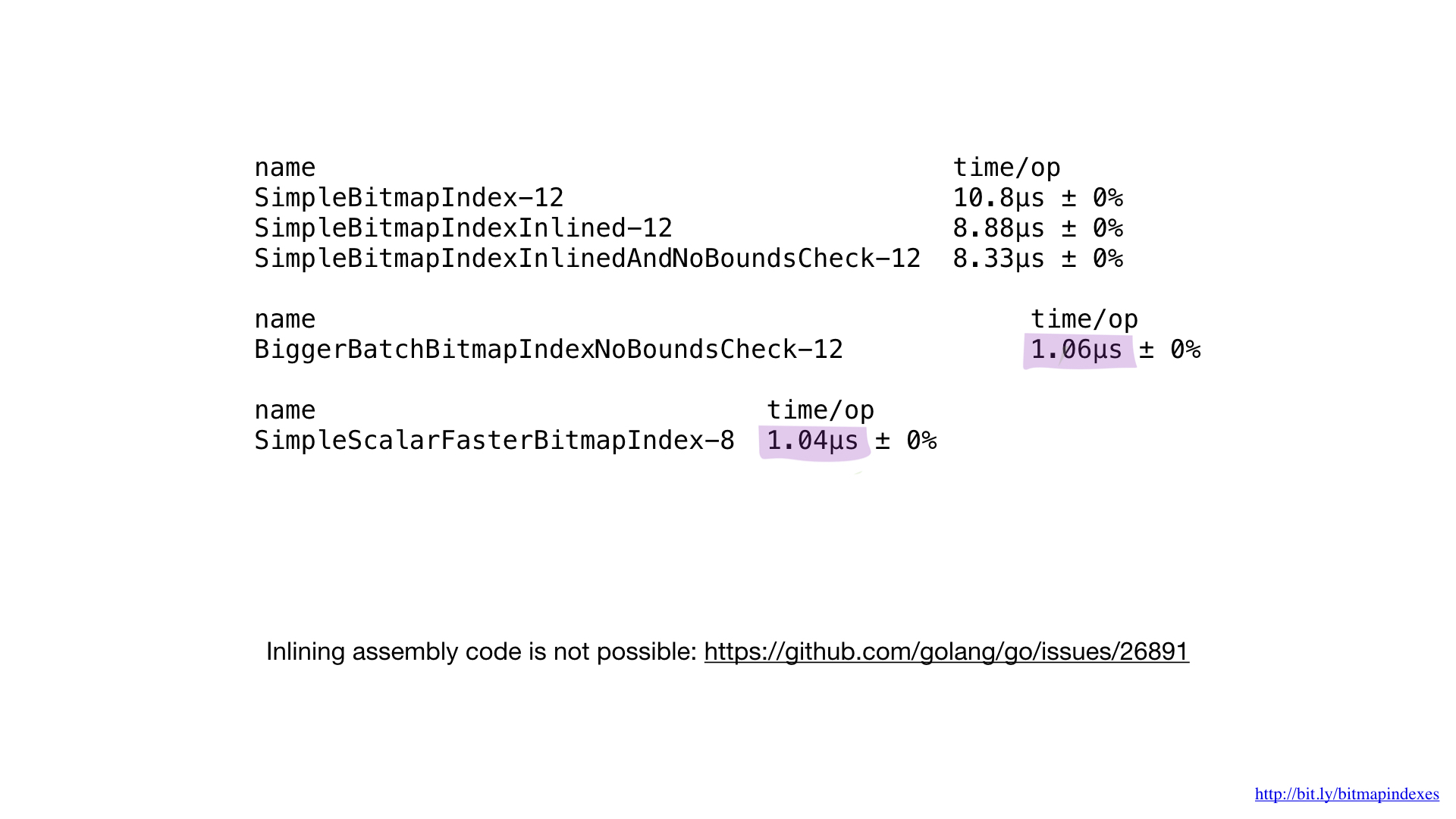
Si nous comparions cette implémentation en assembleur avec la meilleure précédente écrite en go, nous verrions que les performances sont les mêmes que prévu. Nous n'avons rien fait différemment.
Malheureusement, nous ne pouvons pas forcer le compilateur Go à intégrer nos fonctions écrites en asm. Il manque complètement de support pour cela et la demande pour cette fonctionnalité existe depuis un certain temps maintenant. C'est pourquoi les petites fonctions asm dans go ne donnent aucun avantage. Vous devez soit écrire des fonctions plus grandes, utiliser un nouveau package math / bits ou ignorer complètement asm.
Écrivons maintenant une version vectorielle de nos fonctions.

J'ai choisi d'utiliser AVX2, nous allons donc utiliser des morceaux de 32 octets. Il est très similaire à la structure scalaire. Nous chargeons des paramètres, demandons des registres généraux, etc.
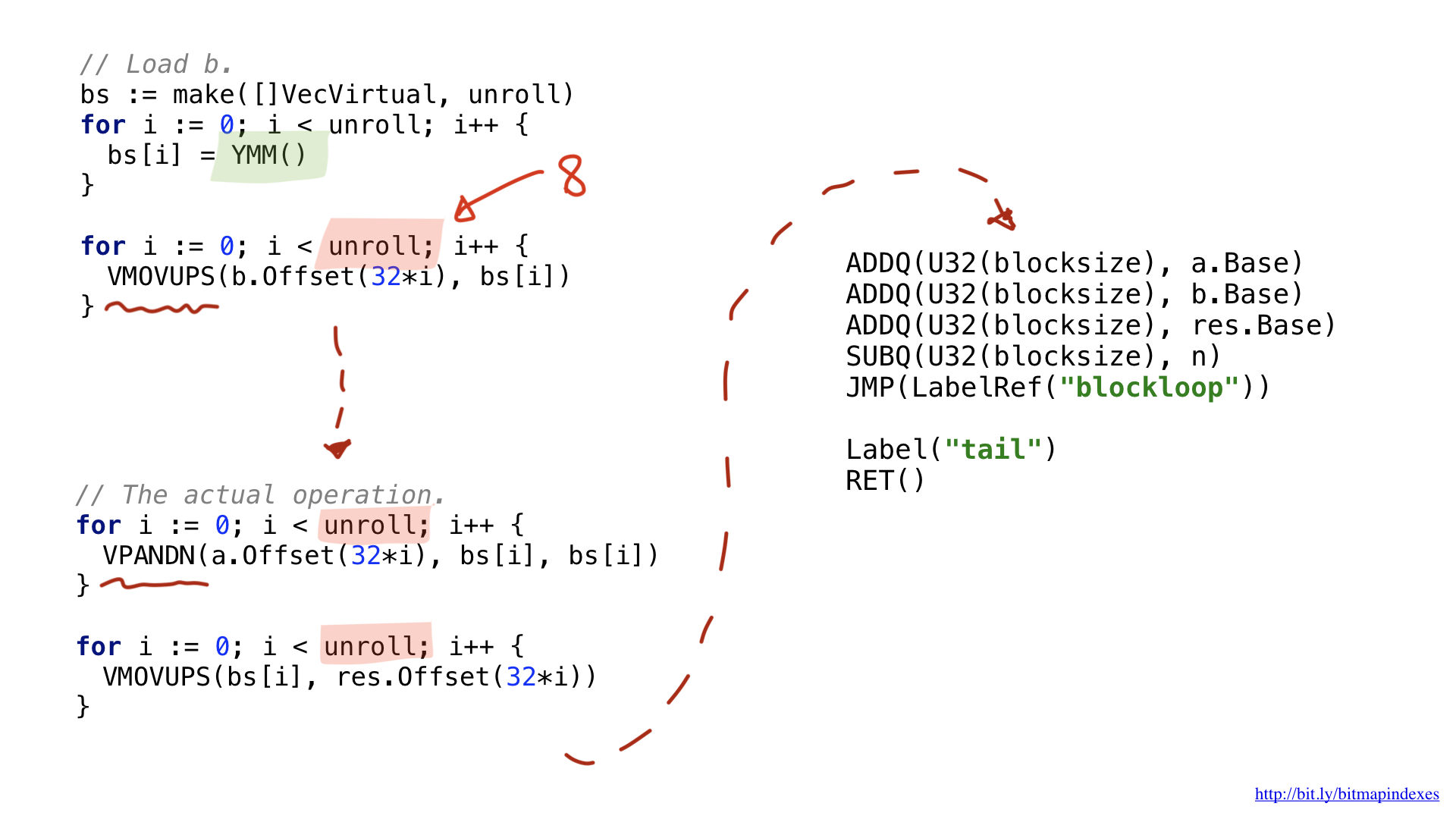
L'un des changements concerne le fait que les opérations vectorielles utilisent des registres larges spécifiques. Pour 32 octets, ils ont le préfixe Y, c'est pourquoi vous y voyez YMM (). Pour 64 octets, ils auraient eu le préfixe Z.
Une autre différence a à voir avec l'optimisation que j'ai effectuée, appelée déroulage ou déroulage de boucle. J'ai choisi de dérouler partiellement notre boucle et de faire 8 opérations de boucle en séquence avant de reboucler. Cette technique accélère le code en réduisant les branches dont nous disposons et elle est à peu près limitée par le nombre de registres dont nous disposons.
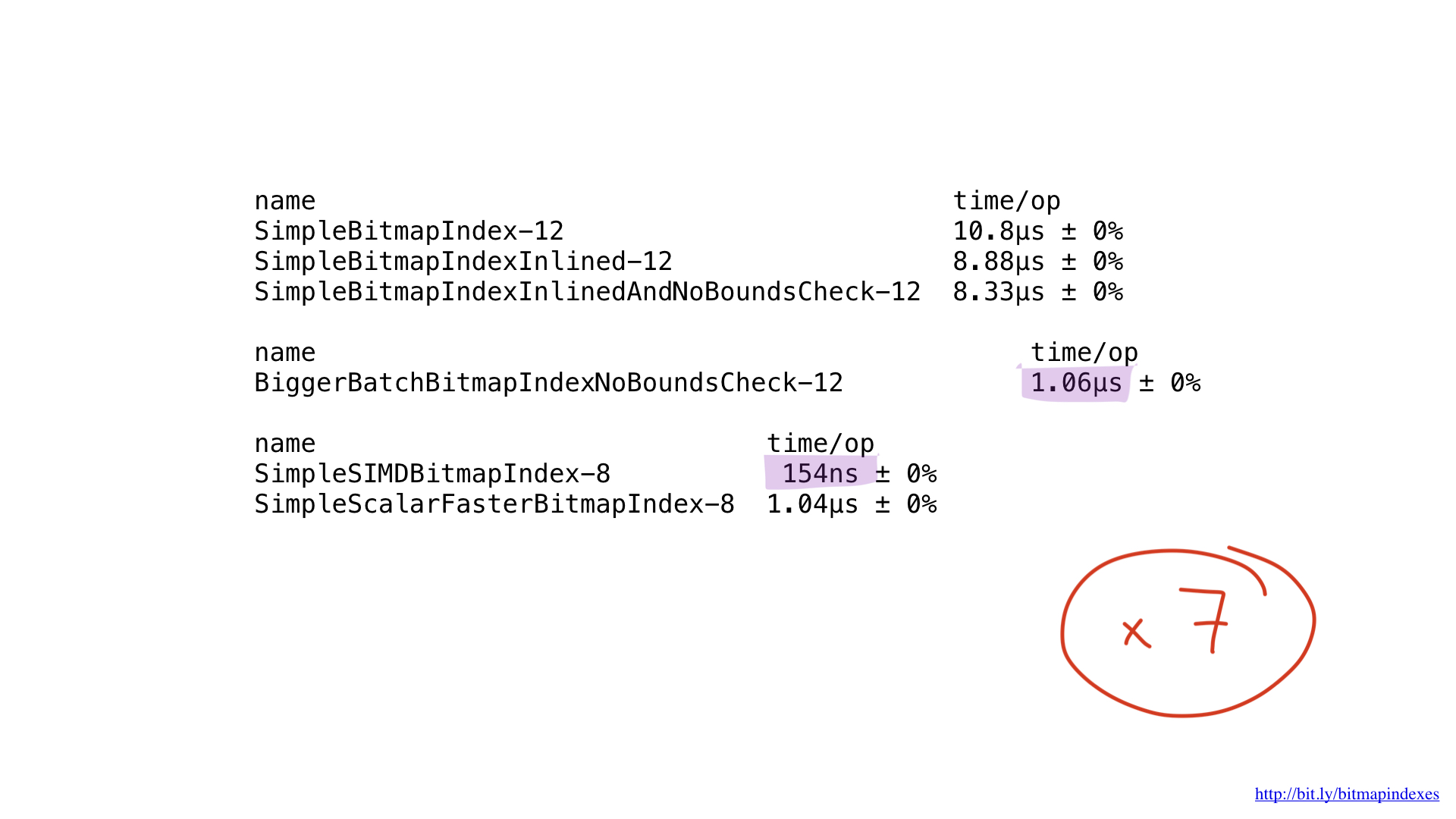
Quant aux performances ... c'est incroyable. Nous avons obtenu une amélioration d'environ 7x par rapport au meilleur précédent. Assez impressionnant, non?
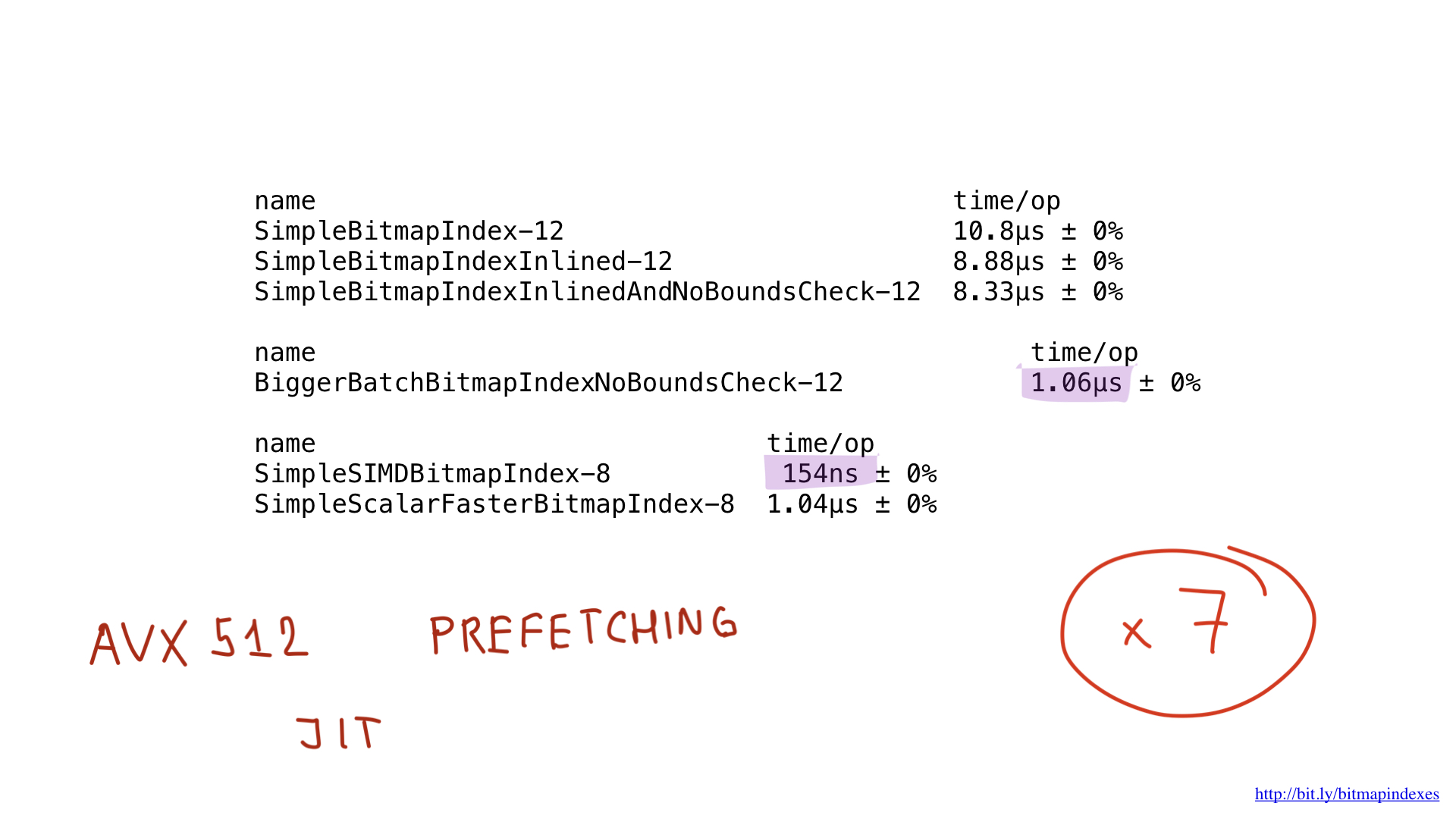
Il devrait être possible d'améliorer encore plus ces résultats en utilisant AVX512, la prélecture et peut-être même en utilisant la compilation JIT (juste à temps) au lieu du générateur de plan de requête "manuel", mais ce serait un sujet pour un article totalement différent.
Problèmes d'index bitmap
Maintenant que nous avons vu l'implémentation de base et la vitesse impressionnante de l'implémentation asm, parlons du fait que les index bitmap ne sont pas très largement utilisés. Pourquoi ça?

Des publications plus anciennes nous donnent ces trois raisons. Mais les plus récents et je soutiens que ceux-ci ont été "corrigés" ou traités à ce jour. Je n'entrerai pas dans beaucoup de détails à ce sujet ici parce que nous n'avons pas beaucoup de temps, mais cela vaut certainement le coup d'œil.
Problème de cardinalité élevée
Ainsi, on nous a dit que les index bitmap ne sont réalisables que pour les champs à faible cardinalité. c'est-à-dire des champs qui ont peu de valeurs distinctes, comme le sexe ou la couleur des yeux. La raison en est que la représentation commune (un bit par valeur distincte) peut devenir assez grande pour les valeurs à cardinalité élevée. Et, par conséquent, le bitmap peut devenir énorme même s'il est peu peuplé.
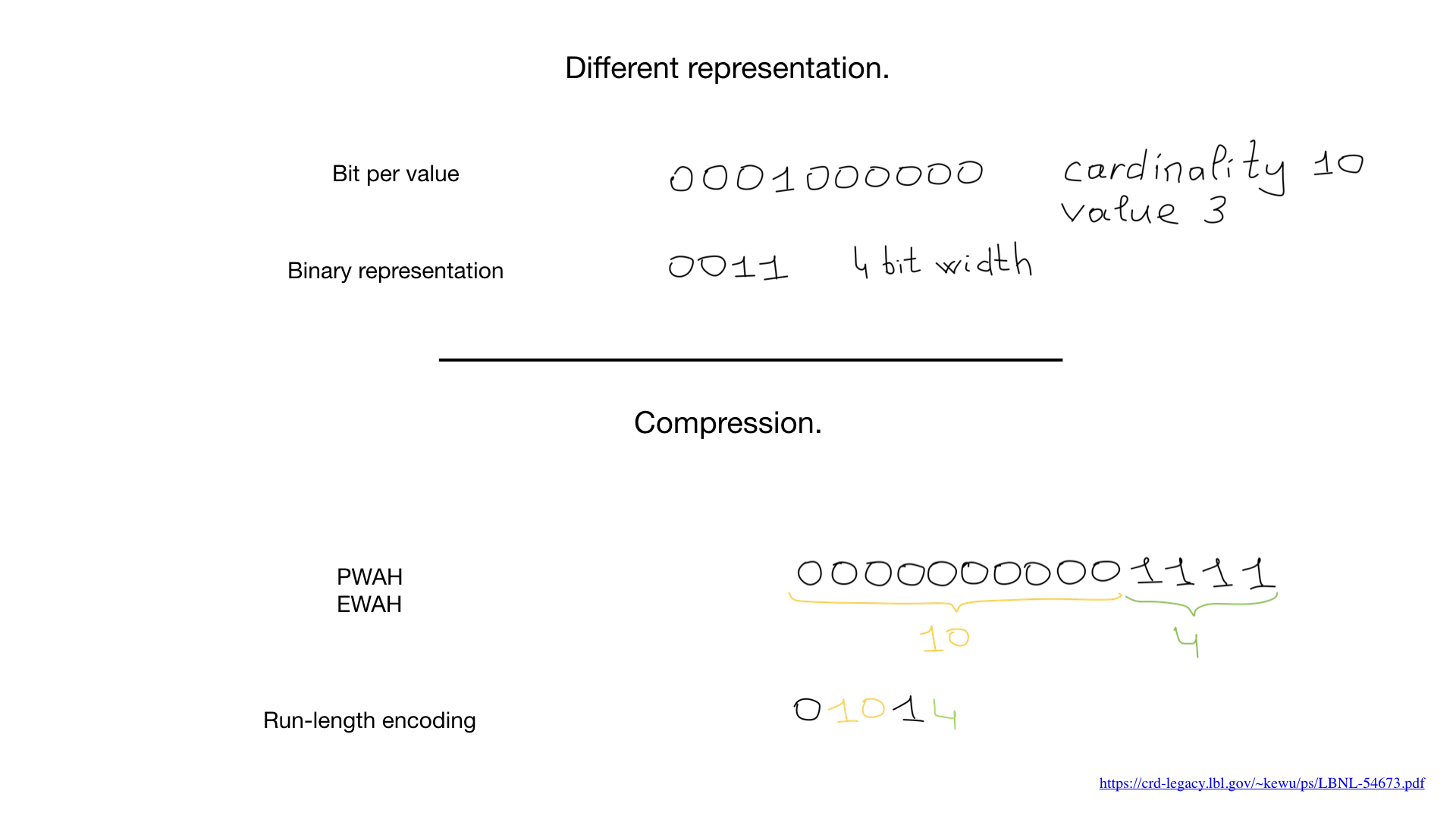
Parfois, une représentation différente peut être utilisée pour ces champs, comme une représentation numérique binaire comme illustré ici, mais le plus grand changeur de jeu est une compression. Les scientifiques ont mis au point des algorithmes de compression incroyables. Presque tous sont basés sur des algorithmes de longueur d'exécution répandus, mais ce qui est plus étonnant, c'est que nous n'avons pas besoin de décompresser les bitmaps pour effectuer des opérations au niveau du bit sur eux. Les opérations normales au niveau du bit fonctionnent sur les bitmaps compressés.

Récemment, nous avons vu des approches hybrides ressembler à des "bitmaps rugissants". Les bitmaps rugissants utilisent trois représentations distinctes pour les bitmaps: les bitmaps, les tableaux et les "exécutions de bits" et ils équilibrent l'utilisation de ces trois représentations à la fois pour maximiser la vitesse et pour minimiser l'utilisation de la mémoire.
Des bitmaps rugissants peuvent être trouvés dans certaines des applications les plus utilisées et il existe des implémentations pour de nombreux langages, y compris plusieurs implémentations pour Go.
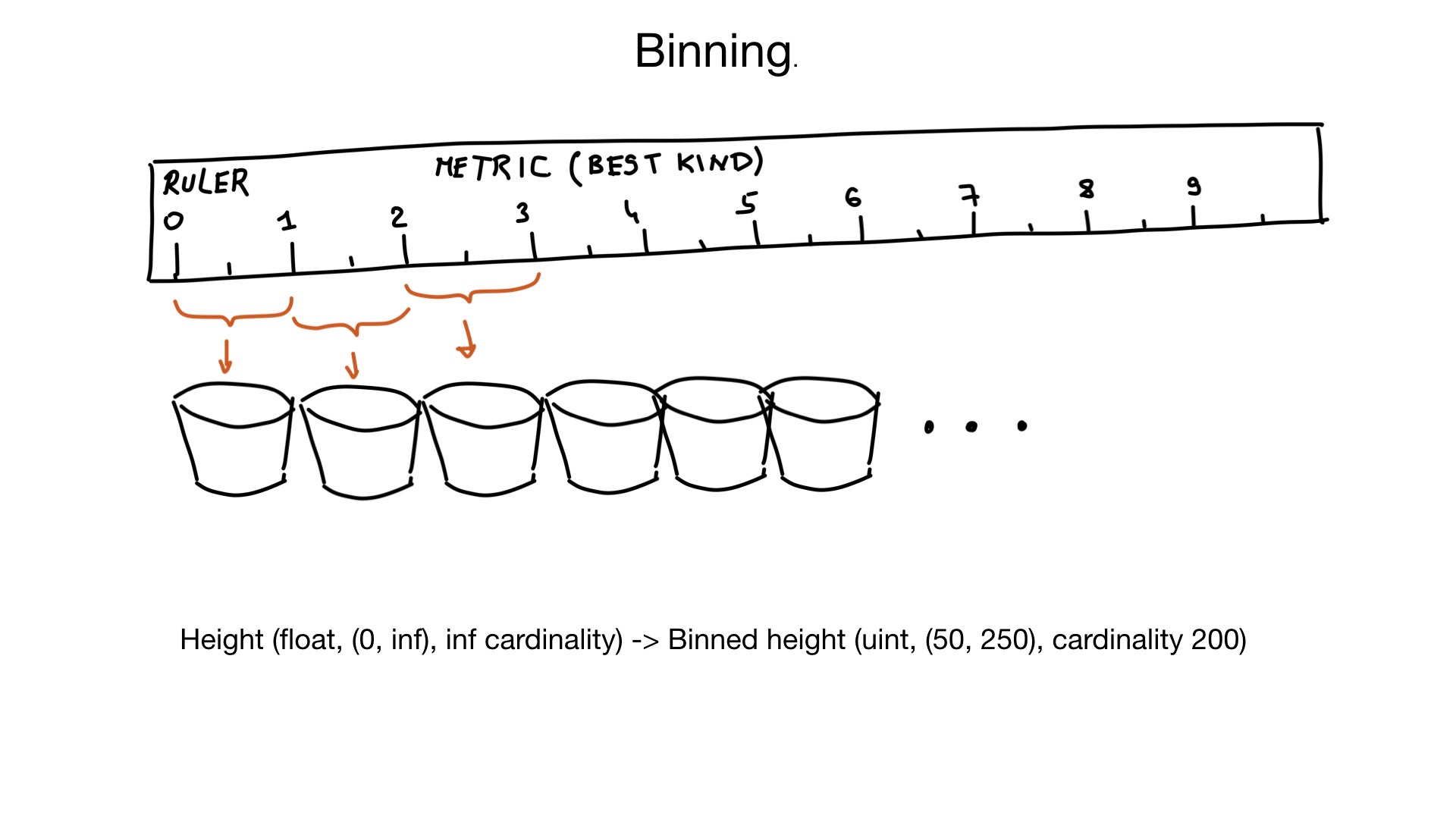
Une autre approche qui peut aider avec les champs à cardinalité élevée est appelée binning. Imaginez que nous ayons un champ représentant la taille d'une personne. La hauteur est un flotteur, mais nous ne pensons pas de cette façon. Personne ne se soucie si votre taille est de 185,2 ou 185,3 cm. Nous pouvons donc utiliser des «bacs virtuels» pour presser des hauteurs similaires dans le même bac: le bac de 1 cm, dans ce cas. Et si vous supposez qu'il y a très peu de personnes avec une hauteur inférieure à 50 cm, ou supérieure à 250 cm, nous pouvons convertir notre hauteur sur le terrain avec une cardinalité d'environ 200 éléments, au lieu d'une cardinalité presque infinie. Si nécessaire, nous pourrions effectuer un filtrage supplémentaire sur les résultats ultérieurement.
Problème de haut débit
Une autre raison pour laquelle les index bitmap sont mauvais est qu'il peut être coûteux de mettre à jour les bitmaps.
Les bases de données effectuent des mises à jour et des recherches en parallèle, vous devez donc être en mesure de mettre à jour les données alors qu'il peut y avoir des centaines de threads passant par des bitmaps faisant une recherche. Les verrous seraient des verrous nécessaires pour éviter les courses de données ou les problèmes de cohérence des données. Et là où il y a un gros verrou, il y a conflit de verrouillage.
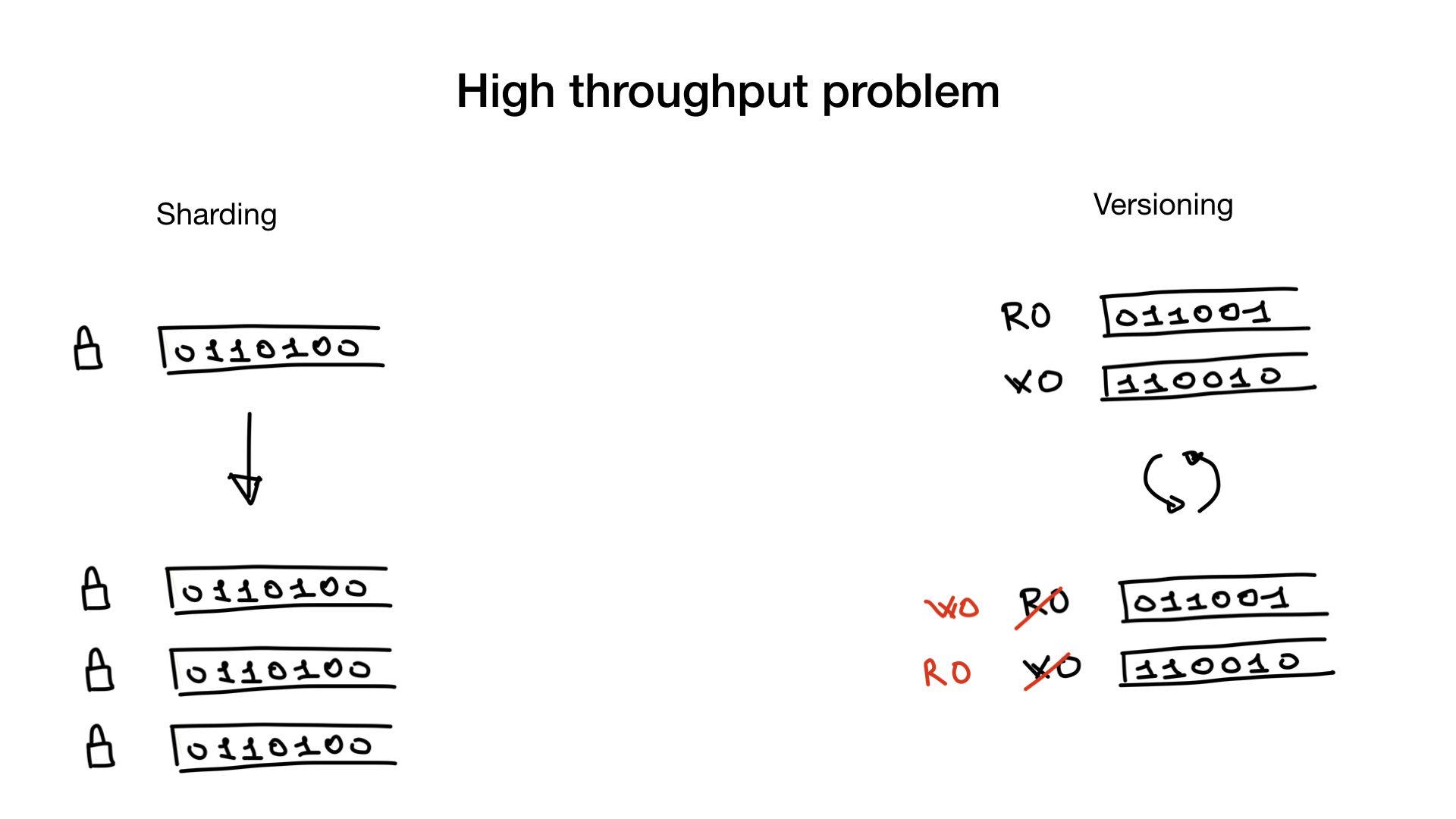
Ce problème, si vous l'avez, peut être résolu en partitionnant vos index ou en ayant des versions d'index, le cas échéant.
Le sharding est simple. Vous les divisez comme vous le feriez pour les utilisateurs d'une base de données et maintenant, au lieu d'un verrou, vous disposez de plusieurs verrous, ce qui réduit considérablement votre conflit de verrous.
Une autre approche qui est parfois réalisable est d'avoir des index versionnés. Vous avez l'index que vous utilisez pour la recherche et vous avez un index que vous utilisez pour les écritures, pour les mises à jour. Et vous les copiez et les commutez à une basse fréquence, par exemple 100 ou 500 ms.
Mais cette approche n'est possible que si votre application est capable de tolérer des index de recherche périmés qui sont un peu périmés.
Bien entendu, ces deux approches peuvent également être utilisées ensemble. Vous pouvez avoir des index versionnés fragmentés.
Requêtes non triviales
Un autre problème d'index bitmap concerne l'utilisation d'index bitmap avec des requêtes de plage. Et à première vue, les opérations au niveau du bit comme ET et OU ne semblent pas être très utiles pour les requêtes de gamme comme "donnez-moi des chambres d'hôtel qui coûtent de 200 à 300 dollars par nuit".

Une solution naïve et très inefficace consisterait à obtenir des résultats pour chaque prix de 200 à 300 et à OU les résultats.

Une approche légèrement meilleure consisterait à utiliser le binning et à placer nos hôtels dans des fourchettes de prix avec des largeurs de gamme de, disons, 50 dollars. Cette approche réduirait nos frais de recherche d'environ 50 fois.
Mais ce problème peut également être résolu très facilement en utilisant un encodage spécial qui rend les requêtes de plage possibles et rapides. Dans la littérature, ces bitmaps sont appelés bitmaps à plage codée.

Dans les bitmaps codés par plage, nous ne définissons pas seulement un bit spécifique pour, disons, la valeur 200, mais nous définissons tous les bits à 200 et plus. La même chose pour 300.
Ainsi, en utilisant cette requête de plage de représentation bitmap codée par plage, il est possible de répondre en seulement deux passages par bitmap. Nous obtenons tous les hôtels dont le coût est inférieur ou égal à 300 dollars et nous retirons du résultat tous les hôtels dont le coût est inférieur ou égal à 199 dollars. Terminé

Vous seriez étonné mais même les requêtes géographiques sont possibles en utilisant des bitmaps. L'astuce consiste à utiliser une représentation comme Google S2 ou similaire qui entoure une coordonnée dans une figure géométrique qui peut être représentée sous forme de trois lignes indexées ou plus. Si vous utilisez une telle représentation, vous pouvez alors représenter la requête géographique comme plusieurs requêtes de plage sur ces index de ligne.
Solutions prêtes
Eh bien, j'espère avoir un peu piqué votre intérêt. Vous avez maintenant un outil de plus sous votre ceinture et si jamais vous avez besoin d'implémenter quelque chose comme ça dans votre service, vous saurez où chercher.
C'est bien beau, mais tout le monde n'a pas le temps, la patience et les ressources pour implémenter l'index bitmap eux-mêmes, surtout quand il s'agit de choses plus avancées comme les instructions SIMD.
N'ayez crainte, il existe deux produits open source qui peuvent vous aider dans votre entreprise.

Rugissant
Tout d'abord, il y a une bibliothèque que j'ai déjà mentionnée appelée "bitmaps rugissants". Cette bibliothèque implémente un "conteneur" rugissant et toutes les opérations au niveau du bit dont vous auriez besoin si vous deviez implémenter un index bitmap complet.
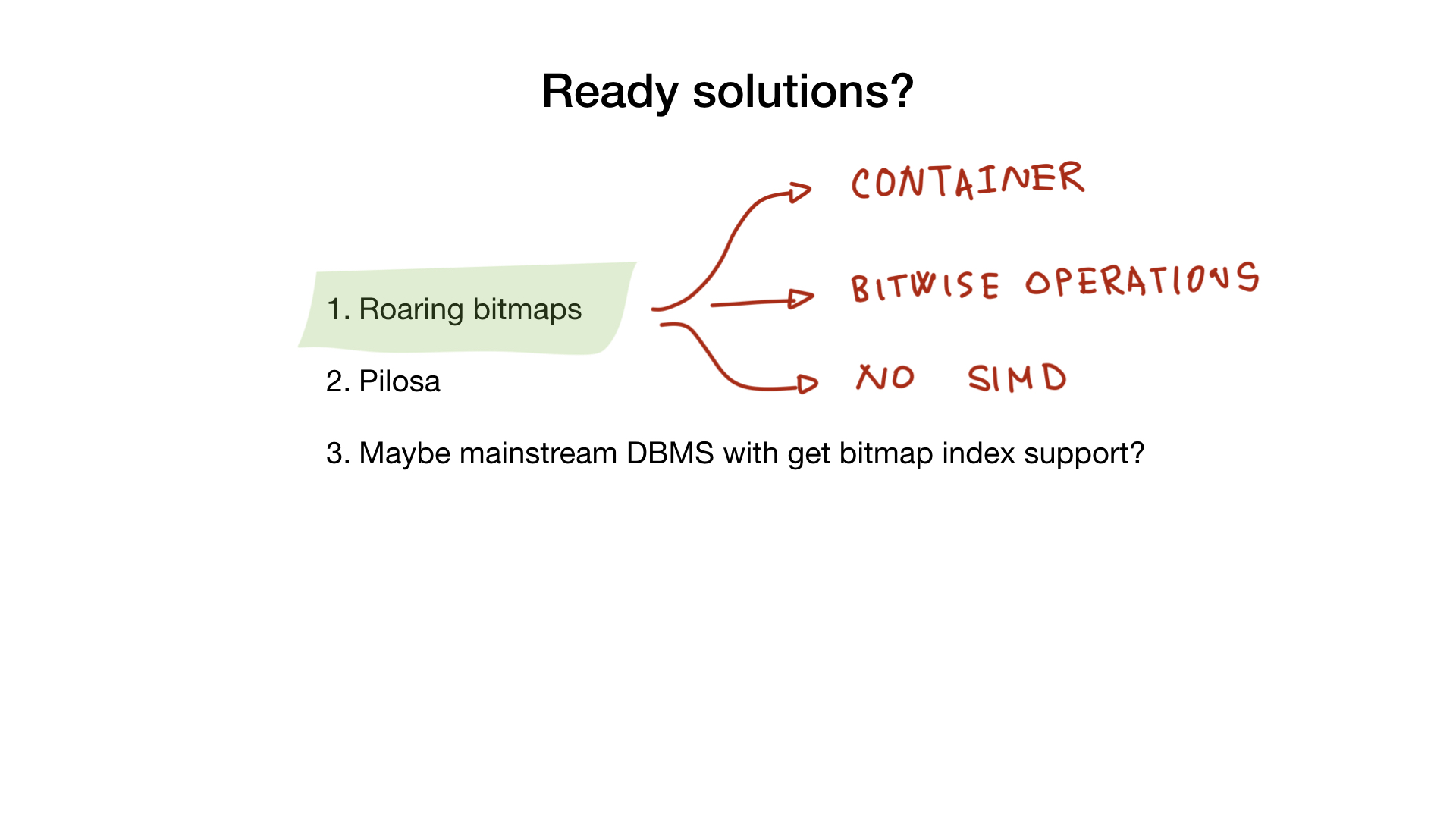
Malheureusement, les implémentations go n'utilisent pas SIMD, elles donnent donc des performances légèrement inférieures à, disons, l'implémentation C.
Pilosa
Un autre produit est un SGBD appelé Pilosa qui n'a que des index bitmap. C'est un projet récent, mais il a gagné beaucoup de traction ces derniers temps.
E-d3BCvTn1CSSDr5Vj6W_9e5_GC1syQ9qSrwdS0 ">
Pilosa utilise des bitmaps rugissants en dessous et donne, simplifie ou explique presque tout ce que je vous ai dit aujourd'hui: le binning, les bitmaps à plage codée, la notion de champs, etc.
Regardons brièvement un exemple de Pilosa utilisé ...

L'exemple que vous voyez est très très similaire à ce que nous avons vu plus tôt. Nous créons un client pour le serveur pilosa, créons un index et des champs pour nos caractéristiques. Nous remplissons les champs avec des données aléatoires avec quelques probabilités comme nous l'avons fait précédemment, puis nous exécutons notre requête de recherche.
Vous voyez le même modèle de base ici. PAS cher intersecté ou ET-ed avec terrasse et intersecté avec réservations.
Le résultat est comme prévu.

Et enfin, j'espère que dans le futur, les bases de données comme mysql et postgresql obtiendront un nouveau type d'index: index bitmap.

Mots de clôture

Et si vous êtes encore éveillé, je vous en remercie. Le manque de temps a signifié que j'ai dû survoler beaucoup de choses dans ce post, mais j'espère que cela a été utile et peut-être même inspirant.
Les index bitmap sont une chose utile à connaître et à comprendre même si vous n'en avez pas besoin pour le moment. Gardez-les comme un autre outil dans votre portefeuille.
Au cours de mon exposé, nous avons vu diverses astuces de performance que nous pouvons utiliser et des choses avec lesquelles Go a du mal à l'instant. Ce sont certainement des choses que chaque programmeur Go doit savoir.
Et c'est tout ce que j'ai pour vous pour l'instant. Merci beaucoup!