Partie 1 >>
Partie 2 >>
Partie 3
L'un des processeurs les plus populaires de la dernière décennie était l'Intel Core i7-2600K. La conception était révolutionnaire, car elle offrait un bond significatif dans les performances et l'efficacité d'un processeur monocœur, et le processeur lui-même réagissait également bien à l'overclocking. Les prochaines générations de processeurs Intel ne semblaient plus si intéressantes et ne donnaient souvent pas aux utilisateurs une raison de mettre à niveau, de sorte que l'expression "je resterai avec mon 2600K" est devenue omniprésente dans les forums et les sons, même aujourd'hui. Dans cette revue, nous avons secoué la poussière de la boîte avec les anciens processeurs et conduit le vétéran à travers un ensemble de repères en 2019, à la fois sur les paramètres d'usine et en overclocking, pour nous assurer qu'il est toujours le champion.
 Photo de famille Core i7
Photo de famille Core i7Pourquoi le 2600K est devenu crucial pour la génération
Asseyez-vous sur une chaise, asseyez-vous et imaginez-vous en 2010. Cette année-là, vous avez examiné votre ancien système Core 2 Duo ou Athlon II et vous avez réalisé qu'il était temps de procéder à une mise à niveau. Vous connaissez déjà l'architecture de Nehalem, et vous savez que le Core i7-920 accélère bien et fait concurrence. C'était un bon moment, mais soudainement Intel a rééquilibré l'industrie et a créé un produit vraiment révolutionnaire. Les échos de la nostalgie dont on se fait encore entendre.
 Core i7-2600K: le Sandy Bridge le plus rapide (jusqu'à 2700K)
Core i7-2600K: le Sandy Bridge le plus rapide (jusqu'à 2700K)Ce nouveau produit était Sandy Bridge. AnandTech a publié une revue exclusive, et les résultats étaient presque impossibles à croire, pour de nombreuses raisons. Selon nos tests de l'époque, le processeur était tout simplement incomparablement plus élevé que tout ce que nous avons vu auparavant, en particulier compte tenu des monstres thermiques Pentium 4 qui étaient sortis quelques années auparavant. Une mise à niveau de base basée sur le processus 32 nm d'Intel a été le plus grand tournant dans les performances x86, et depuis lors, nous n'avons pas vu de telles percées. AMD aura encore besoin de 8 ans pour obtenir son moment de gloire avec la série Ryzen. Intel a réussi à profiter du succès de son meilleur produit et à obtenir une place de champion.
Dans cette conception de base, Intel n'a pas lésiné sur l'innovation. L'un des éléments clés était le cache de micro-opération. Cela signifiait que les instructions nouvellement décodées, qui étaient à nouveau nécessaires, sont prises déjà décodées, au lieu de gaspiller de l'énergie lors du re-décodage. Pour Intel avec Sandy Bridge, et bien plus tard pour AMD avec Ryzen, l'activation du cache micro-opérationnel était un miracle pour les performances à un seul thread. Intel a également commencé à améliorer le multithreading simultané (appelé depuis plusieurs générations HyperThreading), en travaillant progressivement sur l'allocation dynamique des threads de calcul.
La conception quadricœur du meilleur processeur au lancement, le Core i7-2600K, est devenue la base des produits des cinq prochaines générations d'architecture Intel, notamment Ivy Bridge, Haswell, Broadwell, Skylake et Kaby Lake. Depuis Sandy Bridge, bien qu'Intel soit passé à un processus plus petit et ait profité d'une consommation d'énergie plus faible, la société n'a pas été en mesure de recréer ce saut exceptionnel dans la bande passante nette des équipes. Plus tard, la croissance pour l'année a été de 1 à 7%, principalement en raison de l'augmentation des tampons opérationnels, des ports d'exécution et du support des commandes.
Étant donné qu'Intel n'a pas pu reproduire la percée de Sandy Bridge et que la microarchitecture de base était la clé des performances x86, les utilisateurs qui ont acheté le Core i7-2600K (j'en ai acheté deux) y sont restés longtemps. En grande partie à cause de l'attente d'un autre grand bond des performances. Et au fil des ans, leur frustration grandit: pourquoi investir dans un quad-core Kaby Lake Core i7-7700K cadencé à 4,7 GHz alors que votre quad-core Sandy Bridge Core i7-2600K est toujours overclocké à 5,0 GHz?
(Les réponses d'Intel concernent généralement la consommation d'énergie et les nouvelles fonctionnalités telles que les GPU et les disques via PCIe 3.0. Mais certains utilisateurs ne sont pas satisfaits de ces explications.)
C'est pourquoi le Core i7-2600K a défini une génération. Il est resté valable, d'abord à la joie d'Intel, puis à la déception lorsque les utilisateurs n'ont pas voulu mettre à jour. Maintenant, en 2019, nous comprenons qu'Intel a déjà dépassé les quatre cœurs de ses principaux processeurs, et si l'utilisateur est trop cher pour la DDR4, il peut soit passer au nouveau système Intel, soit choisir le chemin AMD. Mais voici la question de savoir comment le Core i7-2600K gère les charges de travail et les jeux de 2019; ou, plus précisément, comment fonctionne le Core i7-2600K overclocké?
Trouvez les différences: Sandy Bridge, Kaby Lake, Coffee Lake
En vérité, le Core i7-2600K n'était pas le processeur Sandy Bridge le plus rapide. Quelques mois plus tard, Intel a lancé un 2700K légèrement plus «haute fréquence» sur le marché. Il fonctionnait presque de la même manière et accélérait de façon similaire à 2600K, mais cela coûtait un peu plus. À ce moment-là, les utilisateurs qui ont vu une amélioration des performances et une mise à niveau étaient déjà à 2600K, et sont restés avec.
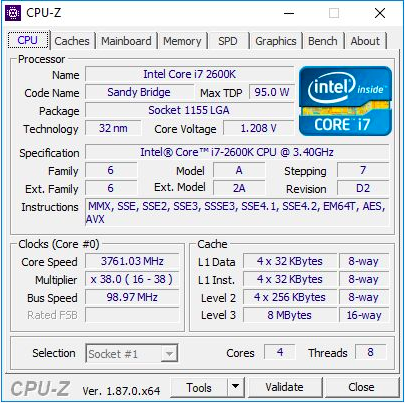
Le Core i7-2600K était un processeur quadricœur de 32 nm doté de la technologie HyperThreading, avec une fréquence de base de 3,4 GHz, une fréquence turbo de 3,8 GHz et un TDP nominal de 95 watts. Ensuite, le TDP d'Intel n'était pas encore séparé de la réalité: lors de nos tests pour cet article, nous avons constaté une consommation électrique maximale de 88 W sur un processeur non synchronisé. Le processeur est livré avec une carte graphique intégrée Intel HD 3000 et prend en charge la mémoire DDR3-1333 par défaut. Intel a fixé un prix de 317 $ lors du lancement de la puce.
Pour cet article, j'ai utilisé le deuxième i7-2600K, que j'ai acheté lors de leur première apparition. Il a été testé à la fréquence standard et overclocké à 4,7 GHz sur tous les cœurs. Il s'agit d'un overclocking moyen - le meilleur de ces puces fonctionne à une fréquence de 5,0 GHz à 5,1 GHz en mode quotidien. En fait, je me souviens bien comment mon premier Core i7-2600K fonctionnait à 5,1 GHz sur tous les cœurs, et même à 5,3 GHz (également sur tous les cœurs), lors de compétitions d'overclocking en plein hiver, à température ambiante à une température d'environ 2 ° C, j'ai utilisé un refroidisseur de liquide puissant et des radiateurs de 720 mm. Malheureusement, au fil du temps, j'ai endommagé cette puce, et maintenant elle ne se charge même pas à la fréquence et à la tension nominales. Ainsi, nous devrions utiliser ma deuxième puce, qui n'était pas si bonne, mais qui pouvait quand même donner une idée du processeur overclocké. Lors de l'overclocking, nous avons également utilisé la mémoire overclockée, DDR3-2400 C11.
Il convient de noter que depuis le lancement du Core i7-2600K, nous sommes passés de Windows 7 à Windows 10. Le Core i7-2600K ne prend pas en charge les instructions AVX2 et n'a pas été créé pour Windows 10, il sera donc particulièrement intéressant de voir comment cela s'affiche sur les résultats.

 Core i7-7700K: dernier processeur quadricœur Intel Core i7 avec technologie HyperThreading
Core i7-7700K: dernier processeur quadricœur Intel Core i7 avec technologie HyperThreadingLe processeur Quad-core le plus rapide et le plus récent (et le plus récent?) Avec HyperThreading, publié par Intel, était le Core i7-7700K, un membre de la famille Kaby Lake. Ce processeur est construit sur la technologie de processus améliorée de 14 nm d'Intel, fonctionne à une fréquence de base de 4,2 GHz et une fréquence turbo de 4,5 GHz. Son TDP avec une puissance nominale de 91 watts dans notre test a montré une consommation d'énergie de 95 watts. Il est livré avec une carte graphique Intel Gen9 HD 630 et prend en charge la mémoire DDR4-2400 standard. Intel a sorti une puce au prix déclaré de 339 dollars.
Avec le 7700K, Intel a également publié son premier processeur dual-core overclocké avec hypertreading - Core i3-7350K. Au cours de cet examen, nous avons overclocké un tel Core i3 et l'avons comparé avec le Core i7-2600K aux paramètres d'usine, essayant de répondre à la question de savoir si Intel a réussi à obtenir des performances de processeur dual-core similaires à leur ancien produit phare quad-core. En conséquence, bien que i3 ait prévalu en termes de performances monothread et de travail avec la mémoire, le manque de quelques cœurs dans le compte a rendu la plupart des tâches trop difficiles pour Core i3.

 Core i7-9700K: le dernier sommet de l'Intel Core i7 (maintenant avec 8 cœurs)
Core i7-9700K: le dernier sommet de l'Intel Core i7 (maintenant avec 8 cœurs)Notre dernier processeur pour les tests est le Core i7-9700K. Dans la génération actuelle, ce n'est plus le fleuron de Coffee Lake (maintenant c'est le i9-9900K), mais il a huit cœurs sans hypertreading. La comparaison avec le 9900K, qui a deux fois plus de cœurs et de threads, semble inutile, surtout lorsque le prix de l'i9 est de 488 $. En revanche, le Core i7-9700K est vendu en vrac à "seulement" 374 $, avec une fréquence de base de 3,6 GHz et une fréquence turbo de 4,9 GHz. Son TDP est défini par Intel à 95 watts, mais sur la carte mère grand public, la puce consomme ~ 125 watts à pleine charge. La mémoire DDR4-2666 est prise en charge en standard.
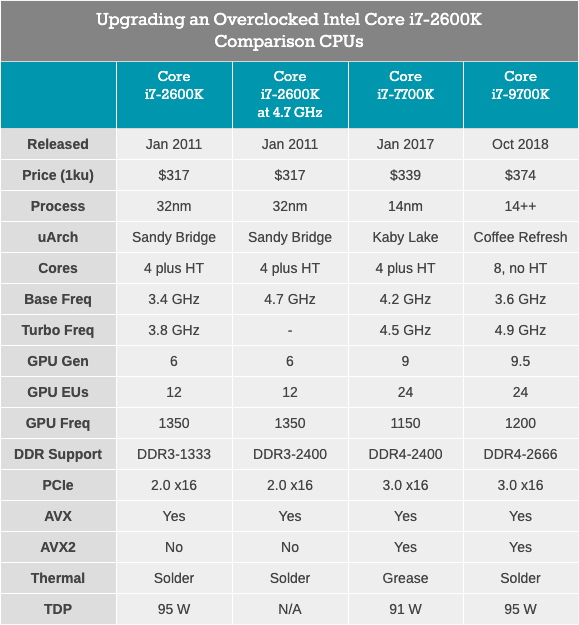
Le Core i7-2600K est forcé de fonctionner avec DDR3, prend en charge PCIe 2.0, pas PCIe 3.0, et n'est pas conçu pour fonctionner avec les disques NVMe (qui ne sont pas impliqués dans ce test). Il sera intéressant de voir à quel point le vétéran overclocké est proche du Core i7-7700K, et quel type de croissance nous verrons lorsque nous passerons à quelque chose comme le Core i7-9700K.
Sandy Bridge: Core Architecture
En 2019, nous parlons de puces 100-200 mm2 avec jusqu'à huit cœurs haute performance, et créées sur la dernière technologie de processus Intel ou AMD GlobalFoundries / TSMC. Mais le Sandy Bridge de 32 nm était une bête complètement différente. Le processus de production était toujours «plat», sans transistors FinFET. Dans le nouveau processeur, la deuxième génération de High-K a été mise en œuvre et une mise à l'échelle de 0,7x a été obtenue par rapport à la technologie de processus précédente de 45 nm plus grande. Le Core i7-2600K était la plus grande puce quadricœur et contenait 1,16 milliard de transistors par 216 mm2. À titre de comparaison, le dernier processeur Coffee Lake à 14 nm possède huit cœurs et plus de 2 milliards de transistors dans une zone d'environ 170 mm2.
Le secret de l'énorme saut de performance réside dans la microarchitecture du processeur. Sandy Bridge a promis (et assuré) des performances significatives à des vitesses d'horloge égales par rapport aux processeurs Westmere de la génération précédente, et a également constitué le circuit de base des puces Intel pour la prochaine décennie. De nombreuses innovations clés sont apparues dans le commerce de détail avec l'avènement de Sandy Bridge, puis de nombreuses itérations ont été répétées et améliorées, atteignant progressivement les hautes performances que nous utilisons aujourd'hui.
Dans la revue actuelle, je me suis largement appuyé sur le rapport initial de microarchitecture 2600K d'Anandtech, publié en 2010. Bien sûr, avec quelques ajouts basés sur un look moderne de ce processeur.
Brève revue: cœur de processeur avec exécution extraordinaire des instructions
Pour les débutants en conception de processeur, voici un bref aperçu du fonctionnement d'un processeur extra-processeur. En bref, le noyau est divisé en interfaces externes et internes (front-end et back-end), et les données vont d'abord à l'interface externe.
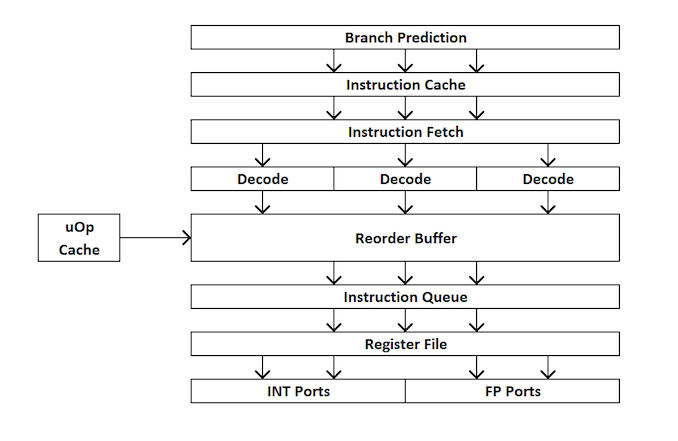
Dans l'interface externe, nous avons des prefetchers et des prédicteurs de branche qui prédiront et récupéreront les instructions de la mémoire principale. L'idée est que si vous pouvez prédire quelles données et instructions seront nécessaires dans un avenir proche (avant qu'elles ne soient nécessaires), vous pouvez gagner du temps en plaçant ces données près du noyau. Ensuite, les instructions sont placées dans un décodeur, qui convertit l'instruction de bytecode en une série de "micro-opérations" que le noyau peut ensuite traiter.
Il existe différents types de décodeurs pour les instructions simples et complexes - les instructions x86 simples sont facilement mappées à une seule micro-opération, tandis que les instructions plus complexes peuvent être décodées pour plus d'opérations. La situation idéale est le coefficient de décodage le plus bas possible, même si parfois les instructions peuvent être divisées en un plus grand nombre de micro-opérations si ces opérations peuvent être effectuées en parallèle (parallélisme au niveau commande ou ILP).
Si le noyau a un cache de micro-opération, c'est aussi un cache uOp, alors les résultats de chaque instruction décodée y sont stockés. Avant que l'instruction ne soit décodée, le noyau vérifie si cette instruction particulière a été décodée récemment et, en cas de succès, utilise le résultat du cache au lieu de re-décoder, ce qui consomme de l'énergie.
Désormais, les micro-opérations placent des «files d’attribution» - file d’attribution. Le cœur moderne peut déterminer si les instructions font partie d'un cycle simple ou si les uOps (micro-opérations) peuvent être combinés pour accélérer l'ensemble du processus. Ensuite, les uOps sont introduits dans le tampon de réorganisation, qui forme le «back-end» du noyau.
Dans le backend, en commençant par le tampon de réorganisation, les uOps peuvent être réorganisés en fonction de l'emplacement des données nécessaires à chaque micro-opération. Ce tampon peut renommer et distribuer des micro-opérations selon où elles doivent aller (opérations entières ou FP), et, selon le noyau, il peut également agir comme un mécanisme de suppression des instructions terminées. Après la réorganisation, les tampons uOps sont envoyés au planificateur dans l'ordre nécessaire pour s'assurer que les données sont prêtes et maximiser le débit de uOp.
Le planificateur envoie des uOps aux ports d'exécution (pour effectuer des calculs) selon les besoins. Certains noyaux ont un planificateur unique pour tous les ports, mais dans certains cas, il est divisé en un planificateur pour les opérations de type entier / vecteur. La plupart des noyaux avec une exécution extraordinaire ont de 4 à 10 ports (certains de plus), et ces ports effectuent les calculs nécessaires pour que l'instruction «passe» à travers le noyau. Les ports d'exécution peuvent prendre la forme d'un module de chargement (chargement à partir d'un cache), d'un module de stockage (stockage dans un cache), d'un module d'opérations mathématiques entières, d'un module d'opérations mathématiques à virgule flottante, ainsi que d'opérations mathématiques vectorielles, de modules de division spéciaux et d'autres pour les opérations spéciales . Une fois que le port d'exécution a fonctionné, les données peuvent être stockées dans un cache pour réutilisation, placées dans la mémoire principale; à ce moment, l'instruction est envoyée à la file d'attente de suppression et finalement supprimée.
Cette vue d'ensemble ne couvre pas certains des mécanismes que les noyaux modernes utilisent pour faciliter la mise en cache et la récupération des données, tels que les tampons de transaction, les tampons de flux, le balisage, etc. Certains mécanismes s'améliorent de manière itérative à chaque génération, mais généralement lorsque nous parlons d '«instructions» par horloge »comme indicateur de performance, nous nous efforçons de« sauter »autant d'instructions que possible à travers le noyau (via le frontend et le backend). Cet indicateur dépend de la vitesse de décodage sur le frontend du processeur, des instructions de prélecture, du tampon de réorganisation et de l'utilisation maximale des ports d'exécution ainsi que de la suppression du nombre maximal d'instructions exécutées pour chaque cycle d'horloge.
Sur la base de ce qui précède, nous espérons que le lecteur sera en mesure de mieux comprendre les résultats des tests Anandtech obtenus lors du lancement de Sandy Bridge.
Pont de sable: extrémité avant
L'architecture du processeur Sandy Bridge semble évolutive en un coup d'œil, mais elle est révolutionnaire en termes de nombre de transistors qui ont changé depuis Nehalem / Westmere. Le changement le plus important pour Sandy Bridge (et toutes les microarchitectures après) est le cache micro-opérationnel (cache uOp).

Un cache micro-opérationnel est apparu dans Sandy Bridge, qui met en cache les instructions après les avoir décodées. Il n'y a pas d'algorithme compliqué, les instructions décodées sont simplement enregistrées. Lorsque le préfet Sandy Bridge reçoit une nouvelle instruction, l'instruction est d'abord recherchée dans le cache de micro-opération, et si elle est trouvée, le reste du pipeline fonctionne avec le cache et le frontend est désactivé. Le décodage du matériel est une partie très complexe du pipeline x86, et sa désactivation permet d'économiser une quantité importante d'énergie.
Il s'agit d'un cache de mappage direct et peut stocker environ 1,5 Ko de micro-opérations, ce qui équivaut en fait à un cache d'instructions de 6 Ko. Le cache de micro-opération est inclus dans le cache d'instructions L1 et son taux de réussite pour la plupart des applications atteint 80%. Le cache de micro-opération a une bande passante légèrement plus élevée et plus stable par rapport au cache d'instructions. Les caches d'instructions et de données L1 réels n'ont pas changé; ils sont toujours de 32 Ko chacun (un total de 64 Ko L1).
Toutes les instructions provenant du décodeur peuvent être mises en cache par ce mécanisme, et, comme je l'ai déjà dit, il contient des algorithmes spéciaux - simplement, toutes les instructions sont mises en cache. Les données longtemps inutilisées sont supprimées lorsque le lieu est épuisé. Le cache micro-opérationnel peut sembler similaire au cache de trace dans Pentium 4, mais avec une différence significative: il ne cache pas les traces. Il s'agit simplement d'un cache d'instructions qui stocke des micro-opérations au lieu de macro-opérations (instructions x86).
Parallèlement au nouveau cache micro-opérationnel, Intel a également introduit un module de prédiction de branche entièrement repensé. Le nouveau BPU est à peu près le même que son prédécesseur, mais beaucoup plus précis. Une précision accrue est le résultat de trois innovations majeures.
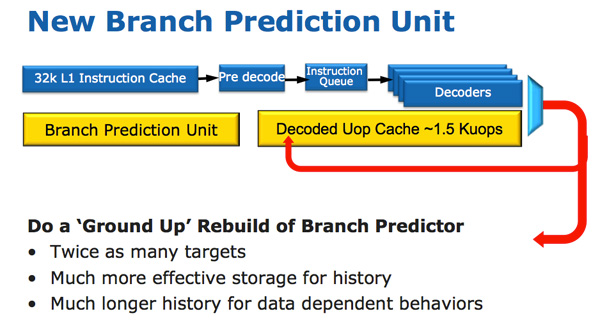
Le prédicteur de branche standard est un prédicteur 2 bits. Chaque branche est marquée dans le tableau comme acceptée / non acceptée avec une fiabilité appropriée (forte / faible). Intel a constaté que presque toutes les branches prédites par ce prédicteur bimodal ont une confiance «élevée». Par conséquent, dans le Sandy Bridge, un prédicteur de branche bimodal utilise un bit de confiance pour plusieurs branches, plutôt qu'un bit de confiance pour chaque branche. Par conséquent, votre table d'historique de branche aura le même nombre de bits représentant beaucoup plus de branches, ce qui conduira à des prévisions plus précises à l'avenir.
Sandy Bridge: près du cœur
Avec la croissance des processeurs multicœurs, la gestion du flux de données entre les cœurs et la mémoire est devenue un sujet important. Nous avons vu de nombreuses façons différentes de déplacer des données autour du CPU, telles que la barre transversale, l'anneau, le maillage et, plus tard, des puces d'E / S complètement séparées. La bataille de la prochaine décennie (2020+), comme mentionné précédemment par AnandTech, sera une bataille de connexions internucléaires, et maintenant elle commence déjà.
Une caractéristique de Sandy Bridge est précisément qu'il s'agissait du premier processeur grand public d'Intel, qui utilisait un bus en anneau reliant tous les cœurs, la mémoire, le cache de dernier niveau et les graphiques intégrés. C'est toujours le même design que nous voyons dans les processeurs Coffee Lake modernes.
Pneu anneau
Nehalem / Westmery Bridge ajoute un processeur graphique et un moteur de transcodage vidéo à la puce qui partage le cache L3. Et au lieu de poser plus de fils au L3, Intel a introduit le bus en anneau.
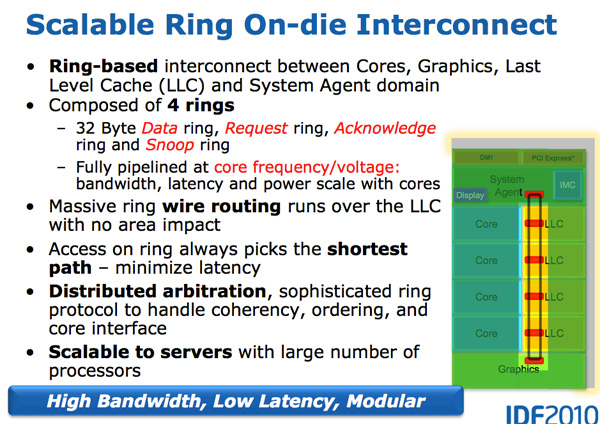
Sur le plan architectural, il s'agit du même bus circulaire utilisé dans Nehalem EX et Westmere EX. Chaque cœur, chaque fragment du cache L3 (LLC), le processeur graphique intégré, le moteur multimédia et l'agent système (un drôle de nom pour le pont nord) sont connectés au bus en anneau. : , , . 32 . .
L3, Westmere — 96 /. Sandy Bridge 4 , Westmere, , 384 /.
, L3 36 Westmere 26 — 31 Sandy Bridge ( , , ). , Westmere, - L3 — un-Core , Intel « », - L3. ( «un-Core» .)
- L3, , . , L3 , . L3, , L3 , . .
L3 , . Sandy Bridge L3, . , . Westmere , , Sandy Bridge . , . , , . , «», .
- Intel un-core SB, Sandy Bridge « ». (-, un-core , - ). . 16 PCIe 2.0, x8. DDR3, , , Lynnfield (Clarkdale ).
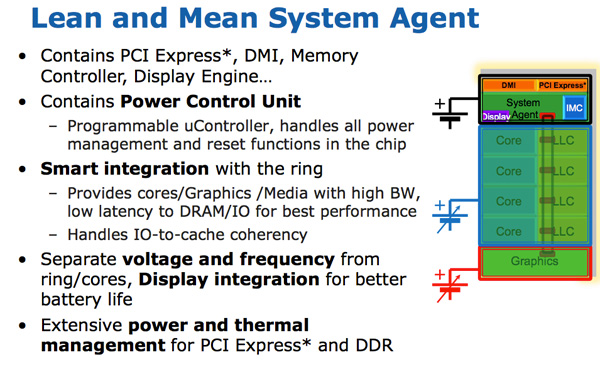
DMI, PCU ( ). SA , , .
Sandy Bridge
Sandy Bridge Westmere . 10-30%, Sandy Bridge , Intel Westmere (Clarkdale / Arrandale). 45 32 , IPC.
Sandy Bridge 32- , . . GPU . , .
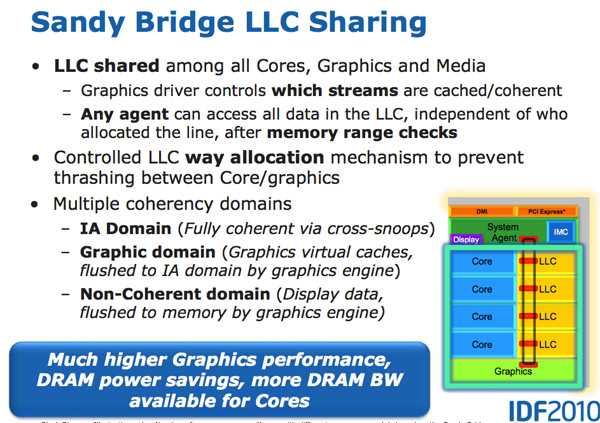
GPU Sandy Bridge, - L3. , L3, , . , , , . .
SNB ( Gen 6) . : , , . – , , .
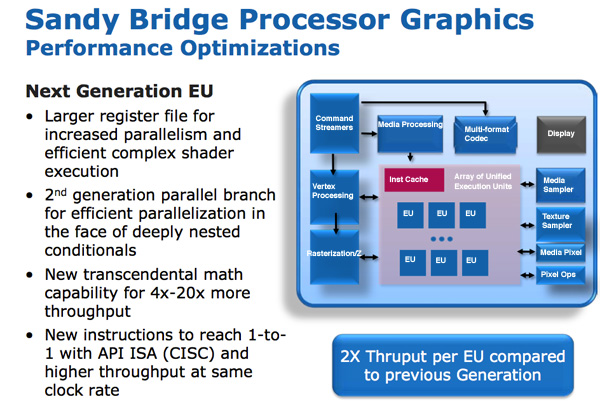
/ / (execution units), Intel EU. EU . ISA -- API DirectX 10, CISC- . - API IPC EU.
EU . EU, . Intel , , Westmere.
Intel « ». , . , , . , . Intel 64 80, , , 120 Sandy Bridge. - .

, EU.
GPU Sandy Bridge: 6 EU 12 EU. ( ) 12 EU, SKU 6 12 . Sandy Bridge Intel, , Intel , GPU. (2019 .) 24 EU (Gen 9.5), 10- ~ 64 EU (Gen11).
Sandy Bridge Media Engine
GPU Sandy Bridge -. SNB : .
: . Intel SNB, EU. Intel , SNB HD-.
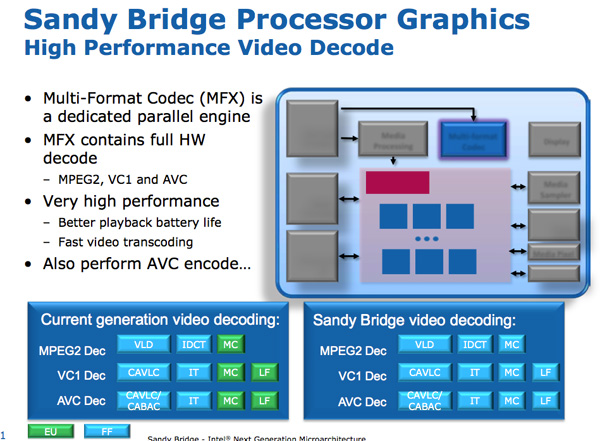
Sandy Bridge. Intel ~ 3- 1080p 30 / iPhone 640 x 360. 14 400 .
/ . Sandy Bridge 3 2 / .
,
Lynnfield Intel, . , TDP 95 , , , -.
, - . , , — , .
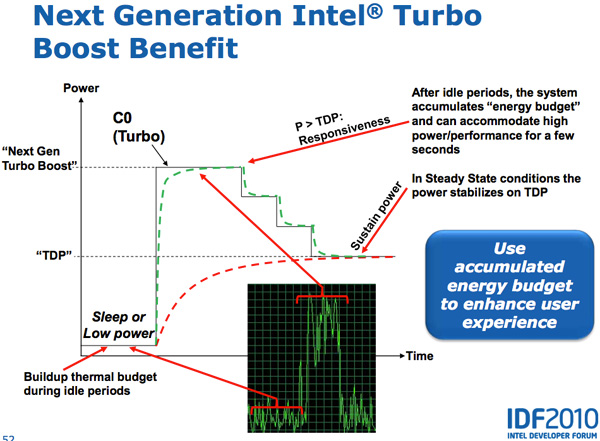
Sandy Bridge , PCU TDP ( 25 ). PCU , . , , TDP. , , TDP, , , TDP. SNB TDP, PCU .

CPU, GPU Turbo . , GPU, SNB, CPU, GPU. , CPU, GPU CPU. Sandy Bridge , , .
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en le recommandant à vos amis, une
réduction de 30% pour les utilisateurs Habr sur un analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbps à partir de 20 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
Dell R730xd 2 fois moins cher? Nous avons seulement
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV à partir de 199 $ aux Pays-Bas! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - à partir de 99 $! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?