Dans une véritable implémentation ML, l'apprentissage lui-même prend un quart de l'effort. Les trois quarts restants sont la préparation des données par la douleur et la bureaucratie, un déploiement complexe souvent en boucle fermée sans accès à Internet, la configuration de l'infrastructure, les tests et la surveillance. Documents sur des centaines de feuilles, mode manuel, conflits de version de modèle, open source et entreprise sévère - tout cela attend un data scientist. Mais il n'est pas intéressé par de tels problèmes opérationnels «ennuyeux», il veut développer un algorithme, atteindre une haute qualité, redonner et ne plus se souvenir.
Peut-être, quelque part ML est implémenté plus facilement, plus simplement, plus rapidement et avec un seul bouton, mais nous n'avons pas vu de tels exemples. Tout ce qui précède est l’expérience de Front Tier en fintech et en télécommunications. Sergey Vinogradov, expert en architecture de systèmes fortement chargés, en grands stockages et en analyse de données lourdes, a parlé de lui à
HighLoad ++ .

Cycle de vie du modèle
Habituellement, le cycle de vie dans notre domaine comprend trois parties. Dans le premier
, une tâche vient de l'entreprise . Dans le second, un
ingénieur de données et / ou un scientifique des données préparent des données , construisent un modèle. Dans la troisième partie, le
chaos commence. Dans les deux derniers, différentes situations intéressantes se produisent.
Jack de tous les métiers
La première situation fréquente est qu'un data scientist ou data engineer a accès aux produits, alors ils lui disent: "Tu as fait tout ça, tu paries."
Une personne prend un
bloc-notes Jupyter ou un ensemble de blocs-notes, les considère exclusivement comme un artefact de déploiement et commence à se répliquer avec joie sur certains serveurs.
Tout semble aller bien, mais pas toujours. Je te dirai plus tard pourquoi.
Exploitation impitoyable
La deuxième histoire est plus complexe et se produit généralement dans les entreprises où l'exploitation a atteint un état de folie légère. Le data scientist met sa solution en service. Ils ouvrent cette boîte noire et voient quelque chose de terrible:
- cahiers
- cornichon de différentes versions;
- tas de scripts: il n'est pas clair où et quand les exécuter, où enregistrer les données qu'ils génèrent.
Dans ce puzzle, l'exploitation rencontre l'incompatibilité de version. Par exemple, un data scientist n'a pas spécifié de version spécifique de la bibliothèque et l'opération a pris la dernière version. Après un certain temps, le data scientist recourt:
- Vous définissez scikit-learn sur la mauvaise version, maintenant toutes les mesures ont disparu! Besoin de revenir à la version précédente.Cela casse complètement la prod et l'exploitation en souffre.
Bureaucratie
Dans les entreprises avec des logos verts, lorsque le Data Scientist entre en service et apporte le modèle, il reçoit généralement un document de 800 feuilles en réponse: «Suivez ces instructions, sinon votre produit ne verra jamais le jour».
Le triste scientifique des données part, jette tout à mi-chemin, puis quitte - il n'est pas intéressé à faire cela.
Déployer
Supposons qu'un data scientist ait parcouru tous les cercles et finalement tout a été déployé. Mais il ne pourra pas comprendre que tout fonctionne comme il se doit. D'après mon expérience, dans les mêmes banques bénies, il n'y a pas de surveillance des produits de science des données.
C'est bien si le spécialiste écrit les résultats de son travail dans la base de données. Au bout d'un moment, il les recevra et verra ce qui se passe à l'intérieur. Mais cela ne se produit pas toujours. Lorsqu'une entreprise et un data scientist croient simplement que tout fonctionne correctement et à merveille, cela se traduit par des cas infructueux.
MFI
D'une manière ou d'une autre, nous avons développé un moteur de notation pour une grande organisation de microfinance. Ils ne les ont pas laissés aller au prod, mais ont simplement pris une cascade de modèles de nous, l'ont installé et l'ont lancé. Les résultats des tests des modèles les ont satisfaits. Mais après 6 mois, ils sont revenus:
- C'est tout mauvais. Les affaires ne vont pas, nous allons de pire en pire. Il semble que les modèles soient excellents, mais les résultats baissent, les fraudes et les défauts de plus en plus, et moins d'argent. Pourquoi t'avons-nous payé? Faisons les choses correctement.De plus, l'accès au modèle n'est à nouveau pas donné. Les journaux ont été déchargés pendant un mois, d'ailleurs, il y a six mois. Nous avons étudié le déchargement pendant un autre mois et sommes arrivés à la conclusion qu'à un moment donné, le service informatique de l'IMF a modifié les données d'entrée et qu'au lieu de documents en json, ils ont commencé à envoyer des documents en xml. Le modèle attendait json, mais a reçu xml, était triste et pensait qu'il n'y avait pas de données à l'entrée.
S'il n'y a pas de données, alors l'évaluation de ce qui se passe est différente. Sans surveillance, cela ne peut pas être détecté.
Nouvelle version, cascade et tests
Souvent, nous sommes confrontés au fait que le modèle fonctionne bien, mais pour une raison quelconque, une
nouvelle version a été développée. Le modèle doit à nouveau être introduit d'une manière ou d'une autre, et à nouveau parcourir tous les cercles de l'enfer. C'est bien si les versions de la bibliothèque sont les mêmes que dans le modèle précédent, et sinon, le déploiement recommence ...
Parfois, avant de mettre une nouvelle version au combat, nous voulons la
tester - mettez-la sur la prod, regardez le même flux de trafic, assurez-vous qu'elle est bonne. Il s'agit là encore de la chaîne de déploiement complète. De plus, nous avons mis en place les systèmes de sorte que selon ce modèle, les résultats réels ne se produisent pas, si nous parlons de notation, mais il n'y avait que le suivi et l'analyse des résultats pour une analyse plus approfondie.
Il existe des situations où une
cascade de modèles est utilisée. Lorsque les résultats des modèles suivants dépendent des précédents, vous devez d'une manière ou d'une autre établir une interaction entre eux et quelque part, tout cela devrait être enregistré.
Comment résoudre de tels problèmes?
Souvent, une personne résout les problèmes
manuellement , en particulier dans les petites entreprises. Il sait comment tout fonctionne, garde à l'esprit toutes les versions des modèles et des bibliothèques, sait où et quels scripts fonctionnent, quelles vitrines ils construisent. Tout cela est merveilleux. Les histoires que le mode manuel laisse derrière elles sont particulièrement belles.
L'histoire de l'héritage . Un homme bon travaillait dans une petite banque. Une fois, il est allé dans un pays du sud et n'est pas revenu. Après cela, nous avons obtenu un héritage: un tas de code qui génère des vitrines sur lesquelles les modèles de modèles fonctionnent. Le code est beau, il fonctionne, mais nous ne connaissons pas la version exacte du script qui génère telle ou telle vitrine. Dans la bataille, toutes les vitrines sont présentes et toutes sont lancées. Nous avons passé deux mois à essayer de distinguer cet enchevêtrement complexe et de le structurer en quelque sorte.
Dans une entreprise difficile, les gens ne veulent pas se soucier de toutes sortes de Python, Jupiters, etc. Ils disent:
- Achetons IBM SPSS, installons et tout ira bien. Les problèmes de versionnage, de sources de données et de déploiement y ont été résolus.Cette approche a le droit d'exister, mais tout le monde ne peut pas se le permettre. Dans tous les cas, il s'agit d'une telle aiguille dentelée de haute qualité. Ils sont assis dessus, mais ça ne marche pas pour descendre - des encoches. Et cela coûte généralement beaucoup.
L'Open Source est l' opposé de l'approche précédente. Les développeurs ont surfé sur Internet, ont trouvé de nombreuses solutions Open Source qui résolvent leurs tâches à des degrés divers. C'est un excellent moyen, mais pour nous, nous n'avons pas trouvé de solutions qui satisferaient à 100% nos exigences.
Par conséquent, nous avons choisi l'option classique -
notre décision . Ses béquilles, ses vélos, tous les leurs, natifs.
Que voulons-nous de notre décision?
N'écrivez pas tout vous-même . Nous voulons prendre des composants, en particulier des infrastructures, qui ont fait leurs preuves et qui connaissent bien le fonctionnement des institutions avec lesquelles nous travaillons. Nous venons d'écrire un environnement qui isolera facilement le travail du data scientist du travail de DevOps.
Traitez les données en deux modes: en mode batch - Batch et en temps réel . Nos tâches incluent les deux modes de fonctionnement.
Facilité de déploiement et dans un périmètre fermé . Lorsque vous travaillez avec des données privées sensibles, il n'y a pas de connexion Internet. À ce stade, tout doit arriver rapidement et avec précision à la production. Par conséquent, nous avons commencé à regarder vers Gitlab, le pipeline CI / CD à l'intérieur et Docker.
Un modèle n'est pas une fin en soi. Nous ne résolvons pas le problème de la construction d'un modèle, nous résolvons un problème commercial.
À l'intérieur du pipeline, il doit y avoir des règles et une conglomération de modèles avec prise en charge de la
gestion des
versions de tous les composants du pipeline.
Qu'entend-on par pipeline? En Russie, la loi fédérale 115 sur la lutte contre le blanchiment d'argent et le financement du terrorisme est en vigueur. Seule la table des matières des recommandations de la Banque centrale occupe 16 écrans. Ce sont des règles simples qu'une banque peut respecter si elle dispose de telles données, ou ne peut pas le faire si elle n'a pas de données.
L'évaluation d'un emprunteur, d'une transaction financière ou d'un autre processus opérationnel est un flux de données que nous traitons. Un flux doit passer par ce type de règle. Ces règles sont décrites de manière simple par l'analyste. Ce n'est pas un scientifique des données, mais il connaît bien la loi ou d'autres instructions. L'analyste s'assoit et, en langage clair, décrit les vérifications des données.
Construisez des cascades de modèles . Souvent, une situation se présente lorsque le modèle suivant utilise pour son travail les valeurs obtenues dans les modèles précédents.
Testez rapidement les hypothèses. Je répète la thèse précédente: un scientifique des données a fait une sorte de modèle, il tourne au combat et fonctionne bien. Pour une raison quelconque, le spécialiste a trouvé une meilleure solution, mais ne veut pas ruiner le flux de travail établi. Le data scientist suspend un nouveau modèle sur le même trafic de combat dans le système de combat. Elle ne participe pas directement à la prise de décision, mais sert le même trafic, considère certaines conclusions et ces conclusions sont stockées quelque part.
Fonction de réutilisation facile. De nombreuses tâches ont le même type de composants, en particulier celles liées à l'extraction de fonctionnalités ou de règles. Nous voulons faire glisser ces composants dans d'autres pipelines.
Qu'avez-vous décidé de faire?
Nous voulons d'abord une surveillance. Et deux du genre.
Suivi
Suivi technique. Si des composants de pipeline sont déployés, en fonctionnement, ils devraient voir ce qui arrive au composant: comment il consomme de la mémoire, du processeur, du disque.
Suivi des affaires. Il s'agit d'un outil de data scientist qui vous permet de faire abstraction des nuances techniques de la mise en œuvre. Au niveau de la conception, la construction permet de déterminer les métriques de modèle qui doivent être disponibles dans la surveillance, par exemple, la distribution des fonctionnalités ou les résultats du service de notation.
Un data scientist définit des métriques et ne doit pas se soucier de la manière dont elles entrent dans le système de surveillance. La seule chose importante est qu'il a défini ces métriques et l'apparence du tableau de bord sur lequel les métriques seront affichées. Ensuite, le spécialiste a tout lancé sur la production, déployé, et après un certain temps, les mesures ont été versées dans la surveillance. Ainsi, un data scientist sans accès au produit peut voir ce qui se passe à l'intérieur du modèle.
Test
Testez la
cohérence du
pipeline . Compte tenu des spécificités du pipeline, il s'agit d'une sorte de graphe informatique. Nous voulons comprendre que nous mettons en œuvre un graphique, nous pouvons le contourner et trouver un moyen de s'en sortir.
Le graphique a des composants - modules. Tous les modules doivent réussir les tests unitaires et d'intégration. Le processus doit être transparent et facile pour un scientifique des données.
Le développeur décrit le modèle et teste seul ou avec l'aide de quelqu'un d'autre. Met tout dans Gitlab, le pipeline configuré par l'intégration continue soulève, teste, voit les résultats. Si tout va bien - ça va plus loin, non - ça recommence.
Le data scientist se concentre sur le modèle et ne sait pas ce qu'il y a sous le capot. Pour cela, on lui donne plusieurs choses.
- Une API pour l'intégration avec le cœur du système lui-même via le bus de données - bus de messages. Dans ce cas, le spécialiste doit décrire ce qui entre et ce qui sort de son modèle, le point d'entrée et la jonction avec différents composants à l'intérieur du pipeline.
- Après avoir entraîné le modèle, un artefact apparaît - un fichier XGBoost ou pickle . Le data scientist a un exécuteur pour travailler avec les artefacts - il doit intégrer les composants du pipeline à l'intérieur.
- API simple et transparente pour le scientifique des données pour surveiller le fonctionnement des composants du pipeline - surveillance technique et commerciale.
- Une infrastructure simple et transparente pour l'intégration avec les sources de données et la préservation des résultats de travail.
Souvent, les modèles fonctionnent pour nous, et après un certain temps arrive un audit qui veut retracer toute l'histoire du service. L'audit veut vérifier l'exactitude des travaux, l'absence de fraude de notre part. Des outils simples sont nécessaires pour que tout auditeur connaissant SQL puisse accéder à un référentiel spécial et voir comment tout a fonctionné, quelles décisions ont été prises et pourquoi.
Nous avons jeté les bases de deux histoires importantes pour nous.
Parcours client. C'est l'occasion d'utiliser les mécanismes de préservation de l'historique complet du client - ce qui est arrivé au client dans le cadre des processus métier mis en œuvre sur ce système.
Nous pouvons avoir des sources de données externes, par exemple, des plates-formes DMP. Nous obtenons d'eux des informations sur le comportement humain sur le réseau et sur les appareils mobiles. Cela peut avoir un effet sur le LTV et les modèles de score de son modèle. Si l'emprunteur est en retard de paiement, nous pouvons prédire qu'il ne s'agit pas d'une intention malveillante - il y a simplement des problèmes. Dans ce cas, nous appliquons des méthodes douces d'exposition à l'emprunteur. Lorsque les problèmes sont résolus, le client clôturera le prêt. Quand il viendra la prochaine fois, nous connaîtrons toute son histoire. Le scientifique des données obtiendra un historique visuel du modèle et effectuera la notation en mode lumière.
Identification des anomalies . Nous sommes constamment confrontés à un monde très complexe. Par exemple, les points faibles de l'évaluation accélérée des IMF peuvent être une source de fraude automatique.
Customer Journey est un concept d'accès rapide et facile au flux de données qui traverse le modèle. Le modèle permet de détecter facilement les anomalies caractéristiques de la fraude au moment de son apparition massive.
Comment tout est-il arrangé?
Sans hésitation, nous avons pris
Kafka comme un patch Message Bus. C'est une bonne solution qui est utilisée par beaucoup de nos clients, l'opération est en mesure de travailler avec elle.
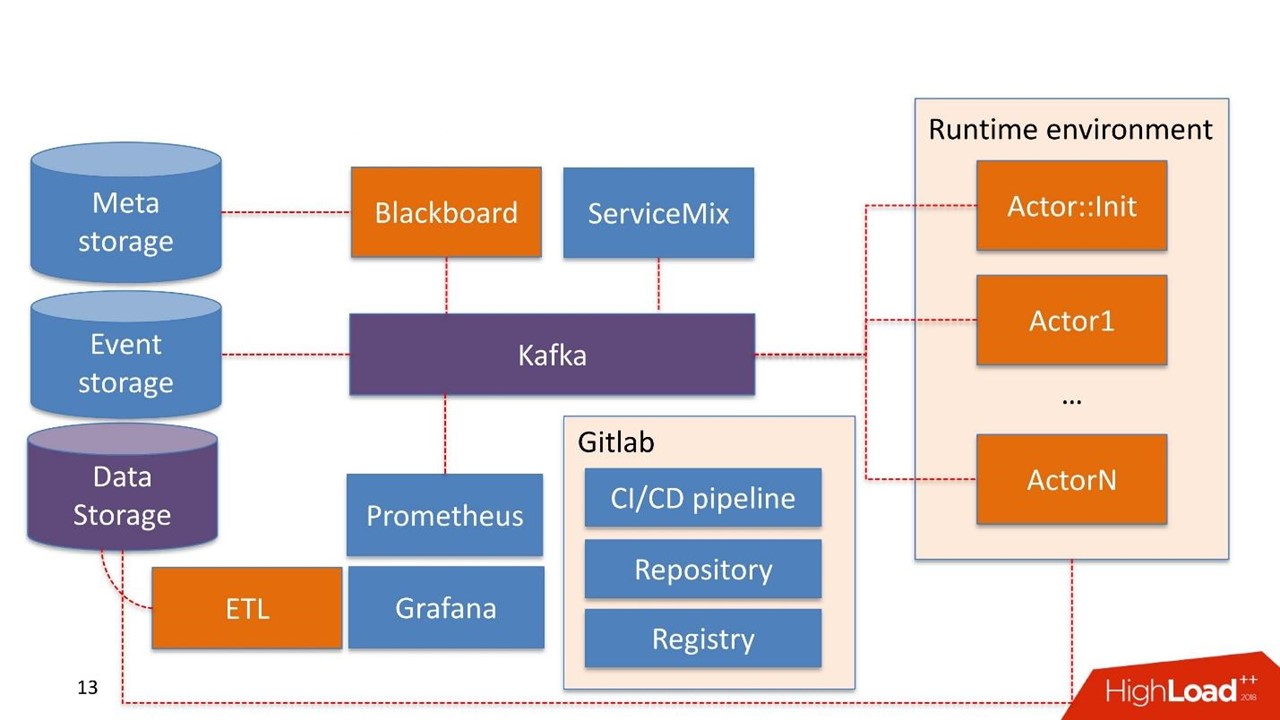
Certains composants du système peuvent déjà être utilisés dans l'entreprise elle-même. Nous ne reconstruisons pas le système, mais réutilisons ce qu'ils ont déjà.
Le stockage de données dans ce cas est le stockage que le client possède généralement déjà. Il peut s'agir de bases de données Hadoop, relationnelles et non relationnelles. Nous pouvons travailler nativement hors de la boîte avec HDFS, Hive, Impala, Greenplum et PostgreSQL. Nous considérons ces stockages comme une source de vitrines.
Les données arrivent à l'entrepôt, transitent par notre ETL ou l'ETL du client, s'il en a un. Nous construisons des vitrines qui sont davantage utilisées à l'intérieur des modèles. Le stockage des données est utilisé en mode lecture seule.
Nos développements
Tableau noir Le nom est tiré d'une pratique assez étrange des mathématiciens des années 30-40. Il s'agit du gestionnaire des pipelines qui vivent dans le système d'administration. Blackboard a une sorte de méta-stockage. Il stocke les pipelines eux-mêmes et les configurations nécessaires pour initialiser tous les composants.
Tout le travail sur le système commence par le Blackboard. Par miracle, le pipeline s'est retrouvé dans Meta Storage, Blackboard après un certain temps comprend cela, sort la version actuelle du pipeline, l'initialise et envoie un signal à l'intérieur de Kafka.
Il existe un
environnement d'exécution . Il est construit sur Dockers et peut être répliqué sur des serveurs, y compris dans le cloud privé du client.
De la boîte vient le principal
Actor :: Init - c'est l'initialiseur. C'est un génie qui ne peut faire que deux choses:
construire et
détruire des composants . Il reçoit une commande de Blackboard: "Voici le pipeline, il faut le lancer sur tel ou tel serveur avec telle ou telle ressource en telle ou telle quantité - ça marche!" Ensuite, l'acteur commence tout.
Mathématiquement, un acteur est une fonction qui prend un ou plusieurs objets en entrée, à l'intérieur il modifie l'état des objets selon un algorithme, à la sortie il crée un nouvel objet ou change l'état d'un existant.
Techniquement, un acteur est un programme Python. S'exécute dans un conteneur Docker avec son environnement.
L'acteur ne connaît pas l'existence d'autres acteurs. La seule entité qui sait qu'en plus de l'acteur existe l'ensemble du pipeline dans son ensemble - c'est Blackboard. Il surveille l'état d'exécution de tous les acteurs du système et maintient l'état actuel, qui s'exprime dans la surveillance comme une image de l'ensemble du processus métier dans son ensemble.
Actor :: Init génère de nombreux conteneurs Docker. De plus, les acteurs peuvent travailler avec le stockage de données.
Le système lui-même possède un composant de
stockage d'événements . En tant que stockage d'événements, nous utilisons
ClickHouse . Sa tâche est simple: toutes les informations échangées entre l'acteur via Kafka sont stockées dans ClickHouse. Ceci est fait
pour un audit supplémentaire . Il s'agit du journal des opérations du pipeline.
Des acteurs peuvent également être développés pour le
parcours client . Ils voient les modifications dans le journal du pipeline et peuvent reconstruire à la volée les fenêtres nécessaires pour que les modèles ou les composants fonctionnent avec les règles, déjà à l'intérieur du pipeline. Il s'agit d'un processus continu de modification des données.
La surveillance est plutôt basée primitivement sur
Prométhée . L'acteur reçoit une API de base, et en mode fermé, mais suffisamment transparent pour le développeur, il envoie des messages avec des métriques à Kafka. Prometheus lit les métriques de Kafka et les enregistre dans son référentiel.
Pour la visualisation, nous utilisons
Grafana .
Deux points d'intégration
Le premier est le point d'intégration avec les sources de données qui passent par des ETL à l'entrepôt de données. Deuxième point d'intégration lorsqu'un service est déjà utilisé par un consommateur de données, par exemple un service de scoring.
Nous avons pris
Apache ServiceMix. Par expérience, ces points d'intégration sont du même type avec le même type de protocoles: SOAP, RESTful, moins souvent les files d'attente. Chaque fois, nous ne voulons pas développer notre propre constructeur ou service afin de générer le prochain service SOAP. Par conséquent, nous prenons ServiceMix, le décrivons dans le SDL, dans lequel les modèles de données de ce service et les méthodes qui y existent sont construits. Ensuite, nous poussons le routeur à l'intérieur de ServiceMix, et il génère le service lui-même.
De nous-mêmes, nous avons ajouté une conversion synchrone-asynchrone délicate. Toutes les demandes qui vivent à l'intérieur du système sont asynchrones et passent par le bus de messages.
La plupart des services de notation sont synchrones. Les demandes ServiceMix proviennent de REST ou SOAP. À ce stade, il passe par notre passerelle, qui conserve la connaissance de la session HTTP. Ensuite, il envoie un message à Kafka, il passe par un pipeline et une solution est générée.
Cependant, il n'y a peut-être toujours pas de solution. Par exemple, quelque chose est tombé, ou il y a un SLA difficile à prendre, et Gateway surveille: «OK, j'ai reçu une demande, il est venu vers moi dans un autre sujet Kafka, ou rien ne m'est venu, mais mon déclencheur de délai d'attente a fonctionné.» Là encore, la conversion de synchrone en asynchrone va, et au sein de la même session HTTP, il y a une réponse au consommateur avec le résultat du travail. Cela peut être une erreur ou une prévision normale.
Dans ce lieu, d'ailleurs, nous avons mangé un chien insipide grâce à la grande et puissante Open Source. Nous avons utilisé ServiceMix de l'une des dernières versions et Kafka des versions précédentes et tout fonctionnait parfaitement. Nous avons écrit dans cette passerelle, sur la base de ces cubes qui étaient déjà dans ServiceMix. Lorsque la nouvelle version de Kafka est sortie, nous l'avons heureusement saisie, mais il s'est avéré que le soutien aux headders dans le message à Kafka qui existait auparavant avait changé. La passerelle à l'intérieur de ServiceMix ne peut plus fonctionner avec eux. Pour comprendre cela, nous avons passé beaucoup de temps. En conséquence, nous avons construit notre passerelle, qui peut fonctionner avec de nouvelles versions de Kafka. Nous avons écrit sur le problème aux développeurs de ServiceMix et avons reçu la réponse: "Merci, nous vous aiderons certainement dans les prochaines versions!"
Par conséquent, nous sommes obligés de surveiller les mises à jour et de changer régulièrement quelque chose.
L'infrastructure est Gitlab. Nous utilisons presque tout ce qui s'y trouve.
- Dépôt de code.
- Poursuite de l'intégration / Poursuite du pipeline de livraison.
- Registre pour gérer un registre de conteneurs Docker.
Composants
Nous avons développé 5 composants:
- Tableau noir - gestion du cycle de vie du pipeline. Où, quoi et avec quels paramètres s'exécuter à partir du pipeline.
- L'extracteur de fonctionnalités fonctionne simplement - nous informons l'extracteur de fonctionnalités que nous obtenons tel ou tel modèle de données à l'entrée, sélectionnons les champs nécessaires dans les données, les mappons à certaines valeurs. Par exemple, nous obtenons la date de naissance du client, la convertissons en âge, l'utilisons comme fonctionnalité dans notre modèle. L'extracteur de fonctionnalités est responsable de l'enrichissement des données.
- Moteur basé sur des règles - vérification des données selon les règles. Il s'agit d'un langage de description simple qui permet à une personne familiarisée avec la construction des blocs <code> if, else <code /> de décrire les règles de vérification au sein du système.
- Moteur d'apprentissage automatique - vous permet d'exécuter l'exécuteur, d'initialiser le modèle formé et de le soumettre aux données d'entrée. En sortie, le modèle prend des données.
- Moteur de décision - moteur de décision, sortie du graphique. Ayant une cascade de modèles, par exemple, différentes branches de l'évaluation de l'emprunteur, vous devez décider quelque part de la question de l'argent. L'ensemble de règles pour la solution doit être simple. , LTV- — , , .
. — , . — , .
pipeline .
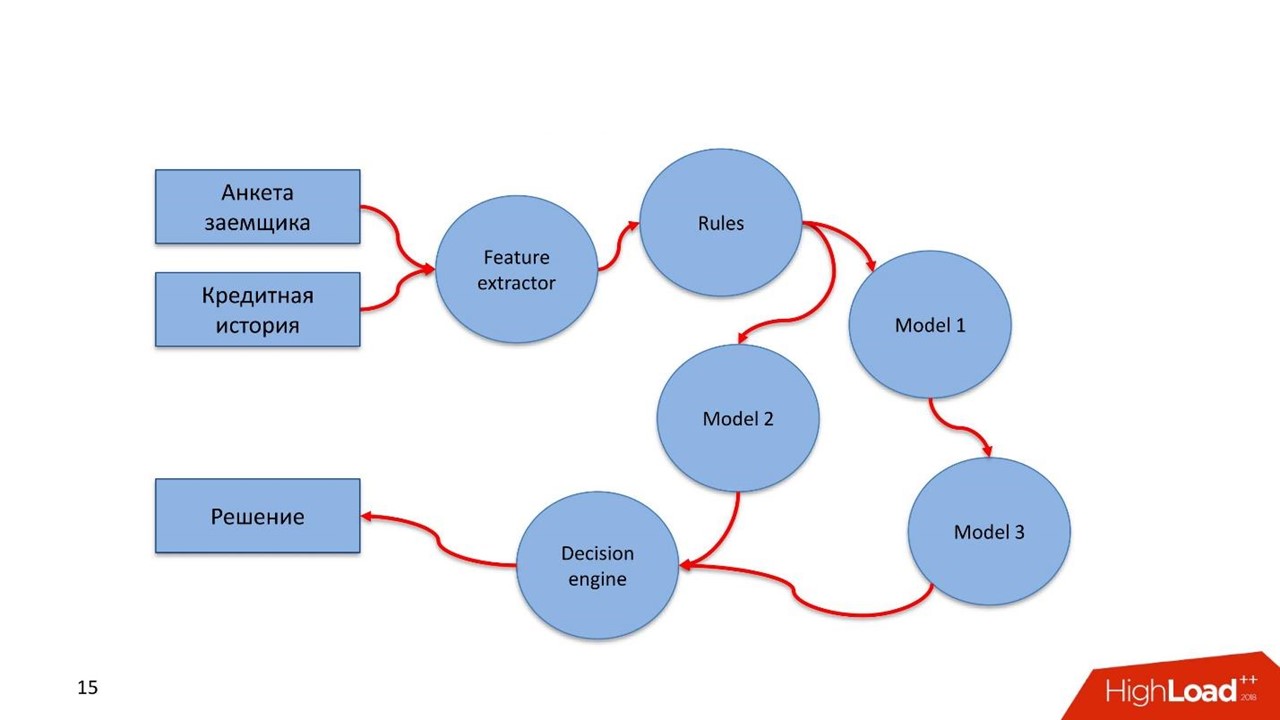
- Feature extractor : , , .
- . , -: , , 18.
- . , . , , pipeline.
- Decision engine . .
- .
yaml. . , , . yaml.
pipeline, , : feature extractor, rules, models, decision engine, . —
Docker- . Registry, Docker-. -, , . , , Docker- .
Pipeline
,
Python — . Feature extractor, , decision engine Python.
Pipeline
yaml. meta storage —
.
Runtime environment 10 , Blackboard , pipeline 10 . , : , , IP- Kafka, , . .
GitLab. Ansible. , . , 50 000 Ansible .
?
GitLab pipeline. GitLab. CI , , , .
GitLab Runner , Docker- , pipeline. — Registry.
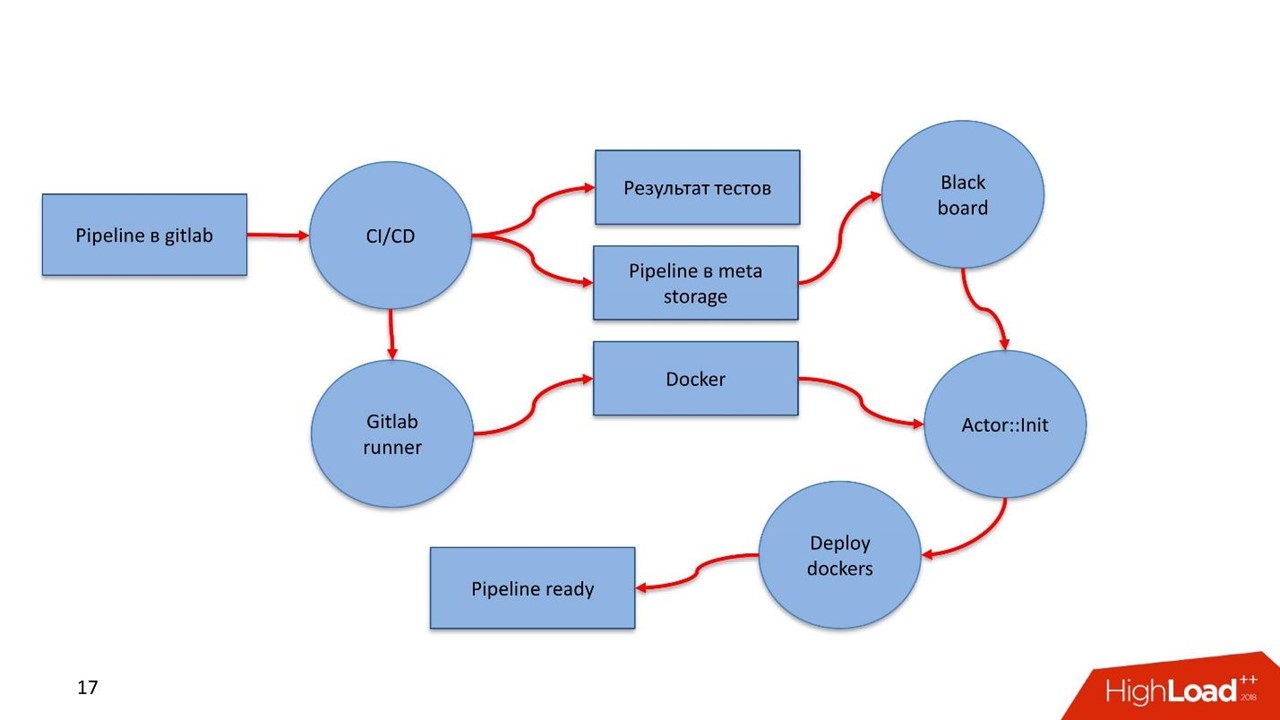
Docker , . Docker- . CI pipeline pipeline - Meta Storage, Blackboard.
Blackboard Meta Storage — , , , -. Docker- , , .
- Blackboard Meta Storage : , Kafka, . , , Docker- , .
, Docker-, — pipeline !
DigitalOcean. AWS Scaleway, .
, . pipeline . , .
?
— . , pipeline, real-time .
- 2 Feature extractor . 1 , .. json .
- 8 — 8 ML engine. XGBoost.
- 18 RB engine (115 ). 1000 .
- 1 decision engine.
200 . 2 Feature extractor, 8 , 18 1 decision engine 1,2 .
Discovery . , - . , , . . Meta Storage.
pipeline . ,
BPM . yaml , , .
. Java, Scala, R. Python, , . API , pipeline .
Quel est le résultat?
— . — .
, . , . — 2018 .
, . — , , .
, . , , notebook , .
, - , , . , , UseData Conf . , , , 16 .