Plus il y a d'utilisateurs de votre service, plus il est probable qu'ils auront besoin d'aide. Le chat du support technique est une solution évidente mais plutôt coûteuse. Mais si vous utilisez la technologie d'apprentissage automatique, vous pouvez économiser de l'argent.
Le bot peut désormais répondre à des questions simples. De plus, le chatbot peut apprendre à déterminer les intentions de l'utilisateur et à capturer le contexte afin qu'il puisse résoudre la plupart des problèmes des utilisateurs sans intervention humaine. Pour ce faire, Vladislav Blinov et Valery Baranova, développeurs de l'assistant populaire Oleg, aideront à le comprendre.
En passant de méthodes simples à des méthodes plus compliquées dans la tâche de développement d'un chat bot, nous analyserons les problèmes pratiques de mise en œuvre et verrons quel gain de qualité vous pouvez obtenir et combien cela coûtera.
Vladislav Blinov est un développeur senior de systèmes de dialogue à
Tinkoff , jette souvent des abréviations: ML, NLP, DL, etc. En outre, l'école doctorale examine la modélisation de l'humour à travers l'apprentissage automatique et les réseaux de neurones.
Valeria Baranova écrit des choses sympas dans le domaine de la PNL en Python depuis plus de 5 ans. Désormais, dans l'équipe de systèmes interactifs, Tinkoff crée des robots de discussion et enseigne un cours de Machine Learning aux étudiants. Il est également engagé dans la recherche dans le domaine de l'humour informatique, c'est-à-dire qu'il enseigne à l'IA à comprendre les blagues et à en proposer de nouvelles - Valeria et Vladislav
en parleront à UseData Conf.
Les services de Tinkoff Bank sont utilisés par des millions de personnes. Pour fournir une assistance 24h / 24 à un tel nombre d'utilisateurs, un personnel important est nécessaire, ce qui entraîne un coût de service élevé. Il semble logique que les questions populaires des utilisateurs puissent être répondues automatiquement à l'aide du chat bot.
Intention ou intention de l'utilisateur
La première chose dont un chatbot a besoin est de comprendre
ce que veut l'utilisateur . Cette tâche est appelée la classification des intentions ou des intentions. De plus, tous les modèles et approches seront examinés dans le cadre de cette tâche.
Regardons un exemple de classification des intentions. Si vous écrivez: «Transférez une centaine de Lera», le chat bot Oleg comprendra que c'est l'intention d'un transfert d'argent, c'est-à-dire l'intention de l'utilisateur de transférer de l'argent. Ou plutôt, que Lera doit transférer le montant de 100 roubles.
Nous comparerons les méthodes et testerons la qualité de leur travail sur un échantillon de test, qui consiste en de vrais dialogues avec les utilisateurs. Notre échantillon contient plus de 30 000 exemples marqués et 170 intentions, par exemple: aller au cinéma, chercher des restaurants, ouvrir ou fermer un dépôt, etc. Oleg a également sa propre opinion sur beaucoup de choses, et il peut simplement discuter avec vous.
Classification du dictionnaire
La chose la plus simple qui puisse être faite dans la tâche de classification des intentions est d'
utiliser un dictionnaire . Par exemple, si le mot «traduire» apparaît dans la phrase d'un utilisateur, considérez qu'un transfert d'argent doit être effectué.
Examinons la qualité d'une approche aussi simple.
Si le classificateur définit simplement l'intention de l'utilisateur comme «transfert d'argent» par le mot «traduire», alors la qualité sera déjà assez élevée. Précision - 88%, tandis que l'exhaustivité est faible, égal à seulement 23%. C'est compréhensible: le mot «traduire» ne décrit pas toutes les possibilités de dire «transférer de l'argent à quelqu'un».
Cependant, cette approche présente des avantages:
- Aucun échantillonnage étiqueté n'est nécessaire (si vous n'étudiez pas le modèle, l'échantillonnage n'est pas nécessaire).
- Vous pouvez obtenir une grande précision si vous compilez bien les dictionnaires (mais cela prendra du temps et des ressources).
Cependant, l'exhaustivité d'une telle solution est susceptible d'être faible, car toutes les variations d'une classe sont difficiles à décrire.
Prenons un contre-exemple. Si, en plus de l'intention de transfert d'argent, «transfert» peut également inclure la deuxième intention - «transfert à l'opérateur». Lorsque nous ajoutons une nouvelle intention de traduction à l'opérateur, nous obtenons des résultats différents.
La précision diminue de 18 points, alors que, bien entendu, l'exhaustivité ne se développe pas. Cela montre qu'une approche plus avancée est nécessaire.
Analyse de texte
Avant d'utiliser l'apprentissage automatique, vous devez comprendre comment présenter du texte en tant que vecteur. L'une des approches les plus simples consiste à
utiliser un vecteur tf-idf .
Le vecteur tf-idf prend en compte l'occurrence de chaque mot dans la phrase de l'utilisateur et prend en compte l'occurrence totale des mots dans la collection. Les mots que l'on retrouve souvent dans différents textes ont moins de poids dans cette représentation vectorielle.
Examinons la qualité du modèle linéaire sur les représentations tf-idf (dans notre cas, régression logistique).
En conséquence,
l'exhaustivité a fortement
augmenté et la précision est restée comparable à l'utilisation du dictionnaire, la mesure f1 (moyenne harmonique pondérée entre l'exactitude et l'exhaustivité) a également augmenté. Autrement dit, le modèle lui-même comprend déjà quels mots sont importants pour quelle intention - vous n'avez pas besoin d'inventer quoi que ce soit vous-même.
Visualisation des données
La visualisation des données aide à comprendre à quoi ressemblent les intentions, à quel point elles sont regroupées dans l'espace. Mais nous ne pouvons pas visualiser directement les représentations tf-idf en raison de la grande dimension, nous allons donc utiliser
la méthode de compression de dimension - t-SNE .
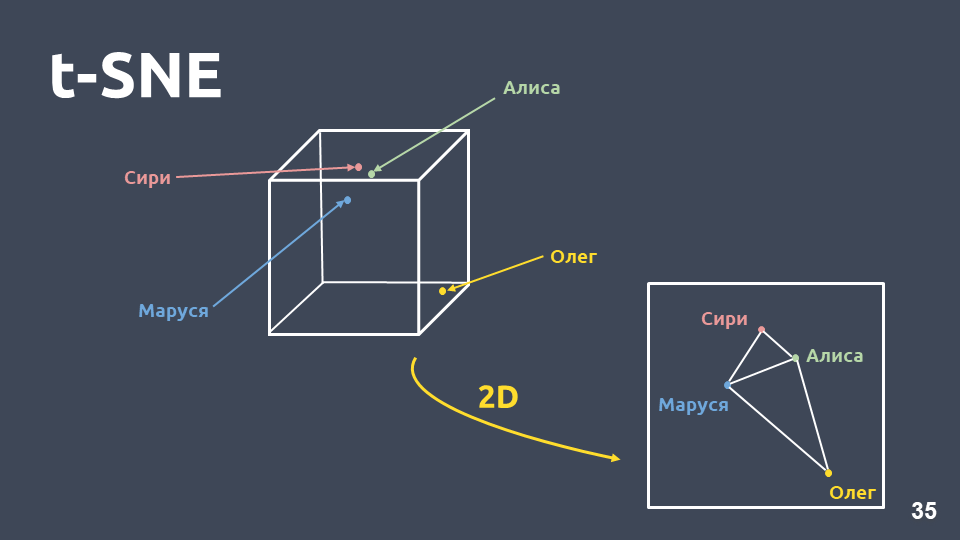
La principale différence entre cette méthode et l'ACP est que lorsqu'elle est transférée dans un espace à deux dimensions, la
distance relative entre les objets est préservée .
t-SNE sur tf-idf (10 meilleures intentions), score F1 0,92Les 10 meilleures intentions par occurrence dans notre collection sont présentées ci-dessus. Il y a des points verts qui n'appartiennent à aucune intention, et 10 grappes qui sont marquées avec des couleurs différentes sont des intentions différentes. On voit que certains d'entre eux sont très bien groupés. La
mesure f1 pondérée
est de 0,92 - c'est beaucoup, vous pouvez déjà travailler avec.
Donc, avec un classificateur linéaire sur tf-idf:
- exhaustivité beaucoup plus élevée que l'utilisation d'un dictionnaire, avec une précision comparable;
- pas besoin de penser quels mots correspondent à quelle intention.
Mais il y a aussi des inconvénients:
- vocabulaire limité, vous ne pouvez obtenir du poids que pour les mots présents dans l'échantillon d'apprentissage;
- la reformulation n'est pas prise en compte;
- l'ordre dans lequel les mots apparaissent dans le texte n'est pas pris en compte.
Reformulation
Examinons plus en détail le problème de la reformulation.
Les vecteurs Tf-idf ne peuvent être proches que pour les textes qui se croisent dans les mots. La proximité entre les vecteurs peut être calculée par le cosinus de l'angle entre eux. La proximité du cosinus dans la représentation vectorielle tf-idf est calculée pour des exemples spécifiques.
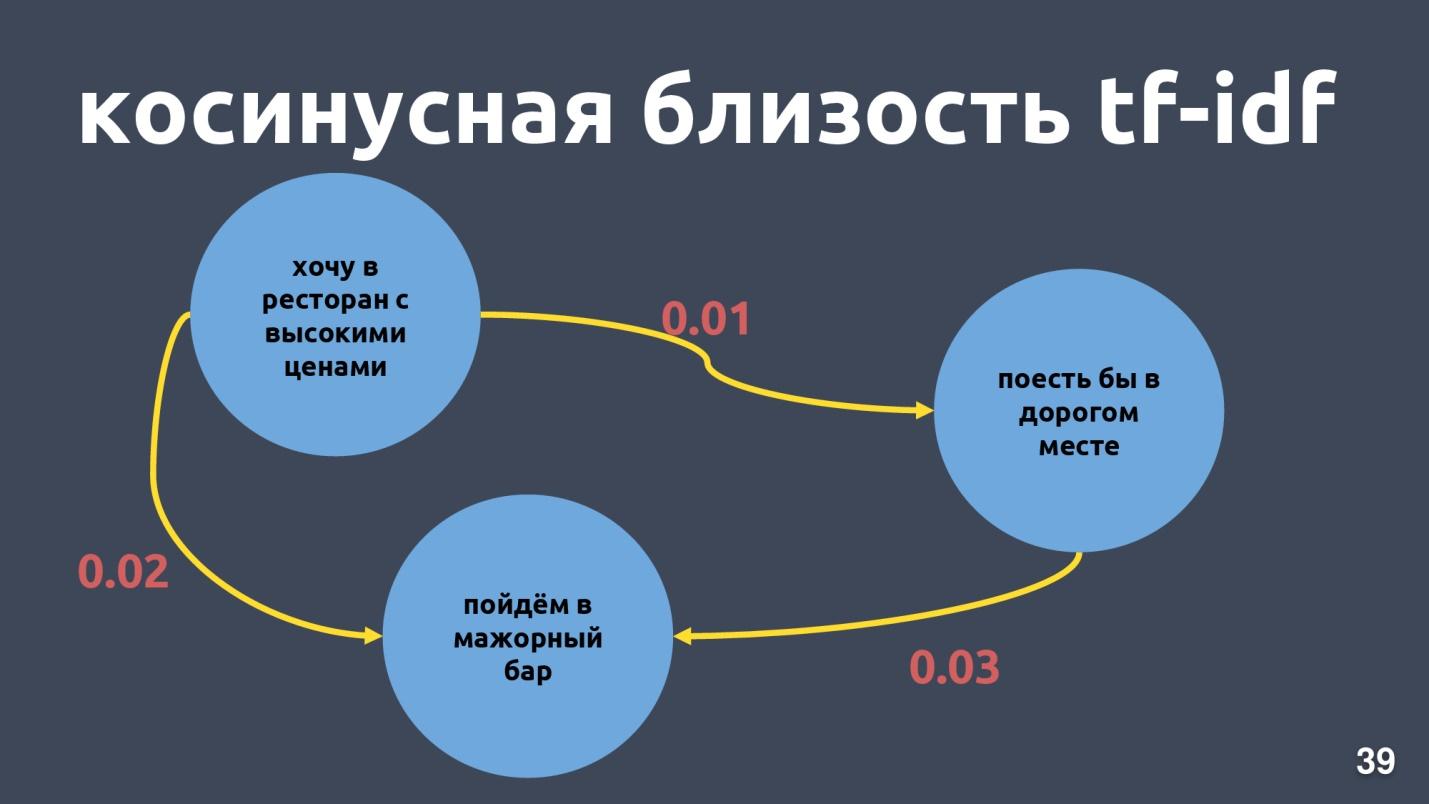
Ce ne sont pas des expressions très proches pour la représentation vectorielle tf-idf, bien que pour nous ce soit la même intention et la même classe.
Que peut-on faire à ce sujet? Par exemple, au lieu d'un nombre, vous pouvez représenter un mot comme un vecteur entier - c'est ce qu'on appelle «l'intégration de mots».
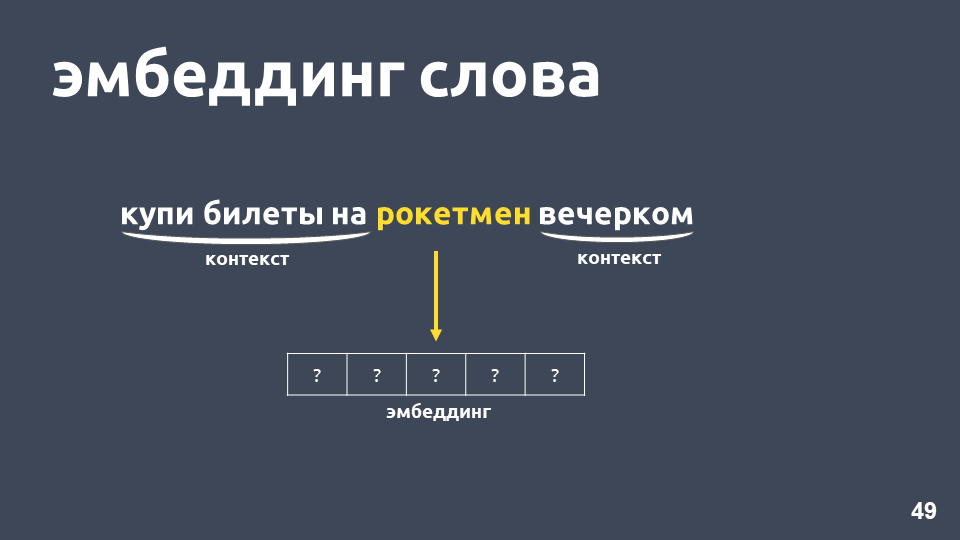
L'un des modèles les plus populaires pour résoudre ce problème a été proposé en 2013. Il s'appelle
word2vec et a été largement utilisé depuis.
L'une des façons d'apprendre Word2vec fonctionne approximativement comme suit: nous prenons le texte, nous prenons un mot du contexte et le jetons, puis nous prenons un autre mot aléatoire du contexte et présentons les deux mots comme des vecteurs uniques. Un vecteur unique est un vecteur selon la dimension du dictionnaire, où seule la coordonnée correspondant à l'index du mot dans le dictionnaire a la valeur 1, le 0 restant.
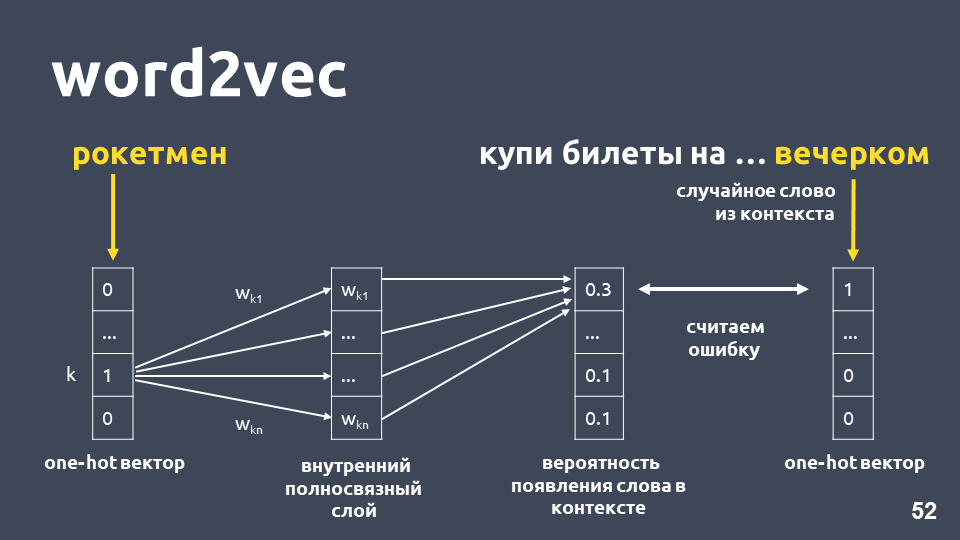
Ensuite, nous formons un réseau neuronal simple couche sans activation sur la couche intérieure pour prédire le mot suivant en contexte, c'est-à-dire pour prédire le mot «le soir» en utilisant le mot «rocketman». En sortie, nous obtenons la distribution de probabilité pour tous les mots du dictionnaire comme suit. Puisque nous savons ce qu'était réellement le mot, nous pouvons calculer l'erreur, mettre à jour les poids, etc.

Les poids mis à jour obtenus à la suite de la formation sur notre échantillon sont le mot intégration.
L'avantage d'utiliser l'incorporation au lieu du nombre est, tout d'abord,
que le contexte est pris en compte . Un exemple populaire: Trump et Poutine sont proches dans word2vec car ils sont tous deux présidents et sont souvent utilisés ensemble dans les textes.
Pour les mots trouvés dans l'exemple d'apprentissage, il vous suffit de prendre la matrice d'intégration, de prendre son vecteur par l'index du mot et d'obtenir l'intégration.
Il semblerait que tout va bien, sauf que certains mots de votre matrice peuvent ne pas l'être, car le modèle ne les a pas vus pendant la formation. Afin de faire face au problème des mots inconnus (hors vocabulaire), ils ont proposé en 2014 une modification de word2vec -
fasttext .
Fasttext fonctionne comme suit: si le mot n'est pas dans le dictionnaire, il est divisé en n-grammes symboliques, pour chaque incorporation de n-gramme est prise à partir de la matrice des plongements de n-grammes (qui sont entraînés comme word2vec), les plongements sont moyennés et un vecteur est obtenu.
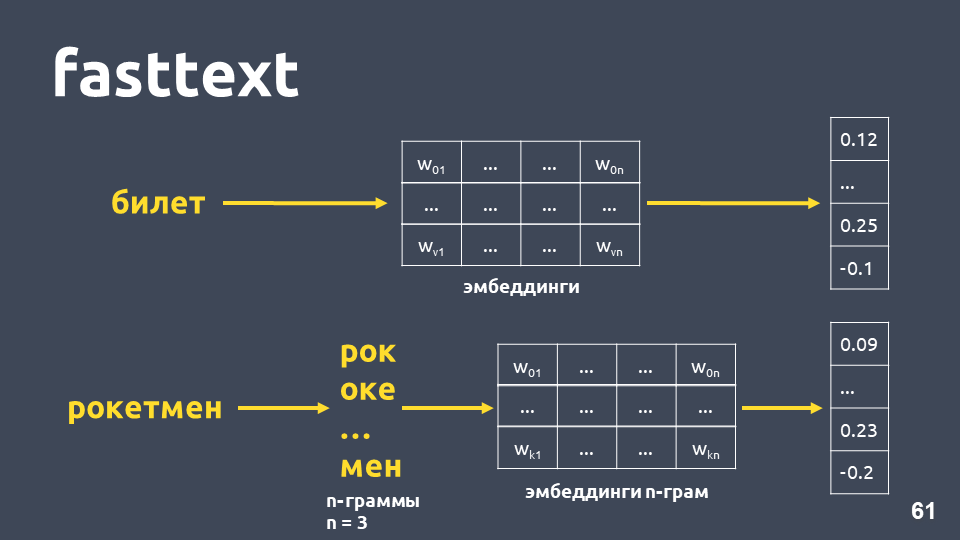
Au total, nous obtenons des vecteurs pour des mots qui ne sont pas dans notre dictionnaire. Maintenant, nous pouvons
calculer la similitude même pour des mots inconnus . Et, ce qui est très important, il existe des modèles formés pour le russe, l'anglais et le chinois, par exemple, Facebook et le projet
DeepPavlov , afin que vous puissiez rapidement l'inclure dans votre pipeline.
Mais les inconvénients demeurent:- Le modèle n'est pas utilisé pour l'ensemble du vecteur texte. Pour obtenir un vecteur de texte commun, vous devez penser à quelque chose: moyen ou moyen avec multiplication par poids idf, et cela peut fonctionner différemment dans différentes tâches.
- Le vecteur d'un mot est toujours un, quel que soit le contexte. Word2vec forme un vecteur de mots pour tout contexte dans lequel le mot apparaît. Pour les mots à valeurs multiples (comme, par exemple, la langue), il y aura un seul et même vecteur.
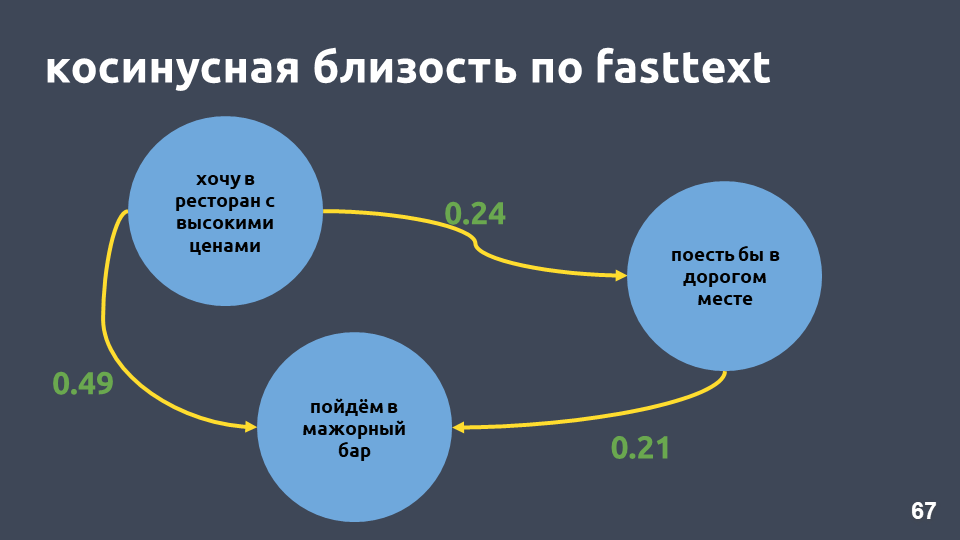
En effet, la proximité de cosinus dans notre exemple en texte rapide est plus élevée que la proximité de cosinus dans tf-idf, même si les phrases de ces phrases ne sont que «in».
t-SNE sur fasttext (top 10 intentions), score F1: 0,86Cependant, lors de la visualisation des résultats de texte rapide sur la décomposition t-SNE, les clusters d'intention se distinguent bien pire que pour tf-idf. La mesure F1 ici est de 0,86 au lieu de 0,92.
Nous avons mené une expérience: combinés vecteurs tf-idf et fasttext. La qualité est absolument la même que lorsque vous utilisez uniquement tf-idf. Ce n'est pas vrai pour toutes les tâches, il y a des problèmes où le tf-idf et le fasttext combinés fonctionnent mieux que juste le tf-idf, ou où le fasttext fonctionne mieux que le tf-idf. Vous devez expérimenter et essayer.
Essayons d'augmenter le nombre d'intentions (rappelons que nous en avons 170). Vous trouverez ci-dessous des grappes pour les 30 premières intentions sur les vecteurs tf-idf.
t-SNE à tf-idf (30 premières intentions), score F1 0, 85 (à 10, il était de 0,92)La qualité chute de 7 points, et maintenant nous ne voyons pas de structure de cluster prononcée.
Regardons des exemples de textes qui ont commencé à se confondre, car plus d'intentions ont été ajoutées qui se croisent sémantiquement et avec des mots.
Par exemple: "Et si vous ouvrez un dépôt, quels sont les intérêts?" »et« Et je veux ouvrir une contribution à 7% ». Expressions très similaires, mais ce sont des intentions différentes. Dans le premier cas, une personne veut connaître les conditions de dépôt, et dans le second cas, ouvrir un dépôt. Pour séparer ces textes en différentes classes, nous avons besoin de quelque chose de plus complexe -
l'apprentissage en profondeur .
Modèle de langage
Nous voulons obtenir un vecteur de texte et, en particulier, un vecteur de mot, qui dépendra du contexte d'utilisation. La méthode standard pour obtenir un tel vecteur consiste à
utiliser des incorporations à partir du modèle de langage .
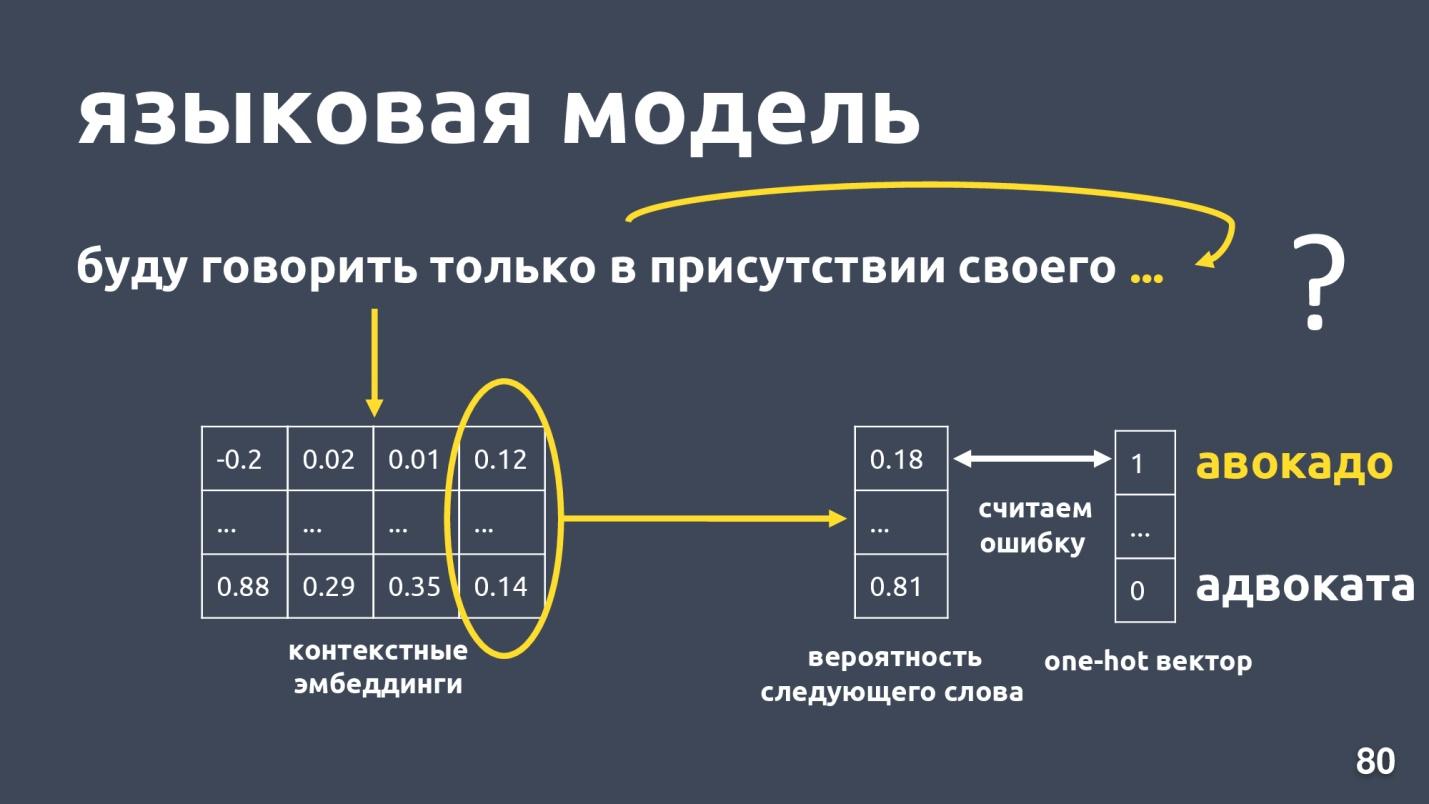
Le modèle de langage résout le problème de la modélisation de langage. Et quelle est cette tâche? Qu'il y ait une séquence de mots, par exemple: «Je ne parlerai qu'en présence des miens ...», et nous essayons de prédire le mot suivant dans la séquence. Le modèle de langage fournit un contexte pour les incorporations. Après avoir obtenu des plongements contextuels et des vecteurs pour chaque mot, on peut prédire la probabilité du mot suivant.
Il existe un vecteur de dimension de dictionnaire et chaque mot se voit attribuer la probabilité d'être le suivant. Nous savons à nouveau quel mot était en réalité, considérons une erreur et formons le modèle.
Il y a pas mal de modèles linguistiques, y a-t-il eu un boom l'année dernière? et de nombreuses architectures différentes ont été proposées. L'un d'eux est
ELMo .
ELMo
L'idée du modèle ELMo est de construire d'abord une incorporation symbolique du mot pour chaque mot dans le texte, puis d'appliquer le
réseau LSTM pour eux de telle manière que les incorporations soient prises en compte qui tiennent compte du contexte dans lequel le mot apparaît.
Examinons comment l’incorporation symbolique est obtenue: nous divisons le mot en symboles, appliquons une couche d’incorporation pour chaque symbole et obtenons une matrice d’incorporation. Lorsqu'il ne s'agit que de symboles, la dimension d'une telle matrice est petite. Ensuite, une convolution unidimensionnelle est appliquée à la matrice d'intégration, comme cela se fait habituellement en PNL, avec un regroupement maximal à la fin, un vecteur est obtenu. Un
réseau à deux couches, appelé
réseau routier, est appliqué à ce vecteur, qui calcule le
vecteur général d'un mot .
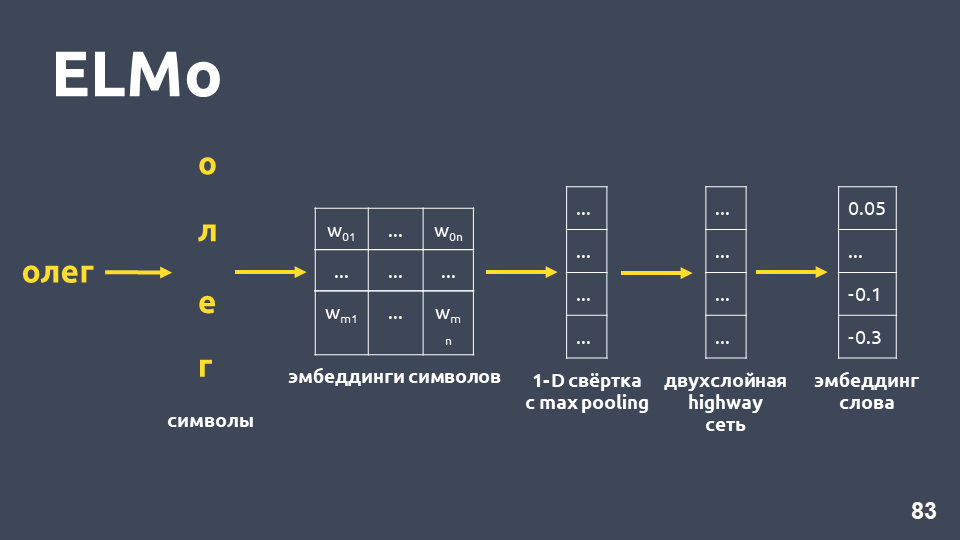
De plus, le modèle construira une sorte d'hypothèse d'incorporation, même pour un mot qui n'a pas été trouvé dans l'ensemble d'apprentissage.
Après avoir reçu des incorporations symboliques pour chaque mot, nous leur appliquons un réseau BiLSTM à deux couches.
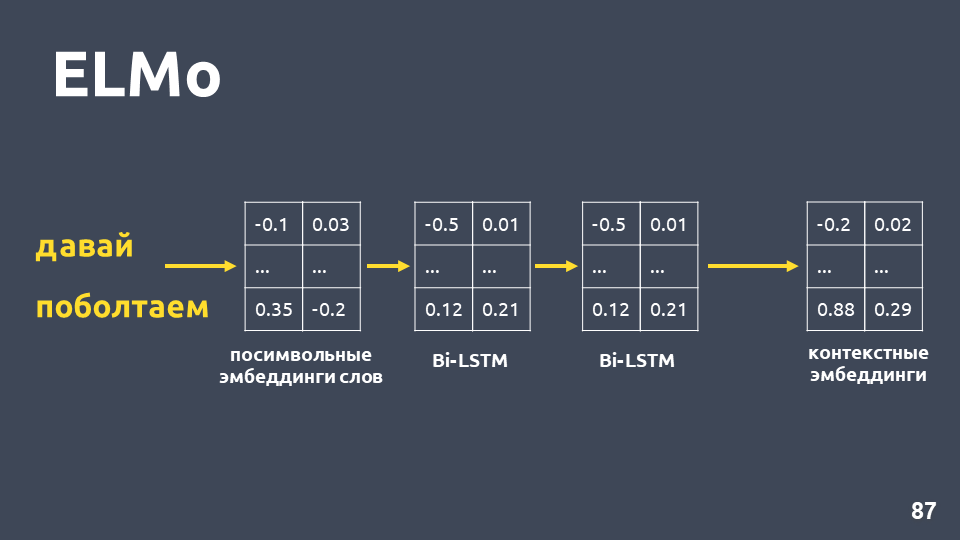
Après avoir appliqué un réseau BiLSTM à deux couches, les états masqués de la dernière couche sont généralement pris, et on pense que c'est une intégration contextuelle. Mais ELMo a deux fonctionnalités:
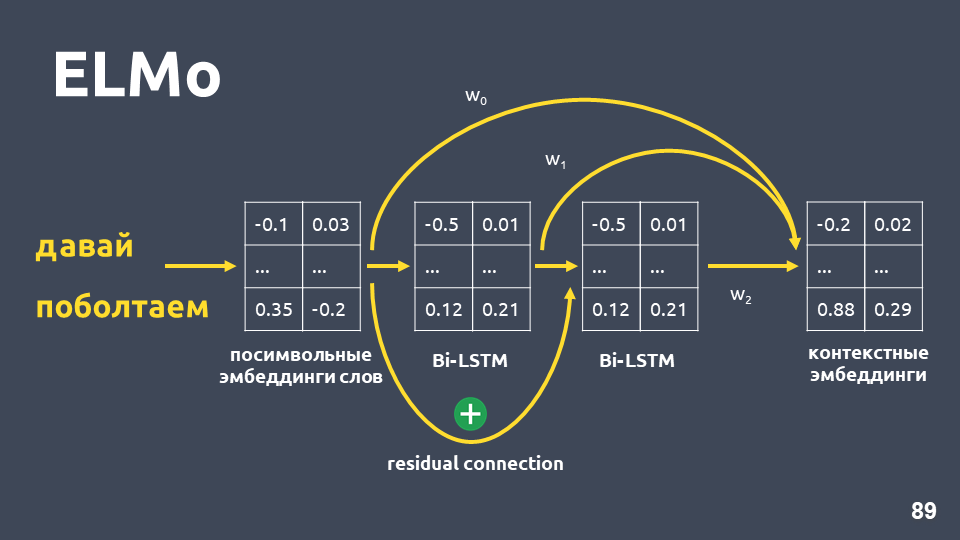
- Connexion résiduelle entre l'entrée de la première couche LSTM et sa sortie. L'entrée LSTM est ajoutée à la sortie pour éviter le problème de la décoloration des gradients.
- Les auteurs d'ELMo proposent de combiner l'incorporation symbolique pour chaque mot, la sortie de la première couche LSTM et la sortie de la deuxième couche LSTM avec des pondérations sélectionnées pour chaque tâche. Cela est nécessaire pour prendre en compte à la fois les fonctionnalités de bas niveau et les fonctionnalités de niveau supérieur qui donnent les première et deuxième couches de LSTM.
Dans notre problème, nous avons utilisé une moyenne simple de ces trois plongements et avons ainsi obtenu une intégration contextuelle pour chaque mot.
Le modèle de langage offre les avantages suivants:
- Le vecteur d'un mot dépend du contexte dans lequel le mot est utilisé. C'est-à-dire, par exemple, pour le mot «langue» au sens de la partie du corps et le terme linguistique, nous obtenons différents vecteurs.
- Comme dans le cas de word2vec et fasttext, il existe de nombreux modèles formés, par exemple, du projet DeepPavlov . Vous pouvez prendre le modèle fini et essayer de l'appliquer dans votre tâche.
- Vous n'avez plus besoin de penser à la moyenne des vecteurs de mots. Le modèle ELMo produit immédiatement un vecteur de tout le texte.
- Vous pouvez recycler le modèle de langage pour votre tâche, il existe différentes façons pour cela, par exemple, ULMFiT.
Le seul inconvénient demeure - le
modèle de langage ne garantit pas que les textes appartenant à la même classe, c'est-à-dire à une seule intention, seront proches dans l'espace vectoriel.
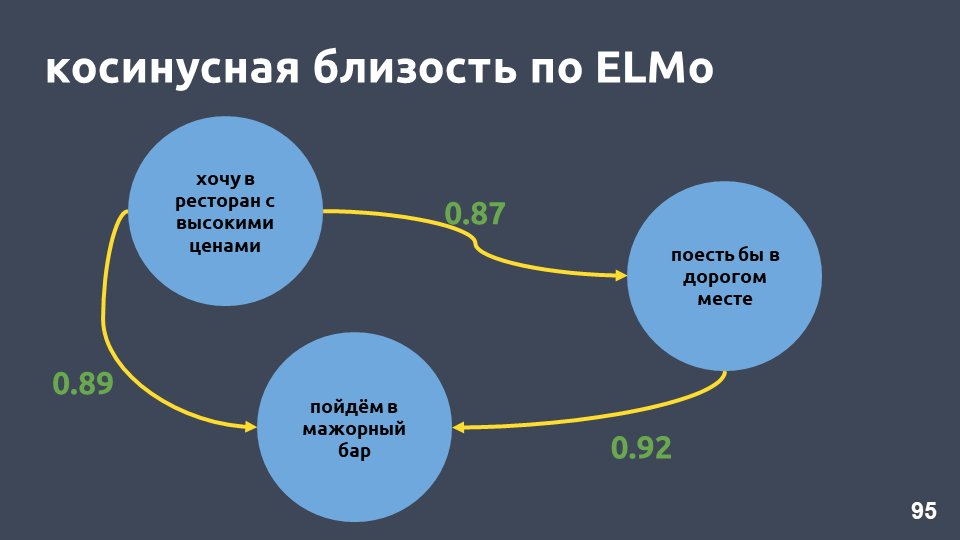
Dans notre exemple de restaurant, les valeurs de cosinus selon le modèle ELMo sont vraiment devenues plus élevées.
t-SNE sur ELMo (10 premières intentions), score F1 0,93 (0,92 par tf-idf)Les grappes affichant les 10 meilleures intentions sont également plus prononcées. Dans la figure ci-dessus, les 10 clusters sont clairement visibles, tandis que la précision a légèrement augmenté.
t-SNE sur ELMo (30 premières intentions) F1 score 0,86 (0,85 par tf-idf)Pour les 30 premières intentions, la structure du cluster est toujours préservée, et il y a aussi une augmentation de la qualité d'un point.
Mais dans un tel modèle, il n'y a aucune garantie que les propositions "Et si vous ouvrez un dépôt, quels sont les intérêts sur eux?" et "Et je veux ouvrir une contribution à 7 pour cent" seront loin les uns des autres, bien qu'ils appartiennent à des classes différentes. Avec ELMo, nous apprenons simplement le modèle de langage, et si les textes sémantiquement similaires, alors ils seront proches.
ELMo ne sait rien de nos classes , mais vous pouvez rassembler des vecteurs de texte de même intention dans l'espace en utilisant des étiquettes de classe.
Réseau siamois
Prenez votre architecture de réseau neuronal préférée pour la vectorisation de texte et deux exemples d'intentions. Pour chacun des exemples, nous obtenons des plongements, puis nous calculons la distance cosinus entre eux.
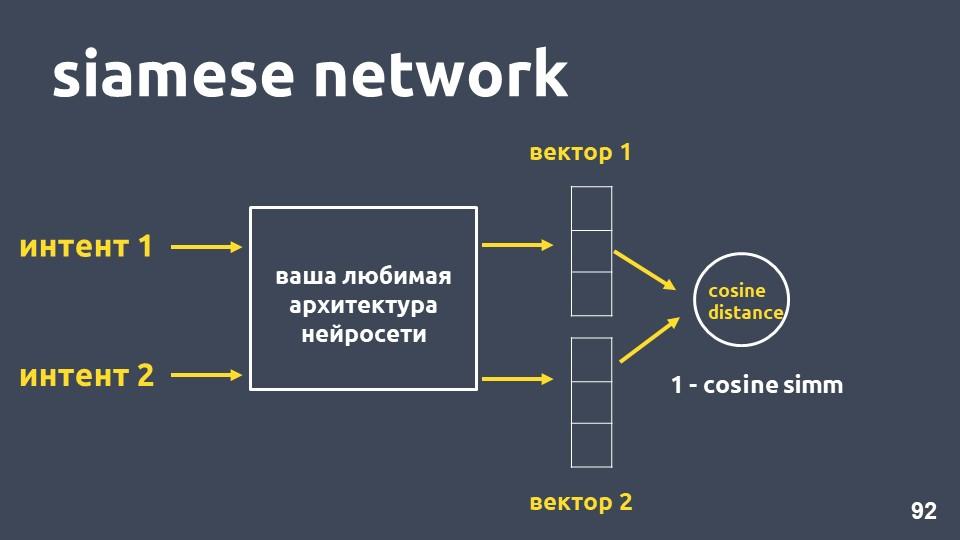
La distance cosinus est égale à un moins la proximité cosinus que nous avons rencontrée précédemment.
Cette approche s'appelle le
réseau siamois .
Nous voulons que les textes de la même classe, par exemple, «faites un transfert» et «jetez de l'argent», se trouvent tout près dans l'espace. Autrement dit, la distance cosinus entre leurs vecteurs doit être aussi petite que possible, idéalement nulle. Et les textes relatifs à des intentions différentes doivent être aussi éloignés que possible.
Mais en pratique, cette méthode de formation ne fonctionne pas si bien, car les objets de différentes classes ne sont pas suffisamment éloignés les uns des autres. La fonction de perte appelée
"perte de triplet" fonctionne beaucoup mieux. Il utilise des triplets d'objets appelés triplets.
L'illustration montre un triplet: un objet d'ancrage dans un cercle bleu, un objet positif en vert et un objet négatif dans un cercle rouge. L'objet négatif et l'ancre sont dans des classes différentes, et le positif et l'ancre sont dans une seule.

Nous voulons nous assurer qu'après l'entraînement, l'objet positif est plus proche de l'ancre que du négatif. Pour ce faire, nous considérons la distance cosinus entre les paires d'objets et entrons dans l'hyperparamètre - «marge» - la distance que nous prévoyons être entre les objets positifs et négatifs.

La fonction de perte ressemble à ceci:
, , , , margin. , , , .
, , , , , , , .
, .
kNN , , .
, kNN : , , , , . , .
, , 300, 500 000 . .
HNSW —
Hierarchical Navigable Small World .
Navigable Small World — , , , . , , .. , , .
, Hierarchical. , , , . .
, , , , .
, , , , , . , , ,
— 0,95-0,99 , .
, , , ,
. .
, . , . .
t-SNE siamese (-10 ), F1 score 0,95 (0,93 ELMo)t-SNE siamese (-30 ), F1 score 0,87 (0,86 ELMo)10 ELMo, 30 — , .
Résumé
, , , 2-5, . , , , 20-30 . , .
, , , tf-idf . , , , .
, word2vec fasttext. , , . , , , .
, , ELMo. , , , , , .
ELMo, , .
, - . . , . , , . , , .. , .
:— «Deep Learning vs common sense» — UseData Conf . , - , 18 , , .
, , , , 16 UseData Conf .