Récemment, les fabricants de FPGA et des sociétés tierces ont développé activement des méthodes de développement pour les FPGA qui diffèrent des approches conventionnelles utilisant des outils de développement de haut niveau.
En tant que développeur FPGA, j'utilise le langage de description matérielle (
HDL ) de Verilog comme outil principal, mais la popularité croissante des nouvelles méthodes a suscité mon grand intérêt, alors dans cet article, j'ai décidé de comprendre ce qui se passait.
Cet article n'est pas un guide ou une instruction d'utilisation, c'est mon examen et mes conclusions sur ce que divers outils de développement de haut niveau peuvent donner à un développeur ou programmeur FPGA qui veut plonger dans le monde du FPGA. Afin de comparer les outils de développement les plus intéressants à mon avis, j'ai écrit plusieurs tests et analysé les résultats. Sous la coupe - ce qui en est sorti.
Pourquoi avez-vous besoin d'outils de développement de haut niveau pour FPGA?
- Accélérez le développement du projet
- en raison de la réutilisation de code déjà écrit dans des langages de haut niveau;
- grâce à l'utilisation de tous les avantages des langages de haut niveau, lors de l'écriture de code à partir de zéro;
- en réduisant le temps de compilation et la vérification du code.
- Possibilité de créer du code universel qui fonctionnera sur n'importe quelle famille FPGA.
- Réduisez le seuil de développement des FPGA, par exemple, en évitant les concepts de «vitesse d'horloge» et d'autres entités de bas niveau. Possibilité d'écrire du code pour FPGA à un développeur qui n'est pas familier avec HDL.
D'où viennent les outils de développement de haut niveau?
Aujourd'hui, beaucoup sont attirés par l'idée d'un développement de haut niveau. Des passionnés, comme par exemple
Quokka et
le générateur de code Python , ainsi que des sociétés telles que
Mathworks et les fabricants de FPGA
Intel et
Xilinx s'y sont engagés.
Chacun utilise ses méthodes et ses outils pour atteindre son objectif. Les amateurs de lutte pour un monde parfait et beau utilisent leurs langages de développement préférés, tels que Python ou C #. Les entreprises, essayant de plaire au client, proposent les leurs ou adaptent les outils existants. Mathworks propose son propre outil de codage HDL pour générer du code HDL à partir de scripts m et de modèles Simulink, tandis qu'Intel et Xilinx proposent des compilateurs pour le C / C ++ commun.
À l'heure actuelle, les entreprises dotées de ressources financières et humaines importantes ont connu un plus grand succès, tandis que les passionnés sont quelque peu en retard. Cet article sera consacré à l'examen du codeur HDL produit de Mathworks et du compilateur HLS d'Intel.
Qu'en est-il de XilinxDans cet article, je ne considère pas HIL de Xilinx, en raison des différentes architectures et systèmes de CAO d'Intel et de Xilinx, ce qui rend impossible de faire une comparaison sans ambiguïté des résultats. Mais je veux noter que Xilinx HLS, comme Intel HLS, fournit un compilateur C / C ++ et ils sont conceptuellement similaires.
Commençons par comparer le codeur HDL de Mathworks et Intel HLS Compiler, après avoir résolu plusieurs problèmes en utilisant différentes approches.
Comparaison d'outils de développement de haut niveau
Testez-en un. "Deux multiplicateurs et un additionneur"
La solution à ce problème n'a aucune valeur pratique, mais convient bien comme premier test. La fonction prend 4 paramètres, multiplie le premier par le second, le troisième par le quatrième et ajoute les résultats de la multiplication. Rien de compliqué, mais voyons comment nos sujets y font face.
Codeur HDL par Mathworks
Pour résoudre ce problème, le m-script se présente comme suit:
function [out] = TwoMultAdd(a,b,c,d) out = (a*b)+(c*d); end
Voyons ce que Mathworks nous offre pour convertir le code en HDL.
Je ne considérerai pas en détail le travail avec le codeur HDL, je m'attarderai uniquement sur les paramètres que je changerai à l'avenir pour obtenir des résultats différents dans FPGA, et dont les changements devront être pris en compte par le programmeur MATLAB qui doit exécuter son code dans FPGA.
Ainsi, la première chose à faire est de définir le type et la plage de valeurs d'entrée. Il n'y a pas de char, int, float, double familier dans FPGA. La profondeur de bits du nombre peut être quelconque, il est logique de le choisir, en fonction de la plage de valeurs d'entrée que vous prévoyez d'utiliser.
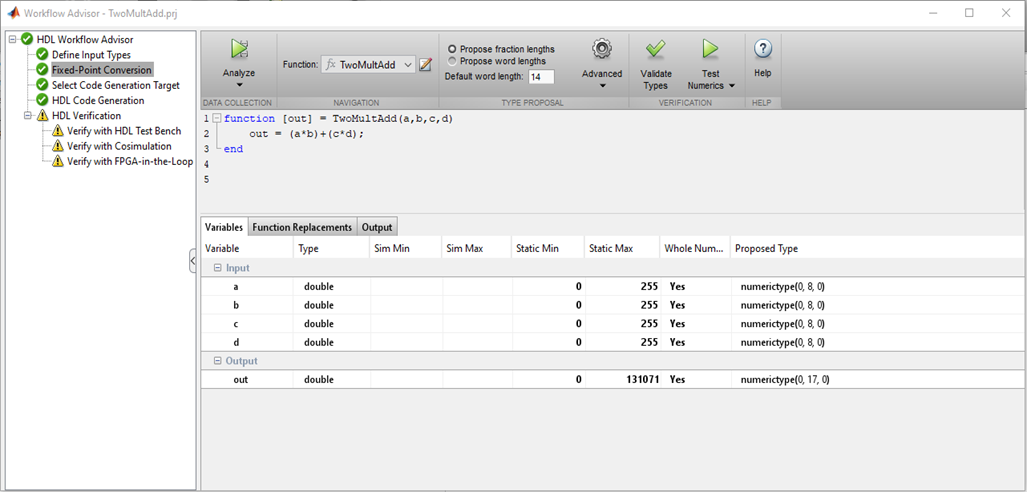 Figure 1
Figure 1MATLAB vérifie les types de variables, leurs valeurs et sélectionne les bonnes tailles de bits pour les bus et les registres, ce qui est vraiment pratique. S'il n'y a aucun problème de profondeur de bit et de frappe, vous pouvez passer aux points suivants.
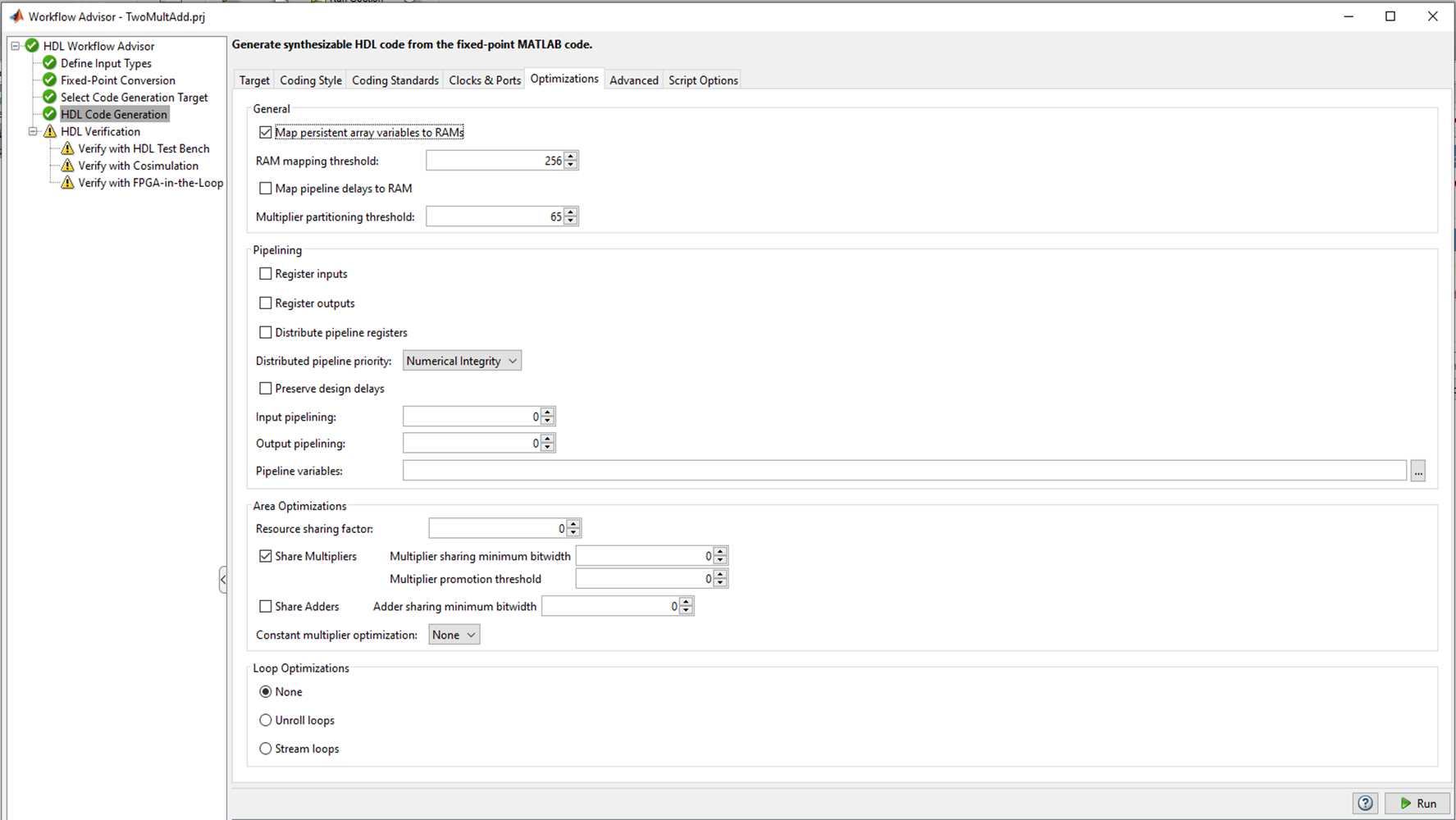 Figure 2
Figure 2Il y a plusieurs onglets dans la génération de code HDL où vous pouvez choisir la langue vers laquelle convertir (Verilog ou VHDL); style de code noms des signaux. L'onglet le plus intéressant, à mon avis, est l'optimisation, et je vais l'expérimenter, mais plus tard, pour l'instant, laissons tous les paramètres par défaut et voyons ce qui se passe avec le codeur HDL «prêt à l'emploi».
Appuyez sur le bouton Exécuter et obtenez le code suivant:
`timescale 1 ns / 1 ns module TwoMultAdd_fixpt (a, b, c, d, out); input [7:0] a; // ufix8 input [7:0] b; // ufix8 input [7:0] c; // ufix8 input [7:0] d; // ufix8 output [16:0] out; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16 wire [16:0] TwoMultAdd_fixpt_2; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16 wire [16:0] TwoMultAdd_fixpt_3; // ufix17 //HDL code generation from MATLAB function: TwoMultAdd_fixpt //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% // % // Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 % // % //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% assign TwoMultAdd_fixpt_mul_temp = a * b; assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp}; assign TwoMultAdd_fixpt_mul_temp_1 = c * d; assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1}; assign out = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3; endmodule // TwoMultAdd_fixpt
Le code semble bon. MATLAB comprend que l'écriture de l'expression entière sur une seule ligne sur Verilog est une mauvaise pratique. Crée des
fils séparés pour le multiplicateur et l'additionneur, il n'y a rien à redire.
Il est alarmant que la description des registres soit manquante. Cela est arrivé parce que nous n'avons pas demandé à ce sujet le codeur HDL et laissé tous les champs dans les paramètres à leurs valeurs par défaut.
Voici ce que Quartus synthétise à partir d'un tel code.
 Figure 3
Figure 3Aucun problème, tout était comme prévu.
Dans FPGA, nous implémentons des circuits synchrones, et je voudrais toujours voir les registres. Le codeur HDL offre un mécanisme pour placer des registres, mais où les placer dépend du développeur. On peut placer les registres à l'entrée des multiplicateurs, à la sortie des multiplicateurs devant l'additionneur, ou à la sortie de l'additionneur.
Pour synthétiser les exemples, j'ai choisi la famille FPGA Cyclone V, où des blocs DSP spéciaux avec des additionneurs et des multiplicateurs intégrés sont utilisés pour implémenter des opérations arithmétiques. Le bloc DSP ressemble à ceci:
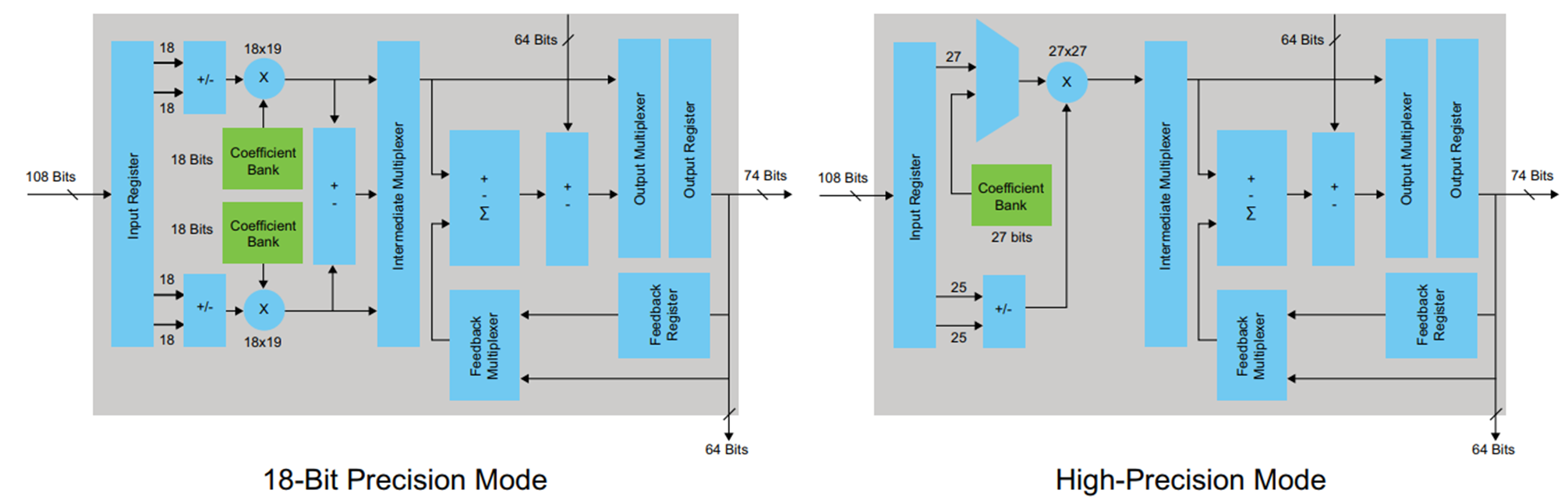 Figure 4
Figure 4Le bloc DSP a des registres d'entrée et de sortie. Il n'est pas nécessaire d'essayer de capturer les résultats de la multiplication dans le registre avant l'ajout, cela ne fera que violer l'architecture (dans certains cas, cette option est possible et même nécessaire). C'est au développeur de décider comment gérer le registre d'entrée et de sortie en fonction des exigences de latence et de la fréquence maximale requise. J'ai décidé d'utiliser uniquement le registre de sortie. Pour que ce registre soit décrit dans le code généré par le codeur HDL, dans l'onglet Options du codeur HDL, vous devez cocher la case Enregistrer la sortie et redémarrer la conversion.
Il s'avère que le code suivant:
`timescale 1 ns / 1 ns module TwoMultAdd_fixpt (clk, reset, clke_ena_i, a, b, c, d, clke_ena_o, out); input clk; input reset; input clke_ena_i; input [7:0] a; // ufix8 input [7:0] b; // ufix8 input [7:0] c; // ufix8 input [7:0] d; // ufix8 output clke_ena_o; output [16:0] out; // ufix17 wire enb; wire [16:0] out_1; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16 wire [16:0] TwoMultAdd_fixpt_2; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16 wire [16:0] TwoMultAdd_fixpt_3; // ufix17 reg [16:0] out_2; // ufix17 //HDL code generation from MATLAB function: TwoMultAdd_fixpt //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% // % // Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 % // % //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% assign TwoMultAdd_fixpt_mul_temp = a * b; assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp}; assign TwoMultAdd_fixpt_mul_temp_1 = c * d; assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1}; assign out_1 = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3; assign enb = clke_ena_i; always @(posedge clk or posedge reset) begin : out_reg_process if (reset == 1'b1) begin out_2 <= 17'b00000000000000000; end else begin if (enb) begin out_2 <= out_1; end end end assign clke_ena_o = clke_ena_i; assign out = out_2; endmodule // TwoMultAdd_fixpt
Comme vous pouvez le voir, le code présente des différences fondamentales par rapport à la version précédente. Un bloc toujours apparu, qui est une description du registre (juste ce que nous voulions). Pour l'opération toujours bloquée, les entrées du module clk (fréquence d'horloge) et reset (reset) sont également apparues. On peut voir que la sortie de l'additionneur est verrouillée dans le déclencheur décrit dans toujours. Il y a aussi quelques signaux d'autorisation ena, mais ils ne sont pas très intéressants pour nous.
Regardons le diagramme que Quartus synthétise maintenant.
 Figure 5
Figure 5Et encore une fois, les résultats sont bons et attendus.
Le tableau ci-dessous montre le tableau des ressources utilisées - nous le gardons à l'esprit.
 Figure 6
Figure 6Pour cette première quête, Mathworks reçoit un crédit. Tout n'est pas compliqué, prévisible et avec le résultat souhaité.
J'ai décrit en détail un exemple simple, fourni un schéma d'un bloc DSP et décrit les possibilités d'utilisation des paramètres d'utilisation des registres dans le codeur HDL, qui sont différents des paramètres «par défaut». Cela est fait pour une raison. Par cela, je tiens à souligner que même dans un exemple aussi simple, lors de l'utilisation du codeur HDL, la connaissance de l'architecture FPGA et des principes fondamentaux des circuits numériques est nécessaire, et les paramètres doivent être modifiés consciemment.
Compilateur Intel HLS
Essayons de compiler du code avec les mêmes fonctionnalités écrites en C ++ et de voir ce qui est finalement synthétisé dans FPGA à l'aide du compilateur HLS.
Donc du code C ++
component unsigned int TwoMultAdd(unsigned char a, unsigned char b, unsigned char c, unsigned char d) { return (a*b)+(c*d); }
J'ai choisi des types de données pour éviter les débordements de variables.
Il existe des méthodes avancées pour définir les profondeurs de bits, mais notre objectif est de tester la capacité d'assembler des fonctions écrites en style C / C ++ sous FPGA sans apporter de modifications, le tout dès le départ.
Le compilateur HLS étant un outil natif d'Intel, nous collectons le code avec un compilateur spécial et vérifions le résultat immédiatement dans Quartus.
Regardons le circuit synthétisé par Quartus.
 Figure 7
Figure 7Le compilateur a créé des registres à l'entrée et à la sortie, mais l'essentiel est caché dans le module wrapper. Nous commençons à déployer le wrapper et ... voir de plus en plus de modules imbriqués.
La structure du projet ressemble à ceci.
 Figure 8
Figure 8Un indice évident d'Intel est «ne mettez pas la main dessus!». Mais on va essayer, surtout la fonctionnalité n'est pas compliquée.
Dans les entrailles de l'arborescence du projet | quartus_compile | TwoMultAdd: TwoMultAdd_inst | TwoMultAdd_internal: twomultadd_internal_inst | TwoMultAdd_fu
nction_wrapper: TwoMultAdd_internal | TwoMultAdd_function: theTwoMultAdd_function | bb_TwoMultAdd_B1_start:
thebb_TwoMultAdd_B1_start | bb_TwoMultAdd_B1_start_stall_region: thebb_TwoMultAdd_B1_start_stall_region | i
_sfc_c1_wt_entry_twomultadd_c1_enter_twomultadd: thei_sfc_c1_wt_entry_twomultadd_c1_enter_twomultad
d_aunroll_x | i_sfc_logic_c1_wt_entry_twomultadd_c1_enter_twomultadd13: thei_sfc_logic_c1_wt_entry_twom
ultadd_c1_enter_twomultadd13_aunroll_x | Mult1 est le module que vous recherchez.
Nous pouvons regarder le schéma du module souhaité synthétisé par Quartus.
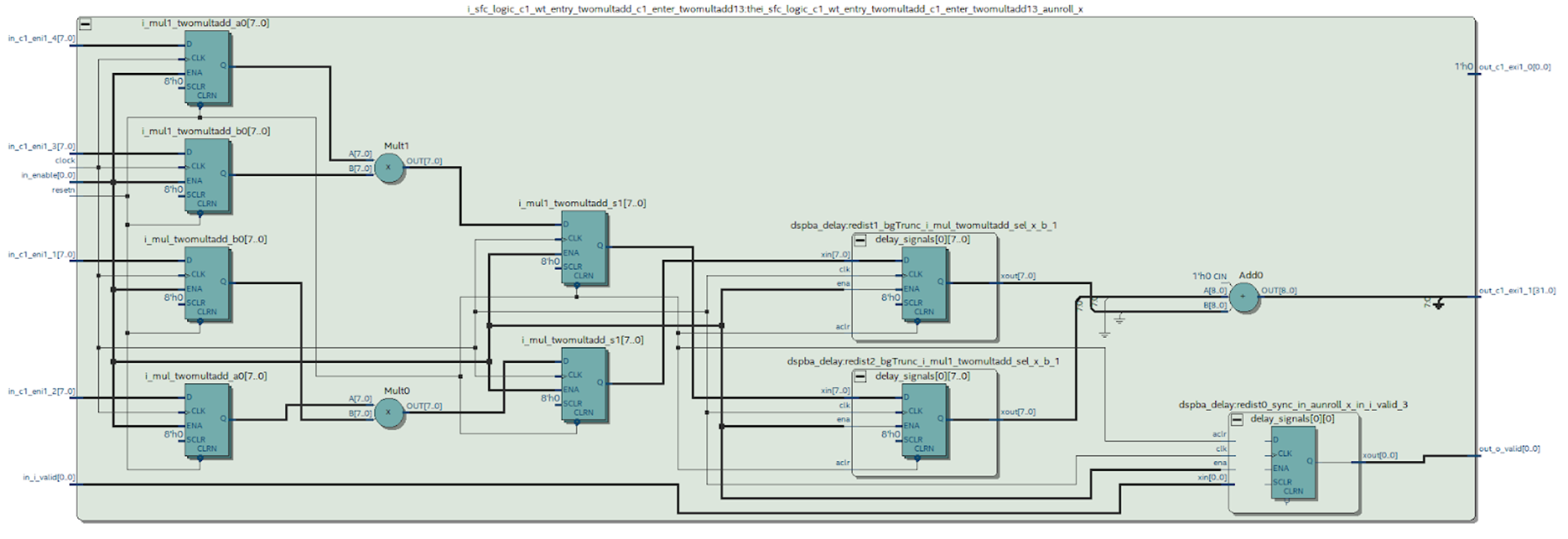 Figure 9
Figure 9Quelles conclusions peut-on tirer de ce schéma.
Il est évident que quelque chose s'est produit que nous avons essayé d'éviter en travaillant dans MATLAB: le cas à la sortie du multiplicateur a été synthétisé - ce n'est pas très bon. On peut voir sur le schéma de principe du DSP (figure 4) qu'il n'y a qu'un seul registre à sa sortie, ce qui signifie que chaque multiplication devra être effectuée dans un bloc séparé.
Le tableau des ressources utilisées montre à quoi cela mène.
 Figure 10
Figure 10Comparez les résultats avec le tableau du codeur HDL (figure 6).
Si vous utilisez un plus grand nombre de registres, alors dépenser de précieux blocs DSP sur des fonctionnalités aussi simples est très désagréable.
Mais il y a un énorme plus dans Intel HLS par rapport au codeur HDL. Avec les paramètres par défaut, le compilateur HLS a développé une conception synchrone dans FPGA, bien qu'il ait dépensé plus de ressources. Une telle architecture est possible, il est clair qu'Intel HLS est configuré pour atteindre des performances maximales, et non pour économiser des ressources.
Voyons comment nos sujets se comportent avec des projets plus complexes.
Le deuxième test. «Multiplication des matrices élément par élément avec sommation du résultat»
Cette fonction est largement utilisée dans le traitement d'images: le soi-disant
«filtre matriciel» . Nous le vendons à l'aide d'outils de haut niveau.
Codeur HDL par Mathwork
Le travail commence immédiatement avec une limitation. Le codeur HDL ne peut pas accepter les fonctions matricielles 2D comme entrées. Étant donné que MATLAB est un outil pour travailler avec des matrices, cela porte un coup sérieux à tout le code hérité, ce qui peut devenir un problème grave. Si le code est écrit à partir de zéro, c'est une fonctionnalité désagréable qui doit être prise en compte. Il faut donc déployer toutes les matrices dans un vecteur et implémenter les fonctions en tenant compte des vecteurs d'entrée.
Le code de la fonction dans MATLAB est le suivant
function [out] = mhls_conv2_manually(target,kernel) len = length(kernel); mult = target.*kernel; summ = sum(mult); out = summ/len; end
Le code HDL généré s'est avéré être très gonflé et contient des centaines de lignes, donc je ne le donnerai pas ici. Voyons quel schéma Quartus synthétise à partir de ce code.
 Figure 11
Figure 11Ce schéma semble infructueux. Formellement, cela fonctionne, mais je suppose que cela fonctionnera à une fréquence très basse, et il peut difficilement être utilisé dans du vrai matériel. Mais toute hypothèse doit être vérifiée. Pour ce faire, nous placerons les registres à l'entrée et à la sortie de ce circuit et à l'aide de Timing Analyzer nous évaluerons la situation réelle. Pour effectuer l'analyse, vous devez spécifier la fréquence de fonctionnement souhaitée du circuit afin que Quartus sache quoi rechercher lors du câblage et, en cas de panne, fournit des rapports de violations.
Nous avons réglé la fréquence à 100 MHz, voyons ce que Quartus peut faire sortir du circuit proposé.
 Figure 12
Figure 12On peut voir que cela s'est avéré un peu: 33 MHz ont l'air frivole. Le retard dans la chaîne des multiplicateurs et des additionneurs est d'environ 30 ns. Pour se débarrasser de ce «goulot d'étranglement», vous devez utiliser le convoyeur: insérez des registres après les opérations arithmétiques, réduisant ainsi le chemin critique.
Le codeur HDL nous offre cette opportunité. Dans l'onglet Options, vous pouvez définir des variables de pipeline. Étant donné que le code en question est écrit dans le style MATLAB, il n'y a aucun moyen de pipeline de variables (à l'exception des variables mult et summ), ce qui ne nous convient pas. Il est nécessaire d'insérer les registres dans les circuits intermédiaires cachés dans notre code HDL.
De plus, la situation avec l'optimisation pourrait être pire. Par exemple, rien ne nous empêche d'écrire du code
out = (sum(target.*kernel))/len;
il est tout à fait adéquat pour MATLAB, mais nous prive complètement de la possibilité d'optimiser le HDL.
La prochaine solution consiste à modifier le code à la main. C'est un point très important, car nous refusons d'hériter et de commencer à réécrire le m-script, et PAS dans le style MATLAB.
Le nouveau code est le suivant
function [out] = mhls_conv2_manually(target,kernel) len = length(kernel); mult = target.*kernel; summ_1 = zeros([1,(len/2)]); summ_2 = zeros([1,(len/4)]); summ_3 = zeros([1,(len/8)]); for i=0:1:(len/2)-1 summ_1(i+1) = (mult(i*2+1)+mult(i*2+2)); end for i=0:1:(len/4)-1 summ_2(i+1) = (summ_1(i*2+1)+summ_1(i*2+2)); end for i=0:1:(len/8)-1 summ_3(i+1) = (summ_2(i*2+1)+summ_2(i*2+2)); end out = summ_3/len; end
Dans Quartus, nous collectons le code généré par le codeur HDL. On peut voir que le nombre de couches avec des primitives a diminué, et le schéma semble beaucoup mieux.
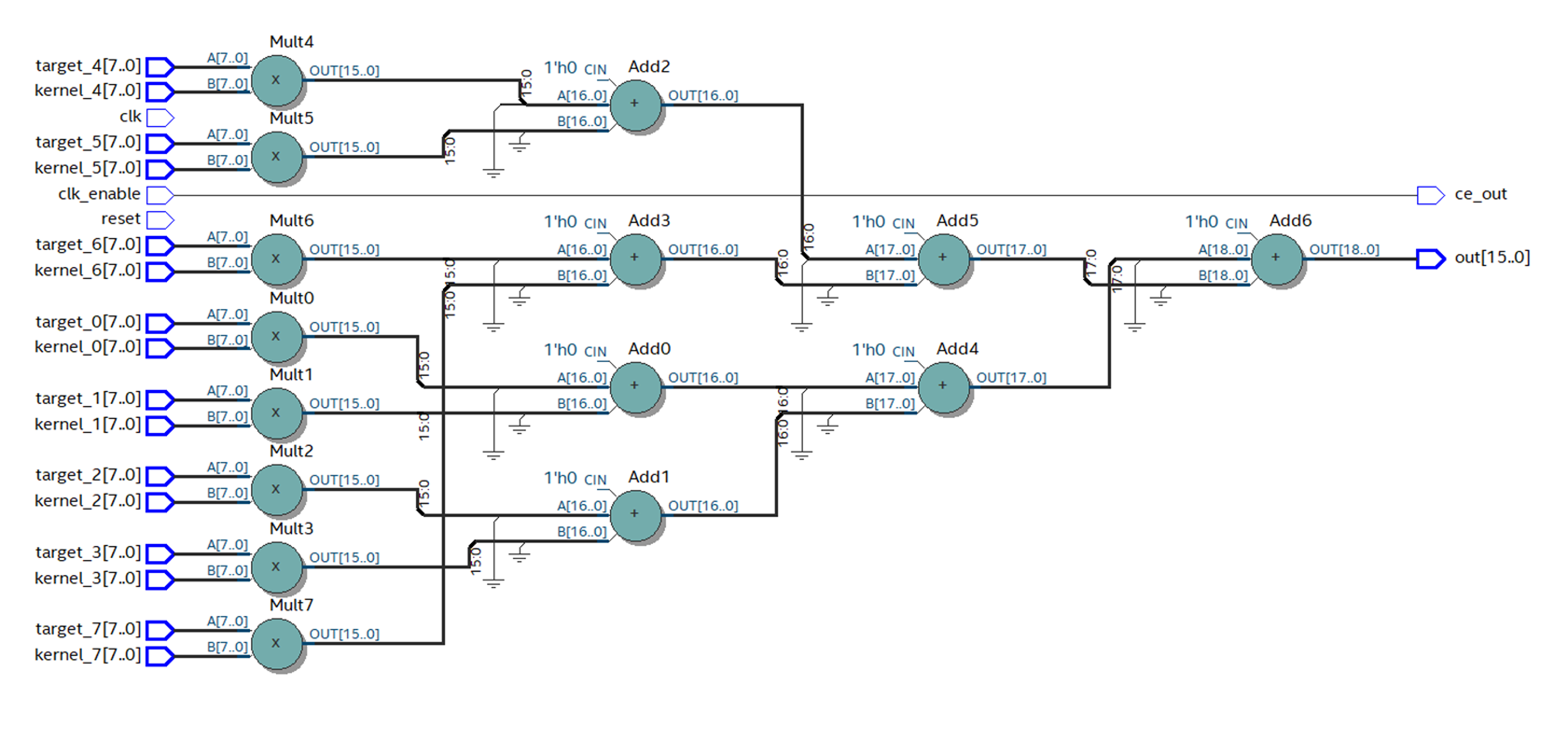 Figure 12
Figure 12Avec la disposition correcte des primitives, la fréquence augmente presque 3 fois, jusqu'à 88 MHz.
 Figure 13
Figure 13Maintenant la touche finale: dans les paramètres d'optimisation, spécifiez summ_1, summ_2 et summ_3 comme éléments du pipeline. Nous collectons le code résultant dans Quartus. Le schéma change comme suit:
 Figure 14
Figure 14La fréquence maximale augmente à nouveau et maintenant sa valeur est d'environ 195 MHz.
 Figure 15
Figure 15Combien de ressources sur la puce prendront une telle conception? La figure 16 montre le tableau des ressources utilisées pour le cas décrit.
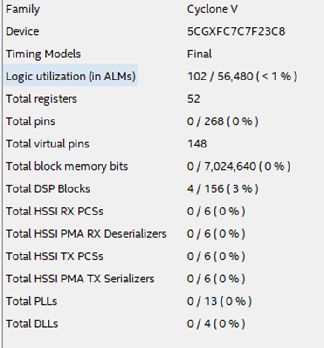 Figure 16
Figure 16Quelles conclusions peut-on tirer après avoir examiné cet exemple?
Le principal inconvénient du codeur HDL est qu'il est peu probable qu'il utilise le code MATLAB dans sa forme pure.
Il n'y a pas de prise en charge des matrices comme entrées de fonction, la disposition du code dans le style MATLAB est médiocre.
Le principal danger est le manque de registres dans le code généré sans paramètres supplémentaires. Sans ces registres, même après avoir reçu un code HDL fonctionnellement formel sans erreurs de syntaxe, l'utilisation d'un tel code dans les réalités et développements modernes n'est pas souhaitable.
Il est conseillé d'écrire immédiatement du code affiné pour la conversion en HDL. Dans ce cas, vous pouvez obtenir des résultats tout à fait acceptables en termes de vitesse et d'intensité des ressources.
Si vous êtes un développeur MATLAB, ne vous précipitez pas pour cliquer sur le bouton Exécuter et compilez votre code sous FPGA, n'oubliez pas que votre code sera synthétisé dans un circuit réel. =)
Compilateur Intel HLS
Pour la même fonctionnalité, j'ai écrit le code C / C ++ suivant
component unsigned int conv(unsigned char *data, unsigned char *kernel) { unsigned int mult_res[16]; unsigned int summl; summl = 0; for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; summl = summl+mult_res[i]; } return summl/16; }
La première chose qui attire votre attention est la quantité de ressources utilisées.
 Figure 17
Figure 17Le tableau montre qu'un seul bloc DSP a été utilisé, donc quelque chose s'est mal passé et les multiplications ne sont pas effectuées en parallèle. Le nombre de registres utilisés est également surprenant, et même la mémoire est impliquée, mais nous laisserons cela à la conscience du compilateur HLS.
Il convient de noter que le compilateur HLS a développé un sous-optimal, en utilisant une énorme quantité de ressources supplémentaires, mais toujours un circuit de travail qui, selon les rapports Quartus, fonctionnera à une fréquence acceptable, et un échec comme le codeur HDL ne le fera pas.
 Figure 18
Figure 18Essayons d'améliorer la situation. Que faut-il pour cela? C'est vrai, fermez les yeux sur l'héritage et explorez le code, mais jusqu'à présent, ce n'est pas beaucoup.
HLS a des directives spéciales pour optimiser le code pour FPGA. Nous insérons la directive unroll, qui devrait étendre notre boucle en parallèle:
#pragma unroll for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; }
Voyons comment Quartus y a réagi
 Figure 19
Figure 19Tout d'abord, faites attention au nombre de blocs DSP - il y en a 16, ce qui signifie que les multiplications sont effectuées en parallèle.
Hourra! dérouler les travaux! Mais il est déjà difficile de supporter l’augmentation de l’utilisation des autres ressources. Le circuit est devenu complètement illisible.
 Figure 20
Figure 20Je pense que cela est dû au fait que personne n'a signalé au compilateur que les calculs en nombres à virgule fixe nous convenaient tout à fait, et il a honnêtement mis en œuvre toutes les mathématiques à virgule flottante sur la logique et les registres. Nous devons expliquer au compilateur ce qui est requis de lui, et pour cela nous replongons dans le code.
Dans le but d'utiliser des virgules fixes, des classes de modèles sont implémentées.
 Figure 21
Figure 21En parlant avec nos propres mots, nous pouvons utiliser des variables dont la profondeur de bits est définie manuellement jusqu'à un bit. Pour ceux qui écrivent en HDL, vous ne pouvez pas vous y habituer, mais les programmeurs C / C ++ vont probablement se serrer la tête. Profondeurs de bits, comme dans MATLAB, dans ce cas, personne ne le dira, et le développeur lui-même doit compter le nombre de bits.
Voyons à quoi cela ressemble dans la pratique.
Nous éditons le code comme suit:
component ac_fixed<16,16,false> conv(ac_fixed<8,8,false> *data, ac_fixed<8,8,false> *kernel) { ac_fixed<16,16,false>mult_res[16]; ac_fixed<32,32,false>summl; #pragma unroll for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; } for (int i = 0; i < 16; i++) { summl = summl+mult_res[i]; } return summl/16; }
Et au lieu des pâtes effrayantes de la figure 20, nous obtenons cette beauté:
 Figure 22
Figure 22Malheureusement, quelque chose d'étrange continue de se produire avec les ressources utilisées.
 Figure 23
Figure 23Mais un examen détaillé des rapports montre que le module qui nous intéresse directement semble plus que suffisant:
 Figure 24
Figure 24L'énorme consommation de registres et de mémoire de bloc est associée à un grand nombre de modules périphériques. Je ne comprends toujours pas pleinement le sens profond de leur existence, et cela devra être réglé, mais le problème est résolu. Dans un cas extrême, vous pouvez soigneusement découper un module qui nous intéresse dans la structure générale du projet, ce qui nous épargnera des modules périphériques qui dévorent les ressources.
Le troisième test. «Transition de RVB à HSV»
Commençant à écrire cet article, je ne m'attendais pas à ce qu'il soit si volumineux. Mais je ne peux pas refuser le troisième et le dernier dans le cadre de cet article, un exemple.
Tout d'abord, c'est un véritable exemple de ma pratique, et c'est à cause de cela que j'ai commencé à me tourner vers des outils de développement de haut niveau.
Deuxièmement, à partir des deux premiers exemples, nous pourrions faire l'hypothèse que plus la conception est complexe, plus les outils de haut niveau font face à la tâche.
Je veux démontrer que ce jugement est erroné et, en fait, plus la tâche est complexe, plus les avantages des outils de développement de haut niveau se manifestent.
L'année dernière, lorsque je travaillais sur l'un des projets, je n'aimais pas l'appareil photo acheté sur Aliexpress, à savoir que les couleurs n'étaient pas assez saturées. L'une des façons les plus courantes de faire varier la saturation des couleurs consiste à passer de l'espace colorimétrique RVB à l'espace HSV, où l'un des paramètres est la saturation. Je me souviens de la façon dont j'ai ouvert la formule de transition et pris une profonde inspiration ... La mise en œuvre de tels calculs dans FPGA n'est pas quelque chose d'extraordinaire, mais bien sûr, il faudra du temps pour écrire du code. Ainsi, la formule pour passer du RVB au HSV est la suivante:
 Figure 25
Figure 25La mise en œuvre d'un tel algorithme dans FPGA ne prendra pas des jours, mais des heures, et tout cela doit être fait très soigneusement en raison des spécificités de HDL, et la mise en œuvre en C ++ ou en MATLAB prendra, je pense, quelques minutes.
En C ++, vous pouvez écrire du code directement sur le front et toujours obtenir un résultat fonctionnel.
J'ai écrit l'option suivante en C ++
struct color_space{ unsigned char rh; unsigned char gs; unsigned char bv; }; component color_space rgb2hsv(color_space rgb_0) { color_space hsv; float h,s,v,r,g,b; float max_col, min_col; r = static_cast<float>(rgb_0.rh)/255; g = static_cast<float>(rgb_0.gs)/255; b = static_cast<float>(rgb_0.bv)/255; max_col = std::max(std::max(r,g),b); min_col = std::min(std::min(r,g),b);
Et Quartus a réussi à mettre en œuvre le résultat, comme le montre le tableau des ressources utilisées.
 Figure 26
Figure 26La fréquence est très bonne.
 Figure 27
Figure 27Avec le codeur HDL, les choses sont un peu plus compliquées.
Afin de ne pas gonfler l'article, je ne fournirai pas de m-script pour cette tâche, cela ne devrait pas poser de problème. Un m-script écrit sur le front peut difficilement être utilisé avec succès, mais si vous modifiez le code et spécifiez correctement les emplacements de pipelining, nous obtenons un résultat fonctionnel. Bien sûr, cela prendra plusieurs dizaines de minutes, mais pas des heures.
En C ++, il est également souhaitable de définir les directives et de traduire les calculs en un point fixe, ce qui prendra également très peu de temps.Ainsi, en utilisant des outils de développement de haut niveau, nous gagnons du temps, et plus l'algorithme est compliqué, plus il gagne de temps - cela continuera jusqu'à ce que nous rencontrions des limites de ressources FPGA ou des limites de vitesse de calcul strictes où vous devez vous attaquer au HDL.Conclusion
Ce qui peut être dit en conclusion.De toute évidence, le marteau d'or n'a pas encore été inventé, mais il existe des outils supplémentaires qui peuvent être utilisés dans le développement.Le principal avantage des outils de haut niveau, à mon avis, est la rapidité de développement. C’est une réalité d’obtenir suffisamment de qualité en termes de temps, parfois un ordre de grandeur plus petit que lors du développement avec HDL.Je me méfie des avantages tels que l'utilisation du code hérité pour FPGA et la connexion au développement pour les programmeurs FPGA sans préparation préalable. Pour obtenir des résultats satisfaisants, vous devrez abandonner de nombreuses techniques de programmation familières.Encore une fois, je tiens à noter que cet article n'est qu'un aperçu superficiel des outils de développement de haut niveau pour FPGA.Le compilateur HLS offre de grandes opportunités d'optimisations: pragmas, bibliothèques spéciales avec fonctions optimisées, descriptions d'interfaces, nombreux articles sur Internet sur les «meilleures pratiques», etc. La puce MATLAB, qui n'a pas été prise en compte, est la capacité de générer directement, par exemple, un filtre à partir de l'interface graphique sans écrire une seule ligne de code, indiquant simplement les caractéristiques souhaitées, ce qui accélère encore le temps de développement.Qui a gagné l'étude d'aujourd'hui? Mon opinion est le compilateur Intel HLS. Il génère une conception fonctionnelle même à partir de code non optimisé. Codeur HDL sans analyse réfléchie et traitement de code que j'aurais peur d'utiliser. Je tiens également à noter que le codeur HDL est un outil assez ancien, mais comme je le sais, il n'a pas été largement reconnu. Mais HLS, bien que jeune, il est clair que les fabricants de FPGA parient dessus, je pense que nous verrons son développement et sa popularité grandir.Les représentants de Xilinx assurent que le développement et la mise en œuvre d'outils de haut niveau est la seule opportunité à l'avenir de se développer pour des puces FPGA de plus en plus grandes. Les outils traditionnels ne pourront tout simplement pas faire face à cela, et Verilog / VHDL est probablement destiné à l'assembleur, mais c'est dans le futur. Et maintenant, nous avons entre nos mains des outils de développement (avec leurs avantages et leurs inconvénients), que nous devons choisir en fonction de la tâche.Vais-je utiliser des outils de développement de haut niveau dans mon travail? Au contraire, oui, maintenant leur développement va à pas de géant, nous devons donc au moins suivre le rythme, mais je ne vois aucune raison objective d'abandonner immédiatement le HDL.En fin de compte, je tiens à noter une fois de plus qu'à ce stade du développement d'outils de conception de haut niveau, l'utilisateur ne doit pas oublier une minute qu'il écrit un programme qui n'est pas exécutable dans le processeur, mais crée un circuit avec de vrais fils, déclencheurs et éléments logiques.