Récemment,
un article a été publié qui montre une bonne tendance dans l'apprentissage automatique au cours des dernières années. En bref: le nombre de startups dans le domaine du machine learning a fortement diminué au cours des deux dernières années.
Eh bien quoi. Analysons "si la bulle a éclaté", "comment continuer à vivre" et parlons d'où vient un tel gribouillis.
Tout d'abord, parlons de ce qui a été le booster de cette courbe. D'où venait-elle? Tout le monde se souviendra probablement de la
victoire du machine learning en 2012 au concours ImageNet. Après tout, c'est le premier événement mondial! Mais en réalité, ce n'est pas le cas. Et la croissance de la courbe commence un peu plus tôt. Je le décomposerais en plusieurs points.
- 2008 est l'émergence du terme «big data». De vrais produits ont commencé à apparaître en 2010. Le Big Data est directement lié à l'apprentissage automatique. Sans big data, le fonctionnement stable des algorithmes qui existaient à l'époque est impossible. Et ce ne sont pas des réseaux de neurones. Jusqu'en 2012, les réseaux de neurones sont le lot d'une minorité marginale. Mais des algorithmes complètement différents ont commencé à fonctionner, qui existaient depuis des années, voire des décennies: SVM (1963, 1993), Random Forest (1995), AdaBoost (2003), ... Les startups de ces années sont principalement associées au traitement automatique de données structurées : billetterie, utilisateurs, publicité, bien plus.
Le dérivé de cette première vague est un ensemble de frameworks tels que XGBoost, CatBoost, LightGBM, etc.
- En 2011-2012, les réseaux de neurones convolutifs ont remporté une série de concours de reconnaissance d'images. Leur utilisation réelle a été quelque peu retardée. Je dirais que des startups et des solutions massivement significatives ont commencé à apparaître en 2014. Il a fallu deux ans pour comprendre que les neurones fonctionnent toujours, pour créer des cadres pratiques qui pourraient être installés et lancés dans un délai raisonnable, pour développer des méthodes qui stabiliseraient et accéléreraient le temps de convergence.
Les réseaux convolutifs ont permis de résoudre des problèmes de vision industrielle: classification d'images et d'objets dans une image, détection d'objets, reconnaissance d'objets et de personnes, amélioration d'image, etc., etc. - 2015-2017 ans. Le boom des algorithmes et des projets liés aux réseaux récurrents ou à leurs analogues (LSTM, GRU, TransformerNet, etc.). Des algorithmes de synthèse vocale et des systèmes de traduction automatique fonctionnant bien sont apparus. En partie, ils sont basés sur des réseaux convolutifs pour mettre en évidence les fonctionnalités de base. En partie sur le fait qu'ils ont appris à collecter des ensembles de données vraiment grands et bons.
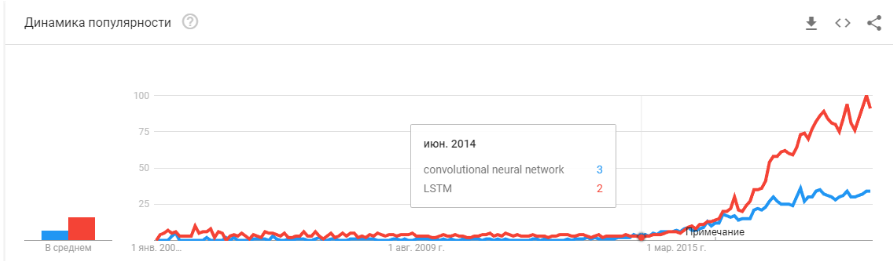
"La bulle a-t-elle éclaté?" Est-ce que Hype surchauffe? Sont-ils morts comme une blockchain? "
Eh bien! Demain, Siri cessera de travailler sur votre téléphone et après-demain, Tesla ne distinguera pas un virage d'un kangourou.
Les réseaux de neurones fonctionnent déjà. Ils sont dans des dizaines d'appareils. Ils vous permettent vraiment de gagner, de changer le marché et le monde qui vous entoure. Hype est un peu différent:
C'est juste que les réseaux de neurones ont cessé d'être quelque chose de nouveau. Oui, beaucoup de gens ont des attentes élevées. Mais un grand nombre d'entreprises ont appris à utiliser leurs neurones et à fabriquer des produits à partir d'eux. Les neurones donnent de nouvelles fonctionnalités, peuvent réduire les emplois, réduire le prix des services:
- Les entreprises manufacturières intègrent des algorithmes pour l'analyse des rejets sur le convoyeur.
- Les fermes d'élevage achètent des systèmes de contrôle des vaches.
- Récolteuses automatiques.
- Centres d'appels automatisés.
- Filtres dans Snapchat. (
enfin, au moins quelque chose de sensé! )
Mais l'essentiel, et pas le plus évident: "Il n'y a plus d'idées nouvelles, sinon elles n'apporteront pas de capital instantané". Les réseaux de neurones ont résolu des dizaines de problèmes. Et ils décideront encore plus. Toutes les idées évidentes qui ont donné naissance à de nombreuses startups. Mais tout ce qui était en surface a déjà été collecté. Au cours des deux dernières années, je n'ai pas rencontré une seule nouvelle idée pour l'utilisation des réseaux de neurones. Pas une seule nouvelle approche (enfin, d'accord, il y a quelques problèmes avec les GAN).
Et chaque prochain démarrage est de plus en plus compliqué. Il ne faut plus deux gars qui entraînent un neurone sur les données ouvertes. Cela nécessite des programmeurs, un serveur, une équipe de scribers, un support complexe, etc.
En conséquence, il y a moins de startups. Mais la production est plus. Besoin de joindre une reconnaissance de plaque d'immatriculation? Il existe des centaines de professionnels ayant une expérience pertinente sur le marché. Vous pouvez embaucher et dans quelques mois, votre employé créera un système. Ou achetez-en un fini. Mais faire une nouvelle startup? .. Madness!
Nous devons créer un système de suivi des visiteurs - pourquoi payer pour un tas de licences, alors que vous pouvez faire le vôtre pendant 3-4 mois, affinez-le pour votre entreprise.
Désormais, les réseaux de neurones fonctionnent de la même manière que des dizaines d'autres technologies.
Rappelez-vous comment le concept de "développeur de site" a changé depuis 1995? Certes, le marché n'est pas saturé de spécialistes. Il y a très peu de professionnels. Mais je peux parier que dans 5 à 10 ans, il n'y aura pas beaucoup de différence entre un programmeur Java et un développeur de réseau de neurones. Et ceux-là et ces spécialistes suffiront sur le marché.
Il y aura simplement une classe de tâches qui sont résolues par les neurones. Il y avait une tâche - embaucher un spécialiste.
«Et puis quoi? Où est l'intelligence artificielle promise? "Et ici, il y a un petit mais intéressant neponyatchka :)
La pile technologique qui existe aujourd'hui, apparemment, ne nous mènera toujours pas à l'intelligence artificielle. Les idées, leur nouveauté, se sont largement épuisées. Parlons de ce qui détient le niveau de développement actuel.
Limitations
Commençons par les auto-drones. Il semble être entendu qu'il est possible de fabriquer des voitures entièrement autonomes avec les technologies d'aujourd'hui. Mais après combien d'années cela se produira n'est pas clair. Tesla pense que cela arrivera dans quelques années -
Il existe de nombreux autres
spécialistes qui évaluent cela à 5-10 ans.
Très probablement, à mon avis, après 15 ans, l'infrastructure des villes va elle-même changer pour que l'émergence de voitures autonomes devienne inévitable, sera sa poursuite. Mais cela ne peut pas être considéré comme une intelligence. Tesla moderne est un pipeline très complexe pour filtrer les données, les rechercher et se recycler. Ce sont des règles, des règles, des règles, la collecte de données et des filtres au-dessus d'eux (
ici, j'ai écrit un peu plus à ce sujet, ou regardez à partir de
ce point).
Premier problème
Et c'est ici que nous voyons le
premier problème fondamental . Big data. C'est exactement ce qui a généré la vague actuelle de réseaux de neurones et d'apprentissage automatique. Maintenant, pour faire quelque chose de complexe et automatique, vous avez besoin de beaucoup de données. Pas seulement beaucoup, mais beaucoup. Nous avons besoin d'algorithmes automatisés pour leur collecte, leur balisage, leur utilisation. Nous voulons que la voiture puisse voir les camions contre le soleil - nous devons d'abord en collecter un nombre suffisant. Nous voulons que la voiture ne devienne pas folle avec un vélo vissé au coffre - plus d'échantillons.
De plus, un exemple ne suffit pas. Des centaines? Des milliers?

Deuxième problème
Le deuxième problème est la visualisation de ce que notre réseau de neurones a compris. Il s'agit d'une tâche très simple. Jusqu'à présent, peu de gens savent comment visualiser cela. Ces articles sont très récents, ce ne sont que quelques exemples, même à distance:
Visualisation de la fixation sur les textures. Cela montre bien ce que le neurone a tendance à faire dans les cycles + ce qu'elle perçoit comme information initiale.
 Visualisation de l'
Visualisation de l' atténuation lors des
traductions . En réalité, l'atténuation peut souvent être utilisée précisément pour montrer ce qui a provoqué une telle réaction de réseau. J'ai rencontré de telles choses pour le débogage et pour les solutions de produits. Il y a beaucoup d'articles sur ce sujet. Mais plus les données sont complexes, plus il est difficile de comprendre comment obtenir une visualisation durable.

Eh bien et oui, le bon vieux jeu de "regardez ce que la grille à l'intérieur est dans les
filtres ." Ces photos étaient populaires il y a environ 3 à 4 ans, mais tout le monde s'est vite rendu compte que les photos étaient belles, mais qu'elles n'avaient pas beaucoup de sens.

Je n'ai pas nommé des dizaines d'autres lotions, méthodes, hacks, études sur la façon d'afficher l'intérieur du réseau. Ces outils fonctionnent-ils? Est-ce qu'ils vous aident à comprendre rapidement quel est le problème et à déboguer le réseau? .. Retirez le dernier pour cent? Eh bien, quelque chose comme ça:

Vous pouvez regarder n'importe quel concours sur Kaggle. Et une description de la façon dont les gens prennent les décisions finales. Nous sommes arrivés 100-500-800 modèle mulenov et cela a fonctionné!
Bien sûr, j'exagère. Mais ces approches ne donnent pas de réponses rapides et directes.
Ayant suffisamment d'expérience, ayant poussé différentes options, vous pouvez rendre un verdict sur les raisons pour lesquelles votre système a pris une telle décision. Mais corriger le comportement du système sera difficile. Mettez une béquille, déplacez le seuil, ajoutez un jeu de données, prenez un autre réseau backend.
Troisième problème
Le troisième problème fondamental est que les grilles n'enseignent pas la logique, mais les statistiques. Statistiquement, cette
personne :

Logiquement - pas très similaire. Les réseaux de neurones n'apprennent pas quelque chose de compliqué s'ils ne sont pas forcés. Ils apprennent toujours les symptômes les plus simples. Vous avez les yeux, le nez, la tête? Alors ce visage! Ou donnez un exemple où les yeux ne signifieront pas le visage. Et encore une fois, des millions d'exemples.
Il y a beaucoup de place en bas
Je dirais que ce sont ces trois problèmes mondiaux qui limitent aujourd'hui le développement des réseaux de neurones et le machine learning. Et où ces problèmes n'étaient pas limités à est déjà activement utilisé.
Est-ce la fin? Les réseaux de neurones se sont levés?Inconnu Mais, bien sûr, tout le monde espère que non.
Il existe de nombreuses approches et directions pour résoudre ces problèmes fondamentaux que j'ai abordés ci-dessus. Mais jusqu'à présent, aucune de ces approches ne nous a permis de faire quelque chose de fondamentalement nouveau, de résoudre quelque chose qui n'a pas encore été résolu. Jusqu'à présent, tous les projets fondamentaux se font sur la base d'approches stables (Tesla), ou restent des projets tests d'instituts ou d'entreprises (Google Brain, OpenAI).
En gros, la direction principale est la création d'une représentation de haut niveau des données d'entrée. Dans un sens, la «mémoire». L'exemple le plus simple de la mémoire est les diverses représentations «enrobées» d'images. Eh bien, par exemple, tous les systèmes de reconnaissance faciale. Le réseau apprend à obtenir du visage une certaine idée stable qui ne dépend pas de la rotation, de l'éclairage, de la résolution. En fait, le réseau minimise la métrique de «visages différents - éloignés» et «identiques - proches».

Une telle formation nécessite des dizaines et des centaines de milliers d'exemples. Mais le résultat apporte quelques rudiments de «One-shot Learning». Maintenant, nous n'avons pas besoin de centaines de visages pour nous souvenir d'une personne. Un seul visage, et c'est tout - nous le saurons!
Seul le problème se pose ... La grille ne peut apprendre que des objets assez simples. Lorsqu'on essaie de distinguer non pas des visages, mais, par exemple, des «personnes par des vêtements» (la
tâche de ré-identification ), la qualité échoue de plusieurs ordres de grandeur. Et le réseau ne peut plus apprendre suffisamment de changements d'angle évidents.
Et apprendre à partir de millions d'exemples est aussi en quelque sorte un divertissement moyen.
Il y a du travail pour réduire considérablement l'élection. Par exemple, vous pouvez immédiatement rappeler l'un des premiers
travaux d' apprentissage de Google OneShot :
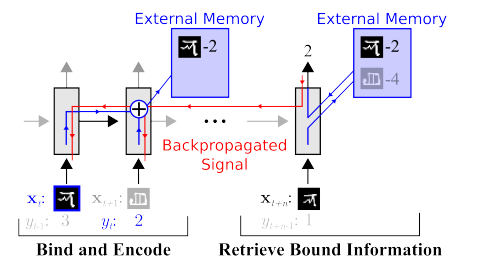
Il existe de nombreuses œuvres de ce type, par exemple
1 ou
2 ou
3 .
Il y a un inconvénient - la formation fonctionne généralement bien sur quelques «exemples MNIST'ovskie» simples. Et dans la transition vers des tâches complexes - vous avez besoin d'une grande base, d'un modèle d'objets ou d'une sorte de magie.
En général, le travail sur la formation One-Shot est un sujet très intéressant. Vous trouvez beaucoup d'idées. Mais pour la plupart, les deux problèmes que j'ai énumérés (pré-formation sur un énorme ensemble de données / instabilité sur des données complexes) entravent très fortement l'apprentissage.
D'un autre côté, le GAN - réseaux générativement compétitifs - approche de l'intégration. Vous avez probablement lu un tas d'articles sur ce sujet sur Habré. (
1 ,
2 ,
3 )
Une caractéristique du GAN est la formation d'un espace d'état interne (essentiellement le même incorporation), qui vous permet de dessiner une image. Il peut s'agir de
personnes , il peut y avoir des
actions .
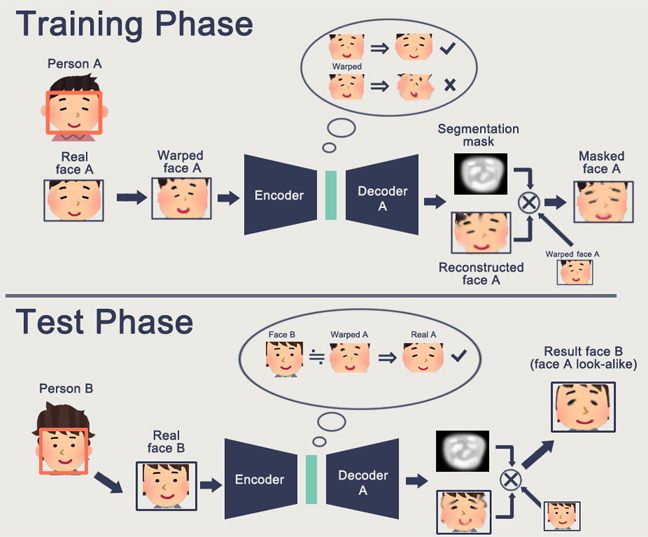
Le problème du GAN est que plus l'objet généré est complexe, plus il est difficile de le décrire dans la logique «générateur-discriminateur». En conséquence, à partir d'applications réelles de GAN, qui ne sont entendues que DeepFake, qui, encore une fois, manipule les représentations des individus (pour lesquels il existe une énorme base).
J'ai rencontré très peu d'autres applications utiles. Habituellement, une sorte de faux coup de sifflet avec des dessins.
Et encore. Personne ne sait comment cela nous permettra d'avancer vers un avenir meilleur. Représenter la logique / l'espace dans un réseau neuronal est bon. Mais nous avons besoin d'un grand nombre d'exemples, nous ne comprenons pas comment ce neurone se représente en lui-même, nous ne comprenons pas comment faire en sorte que le neurone se souvienne d'une idée vraiment compliquée.
L'apprentissage par renforcement est une approche complètement différente. Vous vous souvenez sûrement de la façon dont Google a battu tout le monde dans Go. Victoires récentes dans Starcraft et Dota. Mais ici, tout est loin d'être aussi rose et prometteur. La meilleure chose à propos de RL et de sa complexité est
cet article .
Pour résumer brièvement ce que l'auteur a écrit:
- Les modèles prêts à l'emploi ne correspondent pas / fonctionnent mal dans la plupart des cas
- Les tâches pratiques sont plus faciles à résoudre par d'autres moyens. Boston Dynamics n'utilise pas RL en raison de sa complexité / imprévisibilité / complexité de calcul
- Pour que RL fonctionne, vous avez besoin d'une fonction complexe. Il est souvent difficile de créer / écrire.
- Il est difficile de former des modèles. Nous devons passer beaucoup de temps à nous balancer et à sortir des optima locaux
- En conséquence, il est difficile de répéter le modèle, l'instabilité du modèle au moindre changement
- Il déborde souvent sur certains motifs de gauche, jusqu'au générateur de nombres aléatoires
Le point clé est que RL ne fonctionne pas encore en production. Google a une sorte d'expériences (
1 ,
2 ). Mais je n'ai pas vu un seul système d'épicerie.
La mémoire L'inconvénient de tout ce qui est décrit ci-dessus n'est pas structuré. Une approche pour essayer de ranger tout cela est de fournir au réseau neuronal un accès à une mémoire séparée. Pour qu'elle puisse y enregistrer et réécrire les résultats de ses pas. Ensuite, le réseau neuronal peut être déterminé par l'état actuel de la mémoire. C'est très similaire aux processeurs et ordinateurs classiques.
L'article le plus célèbre et le plus populaire est de DeepMind:
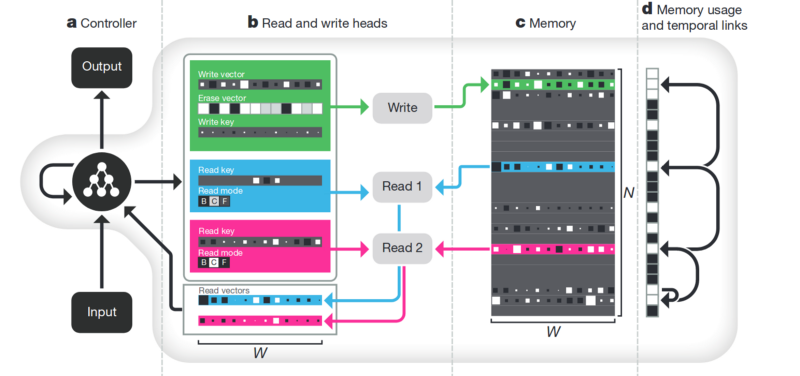
Il semble que la voici, la clé pour comprendre l'intelligence? Mais plutôt non. Le système a encore besoin d'une énorme quantité de données pour la formation. Et cela fonctionne principalement avec des données tabulaires structurées. En même temps, lorsque Facebook a
résolu un problème similaire, ils sont allés dans le sens "voir la mémoire, rendre le neurone plus compliqué, mais plus d'exemples, et il apprendra tout seul".
Désenchevêtrement . Une autre façon de créer une mémoire significative est de prendre les mêmes intégrations, mais en apprenant à introduire des critères supplémentaires qui vous permettraient de mettre en évidence des «significations». Par exemple, nous voulons former un réseau de neurones pour distinguer le comportement d'une personne dans un magasin. Si nous devions suivre le chemin standard, il faudrait faire une dizaine de réseaux. L'un cherche une personne, le second détermine ce qu'il fait, le troisième est son âge, le quatrième est le sexe. Une logique distincte regarde la partie du magasin où il fait / apprend pour cela. Le troisième détermine sa trajectoire, etc.
Ou, s'il y avait infiniment beaucoup de données, alors il serait possible de former un réseau pour toutes sortes de résultats (il est évident qu'un tel tableau de données ne peut pas être saisi).
L'approche de la dissociation nous le dit - et formons le réseau pour qu'il puisse lui-même distinguer les concepts. Pour qu'elle puisse former une intégration dans la vidéo, où une zone déterminerait l'action, une - la position sur le sol dans le temps, une - la taille de la personne et une autre - son sexe. En même temps, lors de la formation, je ne voudrais presque jamais suggérer de tels concepts clés au réseau, mais pour qu'il identifie et regroupe les domaines. Il y a peu d'articles de ce type (certains sont
1 ,
2 ,
3 ) et en général, ils sont assez théoriques.
Mais cette direction, au moins théoriquement, devrait couvrir les problèmes énumérés au début.
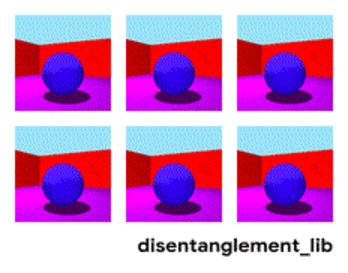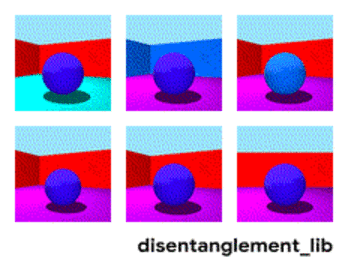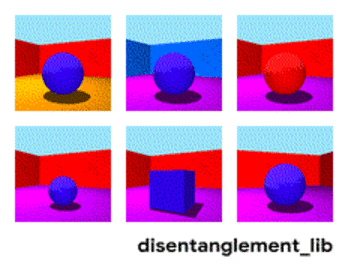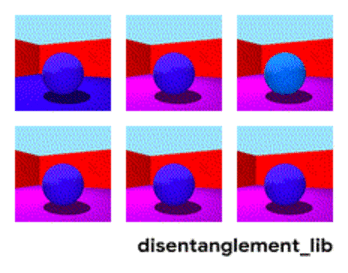
Décomposition de l'image selon les paramètres "couleur du mur / couleur du sol / forme de l'objet / couleur de l'objet / etc."

Décomposition du visage selon les paramètres «taille, sourcils, orientation, couleur de peau, etc.»
Autre
Il existe de nombreuses autres directions moins globales qui nous permettent de réduire en quelque sorte la base, de travailler avec des données plus hétérogènes, etc.
Attention . Il n'est probablement pas logique d'isoler cela en tant que méthode distincte. Juste une approche qui renforce les autres. De nombreux articles lui ont été consacrés (
1 ,
2 ,
3 ). Le sens de l'attention est de renforcer la réponse du réseau aux objets significatifs pendant la formation. Souvent par une désignation de cible externe ou un petit réseau externe.
Simulation 3D . Si vous faites un bon moteur 3D, vous pouvez souvent fermer 90% des données d'entraînement avec (j'ai même vu un exemple où près de 99% des données étaient fermées avec un bon moteur). Il existe de nombreuses idées et astuces sur la façon de faire fonctionner un réseau formé sur un moteur 3D sur des données réelles (réglage fin, transfert de style, etc.). Mais souvent, faire un bon moteur est plus difficile de plusieurs ordres de grandeur que de collecter des données. Exemples lors de la fabrication de moteurs:
Formation de robot (
google ,
braingarden )
Apprendre à
reconnaître des marchandises dans un magasin (mais dans deux projets que nous avons réalisés, nous nous en sommes tranquillement dispensés).
Entraînement chez Tesla (encore une fois, la vidéo ci-dessus).
Conclusions
L'article dans son ensemble est en quelque sorte des conclusions. Le message principal que je voulais faire était probablement "le cadeau est terminé, les neurones ne donnent pas de solutions plus simples". Nous devons maintenant travailler dur pour créer des solutions complexes. Ou travaillez dur pour rédiger des rapports scientifiques complexes.
En général, le sujet est discutable. Peut-être que les lecteurs ont des exemples plus intéressants?