Au lieu de rejoindre
Plus tôt dans notre blog, nous avons écrit
ce que fait IPONWEB - nous automatisons l'affichage des publicités sur Internet. Nos systèmes prennent des décisions non seulement sur la base de données historiques, mais utilisent également activement les informations obtenues en temps réel. Dans le cas de DSP (Demand Side Platform - une plate-forme publicitaire pour les annonceurs), l'annonceur (ou son représentant) doit créer et télécharger une bannière publicitaire (créative) dans l'un des formats (image, vidéo, bannière interactive, image + texte, etc.) , sélectionnez l'audience des utilisateurs auxquels cette bannière sera affichée, déterminez combien de fois il est possible d'afficher de la publicité à un utilisateur, dans quels pays, sur quels sites, sur quels appareils, et reflétez cela (et bien plus) dans les paramètres de ciblage de la campagne publicitaire, ainsi que de diffuser de la publicité le budget s. Pour SSP (Supply Side Platform - une plateforme publicitaire pour les propriétaires de plateformes publicitaires), le propriétaire du site (application mobile, panneau d'affichage, chaîne de télévision) doit déterminer les spots publicitaires sur son site et indiquer, par exemple, les catégories de publicités qu'il est prêt à y afficher. Tous ces paramètres sont définis manuellement à l'avance (pas au moment de l'affichage des annonces) à l'aide de l'interface utilisateur. Dans cet article, je parlerai de notre approche de la construction de telles interfaces, à condition qu'elles soient nombreuses, qu'elles soient similaires les unes aux autres et aient en même temps des caractéristiques individuelles.
Comment tout a commencé
Nous avons commencé à faire de la publicité en 2007, mais nous n'avons pas fait d'interfaces immédiatement, mais seulement en 2014. Nous sommes traditionnellement engagés dans le développement de plates-formes personnalisées qui sont entièrement conçues conformément aux spécificités de l'entreprise de chaque client individuel - parmi les dizaines de plates-formes que nous avons construites, il n'y en a pas deux identiques. Et comme nos plateformes publicitaires ont été conçues sans restrictions sur les possibilités de personnalisation, l'interface utilisateur devait répondre aux mêmes exigences.
Lorsque nous avons reçu la première demande d'interface publicitaire pour DSP il y a cinq ans, notre choix s'est porté sur la pile technologique populaire et pratique: JavaScript et AngularJS à l'avant, et le backend sur Python, Django et Django Rest Framework (DRF). À partir de là, le projet le plus ordinaire a été réalisé, dont la tâche principale était de fournir la fonctionnalité CRUD. Le résultat de son travail était un fichier de paramètres pour le système de publicité au format XML. Maintenant, un tel protocole d'interaction peut sembler étrange, mais, comme nous l'avons déjà mentionné, les premiers systèmes publicitaires (même sans interface utilisateur), nous avons commencé à construire dans les «zéro», et ce format a été conservé à ce jour.
Après le lancement réussi du premier projet, ce qui suit n'a pas tardé. Il s'agissait également de l'interface utilisateur du DSP et les conditions requises étaient les mêmes que pour le premier projet. Presque. Malgré le fait que tout était très similaire, le diable se cachait dans les détails - il y a une hiérarchie d'objets légèrement différente, quelques champs y sont ajoutés ... La façon la plus évidente d'obtenir le deuxième projet, très similaire au premier, mais avec des améliorations, était la méthode de réplication, que nous avons utilisée . Et cela a entraîné des problèmes familiers à beaucoup - avec le «bon» code, des bogues ont également été copiés, dont les correctifs devaient être distribués à la main. La même chose s'est produite avec toutes les nouvelles fonctionnalités déployées sur tous les projets actifs.
Dans ce mode, il était possible de travailler alors qu'il y avait peu de projets, mais lorsque leur nombre dépassait 20, l'approche familière cessait de se développer. Par conséquent, nous avons décidé de transférer les parties communes des projets vers la bibliothèque, à partir de laquelle le projet connectera les composants dont il a besoin. Si un bogue est détecté, il est réparé une fois dans la bibliothèque et est automatiquement distribué aux projets lorsque la version de la bibliothèque est mise à jour, et la même chose se produit avec la réutilisation de nouvelles fonctionnalités.
Configuration et terminologie
Nous avons eu plusieurs itérations dans la mise en œuvre de cette approche, et elles se sont toutes coulées de manière évolutive, à commencer par notre projet habituel sur DRF pur. Dans la dernière implémentation, notre projet est décrit en utilisant DSL basé sur JSON (voir photo). Ce JSON décrit à la fois la structure des composants du projet et leurs interconnexions, et le frontend et le backend peuvent le lire.
Après avoir initialisé l'application Angular, le frontend demande une configuration JSON au backend. Le backend ne donne pas seulement un fichier de configuration statique, mais le traite en plus, en le complétant avec diverses métadonnées ou en supprimant des parties de la configuration qui sont responsables de parties du système inaccessibles à l'utilisateur. Cela vous permet de montrer l'interface à différents utilisateurs de différentes manières, y compris les formulaires interactifs, les styles CSS de l'application entière et des éléments de conception spécifiques. Ce dernier est particulièrement vrai pour les interfaces utilisateur des plates-formes qui sont utilisées par différents types de clients avec différents rôles et niveaux d'accès.

Le backend, contrairement au frontend, lit la configuration une fois lors de la phase d'initialisation de l'application Django. Ainsi, la quantité complète de fonctionnalités est enregistrée sur le backend, et l'accès aux différentes parties du système est vérifié à la volée.
Avant de passer à la partie la plus intéressante - la structure de la base de données - je veux introduire plusieurs concepts que nous utilisons lorsque nous parlons de la structure de nos projets afin d'être sur la même longueur d'onde avec le lecteur.
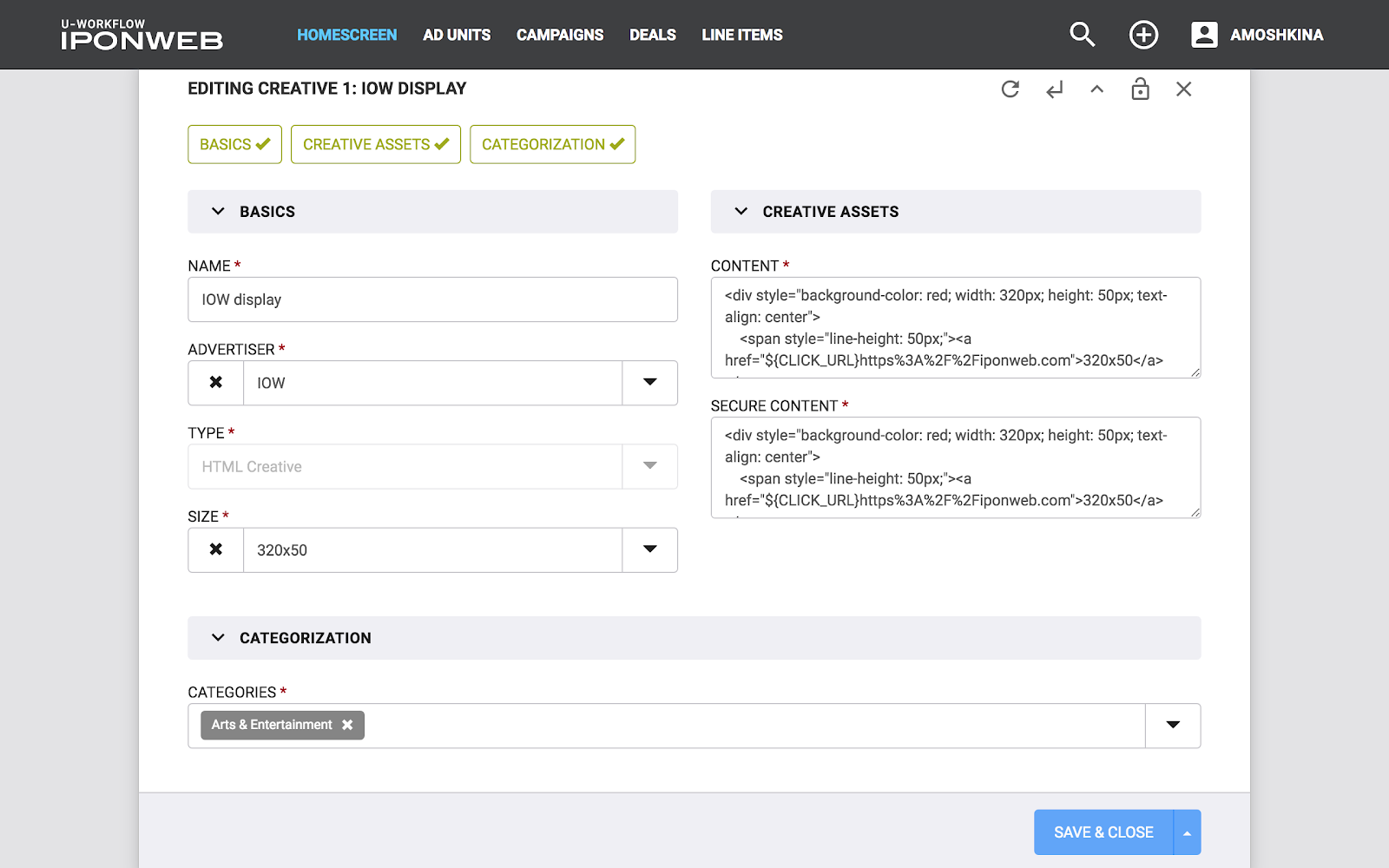
Ces concepts - Entité et Fonction - sont bien illustrés sur le formulaire de saisie des données (voir photo). Le formulaire entier est Entité et les champs individuels sur celui-ci sont Entité. L'image montre également Endpoint (juste au cas où). Ainsi, Entity est un objet indépendant dans le système sur lequel les opérations CRUD peuvent être effectuées, tandis que Feature n'est qu'une partie de «quelque chose de plus», une partie d'Entity. Avec Feature, vous ne pouvez pas effectuer d'opérations CRUD sans être lié à une entité. Par exemple: le budget d'une campagne publicitaire sans référence à la campagne elle-même est simplement un nombre qui ne peut pas être utilisé sans informations sur la campagne parent.
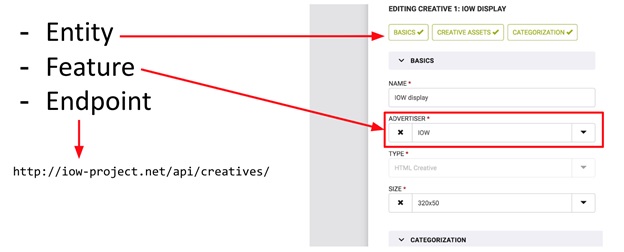
Les mêmes concepts peuvent être trouvés dans la configuration JSON du projet (voir l'image).

Structure de la base de données
La partie la plus intéressante de nos projets est la structure de la base de données et les mécanismes qui la supportent. Ayant commencé à utiliser PostgreSQL pour les toutes premières versions de nos projets, nous restons avec cette technologie aujourd'hui. Parallèlement à cela, nous utilisons activement Django ORM. Dans les premières implémentations, nous avons utilisé le modèle standard de relations entre les objets (entités) sur la clé étrangère, cependant, cette approche a causé des difficultés lorsqu'il était nécessaire de changer la hiérarchie des relations. Ainsi, par exemple, dans la hiérarchie standard de la Business Unit DSP -> Annonceur -> Campagne, certains clients devaient entrer au niveau Agence (Business Unit -> Agence -> Annonceur -> ...). Par conséquent, nous avons progressivement abandonné l'utilisation de la clé étrangère et organisé les liens entre les objets à l'aide de liens Many To Many via une table distincte, nous l'appelons `LinkRegistry`.
De plus, nous avons progressivement abandonné le code dur pour remplir les entités et commencé à stocker la plupart des champs dans des tableaux séparés, en les liant également via `LinkRegistry` (voir photo). Pourquoi était-ce nécessaire? Pour chaque client, le contenu de l'entité peut varier - certains champs seront ajoutés ou supprimés. Il s'avère que nous devrons stocker dans chaque entité un surensemble de champs pour tous nos clients. En même temps, ils devront tous être rendus facultatifs, afin que les champs obligatoires «étrangers» n'interfèrent pas avec le travail.

Prenons l'exemple de l'image: ici, la structure de la base de données pour la création avec un champ supplémentaire est décrite - `image_url`. Seul son identifiant est stocké dans la table des créations et image_url est stocké dans une table distincte, leur relation est décrite par une autre entrée dans la table LinkRegistry. Ainsi, cette création sera décrite par trois entrées, une dans chacun des tableaux. En conséquence, afin de sauvegarder une telle création, vous devez faire une entrée dans chacun d'eux, et pour la lire de la même manière, visitez 3 tableaux. Il serait très gênant d'écrire un tel traitement à chaque fois à partir de zéro, donc notre bibliothèque résume tous ces détails du programmeur. Pour travailler avec des données, Django et DRF utilisent des modèles et des sérialiseurs décrits par code. Dans nos projets, l'ensemble des champs dans les modèles et les sérialiseurs est déterminé lors de l'exécution par la configuration JSON, les classes de modèle sont créées dynamiquement (à l'aide de la fonction type) et stockées dans un registre spécial, d'où elles sont disponibles pendant le fonctionnement de l'application. Nous utilisons également des classes de base spéciales pour ces modèles et sérialiseurs, qui aident à travailler avec une structure de base non standard.
Lors de l'enregistrement d'un nouvel objet (ou de la mise à jour d'un objet existant), les données reçues du frontal pénètrent dans le sérialiseur, où elles sont validées - il n'y a rien d'inhabituel, les mécanismes DRF standard fonctionnent. Mais la sauvegarde et la mise à jour sont redéfinies ici. Le sérialiseur sait toujours avec quel modèle il travaille et, selon la représentation interne de notre modèle dynamique, il peut comprendre dans quelle table les données du champ suivant doivent être insérées. Nous encodons ces informations dans des champs de modèle personnalisés (rappelez-vous comment la «ForeignKey» est décrite dans Django - un modèle connexe est passé à l'intérieur du champ, nous faisons de même). Dans ces champs spéciaux, nous résumons également la nécessité d'ajouter un troisième enregistrement de liaison à LinkRegistry à l'aide du mécanisme de descripteur - dans le code que vous écrivez `creative.image_url = 'http: // foo.bar' ', et dans la méthode substituée __set__ dans laquelle nous écrivons `LinkRegistry`.
Cela s'applique à l'écriture dans la base de données. Et maintenant, parlons de lecture. Comment un tuple extrait d'une base de données est-il converti en une instance de modèle Django? Dans le modèle Django de base, il existe une méthode `from_db`, qui est appelée pour chaque tuple reçu lors de l'exécution d'une requête dans` queryset`. En entrée, il reçoit un tuple et retourne l'instance du modèle Django. Nous avons redéfini cette méthode dans notre modèle de base, où selon le tuple du modèle principal (où seul «id» entre), nous obtenons des données d'autres tables connexes et, ayant cet ensemble complet, nous instancions le modèle. Bien sûr, nous avons également travaillé pour optimiser le mécanisme de prélecture Django pour notre cas d'utilisation non standard.
Test
Notre framework est assez complexe, nous écrivons donc beaucoup de tests. Nous avons des tests pour le frontend et le backend. Je m'attarderai sur les tests backend en détail.
Pour exécuter les tests, nous utilisons pytest. Sur le backend, nous avons deux grandes classes de tests: les tests de notre framework (nous l'appelons aussi le «core») et les tests de projet.
Dans le noyau, nous écrivons à la fois des tests unitaires isolés et des tests fonctionnels pour tester les points de terminaison à l'aide du plugin pytest-django. En général, tout travail avec la base de données est principalement testé par le biais de requêtes à l'API - comme cela se produit en production.
Les tests fonctionnels peuvent spécifier une configuration JSON. Afin de ne pas être attaché à la terminologie de conception, nous utilisons des noms «factices» pour les entités avec lesquelles nous testons nos fonctionnalités dans le noyau («Emma», «Alla», «Karl», «Maria», etc.). Puisque, en écrivant la fonctionnalité image_url, nous ne voulons pas limiter la conscience du développeur au fait qu'elle ne peut être utilisée qu'avec l'entité créative - les fonctionnalités et les entités sont universelles, et elles peuvent être connectées les unes aux autres dans toutes les combinaisons pertinentes pour un client particulier.
En ce qui concerne les projets de test, tous les cas de test sont exécutés avec la configuration de production, pas d'entités factices, car il est important pour nous de vérifier exactement avec quoi le client travaillera. Dans le projet, vous pouvez écrire tous les tests qui couvriront les fonctionnalités de la logique métier du projet. En même temps, les tests CRUD de base peuvent être connectés au projet à partir du noyau. Ils sont écrits de manière générale et peuvent être connectés à n'importe quel projet: un test de fonctionnalité peut lire la configuration JSON d'un projet, déterminer à quelles entités cette fonctionnalité est connectée et exécuter des vérifications uniquement pour les entités nécessaires. Pour faciliter la préparation des données de test, nous avons développé un système d'aides qui sont également en mesure de préparer des jeux de données de test basés sur la configuration JSON. Une place particulière dans les tests de projet est occupée par les tests E2E sur Protractor, qui testent toutes les fonctions de base du projet. Ces tests sont également décrits à l'aide de JSON, ils sont écrits et pris en charge par les développeurs front-end.
Postface
Dans cet article, nous avons examiné l'approche de conception modulaire développée par IPONWEB dans le département UI. Cette solution fonctionne avec succès en production depuis trois ans. Cependant, cette solution présente encore un certain nombre de limites qui ne nous permettent pas de nous reposer sur nos lauriers. Premièrement, notre base de code est encore assez complexe. Deuxièmement, le code de base qui prend en charge les modèles dynamiques est associé à des composants critiques tels que la recherche, le chargement en bloc d'objets, les droits d'accès et autres. De ce fait, les modifications de l'un des composants peuvent affecter de manière significative les autres. Afin de nous débarrasser de ces restrictions, nous continuons de traiter activement notre bibliothèque, en la divisant en plusieurs parties indépendantes et en réduisant la complexité du code. Nous vous informerons des résultats dans les articles suivants.
Cet article est une transcription étendue de ma présentation à MoscowPythonConf ++ 2019, je partage donc également des liens vers des
vidéos et des
diapositives .