C ++ Enterprise Edition
Qu'est-ce que "l'édition entreprise"
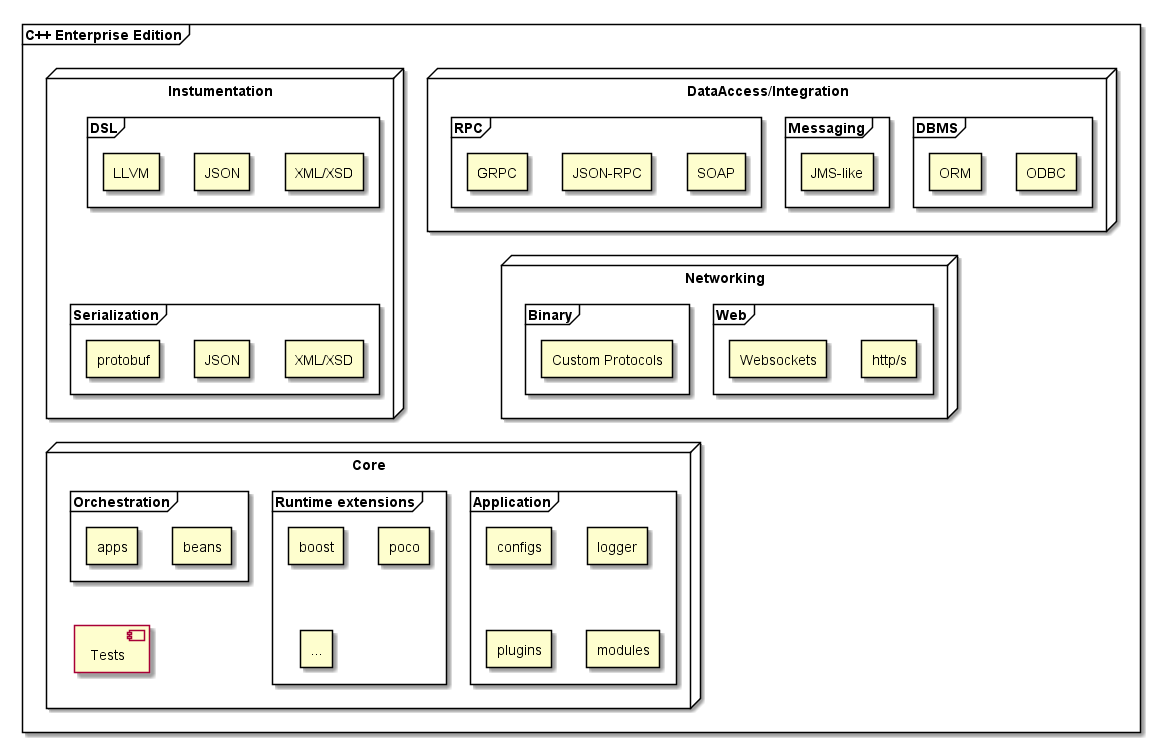
Étonnamment, pendant tout le temps que j'ai travaillé dans l'informatique, je n'ai jamais entendu personne dire «édition entreprise» à propos d'un langage de programmation, à l'exception de Java. Mais après tout, les gens écrivent des applications pour le segment d'entreprise dans de nombreux langages de programmation, et les entités sur lesquelles les programmeurs opèrent, sinon identiques, sont similaires. Et pour le c ++ en particulier, je voudrais combler le vide de l'entrepreneuriat, au moins en parler.
En ce qui concerne le C ++, "l'édition entreprise" est un sous-ensemble du langage et des bibliothèques qui vous permet de développer "rapidement" des applications [multiplates-formes] pour des systèmes modulaires à couplage lâche avec une architecture distribuée et / ou en cluster et avec une logique métier appliquée et, en règle générale, une charge élevée.
Pour continuer notre conversation, il faut tout d'abord introduire les concepts d' application , de module et de plug-in
- Une application est un fichier exécutable qui peut fonctionner comme un service système, a sa propre configuration, peut accepter des paramètres d'entrée et peut avoir une structure de plug-in modulaire.
- Un module est une implémentation d'une interface qui vit à l'intérieur d'une application ou d'une logique métier.
- Un plugin est une bibliothèque chargée dynamiquement qui implémente une ou plusieurs interfaces, ou une partie d'une logique métier.
Toutes les applications, effectuant leur travail unique, ont généralement besoin de mécanismes à l'échelle du système, tels que l'accès aux données (SGBD), l'échange d'informations via un bus commun (JMS), l'exécution de scripts distribués et locaux avec préservation de la cohérence (transactions), le traitement des demandes venant par exemple, via le protocole http (s) (fastcgi) ou via des websockets, etc.
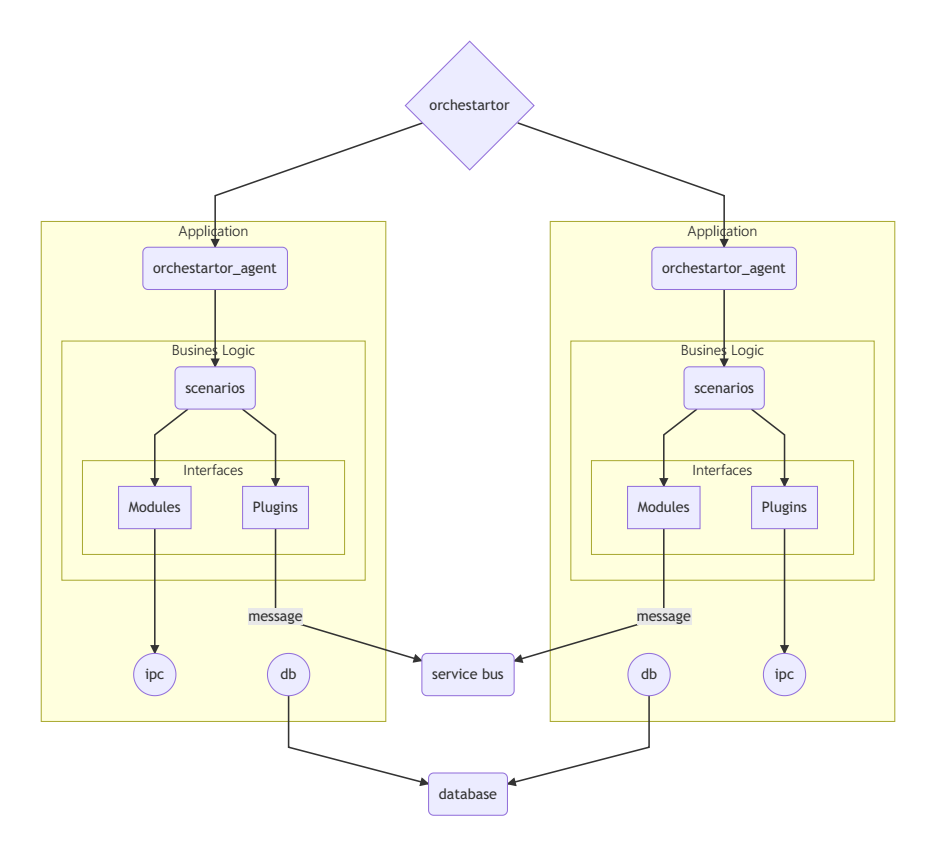
Un exemple d'un système distribué faiblement connecté
App
Un exemple de schéma d'application de serveur d'entreprise d'entreprise.

J'ai déjà donné une définition générale de l'application, alors voyons ce qu'il en est maintenant dans le monde C ++ pour implémenter ce concept. Les premiers à montrer la mise en œuvre de l'application étaient des cadres graphiques tels que Qt et GTK, mais leurs versions d'application supposaient initialement que l'application était une «fenêtre» graphique avec son contexte et ce n'est qu'après un certain temps qu'une vision générale de l'application est apparue, y compris en tant que service système, par exemple, qtservice . Mais je ne veux pas vraiment faire glisser un cadre graphique conditionnel pour une tâche de service, alors regardons vers les bibliothèques non graphiques. Et boost vient en premier ... Mais malheureusement, la liste des bibliothèques officielles ne comprend pas Boost.Application et autres. Il existe un projet distinct Boost.Application . Le projet est très intéressant, mais, à mon avis, bavard, bien que l'idéologie du boost soit respectée. Voici un exemple d'application de Boost.
#define BOOST_ALL_DYN_LINK #define BOOST_LIB_DIAGNOSTIC #define BOOST_APPLICATION_FEATURE_NS_SELECT_BOOST #include <fstream> #include <iostream> #include <boost/application.hpp> using namespace boost; // my application code class myapp { public: myapp(application::context& context) : context_(context) {} void worker() { // ... while (st->state() != application::status::stopped) { boost::this_thread::sleep(boost::posix_time::seconds(1)); if (st->state() == application::status::paused) my_log_file_ << count++ << ", paused..." << std::endl; else my_log_file_ << count++ << ", running..." << std::endl; } } // param int operator()() { // launch a work thread boost::thread thread(&myapp::worker, this); context_.find<application::wait_for_termination_request>()->wait(); return 0; } bool stop() { my_log_file_ << "Stoping my application..." << std::endl; my_log_file_.close(); return true; // return true to stop, false to ignore } private: std::ofstream my_log_file_; application::context& context_; }; int main(int argc, char* argv[]) { application::context app_context; // auto_handler will automatically add termination, pause and resume (windows) // handlers application::auto_handler<myapp> app(app_context); // to handle args app_context.insert<application::args>( boost::make_shared<application::args>(argc, argv)); // my server instantiation boost::system::error_code ec; int result = application::launch<application::server>(app, app_context, ec); if (ec) { std::cout << "[E] " << ec.message() << " <" << ec.value() << "> " << std::endl; } return result; }
L'exemple ci-dessus définit l'application myapp avec son thread de travail principal et le mécanisme de lancement de cette application.
En plus, je vais donner un exemple similaire du framework pocoproject
#include <iostream> #include <sstream> #include "Poco/AutoPtr.h" #include "Poco/Util/AbstractConfiguration.h" #include "Poco/Util/Application.h" #include "Poco/Util/HelpFormatter.h" #include "Poco/Util/Option.h" #include "Poco/Util/OptionSet.h" using Poco::AutoPtr; using Poco::Util::AbstractConfiguration; using Poco::Util::Application; using Poco::Util::HelpFormatter; using Poco::Util::Option; using Poco::Util::OptionCallback; using Poco::Util::OptionSet; class SampleApp : public Application { public: SampleApp() : _helpRequested(false) {} protected: void initialize(Application &self) { loadConfiguration(); Application::initialize(self); } void uninitialize() { Application::uninitialize(); } void reinitialize(Application &self) { Application::reinitialize(self); } void defineOptions(OptionSet &options) { Application::defineOptions(options); options.addOption( Option("help", "h", "display help information on command line arguments") .required(false) .repeatable(false) .callback(OptionCallback<SampleApp>(this, &SampleApp::handleHelp))); } void handleHelp(const std::string &name, const std::string &value) { _helpRequested = true; displayHelp(); stopOptionsProcessing(); } void displayHelp() { HelpFormatter helpFormatter(options()); helpFormatter.setCommand(commandName()); helpFormatter.setUsage("OPTIONS"); helpFormatter.setHeader( "A sample application that demonstrates some of the features of the " "Poco::Util::Application class."); helpFormatter.format(std::cout); } int main(const ArgVec &args) { if (!_helpRequested) { logger().information("Command line:"); std::ostringstream ostr; logger().information(ostr.str()); logger().information("Arguments to main():"); for (const auto &it : args) { logger().information(it); } } return Application::EXIT_OK; } private: bool _helpRequested; }; POCO_APP_MAIN(SampleApp)
J'attire votre attention sur le fait que l'application doit contenir des mécanismes de journalisation, de téléchargement des configurations et des options de traitement.
Par exemple, pour traiter les options, il existe:
Pour configurer:
Pour la journalisation:
Faiblesse, modules et plugins.
La faiblesse du système "corporate" est la possibilité d'une substitution rapide et indolore de certains mécanismes. Cela s'applique à la fois aux modules de l'application et aux applications elles-mêmes, ainsi qu'aux implémentations, par exemple, les microservices. Qu'avons-nous, du point de vue du C ++. Tout est mauvais avec les modules, bien qu'ils implémentent des interfaces, mais ils vivent dans une application «compilée», donc il n'y aura pas de changement rapide, mais les plugins viennent à la rescousse! À l'aide de bibliothèques dynamiques, vous pouvez non seulement organiser une substitution rapide, mais également le fonctionnement simultané de deux versions différentes. Il existe tout un monde d '"appel de procédure à distance", alias RPC. Les mécanismes de recherche des implémentations d'interface, couplés à RPC, ont engendré quelque chose de similaire à OSGI du monde Java. C'est formidable d'avoir un support pour cela dans l'écosystème C ++ et il y en a un, voici quelques exemples:
Exemple de module pour le "serveur d'application" POCO OSP
#include "Poco/OSP/BundleActivator.h" #include "Poco/OSP/BundleContext.h" #include "Poco/ClassLibrary.h" namespace HelloBundle { class BundleActivator: public Poco::OSP::BundleActivator { public: void start(Poco::OSP::BundleContext::Ptr pContext) { pContext->logger().information("Hello, world!"); } void stop(Poco::OSP::BundleContext::Ptr pContext) { pContext->logger().information("Goodbye!"); } }; }
Exemple de module pour le "serveur d'applications" Apache Celix
#include "Bar.h" #include "BarActivator.h" using namespace celix::dm; DmActivator* DmActivator::create(DependencyManager& mng) { return new BarActivator(mng); } void BarActivator::init() { std::shared_ptr<Bar> bar = std::shared_ptr<Bar>{new Bar{}}; Properties props; props["meta.info.key"] = "meta.info.value"; Properties cProps; cProps["also.meta.info.key"] = "also.meta.info.value"; this->cExample.handle = bar.get(); this->cExample.method = [](void *handle, int arg1, double arg2, double *out) { Bar* bar = static_cast<Bar*>(handle); return bar->cMethod(arg1, arg2, out); }; mng.createComponent(bar) //using a pointer a instance. Also supported is lazy initialization (default constructor needed) or a rvalue reference (move) .addInterface<IAnotherExample>(IANOTHER_EXAMPLE_VERSION, props) .addCInterface(&this->cExample, EXAMPLE_NAME, EXAMPLE_VERSION, cProps) .setCallbacks(&Bar::init, &Bar::start, &Bar::stop, &Bar::deinit); }
Il convient de noter que dans les systèmes distribués faiblement connectés, il est nécessaire de disposer de mécanismes qui assurent les opérations transactionnelles, mais pour le moment il n'y a rien de similaire pour C ++. C'est-à-dire tout comme il n'y a aucun moyen à l'intérieur d'une application de faire une demande à la base de données, au fichier et à l'esb dans une transaction, il n'y a pas un tel moyen pour les opérations distribuées. Bien sûr, tout peut être écrit, mais il n'y a rien de généralisé. Quelqu'un dira qu'il existe une software transactional memory , oui, bien sûr, mais cela ne fera que faciliter l'écriture des mécanismes de transaction par lui-même.
Boîte à outils
De tous les nombreux outils auxiliaires, je veux mettre en évidence la sérialisation et DSL, car leur présence vous permet d'implémenter de nombreux autres composants et scénarios.
Sérialisation
La sérialisation est le processus de traduction d'une structure de données en une séquence de bits. L'inverse de l'opération de sérialisation est l'opération de désérialisation (structuration) - restauration de l'état initial de la structure de données à partir de la séquence de bits wikipedia . Dans le contexte de C ++, il est important de comprendre qu'aujourd'hui il n'y a aucun moyen de sérialiser des objets et de les transférer vers un autre programme qui ne connaissait auparavant rien de cet objet. Dans ce cas, je veux dire un objet en tant qu'implémentation d'une certaine classe avec des champs et des méthodes. Par conséquent, je vais souligner deux approches principales utilisées dans le monde C ++:
- sérialisation au format binaire
- sérialisation au format formel
Dans la littérature et sur Internet, il y a souvent une séparation entre les formats binaire et texte, mais je pense que cette séparation n'est pas entièrement correcte, par exemple, MsgPack ne sauvegarde pas d'informations sur le type d'objet, par conséquent, le programmeur a le contrôle sur l'affichage correct et le format MsgPack est binaire. Protobuf , au contraire, enregistre toutes les méta-informations dans une représentation intermédiaire, ce qui permet de les utiliser entre différents langages de programmation, tandis que Protobuf est également binaire.
Donc, le processus de sérialisation, pourquoi en avons-nous besoin? Pour dévoiler toutes les nuances, il nous faut un autre article, je vais essayer de l'expliquer avec des exemples. La sérialisation permet, tout en restant en termes de langage de programmation, de «packager» des entités logicielles (classes, structures) pour les transférer sur le réseau, pour un stockage persistant, par exemple, dans des fichiers et autres scripts qui, sans sérialisation, nous obligent à inventer nos propres protocoles et à prendre en compte le matériel et plate-forme logicielle, encodage de texte, etc.
Voici quelques exemples de bibliothèques pour la sérialisation:
DSL
Langage spécifique au domaine - un langage de programmation pour votre domaine. En effet, lorsque nous nous engageons dans l'automatisation d'une entreprise, nous sommes confrontés au domaine du client et décrivons tous les processus métier en termes de domaine, mais dès qu'il s'agit de programmation, les programmeurs, ainsi que les analystes, sont engagés dans la cartographie des concepts de processus métier en concepts cadre et langage de programmation. Et s'il n'y a pas un certain nombre de processus métier et que le domaine est défini de manière suffisamment stricte, il est logique de créer votre propre DSL, de mettre en œuvre la plupart des scénarios existants et d'en ajouter de nouveaux. Dans le monde C ++, il n'y a pas beaucoup d'opportunités pour l'implémentation "rapide" de votre DSL. Il existe, bien sûr, des mécanismes pour intégrer lua, javascript et d'autres langages de programmation en C ++ - un programme, mais qui a besoin de vulnérabilités et d'un moteur d'exécution potentiellement incontrôlé pour "tout"?! Nous allons donc analyser les outils qui vous permettent de faire vous-même DSL.
La bibliothèque Boost.Proto est juste conçue pour créer votre propre DSL, c'est son but direct, voici un exemple
#include <iostream> #include <boost/proto/proto.hpp> #include <boost/typeof/std/ostream.hpp> using namespace boost; proto::terminal< std::ostream & >::type cout_ = { std::cout }; template< typename Expr > void evaluate( Expr const & expr ) { proto::default_context ctx; proto::eval(expr, ctx); } int main() { evaluate( cout_ << "hello" << ',' << " world" ); return 0; }
Flex et Bison sont utilisés pour générer des lexers et des analyseurs pour votre grammaire. La syntaxe n'est pas simple, mais elle résout le problème efficacement.
Exemple de code pour générer un lexer
%{ #include <math.h> %} DIGIT [0-9] ID [az][a-z0-9]* %% {DIGIT}+ { printf( "An integer: %s (%d)\n", yytext, atoi( yytext ) ); } {DIGIT}+"."{DIGIT}* { printf( "A float: %s (%g)\n", yytext, atof( yytext ) ); } if|then|begin|end|procedure|function { printf( "A keyword: %s\n", yytext ); } {ID} printf( "An identifier: %s\n", yytext ); "+"|"-"|"*"|"/" printf( "An operator: %s\n", yytext ); "{"[^}\n]*"}" /* eat up one-line comments */ [ \t\n]+ /* eat up whitespace */ . printf( "Unrecognized character: %s\n", yytext ); %% main( argc, argv ) int argc; char **argv; { ++argv, --argc; /* skip over program name */ if ( argc > 0 ) yyin = fopen( argv[0], "r" ); else yyin = stdin; yylex(); }
Et pourtant, il existe la spécification SCXML - State Chart XML: State Machine Notation for Control Abstraction, une description d'une machine à états dans un balisage de type XML. Ce n'est pas exactement DSL, mais aussi un mécanisme pratique pour automatiser des processus sans programmation. Qt SCXML a une excellente implémentation. Il existe d'autres implémentations, mais elles ne sont pas si flexibles.
Ceci est un exemple de client FTP en notation SCXML, un exemple tiré du site de documentation Qt
<scxml xmlns="http://www.w3.org/2005/07/scxml" version="1.0" name="FtpClient" datamodel="ecmascript"> <state id="G" initial="I"> <transition event="reply" target="E"/> <transition event="cmd" target="F"/> <state id="I"> <transition event="reply.2xx" target="S"/> </state> <state id="B"> <transition event="cmd.DELE cmd.CWD cmd.CDUP cmd.HELP cmd.NOOP cmd.QUIT cmd.SYST cmd.STAT cmd.RMD cmd.MKD cmd.PWD cmd.PORT" target="W.general"/> <transition event="cmd.APPE cmd.LIST cmd.NLST cmd.REIN cmd.RETR cmd.STOR cmd.STOU" target="W.1xx"/> <transition event="cmd.USER" target="W.user"/> <state id="S"/> <state id="F"/> </state> <state id="W"> <onentry> <send eventexpr=""submit." + _event.name"> <param name="params" expr="_event.data"/> </send> </onentry> <transition event="reply.2xx" target="S"/> <transition event="reply.4xx reply.5xx" target="F"/> <state id="W.1xx"> <transition event="reply.1xx" target="W.transfer"/> </state> <state id="W.transfer"/> <state id="W.general"/> <state id="W.user"> <transition event="reply.3xx" target="P"/> </state> <state id="W.login"/> </state> <state id="P"> <transition event="cmd.PASS" target="W.login"/> </state> </state> <final id="E"/> </scxml>
Et donc il regarde dans le visualiseur SCXML

Accès aux données et intégration
C'est peut-être l'un des sujets les plus «douloureux» au monde avec ++. Le monde des données pour un développeur c ++ est toujours lié à la nécessité de pouvoir les afficher sur l'essence d'un langage de programmation. Une ligne d'une table est dans un objet ou une structure, json est dans une classe, etc. En l'absence de réflexion - c'est un énorme problème, mais nous, avec ++ - les surnoms, ne désespérons pas et trouvons différentes façons de sortir de la situation. Commençons par le SGBD.
Maintenant, je serai banal, mais ODBC est le seul mécanisme universel pour accéder aux SGBD relationnels, aucune autre option n'a encore été inventée, mais C ++ - la communauté ne reste pas immobile et il existe aujourd'hui des bibliothèques et des cadres qui fournissent des interfaces d'accès généralisées à plusieurs SGBD.
Tout d'abord, je mentionnerai les bibliothèques qui fournissent un accès unifié au SGBD à l'aide des bibliothèques clientes et SQL
Tous sont bons, mais ils vous rappellent les nuances de l'affichage des données de la base de données dans des objets et des structures C ++, plus l'efficacité des requêtes SQL retombe immédiatement sur vos épaules.
Les exemples suivants sont des ORM en C ++. Oui, il y en a! Et au fait, SOCI prend en charge les mécanismes ORM à travers la spécialisation soci :: type_conversion, mais je ne l'ai pas intentionnellement inclus, car ce n'est pas son but direct.
- LiteSQL C ++ - ORM, qui vous permet d'interagir avec SGBD SQLite3, PostgreSQL, MySQL. Cette bibliothèque nécessite que le programmeur prédéfinisse des fichiers xml avec une description des objets et des relations afin de générer des sources supplémentaires à l'aide de litesql-gen.
- L'ODB de Code Synthesis est un ORM très intéressant, il vous permet de rester en C ++, sans utiliser de fichiers de description intermédiaires, voici un petit exemple:
#pragma db object class person {
- Wt ++ est un grand framework, vous pouvez écrire un article séparé à ce sujet en général, il contient également des ORM qui peuvent interagir avec le SGBD Sqlite3, Firebird, MariaDB / MySQL, MSSQL Server, PostgreSQL et Oracle.
- Je voudrais également mentionner ORM sur sqlite sqlite_orm et hiberlite . Étant donné que sqlite est un SGBD intégré et que l'ORM vérifie les requêtes, et en fait toutes les interactions avec la base de données, au moment de la compilation, l'outil devient très pratique pour un déploiement et un prototypage rapides.
- QHibernate - ORM pour Qt5 avec support Postgresql. Imprégné d'idées d'hibernation de Java.
Bien que l'intégration via un SGBD soit considérée comme une "intégration", je préfère la laisser en dehors des crochets et passer à l'intégration via les protocoles et les API.
RPC - appel porocess distant, une technique bien connue pour l'interaction du "client" avec le "serveur". Comme dans le cas de l'ORM, la principale difficulté est d'écrire / générer divers fichiers auxiliaires pour lier le protocole avec des fonctions réelles dans le code. Je ne mentionnerai pas intentionnellement les différents RPC implémentés directement dans le système d'exploitation, mais je me concentrerai sur les solutions multiplateformes.
- grpc est un framework de Google pour les appels de procédure à distance, un framework très populaire et efficace de google. Il utilise essentiellement google protobuf, je l'ai mentionné dans la section sérialisation, il prend en charge de nombreux langages de programmation, mais c'est nouveau pour l'environnement d'entreprise.
- json-rpc - RPC, où JSON est utilisé comme protocole, un bon exemple d'implémentation est la bibliothèque libjson-rpc-cpp , voici un exemple de fichier de description:
[ { "name": "sayHello", "params": { "name": "Peter" }, "returns" : "Hello Peter" }, { "name" : "notifyServer" } ]
Sur la base de cette description, des codes client et serveur sont générés et peuvent être utilisés dans votre application. En général, il existe une spécification pour JSON-RPC 1.0 et 2.0 . Ainsi, appeler une fonction à partir d'une application Web et la traiter en C ++ n'est pas difficile.
- XML-RPC et SOAP - le leader incontesté ici - est gSOAP , une bibliothèque très puissante, je ne pense pas qu'il existe des alternatives valables . Comme dans l'exemple précédent, nous créons un fichier intermédiaire avec du contenu xml-rpc ou soap, définissons le générateur dessus, récupérons le code et utilisons-le. Exemples typiques de requêtes et de réponses en notation xml-rpc:
<?xml version="1.0"?> <methodCall> <methodName>examples.getState</methodName> <params> <param> <value><i4>41</i4></value> </param> </params> </methodCall> <methodResponse> <params> <param> <value><string>State-Ready</string></value> </param> </params> </methodResponse>
- Poco :: RemotingNG est un projet très intéressant de pocoproject. Vous permet de déterminer quelles classes, fonctions, etc. peut être appelé à distance en utilisant des annotations dans les commentaires. Voici un exemple
typedef unsigned long GroupID; typedef std::string GroupName;
Pour générer du code auxiliaire, son propre "compilateur" est utilisé. Pendant longtemps, cette fonctionnalité était uniquement dans la version payante du cadre POCO, mais avec l'avènement du projet macchina.io , vous pouvez l'utiliser gratuitement.
La messagerie est un concept assez large, mais je vais l'analyser du point de vue de la messagerie via un bus de données commun, à savoir, je passerai par des bibliothèques et des serveurs implémentant Java Message Service en utilisant divers protocoles, par exemple AMQP ou STOMP . Le bus de données commun, également appelé Enterprise Servise Bus (ESB), est très courant dans les solutions de segment d'entreprise, comme vous permet d'intégrer rapidement divers éléments de l'infrastructure informatique entre eux, en utilisant un modèle de point à point et de publication-abonnement. Il y a peu de courtiers de messages industriels écrits en C ++, j'en connais deux: Apache Qpid et UPMQ , et le second est écrit par moi. Il y a Eclipse Mosquitto , mais il est écrit en si. La beauté de JMS pour java est que votre code ne dépend pas du protocole utilisé par le client et le serveur, JMS comme ODBC, déclare les fonctions et le comportement, vous pouvez donc changer le fournisseur JMS au moins une fois par jour et ne pas réécrire le code, pour C ++, malheureusement, ne l'est pas. Vous devrez réécrire la partie client pour chaque fournisseur. Je vais énumérer, à mon avis, les bibliothèques C ++ les plus populaires pour les courtiers de messages non moins populaires:
Le principe selon lequel ces bibliothèques fournissent des fonctionnalités générales est généralement conforme à la spécification JMS. À cet égard, il existe un désir de rassembler un groupe de personnes partageant les mêmes idées et d'écrire une sorte d'ODBC, mais pour les courtiers de messages, de sorte que chaque programmeur C ++ souffre un peu moins que d'habitude.
Connectivité réseau
J'ai délibérément laissé tout ce qui était connecté directement à l'interaction avec le réseau, car dans ce domaine, les développeurs C ++ ont le moins de problèmes, à mon avis. Il ne reste plus qu'à choisir le schéma le plus proche de votre décision, et le cadre qui le met en œuvre. Avant d'énumérer les bibliothèques les plus populaires, je tiens à noter un détail important dans le développement de vos propres applications réseau. Si vous décidez de créer votre propre protocole via TCP ou UDP, préparez-vous à ce que toutes sortes d'outils de sécurité «intelligents» bloquent votre trafic, alors faites attention à compresser votre protocole, par exemple, en https ou il peut y avoir des problèmes. Donc les bibliothèques:
- Boost.Asio et Boost.Beast - l'une des implémentations les plus populaires pour la communication réseau asynchrone, il existe un support pour HTTP et WebSockets
- Poco :: Net est également une solution très populaire, et en plus de l'interaction brute, vous pouvez utiliser des classes prédéfinies de TCP Server Framework, Reactor Framework, ainsi que des classes client et serveur pour HTTP, FTP et E-Mail. Il existe également un support pour WebSockets
- ACE - n'a jamais utilisé cette bibliothèque, mais ses collègues disent que c'est aussi une bibliothèque digne, avec une approche intégrée pour la mise en œuvre d'applications réseau et plus encore.
- Qt Network - dans Qt, la partie réseau est bien implémentée. Le seul point controversé concerne les signaux et les emplacements pour les solutions serveur, bien que le serveur soit sur Qt!?
Total
Donc, ce que je voulais dire, c'est un aperçu de ces bibliothèques. Si j'ai réussi, alors vous avez l'impression qu'il y a, pour ainsi dire, une "édition entreprise", mais il n'y a pas de solutions pour sa mise en œuvre et son utilisation, seulement un zoo de bibliothèques. C'est vraiment le cas. Il existe des bibliothèques plus ou moins complètes pour développer des applications pour le segment entreprise, mais il n'y a pas de solution standard. Seul, je ne peux que recommander pocoproject et maccina.io comme point de départ dans la recherche de solutions pour le backend et le boost pour tous les cas, et bien sûr je recherche des personnes partageant les mêmes idées pour promouvoir le concept de "C ++ Enterprise Edition"!