En théorie, l'utilisation du machine learning (ML) permet de réduire l'implication humaine dans les processus et les opérations, de réaffecter les ressources et de réduire les coûts. Comment cela fonctionne-t-il dans une entreprise et une industrie particulières? Comme notre expérience le montre, cela fonctionne.
À un certain stade de développement, chez VTB Capital, nous étions confrontés à un besoin urgent de réduire le temps de traitement des demandes d'assistance technique. Après avoir analysé les options, il a été décidé d'utiliser la technologie ML pour classer les appels des utilisateurs professionnels de Calypso, la plateforme d'investissement clé de l'entreprise. Le traitement rapide de ces demandes est crucial pour la haute qualité du service informatique. Nous avons demandé à nos partenaires clés,
EPAM, d' aider à résoudre ce problème.

Ainsi, les demandes d'assistance sont reçues par e-mail et transformées en tickets à Jira. Ensuite, les spécialistes du support les classent manuellement, les classent par ordre de priorité, saisissent des données supplémentaires (par exemple, de quel département et emplacement une demande a été reçue, à quelle unité fonctionnelle du système elle appartient) et désignent des interprètes. Au total, environ 10 catégories de requêtes sont utilisées. Cela peut, par exemple, être une demande pour analyser certaines données et fournir des informations au demandeur, ajouter un nouvel utilisateur, etc. De plus, les actions peuvent être standard ou non standard, il est donc très important de déterminer immédiatement et correctement le type de demande et d'assigner l'exécution au bon spécialiste.
Il est important de noter: VTB Capital souhaitait non seulement développer une solution technologique appliquée, mais également évaluer les capacités des différents outils et technologies du marché. Une tâche, deux approches différentes, deux plateformes technologiques et trois semaines et demie: quel a été le résultat?
Prototype n ° 1: technologies et modèles
La base du développement du prototype a été l'approche proposée par l'équipe EPAM et les données historiques - environ 10 000 billets de Jira. L'attention principale a été concentrée sur les 3 champs obligatoires que contient chaque ticket: type de problème (type de problème), résumé («en-tête» de la lettre ou objet de la demande) et description (description). Dans le cadre du projet, il était prévu de résoudre le problème d'analyse du texte des champs Résumé et Description et de déterminer automatiquement le type de demande en fonction de ses résultats.
Ce sont les caractéristiques du texte dans ces deux champs de ticket qui sont devenues la principale difficulté technique dans l'analyse des données et le développement de modèles ML. Ainsi, le champ Résumé peut contenir un texte assez «propre», mais comprenant des mots et des termes spécifiques (par exemple, les
rapports CWS ne s'exécutent pas). Le champ Description, au contraire, est caractérisé par un texte plus «sale» avec une abondance de caractères spéciaux, symboles, barres obliques inverses et résidus d'éléments non textuels:
Collègues Dera,
Pourriez-vous nous expliquer quelle est la différence entre les mesures de risque FX_Opt_delta_all et FX_Opt_delta_cash?
! 01D39C59.62374C90_image001.png! )
De plus, le texte combine souvent plusieurs langues (principalement, naturellement, le russe et l'anglais), la terminologie commerciale, le jargon et l'argot du programmeur peuvent être trouvés. Et bien sûr, puisque les demandes sont souvent rédigées à la hâte, dans les deux cas, les fautes de frappe et les fautes d'orthographe ne sont pas exclues.
Les technologies choisies par l'équipe EPAM comprenaient Python 3.5 pour le développement de prototypes, NLTK + Gensim + Re pour le traitement de texte, Pandas + Sklearn pour l'analyse de données et le développement de modèles, et Keras + Tensorflow comme cadre d'apprentissage en profondeur et backend.
En tenant compte des caractéristiques possibles des données initiales, trois représentations ont été construites pour l'extraction de caractères du champ Résumé: au niveau des symboles, combinaison de symboles et mots individuels. Chacune des représentations a été utilisée comme entrée d'un réseau neuronal récurrent.
À leur tour, les statistiques de caractère de service (importantes pour le traitement de texte à l'aide de points d'exclamation, de barres obliques, etc.) et les valeurs moyennes des chaînes après filtrage des caractères de service et des ordures (pour une conservation compacte de la structure de texte) ont été choisies comme représentation pour le champ Description; ainsi que la représentation au niveau des mots après filtrage des mots vides. Chaque représentation servait d'entrée dans un réseau de neurones: des statistiques dans une connexion complète, ligne par ligne et au niveau des mots - dans une récurrente.
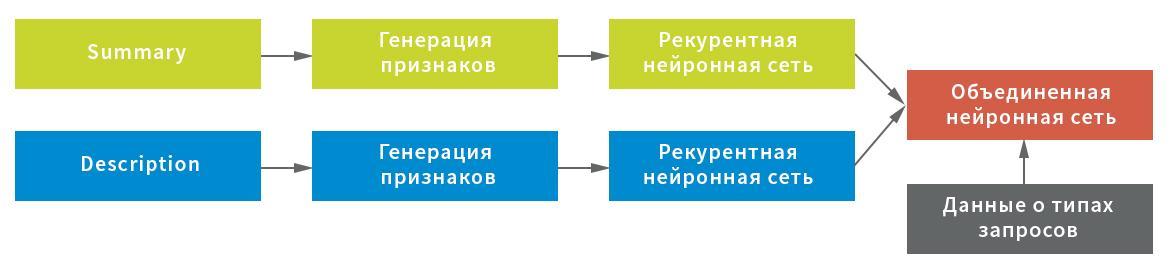
Dans ce schéma, un réseau neuronal a été utilisé comme réseau récurrent, composé d'une couche GRU bidirectionnelle avec un décrochage normal et récurrent, un pool d'états cachés du réseau récurrent utilisant la couche GlobalMaxPool1D et une couche de décrochage entièrement connectée (dense). Pour chacune des entrées, sa propre «tête» du réseau neuronal a été construite, puis elles ont été combinées par concaténation et verrouillées sur la variable cible.
Pour obtenir le résultat final, le réseau neuronal combiné a renvoyé les probabilités d'une demande particulière appartenant à chaque type. Les données ont été divisées en cinq blocs sans intersections: le modèle a été construit sur quatre d'entre eux et testé sur le cinquième. Étant donné que chaque demande ne peut être affectée qu'à un seul type de demande, la règle pour prendre une décision était simple - par la valeur de probabilité maximale.
Prototype n ° 2: algorithmes et principes de travail
Le deuxième prototype, pour lequel la proposition préparée par l'équipe VTB Capital a été prise, est une application sur Microsoft .NET Core avec des bibliothèques Microsoft.ML pour implémenter des algorithmes d'apprentissage machine et le SDK Atlassian.Net pour interagir avec Jira via l'API REST. La base de la construction de modèles ML est également devenue des données historiques - 50 000 billets Jira. Comme dans le premier cas, l'apprentissage automatique a couvert les champs Résumé et Description. Avant utilisation, les deux champs ont également été «nettoyés». Les salutations, les signatures, l'historique des correspondances et les éléments non textuels (par exemple, les images) ont été supprimés de la lettre de l'utilisateur. En outre, à l'aide de la fonctionnalité intégrée de Microsoft ML, les mots vides non pertinents pour le traitement et l'analyse du texte ont été supprimés du texte anglais.
Le Perceptron moyen (classification binaire) a été choisi comme algorithme d'apprentissage automatique, qui est complété par la méthode One Versus All pour fournir une classification multiclasse
Évaluation des résultats
Aucun modèle ML ne peut (éventuellement, encore) fournir une précision de 100% du résultat.
Le prototype d'algorithme n ° 1 fournit la part de la classification correcte (précision), égale à 0,8003 du nombre total de demandes, soit 80%. De plus, la valeur d'une métrique similaire dans une situation où l'on suppose que la bonne réponse sera choisie par la personne parmi les deux présentées par la solution atteint 0,901, soit 90%. Bien sûr, il existe des cas où la solution développée fonctionne moins bien ou ne peut pas donner la bonne réponse - en règle générale, en raison d'un ensemble de mots très court ou de la spécificité des informations contenues dans la demande elle-même. Le rôle est toujours joué par la quantité insuffisamment importante de données utilisées dans le processus d'apprentissage. Selon des estimations préliminaires, une augmentation du volume d'informations traitées permettra d'augmenter la précision de la classification de 0,01 à 0,03 points supplémentaires.
Les résultats du meilleur modèle dans les métriques d'exactitude (précision) et d'exhaustivité (rappel) sont évalués comme suit:

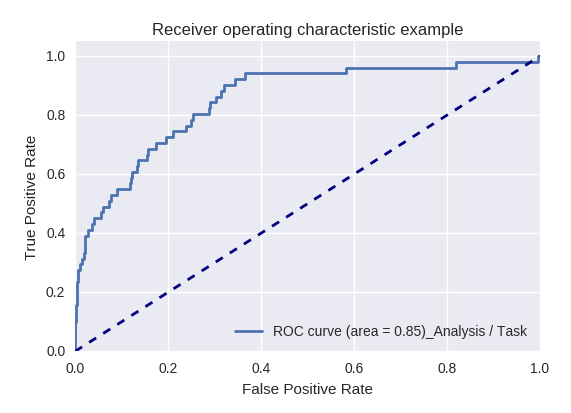
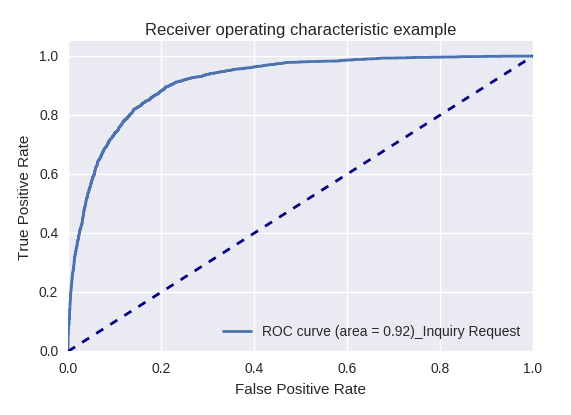
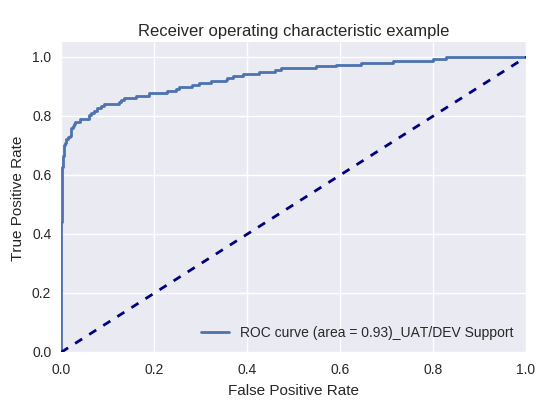
Si nous évaluons la qualité du modèle dans son ensemble pour différents types de requêtes à l'aide des courbes ROC-AUC, les résultats sont les suivants.
Demandes d'action (Action Request) et analyse des informations (Analysis / Task Request)
 Demandes de modifications des données métiers (Business Data Request) et de modifications (Change Request)
Demandes de modifications des données métiers (Business Data Request) et de modifications (Change Request)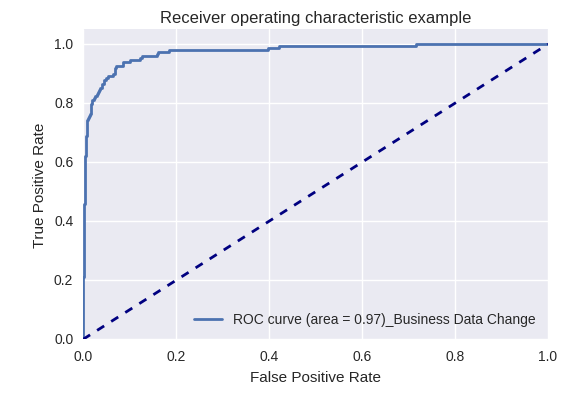
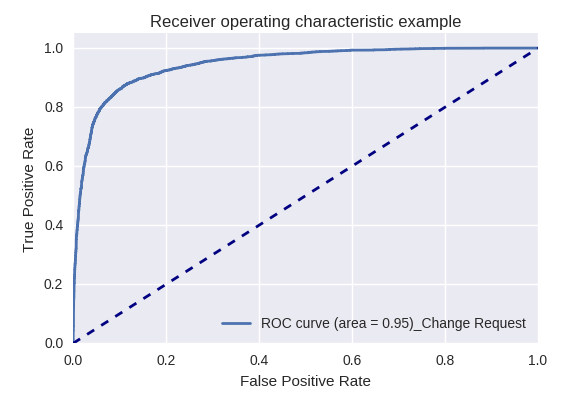 Demande de développement et demande d'enquête
Demande de développement et demande d'enquête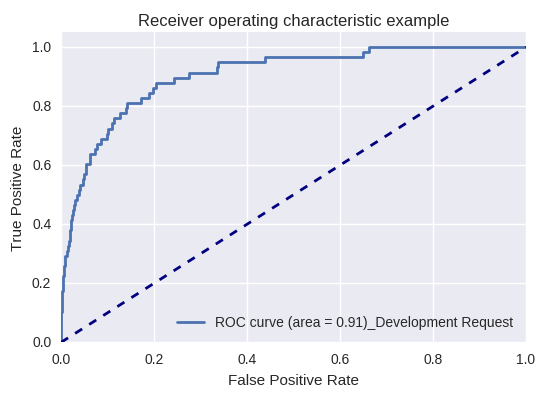
 Demandes de création d'un nouvel objet (New Object Request) et d'ajout d'un nouvel utilisateur (New User Request)
Demandes de création d'un nouvel objet (New Object Request) et d'ajout d'un nouvel utilisateur (New User Request)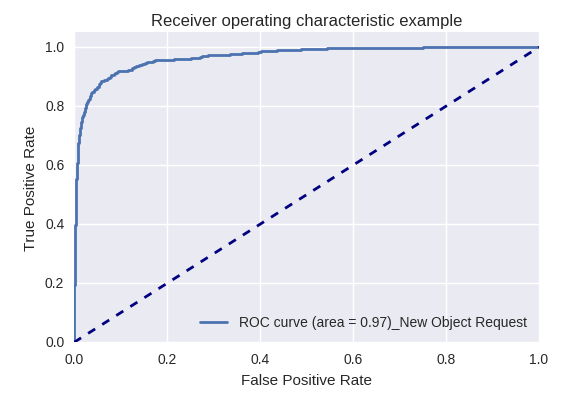
 Demande de production et demande de support UAT / DEV (demande de support UAT / Dev)
Demande de production et demande de support UAT / DEV (demande de support UAT / Dev)
Des exemples de classification correcte et incorrecte pour certains types de requêtes sont donnés ci-dessous:
Demande d'enquête
Demande de changement
Classification correcte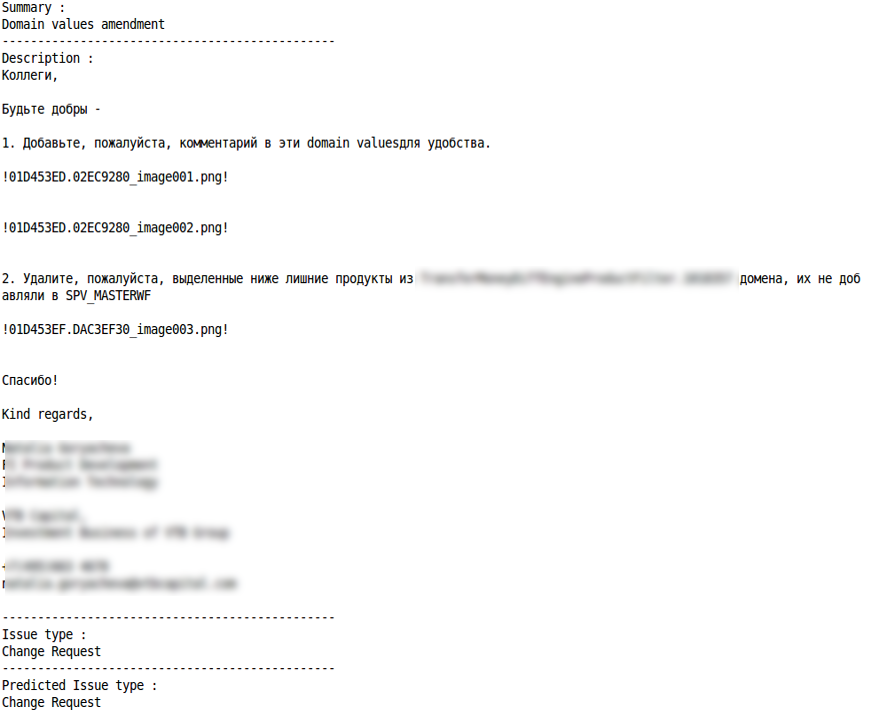 Mauvaise classification
Mauvaise classification Demande d'actionClassification correcte
Demande d'actionClassification correcte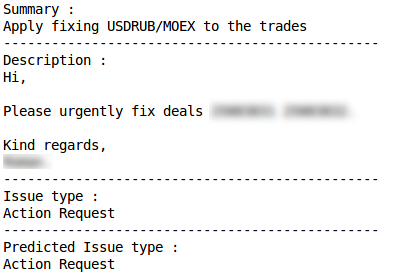 Mauvaise classificationProblème de productionClassification correcte
Mauvaise classificationProblème de productionClassification correcte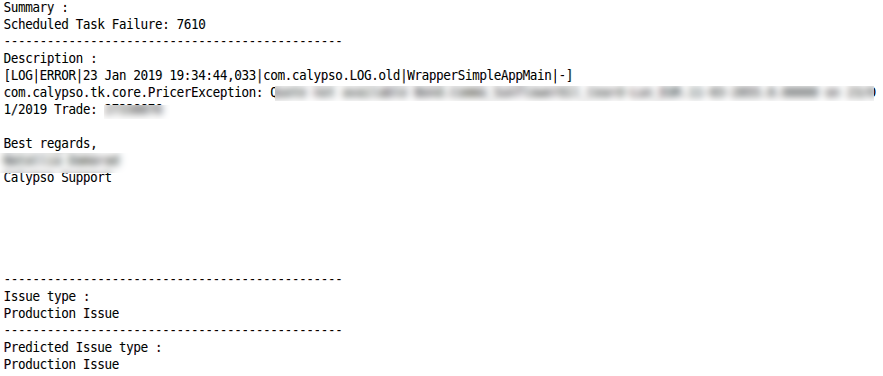 Mauvaise classification
Mauvaise classification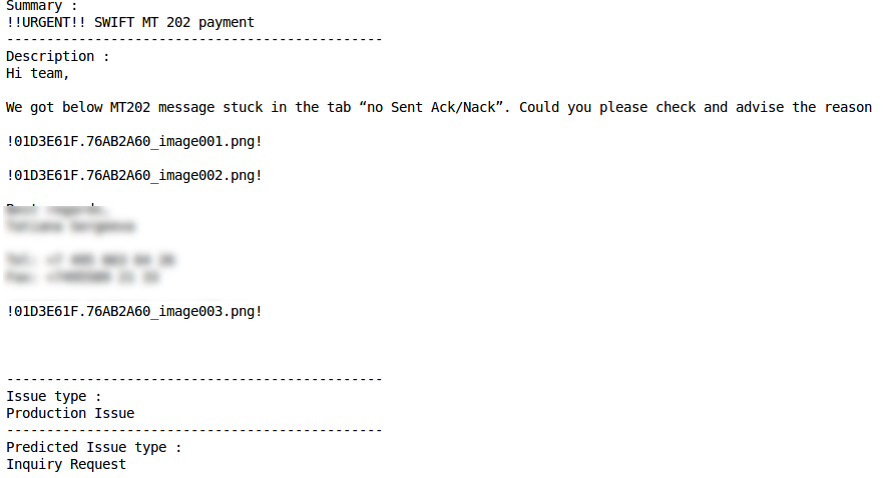
Le deuxième prototype a également montré de bons résultats: dans environ 75% des cas, ML détermine correctement le type de requête (métrique de précision). La possibilité d'améliorer l'indicateur est associée à l'amélioration de la qualité des données source, en particulier, en éliminant les cas où les mêmes requêtes ont été affectées à différents types.
Pour résumer
Chacun des prototypes mis en œuvre a montré son efficacité, et maintenant une combinaison de deux prototypes développés a été lancée en production pilote chez VTB Capital. Une petite expérience avec ML en moins d'un mois et à un coût minimal a permis à l'entreprise de se familiariser avec les outils d'apprentissage automatique et de résoudre un problème d'application important pour classer les demandes des utilisateurs.
L'expérience acquise par les développeurs d'EPAM et de VTB Capital - en plus d'utiliser des algorithmes mis en œuvre pour traiter les demandes des utilisateurs pour un développement ultérieur - peut être réutilisée pour résoudre une variété de problèmes liés au traitement en continu des informations. Le mouvement en petites itérations et la couverture d'un processus après l'autre vous permet de maîtriser et de combiner progressivement différents outils et technologies, en choisissant des options éprouvées et en abandonnant les moins efficaces. Cela est intéressant pour l'équipe informatique et permet en même temps d'obtenir des résultats importants pour la gestion et les affaires.