Articles sur la vision par ordinateur, l'interprétabilité, la PNL - nous avons visité la conférence AISTATS au Japon et voulons partager un aperçu des articles. Il s'agit d'une conférence majeure sur les statistiques et l'apprentissage automatique, qui se tient cette année à Okinawa, une île près de Taiwan. Dans ce post, Yulia Antokhina ( Yulia_chan ) a préparé une description des articles brillants de la section principale, dans la prochaine avec Anna Papeta, elle parlera des rapports des professeurs invités et des études théoriques. Nous parlerons également de la façon dont la conférence elle-même s'est déroulée et du Japon «non japonais». Se défendre contre les attaques adverses de la Whitebox via la discrétisation aléatoire
Se défendre contre les attaques adverses de la Whitebox via la discrétisation aléatoireYuchen Zhang (Microsoft); Percy Liang (Université de Stanford)
→
Article→
CodeCommençons par un article sur la protection contre les attaques contradictoires en vision par ordinateur. Il s'agit d'attaques ciblées sur des modèles, lorsque le but de l'attaque est de faire commettre une erreur au modèle, jusqu'à un résultat prédéterminé. Les algorithmes de vision par ordinateur peuvent être confondus même avec des modifications mineures de l'image d'origine pour une personne. La tâche est pertinente, par exemple, pour la vision industrielle qui, dans de bonnes conditions, reconnaît les panneaux de signalisation plus rapidement qu'une personne, mais fonctionne bien pire pendant les attaques.
Attaque contradictoire clairement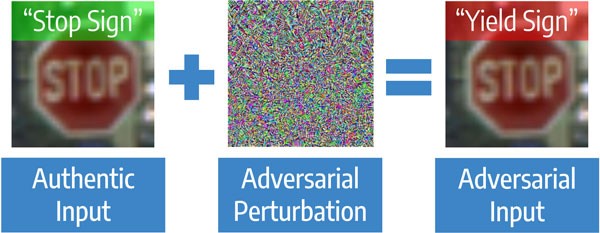
Les attaques sont Blackbox - lorsque l'attaquant ne sait rien de l'algorithme, et Whitebox est la situation inverse. Il existe deux approches principales pour protéger les modèles. La première approche consiste à entraîner le modèle sur des images régulières et «attaquées» - c'est ce qu'on appelle la formation contradictoire. Cette approche fonctionne bien sur de petites images comme MNIST, mais il y a des articles qui montrent qu'elle ne fonctionne pas bien sur de grandes images comme ImageNet. Le deuxième type de protection ne nécessite pas de recyclage du modèle. Il suffit de prétraiter l'image avant de la soumettre au modèle. Exemples de conversions: compression JPEG, redimensionnement. Ces méthodes nécessitent moins de calcul, mais maintenant elles ne fonctionnent que contre les attaques Blackbox, car si la conversion est connue, l'inverse peut être appliqué.
La méthodeDans l'article, les auteurs proposent une méthode qui ne nécessite pas de surentraînement du modèle et fonctionne pour les attaques Whitebox. Le but est de réduire la distance Kullback - Leibner entre les exemples ordinaires et ceux «gâtés» en utilisant une transformation aléatoire. Il s'avère qu'il suffit d'ajouter du bruit aléatoire, puis d'échantillonner au hasard les couleurs. Autrement dit, une qualité d'image «altérée» est envoyée à l'entrée d'algorithme, mais toujours suffisante pour que l'algorithme fonctionne. Et en raison du hasard, il existe un potentiel pour résister aux attaques de la Whitebox.
À gauche, l'image d'origine, au milieu, un exemple de regroupement des couleurs de pixels dans l'espace Lab, à droite, une image en plusieurs couleurs (par exemple, au lieu de 40 nuances de bleu - une) Résultats
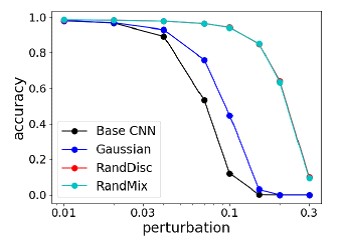
RésultatsCette méthode a été comparée aux attaques les plus fortes du concours NIPS 2017 Adversarial Attacks & Defenses, et elle montre en moyenne la meilleure qualité et ne se recycle pas sous le «pirate».
Comparaison des méthodes de défense les plus puissantes contre les attaques les plus fortes contre NIPS Competition Comparaison de la précision des méthodes sur MNIST avec différents changements d'image
Comparaison de la précision des méthodes sur MNIST avec différents changements d'image
 Atténuation du biais dans les vecteurs Word
Atténuation du biais dans les vecteurs WordSunipa Dev (Université de l'Utah); Jeff Phillips (Université de l'Utah)
→
ArticleLe discours «à la mode» portait sur les vecteurs de mots impartiaux. Dans ce cas, le biais signifie des biais par sexe ou nationalité dans les représentations des mots. Tous les régulateurs peuvent s'opposer à une telle "discrimination", et les scientifiques de l'Université de l'Utah ont donc décidé d'étudier la possibilité d'une "égalisation des droits" pour la PNL. En fait, pourquoi un homme ne peut-il pas être «glamour» et une femme un «Data Scientist»?
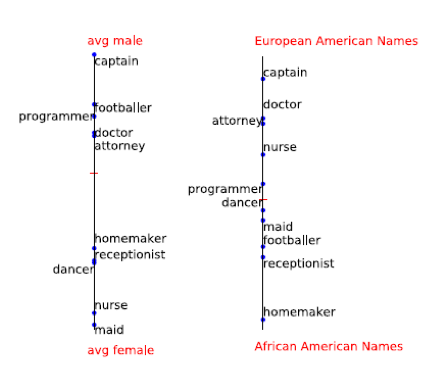
Original - le résultat qui est obtenu maintenant, le reste - les résultats de l'algorithme non biaisé

L'article discute d'une méthode pour trouver un tel biais. Ils ont décidé que le sexe et la nationalité sont bien caractérisés par les noms. Donc, si vous trouvez le décalage par nom et le soustrayez, alors, vous pouvez probablement vous débarrasser du biais de l'algorithme.
Un exemple de mots plus «masculins» et «féminins»:
 Noms pour trouver des compensations de genre:
Noms pour trouver des compensations de genre:
Curieusement, une méthode aussi simple fonctionne. Les auteurs ont formé un gant impartial et présenté dans Git.
Qu'est-ce qui vous a fait faire ça? Comprendre les décisions de la boîte noire avec des sous-ensembles d'entrée suffisantsBrandon Carter (MIT CSAIL); Jonas Mueller (Amazon Web Services); Siddhartha Jain (MIT CSAIL); David Gifford (MIT CSAIL)
→
Article→
Code une et
deux foisL'article suivant décrit l'algorithme de sous-ensemble d'entrée suffisant. SIS sont les sous-ensembles minimaux de fonctionnalités pour lesquels le modèle produira un certain résultat, même si toutes les autres fonctionnalités sont réinitialisées. C'est une autre façon d'interpréter en quelque sorte les résultats de modèles complexes. Fonctionne sur les textes et les images.
Algorithme de recherche SIS en détail: Exemple d'application sur le texte avec des critiques sur la bière:
Exemple d'application sur le texte avec des critiques sur la bière: Exemple d'application sur MNIST:
Exemple d'application sur MNIST: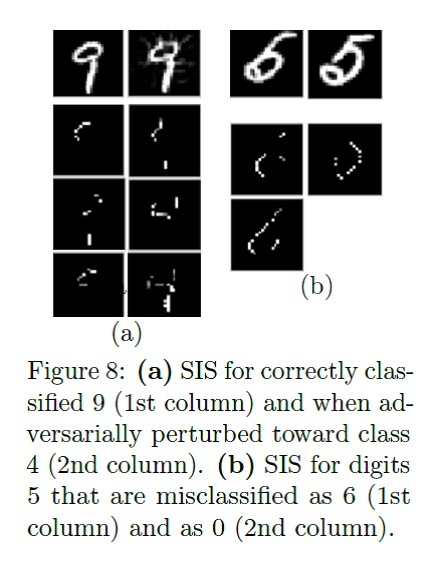 Comparaison des méthodes "d'interprétation" de la distance Kullback - Leibler par rapport au résultat "idéal":
Comparaison des méthodes "d'interprétation" de la distance Kullback - Leibler par rapport au résultat "idéal":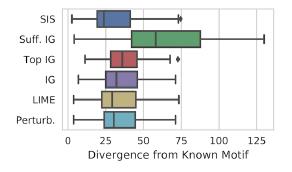
Les fonctionnalités sont d'abord classées par impact sur le modèle, puis décomposées en sous-ensembles disjoints, en commençant par les plus influents. Il fonctionne par force brute, et sur un jeu de données étiqueté, le résultat interprète mieux que LIME. Il existe une implémentation pratique de la recherche SIS de Google Research.
Minimisation des risques empiriques et descente de gradient stochastique pour les données relationnellesVictor Veitch (Université Columbia); Morgane Austern (Université Columbia); Wenda Zhou (Columbia University); David Blei (Columbia University); Peter Orbanz (Columbia University)
→
Article→
CodeDans la section d'optimisation, il y avait un rapport sur la minimisation des risques empiriques, où les auteurs ont exploré des façons d'appliquer la descente de gradient stochastique sur les graphiques. Par exemple, lors de la création d'un modèle sur des données de réseaux sociaux, vous ne pouvez utiliser que des fonctionnalités fixes du profil (le nombre d'abonnés), mais les informations sur les connexions entre les profils (qui sont abonnées) sont perdues. De plus, le graphique entier est le plus souvent difficile à traiter - par exemple, il ne tient pas en mémoire. Lorsque cette situation se produit sur des données tabulaires, le modèle peut être exécuté sur des sous-échantillons. Et comment choisir l'analogue du sous-échantillon sur le graphique n'était pas clair. Les auteurs ont théoriquement justifié la possibilité d'utiliser des sous-graphes aléatoires comme analogues de sous-échantillons, et cela s'est avéré être «une idée pas folle». Il existe des exemples reproductibles de l'article sur Github, y compris l'exemple de Wikipedia.
Catégorie Embeddings sur les données de "Wikipedia" compte tenu de sa structure graphique, les articles sélectionnés sont les plus proches sur le sujet des "physiciens français":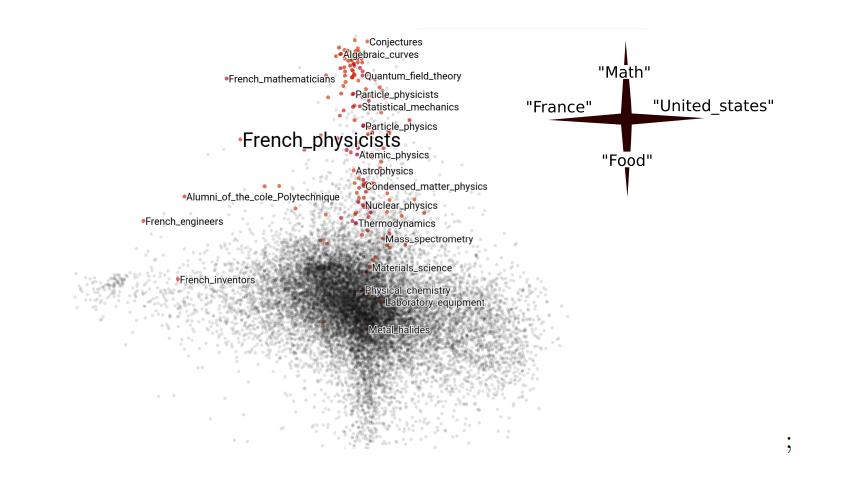
→
Science des données pour les données en réseauLes graphiques de données discrets étaient un autre rapport d'examen par Data Science pour les données en réseau du conférencier invité Poling Loh (Université du Wisconsin-Madison). La présentation a couvert les sujets de l'inférence statistique, l'allocation des ressources, les algorithmes locaux. Dans l'inférence statistique, par exemple, il s'agissait de savoir comment comprendre la structure du graphique sur les données sur les maladies infectieuses. Il est proposé d'utiliser des statistiques sur le nombre de connexions entre les nœuds infectés - et le théorème est prouvé pour le test statistique correspondant.
En général, le rapport est plus intéressant à regarder, très probablement, pour ceux qui ne sont pas impliqués dans les modèles de graphique, mais qui aimeraient essayer de savoir comment tester correctement les hypothèses pour les graphiques.
Comment s'est déroulée la conférenceAISTATS 2019 est une conférence de trois jours à Okinawa. C’est le Japon, mais la culture d’Okinawa est plus proche de la Chine. La principale rue commerçante rappelle un si petit Miami, il y a de longues voitures dans les rues, de la musique country et vous vous éloignez un peu - la jungle avec des serpents, des mangroves tordues par des typhons. La saveur locale est créée par la culture de Ryukyu - un royaume qui était situé à Okinawa, mais est d'abord devenu un vassal et un partenaire commercial de la Chine, puis a été capturé par les Japonais.
Et à Okinawa, apparemment, ils organisent souvent des mariages, car il y a beaucoup de salons de mariage, et la conférence a eu lieu dans les locaux de Wedding Hall.
Plus de 500 personnes ont réuni des scientifiques, des auteurs d'articles, des auditeurs et des conférenciers. En trois jours, vous pouvez avoir le temps de parler avec presque tout le monde. Bien que la conférence ait eu lieu "aux extrémités du monde", des représentants du monde entier sont arrivés. Malgré la vaste géographie, il s'est avéré que les intérêts de chacun d'entre nous sont similaires. Ce fut une surprise pour nous, par exemple, que des scientifiques australiens résolvent les mêmes problèmes de Data Science et les mêmes méthodes que nous dans notre équipe. Mais, après tout, nous vivons sur des côtés presque opposés de la planète ... Il n'y avait pas autant de participants de l'industrie: Google, Amazon, MTS et plusieurs autres grandes sociétés.
Il y avait des représentants de sociétés japonaises de parrainage, qui regardaient et écoutaient la plupart du temps et, probablement, cherchaient quelqu'un, malgré le fait que les «non japonais» étaient très difficiles à travailler au Japon.
Articles soumis à la conférence sur les thèmes:
Tout le reste est dans notre prochain post. Ne le manquez pas!
Annonce: