
Le problème de la confiance dans les prédictions faites par les modèles d'apprentissage automatique devient de plus en plus pertinent. Plus la décision prise sur la base de cette prédiction est importante, moins la confiance est grande. Cela est principalement dû au fait qu'il est loin d'être toujours clair ce qui a affecté la décision finale, y a-t-il eu des biais dans les données initiales sur lesquelles le modèle a été formé et si le développeur a fait des erreurs dans le calcul des paramètres. Il n'est pas possible de vérifier tout cela manuellement dans la pratique, il est donc souvent plus facile pour la direction de ne pas implémenter l'IA du tout.
Mais que se passe-t-il si vous automatisez ce processus?
Présentation de
Watson OpenScale , une solution basée sur le cloud qui vous permet non seulement de contrôler la qualité de vos modèles, mais également de suivre la présence de biais dans les prévisions, de détecter et d'éliminer leurs causes.
Nous vous dirons ce que c'est et où apprendre à travailler avec.
Biais - Un problème d'IA caché
Imaginez que vous regardez un match de football et que quelqu'un vous demande qui était le meilleur joueur en 2018. Que répondriez-vous? Arrêtez-vous et réfléchissez une seconde avant de lire plus loin ... Si vous étiez fan de l'Argentine, vous diriez probablement "Messi", si vous étiez fan du Portugal - votre réponse serait "Ronaldo". Quelqu'un d'autre dirait que Messi est le meilleur, ou peut-être Dziuba. Chacune de ces réponses (y compris celle qui est apparue dans votre tête) reflète le parti pris inhérent à chaque personne qui répond à cette question. Elle peut être causée par l'admiration directe du joueur lui-même, ou par l'équipe dans son ensemble, ou par certains sentiments pour le pays pour lequel l'équipe représente.
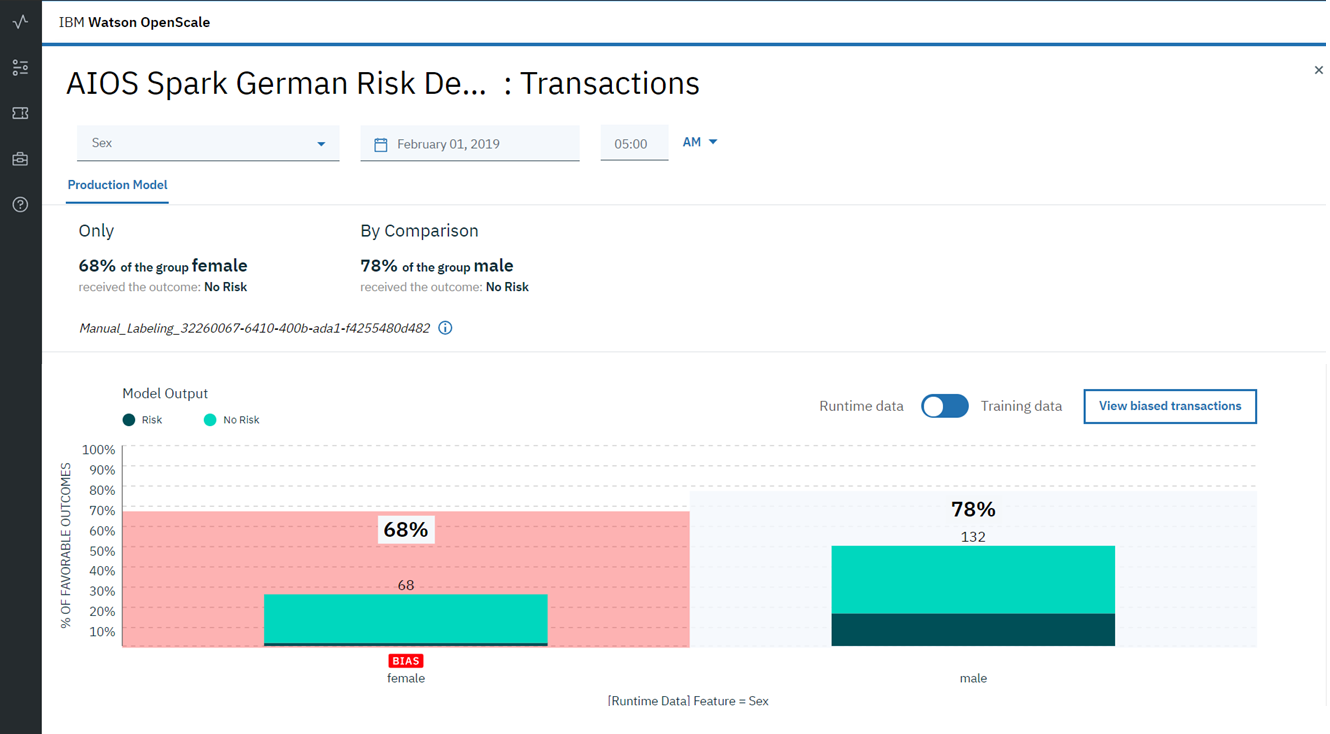
Les biais, conscients et inconscients, se retrouvent dans presque tous les aspects de nos activités. En ce qui concerne la prise de décision, y compris les algorithmes d'intelligence artificielle, le biais peut avoir des conséquences importantes. Considérez une banque utilisant l'IA pour reconnaître une activité frauduleuse. Imaginez que la personne qui développe ce modèle utilise un ensemble de données dans lequel toutes les transactions frauduleuses ont été commises par des personnes d'un certain sexe, nationalité ou niveau de revenu. Ensuite, avec une grande certitude, nous pouvons dire qu'un modèle formé sur de telles données biaisées tiendra compte de ce biais dans ses prédictions. De plus, étant donné que les métriques décrivant ce modèle (précision / rappel) seront proches de l'idéal (après tout, la vérification a lieu sur un sous-échantillon du même ensemble de données), il sera extrêmement difficile pour un employé de détecter la présence de biais à la suite de l'algorithme. En conséquence, un tel modèle, même en dépit des excellentes valeurs des métriques, fonctionnera extrêmement mal, marquant comme des actions frauduleuses qui ne le sont pas et vice versa, sautant les transactions vraiment dangereuses. Et tout cela est dû au biais (biais) dans les données sources sur lesquelles le modèle a été formé.
Un problème encore plus important peut être la présence de biais dans les résultats du modèle, en l'absence de tout biais dans les données. Cela peut être dû à une erreur dans la distribution des poids des paramètres, ou à la suite de transformations non linéaires au cours de la formation ou de la formation continue du modèle. Par conséquent, il est très important non seulement de trouver des biais au stade du prétraitement des données, mais également de surveiller en permanence les prédictions pendant les tests et l'utilisation dans le produit afin d'éviter que des biais n'apparaissent dans les résultats de l'algorithme.
C'est à cause de ces problèmes que les IA
semblent peu fiables aux yeux de nombreux propriétaires d'entreprise.
L'IA peut-elle aider à améliorer l'IA?
IBM propose la solution cloud
Watson OpenScale , qui permet une surveillance continue des performances du modèle et des biais de prédiction en temps réel. Non seulement il détecte l'occurrence des problèmes, il trouve la cause de leur apparition et offre une option sur la façon de corriger les données initiales afin d'éviter l'apparition de biais dans les prédictions. IBM Watson OpenScale vous permet de surveiller en continu le fonctionnement du modèle, en vérifiant son biais.
Une autre grande question pour les entreprises utilisant des modèles d'intelligence artificielle est la nature de la boîte noire des modèles. Comment un propriétaire d'entreprise peut-il vérifier que l'IA prend la bonne décision sur la base des bonnes données? Comment expliquer le «comportement» du modèle d'intelligence artificielle? L'absence de réponses «simples» à ces questions est un gros problème que les experts ont récemment rencontré. IBM Watson OpenScale le résout. La prédiction finie faite par le modèle, IBM Watson OpenScale est accompagnée de deux explications différentes qui vous permettent de comprendre le comportement de l'algorithme. Pour cette raison, il semble qu'il existe une chance tout à fait tangible d'accroître le niveau de confiance entre les managers et, par conséquent, d'accélérer la mise en œuvre de l'IA dans les entreprises.
Alors, qu'est-ce que Watson OpenScale tout de même?
- Service cloud disponible sur IBM CloudAvec utilisation
gratuite dans le cadre du compte Lite
- Suivi et suivi des résultats du modèleMesure de la vitesse du modèle et suivi des résultats en projection sur un objectif commercial, avec une interface graphique claire et pratique
- Modèles de tuning à des fins commercialesLes résultats commerciaux du modèle fonctionnent constamment pour ajuster les données afin d'améliorer les résultats des modèles d'apprentissage automatique
 - Gestion et décodage du modèle
- Gestion et décodage du modèleSoutenez la conformité réglementaire en suivant et expliquant les solutions d'IA dans les processus métier, ainsi que la détection et la correction intelligentes des erreurs pour améliorer les résultats.

Vous voulez tester votre modèle de biais avec IBM Watson OpenScale?
Ou peut-être découvrir pourquoi elle a pris telle ou telle décision sur des données spécifiques?
Venez
le 9 juillet à un
atelier gratuit d'une journée à Moscou et vous pourrez:
- Se familiariser avec les principes et les caractéristiques de la formation et du fonctionnement des réseaux de neurones
- Entraînez différents types de réseaux de neurones à l'aide des jeux de données fournis et des instructions détaillées
- Testez le fonctionnement des réseaux de neurones à l'aide de la plateforme Watson OpenScale et de la bibliothèque open source IBM Adversarial Robustness Toolbox (IBM ART)
- Essayez les capacités de l'IA pour créer rapidement des modèles de réseau neuronal à l'aide du moteur NeuNetS
Tout le traitement des données a lieu dans le cloud IBM - vous n'avez besoin que d'un ordinateur portable et d'un navigateur. Inscription et informations détaillées -
cliquez ici .