Un modèle d'apprentissage automatique en Python utilisant la bibliothèque Scikit-learn pour prédire les résultats des matchs de football en Premier League russe (RPL).
Entrée
J'ai été inspiré pour écrire cet article par l'article
Apprentissage automatique: prédire les mathes EPL 2018 . Notre modèle d'apprentissage automatique s'entraînera sur les statistiques des matchs de la Premier League russe (RPL) à partir de la saison 2015/2016 pour prédire les résultats des prochains matchs. Données tirées du site Web de statistiques de football de wyscout.com.
Le code et les données sont disponibles sur
github .
Les données
Nous connectons les bibliothèques nécessaires:
import pandas as pd import numpy as np import collections
Les données de correspondance sont sur
github .
data = pd.read_csv("RPL.csv", encoding = 'cp1251', delimiter=';') data.head()
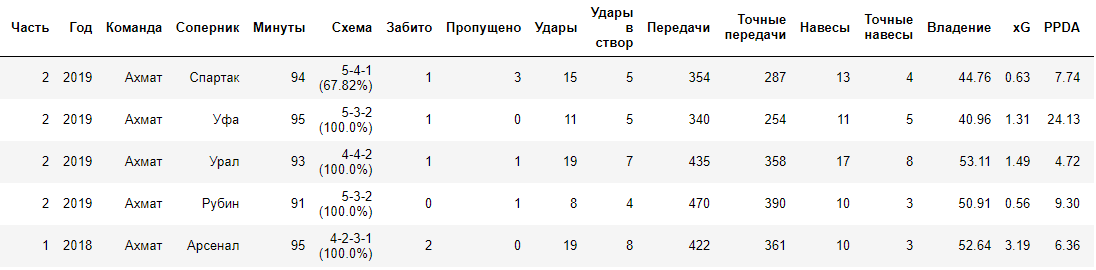
Que signifient xG et PPDA?xG (objectifs attendus) est un modèle d'objectifs attendus. Il est basé sur l'indicateur de tirs au but, sur la base duquel nous pouvons estimer le nombre de buts que l'équipe a vraiment dû marquer si l'on prend en compte tous les tirs qu'elle a délivrés.
En savoir plus sur xG.PPDA (passes autorisées par action défensive) est un indicateur de statistiques de football qui vous permet de déterminer l'intensité de la pression dans un match. Plus la valeur PPDA est faible, plus l'intensité du jeu en défense est élevée.
En savoir plus sur PPDAPPDA = nombre de passes effectuées par l'équipe attaquante / nombre d'actions en défense
Nous prédirons les résultats des matchs pour la deuxième partie de la saison 2018/2019 (c'est-à-dire les matchs joués en 2019). La liste des équipes qui jouent cette saison (hors Arsenal, Orenburg, Dynamo, Krylia Sovetov et Yenisei, car elles n'ont pas de statistiques pour les saisons passées, ou il y a peu de statistiques à leur sujet):
RPL_2018_2019 = pd.read_csv('Team Name 2018 2019.csv', encoding = 'cp1251') teamList = RPL_2018_2019['Team Name'].tolist() teamList

Nous supprimons les matchs avec des équipes qui ne participent pas à la saison 2018/2019:
deleteTeam = [x for x in pd.unique(data['']) if x not in teamList] for name in deleteTeam: data = data[data[''] != name] data = data[data[''] != name] data = data.reset_index(drop=True)
Fonction qui renvoie les statistiques d'équipe pour une saison:
def GetSeasonTeamStat(team, season): goalScored = 0
Exemple d'utilisation de la fonction:
GetSeasonTeamStat("", 2018)

Pour plus de commodité, nous pouvons ajouter le code:
returnNames = ["", "", "", "\n ", " ", "\n ", "\nxG ( )", "PPDA ( )", "\n", " ", "\n", " ", "\n", " ", "\n ( )"] for i, n in zip(returnNames, GetSeasonTeamStat("", 2018)): print(i, n)

Pourquoi nos statistiques sont différentes des statistiques réellesStatistiques réelles du Spartak dans la saison 2017/2018:

Les statistiques sont différentes car Nous avons pris en compte les matchs des équipes qui ne jouent pas en RPL lors de la saison 2018/2019. Autrement dit, nous ne prenons pas en compte les matches de Spartak - SKA, Spartak - Tosno, etc.
Fonction qui renverra les statistiques de toutes les équipes pour la saison:
def GetSeasonAllTeamStat(season): annual = collections.defaultdict(list) for team in teamList: team_vector = GetSeasonTeamStat(team, season) annual[team] = team_vector return annual
Formation modèle
Nous allons écrire une fonction qui renverra des données d'entraînement. Elle crée un dictionnaire avec des vecteurs d'équipe pour toutes les saisons. Pour chaque jeu, la fonction calcule la différence entre les vecteurs d'équipes pour une certaine saison et l'écrit sur xTrain. La fonction définit ensuite yTrain sur 1 si l'équipe à domicile gagne et 0 sinon.
def GetTrainingData(seasons): totalNumGames = 0 for season in seasons: annual = data[data[''] == season] totalNumGames += len(annual.index) numFeatures = len(GetSeasonTeamStat('', 2016))
Nous apprenons les données d'entraînement pour toutes les saisons de 2015/2016 à 2018/2019.
years = range(2016,2019) xTrain, yTrain = GetTrainingData(years)
Pour prédire la probabilité de gagner, nous utiliserons l'algorithme d'apprentissage automatique LinearRegression de la bibliothèque Scikit-Learn.
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(xTrain, yTrain)
Nous allons écrire une fonction qui renverra des prévisions. Il renverra une valeur entre 0 et 1, où 0 est la perte et 1 est le gain.
def createGamePrediction(team1_vector, team2_vector): diff = [[a - b for a, b in zip(team1_vector, team2_vector)]] predictions = model.predict(diff) return predictions
Résultats
Par exemple, regardons les prédictions de l'algorithme pour le match Zenit - Spartak
team1_name = "" team2_name = "" team1_vector = GetSeasonTeamStat(team1_name, 2019) team2_vector = GetSeasonTeamStat(team2_name, 2019) print (', ' + team1_name + ':', createGamePrediction(team1_vector, team2_vector)) print (', ' + team2_name + ':', createGamePrediction(team2_vector, team1_vector))

Il s'avère que dans le match Zenit - Spartak, la probabilité de victoire de Zenit est de 47% (17/03/2019 Spartak 1-1 Zenit).
Je propose de faire une prévision compte tenu des éléments suivants:
Jusqu'à 40% - l'équipe ne gagnera tout simplement pas (défaite ou match nul)
De 40% à 60% - une forte probabilité de match nul
A partir de 60% - l'équipe ne perdra certainement pas (victoire ou nul)
Calculez les prévisions pour le CSKA contre tous les autres clubs
for team_name in teamList: team1_name = "" team2_name = team_name if(team1_name != team2_name): team1_vector = GetSeasonTeamStat(team1_name, 2019) team2_vector = GetSeasonTeamStat(team2_name, 2019) print(team1_name, createGamePrediction(team1_vector, team2_vector), " - ", team2_name, createGamePrediction(team2_vector, team1_vector,))

L'algorithme a donné une prévision correcte pour presque tous les matchs qui ne se sont pas terminés par un match nul. La seule prévision inexacte: CSKA Moscou - Zenit. La probabilité de victoire du CSKA est plus élevée de 0,001, on pourrait supposer que les équipes sont de force égale et joueront dans un match nul, mais au final Zenit a gagné (3-1).
Conclusion
Notre algorithme est très primitif. Il ne prend en compte que les statistiques des matchs (puis seulement 15 paramètres de base), et le résultat dans le football dépend de nombreux facteurs. Même l'état du terrain ou la météo peuvent affecter le résultat du match.
Ensuite, je voudrais augmenter le nombre de signes, créer un échantillon de test, essayer différents algorithmes, configurer le modèle et obtenir les prévisions les plus précises.
Je vous serais reconnaissant de bien vouloir laisser vos idées et commentaires.