Bonjour, Habr! Je vous présente la traduction gratuite du «Guide de l'architecture des applications» de
JetPack . Je vous demande de laisser tous les commentaires sur la traduction dans les commentaires, et ils seront corrigés. De plus, les commentaires de ceux qui ont utilisé l'architecture présentée avec des recommandations pour son utilisation seront utiles à tous.
Ce guide couvre les meilleures pratiques et l'architecture recommandée pour créer des applications robustes. Cette page suppose une introduction de base à Android Framework. Si vous êtes nouveau dans le développement d'applications Android, consultez nos
guides de développement pour commencer et en savoir plus sur les concepts mentionnés dans ce guide. Si vous êtes intéressé par l'architecture des applications et souhaitez vous familiariser avec les matériaux de ce guide en termes de programmation sur Kotlin, consultez le cours Udacity,
«Développement d'applications pour Android avec Kotlin» .
Expérience utilisateur de l'application mobile
Dans la plupart des cas, les applications de bureau ont un point d'entrée unique à partir du bureau ou du lanceur, puis s'exécutent comme un processus monolithique unique. Les applications Android ont une structure beaucoup plus complexe. Une application Android typique contient plusieurs
composants d'application , notamment des
activités , des
fragments , des
services , des
fournisseurs de contenu et des
récepteurs de diffusion .
Vous déclarez tout ou partie de ces composants d'application dans le
manifeste d' application. Android utilise ensuite ce fichier pour décider comment intégrer votre application dans l'interface utilisateur commune de l'appareil. Étant donné qu'une application Android bien écrite contient plusieurs composants et que les utilisateurs interagissent souvent avec plusieurs applications dans un court laps de temps, les applications doivent s'adapter à différents types de flux de travail et de tâches pilotées par l'utilisateur.
Par exemple, considérez ce qui se passe lorsque vous partagez une photo dans votre application de médias sociaux préférée:
- L'application déclenche l'intention de la caméra. Android lance une application appareil photo pour traiter la demande. Pour le moment, l'utilisateur a quitté l'application pour les réseaux sociaux, et son expérience en tant qu'utilisateur est impeccable.
- Une application de caméra peut déclencher d'autres intentions, comme le lancement d'un sélecteur de fichiers, qui peut lancer une autre application.
- À la fin, l'utilisateur revient à l'application de réseau social et partage la photo.
À tout moment du processus, l'utilisateur peut être interrompu par un appel téléphonique ou une notification. Après l'action associée à cette interruption, l'utilisateur s'attend à pouvoir revenir et reprendre ce processus de partage de photos. Ce comportement de changement d'application est courant sur les appareils mobiles, votre application doit donc gérer correctement ces points (tâches).
N'oubliez pas que les appareils mobiles sont également limités en ressources, donc à tout moment le système d'exploitation peut détruire certains processus d'application afin de libérer de l'espace pour de nouveaux.
Compte tenu des conditions de cet environnement, les composants de votre application peuvent être lancés individuellement et non dans l'ordre, et le système d'exploitation ou l'utilisateur peut les détruire à tout moment. Étant donné que ces événements ne sont pas sous votre contrôle,
vous ne devez pas stocker de données ou d'états dans vos composants d'application et vos composants d'application ne doivent pas dépendre les uns des autres.
Principes architecturaux généraux
Si vous ne devez pas utiliser de composants d'application pour stocker des données et l'état de l'application, comment devez-vous développer votre application?
Répartition des responsabilités
Le principe le plus important à suivre est
le partage des responsabilités . Une erreur courante est lorsque vous écrivez tout votre code dans
Activity ou
Fragment . Ce sont des classes d'interface utilisateur qui doivent contenir uniquement une logique traitant l'interaction de l'interface utilisateur et du système d'exploitation. En partageant autant que possible la responsabilité dans ces classes
(SRP) , vous pouvez éviter bon nombre des problèmes associés au cycle de vie de l'application.
Contrôle de l'interface utilisateur à partir du modèle
Un autre principe important est que vous devez
contrôler votre interface utilisateur à partir d'un modèle , de préférence à partir d'un modèle permanent. Les modèles sont les composants qui sont responsables du traitement des données pour l'application. Ils sont indépendants des objets
View et des composants d'application, par conséquent, ils ne sont pas affectés par le cycle de vie de l'application et les problèmes associés.
Un modèle permanent est idéal pour les raisons suivantes:
- Vos utilisateurs ne perdront pas de données si le système d'exploitation Android détruit votre application pour libérer des ressources.
- Votre application continue de fonctionner lorsque la connexion réseau est instable ou indisponible.
En organisant la fondation de votre application en classes de modèle avec une responsabilité clairement définie pour la gestion des données, votre application devient plus testable et prise en charge.
Architecture d'application recommandée
Cette section montre comment structurer une application à l'aide de
composants architecturaux , en travaillant dans un
scénario d'utilisation de bout en bout .
Remarque Il n'est pas possible d'avoir une façon d'écrire des applications qui fonctionne le mieux pour chaque scénario. Cependant, l'architecture recommandée est un bon point de départ pour la plupart des situations et des workflows. Si vous avez déjà un bon moyen d'écrire des applications Android qui répondent aux principes architecturaux généraux, vous ne devriez pas le changer.Imaginez que nous créons une interface utilisateur qui affiche un profil utilisateur. Nous utilisons une API privée et une API REST pour récupérer les données de profil.
Revue
Pour commencer, considérons le schéma d'interaction des modules de l'architecture de l'application finie:
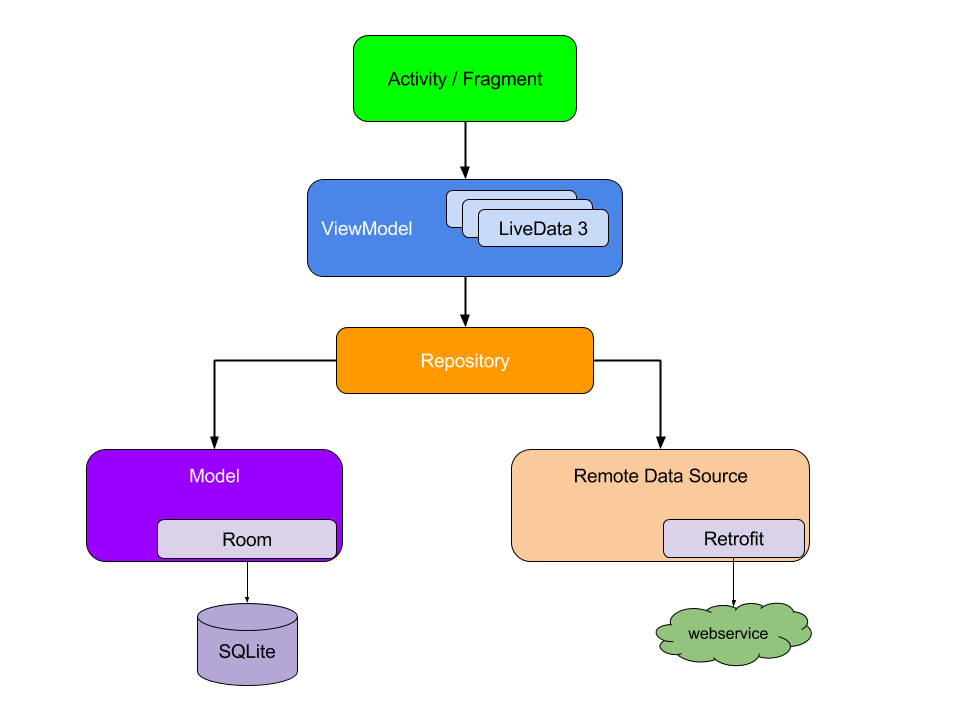
Veuillez noter que chaque composant dépend uniquement du composant un niveau en dessous. Par exemple, l'activité et les fragments dépendent uniquement du modèle de vue. Le référentiel est la seule classe qui dépend de nombreuses autres classes; dans cet exemple, le stockage dépend d'un modèle de données persistant et d'une source de données interne distante.
Ce modèle de conception crée une expérience utilisateur cohérente et agréable. Que l'utilisateur revienne à l'application quelques minutes après sa fermeture ou quelques jours plus tard, il verra instantanément les informations utilisateur indiquant que l'application est enregistrée localement. Si ces données sont obsolètes, le module de stockage d'application commence à mettre à jour les données en arrière-plan.
Créer une interface utilisateur
L'interface utilisateur se compose du fragment
UserProfileFragment et du
user_profile_layout.xml disposition
user_profile_layout.xml correspondant.
Pour gérer l'interface utilisateur, notre modèle de données doit contenir les éléments de données suivants:
- ID utilisateur : ID utilisateur. La meilleure solution consiste à transmettre ces informations au fragment à l'aide des arguments du fragment. Si le système d'exploitation Android détruit notre processus, ces informations sont enregistrées, de sorte que l'identifiant sera disponible la prochaine fois que nous lancerons notre application.
- Objet utilisateur: une classe de données qui contient des informations utilisateur.
Nous utilisons un
UserProfileViewModel basé sur un composant de l'architecture ViewModel pour stocker ces informations.
L'objet ViewModel fournit des données pour un composant d'interface utilisateur spécifique, tel qu'un fragment ou une activité, et contient une logique de traitement des données métier pour interagir avec le modèle. Par exemple, le ViewModel peut appeler d'autres composants pour charger des données et peut transmettre des demandes d'utilisateurs pour des modifications de données. ViewModel ne connaît pas les composants de l'interface utilisateur, il n'est donc pas affecté par les modifications de configuration, telles que la recréation de l'activité lorsque le périphérique est tourné.Nous avons maintenant identifié les fichiers suivants:
user_profile.xml : disposition d'interface utilisateur définie.UserProfileFragment : décrit un contrôleur d'interface utilisateur qui est responsable de l'affichage des informations à l'utilisateur.UserProfileViewModel : une classe chargée de préparer les données pour les afficher dans UserProfileFragment et répondre à l'interaction de l'utilisateur.
Les extraits de code suivants montrent le contenu initial de ces fichiers. (Le fichier de mise en page est omis pour plus de simplicité.)
class UserProfileViewModel : ViewModel() { val userId : String = TODO() val user : User = TODO() } class UserProfileFragment : Fragment() { private val viewModel: UserProfileViewModel by viewModels() override fun onCreateView( inflater: LayoutInflater, container: ViewGroup?, savedInstanceState: Bundle? ): View { return inflater.inflate(R.layout.main_fragment, container, false) } }
Maintenant que nous avons ces modules de code, comment les connecter? Une fois le champ utilisateur défini dans la classe UserProfileViewModel, nous avons besoin d'un moyen d'informer l'interface utilisateur.
Remarque SavedStateHandle permet au ViewModel d'accéder à l'état enregistré et aux arguments du fragment ou de l'action associé.
Nous devons maintenant informer notre Fragment lorsque l'objet utilisateur est reçu. C'est là que le composant de l'architecture LiveData apparaît.
LiveData est un détenteur de données observable. D'autres composants de votre application peuvent suivre les modifications apportées aux objets à l'aide de ce support, sans créer de chemins de dépendance explicites et matériels entre eux. Le composant LiveData prend également en compte l'état du cycle de vie des composants de votre application, tels que les activités, les fragments et les services, et inclut une logique de nettoyage pour éviter les fuites d'objets et la consommation excessive de mémoire.
Remarque Si vous utilisez déjà des bibliothèques comme RxJava ou Agera, vous pouvez continuer à les utiliser à la place de LiveData. Cependant, lorsque vous utilisez des bibliothèques et des approches similaires, assurez-vous de gérer correctement le cycle de vie de votre application. En particulier, assurez-vous de suspendre vos flux de données lorsque le LifecycleOwner associé est arrêté et de détruire ces flux lorsque le LifecycleOwner associé a été détruit. Vous pouvez également ajouter l'artefact android.arch.lifecycle: jet streams pour utiliser LiveData avec une autre bibliothèque de jet stream telle que RxJava2.Pour inclure le composant LiveData dans notre application, nous changeons le type de champ dans
UserProfileViewModel en LiveData.
UserProfileFragment désormais informé des mises à jour des données. De plus, puisque ce champ
LiveData prend en charge le cycle de vie, il efface automatiquement les liens lorsqu'ils ne sont plus nécessaires.
class UserProfileViewModel( savedStateHandle: SavedStateHandle ) : ViewModel() { val userId : String = savedStateHandle["uid"] ?: throw IllegalArgumentException("missing user id") val user : LiveData<User> = TODO() }
Maintenant, nous modifions
UserProfileFragment pour observer les données dans le
ViewModel et pour mettre à jour l'interface utilisateur en fonction des changements:
override fun onViewCreated(view: View, savedInstanceState: Bundle?) { super.onViewCreated(view, savedInstanceState) viewModel.user.observe(viewLifecycleOwner) {
Chaque fois que les données du profil utilisateur sont mises à jour, le rappel
onChanged () est appelé et l'interface utilisateur est mise à jour.
Si vous connaissez d'autres bibliothèques qui utilisent des rappels observables, vous avez peut-être réalisé que nous n'avons pas redéfini la méthode
onStop () du fragment pour arrêter l'observation des données. Cette étape est facultative pour LiveData car elle prend en charge le cycle de vie, ce qui signifie qu'elle n'appellera pas le rappel
onChanged() si le fragment est dans un état inactif; c'est-à-dire qu'il a reçu un appel à
onStart () , mais n'a pas encore reçu
onStop() ). LiveData supprime également automatiquement l'observateur lors de l'appel de la méthode
onDestroy () sur le fragment.
Nous n'avons ajouté aucune logique pour gérer les modifications de configuration, telles que la rotation de l'écran de l'appareil par l'utilisateur.
UserProfileViewModel automatiquement restauré lorsque la configuration est modifiée, donc dès qu'un nouveau fragment est créé, il obtient la même instance de
ViewModel et le rappel est appelé immédiatement à l'aide des données actuelles. Étant donné que les objets
ViewModel sont conçus pour survivre aux objets
View correspondants qu'ils mettent à jour, vous ne devez pas inclure de références directes aux objets
View dans votre implémentation ViewModel. Pour plus d'informations sur la durée de vie du
ViewModel correspond au cycle de vie des composants de l'interface utilisateur, voir
ViewModel Life Cycle.Récupération de données
Maintenant que nous avons utilisé LiveData pour connecter
UserProfileViewModel à
UserProfileFragment , comment pouvons-nous obtenir les données de profil utilisateur?
Dans cet exemple, nous supposons que notre backend fournit une API REST. Nous utilisons la bibliothèque Retrofit pour accéder à notre backend, bien que vous puissiez utiliser une bibliothèque différente qui sert le même objectif.
Voici notre définition d'un
Webservice qui relie à notre backend:
interface Webservice { @GET("/users/{user}") fun getUser(@Path("user") userId: String): Call<User> }
Une première idée pour implémenter un
ViewModel pourrait impliquer d'appeler
Webservice pour récupérer les données et affecter ces données à notre objet
LiveData . Cette conception fonctionne, mais son utilisation rend notre application plus difficile à maintenir à mesure qu'elle grandit. Cela donne trop de responsabilité à la classe
UserProfileViewModel , qui viole le principe de
séparation des intérêts . De plus, la portée du ViewModel est associée au cycle de vie de l'
activité ou du
fragment , ce qui signifie que les données du
Webservice perdues lorsque le cycle de vie de l'objet d'interface utilisateur associé se termine. Ce comportement crée une expérience utilisateur indésirable.
Au lieu de cela, notre
ViewModel délègue le processus de récupération des données à un nouveau module de stockage.
Les modules du référentiel gèrent les opérations de données. Ils fournissent une API propre pour que le reste de l'application puisse facilement obtenir ces données. Ils savent où obtenir les données et quels appels d'API effectuer lors de la mise à jour des données. Vous pouvez considérer les référentiels comme des intermédiaires entre différentes sources de données, telles que les modèles persistants, les services Web et les caches.Notre classe
UserRepository , illustrée dans l'extrait de code suivant, utilise une instance de
WebService pour récupérer les données utilisateur:
class UserRepository { private val webservice: Webservice = TODO()
Bien que le module de stockage semble inutile, il sert un objectif important: il extrait les sources de données du reste de l'application. Maintenant, notre
UserProfileViewModel ne sait pas comment récupérer des données, nous pouvons donc fournir des modèles de présentation avec des données obtenues à partir de plusieurs implémentations d'extraction de données différentes.
Remarque Nous avons raté le cas des erreurs de réseau pour plus de simplicité. Pour une implémentation alternative qui expose les erreurs et l'état de téléchargement, voir l'annexe: divulgation de l'état du réseau.
Gestion des dépendances entre les composantsLa classe
UserRepository ci-dessus a besoin d'une instance de
Webservice pour récupérer les données utilisateur. Il pourrait simplement créer une instance, mais pour cela, il doit également connaître les dépendances de la classe
Webservice . De plus,
UserRepository n'est probablement pas la seule classe à avoir besoin d'un service Web. Cette situation nous oblige à dupliquer le code, car chaque classe qui a besoin d'un lien vers le
Webservice doit savoir comment le créer et ses dépendances. Si chaque classe crée un nouveau
WebService , notre application peut devenir très gourmande en ressources.
Pour résoudre ce problème, vous pouvez utiliser les modèles de conception suivants:
- Injection de dépendance (DI) . L'injection de dépendances permet aux classes de définir leurs dépendances sans les créer. Au moment de l'exécution, une autre classe est chargée de fournir ces dépendances. Nous recommandons la bibliothèque Dagger 2 pour implémenter l'injection de dépendances dans les applications Android. Dagger 2 crée automatiquement des objets, en contournant l'arborescence des dépendances et fournit des garanties de compilation pour les dépendances.
- (Emplacement du service) Localisateur de services : le modèle de localisateur de services fournit un registre dans lequel les classes peuvent obtenir leurs dépendances au lieu de les créer.
L'implémentation d'un registre de services est plus facile que l'utilisation de DI, donc si vous débutez avec DI, utilisez plutôt le template: service location.
Ces modèles vous permettent de faire évoluer votre code car ils fournissent des modèles clairs pour gérer les dépendances sans dupliquer ou compliquer le code. De plus, ces modèles vous permettent de basculer rapidement entre les implémentations de test et de production d'échantillonnage de données.
Notre exemple d'application utilise
Dagger 2 pour gérer les dépendances de l'objet
Webservice .
Connectez ViewModel et Storage
Maintenant, nous modifions notre
UserProfileViewModel pour utiliser l'objet
UserRepository :
class UserProfileViewModel @Inject constructor( savedStateHandle: SavedStateHandle, userRepository: UserRepository ) : ViewModel() { val userId : String = savedStateHandle["uid"] ?: throw IllegalArgumentException("missing user id") val user : LiveData<User> = userRepository.getUser(userId) }
Mise en cache
L'implémentation
UserRepository résume l'invocation de l'objet
Webservice , mais comme elle ne repose que sur une seule source de données, elle n'est pas très flexible.
Le principal problème avec la mise en œuvre de
UserRepository est qu'après avoir reçu des données de notre backend, ces données ne sont stockées nulle part. Par conséquent, si l'utilisateur quitte
UserProfileFragment puis y revient, notre application doit récupérer les données, même si elles n'ont pas changé.
Cette conception n'est pas optimale pour les raisons suivantes:
- Il dépense de précieuses ressources de trafic.
- Cela oblige l'utilisateur à attendre la fin d'une nouvelle demande.
Pour remédier à ces lacunes, nous ajoutons une nouvelle source de données à notre
UserRepository , qui met en cache
User objets
User en mémoire:
Données persistantes
En utilisant notre implémentation actuelle, si l'utilisateur fait pivoter l'appareil ou quitte et revient immédiatement à l'application, l'interface utilisateur existante devient immédiatement visible, car le magasin récupère les données de notre cache en mémoire.
Cependant, que se passe-t-il si un utilisateur quitte l'application et revient quelques heures après la fin du processus sous Android OS? En nous appuyant sur notre implémentation actuelle dans cette situation, nous devons à nouveau récupérer les données du réseau. Ce processus de mise à niveau n'est pas seulement une mauvaise expérience utilisateur; c'est aussi un gaspillage car il consomme de précieuses données mobiles.
Vous pouvez résoudre ce problème en mettant en cache les demandes Web, mais cela crée un nouveau problème clé: que se passe-t-il si les mêmes données utilisateur sont affichées dans une demande d'un type différent, par exemple, lors de la réception d'une liste d'amis? L'application affichera des données contradictoires, ce qui est au mieux déroutant. Par exemple, notre application peut afficher deux versions différentes des données du même utilisateur si l'utilisateur a envoyé une demande de liste d'amis et une demande mono-utilisateur à des moments différents. Notre application devrait comprendre comment combiner ces données contradictoires.
La bonne façon de gérer cette situation est d'utiliser un modèle constant. La bibliothèque de données permanentes (DB) de
pièce vient à notre aide.
Room est une bibliothèque de cartographie d'objets qui fournit un stockage de données local avec un code standard minimum. Au moment de la compilation, il vérifie la conformité de chaque requête avec votre schéma de données, de sorte que les requêtes SQL qui ne fonctionnent pas entraînent des erreurs au moment de la compilation et non des blocages d'exécution. Résumés de salle de certains détails de base de l'implémentation des tables et requêtes SQL brutes. Il vous permet également d'observer les changements dans les données de base de données, y compris les collections et les demandes de connexion, exposant ces changements à l'aide d'objets LiveData. Il définit même explicitement les contraintes d'exécution qui résolvent les problèmes de threads courants, tels que l'accès au stockage dans le thread principal.
Remarque Si votre application utilise déjà une autre solution, telle que le mappage relationnel objet SQLite (ORM), vous n'avez pas besoin de remplacer la solution existante par Room. Cependant, si vous écrivez une nouvelle application ou réorganisez une application existante, nous vous recommandons d'utiliser Room pour enregistrer vos données d'application. Ainsi, vous pouvez profiter de l'abstraction de la bibliothèque et de la validation des requêtes.Pour utiliser Room, nous devons définir notre disposition locale. Tout d'abord, nous ajoutons l'annotation
@Entity à notre classe de modèle de données
User et l'annotation
@PrimaryKey dans le champ
id la classe. Ces annotations marquent l'
User comme table dans notre base de données et
id comme clé primaire de la table:
@Entity data class User( @PrimaryKey private val id: String, private val name: String, private val lastName: String )
Ensuite, nous créons la classe de base de données en implémentant
RoomDatabase pour notre application:
@Database(entities = [User::class], version = 1) abstract class UserDatabase : RoomDatabase()
Notez que
UserDatabase est abstrait. La bibliothèque de salle fournit automatiquement une implémentation de cela. Voir la documentation de
Room pour plus de détails.
Nous avons maintenant besoin d'un moyen d'insérer des données utilisateur dans la base de données. Pour cette tâche, nous créons
un objet d'accès aux données (DAO) .
@Dao interface UserDao { @Insert(onConflict = REPLACE) fun save(user: User) @Query("SELECT * FROM user WHERE id = :userId") fun load(userId: String): LiveData<User> }
Notez que la méthode de
load renvoie un objet de type LiveData. La salle sait quand la base de données est modifiée et informe automatiquement tous les observateurs actifs des changements de données. Puisque Room utilise
LiveData , cette opération est efficace; il met à jour les données uniquement s'il y a au moins un observateur actif.
Remarque: La salle vérifie l'invalidation en fonction des modifications de la table, ce qui signifie qu'elle peut envoyer des notifications fausses positives.Après avoir défini notre classe
UserDao , nous référençons ensuite le DAO à partir de notre classe de base de données:
@Database(entities = [User::class], version = 1) abstract class UserDatabase : RoomDatabase() { abstract fun userDao(): UserDao }
Nous pouvons maintenant modifier notre
UserRepository d'
UserRepository pour inclure la source de données de la salle:
Veuillez noter que même si nous avons changé la source de données dans
UserRepository , nous n'avons pas eu besoin de changer notre
UserProfileViewModel ou
UserProfileFragment . Cette petite mise à jour démontre la flexibilité de notre architecture d'application. Il est également idéal pour les tests car nous pouvons fournir un faux
UserRepository et tester notre production
UserProfileViewModel en même temps.
Si les utilisateurs reviennent dans quelques jours, une application utilisant cette architecture est susceptible d'afficher des informations obsolètes jusqu'à ce que le référentiel reçoive des informations mises à jour. Selon votre cas d'utilisation, vous pouvez ne pas afficher d'informations obsolètes. Au lieu de cela, vous pouvez afficher
des données d'
espace réservé , qui affichent des valeurs fictives et indiquent que votre application télécharge et charge actuellement des informations à jour.
La seule source de vérité.En règle générale, différents points de terminaison de l'API REST renvoient les mêmes données. Par exemple, si notre backend a un autre point de terminaison qui renvoie une liste d'amis, le même objet utilisateur peut provenir de deux points de terminaison API différents, éventuellement même en utilisant différents niveaux de détail. Si nous UserRepositoryrenvoyions la réponse de la demande Webservicetelle quelle, sans vérifier la cohérence, nos interfaces utilisateur pourraient afficher des informations confuses, car la version et le format des données du stockage dépendraient du dernier point de terminaison appelé.Pour cette raison, notre implémentation UserRepositorystocke les réponses des services Web dans une base de données. Les modifications apportées à la base de données déclenchent ensuite des rappels pour les objets LiveData actifs. En utilisant ce modèle, la base de données est la seule source de vérité et d'autres parties de l'application y accèdent via la nôtre UserRepository. Que vous utilisiez ou non un cache disque, nous recommandons que votre référentiel identifie la source de données comme la seule source de vérité pour le reste de votre application.Afficher la progression de l'opération
Dans certains cas d'utilisation, comme le pull-to-refresh, il est important que l'interface utilisateur montre à l'utilisateur qu'une opération réseau est en cours. Il est recommandé de séparer l'action de l'interface utilisateur des données réelles, car les données peuvent être mises à jour pour diverses raisons. Par exemple, si nous obtenons une liste d'amis, le même utilisateur peut être sélectionné à nouveau par programme, ce qui entraînera une mise à jour de LiveData. Du point de vue de l'interface utilisateur, le fait d'avoir une requête en vol n'est qu'un autre point de données, similaire à n'importe quelle autre donnée dans l'objet lui-même User.Nous pouvons utiliser l'une des stratégies suivantes pour afficher l'état de mise à jour des données convenu dans l'interface utilisateur, indépendamment de l'origine de la demande de mise à jour des données:Dans la section sur la séparation des intérêts, nous avons mentionné que l'un des principaux avantages de suivre ce principe est la testabilité.La liste suivante montre comment tester chaque module de code à partir de notre exemple étendu:- Interface utilisateur et interaction : utilisez la boîte à outils de test de l'interface utilisateur Android . La meilleure façon de créer ce test est d'utiliser la bibliothèque Espresso . Vous pouvez créer un fragment et lui fournir une mise en page
UserProfileViewModel. Étant donné que le fragment n'est associé qu'à UserProfileViewModel, la simulation (imitation) de cette seule classe suffit pour tester complètement l'interface utilisateur de votre application. - ViewModel:
UserProfileViewModel JUnit . , UserRepository . - UserRepository:
UserRepository JUnit. Webservice UserDao . :
Webservice , UserDao , .- UserDao: DAO . - , . , , , …
: Room , DAO, JSQL SupportSQLiteOpenHelper . , SQLite SQLite . - -: . , -, . , MockWebServer , .
- : maven .
androidx.arch.core : JUnit:
InstantTaskExecutorRule: .CountingTaskExecutorRule: . Espresso .
La programmation est un domaine créatif et la création d'applications Android ne fait pas exception. Il existe de nombreuses façons de résoudre le problème, qu'il s'agisse de transférer des données entre plusieurs actions ou fragments, de récupérer des données supprimées et de les stocker localement hors ligne, ou de nombreux autres scénarios courants rencontrés par des applications non triviales.Bien que les recommandations suivantes ne soient pas requises, notre expérience montre que leur implémentation rend votre base de code plus fiable, testable et prise en charge à long terme:évitez de désigner les points d'entrée de votre application - tels que les actions, les services et les récepteurs de diffusion - comme sources de données.Au lieu de cela, ils ont seulement besoin de se coordonner avec d'autres composants pour obtenir un sous-ensemble des données liées à ce point d'entrée. Chaque composant de l'application est assez éphémère, selon l'interaction de l'utilisateur avec son appareil et l'état général actuel du système.Créez des lignes de responsabilité claires entre les différents modules de votre application.Par exemple, ne distribuez pas de code qui télécharge des données du réseau vers plusieurs classes ou packages de votre base de code. De même, ne définissez pas plusieurs responsabilités non liées - telles que la mise en cache et la liaison de données - dans la même classe.Exposez le moins possible de chaque module.Résistez à la tentation de créer une étiquette «juste un» qui révèle les détails d'une implémentation interne d'un module. Vous pouvez gagner du temps à court terme, mais vous encourrez alors une dette technique plusieurs fois à mesure que votre base de code se développera.Réfléchissez à la façon de rendre chaque module testable de manière isolée.Par exemple, avoir une API bien définie pour récupérer des données du réseau facilite le test d'un module qui stocke ces données dans une base de données locale. Si au contraire vous mélangez la logique de ces deux modules en un seul endroit ou distribuez votre code réseau à travers la base de code, le test devient beaucoup plus difficile - dans certains cas, même pas impossible.Concentrez-vous sur le cœur unique de votre application pour vous démarquer des autres applications.Ne réinventez pas la roue en écrivant le même motif encore et encore. Au lieu de cela, concentrez votre temps et votre énergie sur ce qui rend votre application unique et laissez les composants de l'architecture Android et les autres bibliothèques recommandées faire face à un modèle répétitif.Conservez autant de données pertinentes et récentes que possible.Ainsi, les utilisateurs peuvent profiter des fonctionnalités de votre application, même si leur appareil est hors ligne. N'oubliez pas que tous vos utilisateurs n'utilisent pas une connexion haut débit constante.Désignez une seule source de données comme seule véritable source.Chaque fois que votre application a besoin d'accéder à cette donnée, elle doit toujours provenir de cette seule source de vérité.Addendum: divulgation de l'état du réseau
Dans la section ci-dessus de l'architecture d'application recommandée, nous avons ignoré les erreurs réseau et les états de démarrage pour simplifier les extraits de code.Cette section montre comment afficher l'état du réseau à l'aide de la classe Resource, qui encapsule à la fois les données et son état.L'extrait de code suivant fournit un exemple d'implémentationResource:
Étant donné que le téléchargement de données à partir du réseau lors de l'affichage d'une copie de ces données est une pratique courante, il est utile de créer une classe d'assistance qui peut être réutilisée à plusieurs endroits. Pour cet exemple, nous créons une classe avec le nom NetworkBoundResource.Le diagramme suivant montre l'arbre de décision pour NetworkBoundResource: Il commence par observer la base de données de la ressource. Lorsqu'un enregistrement est téléchargé depuis la base de données pour la première fois, il
Il commence par observer la base de données de la ressource. Lorsqu'un enregistrement est téléchargé depuis la base de données pour la première fois, il NetworkBoundResourcevérifie si le résultat est suffisamment bon pour être envoyé ou s'il doit être récupéré sur le réseau. Veuillez noter que ces deux situations peuvent se produire simultanément, étant donné que vous souhaitez probablement afficher les données mises en cache lors de la mise à jour à partir du réseau.Si l'appel réseau réussit, il stocke la réponse dans la base de données et réinitialise le flux. En cas d' NetworkBoundResourceéchec d'une demande de réseau , il envoie l'échec directement.. . , .Gardez à l'esprit que compter sur une base de données pour envoyer des modifications implique l'utilisation d'effets secondaires associés, ce qui n'est pas très bon car le comportement indéfini de ces effets secondaires peut se produire si la base de données n'envoie pas les modifications car les données n'ont pas changé.N'envoyez pas non plus les résultats reçus du réseau, car cela viole le principe d'une seule source de vérité. Au final, il est possible que la base de données contienne des déclencheurs qui modifient les valeurs des données lors de l'opération de sauvegarde. De même, n'envoyez pas «SUCCÈS» sans nouvelles données, car alors le client recevra la mauvaise version des données.L'extrait de code suivant montre l'API ouverte fournie par la classe NetworkBoundResourcepour ses sous-classes:
Faites attention aux détails importants suivants de la définition de classe:- Il définit deux paramètres de type,
ResultTypeet RequestTypepuisque le type de données renvoyé par l'API peut ne pas correspondre au type de données utilisé localement. - Il utilise une classe
ApiResponsepour les requêtes réseau. ApiResponseEst un simple wrapper pour une classe Retrofit2.Callqui convertit les réponses en instances LiveData.
L'implémentation complète de la classe NetworkBoundResourceapparaît dans le cadre du projet GitHub android-Architecture-components .Une fois créé, NetworkBoundResourcenous pouvons l'utiliser pour écrire nos implémentations de disque et de réseau Userdans la classe UserRepository: