
Bonjour lecteurs d'Habr! Le sujet de cet article sera la mise en œuvre de la tolérance aux catastrophes dans les systèmes de stockage AERODISK Engine. Initialement, nous voulions écrire dans un article sur les deux moyens: la réplication et le cluster de métro, mais, malheureusement, l'article s'est avéré trop volumineux, nous avons donc divisé l'article en deux parties. Passons du simple au complexe. Dans cet article, nous allons configurer et tester la réplication synchrone - supprimer un centre de données et couper également le canal de communication entre les centres de données et voir ce qui se passe.
Nos clients nous posent souvent des questions différentes sur la réplication.Par conséquent, avant de passer à la configuration et au test de l'implémentation de la réplique, nous vous expliquerons un peu ce qu'est la réplication dans les systèmes de stockage.
Un peu de théorie
La réplication vers le stockage est un processus continu visant à garantir l'identité des données sur plusieurs systèmes de stockage simultanément. Techniquement, la réplication est effectuée par deux méthodes.
La réplication synchrone est la copie des données du système de stockage principal vers le système de sauvegarde, suivie de la confirmation obligatoire des deux systèmes de stockage que les données sont enregistrées et confirmées. C'est après confirmation des deux côtés (sur les deux systèmes de stockage) que les données sont considérées comme enregistrées, et vous pouvez travailler avec elles. Cela garantit une identité de données garantie sur tous les systèmes de stockage participant à la réplique.
Les avantages de cette méthode:
- Les données sont toujours identiques sur tous les systèmes de stockage.
Inconvénients:
- Coût élevé de la solution (canaux de communication rapides, fibre coûteuse, émetteurs-récepteurs à ondes longues, etc.)
- Restrictions de distance (dans quelques dizaines de kilomètres)
- Il n'y a aucune protection contre la corruption des données logiques (si les données sont corrompues (sciemment ou accidentellement) sur le système de stockage principal, alors elles seront automatiquement et immédiatement corrompues sur le stockage de sauvegarde, car les données sont toujours identiques (c'est un paradoxe)
La réplication asynchrone consiste également à copier des données du stockage principal vers la sauvegarde, mais avec un certain retard et sans avoir besoin de confirmer l'enregistrement de l'autre côté. Vous pouvez travailler avec les données immédiatement après l'écriture dans le stockage principal et sur le stockage de sauvegarde, les données seront disponibles après un certain temps. L'identité des données dans ce cas, bien sûr, n'est pas du tout fournie. Les données sur le stockage de sauvegarde sont toujours un peu «dans le passé».
Avantages de la réplication asynchrone:
- Faible coût de la solution (tous les canaux de communication, optique en option)
- Aucune limite de distance
- Les données sur le stockage de sauvegarde ne sont pas corrompues si elles sont corrompues sur le principal (au moins pendant un certain temps), si les données sont corrompues, vous pouvez toujours arrêter la réplique pour éviter la corruption des données sur le stockage de sauvegarde
Inconvénients:
- Les données dans différents centres de données ne sont pas toujours identiques
Ainsi, le choix du mode de réplication dépend des tâches de l'entreprise. S'il est essentiel pour vous que le centre de données de sauvegarde ait exactement les mêmes données que les données principales (c'est-à-dire les exigences commerciales pour RPO = 0), vous devrez débourser et accepter les limitations de la réplique synchrone. Et si le retard dans l'état des données est admissible ou s'il n'y a tout simplement pas d'argent, alors, vous devez certainement utiliser la méthode asynchrone.
Nous distinguons également séparément un tel régime (plus précisément, déjà une topologie) comme un cluster de métro. Le mode métrocluster utilise la réplication synchrone, mais, contrairement à une réplique régulière, le métrocluster permet aux deux systèmes de stockage de fonctionner en mode actif. C'est-à-dire vous n'avez pas de séparation des centres de données en veille active. Les applications fonctionnent simultanément avec deux systèmes de stockage physiquement situés dans différents centres de données. Les temps d'arrêt des accidents dans une telle topologie sont très faibles (RTO, généralement quelques minutes). Dans cet article, nous ne considérerons pas notre implémentation du cluster de métro, car il s'agit d'un sujet très vaste et vaste, nous allons donc lui consacrer un article distinct, suivant dans la suite de celui-ci.
Très souvent également, lorsque nous parlons de réplication à l'aide de systèmes de stockage, beaucoup ont une question raisonnable:> «De nombreuses applications ont leurs propres outils de réplication, pourquoi utiliser la réplication sur les systèmes de stockage? Est-ce mieux ou pire? "
Il n'y a pas de réponse unique, voici donc les avantages et les inconvénients:
Arguments POUR la réplication du stockage:
- La simplicité de la solution. D'une manière, vous pouvez répliquer un tableau complet de données, quel que soit le type de chargement ou l'application. Si vous utilisez une réplique d'applications, vous devrez configurer chaque application séparément. S'il y en a plus de 2, cela prend beaucoup de temps et coûte cher (la réplication des applications nécessite, en règle générale, une licence distincte et non gratuite pour chaque application. Mais plus à ce sujet ci-dessous).
- Vous pouvez reproduire n'importe quoi - toutes les applications, toutes les données - et elles seront toujours cohérentes. De nombreuses (la plupart) des applications ne disposent pas d'installations de réplication et les répliques du côté stockage sont le seul moyen de fournir une protection contre les catastrophes.
- Pas besoin de surpayer pour la fonctionnalité de réplication d'application. En règle générale, cela coûte cher, tout comme les licences pour un système de stockage de réplique. Mais vous ne devez payer la licence de réplication de stockage qu'une seule fois, et vous devez acheter la licence pour la réplique d'application pour chaque application séparément. S'il y a beaucoup de telles applications, cela coûte un sou et le coût des licences pour la réplication du stockage devient une goutte d'eau.
Arguments CONTRE la réplication de stockage:
- La réplique utilisant des outils d'application a plus de fonctionnalités du point de vue des applications elles-mêmes, l'application connaît mieux ses données (ce qui est évident), il y a donc plus d'options pour travailler avec elles.
- Les fabricants de certaines applications ne garantissent pas la cohérence de leurs données si la réplication est effectuée par des outils tiers. *
* - une thèse controversée. Par exemple, une société de fabrication de SGBD bien connue a officiellement déclaré pendant très longtemps que son SGBD ne peut normalement être répliqué que par ses moyens, et que le reste de la réplication (y compris SHD-shnaya) n'est «pas vrai». Mais la vie a montré que ce n'est pas le cas. Très probablement (mais ce n'est pas exact) ce n'est tout simplement pas la tentative la plus honnête de vendre plus de licences aux clients.
Par conséquent, dans la plupart des cas, la réplication du côté stockage est meilleure, car Il s'agit d'une option plus simple et moins coûteuse, mais il existe des cas complexes lorsque vous avez besoin de fonctionnalités d'application spécifiques et que vous devez travailler avec la réplication au niveau de l'application.
Avec la théorie terminée, maintenant pratique
Nous allons mettre en place une réplique dans notre laboratoire. En laboratoire, nous avons émulé deux centres de données (en fait, deux racks adjacents qui semblent être dans des bâtiments différents). Le stand se compose de deux systèmes de stockage Engine N2, qui sont interconnectés par des câbles optiques. Un serveur physique exécutant Windows Server 2016 utilisant Ethernet 10 Go est connecté aux deux systèmes de stockage. Le support est assez simple, mais il ne change pas l'essence.
Schématiquement, cela ressemble à ceci:
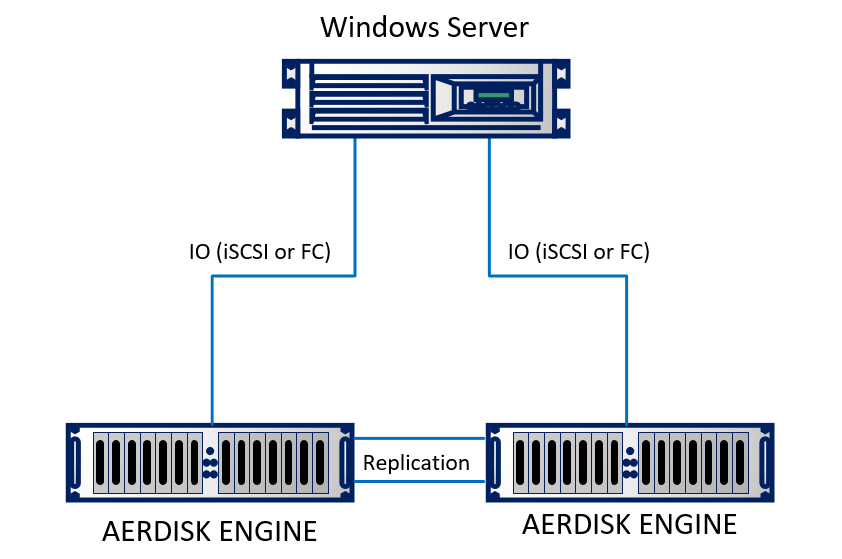
La réplication est organisée de la manière suivante:
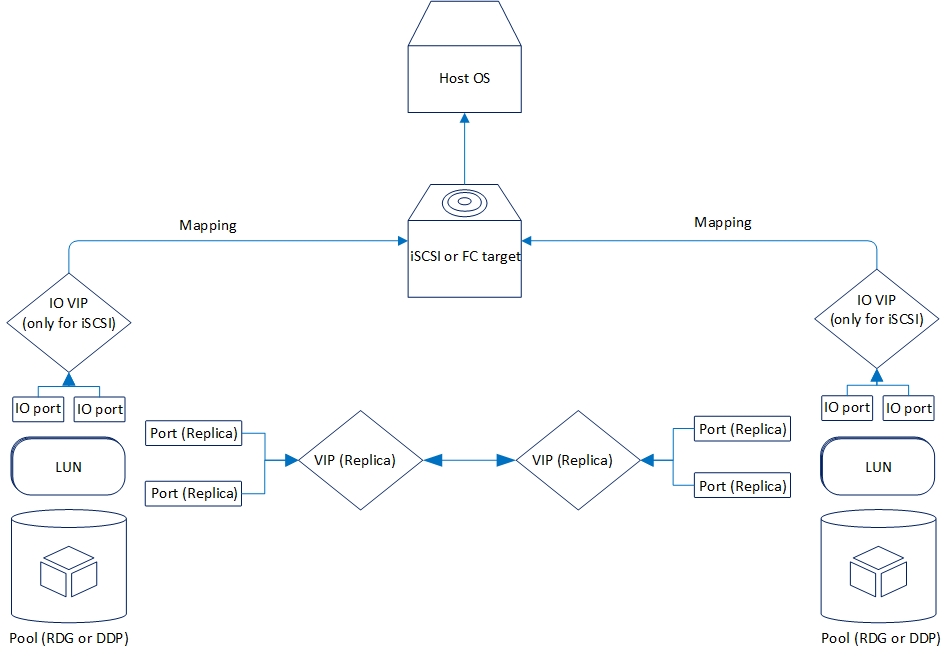
Examinons maintenant la fonctionnalité de réplication que nous avons maintenant.
Deux modes sont pris en charge: asynchrone et synchrone. Il est logique que le mode synchrone soit limité par la distance et le canal de communication. En particulier, le mode synchrone nécessite l'utilisation de la fibre comme physique et Ethernet 10 gigabits (ou supérieur).
La distance prise en charge pour la réplication synchrone est de 40 kilomètres; le retard du canal optique entre les centres de données peut aller jusqu'à 2 millisecondes. En général, cela fonctionnera avec des retards importants, mais il y aura ensuite des freins puissants lors de l'enregistrement (ce qui est également logique), donc si vous envisagez une réplication synchrone entre les centres de données, vous devez vérifier la qualité de l'optique et des retards.
Les exigences de réplication asynchrone ne sont pas si graves. Plus précisément, ils ne le sont pas du tout. Toute connexion Ethernet fonctionnelle convient.
À l'heure actuelle, le stockage AERODISK ENGINE prend en charge la réplication des périphériques de bloc (LUN) à l'aide du protocole Ethernet (cuivre ou optique). Pour les projets qui nécessitent nécessairement une réplication via l'usine SAN Fibre Channel, nous complétons maintenant la solution appropriée, mais jusqu'à présent elle n'est pas prête, donc dans notre cas uniquement Ethernet.
La réplication peut fonctionner entre tous les systèmes de stockage de la série ENGINE (N1, N2, N4) des systèmes inférieurs aux anciens et vice versa.
La fonctionnalité des deux modes de réplication est complètement identique. Voici plus sur ce qui est:
- Réplication "one to one" ou "one to one", c'est-à-dire la version classique avec deux centres de données, le principal et la sauvegarde
- La réplication est «un à plusieurs» ou «un à plusieurs», c'est-à-dire un LUN peut être répliqué sur plusieurs systèmes de stockage à la fois
- Activation, désactivation et «inversion» de la réplication, respectivement, pour activer, désactiver ou changer le sens de la réplication
- La réplication est disponible pour les pools RDG (Raid Distributed Group) et DDP (Dynamic Disk Pool). Cependant, le LUN du pool RDG ne peut être répliqué que sur un autre RDG. C DDP est similaire.
Il y a beaucoup plus de petites fonctionnalités, mais les lister n'a pas beaucoup de sens, nous les mentionnerons lors de la configuration.
Configuration de la réplication
Le processus de configuration est assez simple et comprend trois étapes.
- Configuration du réseau
- Configuration du stockage
- Configuration de règles (liens) et mappage
Un point important dans la configuration de la réplication est que les deux premières étapes doivent être répétées sur un système de stockage distant, la troisième étape - uniquement sur le principal.
Configuration des ressources réseau
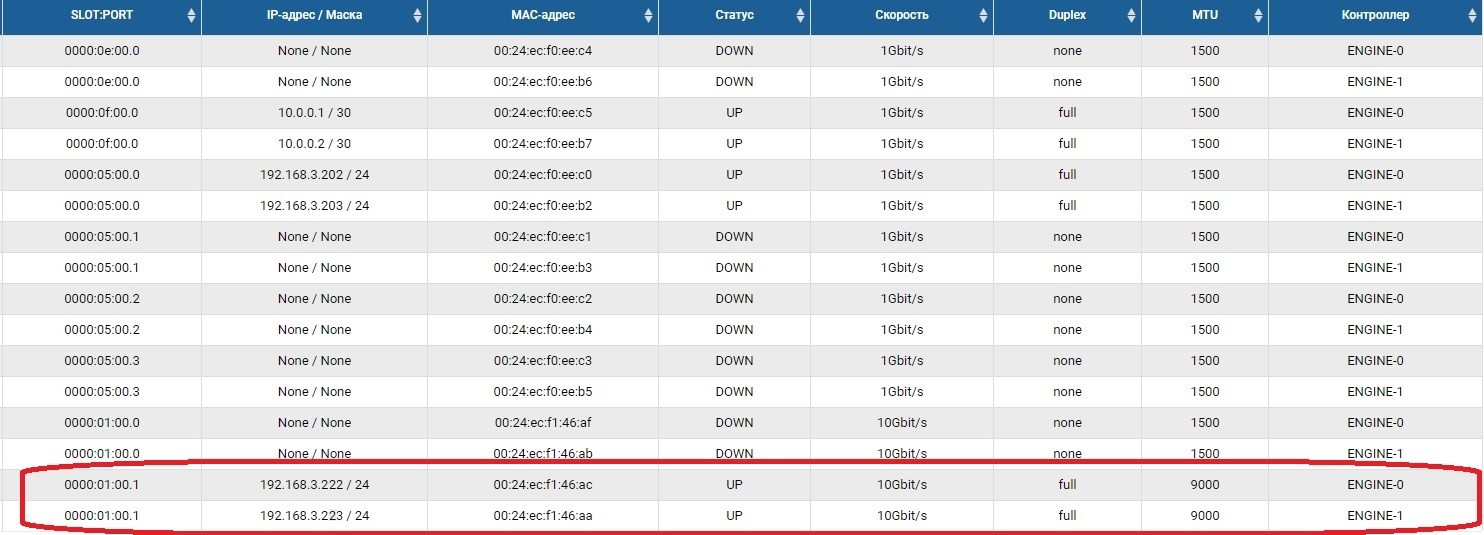
La première étape consiste à configurer les ports réseau via lesquels le trafic de réplication sera transmis. Pour ce faire, vous devez activer les ports et définir des adresses IP dessus dans la section Adaptateurs frontaux.
Après cela, nous devons créer un pool (dans notre cas RDG) et une IP virtuelle pour la réplication (VIP). VIP est une adresse IP flottante qui est liée à deux adresses «physiques» des contrôleurs de stockage (les ports que nous venons de configurer). Ce sera l'interface de réplication principale. Vous pouvez également fonctionner non pas avec VIP, mais avec VLAN si vous devez travailler avec du trafic balisé.
Le processus de création d'un VIP pour une réplique n'est pas très différent de la création d'un VIP pour les E / S (NFS, SMB, iSCSI). Dans ce cas, nous créons un VIP (sans VLAN), mais assurez-vous d'indiquer que c'est pour la réplication (sans ce pointeur, nous ne pourrons pas ajouter VIP à la règle à l'étape suivante).
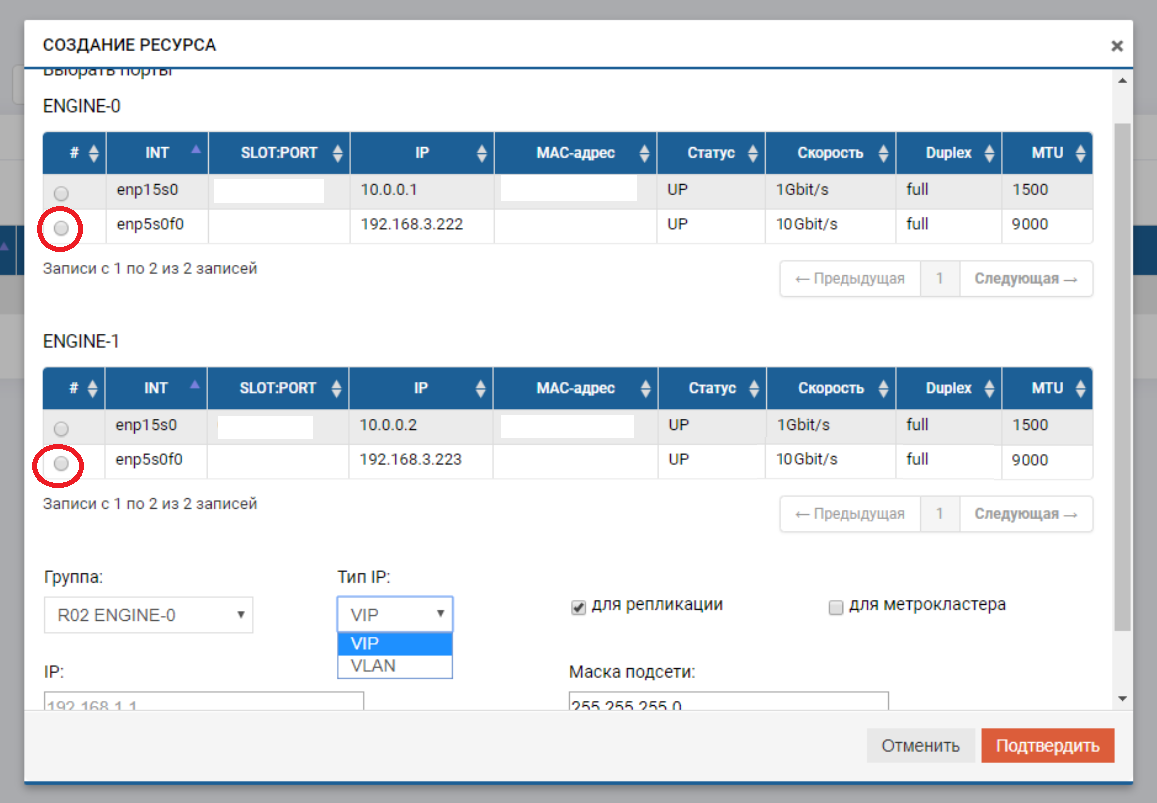
VIP doit être sur le même sous-réseau que les ports IP entre lesquels il «flotte».

Nous répétons ces paramètres sur le système de stockage distant, avec un autre IP-shnik, par lui-même.
Les VIP de différents systèmes de stockage peuvent être dans différents sous-réseaux, l'essentiel est qu'il doit y avoir un routage entre eux. Dans notre cas, cet exemple vient d'être montré (192.168.3.XX et 192.168.2.XX)

Sur ce point, la préparation de la partie réseau est terminée.
Configurer le stockage
La configuration du stockage pour une réplique diffère de celle habituelle uniquement en ce que nous effectuons le mappage via le menu spécial «Mappage de réplication». Sinon, tout est le même qu'avec le réglage habituel. Maintenant en ordre.
Dans le pool R02 précédemment créé, vous devez créer un LUN. Créez, appelez-le LUN1.
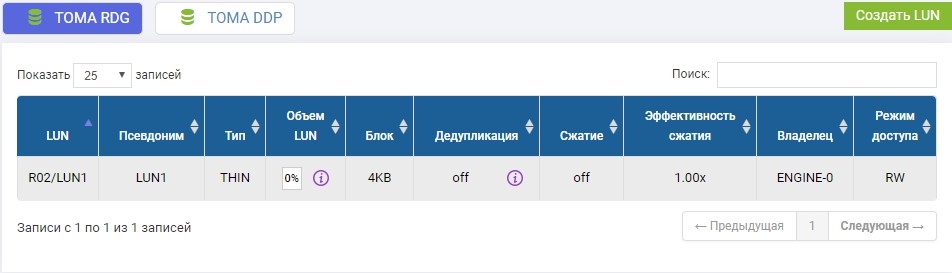
Nous devons également créer le même LUN sur un système de stockage distant de volume identique. Nous créons. Pour éviter toute confusion, le LUN distant sera appelé LUN1R
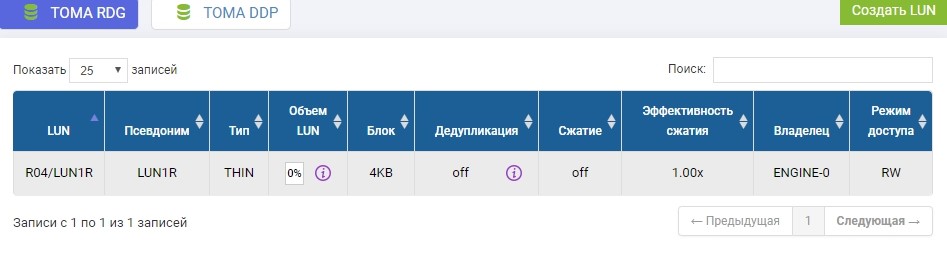
Si nous devions prendre un LUN qui existe déjà, au moment de la configuration de la réplique, ce LUN productif devrait être démonté de l'hôte, et sur le système de stockage distant, créez simplement un LUN vide de taille identique.
La configuration du stockage est terminée, nous procédons à la création de la règle de réplication.
Configurer des règles de réplication ou des liens de réplication
Après avoir créé des LUN sur le stockage, qui sera le principal à l'heure actuelle, nous configurons la règle de réplication LUN1 sur SHD1 dans LUN1R sur SHD2.
La configuration est effectuée dans le menu de réplication à distance.
Créez une règle. Pour ce faire, spécifiez le destinataire de la réplique. Nous spécifions également le nom de la connexion et le type de réplication (synchrone ou asynchrone).
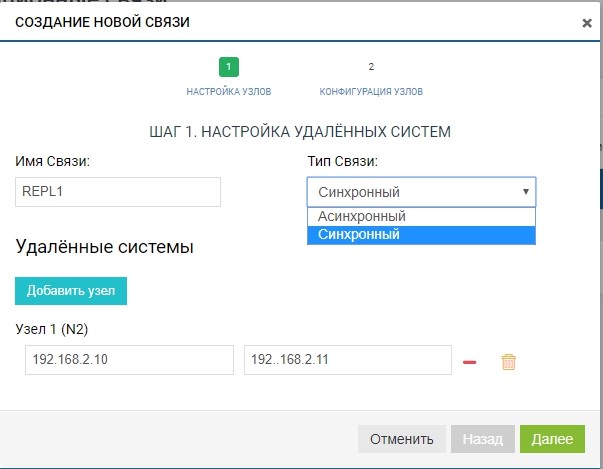
Dans le champ «systèmes distants», ajoutez notre SHD2. Pour ajouter, vous devez utiliser le stockage IP de gestion (MGR) et le nom du LUN distant vers lequel nous allons répliquer (dans notre cas, LUN1R). La gestion des adresses IP n'est nécessaire qu'au stade de l'ajout de communication; le trafic de réplication qui les traverse ne sera pas transmis; pour cela, le VIP précédemment configuré sera utilisé.
Déjà à ce stade, nous pouvons ajouter plusieurs systèmes distants pour la topologie «un à plusieurs»: cliquez sur le bouton «ajouter un nœud», comme dans la figure ci-dessous.
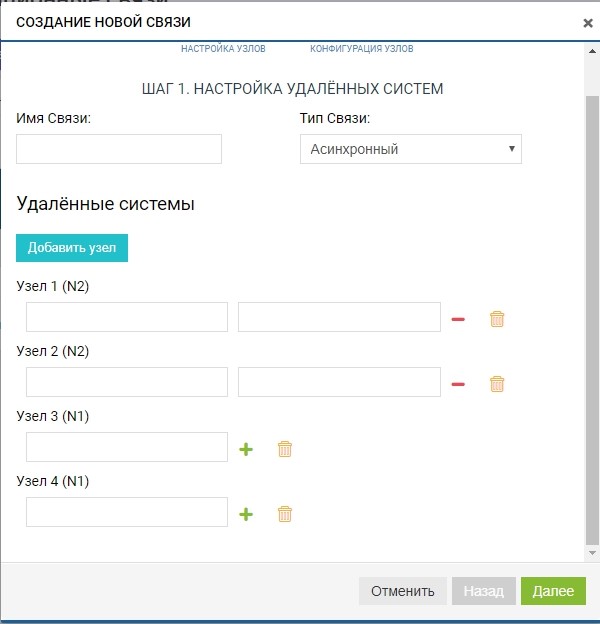
Dans notre cas, le système distant en est un, nous sommes donc limités à cela.
La règle est prête. Notez qu'il est automatiquement ajouté à tous les participants à la réplication (dans notre cas, il y en a deux). Vous pouvez créer autant de règles que vous le souhaitez, pour n'importe quel nombre de LUN et dans n'importe quelle direction. Par exemple, pour équilibrer la charge, nous pouvons répliquer une partie des LUN de SHD1 à SHD2, et l'autre partie, au contraire, de SHD2 à SHD1.
SHD1. Immédiatement après la création, la synchronisation a commencé.
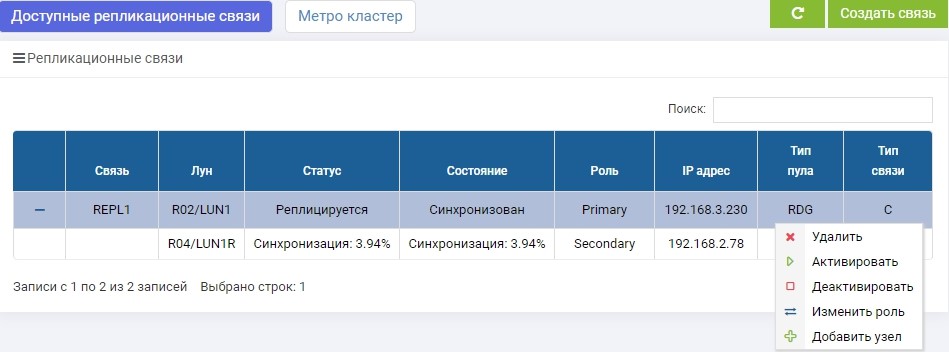
SHD2. Nous voyons la même règle, mais la synchronisation est déjà terminée.
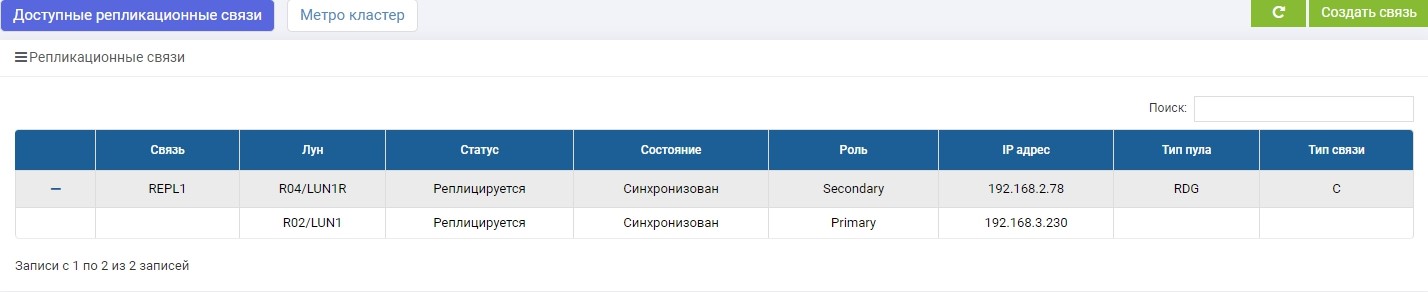
LUN1 sur SHD1 a le rôle de principal, c'est-à-dire qu'il est actif. LUN1R sur SHD2 a le rôle de secondaire, c'est-à-dire qu'il est en attente, en cas de défaillance de SHD1.
Nous pouvons maintenant connecter notre LUN à l'hôte.
Nous ferons la connexion via iSCSI, bien que cela puisse être fait via FC. La configuration du mappage pour iSCSI LUN dans une réplique n'est pratiquement pas différente du scénario habituel, nous n'en discuterons donc pas en détail ici. Si quelque chose, ce processus est décrit dans l'article de configuration rapide .
La seule différence est que nous créons un mappage dans le menu "Mappage de réplication".
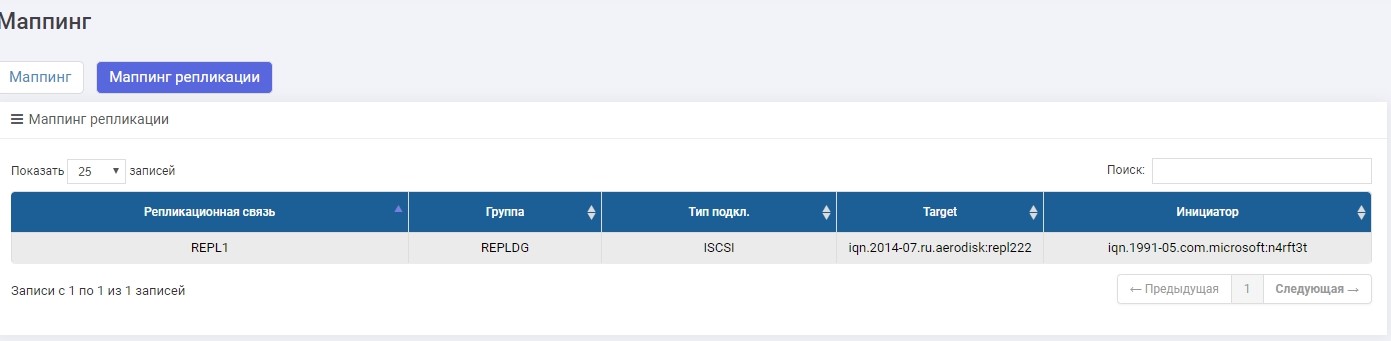
Configurez le mappage, donnez le LUN à l'hôte. L'hôte a vu un LUN.
Formatez-le dans le système de fichiers local.
Voilà, la configuration est terminée. Suivront les tests.
Test
Nous allons tester trois scénarios principaux.
- Le personnel change de rôle Secondaire> Primaire. Un changement de rôle régulier est nécessaire dans le cas, par exemple, où nous avons principalement besoin d'un centre de données pour effectuer certaines opérations préventives, et pendant ce temps, afin que les données soient disponibles, nous transférons la charge vers le centre de données de sauvegarde.
- Basculement des rôles Secondaire> Primaire (défaillance du centre de données). Il s'agit du scénario principal pour lequel il existe une réplication, ce qui peut aider à survivre à une défaillance complète du centre de données sans arrêter l'entreprise pendant longtemps.
- Canaux de communication rompus entre les centres de données. Vérifier le bon comportement des deux systèmes de stockage dans des conditions où, pour une raison quelconque, le canal de communication entre les centres de données n'est pas disponible (par exemple, l'excavatrice a creusé au mauvais endroit et a déchiré l'optique sombre).
Pour commencer, nous allons commencer à écrire des données sur notre LUN (nous écrivons des fichiers avec des données aléatoires). Nous constatons immédiatement que le canal de communication entre les systèmes de stockage est utilisé. Ceci est facile à comprendre si vous ouvrez la surveillance de la charge des ports qui sont responsables de la réplication.
Sur les deux systèmes de stockage, il existe désormais des données «utiles», nous pouvons commencer le test.
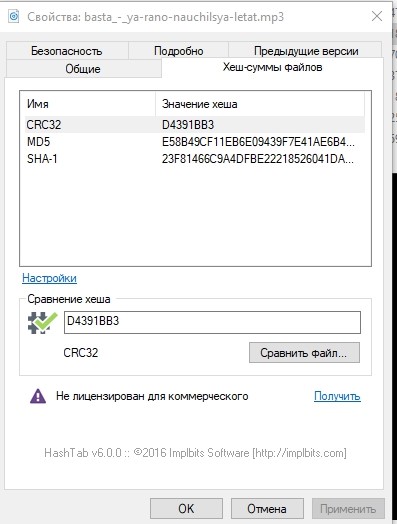
Juste au cas où, regardons les sommes de hachage de l'un des fichiers et notons-le.
Changement de rôle du personnel
L'opération de changement de rôle (changement de direction de la réplication) peut être effectuée à partir de n'importe quel système de stockage, mais vous devez toujours aller aux deux, car vous devrez désactiver le mappage sur le primaire et l'activer sur le secondaire (qui deviendra principal).
Peut-être que maintenant une question raisonnable se pose: pourquoi ne pas automatiser cela? Nous répondons: tout est simple, la réplication est un simple outil de tolérance aux catastrophes basé uniquement sur des opérations manuelles. Pour automatiser ces opérations, il existe un mode cluster métropolitain, il est entièrement automatisé, mais sa configuration est beaucoup plus compliquée. Nous écrirons sur la configuration du cluster de métro dans le prochain article.
Désactivez le mappage sur le stockage principal pour vous assurer que l'enregistrement est arrêté.
Ensuite, sur l'un des systèmes de stockage (peu importe, sur le serveur principal ou de sauvegarde) dans le menu de réplication à distance, sélectionnez notre connexion REPL1 et cliquez sur «Changer de rôle».
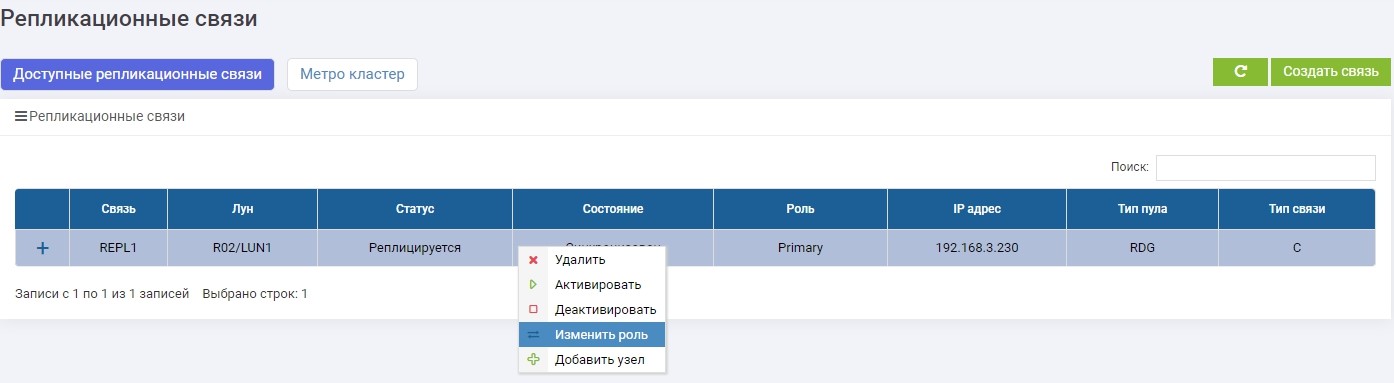
Après quelques secondes, LUN1R (stockage de sauvegarde) devient principal.
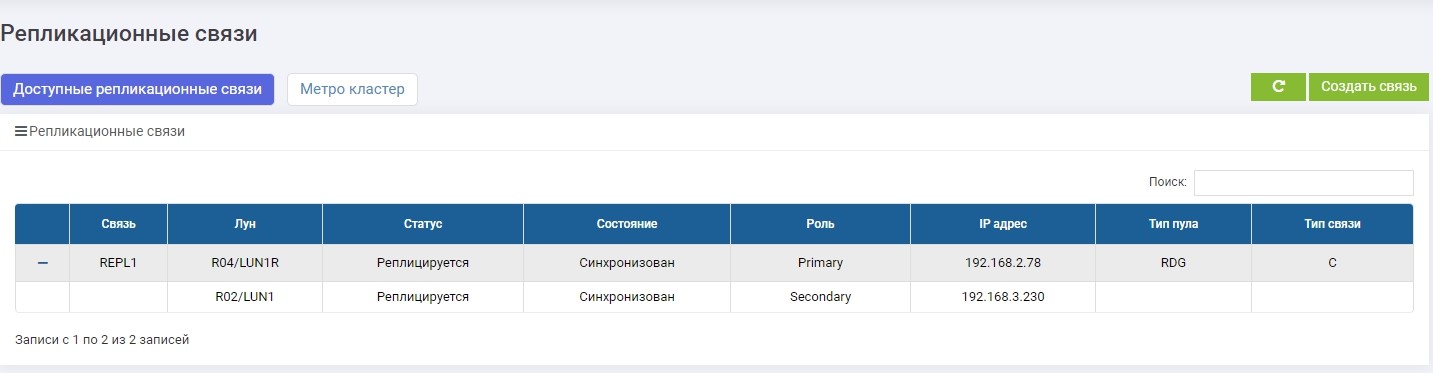
Nous faisons le mappage de LUN1R avec SHD2.
Après cela, notre lecteur E: s'accroche automatiquement à l'hôte, mais cette fois, il a «volé» avec LUN1R.
Au cas où, comparez les quantités de hachage.
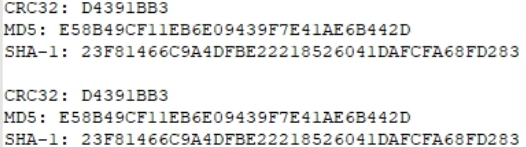
Identique. Test réussi.
Basculement Échec du centre de données
À l'heure actuelle, le stockage principal après commutation régulière est SHD2 et LUN1R, respectivement. Pour simuler un accident, nous coupons l'alimentation des deux contrôleurs SHD2.
L'accès n'est plus.
Nous regardons ce qui se passe sur le stockage 1 (sauvegarde en ce moment).

Nous voyons que le LUN primaire (LUN1R) n'est pas disponible. Un message d'erreur est apparu dans les journaux, dans le panneau d'informations, ainsi que dans la règle de réplication elle-même. Par conséquent, les données de l'hôte ne sont actuellement pas disponibles.
Remplacez le rôle de LUN1 par Primary.
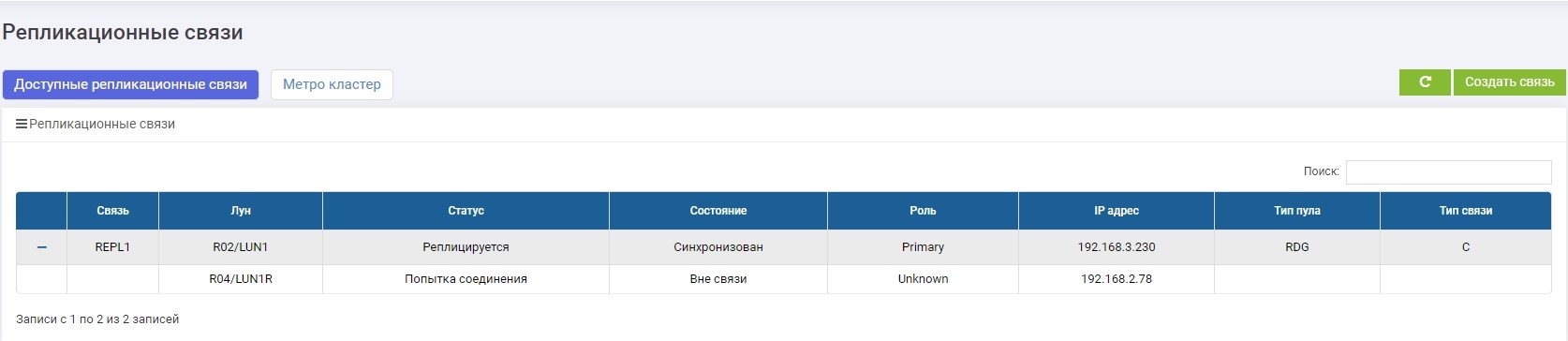
Cartographie des affaires avec l'hôte.

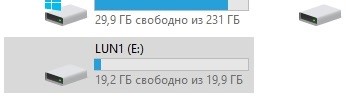
Assurez-vous que le lecteur E apparaît sur l'hôte.
Vérifiez le hachage.
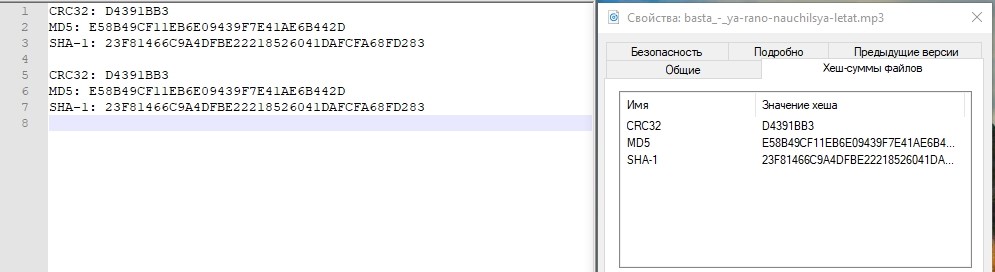
Tout va bien. Le centre de stockage a subi une chute du centre de données, qui était actif. Le temps approximatif que nous avons consacré à la connexion de l '«inversion» de la réplication et à la connexion du LUN à partir du centre de données de sauvegarde était d'environ 3 minutes. Il est clair que dans le produit réel, tout est beaucoup plus compliqué, et en plus des actions avec les systèmes de stockage, vous devez effectuer beaucoup plus d'opérations sur le réseau, sur les hôtes, dans les applications. Et dans la vie, cette période sera beaucoup plus longue.
Ici, je veux écrire que tout, le test s'est terminé avec succès, mais ne nous précipitons pas. Le stockage principal "ment", on sait que lorsqu'elle "tomba", elle était dans le rôle de Primaire. Que se passe-t-il si elle s'allume soudainement? Il y aura deux rôles principaux, ce qui équivaut à la corruption de données? Nous allons le vérifier maintenant.
Nous allons soudain allumer le stockage sous-jacent.
Il se charge pendant plusieurs minutes et redevient opérationnel après une courte synchronisation, mais déjà dans le rôle de Secondaire.

Tout va bien. Le cerveau divisé ne s'est pas produit. Nous avons pensé à cela, et toujours après la chute du système de stockage monte dans le rôle de secondaire, quel que soit son rôle "dans la vie". Maintenant, nous pouvons affirmer avec certitude que le test de défaillance du centre de données a réussi.
Défaillance des canaux de communication entre les centres de données
La tâche principale de ce test est de s'assurer que le système de stockage ne commencera pas à paniquer s'il a temporairement perdu les canaux de communication entre les deux systèmes de stockage et qu'il réapparaît ensuite.
Alors. Nous déconnectons les fils entre les systèmes de stockage (imaginez qu'une excavatrice les a creusés).
Sur le primaire, nous voyons qu'il n'y a aucun lien avec le secondaire.
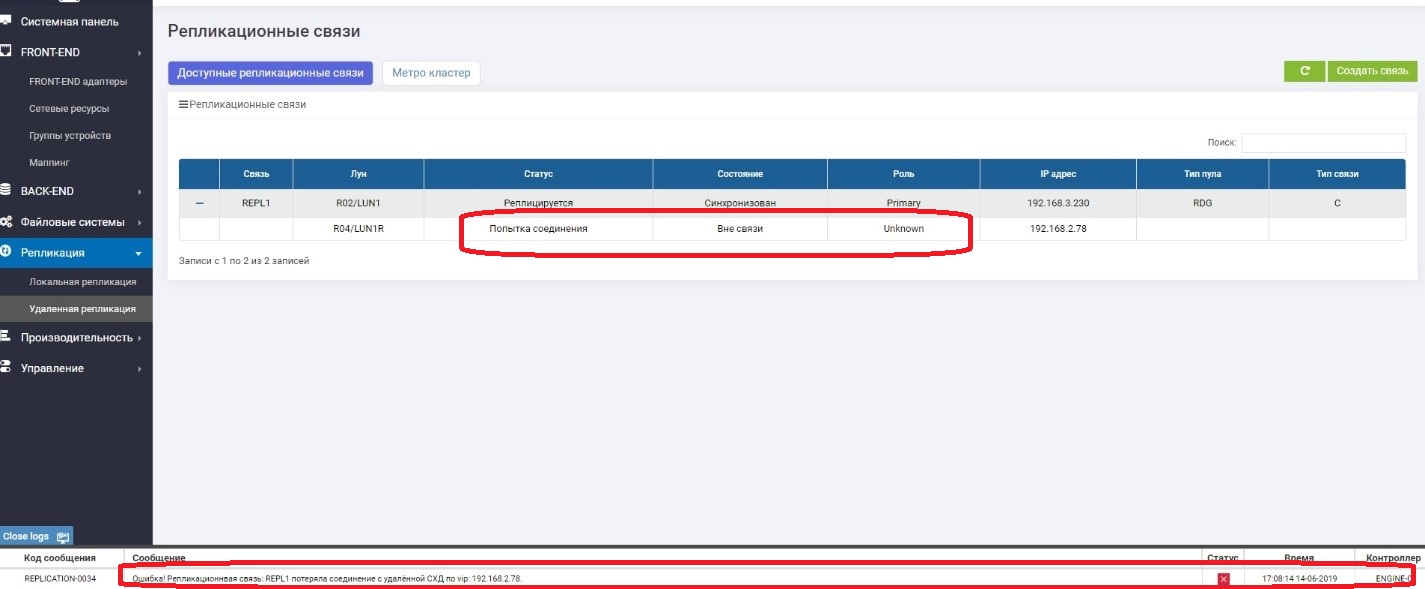
Au secondaire, nous voyons qu'il n'y a aucun lien avec le primaire.
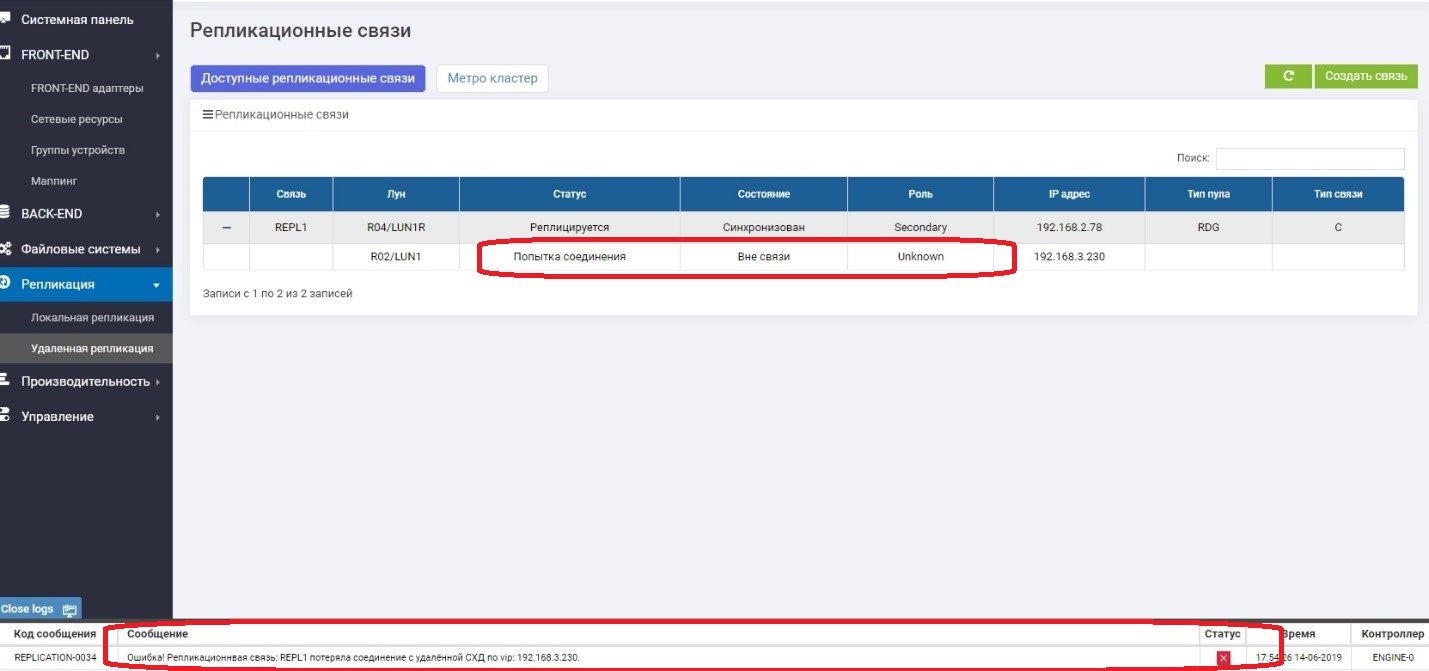
Tout fonctionne bien, et nous continuons d'écrire des données sur le système de stockage principal, c'est-à-dire qu'elles sont déjà garanties de différer du système de sauvegarde, c'est-à-dire qu'elles sont «parties».
Dans quelques minutes, nous réparons le canal de communication. Dès que les systèmes de stockage se sont vus, la synchronisation des données est automatiquement activée. Il n'y a rien requis de l'administrateur.

Après un certain temps, la synchronisation se termine.
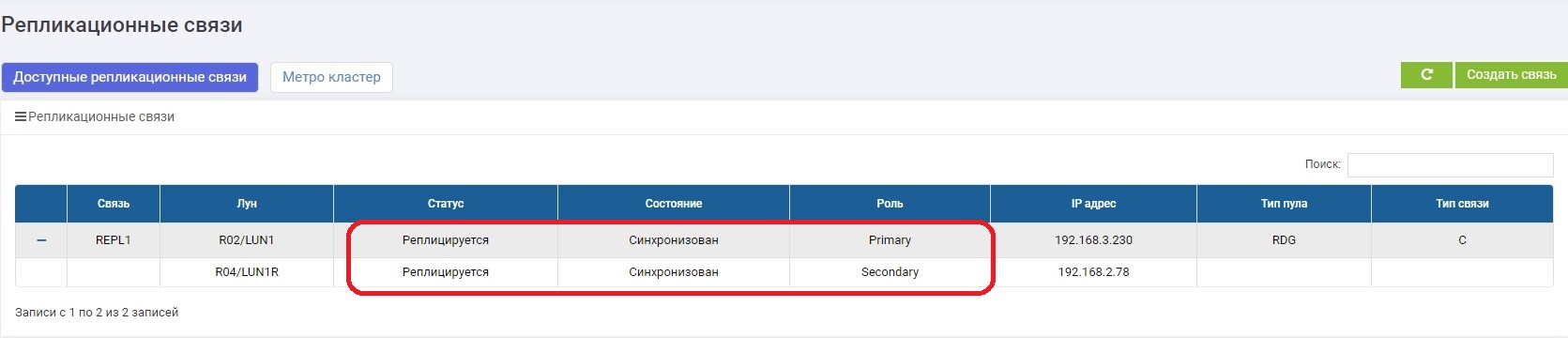
La connexion a été rétablie, la panne des canaux de communication n'a provoqué aucune situation d'urgence et après la mise en marche, la synchronisation a eu lieu automatiquement.
Conclusions
Nous avons analysé la théorie - ce qui est nécessaire et pourquoi, où sont les avantages et les inconvénients. Nous avons ensuite mis en place une réplication synchrone entre les deux systèmes de stockage.
Ensuite, les principaux tests ont été effectués pour la commutation régulière, la défaillance du centre de données et une rupture des canaux de communication. Dans tous les cas, SHD a bien fonctionné. , .
active-active, , .
, .
.