Bonjour, chers Habrausers! Cet article concerne le web 3.0, Internet avec décentralisation. Le Web 3.0 introduit le concept de décentralisation comme base de l'Internet moderne; de nombreux systèmes et réseaux informatiques ont besoin de propriétés de sécurité et de décentralisation pour leurs besoins. La solution de décentralisation est appelée technologie de registre distribué ou blockchain.

Blockchain est un registre distribué. Elle peut être considérée comme une énorme base de données qui dure éternellement et ne change pas dans l'histoire, la blockchain est utilisée comme base pour des applications ou services Web décentralisés.
En substance, la blockchain n'est pas seulement une base de données, c'est une opportunité d'augmenter la confiance entre les participants du réseau avec la possibilité d'exécuter la logique métier sur le réseau.
Le consensus byzantin augmente la fiabilité du réseau résout le problème de cohérence
L'évolutivité apportée par DLT modifie les réseaux d'entreprise existants.
La blockchain offre de nouveaux avantages très importants:
- Prévention des erreurs coûteuses.
- Transactions transparentes.
- Numérisation des biens immobiliers.
- Contrats intelligents.
- Rapidité et sécurité des paiements.
Opporty PoE est un projet dont le but est d'étudier les protocoles cryptographiques et d'améliorer les solutions DLT et blockchain existantes.
La plupart des systèmes de registre distribués publics n'ont pas de propriétés d'évolutivité - leur débit est plutôt faible. Par exemple, l'éthereum ne traite que ~ 20 tx / s.
De nombreuses solutions ont été créées pour augmenter la propriété d'évolutivité et ne pas perdre la décentralisation (comme vous le savez, seules 2 sur 3 sont connues: évolutivité, sécurité, décentralisation).
L'une des plus efficaces est une solution utilisant des sidechains.
Concept de plasma
Le concept est que la chaîne racine traite un petit nombre de validations à partir des chaînes enfants, de sorte que la chaîne racine agit comme la couche la plus sûre et la plus finale pour stocker tous les états intermédiaires. Chaque chaîne enfant fonctionne comme sa propre blockchain avec son propre algorithme de consensus, mais il y a quelques mises en garde importantes.
- Les contrats intelligents sont créés dans la chaîne racine et agissent comme un point de contrôle sur la chaîne enfant dans la chaîne racine.
- Une chaîne enfant est créée qui fonctionne comme sa propre blockchain avec son propre consensus. Tous les États de la chaîne des processus enfants sont protégés par des preuves de fraude, qui garantissent que toutes les transitions entre États sont valides et appliquent un protocole de retrait.
- Les contrats intelligents spécifiques à dapp ou à la chaîne enfant (logique d'application) peuvent ensuite être déployés sur la chaîne enfant.
- Les outils nécessaires peuvent être transférés de la chaîne racine à la chaîne enfant.
Les validateurs ont des incitations économiques à agir honnêtement et à envoyer des commentaires à la chaîne racine - la couche du règlement final de la transaction.
En conséquence, les utilisateurs de dapp travaillant dans la chaîne enfant ne devraient pas du tout interagir avec la chaîne racine. De plus, ils peuvent retirer leur argent à la chaîne racine quand ils le souhaitent, même si la chaîne enfant est piratée. Ces sorties de la chaîne enfant permettent aux utilisateurs de stocker leurs fonds en toute sécurité à l'aide des preuves Merkle, confirmant la propriété d'un certain montant de fonds.
Les principaux avantages du Plasma sont liés à sa capacité à faciliter considérablement les calculs qui surchargent actuellement la chaîne principale. De plus, la blockchain Ethereum peut traiter des ensembles de données plus étendus et plus parallèles. Le temps prélevé sur la chaîne racine est également transféré aux nœuds Ethereum, qui reçoivent des exigences de traitement et de stockage moindres.
Plasma Cash est une conception qui donne aux jetons réseau des numéros de série uniques qui les transforment en jetons uniques. Les avantages de ceci incluent le manque de besoin de confirmations, un support plus simple pour tous les types de jetons (y compris les jetons non fongibles) et l'atténuation contre les sorties massives de la chaîne enfant.
Le problème du plasma est lié au concept de "sorties massives" de la chaîne enfant. Dans ce scénario, une sortie simultanée coordonnée de la chaîne fille pourrait potentiellement conduire à un manque de puissance de calcul pour retirer tous les fonds. En conséquence, les utilisateurs peuvent perdre de l'argent.
Options de mise en œuvre du plasma

Le plasma de base a de nombreuses options de mise en œuvre.
Les principales différences sont:
- stocker des informations sur la méthode de stockage et de présentation de l'état,
- types de jetons (divisible indivisible),
- sécurité des transactions
- type d'algorithme de consensus, etc.
Les principales variations du plasma:
- Basé sur UTXO - chaque transaction se compose d'entrées et de sorties: une transaction peut être effectuée et dépensée, la liste des transactions non dépensées est un état de la chaîne enfant elle-même.
- Compte basé - contient simplement une réflexion de chaque compte-compte et de son solde, ce type est utilisé dans ethereum car chaque compte peut être de deux types - un compte utilisateur et un compte de contrat intelligent. L'avantage de ce type de stockage d'état est sa simplicité, et le moins est que cette option n'est pas évolutive (la propriété spéciale nonce est utilisée pour empêcher la transaction d'être exécutée deux fois).
Le but de cet article est d'expliquer les structures de données utilisées dans la blockchain Plasma Cash.
Afin de comprendre exactement comment fonctionne l'engagement, vous devez clarifier le concept de l'arbre Merkle.
Les arbres Merkle leur utilisation dans le plasma
Les arbres de Merkle sont une structure de données extrêmement importante dans le monde de la blockchain. Essentiellement, les arbres Merkle nous donnent la possibilité de capturer certains ensembles de données d'une manière qui cache les données, mais permet aux utilisateurs de prouver que certaines des informations étaient dans l'ensemble. Par exemple, si j'ai dix nombres, je peux créer une preuve pour ces nombres, puis prouver qu'un nombre particulier se trouvait dans cet ensemble de nombres. Ces épreuves ont une petite taille constante, ce qui les rend bon marché à publier sur Ethereum.
Vous pouvez l'utiliser pour un ensemble de transactions. Vous pouvez également prouver qu'une transaction particulière se trouve dans cet ensemble de transactions. C'est exactement ce que fait l'opérateur. Chaque bloc se compose d'un ensemble de transactions qui se transforment en arbre Merkle. La racine de cet arbre est la preuve, qui est publiée dans Ethereum avec chaque bloc de plasma.
Les utilisateurs devraient pouvoir retirer leurs fonds de la chaîne plasma. Lorsque les utilisateurs souhaitent quitter la chaîne plasma, ils envoient la transaction de «sortie» à Ethereum.
Plasma Cash utilise un Merkle Tree spécial qui permet de ne pas valider le bloc entier mais de ne valider que les branches qui correspondent au token de l'utilisateur.
Autrement dit, pour transférer un jeton, vous devez parcourir l'historique et analyser uniquement les jetons dont un certain utilisateur a besoin.Lors du transfert d'un jeton, l'utilisateur transmet simplement l'historique complet à un autre utilisateur et il peut déjà authentifier toute l'histoire - et surtout, le faire très rapidement.

Structures de données Plasma Cash pour stocker l'état et l'historique
Néanmoins, il est nécessaire de n'utiliser que quelques arbres de Merkle, car il est nécessaire d'obtenir une preuve d'inclusion et également une preuve de non-inclusion de la transaction dans le bloc, par exemple -
- Arbre de merkle clairsemé
- Patricia trie
Opporty a terminé la mise en œuvre de Sparse Merkle Tree et Patricia Trie
Un arbre Merkle clairsemé est similaire à un arbre Merkle standard, sauf que les données qu'il contient sont indexées et chaque point de données est placé sur une feuille qui correspond à l'index de ce point de données
Disons que nous avons un arbre Merkle à quatre feuilles. Nous remplirons cet arbre de quelques lettres (A, D) pour démonstration. La lettre A est la première lettre de l'alphabet, nous devons donc la mettre sur la première feuille. De même, nous pouvons mettre D sur la quatrième feuille.
Que se passe-t-il donc dans les deuxième et troisième feuilles? Nous les laissons simplement vides. Plus précisément, une valeur spéciale (par exemple, zéro) est placée au lieu de placer la lettre.
L'arbre ressemble finalement à ceci:

La preuve d'inclusion fonctionne exactement comme dans un arbre Merkle normal. Que se passe-t-il si nous voulons prouver que C ne fait pas partie de cet arbre Merkle? C'est facile! Nous savons que si C faisait partie d'un arbre, ce serait sur la troisième feuille. Si C ne fait pas partie de l'arbre, alors la troisième feuille doit être nulle.
Tout ce qui est nécessaire est la preuve standard de l'inclusion de Merkle, montrant que la troisième feuille est nulle.
La meilleure partie d'un arbre Merkle clairsemé est qu'ils représentent vraiment des magasins de valeurs-clés à l'intérieur de l'arbre Merkle!
Voici une partie du code du protocole PoE qui implémente la construction Sparse Merkle Tree.
class SparseTree { //... buildTree() { if (Object.keys(this.leaves).length > 0) { this.levels = [] this.levels.unshift(this.leaves) for (let level = 0; level < this.depth; level++) { let currentLevel = this.levels[0] let nextLevel = {} Object.keys(currentLevel).forEach((leafKey) => { let leafHash = currentLevel[leafKey] let isEvenLeaf = this.isEvenLeaf(leafKey) let parentLeafKey = leafKey.slice(0, -1) let neighborLeafKey = parentLeafKey + (isEvenLeaf ? '1' : '0') let neighborLeafHash = currentLevel[neighborLeafKey] if (!neighborLeafHash) { neighborLeafHash = this.defaultHashes[level] } if (!nextLevel[parentLeafKey]) { let parentLeafHash = isEvenLeaf ? ethUtil.sha3(Buffer.concat([leafHash, neighborLeafHash])) : ethUtil.sha3(Buffer.concat([neighborLeafHash, leafHash])) if (level == this.depth - 1) { nextLevel['merkleRoot'] = parentLeafHash } else { nextLevel[parentLeafKey] = parentLeafHash } } }) this.levels.unshift(nextLevel) } } } }
Ce code est assez trivial. Nous avons un magasin de valeurs-clés avec preuve d'inclusion / non-inclusion.
À chaque itération, un niveau spécifique de l'arborescence finale est rempli, en commençant par le dernier. Selon la clé de la feuille courante qui est paire ou impaire, nous prenons deux feuilles adjacentes et considérons le hachage du niveau actuel. Si nous atteignons la fin, nous écrivons un seul merkleRoot - un hachage commun.
Vous devez comprendre que cet arbre est déjà rempli de valeurs initialement vides! Et si nous stockons une énorme quantité de jetons IDS. nous avons une taille d'arbre énorme et cela prend très longtemps à générer!
Il existe de nombreuses solutions à cette non optimisation, mais Opporty a décidé de changer cet arbre en Patricia Trie.
Patricia Trie est un mélange de Radix Trie et Merkle Trie.
La clé de données Radix Trie stockera le chemin de données lui-même! Cela vous permet de créer une structure de données optimisée pour la mémoire!
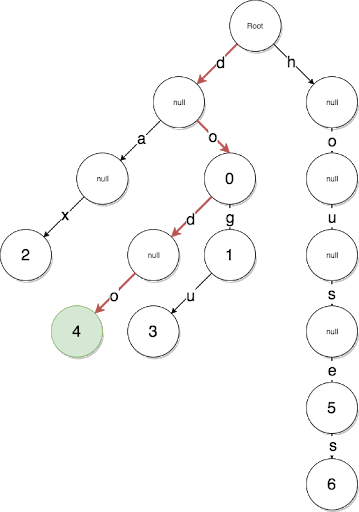
Mise en œuvre de l'opposition
buildNode(childNodes, key = '', level = 0) { let node = {key} this.iterations++ if (childNodes.length == 1) { let nodeKey = level == 0 ? childNodes[0].key : childNodes[0].key.slice(level - 1) node.key = nodeKey let nodeHashes = Buffer.concat([Buffer.from(ethUtil.sha3(nodeKey)), childNodes[0].hash]) node.hash = ethUtil.sha3(nodeHashes) return node } let leftChilds = [] let rightChilds = [] childNodes.forEach((node) => { if (node.key[level] == '1') { rightChilds.push(node) } else { leftChilds.push(node) } }) if (leftChilds.length && rightChilds.length) { node.leftChild = this.buildNode(leftChilds, '0', level + 1) node.rightChild = this.buildNode(rightChilds, '1', level + 1) let nodeHashes = Buffer.concat([Buffer.from(ethUtil.sha3(node.key)), node.leftChild.hash, node.rightChild.hash]) node.hash = ethUtil.sha3(nodeHashes) } else if (leftChilds.length && !rightChilds.length) { node = this.buildNode(leftChilds, key + '0', level + 1) } else if (!leftChilds.length && rightChilds.length) { node = this.buildNode(rightChilds, key + '1', level + 1) } else if (!leftChilds.length && !rightChilds.length) { throw new Error('invalid tree') } return node }
Autrement dit, nous parcourons récursivement et construisons séparément les sous-arbres enfants gauche et droit. En même temps, construire la clé comme chemin dans cet arbre!
Cette solution est encore plus banale et fonctionne plus rapidement tout en étant assez optimisée! En fait, l'arbre Patricia peut être encore optimisé en introduisant de nouveaux types de nœuds - nœud d'extension, nœud de branche, etc., comme cela est fait dans le protocole ethereum, mais cette implémentation satisfait toutes nos conditions - nous avons obtenu une structure de données rapide et optimisée en mémoire.
En mettant en œuvre ces structures de données, Opporty a permis de dimensionner Plasma Cash car il permet de vérifier l'historique du token et l'inclusion de ne pas inclure le token dans l'arbre! Cela vous permet d'accélérer considérablement la validation des blocs et de la chaîne enfant plasma elle-même.
Liens utiles:
- Plasma papier blanc
- Git hub
- Cas d'utilisation et description de l'architecture
- Papier réseau Lightning