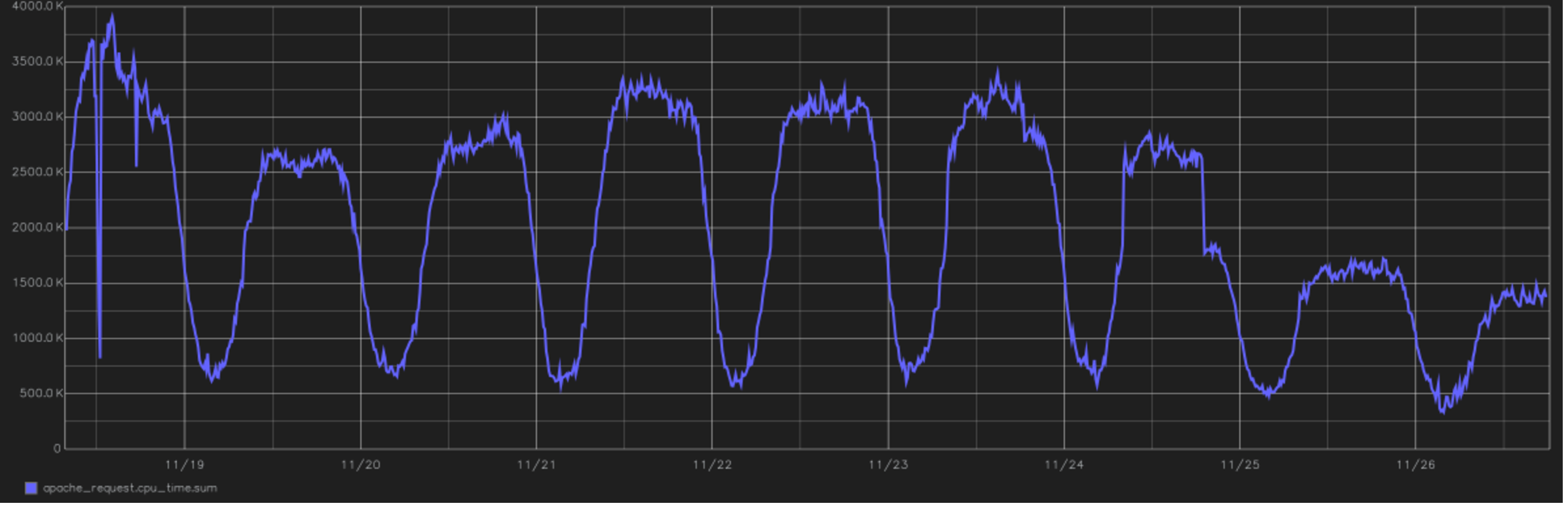
 C'est l'un des reliefs les plus cool du projet. Dans l'image - un graphique du temps total passé par le processeur pour traiter toutes les demandes des utilisateurs. À la fin, vous pouvez voir la transition vers PHP 7.0. depuis la version 5.6. Nous sommes en 2016, en changeant l'après-midi du 24 novembre.
C'est l'un des reliefs les plus cool du projet. Dans l'image - un graphique du temps total passé par le processeur pour traiter toutes les demandes des utilisateurs. À la fin, vous pouvez voir la transition vers PHP 7.0. depuis la version 5.6. Nous sommes en 2016, en changeant l'après-midi du 24 novembre.Du point de vue des calculs, Tutu.ru est principalement une occasion d'acheter un billet du point A au point B.Pour ce faire, nous réduisons un grand nombre d'horaires, mettons en cache les réponses de nombreux systèmes de compagnies aériennes et effectuons périodiquement des requêtes de jointure incroyablement longues dans la base de données. En général, nous sommes écrits en PHP et jusqu'à récemment, nous y étions complètement (si le langage est préparé correctement, vous pouvez même y construire des systèmes en temps réel). Récemment, les domaines critiques pour les performances ont été refondus sur Go.
Nous avons constamment une dette technique . Et cela se produit plus rapidement que nous le souhaiterions. La bonne nouvelle: vous n'avez pas à tout couvrir. Mauvais: à mesure que la fonctionnalité prise en charge augmente, la dette technique augmente également proportionnellement.
En général, la dette technique est le coût d'une erreur de décision. Vous n'avez pas prédit quelque chose comme l'architecte, c'est-à-dire que vous avez fait une erreur de prévision ou pris une décision dans des conditions d'informations insuffisantes. À un moment donné, vous comprenez que vous devez changer quelque chose dans le code (souvent au niveau de l'architecture). Ensuite, vous pouvez changer immédiatement, mais vous pouvez attendre. Si vous attendez - les intérêts se sont précipités sur la dette technologique. Par conséquent, il est recommandé de le restructurer de temps à autre. Eh bien, ou déclarez-vous en faillite et réécrivez tout le bloc.
Comment tout a commencé: monolithe et fonctions générales
Le projet Tutu.ru a commencé en 2003 en tant que site Web Runet régulier de cette époque. Autrement dit, c'était un tas de fichiers au lieu d'une base de données, une page PHP sur le devant de HTML + JS. Il y a eu quelques excellents hacks de mon collègue Yuri, mais il vaut mieux lui dire un jour. J'ai rejoint le projet en 2006, d'abord en tant que consultant externe pouvant apporter à la fois des conseils et un code, puis, en 2009, j'ai été transféré à l'État en tant que directeur technique. Tout d'abord, il fallait mettre les choses en ordre dans le sens des billets d'avion: c'était la partie la plus chargée et la plus complexe de l'architecture.
En 2006, je vous rappelle, il y avait un horaire de train et il y avait une possibilité d'acheter un billet de train. Nous avons décidé de faire de la section des billets d'avion un projet distinct, c'est-à-dire que tout cela n'était uni qu'à l'avant. Les trois projets (horaires des trains, chemin de fer et avion) ont finalement été rédigés à leur manière. A cette époque, le code nous semblait normal, mais quelque peu inachevé. Non perfectionniste. Puis il a vieilli, s'est couvert de béquilles et, dans le sens du chemin de fer, s'est transformé en citrouille en 2010.
Dans le ferroviaire, nous n'avons pas eu le temps de donner de la dette technique. Le refactoring était irréaliste: les problèmes étaient en architecture. Nous avons décidé de tout démolir et de tout refaire, mais c'était aussi difficile sur un projet live. En conséquence, seules les anciennes URL ont été laissées à l'avant, puis bloc par bloc a été réécrit. Comme base, nous avons retenu les approches utilisées un an auparavant dans le développement du secteur de l'aviation.
Réécrit en PHP. Ensuite, il était clair que ce n'était pas le seul moyen, mais il n'y avait pas d'alternative raisonnable pour nous. Ils l'ont choisi parce qu'ils avaient déjà de l'expérience et des réalisations, il était clair que c'est un bon langage entre les mains des développeurs seniors. Parmi les alternatives, C et C ++ étaient incroyablement productifs, mais toute reconstruction ou introduction de modifications y ressemblait alors à un cauchemar. D'accord, pas de rappel. Étaient un cauchemar.
MS et tous les .NET du point de vue d'un projet à forte charge n'ont même pas été pris en compte. Ensuite, il n'y avait aucune option autre que Linux. Java est une bonne option, mais il exige des ressources de la mémoire, il ne pardonne jamais les erreurs juniors et ensuite il n'a pas permis de publier des versions rapidement - enfin, ou nous ne le savions pas. Même maintenant, nous ne considérons pas Python comme un backend, uniquement pour les tâches de manipulation de données. JS - purement sous le devant. Il n'y avait pas de développeurs Ruby on Rails à l'époque (et maintenant). Go était parti. Il y avait encore Perl, mais les experts l'ont jugé peu prometteur pour le développement Web, ils l'ont donc également abandonné. PHP est laissé.
L'histoire holiv suivante est PostgreSQL vs MySQL. Quelque part mieux, ailleurs. En général, alors c'était une bonne pratique de choisir ce qui s'est avéré le mieux, nous avons donc choisi MySQL et ses fourches.
L'approche de développement était monolithique, alors il n'y avait tout simplement pas d'autres approches, mais avec la structure orthogonale des bibliothèques. Ce sont les débuts de l'approche moderne centrée sur l'API, lorsque chaque bibliothèque a une façade à l'extérieur, pour laquelle vous pouvez extraire directement le code d'autres parties du projet. Les bibliothèques ont été écrites en «couches» lorsque chaque niveau a un format spécifique à l'entrée et transmet un certain format plus loin au code, et des tests unitaires tournent entre eux. Autrement dit, quelque chose comme le développement piloté par les tests, mais pixelisé et effrayant.
Tout cela a été hébergé sur plusieurs serveurs, ce qui a permis d'évoluer sous charge. Mais en même temps, la base de code de différents projets s'est fortement recoupée au niveau du système. Cela signifiait en fait que des changements dans le projet ferroviaire pourraient affecter nos propres avions. Et touché souvent. Par exemple, dans les chemins de fer, il était nécessaire d'étendre le travail avec les paiements - il s'agit d'une révision de la bibliothèque partagée. Et l'avion fonctionne avec lui, par conséquent, des tests communs sont nécessaires. Nous avons filtré les dépendances avec des tests, et c'était plus ou moins normal. Même en 2009, la méthode était assez avancée. Mais encore, la charge pourrait en ajouter une autre à partir d'une ressource. Il y avait une intersection dans les bases de données, ce qui a entraîné des effets désagréables sous forme de freins sur tout le site avec des problèmes locaux dans un produit. Le chemin de fer a tué l'avion à plusieurs reprises sur le disque en raison de fortes interrogations dans la base de données.
Nous avons évolué en ajoutant des instances et en les équilibrant. Monolith tel quel.
Âge des pneus
Nous avons ensuite emprunté une voie plutôt marginale. D'une part, nous avons commencé à isoler les services (aujourd'hui, cette approche est appelée microservice, mais nous ne connaissions pas le mot «micro»), mais pour l'interaction, nous avons commencé à utiliser le bus pour le transfert de données, plutôt que REST ou gRPC, comme ils le font maintenant. Nous avons choisi AMQP comme protocole et RabbitMQ comme courtier de messages. À cette époque, nous avions maîtrisé le lancement de démons pour PHP (oui, il y a une implémentation fonctionnelle de fork () et tout le reste pour travailler avec des processus), car pendant longtemps dans le monolithe, nous avons utilisé une chose telle que Gearman pour paralléliser les demandes aux systèmes de réservation .
Ils ont fait un courtier sur le lapin, et il s'est avéré que tout cela ne vivait pas vraiment sous charge. Une sorte de pertes de réseau, de retransmissions, de retards. Par exemple, un cluster de plusieurs courtiers «prêt à l'emploi» se comporte quelque peu différemment de ce qu'indique le développeur (cela ne s'est jamais produit auparavant, et encore). En général, ils ont beaucoup appris. Mais à la fin, nous avons obtenu les SLA requis pour les services. Par exemple, le service RPS le plus chargé a à 400 rps, le 99th percentile aller-retour de client à client, y compris le bus et le traitement de service de l'ordre de 35 ms. Maintenant, au total, dans le bus, nous observons environ 18 krps.
Puis vint la direction des bus. Nous l'avons immédiatement écrit sans monolith sur l'architecture de service. Comme tout a été écrit à partir de zéro, cela s'est avéré très bien, rapidement et commodément, bien qu'il fût nécessaire d'affiner constamment les outils pour une nouvelle approche. Oui, tout cela tournait sur des machines virtuelles, à l'intérieur desquelles les démons PHP communiquent via le bus. Les démons ont commencé à l'intérieur des conteneurs Docker, mais il n'y avait pas de solutions d'orchestration comme Openshift ou Kubernetes. En 2014, nous commençions tout juste à en parler, mais nous n'avons pas envisagé une telle approche des ventes.
Si vous comparez le nombre de billets d'autobus vendus par rapport aux billets d'avion ou de train, vous obtenez une goutte dans le seau. Et dans les trains et les avions, passer à une nouvelle architecture était difficile, car il y avait des fonctionnalités de travail, une charge réelle, et il y avait toujours le choix entre faire quelque chose de nouveau ou dépenser de l'argent pour rembourser une dette technique.
Passer aux services est une bonne chose, mais longue, mais vous devez maintenant gérer la charge et la fiabilité. Par conséquent, en parallèle, ils ont commencé à prendre des mesures ciblées pour améliorer la vie du monolithe. Les backends ont été divisés en types de produits, c'est-à-dire qu'ils ont commencé à contrôler de manière plus flexible l'acheminement des demandes en fonction de leur type: air séparément du chemin de fer, etc. Il était possible de prédire la charge, de l'échelle indépendamment. Lorsqu'ils ont su que dans les chemins de fer, par exemple, le pic des ventes du Nouvel An, plusieurs instances de machines virtuelles ont été ajoutées. Elle a alors commencé exactement 45 jours avant le dernier jour ouvrable de l'année, et les 14 et 15 novembre, nous avons eu une double charge. Maintenant, FPK et d'autres transporteurs ont fabriqué de nombreux billets avec le début des ventes pour 60, 90 et même 120 jours, et ce pic s'est propagé. Mais le dernier jour ouvrable d'avril, il y aura toujours une charge sur les trains électriques avant mai, et il y a toujours des pics. Mais à propos de la saisonnalité des billets et des modes de migration de démobilisation, mes collègues du chemin de fer en parleront mieux, et je continuerai sur l'architecture.
Quelque part en 2014, ils ont commencé à déraner une grande base de données de nombreuses petites. C'était important parce qu'il se développait dangereusement, et la chute était critique. Nous avons commencé à sélectionner des petites bases de données distinctes (pour 5 à 10 tables) pour une fonctionnalité spécifique, afin que d'autres services affectent moins de perturbations, et que tout cela puisse être mis à l'échelle plus facilement. Il convient de noter que pour l'équilibrage de charge et la mise à l'échelle, nous avons utilisé des répliques pour la lecture. Récupérer des répliques pour une grande base après un échec de réplication pourrait prendre des heures, et pendant tout ce temps, j'ai dû "voler en liberté conditionnelle et sur une seule aile". Les souvenirs de ces périodes provoquent toujours un frisson désagréable quelque part entre les oreilles. Nous avons maintenant environ 200 instances de bases différentes, et administrer autant d'installations avec nos mains est une entreprise laborieuse et peu fiable. Par conséquent, nous utilisons Github Orchestrator, qui automatise le travail avec les répliques et proxySql pour répartir la charge et se protéger contre la défaillance d'une base de données particulière.
Comme maintenant
En général, nous avons progressivement commencé à allouer des tâches asynchrones et à séparer leurs lancements dans le gestionnaire d'événements afin que l'un n'interfère pas avec l'autre.
Lorsque PHP 7 est sorti, nous avons vu dans les tests une très grande progression des performances et une réduction de la consommation des ressources. Le passage a eu lieu avec un peu d'hémorroïdes, tout le projet depuis le début des tests jusqu'à la traduction complète de toute la production a pris un peu plus de six mois, mais après cela, la consommation de ressources a diminué de près de moitié. Chronologie de la charge du processeur - en haut de l'article.
Le monolithe a survécu à ce jour et, à mon avis, représente environ 40% de la base de code. Il vaut la peine de dire que la tâche de remplacer l'ensemble du monolithe par des services n'est pas explicitement définie. Nous évoluons de manière pragmatique: tout ce qui est nouveau est fait sur des microservices, mais si vous avez besoin d'affiner l'ancienne fonctionnalité dans un monolithe, alors nous essayons de la transférer vers l'architecture de service, si seulement le raffinement n'est pas vraiment très petit. Dans le même temps, le monolithe est couvert de tests afin que nous puissions le déployer deux fois par semaine avec un niveau de qualité suffisant. Les fonctionnalités sont couvertes de différentes manières, les tests unitaires sont assez complets, les tests d'interface utilisateur et les tests d'acceptation couvrent presque toutes les fonctionnalités du portail (nous avons environ 15000 cas de test), les tests API sont plus ou moins complets. Nous ne faisons presque pas de tests de charge. Plus précisément, notre mise en scène est similaire à la prod en structure, mais pas en puissance, et est bordée du même monitoring. Nous générons une charge, si nous voyons que l'exécution précédente sur l'ancienne version diffère dans les délais, nous regardons à quel point elle est critique. Si la nouvelle version et l'ancienne sont approximativement les mêmes, nous les publions dans la prod. Dans tous les cas, toutes les fonctionnalités sortent sous le commutateur afin que vous puissiez le désactiver à tout moment en cas de problème.
Les fonctionnalités lourdes sont toujours testées pour 1% des utilisateurs. Ensuite, nous passons à 2%, 5%, 10% et nous atteignons donc tous les utilisateurs. Autrement dit, nous pouvons toujours voir la charge atypique avant la montée subite de tuer les serveurs et se déconnecter à l'avance.
Si nécessaire, nous avons pris (et prendrons) 4-5 mois pour un projet de réingénierie, lorsque l'équipe se concentre sur une tâche spécifique. C'est un bon moyen de couper le nœud gordien lorsque le refactoring local n'aide plus. Nous avons donc fait il y a quelques années avec l'air: nous avons refait l'architecture, l'avons fait - nous avons immédiatement obtenu une accélération instantanée du développement, avons pu lancer de nombreuses nouvelles fonctionnalités. Deux mois après la réingénierie, ils ont augmenté d'un ordre de grandeur pour les clients en raison des fonctionnalités. Ils ont commencé à gérer plus précisément les prix, à connecter les partenaires, tout est devenu plus rapide. Joie. Je dois dire que maintenant il est temps de refaire la même chose, mais c'est le destin: les façons de créer des applications changent, de nouvelles solutions, approches, outils apparaissent. Pour rester en affaires, vous devez vous développer.
La principale tâche de la réingénierie pour nous est d'accélérer davantage le développement. Si rien de nouveau n'est nécessaire, la réingénierie n'est pas nécessaire. Inutile d'en inventer un nouveau: cela n'a aucun sens d'investir dans la modernisation. Ainsi, tout en maintenant une pile et une architecture modernes, les gens se mettent au travail plus rapidement, une nouvelle se connecte plus rapidement, le système se comporte de manière plus prévisible, les développeurs sont plus intéressés à travailler sur un projet. Il est maintenant nécessaire de terminer le monolithe sans le jeter complètement, de sorte que chaque produit puisse télécharger des mises à jour, sans dépendre des autres. Autrement dit, obtenez un CI / CD spécifique dans un monolithe.
Aujourd'hui, nous utilisons non seulement le lapin, mais aussi REST et gRPC pour échanger des informations entre les services. Certains microservices sont écrits en Golang: la vitesse de calcul et la gestion de la mémoire y sont excellentes. Il y a eu un appel pour implémenter la prise en charge de nodeJS, mais à la fin, nous avons laissé le nœud uniquement pour le rendu du serveur, et la logique métier a été laissée en PHP et Go. En principe, l'approche choisie nous permet de développer des services dans presque toutes les langues, mais nous avons décidé de limiter le zoo afin de ne pas augmenter la complexité du système.
Nous passons maintenant aux microservices qui fonctionneront dans les conteneurs Docker sous l'orchestration OpenShift. La tâche dans un an et demi - 90% de tous les torsions à l'intérieur de la plate-forme. Pourquoi? Il est donc plus rapide à déployer, plus rapide à vérifier les versions, il y a moins de différence dans la vente à partir de l'environnement de développement. Le développeur peut penser davantage à la fonctionnalité qu'il implémente, et non à la façon de déployer l'environnement, de le configurer, où le démarrer, c'est-à-dire plus d'avantages. Encore une fois - problèmes opérationnels: il existe de nombreux microservices, ils doivent être automatisés par la direction. Manuellement - coûts très élevés, risques d'erreurs avec un contrôle manuel et la plate-forme donne une mise à l'échelle normale.
Chaque année, la charge de travail augmente - de 30 à 40%: de plus en plus de personnes apprennent les trucs avec Internet, cessent d'aller aux caisses physiques, nous ajoutons de nouveaux produits et fonctionnalités aux produits existants. Aujourd'hui, environ 1 million d'utilisateurs par jour accèdent au portail. Bien sûr, tous les utilisateurs ne génèrent pas la même charge. Quelque chose ne nécessite pas du tout de ressources de calcul et, par exemple, les recherches sont un composant plutôt gourmand en ressources. Là, une seule coche «plus ou moins trois jours» dans l'aviation augmente la charge de 49 fois (en regardant en arrière, la matrice est de 7 par 7). Tout le reste par rapport à la recherche d'un billet à l'intérieur des systèmes ferroviaires et aériens est assez simple. La chose la plus simple dans les ressources est l'
aventure et la
recherche de circuits (il n'y a pas le cache le plus simple en termes d'architecture, mais il y a encore beaucoup moins de circuits que de combinaisons de billets), puis
l'horaire des trains (il est facilement mis en cache par des moyens standard), et seulement ensuite tout le reste .
Bien sûr, la dette technique s'accumule encore. De tous côtés. L'essentiel est de comprendre dans le temps où vous pouvez réussir à refactoriser, et tout ira bien, où vous n'aurez rien à toucher (cela arrive aussi: nous vivons avec Legacy, si aucun changement n'est prévu), mais quelque part, nous devons nous précipiter et repenser nous-mêmes, car sans cet avenir ne le sera pas. Bien sûr, nous faisons des erreurs, mais en général, Tutu.ru existe depuis 16 ans et j'aime la dynamique du projet.