Selon vous, qui pourrait mieux configurer l'algorithme PostgreSQL - DBA ou ML? Et si c'est le deuxième, alors il est temps pour nous de réfléchir à ce qu'il faut faire lorsque les voitures nous remplacent. Ou cela n’arrivera pas à cela, et les décisions importantes devraient toujours être prises par les gens. Probablement, le niveau d'isolement et les exigences de stabilité des transactions devraient rester avec l'administrateur. Mais les index peuvent bientôt être fiables pour déterminer la machine vous-même.

Andy Pavlo sur
HighLoad ++ a parlé du SGBD du futur, que vous pouvez "toucher" dès maintenant. Si vous avez manqué ce discours ou si vous préférez recevoir des informations en russe - sous la coupe se trouve la traduction du discours.
Il s'agira du projet de l'Université Carnegie Mellon sur la création de SGBD autonomes. Le terme «autonome» désigne un système qui peut automatiquement se déployer, se configurer, se configurer sans aucune intervention humaine. Cela peut prendre environ dix ans pour développer quelque chose comme ça, mais c'est ce que font Andy et ses élèves. Bien sûr, des algorithmes d'apprentissage automatique sont nécessaires pour créer un SGBD autonome, cependant, dans cet article, nous nous concentrerons uniquement sur le côté ingénierie du sujet. Considérez comment concevoir un logiciel pour le rendre autonome.
À propos du conférencier: Andy Pavlo est professeur agrégé à l'Université Carnegie Mellon, sous sa direction, crée un
SGBD PelotonDB «autogéré» , ainsi que
ottertune , qui aide à régler les
configurations PostgreSQL et MySQL à l'aide de l'apprentissage automatique. Andy et son équipe sont désormais de véritables leaders dans les bases de données autogérées.
La raison pour laquelle nous voulons créer un SGBD autonome est évidente. La gestion de ces outils SGBD est un processus très coûteux et long. Le salaire moyen DBA aux États-Unis est d'environ 89 000 dollars par an. Traduit en roubles, 5,9 millions de roubles sont obtenus chaque année. Ce montant vraiment élevé que vous payez aux gens pour garder un œil sur votre logiciel. Environ 50% du coût total d'utilisation de la base de données est payé par le travail de ces administrateurs et du personnel associé.
Lorsqu'il s'agit de très gros projets, comme nous en discutons sur HighLoad ++ et qui utilisent des dizaines de milliers de bases de données, la complexité de leur structure dépasse la perception humaine. Tout le monde aborde ce problème de manière superficielle et essaie d'atteindre des performances maximales en investissant un minimum d'efforts dans le réglage du système.
Vous pouvez enregistrer une somme ronde si vous configurez le SGBD au niveau de l'application et de l'environnement pour garantir des performances maximales.
Bases de données auto-adaptatives, 1970–1990
L'idée des SGBD autonomes n'est pas nouvelle; leur histoire remonte aux années 1970, lorsque les bases de données relationnelles ont commencé à être créées. Ensuite, ils ont été appelés bases de données auto-adaptatives (bases de données auto-adaptatives), et avec leur aide, ils ont essayé de résoudre les problèmes classiques de conception de bases de données, sur lesquels les gens ont encore du mal à ce jour. Il s'agit du choix des index, de la partition et de la construction du schéma de base de données, ainsi que du placement des données. À cette époque, des outils ont été développés pour aider les administrateurs de bases de données à déployer le SGBD. En fait, ces outils fonctionnaient exactement comme leurs homologues modernes.
Les administrateurs suivent les demandes exécutées par l'application. Ils transmettent ensuite cette pile de requêtes à l'algorithme de réglage, qui construit un modèle interne de la manière dont l'application doit utiliser la base de données.
Si vous créez un outil qui vous aide à sélectionner automatiquement les index, puis créez des graphiques à partir desquels vous pouvez voir la fréquence d'accès à chaque colonne. Ensuite, transmettez ces informations à l'algorithme de recherche, qui examinera de nombreux emplacements différents - tentera de déterminer laquelle des colonnes peut être indexée dans la base de données. L'algorithme utilisera le modèle de coût interne pour montrer que celui-ci donnera de meilleures performances par rapport aux autres indices. Ensuite, l'algorithme donnera une suggestion sur les changements à apporter aux indices. En ce moment, il est temps de participer à la personne, d'examiner cette proposition et non seulement de décider si elle est juste, mais aussi de choisir le bon moment pour sa mise en œuvre.

Les administrateurs de base de données doivent savoir comment l'application est utilisée en cas de baisse de l'activité des utilisateurs. Par exemple, le dimanche à 3 h 00, le niveau le plus bas de requêtes de base de données, vous pouvez donc recharger les index à ce stade.
Comme je l'ai dit, tous les outils de conception de l'époque fonctionnaient de la même manière - c'est
un problème très ancien . Le superviseur scientifique de mon superviseur scientifique a écrit un article sur la sélection automatique des index en 1976.
Bases de données à réglage automatique, 1990-2000
Dans les années 1990, les gens ont en fait travaillé sur le même problème, seul le nom est passé de bases de données adaptatives à autoréglables.
Les algorithmes se sont un peu améliorés, les outils se sont un peu améliorés, mais à un niveau élevé, ils ont fonctionné de la même manière qu'auparavant. La seule entreprise à l'avant-garde du mouvement des systèmes à réglage automatique était Microsoft Research avec son projet d'administration automatique. Ils ont développé des solutions vraiment merveilleuses, et à la fin des années 90 et au début des années 00, ils ont à nouveau présenté un ensemble de recommandations pour la création de leur base de données.
L'idée clé que Microsoft a avancée était différente de ce qu'elle était dans le passé - au lieu d'avoir les outils de personnalisation prenant en charge leurs propres modèles, ils ont simplement réutilisé le modèle de coût de l'optimiseur de requêtes pour aider à déterminer les avantages d'un index par rapport à un autre. Si vous y réfléchissez, cela a du sens. Lorsque vous avez besoin de savoir si un seul index peut vraiment accélérer les requêtes, sa taille n'a pas d'importance si l'optimiseur ne le sélectionne pas. Par conséquent, l'optimiseur est utilisé pour savoir s'il choisira réellement quelque chose.

En 2007, Microsoft Research a publié
un article présentant une rétrospective de la recherche sur dix ans. Et il couvre bien toutes les tâches complexes qui ont surgi sur chaque segment du chemin.
Une autre tâche qui a été mise en évidence à l'ère des bases de données
à réglage automatique est de
savoir comment effectuer des ajustements automatiques des régulateurs. Un contrôleur de base de données est une sorte de paramètre de configuration qui modifie le comportement du système de base de données lors de l'exécution. Par exemple, un paramètre qui est présent dans presque toutes les bases de données est la taille du tampon. Ou, par exemple, vous pouvez gérer des paramètres tels que les stratégies de blocage, la fréquence de nettoyage du disque, etc. En raison de l'augmentation considérable de la complexité des régulateurs de SGBD ces dernières années, ce sujet est devenu pertinent.
Pour montrer à quel point les choses sont mauvaises, je vais donner un examen que mon élève a fait après avoir étudié de nombreuses versions de PostgreSQL et MySQL.
Au cours des 15 dernières années, le nombre de régulateurs dans PostgreSQL a augmenté 5 fois, et pour MySQL - 7 fois.
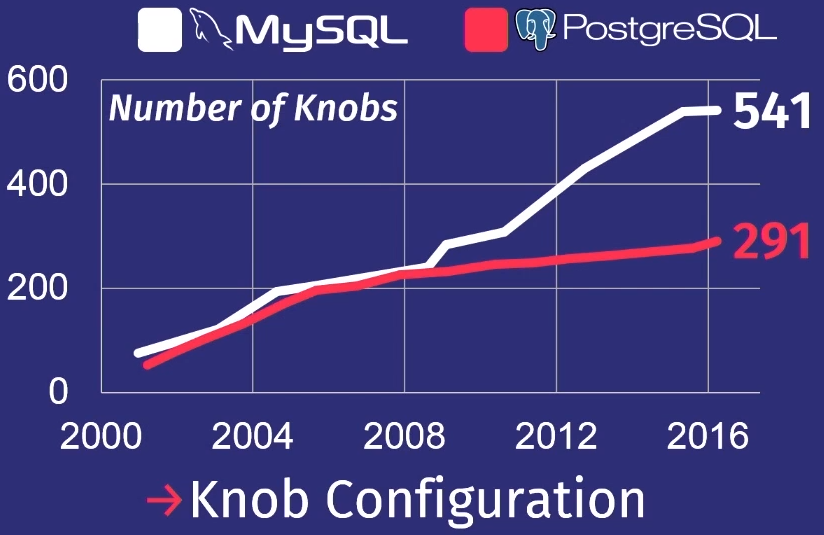
Bien sûr, tous les régulateurs ne contrôlent pas réellement le processus d'exécution des tâches. Certains, par exemple, contiennent des chemins de fichiers ou des adresses réseau, donc seule une personne peut les configurer. Mais quelques dizaines d'entre eux peuvent vraiment affecter les performances. Aucun homme ne peut tenir autant dans sa tête.
Cloud DB, 2010–…
Plus loin, nous nous trouvons à l'ère des années 2010, dans laquelle nous sommes à ce jour. Je l'appelle l'ère des bases de données cloud. Pendant ce temps, beaucoup de travail a été fait pour automatiser le déploiement d'un grand nombre de bases de données dans le cloud.
La principale chose qui inquiète les principaux fournisseurs de cloud est de savoir comment héberger un locataire ou migrer de l'un à l'autre. Comment déterminer la quantité de ressources dont chaque locataire aura besoin, puis essayer de les répartir entre les machines afin de maximiser la productivité ou de respecter le SLA à un coût minimal.
Amazon, Microsoft et Google résolvent ce problème, mais principalement au niveau opérationnel. Ce n'est que récemment que les fournisseurs de services cloud ont commencé à réfléchir à la nécessité de configurer des systèmes de base de données individuels. Ce travail n'est pas visible pour les utilisateurs ordinaires, mais il détermine le haut niveau de l'entreprise.
Résumant les 40 années de recherche sur les bases de données avec des systèmes autonomes et non autonomes, nous pouvons conclure que ce travail n'est pas encore suffisant.
Pourquoi aujourd'hui nous ne pouvons pas avoir un système d'autonomie vraiment autonome? Il y a trois raisons à cela.

Premièrement, tous ces outils, à l'exception de la distribution des charges de travail des fournisseurs de services cloud, ne sont que
de nature consultative . Autrement dit, sur la base de l'option calculée, une personne doit prendre une décision finale et subjective quant à la validité d'une telle proposition. De plus, il est nécessaire d'observer le fonctionnement du système pendant un certain temps pour décider si la décision prise reste correcte au fur et à mesure du développement du service. Et ensuite, appliquez les connaissances à votre propre modèle de prise de décision interne à l'avenir. Cela peut être fait pour une base de données, mais pas pour des dizaines de milliers.
Le problème suivant est que
toute mesure n'est qu'une réaction à quelque chose . Dans tous les exemples que nous avons examinés, le travail s'accompagne de données sur la charge de travail passée. Il y a un problème, les enregistrements à ce sujet sont transférés à l'instrument, et il dit: "Oui, je sais comment résoudre ce problème." Mais la solution ne concerne qu'un problème qui s'est déjà produit. L'outil ne prévoit pas les événements futurs et ne propose donc pas d'actions préparatoires. Une personne peut le faire et le fait manuellement, mais pas les outils.
La dernière raison est que dans aucune des solutions
il n'y a de transfert de connaissances . Voici ce que je veux dire: par exemple, prenons un outil qui a fonctionné dans une application sur la première instance de base de données, si vous le placez dans une autre même application sur une autre instance de base de données, il pourrait, en fonction des connaissances acquises en travaillant avec la première base de données les données aident à créer une deuxième base de données. En fait, tous les outils commencent à fonctionner à partir de zéro, ils ont besoin de récupérer toutes les données sur ce qui se passe. L'homme travaille d'une manière complètement différente. Si je sais comment configurer une application d'une certaine manière, je peux voir les mêmes modèles dans une autre application et, éventuellement, la configurer beaucoup plus rapidement. Mais aucun de ces algorithmes, aucun de ces outils ne fonctionne toujours de cette façon.
Pourquoi suis-je sûr qu'il est temps de changer? La réponse à cette question est à peu près la même que celle de savoir pourquoi les super-tableaux de données ou l'apprentissage automatique sont devenus populaires.
Les équipements deviennent de meilleure qualité : les ressources de production augmentent, la capacité de stockage augmente, la capacité matérielle augmente, ce qui accélère les calculs pour l'apprentissage des modèles d'apprentissage automatique.
Des outils logiciels avancés sont devenus disponibles pour nous. Auparavant, vous deviez être un expert en MATLAB ou en algèbre linéaire de bas niveau pour écrire des algorithmes d'apprentissage automatique. Nous avons maintenant Torch et Tenso Flow, qui rendent ML disponible, et, bien sûr, nous avons appris à mieux comprendre les données. Les gens savent quel type de données peut être nécessaire pour la prise de décision à l'avenir, ils ne rejettent donc pas autant de données qu'auparavant.
L'objectif de nos recherches est de boucler ce cercle dans les SGBD autonomes. Nous pouvons, comme les outils précédents, proposer des solutions, mais au lieu de compter sur la personne - si la décision est juste quand vous devez la déployer exactement - l'algorithme le fera automatiquement. Et puis, à l'aide des commentaires, il étudiera et s'améliorera avec le temps.
Je veux parler des projets sur lesquels nous travaillons actuellement à l'Université Carnegie Mellon. En eux, nous abordons le problème de deux manières différentes.
Dans le premier, OtterTune, nous recherchons des moyens de régler la base de données en les traitant comme des boîtes noires. Autrement dit, des moyens de
régler les SGBD existants sans contrôler la partie interne du système et en observant uniquement la réponse.
Le projet Peloton vise à
créer de nouvelles bases de données à partir de zéro, étant donné que le système devrait fonctionner de manière autonome. Quels ajustements et algorithmes d'optimisation doivent être définis - qui ne peuvent pas être appliqués aux systèmes existants.
Examinons les deux projets dans l'ordre.
Ottertune
Le projet d'ajustement de système existant que nous avons développé s'appelle OtterTune.
Imaginez que la base de données soit configurée en tant que service. L'idée est que vous téléchargiez les mesures d'exécution des opérations de base de données lourdes qui consomment toutes les ressources, et la configuration recommandée des régulateurs vient en réponse, ce qui, à notre avis, augmentera la productivité. Il peut s'agir d'un délai, d'une bande passante ou de toute autre caractéristique que vous spécifiez - nous essaierons de trouver la meilleure option.

La principale nouveauté du projet OtterTune est la
possibilité d'utiliser les données des sessions de réglage
précédentes et d'augmenter l'efficacité des sessions suivantes. Par exemple, prenez la configuration PostgreSQL, qui a une application que nous n'avons jamais vue auparavant. Mais s'il a certaines caractéristiques ou utilise la base de données de la même manière que les bases de données que nous avons déjà vues dans nos applications, alors nous savons déjà comment configurer cette application plus efficacement.
À un niveau supérieur, l'algorithme de travail est le suivant.
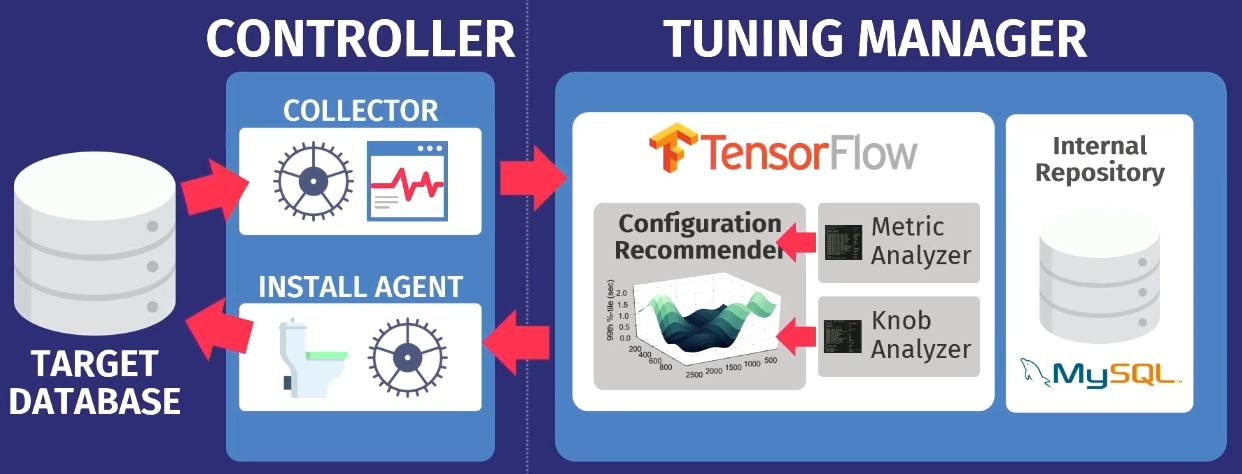
Disons qu'il existe une base de données cible: PostgreSQL, MySQL ou VectorWise. Vous devez installer le contrôleur dans le même domaine, qui effectuera deux tâches.
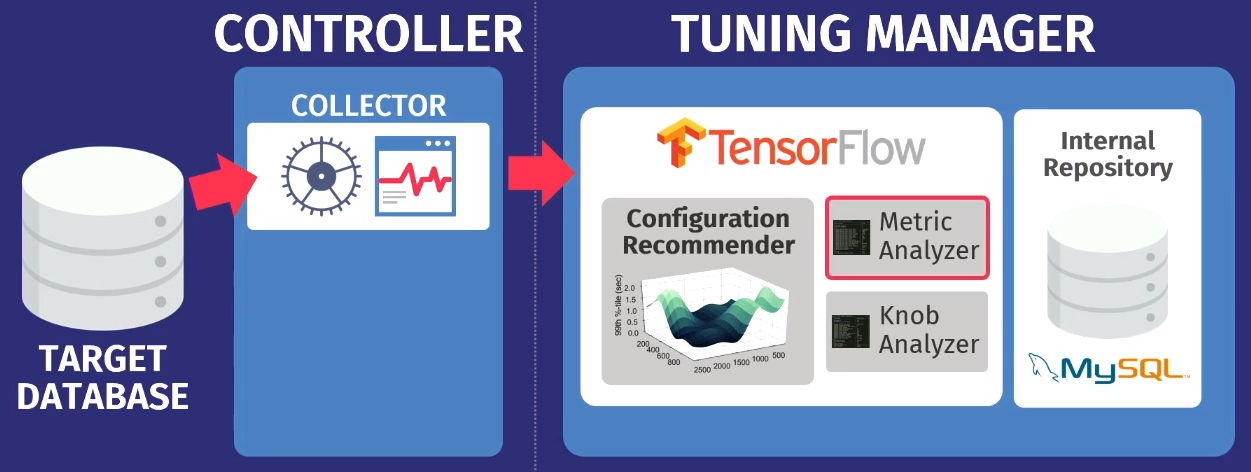
Le premier est exécuté par le soi-disant collecteur - un outil qui collecte des données sur la configuration actuelle, c'est-à-dire interroger les métriques de temps d'exécution des applications vers la base de données. Les données collectées par le collecteur sont chargées dans Tuning Manager, un service de réglage. Peu importe que la base de données fonctionne localement ou dans le cloud. Après le téléchargement, les données sont stockées dans notre propre référentiel interne, qui stocke toutes les sessions de configuration de test jamais effectuées.
Avant de donner des recommandations, vous devez effectuer deux étapes. Tout d'abord, vous devez examiner les métriques d'exécution et découvrir celles qui sont réellement importantes. L'exemple suivant montre les métriques renvoyées par MySQL mais la
SHOW_GLOBAL_STATUS sur InnoDB. Tous ne sont pas utiles pour notre analyse. On sait que dans l'apprentissage automatique, une grande quantité de données n'est pas toujours bonne. Parce qu'alors encore plus de données sont nécessaires pour séparer le grain de l'ivraie. Comme dans ce cas,
il est important de se débarrasser des entités qui n'ont pas vraiment d'importance .
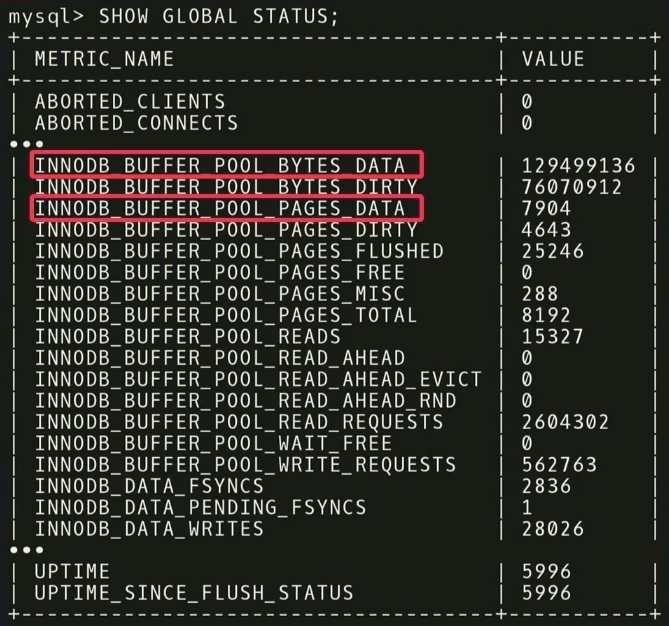
Par exemple, il existe deux mesures:
INNODB_BUFFER_POOL_BYTES_DATA et
INNODB_BUFFER_POOL_PAGES_DATA . En fait, c'est la même métrique, mais dans des unités différentes. Vous pouvez effectuer une analyse statistique, voir que les métriques sont fortement corrélées et conclure que l'utilisation des deux est redondante pour l'analyse. Si vous en jetez un, la dimension de la tâche d'apprentissage diminuera et le temps pour recevoir une réponse sera réduit.
Dans la deuxième étape, nous faisons de même, uniquement en ce qui concerne les régulateurs.
Il y a 500 régulateurs dans MySQL , et, bien sûr, tous ne sont pas vraiment importants, mais différentes applications sont importantes pour différentes applications. Il est nécessaire d'effectuer une autre analyse statistique pour savoir quels régulateurs affectent réellement la fonction cible.
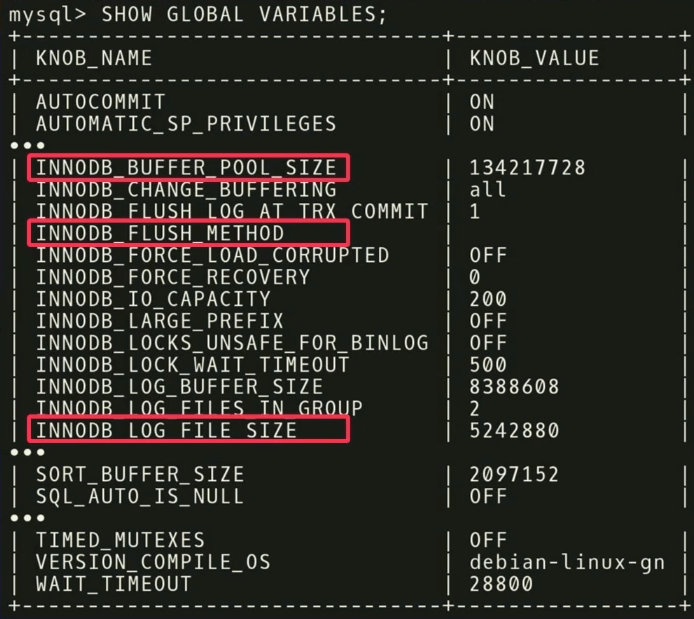
Dans notre exemple, nous avons constaté que les trois
INNODB_BUFFER_POOL_SIZE ,
FLUSH_METHOD et
LOG_FILE_SIZE ont le plus grand impact sur les performances. Ils réduisent le temps de retard pour une charge de travail transactionnelle.
Il y a d'autres points intéressants liés aux régulateurs. Dans la capture d'écran, il y a un régulateur nommé
TIMED_MUTEXES . Si vous vous référez à la documentation de travail de MySQL, dans la section 45.7, il sera indiqué que ce régulateur est obsolète. Mais
l'algorithme d'apprentissage automatique n'est pas en mesure de lire la documentation , il ne le sait donc pas. Il sait qu'il existe un régulateur qui peut être activé ou désactivé, et il faudra beaucoup de temps pour comprendre que cela n'affecte rien. Mais vous pouvez faire des calculs à l'avance et découvrir que le régulateur ne fait rien, et ne perdez pas de temps à le configurer.
Après analyse, les données sont transférées vers notre algorithme de configuration en utilisant
le modèle de processus gaussien - une méthode assez ancienne. Vous avez probablement entendu parler du deep learning, nous faisons quelque chose de similaire, mais sans réseaux profonds. Nous utilisons
GPflow , un package pour travailler avec des modèles de processus gaussiens développés en Russie sur la base de TensorFlow. L'algorithme émet une recommandation qui devrait améliorer la fonction objectif; ces données sont retransférées à l'agent d'installation travaillant à l'intérieur du contrôleur. L'agent applique les modifications en effectuant une réinitialisation - malheureusement, il devra redémarrer la base de données - puis le processus se répète à nouveau. D'autres mesures d'exécution sont collectées, transférées à l'algorithme, une analyse de la possibilité d'améliorer et d'augmenter la productivité est effectuée, une recommandation est émise, etc., encore et encore.
Une caractéristique clé d'OtterTune est que les algorithmes n'ont besoin que d'informations sur les métriques d'exécution en entrée. Nous n'avons pas besoin de voir vos données et demandes d'utilisateurs. Nous avons juste besoin de suivre les opérations de lecture et d'écriture. Il s'agit d'un argument puissant - les données vous appartenant ou appartenant à vos clients ne seront pas divulguées à des tiers. Nous n'avons pas besoin de voir les demandes, l'algorithme fonctionne uniquement sur la base des métriques d'exécution, car il donne des recommandations pour les régulateurs, et non pour la conception physique.
Jetons un coup d'œil à la démo OtterTune. Sur le site Web du projet, nous exécuterons Postgres 9.6 et chargerons le système avec le test TPC-C. Commençons par la configuration initiale de PostgreSQL, qui est déployée lorsqu'elle est installée sur Ubuntu.
Tout d'abord, exécutez le test TPC-C pendant cinq minutes, collectez les mesures d'exécution nécessaires, téléchargez-les sur le service OtterTune, obtenez des recommandations, appliquez les modifications, puis répétez le processus. Nous y reviendrons plus tard. Le système de base de données s'exécute sur un ordinateur, le service Tensor Flow sur un autre et charge les données ici.
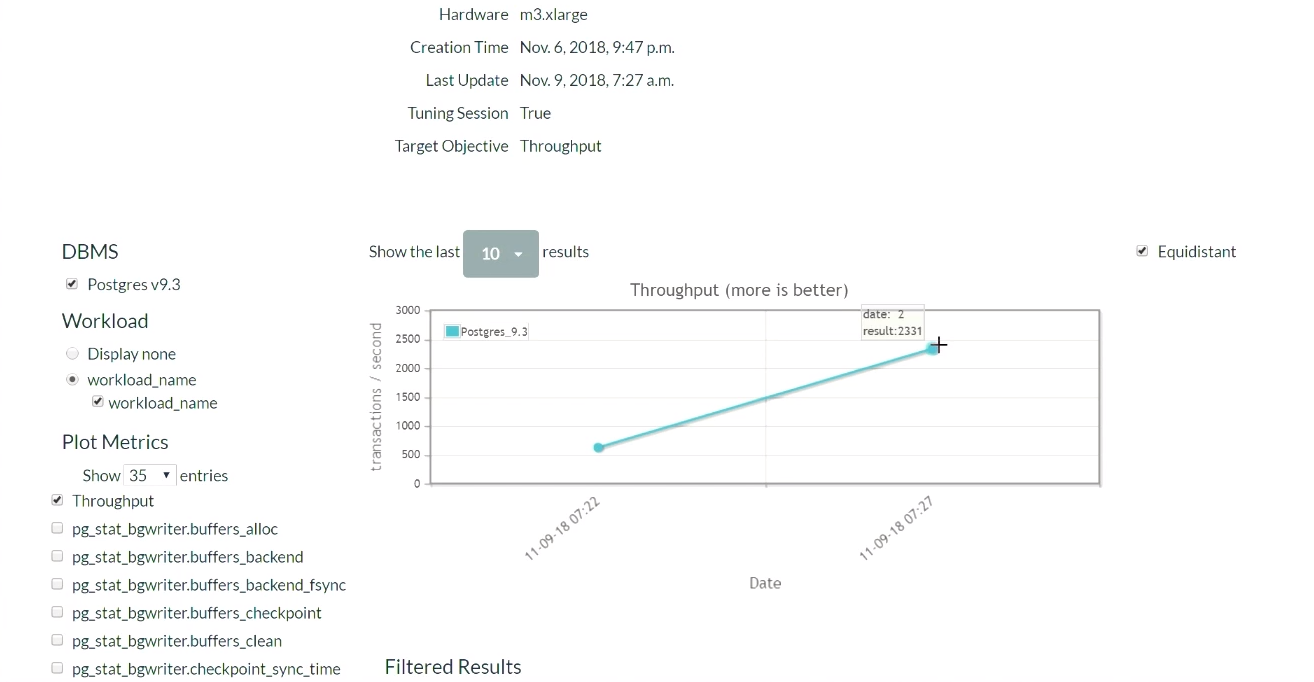
Cinq minutes plus tard, nous rafraîchissons la page (une démonstration de cette partie des résultats commence à
ce moment ). Lorsque nous avons commencé, dans la configuration par défaut de PostgreSQL, il y avait 623 transactions par seconde. Ensuite, après avoir reçu la recommandation et appliqué les modifications une fois, le nombre de transactions est
passé à 2300 par seconde . Il convient de reconnaître que cette démonstration a déjà été lancée plusieurs fois, de sorte que le système dispose déjà d'un ensemble de données précédemment collectées. C'est pourquoi la solution est si rapide. Que se passerait-il si le système ne disposait pas de telles données précédemment collectées? Cet algorithme est une sorte de fonction étape par étape, et il atteindrait progressivement ce niveau.

Après un certain temps et cinq itérations, le meilleur résultat était 2600. Nous sommes passés de 600 transactions par seconde et avons pu atteindre une valeur de 2600. Une petite baisse est apparue car l'algorithme a décidé d'essayer une manière différente d'ajuster les régulateurs après avoir obtenu de bons résultats. Le résultat a été une marge, donc une baisse importante des performances n'a pas eu lieu. Ayant reçu un résultat négatif, l'algorithme s'est reconfiguré et a commencé à chercher d'autres moyens de régulation.
Nous concluons que vous ne devriez pas avoir peur de commencer une mauvaise stratégie au travail, car l'algorithme explorera l'espace de la solution et essaiera différentes configurations pour atteindre les conditions de l'accord SLA. Bien que vous puissiez toujours configurer le service afin que l'algorithme ne sélectionne que des solutions améliorées. Et au fil du temps, vous recevrez tous les meilleurs et meilleurs résultats.
Revenons maintenant au sujet de notre conversation. Je vais vous parler des résultats existants d'un
article publié dans Sigmod. Nous avons configuré MySQL et PostgreSQL pour TPC-C en utilisant OtterTune, afin d'augmenter le débit.
Comparez les configurations de ces SGBD, déployées par défaut lors de la première installation sur Ubuntu. Ensuite, exécutez quelques scripts de configuration open source que vous pouvez obtenir auprès de Percona et d'autres cabinets de conseil travaillant avec PostgreSQL. Ces scripts utilisent des procédures heuristiques, telles que la règle selon laquelle vous devez définir une certaine taille de mémoire tampon pour votre matériel. Nous avons également une configuration d'Amazon RDS, qui possède déjà des préréglages Amazon pour l'équipement sur lequel vous travaillez. Comparez ensuite cela avec le résultat de la configuration manuelle de DBA coûteux, mais avec la condition qu'ils disposent de 20 minutes et la possibilité de définir les paramètres souhaités. Et la dernière étape consiste à lancer OtterTune.
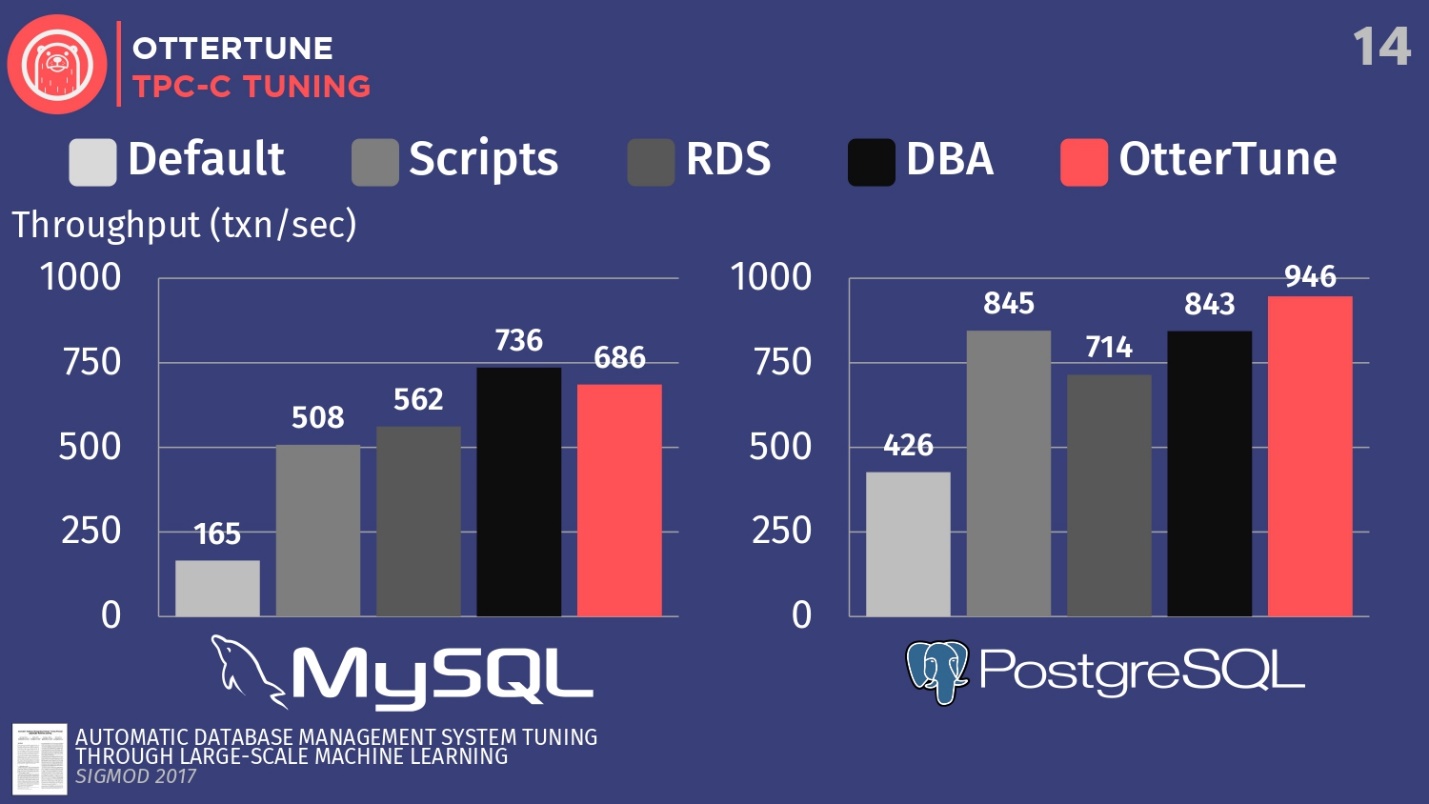
Pour MySQL, vous pouvez voir que la configuration par défaut est loin derrière, les scripts fonctionnent un peu mieux, RDS est un peu mieux. Dans ce cas, le meilleur résultat a été affiché par l'administrateur de la base de données - le principal administrateur MySQL de Facebook.
OtterTune a perdu à l'homme . Mais le fait est qu'il existe un certain régulateur qui désactive la synchronisation du nettoyage des journaux, et ce n'est pas important pour Facebook. Cependant, nous avons refusé l'accès à ce régulateur OtterTune car les algorithmes ne savent pas si vous acceptez de perdre les cinq dernières millisecondes de données. À notre avis, cette décision devrait être prise par une personne. Facebook est peut-être d'accord avec de telles pertes, nous ne le savons pas. Si nous ajustons ce régulateur de la même manière, nous pouvons rivaliser avec la personne.
Cet exemple montre comment nous essayons d'être conservateurs dans la mesure où la décision finale doit être prise par la personne. Parce qu'il y a certains aspects des bases de données que l'algorithme ML ne connaît pas.
Dans le cas de PostgreSQL, les scripts de configuration fonctionnent bien. RDS fait un peu pire. Mais, il convient de noter que les indicateurs OtterTune ont dépassé la personne. L'histogramme montre les résultats obtenus après la création de la base de données par le conseiller expert senior PostgreSQL du Wisconsin. Dans cet exemple, OtterTune a pu trouver l'équilibre optimal entre la taille du fichier journal et la taille du pool de mémoire tampon, équilibrant la quantité de mémoire utilisée par ces deux composants et garantissant les meilleures performances.
La principale conclusion est que le service OtterTune utilise des algorithmes et un apprentissage automatique tels que nous pouvons atteindre des performances identiques ou meilleures par rapport aux DBA très, très chers. Et cela ne s'applique pas seulement à une instance de la base de données, nous pouvons adapter le travail à des dizaines de milliers de copies, car il ne s'agit que de logiciels, de données.
Peloton
Le deuxième projet dont j'aimerais parler s'appelle Peloton. Il s'agit d'un tout nouveau système de données que nous construisons à partir de zéro chez Carnegie Mellon. Nous l'appelons un SGBD autogéré.
L'idée est de savoir quels changements pour le mieux peuvent être apportés si vous contrôlez l'intégralité de la pile logicielle. Comment améliorer les paramètres qu'OtterTune peut faire, en raison de la connaissance de chaque fragment du système, sur l'ensemble du cycle du programme.

Comment cela fonctionnera: nous avons intégré les
composants de l'apprentissage automatique avec renforcement dans le système de base de données, et nous pouvons observer tous les aspects de son comportement au moment de l'exécution, puis donner des recommandations. Et nous ne sommes pas limités aux recommandations sur l'ajustement des régulateurs, comme cela se produit dans le service OtterTune, nous aimerions effectuer l'ensemble des actions standard dont j'ai parlé plus tôt: sélection des index, choix des schémas de partition, mise à l'échelle verticale et horizontale, etc.
Le nom du système Peloton est susceptible de changer. Je ne sais pas comment en Russie, mais aux États-Unis, le terme « peloton» signifie «intrépide» et «terminer», et en français, il signifie «peloton». Aux États-Unis, il existe une entreprise de vélos d' appartement Peloton qui a beaucoup d'argent. Chaque fois qu'une mention d'eux apparaît, par exemple, l'ouverture d'un nouveau magasin, ou une nouvelle publicité à la télévision, tous mes amis m'écrivent: «Écoutez, ils ont volé votre idée, volé votre nom». Les publicités montrent de belles personnes qui font du vélo d'exercice, et nous ne pouvons tout simplement pas rivaliser avec cela. Et récemment, Uber a annoncé un nouveau planificateur de ressources appelé Peloton, nous ne pouvons donc plus l'appeler notre système. Mais nous n'avons pas encore de nouveau nom, donc dans cette histoire, j'utiliserai toujours la version actuelle du nom.Considérez comment ce système fonctionne à un niveau élevé. Par exemple, prenez la base de données cible, je le répète, c'est notre logiciel, c'est ce avec quoi nous travaillons. Nous collectons le même historique de charge de travail que j'ai montré précédemment. La différence est que nous allons générer des modèles de prévision qui nous permettront de prédire quels seront les futurs cycles de charge de travail, quelles seront les futures exigences de charge de travail. C'est pourquoi nous appelons ce système un SGBD autogéré.
L'idée de base d'un SGBD autogéré est similaire à l'idée d'une voiture avec contrôle automatique.
Un véhicule sans pilote regarde devant lui et peut voir ce qui se trouve devant lui sur la route, peut prédire comment se rendre à destination. Un système de base de données autonome fonctionne de la même manière. Vous devriez être en mesure de regarder vers l'avenir et de tirer une conclusion sur ce à quoi ressemblera la charge de travail dans une semaine ou dans une heure. Ensuite, nous transmettons ces données prédites au composant de planification - nous l'appelons le cerveau - fonctionnant sur Tensor Flow.
Le processus fait écho au travail d'AlphaGo de Londres dans le cadre du projet Google Deep Mind, au plus haut niveau, tout fonctionne dans un scénario similaire: Monte Carlo recherche l'arbre, le résultat de la recherche est diverses actions qui doivent être effectuées pour atteindre l'objectif souhaité.
L'algorithme suivant détermine approximativement le schéma de fonctionnement:
- Les données source sont un ensemble d'actions requises, par exemple, la suppression d'un index, l'ajout d'un index, la mise à l'échelle verticale et horizontale, etc.
- Une séquence d'actions est générée, ce qui conduit finalement à la réalisation de la fonction objectif maximale.
- Tous les critères, à l'exception du premier, sont ignorés et les modifications sont appliquées.
- Le système examine l'effet résultant, puis le processus se répète encore et encore.

Ne recourez pas constamment à la métaphore d'une voiture sans pilote, mais c'est ainsi qu'ils fonctionnent. C'est ce qu'on appelle l'horizon de planification.
Après avoir regardé l'horizon sur la route, nous nous fixons un point imaginaire à atteindre, puis nous commençons à planifier une séquence d'actions pour atteindre ce point à l'horizon: accélérer, ralentir, tourner à gauche, tourner à droite, etc. Ensuite, nous rejetons mentalement toutes les actions, sauf la première qui doit être effectuée, effectuez-la, puis répétez le processus à nouveau. Les drones exécutent un tel algorithme 30 fois par seconde. Pour les bases de données, ce processus est un peu plus lent, mais l'idée reste la même.
Nous avons décidé de créer notre propre système
de base de données à
partir de zéro, plutôt que de construire quelque chose sur PostgreSQL ou MySQL , car, pour être honnête, ils sont trop lents par rapport à ce que nous aimerions faire. PostgreSQL est magnifique, je l'adore et je l'utilise dans mes cours universitaires, mais cela prend trop de temps pour créer des index, car toutes les données proviennent de disques.
Par analogie avec les automobiles, un SGBD autonome sur PostgreSQL peut être comparé à un wagon sans pilote. Le camion pourra reconnaître le chien devant la route et le contourner, mais pas s'il s'est enfui sur la chaussée directement devant la voiture. Ensuite, une collision est inévitable, car le camion n'est pas suffisamment maniable. Nous avons décidé de créer un système à partir de zéro afin de pouvoir appliquer les modifications le plus rapidement possible et découvrir quelle est la bonne configuration.
Nous avons maintenant résolu le premier problème et publié
un article sur la combinaison de l'apprentissage en profondeur et de la régression linéaire classique pour la sélection et la prévision automatiques des charges de travail.
Mais il y a un problème plus important, pour lequel nous n'avons pas encore de bonne solution -
les catalogues d'actions . La question n'est pas de savoir comment choisir les actions, car les gars de Microsoft l'ont déjà fait. La question est de savoir si une action est meilleure qu'une autre, en termes de ce qui se passe avant le déploiement et après le déploiement. Comment annuler une action si l'index créé par la commande d'une personne n'est pas optimal, comment pouvez-vous annuler cette action et indiquer la raison de l'annulation. En outre, il existe un certain nombre d'autres tâches en termes d'interaction de notre propre système avec le monde extérieur, pour lesquelles nous n'avons pas encore de solution, mais nous y travaillons.
Soit dit en passant, je vais vous raconter une histoire divertissante sur une société de bases de données bien connue. Cette entreprise avait un outil de sélection d'index automatique, et l'outil avait un problème. Un client annulait constamment tous les index que l'outil recommandait et appliquait. Cette annulation s'est produite si souvent que l'outil s'est bloqué. Il ne savait pas quelle devrait être la nouvelle stratégie de comportement, car toute solution proposée à une personne a reçu une évaluation négative. Lorsque les développeurs se sont tournés vers le client et lui ont demandé: «Pourquoi annulez-vous toutes les recommandations et suggestions sur les indices?», Le client a répondu qu'il n'aimait tout simplement pas leurs noms. Les gens sont stupides, mais vous devez vous en occuper. Et pour ce problème, je n'ai pas non plus de solution.Conception d'un SGBD autonome
Étant donné deux approches différentes de la création de systèmes de bases de données autonomes, parlons maintenant de la façon de concevoir un SGBD afin qu'il soit autonome.
Arrêtons-nous sur trois sujets:
- comment ajuster les régulateurs,
- comment collecter des mesures internes,
- comment concevoir des actions.
Encore une fois, revenons aux points clés: le système de base de données doit fournir les informations correctes aux algorithmes d'apprentissage automatique pour l'adoption ultérieure de meilleures décisions. La quantité de données inutiles que nous transmettons doit être réduite afin d'augmenter la vitesse de réception des réponses.
J'ai déjà dit que tout régulateur qui oblige une personne à porter un jugement de valeur sur les composants autonomes devrait être marqué comme interdit. Il est nécessaire de marquer ce paramètre dans les paramètres PG_SETTINGSou dans tout autre fichier de configuration afin d'empêcher l'algorithme d'accéder à ce régulateur.En ce qui concerne les paramètres tels que les chemins d'accès aux fichiers, les niveaux d'isolement, les exigences de stabilité des transactions, etc. les décisions doivent être prises par l'homme et non par un algorithme.
, , , , .
, , , .
:
- . , , .
- . , , -1 0, .
- , . , . 64- , 0 2 64 . , .
, . , 10 , , 10 . , .
- , . , , . , , , .
, , , . , . , , , — . , .
, , , . , .
, , . , : , , , , . - Oracle, , .

, , .
, , . , , , . - , , , . : PostgreSQL , .

, , , .
- , , , . , , . RocksDB, MyRocks MySQL.
RocksDB . , . , , , . RocksDB, .

, , , , . MyRocks . — :
ROCKSDB_BITES_READ, ROCKSDB_BITES_WRITTEN . , , . , . , .

, , , .
, , open source. , .
, ,
. MySQL , . , . 5 , 10 , , . 5 , — .
, . — PostgreSQL .
— . , . , , , , .
. , — SLA. , .
, . , . , . , .

, - , . , , - , . , , , — , -, , .
, , , .
, . , , , , 5- . downtime, .
, , , , , . , , , , .
Oracle autonomous database
Oracle . 2017 Oracle , . , Oracle, , « , Oracle 20 ».
. , , , , , . CIDR , . , : «, , , . , , , Oracle ?» , — ., , , Oracle. , .
,
— , , , - .
—
, . , , , 2000- . , Oracle , . , : , — - .
, . , , .
—
. , . : JOIN. . . , . .
Oracle. Microsoft 2017 SQL Server, . IBM DB2 00- , «LEO» — . , 1970-, Ingres. , JOIN, , . .
, , .
, , . , , . , , .
, , — , , , . , , , . , , .., .
HighLoad++ , HighLoad++ Siberia . , 39 , , highload- - .
HighLoad++ , . , UseData Conf — 16 , . , .