
L'article est plus technique que sur les affaires, mais nous tirerons également quelques conclusions du point de vue des affaires. La plus grande attention sera accordée à la comparaison automatique des marchandises provenant de différentes sources.
Le travail de la boutique en ligne se compose d'un nombre assez important de composants. Et quel que soit le plan, pour réaliser un profit dès maintenant, ou pour croître et rechercher des investisseurs, ou, par exemple, pour développer des domaines connexes, au moins vous devez fermer ces questions:
- Travailler avec les fournisseurs. Pour vendre quelque chose d'inutile, vous devez d'abord acheter quelque chose d'inutile.
- Gestion d'annuaire. Quelqu'un a une spécialisation étroite, tandis que quelqu'un vend des centaines de milliers de produits différents.
- Gestion des prix de détail. Ici, vous devrez tenir compte des prix des fournisseurs, des prix des concurrents et des instruments financiers abordables.
- Travaillez avec l'entrepôt. En principe, il est possible de ne pas avoir son propre entrepôt, mais de prendre les marchandises dans les entrepôts des partenaires, mais d'une manière ou d'une autre la question est.
- Marketing. Ici, le site est rempli de contenu, de placement sur des sites, de publicité (en ligne et hors ligne), de promotions et bien plus encore.
- Réception et traitement des commandes. Centre d'appels, panier sur le site, commandes via messagerie instantanée, commandes via plateformes et marketplaces.
- Livraison.
- Comptabilité et autres systèmes internes.
Le magasin, dont nous parlerons, n'a pas une spécialisation étroite, mais offre un tas de tout, des cosmétiques au mini-tracteur. Je vais vous dire comment nous travaillons avec les fournisseurs, le suivi des concurrents, la gestion des catalogues et les prix (gros et détail), le travail avec les clients grossistes. Une petite touche sur le sujet de l'entrepôt.
Pour mieux comprendre certaines des solutions techniques, il ne sera pas superflu de savoir qu’en
à un moment donné, nous avons décidé que les choses technologiques, si possible, seraient faites non pas pour nous-mêmes, mais universelles. Et, peut-être, après plusieurs tentatives, il en ressortira pour développer une nouvelle entreprise. Il s'avère, conditionnellement, une startup au sein de l'entreprise.
Nous envisageons donc un système séparé, plus ou moins universel, avec lequel le reste de l'infrastructure de l'entreprise est intégré.
Quel est le problème de travailler avec les fournisseurs?
Et il y en a beaucoup, en fait. Juste pour en donner:
- Il existe de nombreux fournisseurs en soi. Nous en avons environ 400. Tout le monde doit prendre un peu de temps.
- Il n'y a pas de moyen unique d'obtenir des offres des fournisseurs. Quelqu'un envoie le courrier dans les délais, quelqu'un sur demande, quelqu'un télécharge sur l'hébergement de fichiers, quelqu'un place sur le site. Il existe de nombreuses façons, jusqu'à l'envoi du fichier via skype.
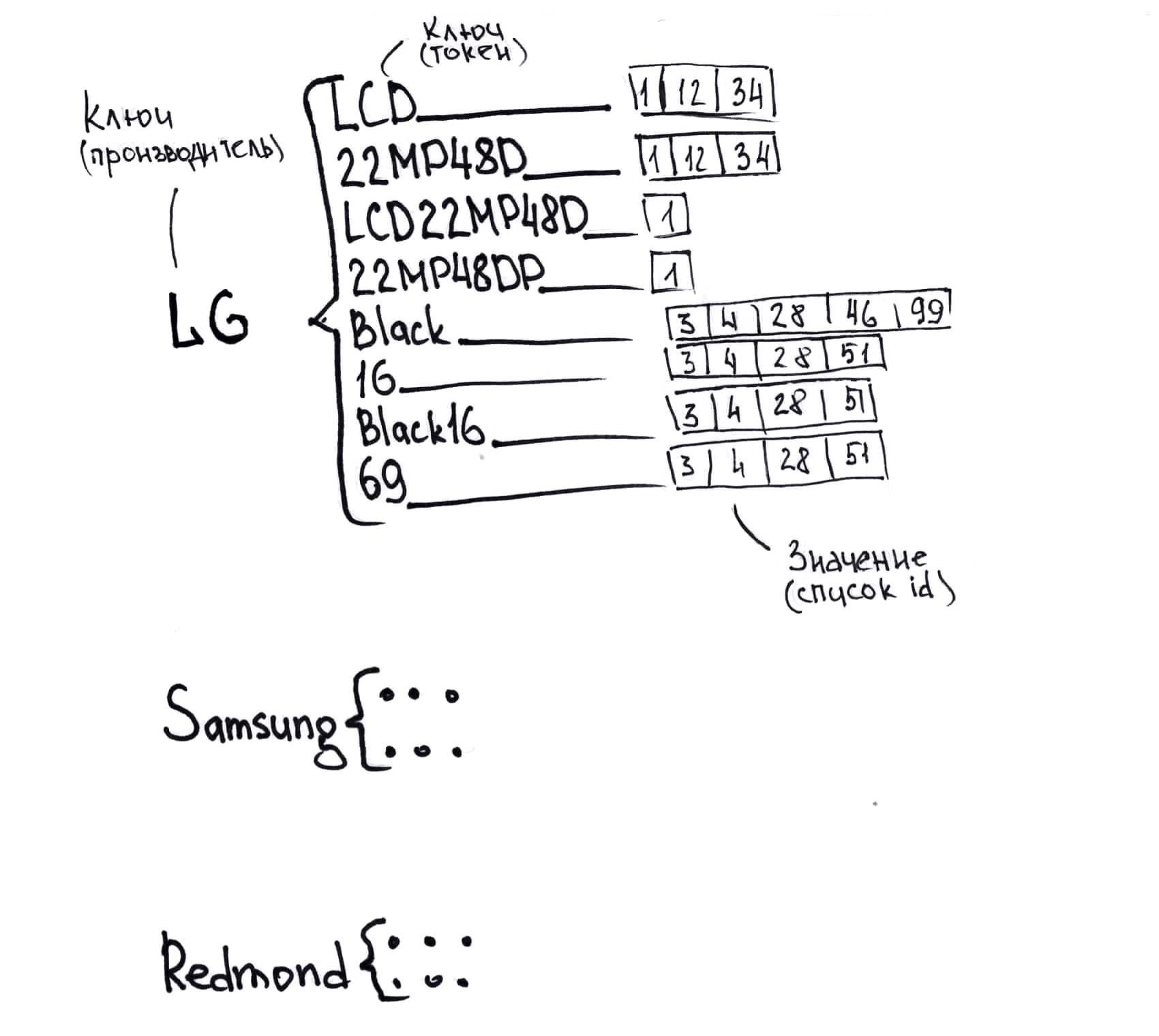
- Il n'y a pas de format de données unique. J'ai même fait un dessin sur ce sujet (il est plus bas, les tableaux symbolisent différents formats).
- Il y a le concept de prix de détail minimum et de prix de gros minimum qui doivent être respectés afin de continuer à travailler avec le fournisseur. Ils sont souvent fournis dans leur propre format.
- La nomenclature de chaque fournisseur est différente. Par conséquent, le même produit est appelé différemment et il n'y a pas de clé unique permettant de le comparer facilement. Par conséquent, nous le comparons difficile.
- Le système de commande auprès du fournisseur n'est pas automatisé. Nous commandons à quelqu'un sur Skype, à quelqu'un de votre compte, à quelqu'un à qui nous envoyons un fichier exel tous les soirs avec une liste de commandes.

Nous avons appris à faire face à ces problèmes. En plus de ce dernier, les travaux sur ce dernier sont en cours. Maintenant, il y aura des détails techniques, puis considérez la liste suivante.
Collecte de données
Comme c'était
Les fichiers des fournisseurs ont été collectés manuellement à partir de diverses sources et préparés. La préparation comprenait le changement de nom selon un modèle spécifique et la modification du contenu. Selon le fichier, il était nécessaire de supprimer les marchandises non standard, les marchandises qui ne sont pas en stock, de renommer les colonnes ou de convertir des devises, de collecter des données à partir de différents onglets sur un seul.
Comment
Tout d'abord, nous avons appris à vérifier le courrier et à récupérer des lettres avec des pièces jointes à partir de là. Ils ont ensuite automatisé le travail avec des liens directs et des liens vers des lecteurs Yandex et Google. Cela a résolu le problème de la réception d'offres d'environ 75% de nos fournisseurs. Nous avons également remarqué que c'est à travers ces canaux que les offres sont le plus souvent mises à jour, de sorte que le pourcentage réel d'automatisation est plus élevé. Nous obtenons toujours des prix dans les messagers.
Deuxièmement, nous ne traitons plus les fichiers manuellement. Pour ce faire, nous avons entré des profils de fournisseur, où vous pouvez spécifier la colonne et l'onglet à utiliser, comment déterminer la devise et la disponibilité, le délai de livraison et le calendrier de travail du fournisseur.
Cela s'est avéré flexible. Naturellement, nous n'avons pas tout pris en compte la première fois, mais maintenant il y a suffisamment de flexibilité pour configurer le traitement des 400 fournisseurs, étant donné que tout le monde a des formats de fichiers différents.
Quant aux formats de fichiers, nous comprenons xls, xlsx, csv, xml (yml). Dans notre cas, c'était suffisant.
Ils ont également compris comment filtrer les enregistrements. Nous avons fait une liste de mots vides et si l'offre du fournisseur en contient, nous ne la traitons pas. Les détails techniques sont les suivants: sur une petite liste, vous pouvez et encore mieux «de face», sur de grandes listes, un filtre Bloom plus rapide. Nous avons fait des expériences avec lui et avons tout laissé tel quel, car le gain est ressenti sur la liste d'un ordre de grandeur plus grand que le nôtre.
Une autre chose importante est le calendrier de travail du fournisseur. Nos fournisseurs travaillent selon des horaires différents, en plus, ils sont situés dans différents pays, sur lesquels les week-ends ne coïncident pas. Et le délai de livraison est généralement indiqué sous forme de nombre ou de plage de nombres en jours ouvrables. Lorsque nous établissons les prix de détail et de gros, nous devrons en quelque sorte évaluer le moment où nous pouvons livrer les marchandises au client. Pour ce faire, nous avons créé des calendriers configurables et dans les paramètres de chaque fournisseur, vous pouvez spécifier sur quels calendriers il fonctionne.
J'ai dû faire une configuration de remises et de marges en fonction de la catégorie et du fabricant. Il arrive que le fournisseur ait un dossier commun à tous les partenaires, mais il existe des accords de remise avec certains partenaires. Grâce à cela, il était encore possible d'ajouter ou de soustraire la TVA si nécessaire.
Soit dit en passant, la configuration des règles de remise et de majoration nous amène au sujet suivant. Après tout, avant de les utiliser, vous devez savoir de quel type de produit il s'agit.
Fonctionnement de la cartographie
Un petit exemple de la façon dont le même produit peut être appelé de différents fournisseurs, pour comprendre avec quoi vous devez travailler:
Moniteur LG LCD 22MP48D-P
21,5 "LG 22MP48D-P Black (16: 9, 1920x1080, IPS, 60 Hz, DVI + D-Sub (VGA))
COMP - Périphériques informatiques - Moniteurs LG 22MP48D-P
jusqu'à 22 "moniteur LG inclus LG 22MP48D-P (21,5", noir, IPS LED 5ms 16: 9 DVI mat 250cd 1920x1080 D-Sub FHD) 22MP48D-P
Moniteurs LG 22 "LG 22MP48D-P Glossy-Black (IPS, LED, 1920x1080, 5 ms, 178 ° / 178 °, 250 cd / m, 100M: 1, + DVI)
Moniteurs LCD LG LCD Monitor 22 "IPS 22MP48D-P LG 22MP48D-P
Moniteur LG 21,5 "LG 22MP48D-P gl.Black IPS, 1920x1080, 5ms, 250 cd / m2, 1000: 1 (Mega DCR), D-Sub, DVI-D (HDCP), vesa 22MP48D-P.ARUZ
Moniteur LG LG 22MP48D-P Noir 22MP48D-P.ARUZ
Moniteur LG 22MP48D-P 22MP48D-P
Moniteurs LG 22MP48D-P Glossy-Black 22MP48D-P
Moniteur 21,5 "LG Flatron 22MP48D-P gl.Black (IPS, 1920x1080, 16: 9, 178/178, 250cd / m2, 1000: 1, 5ms, D-Sub, DVI-D) (22MP48D-P) 22MP48D-P
Moniteur 22 "LG 22MP48D-P
LG 22MP48D-P IPS DVI
LG LG 21.5 "22MP48D-P IPS LED, 1920x1080, 5ms, 250cd / m2, 5Mln: 1, 178 ° / 178 °, D-Sub, DVI, Tilt, VESA, Glossy Black 22MP48D-P
LG 21,5 "22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P
Moniteur 21,5 '' LG 22MP48D-P Noir
LG MONITOR 21.5 "LG 22MP48D-P Glossy-Black (IPS, LED, 1920x1080, 5 ms, 178 ° / 178 °, 250 cd / m, 100M: 1, + DVI) 22MP48D-P
Moniteur LCD LG 21,5 '' [16: 9] 1920x1080 (FHD) IPS, non GLARE, 250cd / m2, H178 ° / V178 °, 1000: 1, 16.7M Color, 5ms, VGA, DVI, Tilt, 2Y, Black OK 22MP48D -P
LCD LG 21,5 "22MP48D-P noir {IPS LED 1920x1080 5ms 16: 9 250cd 178 ° / 178 ° DVI D-Sub} 22MP48D-P.ARUZ
IDS_Monitors LG LG 22 "LCD 22MP48D 22MP48D-P
Moniteur LG 21,5 "16x9 LG 21,5" 22MP48D-P noir IPS LED 5ms 16: 9 DVI mat 250cd 1920x1080 D-Sub FHD 2,7kg 22MP48D-P.ARUZ
Moniteur 21,5 "LG 22MP48D-P [Noir]; 5 ms; 1920x1080, DVI, IPS
Comme c'était
La comparaison portait sur 1C (module tiers payé). Côté commodité / rapidité / précision, un tel système a permis de maintenir un catalogue de 60 000 produits disponibles à ce niveau par 6 personnes. Autrement dit, chaque jour, dépassé et disparu des offres des fournisseurs, autant de produits assortis que de nouveaux ont été créés. Très approximativement - 0,5% de la taille du catalogue, soit 300 produits.
Comment elle est devenue: une description générale de l'approche
Un peu plus haut, j'ai donné un exemple de ce que nous devons faire correspondre. En explorant le sujet de l'appariement, j'ai été un peu surpris qu'ElasticSearch soit populaire pour la tâche d'appariement, à mon avis, il a des limites conceptuelles. Quant à notre pile technologique, nous utilisons MS SQL Server pour le stockage de données, mais la comparaison fonctionne sur notre propre infrastructure, et comme il y a beaucoup de données et que nous devons les traiter rapidement, nous utilisons des structures de données optimisées pour une tâche spécifique et essayons de ne pas accéder au disque ou à la base de données sans avoir besoin et d'autres systèmes lents.
De toute évidence, le problème de comparaison peut être résolu de plusieurs façons, et évidemment, aucun ne donnera une précision absolue. Par conséquent, l'idée principale est d'essayer de combiner ces méthodes, de les classer par précision et vitesse et de les appliquer par ordre décroissant de précision, en tenant compte de la vitesse.
Le plan d'exécution de chacun de nos algorithmes (avec une réserve sur les cas dégénérés) peut être brièvement représenté par la séquence générale suivante:
Tokenisation Nous divisons la ligne source en quelque chose de significatif et indépendant. Cela peut être fait une fois de plus et utilisé dans tous les algorithmes.
Normalisation des jetons. Dans le bon sens, vous devez amener les mots de la langue naturelle au nombre général et à la déclinaison, et des identifiants comme «ABC15MX» (c'est du cyrillique, si quelque chose) pour convertir en latin. Et mettez tout dans le même registre.
Catégorisation des jetons. Essayer de comprendre ce que signifie chaque partie. Par exemple, vous pouvez sélectionner une catégorie, un fabricant, une couleur, etc.
Recherchez le meilleur candidat pour un match.
Une estimation de la probabilité que la ligne d'origine et le meilleur candidat indiquent le même produit.
Les deux premiers points sont communs à tous les algorithmes actuellement disponibles, puis les improvisations commencent.
Tokenisation Ici, nous l'avons fait, nous séparons la ligne en parties en fonction de caractères spéciaux tels que l'espace, la barre oblique, etc. Le jeu de caractères au fil du temps s'est avéré important, mais nous n'avons utilisé rien de compliqué dans l'algorithme lui-même.
Ensuite, nous devons normaliser les jetons. Convertissez-les en minuscules. Au lieu de tout mener au cas nominatif, nous avons simplement coupé les fins. Nous avons également un petit dictionnaire et nous traduisons nos jetons en anglais. Entre autres choses, la traduction nous sauve de synonymes, de sens similaire, les mots russes sont traduits en anglais de la même manière. Là où nous n'avons pas réussi à traduire, nous changeons les caractères cyrilliques orthographiques en alphabet latin. (Ce n'est pas du tout superflu, comme il s'est avéré. Même là où vous ne vous attendez pas à un sale tour, par exemple, dans la ligne "Samsung U43NU7100U", le cyrillique E peut tout à fait se rencontrer).

Catégorisation des jetons. Nous pouvons mettre en évidence la catégorie, le fabricant, le modèle, l'article, l'EAN, la couleur. Nous avons un répertoire où les données sont structurées. Nous avons des données sur les concurrents que les plateformes de trading nous fournissent. Lors de leur traitement, lorsque cela est possible, nous structurons les données. Nous pouvons corriger les erreurs ou les fautes de frappe, par exemple, le fabricant ou la couleur, qui ne se produisent qu'une seule fois dans toutes nos sources, sans tenir compte du fabricant et de la couleur, respectivement. En conséquence, nous avons un grand dictionnaire de fabricants, modèles, articles, couleurs et la catégorisation de jetons possibles n'est qu'une recherche par dictionnaire pour O (1). Théoriquement, vous pouvez avoir une liste ouverte de catégories et une sorte d'algorithme de classification intelligent, mais notre approche de base fonctionne bien et la catégorisation n'est pas un goulot d'étranglement.
Il convient de noter que parfois le fournisseur fournit des données déjà structurées, par exemple, l'article est dans une cellule distincte du tableau, ou le fournisseur fait une remise sur la vente au détail en gros et les prix de détail peuvent être obtenus au format yml (xml). Ensuite, nous enregistrons la structure des données et divisons heuristiquement les jetons en catégories uniquement à partir de données non structurées.
Et maintenant sur quels algorithmes et dans quel ordre nous utilisons.
Correspondances exactes et presque exactes
Le cas le plus simple. Les lignes étaient divisées en jetons, elles les menaient à une seule forme. Ensuite, ils ont proposé une fonction de hachage qui n'est pas sensible à l'ordre des jetons. De plus, en faisant correspondre par hachage, nous pouvons conserver toutes les données en mémoire, nous pouvons nous permettre 16 mégaoctets par dictionnaire avec un million de clés. En pratique, l'algorithme fonctionne mieux que les simples comparaisons de chaînes.
Quant au hachage, l'utilisation de "exclusif ou" se suggère, et une fonction comme celle-ci:
public static long GetLongHashCode(IEnumerable<string> tokens) { long hash = 0; foreach (var token in tokens.Distinct()) { hash ^= GetLongHashCode(token); } return hash; }
La chose la plus intéressante à ce stade est d'obtenir un hachage d'une seule ligne. En pratique, il s'est avéré que 32 bits sont petits, beaucoup de collisions sont obtenues. Et aussi - que vous ne pouvez pas simplement extraire le code source de la fonction du framework et changer le type de la valeur de retour, il y a moins de collisions pour les lignes individuelles, mais après le "exclusif ou" elles se produisent toujours, nous avons donc écrit le nôtre. En fait, ils ont simplement ajouté à la fonction du cadre de non-linéarité des données d'entrée. C'était définitivement mieux, avec la nouvelle fonction avec collision, nous ne nous sommes rencontrés qu'une seule fois sur nos millions d'enregistrements, enregistrés et reportés jusqu'à des temps meilleurs.
Ainsi, nous recherchons des correspondances sans tenir compte de l'ordre des mots et de leur forme. Une telle recherche fonctionne pour O (1).
Malheureusement, rarement, mais cela arrive aussi: «ABC 42 Type 16» et «ABC 16 Type 42», et ce sont deux produits différents. Nous avons également appris à faire face à de telles choses, mais plus à ce sujet plus tard.
Produits humains confirmés assortis
Nous avons des produits qui sont appariés manuellement (le plus souvent, ce sont des produits qui sont appariés automatiquement, mais qui ont été vérifiés manuellement). En fait, nous faisons la même chose dans ce cas, seulement maintenant nous avons ajouté un dictionnaire de hachages correspondants, dont la recherche n'a pas changé la complexité temporelle de l'algorithme.
Les lignes appariées manuellement se trouvent simplement dans la base de données, juste au cas où de telles données brutes vous permettront de modifier l'algorithme de hachage à l'avenir, de tout recalculer et de ne rien perdre.
Mappage d'attributs
Les deux premiers algorithmes sont rapides et précis, mais pas suffisants. Ensuite, nous appliquons la correspondance d'attributs.
Auparavant, nous avions déjà présenté les données sous forme de jetons normalisés et les avions même triés en catégories. Dans ce chapitre, j'appelle des attributs de catégories de jetons.
L'attribut le plus fiable est EAN (https://ru.wikipedia.org/wiki/European_Article_Number). Les correspondances EAN vous garantissent presque 100% qu'il s'agit du même produit. La non-concordance des EAN, cependant, ne dit rien, car un produit peut avoir des EAN différents. Tout irait bien, mais dans nos données l'EAN est rare, donc son influence sur la comparaison au niveau d'erreur.
L'article est moins fiable. Quelque chose d'étrange provient souvent directement des données structurées du fournisseur, mais en tout cas à ce stade, nous l'utilisons.
Comme à la dernière étape, nous utilisons ici des dictionnaires (recherche de O (1)), et le hachage de (fabricant + modèle + article) est utilisé comme clé. Le hachage vous permet d'effectuer toutes les opérations en mémoire. Dans ce cas, nous prenons également en compte la couleur, si elle correspond ou n'existe pas, nous pensons que les marchandises ont coïncidé.
Rechercher la meilleure correspondance
Les étapes précédentes étaient simples, rapides et assez fiables, mais malheureusement elles couvrent moins de la moitié des comparaisons.
Dans la recherche de la meilleure correspondance, il y a une idée simple: la coïncidence des jetons rares a un poids important, la coïncidence des jetons fréquents est petite. Les jetons contenant des nombres ont plus de valeur que les jetons de lettres. Les jetons qui correspondent dans le même ordre sont plus valorisés que les jetons réorganisés. Les matchs longs sont meilleurs que les matchs courts.
Il reste maintenant à proposer une structure de données rapide qui peut prendre tout cela en compte en même temps et s'inscrit dans la mémoire d'un répertoire de quelques millions d'enregistrements.
Nous avons eu l'idée de présenter notre catalogue sous la forme d'un dictionnaire de dictionnaires, au premier niveau, la clé sera un hachage du fabricant (les données du catalogue sont structurées, nous connaissons le fabricant), la valeur est le dictionnaire. Maintenant, le deuxième niveau. La clé au deuxième niveau sera le hachage du jeton, la valeur est la liste des éléments d'identification du catalogue où ce jeton est trouvé. Et dans ce cas, nous utilisons notamment des combinaisons de jetons dans l'ordre dans lequel ils apparaissent dans notre catalogue. Nous décidons quoi utiliser en combinaison, et ce qui ne l'est pas, selon le nombre de jetons, leur longueur, etc., c'est un compromis entre vitesse, précision et mémoire requise. Dans la figure, j'ai simplifié cette structure, sans hachage et sans normalisation.
Si en moyenne 20 jetons sont utilisés pour chaque produit, alors dans nos listes, qui ont les valeurs du dictionnaire ci-joint, un lien vers le produit apparaîtra en moyenne 20 fois. Il n'y aura pas plus de 20 jetons différents que les marchandises du catalogue. Approximativement, vous pouvez calculer la mémoire requise pour un catalogue d'un million d'enregistrements: 20 millions de clés, 4 octets chacun, 20 millions d'identifiant de produit 4 octets chacun, surcharge pour l'organisation des dictionnaires et des listes (l'ordre est le même, mais étant donné la taille des listes et des dictionnaires nous ne savons pas à l'avance, mais augmentez sur la route, multipliez par deux). Total - 480 mégaoctets. En réalité, il s'est avéré un peu plus de jetons pour les marchandises, et nous avons besoin de jusqu'à 800 mégaoctets par catalogue pour un million de marchandises. Ce qui est acceptable, les capacités du fer moderne vous permettent de stocker simultanément en mémoire plus d'une centaine de répertoires de cette taille.
Revenons à l'algorithme. Ayant une chaîne que nous devons faire correspondre, nous pouvons déterminer le fabricant (nous avons un algorithme de catégorisation), puis obtenir des jetons en utilisant le même algorithme que pour les marchandises du catalogue. Ici, je veux dire, y compris les combinaisons de jetons.
Alors tout est relativement simple. Pour chaque jeton, nous pouvons trouver rapidement tous les produits dans lesquels il se trouve, estimer le poids de chaque correspondance, en tenant compte de tout ce dont nous avons parlé plus tôt - longueur, fréquence, présence de chiffres ou de caractères spéciaux, et évaluer la «similitude» de tous les candidats trouvés. En réalité, il y a aussi des optimisations ici, nous ne considérons pas tous les candidats, nous créons d'abord une petite liste de correspondances de jetons avec un poids élevé, et nous n'appliquons pas de correspondances de jetons avec un poids faible à tous les produits, mais uniquement à cette liste.
Nous sélectionnons la meilleure correspondance, examinons la coïncidence des jetons qui se sont avérés être classés et considérons le score de comparaison. De plus, nous avons deux valeurs de seuil P1 et P2, P1 <P2. Si l'évaluation s'est avérée être supérieure à la valeur seuil P2 - la participation humaine n'est pas requise, tout se passe automatiquement. Si entre deux valeurs - nous vous proposons de voir la comparaison manuellement, avant cela, il ne participera pas au prix. Si moins de P1 - très probablement, un tel produit n'est pas dans le catalogue, nous ne retournons rien.
Revenons aux lignes «ABC 42 Type 16» et «ABC 16 Type 42». La solution est étonnamment simple - si plusieurs produits ont les mêmes hachages, nous ne les faisons pas correspondre par hachage. Et le dernier algorithme prendra en compte l'ordre des jetons. Théoriquement, de telles lignes dans la liste de prix du fournisseur ne peuvent pas être mises en correspondance avec quelque chose d’arbitraire, où les nombres 16 et 42 ne se produisent pas du tout. En fait, nous n'avons pas rencontré un tel besoin.
Vitesse et précision
Maintenant, pour la vitesse de tout cela. Le temps nécessaire à la préparation linéaire des dictionnaires dépend de la taille du catalogue. Le temps nécessaire directement à la comparaison dépend linéairement du nombre de marchandises à comparer. Toutes les structures de données impliquées dans la recherche ne sont pas modifiées après la création. Cela nous donne la possibilité d'utiliser le multithreading au stade de l'appariement. Le travail préparatoire pour le catalogue d'un million d'enregistrements prend environ 40 à 80 secondes. La comparaison fonctionne à une vitesse de 20 à 40 000 enregistrements par seconde et ne dépend pas de la taille du répertoire. Ensuite, cependant, vous devez enregistrer les résultats. L'approche choisie est généralement bénéfique pour les gros volumes, mais un fichier avec une dizaine d'enregistrements sera disproportionnellement long. Par conséquent, nous utilisons le cache et recomptons nos structures de recherche toutes les 15 minutes.
Certes, les données de comparaison doivent être lues quelque part (le plus souvent, il s'agit d'un fichier Excel), et les phrases correspondantes doivent être enregistrées quelque part, ce qui prend également du temps. Le nombre total est donc de 2 à 4 000 enregistrements par seconde.
Afin d'évaluer la précision, nous avons préparé une suite de tests d'environ 20 000 comparaisons vérifiées manuellement de différents fournisseurs de différentes catégories. Après chaque modification, l'algorithme a été testé sur ces données. Les résultats sont les suivants:
- les marchandises sont dans le catalogue et ont été comparées correctement - 84%
- le produit est dans le catalogue, mais n'a pas été apparié, l'appariement manuel est requis - 16%
- les marchandises sont dans le catalogue et ont été mal comparées - 0,2%
- le produit n'est pas dans le catalogue et le programme l'a correctement identifié - 98,5%
- le produit n'est pas dans le catalogue, mais le programme l'a associé à l'un des produits - 1,5%
Dans 80% des cas où le produit a été apparié, une confirmation manuelle n'est pas requise (nous confirmons automatiquement la comparaison), parmi ces offres confirmées automatiquement, il y a 0,1% d'erreurs.
Soit dit en passant, 0,1% d'erreurs, c'est beaucoup, il s'avère. Pour un million d'enregistrements appariés, c'est un millier d'enregistrements appariés incorrectement. Et c'est beaucoup parce que les acheteurs trouvent le mieux ces enregistrements. Eh bien, comment ne pas commander un tracteur pour le prix des phares de ce tracteur. Cependant, ce millier d'erreurs est au début des travaux sur un million de propositions, elles ont été progressivement corrigées. La mise en quarantaine des prix suspects, qui clôt ce problème, est apparue plus tard, les premiers mois où nous avons travaillé sans.
Il existe une autre catégorie d'erreurs qui n'est pas liée à la comparaison: ce sont les mauvais prix de nos fournisseurs. C'est en partie pourquoi nous ne prenons pas en compte le prix en comparaison. Nous avons décidé que puisque nous avons des informations supplémentaires sous forme de prix, nous les utiliserons pour essayer de déterminer non seulement nos propres erreurs, mais aussi celles des autres.
Rechercher les mauvais prix
C'est la partie sur laquelle nous expérimentons activement. La version de base est, et elle ne vous permet pas de vendre le téléphone au prix d'un étui, mais j'ai le sentiment que c'est mieux.
Pour chaque produit, nous trouvons les limites des prix fournisseurs acceptables. En fonction des données disponibles, nous prenons en compte les prix des fournisseurs de ce produit, les prix des concurrents, les prix des fournisseurs de biens de ce fabricant dans cette catégorie. Les prix qui ne tombent pas à l'intérieur des frontières sont mis en quarantaine et ignorés dans tous nos algorithmes. Manuellement, vous pouvez marquer un prix aussi suspect comme normal, puis nous nous en souvenons pour ce produit et recomptons les limites des prix acceptables.
L'algorithme direct de calcul des prix maximum et minimum acceptables étant en constante évolution, nous recherchons un compromis entre le nombre de faux positifs et le nombre de prix incorrects détectés.
Nous utilisons des valeurs médianes dans les calculs (les moyennes donnent le pire résultat) et nous n'analysons pas encore la forme de distribution. L'analyse de la forme de distribution est juste l'endroit où, il me semble, l'algorithme peut être amélioré.
Travailler avec la base de données
De tout ce qui précède, nous pouvons conclure que nous mettons à jour les données sur les fournisseurs et les concurrents souvent et de nombreuses manières, et travailler avec la base de données peut devenir un goulot d'étranglement. En principe, nous avons d'abord attiré l'attention sur ce point et essayé d'obtenir des performances maximales. Lorsque vous travaillez avec un grand nombre d'enregistrements, nous procédons comme suit:
- nous supprimons les index de la table avec laquelle nous travaillons
- désactiver l'indexation de texte intégral sur ce tableau
- supprimer tous les enregistrements avec une certaine condition (par exemple, toutes les offres de fournisseurs spécifiques que nous traitons actuellement)
- insérer de nouveaux enregistrements avec BULK COPY
- recréer des index
- activer l'indexation de texte intégral
La copie en bloc fonctionne à une vitesse de 10 à 40 000 enregistrements par seconde, pourquoi une telle propagation reste à voir, mais elle est tellement acceptable.
La suppression d'enregistrements prend environ le même temps que l'insertion. Il faut encore du temps pour recréer les index.
Soit dit en passant, pour chaque répertoire, nous avons une base de données distincte. Nous les créons à la volée. Et maintenant, je vais vous dire pourquoi nous avons plus d'un catalogue.
Quel est le problème du catalogage
Et il y en a aussi beaucoup. Maintenant, nous allons lister:
- Le catalogue contient environ 400 000 produits de catégories complètement différentes. Il est impossible de comprendre professionnellement chacune des catégories.
- Vous devez suivre un certain style, suivre les règles générales pour le nom du catalogue, nommer les sous-catégories, etc. Ainsi, nous essayons de réaliser une structure de répertoires cohérente et logique.
- Vous pouvez créer plusieurs fois le même produit, ce qui pose problème. Sans outil qui analyse des noms similaires, des doublons sont constamment créés.
- Il est raisonnable d'ajouter au catalogue les marchandises que les fournisseurs ont en stock. Dans ce cas, vous devez avoir des priorités pour les catégories de produits.
- Nous avons besoin de plusieurs répertoires. L'un des nôtres, nous le réalisons nous-mêmes, l'autre - le catalogue des agrégateurs, nous le mettons à jour par api. Le sens du deuxième catalogue est que la plate-forme d'agrégation fonctionne uniquement avec son propre catalogue et, par conséquent, accepte les offres dans sa nomenclature. C'est un autre endroit où il s'est avéré que vous aviez besoin d'une comparaison.
Nous avons pensé qu'il était logique et correct de conserver un répertoire au même endroit où les comparaisons sont effectuées. Ainsi, nous pouvons dire aux utilisateurs qui gèrent l'annuaire ce que le fournisseur a, mais pas dans l'annuaire.
Comment tenons-nous un catalogue
Il s'agira du catalogue sans caractéristiques détaillées, les caractéristiques sont une grande histoire distincte, à ce sujet une autre fois.
Comme propriétés de base, nous avons choisi les éléments suivants:
- producteur
- catégorie
- le modèle
- numéro d'article
- couleur
- Ean
Tout d'abord, nous avons créé une API pour obtenir le catalogue à partir d'une source externe, puis nous avons travaillé sur la commodité de créer, modifier et supprimer des enregistrements.
Fonctionnement de la recherche
La commodité de la gestion d'un catalogue, tout d'abord, est la possibilité de trouver rapidement un produit dans un catalogue ou une offre de fournisseur, et il y a des nuances. Par exemple, vous devez pouvoir rechercher la ligne «LG 21.5» 22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P »pour« 2MP48 ».
Une recherche de serveur SQL en texte intégral hors de la boîte ne convient pas, car elle ne sait pas comment le faire, et la recherche avec LIKE '% 2MP48%' est trop lente.
Notre solution est assez standard, nous utilisons des N-grammes. Plus précisément, puis trigrammes. Et déjà par trigrammes, nous construisons un index de texte intégral et effectuons une recherche de texte intégral. Je ne suis pas sûr que nous utilisons l'espace de manière très rationnelle dans ce cas, mais en termes de vitesse, cette solution est apparue, selon la demande, elle fonctionne de 50 à 500 millisecondes, parfois jusqu'à une seconde sur un tableau de trois millions d'enregistrements.
Je m'explique, la ligne «LG 21.5» 22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P »est convertie en la ligne« lg2 g21 215 152 522 22m 2mp mp4 p48 48d 8dp dp1 p16 169 69i 9ip ips psv svg vga gad gad adv dvi vi2 i22 ”, qui est stocké dans un champ séparé qui participe à l'index de texte intégral.
Soit dit en passant, les trigrammes nous sont toujours utiles.
Créer un nouveau produit
Pour la plupart, les produits du catalogue sont créés à la suggestion du fournisseur. Autrement dit, nous avons déjà des informations que le fournisseur propose "LG LCD Monitor 21.5 '' [16: 9] 1920x1080 (FHD) IPS, non GLARE, 250cd / m2, H178 ° / V178 °, 1000: 1, 16.7M Color, 5ms, VGA, DVI, Tilt, 2Y, Black OK 22MP48D-P ”au prix de 120 $, et il a 5 à 10 unités en stock.
Lors de la création d'un produit, tout d'abord, nous devons nous assurer qu'un tel produit n'a pas encore été créé dans le catalogue. Nous résolvons ce problème en quatre étapes.
Premièrement, si nous avons un produit dans le catalogue, il est très probable que la proposition du fournisseur correspondra automatiquement à ce produit.
Deuxièmement, avant de montrer à l'utilisateur le formulaire de création d'un nouveau produit, nous effectuerons une recherche par trigrammes et afficherons les résultats les plus pertinents. (techniquement, cela se fait en utilisant CONTAINSTABLE).
Troisièmement, lorsque nous remplissons les champs d'un nouveau produit, nous afficherons des produits existants similaires. Cela résout deux problèmes: cela permet d'éviter les doublons et de conserver le style dans les noms, des produits similaires peuvent être utilisés comme modèle.
Et quatrièmement, rappelez-vous, nous avons cassé les lignes en jetons, les normalisé, compté les hachages? Nous ferons de même et ne laisserons tout simplement pas créer des marchandises avec les mêmes hachages.
À ce stade, nous essayons d'aider l'utilisateur. Par la ligne qui est dans la liste de prix, nous essaierons de déterminer le fabricant, la catégorie, l'article, l'EAN et la couleur des marchandises. Tout d'abord, par jetons (nous pouvons les diviser en catégories), puis, si cela ne fonctionne pas, nous trouverons le produit le plus similaire par trigrammes. Et, s'il est assez similaire, indiquez le fabricant et la catégorie.
L'édition des produits fonctionne presque de la même manière, mais tout n'est pas applicable.
Comment nous fixons nos prix
La tâche est la suivante: maintenir un équilibre entre la quantité et la marge des ventes, en fait - pour réaliser un profit maximum. Tous les autres aspects du travail du magasin sont également liés à cela, mais ce qui se passe exactement au stade de la tarification a le plus grand impact.
Au minimum, nous aurons besoin d'informations sur les offres des fournisseurs et concurrents. Il convient également de tenir compte des prix de détail et de gros et des frais de livraison minimaux, ainsi que des instruments financiers - prêts et versements.
Nous collectons les prix des concurrents
Pour commencer, nous avons de nombreux profils de nos propres prix. Il existe un profil pour le commerce de détail, il y en a plusieurs pour les clients grossistes. Tous sont créés et configurés dans notre système.
En conséquence, les concurrents pour chaque profil sont différents. Dans le commerce de détail - autres magasins de détail, dans les ventes en gros - nos mêmes fournisseurs.
Tout est clair avec les fournisseurs, mais pour la vente au détail, nous collectons les données des concurrents de plusieurs manières. Premièrement, certains agrégateurs fournissent des informations sur tous les prix de toutes les marchandises présentes sur le site. Dans notre propre nomenclature, mais nous pouvons faire correspondre les produits, donc cela fonctionne automatiquement. Et c'est presque suffisant pour l'instant. Deuxièmement, nous avons des analyseurs concurrents. Puisqu'elles ne sont pas encore automatisées et existent sous forme d'applications console (qui plantent parfois), nous les utilisons rarement.
Personnalisez votre profil
Dans le profil, nous avons la possibilité de configurer différentes gammes de marges en fonction du prix des marchandises du fournisseur, catégorie, fabricant, fournisseur.
Il est toujours possible d'indiquer avec quels fournisseurs dans quelle catégorie ou fabricant nous travaillons, et avec quels - et non, quels concurrents envisageons-nous.Ensuite, nous mettons en place des instruments financiers, indiquons quels versements sont disponibles et combien la banque prendra pour elle-même.Et déjà dans les marges des marges, nous formons nos propres prix, essayant de maintenir le même équilibre en premier lieu et de faire en sorte que nos marchandises d'entrepôt se vendent mieux en deuxième lieu. Il en est ainsi en résumé, mais en fait je ne prétends pas expliquer en termes simples ce qui se passe là-bas.Je peux vous dire ce qui ne se passe pas. Malheureusement, nous ne savons pas encore comment prévoir la demande et prendre en compte le coût de stockage des marchandises dans un entrepôt.Intégration avec des systèmes tiers
Une partie importante d'un point de vue commercial, mais sans intérêt d'un point de vue technique. En résumé, je dirai que nous pouvons envoyer des données à des systèmes tiers (y compris des systèmes incrémentiels, c'est-à-dire que nous comprenons ce qui a changé depuis le dernier échange) et que nous pouvons créer des listes de diffusion.Les newsletters sont personnalisables, donc (et pas seulement) nous livrons nos offres aux clients grossistes.Une autre façon de travailler avec les clients grossistes est le portail b2b. Il est toujours en développement actif, il fonctionnera littéralement dans un mois.Comptes, modification de la journalisation
Une autre question sans intérêt d'un point de vue technique. Chaque utilisateur a un compte.En bref, on peut dire ce qui suit: si ORM est utilisé, alors il a un mécanisme intégré de suivi des modifications. Si vous y entrez (et dans notre cas, c'est EF Core et il y a même une API là-bas), vous pouvez obtenir la journalisation sur près de deux lignes.Pour l'historique des modifications, nous avons créé une interface, et vous pouvez maintenant suivre qui a changé quoi dans les paramètres système, qui a édité ou comparé certains produits, etc.Selon les journaux, des statistiques peuvent être considérées, ce que nous faisons. Nous savons qui a créé ou édité combien de produits, combien de comparaisons ont été confirmées manuellement et combien ont été rejetées, vous pouvez voir chaque changement.Un peu sur la structure générale du système
Nous avons une base de données pour les comptes et les éléments indépendants du catalogue, une base de données pour les journaux et une base de données pour chaque répertoire. Cela facilite les requêtes dans les répertoires et l'analyse des données est plus facile, et le code est plus compréhensible.Soit dit en passant, le système de journalisation est auto-écrit, nous avons vraiment besoin de regrouper les journaux liés à une demande ou à une tâche lourde, en outre, nous avons besoin de fonctionnalités de base pour les analyser. Avec les solutions clé en main, cela s'est avéré difficile, et c'est une autre dépendance qui doit être prise en charge.L'interface Web est réalisée sur ASP.NET Core et bootstrap, et les opérations lourdes sont effectuées par le service Windows.Une autre caractéristique qui a profité au projet, à mon avis, est différents modèles de lecture et d'écriture de données. Nous n'avons pas mis en œuvre le CQRS à part entière, mais nous avons pris l'un des concepts à partir de là. Nous écrivons dans la base de données via les référentiels, mais les objets utilisés pour l'enregistrement ne quittent jamais les méthodes de mise à jour / création / suppression. La mise à jour en masse se fait via BULK COPY. Un modèle et une couche d'accès aux données distincts ont été créés pour la lecture, nous ne lisons donc que ce dont nous avons besoin à un moment particulier. Il s'est avéré que vous pouvez utiliser ORM, et en même temps éviter les requêtes lourdes, l'accès à la base de données à des moments incertains (comme avec le chargement paresseux), les problèmes N + 1. Et nous utilisons également le modèle pour la lecture en tant que DTO.Parmi les principales dépendances, nous avons ASP.NET Core, plusieurs packages de nuget tiers et MS SQL Server. Bien que cela soit possible, nous essayons de ne pas dépendre de nombreux systèmes tiers. Afin de déployer complètement le projet localement, installez simplement SQL Server, récupérez le code source du système de contrôle de version et générez le projet. Les bases de données nécessaires seront créées automatiquement, mais rien d'autre n'est nécessaire. Vous devrez peut-être modifier une ou deux lignes dans la configuration.Ce qui n'a pas
Nous n'avons pas encore réalisé de système de connaissance de projet. Nous voulons faire des wikis et des conseils en place. Ils n'ont pas fait une simple interface intuitive, celle qui n'est pas mauvaise, mais un peu confuse pour une personne non préparée. CI / CD jusqu'à présent uniquement dans les plans.N'a pas traité les caractéristiques détaillées des marchandises. Nous prévoyons également, mais il n'y a pas encore de date limite précise.
Résumé de l'activité
Du début du développement actif jusqu'au lancement en production, deux personnes ont travaillé sur le projet pendant 7 mois. Au début, nous avions fait fabriquer un prototype pendant notre temps libre. L'intégration la plus difficile a été donnée aux systèmes existants.Pendant les trois mois où nous sommes en production, le nombre de marchandises disponibles pour les clients grossistes est passé de 70 000 à 230 000, le nombre de marchandises sur le site - de 60 000 à 140 000. Le site est toujours en retard car il a besoin de fonctionnalités, d'images, de descriptions de produits. Nous déchargeons 106 000 offres sur l'agrégateur au lieu de 40 000 il y a trois mois. Le nombre de personnes travaillant avec le catalogue n'a pas changé.Nous travaillons avec 425 fournisseurs, ce nombre a presque doublé en trois mois. Nous suivons les prix de plus d'un millier de concurrents. Eh bien, pendant que nous le suivons - nous avons un système d'analyse, mais dans la plupart des cas, nous prenons des données toutes faites de ceux qui les fournissent régulièrement.Malheureusement, je ne peux pas vous parler des ventes, je ne dispose pas moi-même de données fiables. La demande est saisonnière et il est impossible de comparer directement le mois au mois précédent. Et en un an, trop de choses se sont passées pour mettre en évidence l'influence de notre système de tous les facteurs. Une croissance du catalogue très, très conditionnelle, plus ou moins un kilomètre, des prix plus flexibles et compétitifs et la croissance des ventes associée ont déjà payé le développement et la mise en œuvre.Autre résultat - nous avons obtenu un projet qui n'est essentiellement pas lié à l'infrastructure d'un magasin particulier, et vous pouvez en faire un service public. Il a été conçu dès le début et ce plan a presque fonctionné. Malheureusement, la solution en boîte a échoué. Pour offrir un projet en tant que service où vous pouvez vous inscrire, cochez la case «J'accepte», et qui fonctionne «tel quel», sans s'adapter au client, vous devez repenser l'interface, ajouter de la flexibilité et créer un wiki. Et pour rendre l'infrastructure facilement évolutive et éliminer un seul point de défaillance. Maintenant, nous n'avons que des sauvegardes régulières pour garantir la fiabilité. En tant que solution d'entreprise, je pense que nous sommes prêts à résoudre les problèmes commerciaux. La petite entreprise est de trouver une entreprise.Soit dit en passant, nous avons déjà attiré un client tiers, disposant des fonctionnalités les plus élémentaires. Les gars avaient besoin d'un outil pour comparer les marchandises, et les inconvénients associés au développement actif ne les effrayaient pas.