A Tcheliabinsk, les réunions des administrateurs système de Sysadminka ont lieu, et au dernier d'entre eux j'ai fait un rapport sur notre solution pour les applications de travail sur 1C-Bitrix à Kubernetes.
Bitrix, Kubernetes, Ceph - un excellent mix?
Je vais vous dire comment nous avons élaboré une solution de travail à partir de tout cela.
C'est parti!

Mitap a eu lieu le 18 avril à Tcheliabinsk. Vous pouvez lire nos mitaps dans Timepad et les regarder sur YouTube .
Si vous souhaitez nous présenter un rapport ou en tant qu'auditeur - à Wellcome, écrivez à vadim.isakanov@gmail.com et Telegram t.me/vadimisakanov.
Mon rapport
Diapositives
Bitrix dans la solution Kubernetes Southbridge 1.0
Je parlerai de notre solution au format "pour les nuls à Kubernetes", comme cela a été fait lors de la réunion. Mais je suppose que les mots Bitrix, Docker, Kubernetes, Ceph vous sont au moins connus au niveau des articles Wikipedia.
Qu'avez-vous à propos de Bitrix dans Kubernetes?
Partout sur Internet, il y a très peu d'informations sur le fonctionnement des applications sur Bitrix dans Kubernetes.
Je n'ai trouvé que de tels matériaux:
Rapport d'Alexander Serbul, 1C-Bitrix et Anton Tuzlukov de Qsoft:
Je recommande de l'écouter.
Développement d'une solution propre de l'utilisateur serkyron sur Habré .
J'ai également trouvé une telle solution .
III ... en fait.
Je vous préviens, nous n'avons pas vérifié la qualité des solutions en utilisant les liens ci-dessus :-)
Au fait, lors de la préparation de notre solution, j'ai parlé avec Alexander Serbul, puis son rapport ne l'était pas encore, donc dans mes diapositives il y a le point «Bitrix n'utilise pas Kubernetes».
Mais il y a déjà beaucoup d'images Docker prêtes à l'emploi pour que Bitrix fonctionne dans Docker: https://hub.docker.com/search?q=bitrix&type=image
Est-ce suffisant pour créer une solution Bitrix complète dans Kubernetes?
Non. Il existe un grand nombre de problèmes qui doivent être résolus.
Quels sont les problèmes avec Bitrix dans Kubernetes?
Premièrement - les images prêtes à l'emploi Dockerhub ne conviennent pas à Kubernetes
Si nous voulons construire une architecture de microservices (et dans Kubernetes, nous voulons généralement), l'application dans Kubernetes doit être divisée en conteneurs et s'assurer que chaque conteneur exécute une petite fonction (et le fait bien). Pourquoi un seul? En bref - le plus simple, le plus fiable.
Si c'est plus authentique, regardez cet article et cette vidéo, s'il vous plaît: https://habr.com/en/company/southbridge/blog/426637/
Les images Docker dans Dockerhub sont principalement construites sur le principe du «tout en un», nous avons donc dû encore fabriquer notre propre vélo et même créer des images à partir de zéro.
Deuxièmement - le code du site est modifié à partir du panneau d'administration
Nous avons créé une nouvelle section sur le site - le code a été mis à jour (un répertoire avec le nom de la nouvelle section a été ajouté).
Modification des propriétés du composant depuis le panneau d'administration - le code a changé.
Kubernetes «par défaut» ne sait pas comment travailler avec cela, les conteneurs doivent être sans état.
Raison: chaque conteneur (sous) du cluster ne traite qu'une partie du trafic. Si vous modifiez le code dans un seul conteneur (en bas), puis dans différents pods, le code sera différent, le site fonctionnera différemment, différentes versions du site seront présentées à différents utilisateurs. Vous ne pouvez pas vivre comme ça.
Troisièmement - vous devez résoudre le problème du déploiement
Si nous avons un monolithe et un serveur «classique», tout est très simple: nous déployons une nouvelle base de code, migrons la base de données, basculons le trafic vers la nouvelle version du code. La commutation se produit instantanément.
Si nous avons un site Web à Kubernetes, il est scié en microservices, il y a beaucoup de conteneurs avec du code. Il est nécessaire de collecter les conteneurs avec la nouvelle version du code, de les déployer à la place des anciens, d'exécuter correctement la migration de la base de données et idéalement de le faire sans que les visiteurs le remarquent. Heureusement, Kubernetes nous aide à cet égard, en prenant en charge tout un nuage de différents types de déploiement.
Quatrièmement - vous devez résoudre le problème du stockage de l'électricité statique
Si votre site ne pèse «que» 10 gigaoctets et que vous le déployez entièrement dans des conteneurs, vous obtiendrez des conteneurs pesant 10 gigaoctets, qui seront déployés pour toujours.
Vous devez stocker les parties les plus «lourdes» du site en dehors des conteneurs, et la question se pose de savoir comment le faire correctement.
Ce qui n'est pas dans notre décision
La quasi-totalité du code Bitrix pour les microfonctions / microservices n'est pas coupée (de sorte que l'enregistrement est séparé, le module de la boutique en ligne est séparé, etc.). Nous stockons la base de code entière dans chaque conteneur dans son ensemble.
Nous ne stockons pas non plus la base dans Kubernetes (j'ai néanmoins implémenté des solutions avec la base dans Kubernetes pour les environnements développeurs, mais pas pour la production).
Les administrateurs du site remarqueront toujours que le site fonctionne dans Kubernetes. La fonction "vérification du système" ne fonctionne pas correctement, pour modifier le code du site à partir du panneau d'administration, vous devez d'abord cliquer sur le bouton "Je souhaite modifier le code".
Nous avons décidé des problèmes, nous avons décidé de la nécessité de mettre en œuvre un microservice, l'objectif est clair - obtenir un système de travail pour travailler sur les applications Bitrix dans Kubernetes, en préservant à la fois les capacités Bitrix et les avantages de Kubernetes. Nous commençons la mise en œuvre.
L'architecture
Beaucoup de foyers «fonctionnants» avec un serveur web (travailleurs).
Un dessous avec des couronnes couronnes (nécessairement un seul).
Une mise à niveau pour éditer le code du site à partir du panneau d'administration (une seule est également requise).
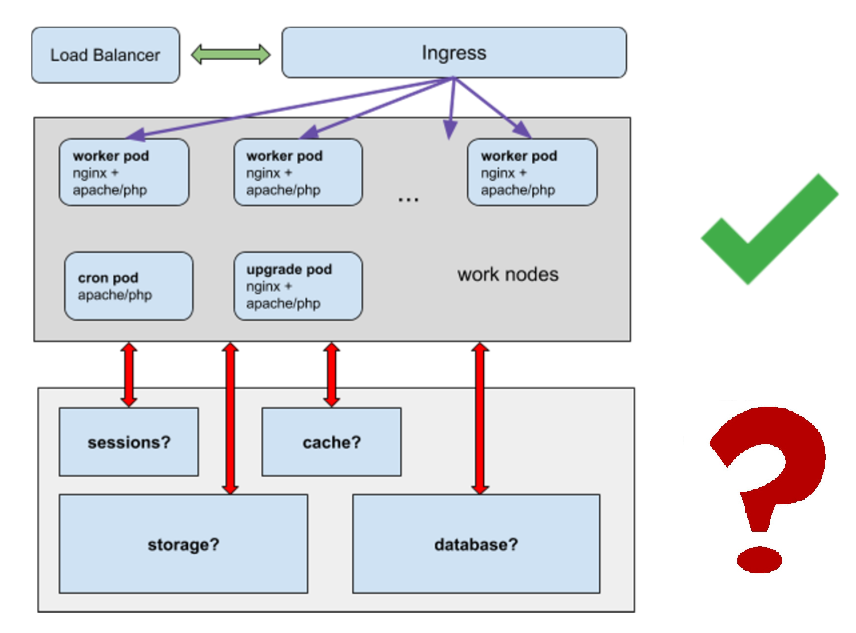
Nous résolvons les problèmes:
- Où stocker les sessions?
- Où stocker le cache?
- Où stocker la statique, pas pour placer des gigaoctets de statique dans un tas de conteneurs?
- Comment fonctionnera la base de données?
Image Docker
Nous commençons par construire une image Docker.
L'option idéale est que nous ayons une image universelle, sur sa base, nous obtenons à la fois des modules de travail et des modules avec des supports et des modules de mise à niveau.
Nous avons fait une telle image .
Il comprend nginx, apache / php-fpm (peut être sélectionné lors de l'assemblage), msmtp pour l'envoi de courrier et cron.
Lors de l'assemblage de l'image, la base de code complète du site est copiée dans le répertoire / app (à l'exception des parties que nous placerons dans un stockage partagé séparé).
Microservice, services
foyers ouvriers:
- Conteneur avec nginx + apache / php-fpm + conteneur msmtp
- msmtp n'a pas fonctionné dans un microservice séparé, Bitrix commence à ressentir qu'il ne peut pas envoyer de courrier directement
- Chaque conteneur a une base de code complète.
- Interdiction de changer le code dans les conteneurs.
cron sous:
- récipient avec apache, php, cron
- base de code complète incluse
- interdiction de changer le code dans les conteneurs
mise à niveau sous:
- conteneur avec nginx + apache / php-fpm + msmtp conteneur
- il n'y a pas d'interdiction de changer le code dans les conteneurs
stockage de session
Stockage de cache Bitrix
Plus important: nous stockons des mots de passe pour nous connecter à tout, de la base de données au courrier électronique en secrets kubernetes. Nous obtenons un bonus, les mots de passe ne sont visibles que par ceux à qui nous donnons accès aux secrets, et pas à tous ceux qui ont accès à la base de code du projet.
Stockage statique
Vous pouvez utiliser n'importe quoi: ceph, nfs (mais les nfs ne sont pas recommandés pour la production), le stockage réseau des fournisseurs "cloud", etc.
Le stockage devra être connecté dans des conteneurs au répertoire / upload / du site et aux autres répertoires statiques.
Base de données
Pour plus de simplicité, nous vous recommandons de déplacer la base en dehors de Kubernetes. La base de Kubernetes est une tâche complexe distincte, cela rendra le circuit beaucoup plus compliqué.
Stockage de session
Nous utilisons memcached :)
Il fait un bon travail de stockage des sessions, des clusters et est nativement pris en charge en tant que session.save_path dans php. Un tel système a été élaboré à plusieurs reprises dans l'architecture monolithique classique, lorsque nous avons construit des clusters avec un grand nombre de serveurs Web. Pour le déploiement, nous utilisons Helm.
$ helm install stable/memcached --name session
php.ini - ici dans les paramètres d'image sont définis pour le stockage des sessions dans memcached
Nous avons utilisé des variables d'environnement pour transférer les données de l'hôte avec https://kubernetes.io/docs/tasks/inject-data-application/define-environment-variable-container/ memcached.
Cela vous permet d'utiliser le même code dans les environnements dev, stage, test, prod (les noms d'hôte de memcached y seront différents, nous devons donc transférer un nom d'hôte unique pour les sessions dans chaque environnement).
Stockage de cache Bitrix
Nous avons besoin d'un stockage à sécurité intégrée dans lequel tous les foyers pourraient écrire et à partir duquel nous pourrions lire.
Nous utilisons également memcached.
Cette solution est recommandée par Bitrix lui-même.
$ helm install stable/memcached --name cache
bitrix / .settings_extra.php - ici dans Bitrix, il est défini où nous stockons le cache
Nous utilisons également des variables d'environnement.
Krontaski
Il existe différentes approches pour faire des crontabs dans Kubernetes.
- déploiement séparé avec un foyer
- cronjob pour effectuer crontask (si c'est une application web - avec wget https: // $ host $ cronjobname , ou kubectl exec à l'intérieur de l'un des foyers de travail, etc.)
- etc.
Vous pouvez discuter sur le plus correct, mais dans ce cas, nous avons choisi l'option "déploiement séparé avec des pods pour crontask"
Comment faire:
- ajouter des couronnes via ConfigMap ou via config / addcron
- dans un cas, exécutez un conteneur identique au sous-travailleur + autorisez l'exécution des tâches de couronne dans celui-ci
- la même base de code est utilisée, grâce à l'unification, l'assemblage du conteneur est simple
Quel bien nous obtenons:
- nous travaillons crontaski dans un environnement identique à l'environnement de développement (docker)
- Krontaski n'a pas besoin d'être "réécrit" pour Kubernetes, ils fonctionnent sous la même forme et dans la même base de code qu'auparavant
- les membres de la couronne peuvent ajouter tous les membres de l'équipe disposant de droits de validation à la branche de production, et pas seulement les administrateurs
Module Southbridge K8SDeploy et modification du code à partir du panneau d'administration
Nous parlions de mise à niveau sous?
Et comment y diriger le trafic?
Hourra, nous avons écrit un module pour cela en php :) C'est un petit module classique pour Bitrix. Il n'est pas encore accessible au public, mais nous prévoyons de l'ouvrir.
Le module est installé en tant que module standard dans Bitrix:

Et cela ressemble à ceci:
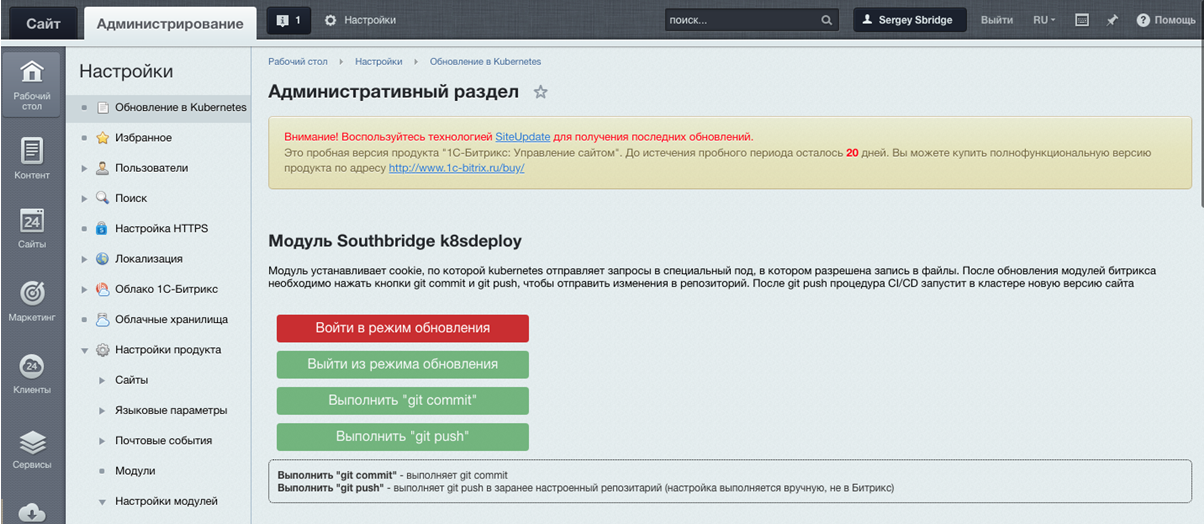
Il vous permet de définir un cookie qui identifie l'administrateur du site et permet à Kubernetes d'envoyer du trafic vers la mise à niveau sous.
Une fois les modifications terminées, vous devez appuyer sur git push, les modifications de code seront envoyées à git, puis le système collectera l'image avec la nouvelle version du code et la «roulera» à travers le cluster, en remplaçant les anciens pods.
Oui, c'est un peu une béquille, mais en même temps, nous maintenons l'architecture de microservice et ne privons pas les utilisateurs Bitrix de l'occasion préférée de corriger le code à partir du panneau d'administration. En fin de compte, c'est une option, vous pouvez résoudre le problème de l'édition de code d'une manière différente.
Tableau de barre
Pour créer des applications dans Kubernetes, nous utilisons généralement le gestionnaire de packages Helm.
Pour notre solution Bitrix chez Kubernetes, Sergey Bondarev, notre administrateur système principal, a écrit un graphique spécial Helm.
Il construit des foyers ouvriers, ugrade, cron, configure les entrées, les services, transfère les variables des secrets Kubernetes aux foyers.
Nous stockons le code dans Gitlab et nous exécutons également l'assembly Helm à partir de Gitlab.
Bref, ça ressemble à ça
$ helm upgrade --install project .helm --set image=registrygitlab.local/k8s/bitrix -f .helm/values.yaml --wait --timeout 300 --debug --tiller-namespace=production
Helm vous permet également d'effectuer une restauration «transparente» en cas de problème pendant le déploiement. C'est bien quand vous n'êtes pas dans une panique "corrigez le code pour ftp, car le prod est tombé", et Kubernetes le fait automatiquement, et sans temps d'arrêt.
Déployer
Oui, nous sommes fans de Gitlab & Gitlab CI, utilisez-le :)
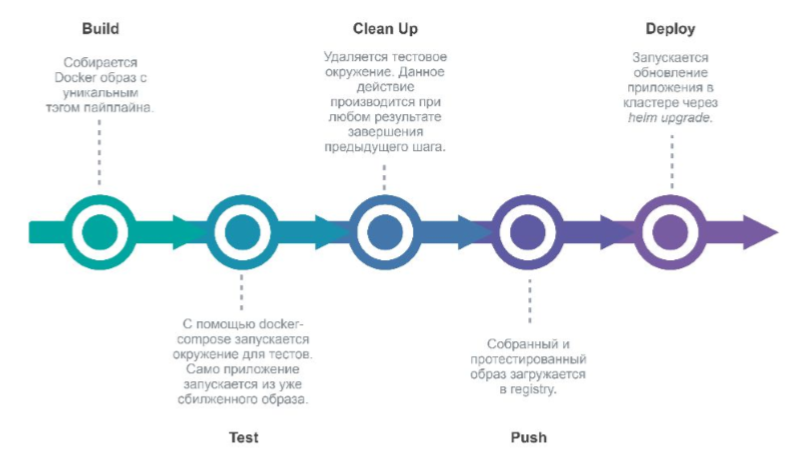
Lors de la validation de Gitlab dans le référentiel de projet, Gitlab lance un pipeline qui déploiera la nouvelle version de l'environnement.
Étapes:
- build (construire une nouvelle image Docker)
- test (test)
- nettoyer (supprimer l'environnement de test)
- pousser (l'envoyer au registre Docker)
- deploy (nous déployons l'application dans Kubernetes via Helm).
Hourra, nous sommes prêts à le présenter!
Eh bien, ou posez des questions, le cas échéant.
Alors qu'avons-nous fait
D'un point de vue technique:
- Bitrix dockerized;
- «Coupez» Bitrix en conteneurs, chacun remplissant un minimum de fonctions;
- état apatride des conteneurs;
- résolu le problème de la mise à jour de Bitrix dans Kubernetes;
- toutes les fonctions Bitrix ont continué de fonctionner (presque toutes);
- déploiement travaillé dans Kubernetes et restauration entre les versions.
D'un point de vue commercial:
- tolérance aux pannes;
- Outils Kubernetes (intégration facile avec Gitlab CI, déploiement transparent, etc.);
- les mots de passe dans les secrets (visibles uniquement à ceux qui ont directement accès aux mots de passe);
- il est pratique de créer des environnements supplémentaires (pour le développement, les tests, etc.) au sein d'une même infrastructure.