Beaucoup de ceux qui ont travaillé avec Spark ML savent que certaines des choses qu'ils ont faites là-bas "ne sont pas entièrement réussies".
ou pas du tout fait. La position des développeurs Spark est que SparkML est la plate-forme de base, et toutes les extensions doivent être des packages séparés. Mais ce n'est pas toujours pratique, car le Data Scientist et les analystes veulent travailler avec des outils familiers (Jupter, Zeppelin), où il y a la plupart de ce qui est nécessaire. Ils ne veulent pas collecter des fichiers JAR de 500 mégaoctets avec maven-assembly ou télécharger des dépendances entre leurs mains et les ajouter aux paramètres de démarrage de Spark. Un travail plus fin avec les systèmes de construction de projets JVM peut nécessiter beaucoup d'efforts supplémentaires de la part des analystes et des DataScientists habitués à Jupyter / Zeppelin. Demander à DevOps et aux administrateurs de cluster de mettre un paquet de packages sur les nœuds de calcul est clairement une mauvaise idée. Quiconque a écrit des extensions pour SparkML par lui-même sait combien de difficultés cachées il y a avec les classes et méthodes importantes (qui pour une raison quelconque sont privées [ml]), les restrictions sur les types de paramètres stockés, etc.
Et il semble que maintenant, avec la bibliothèque MMLSpark, la vie sera un peu plus facile, et le seuil pour entrer dans le machine learning évolutif avec SparkML et Scala est légèrement plus bas.
Présentation
En raison d'un certain nombre de difficultés, ainsi que d'un ensemble clairsemé de méthodes et de solutions prêtes à l'emploi dans SparkML, de nombreuses entreprises écrivent leurs extensions pour Spark. Un exemple est PravdaML , qui est en cours de développement à Odnoklassniki et qui, à en juger par une évaluation rapide de ce qui se trouve sur GitHub, semble très prometteur. Malheureusement, la plupart de ces solutions sont généralement fermées ou ouvertes, mais n'ont pas la possibilité d'installer via Maven / sbt et la documentation de l'API, ce qui rend très difficile de travailler avec elles.
Aujourd'hui, nous regardons la bibliothèque MMLSpark .
Nous considérerons, comme d'habitude, l'exemple de la tâche de classement des passagers du Titanic. Le but est de montrer autant de fonctionnalités de la bibliothèque MMLSpark que possible, pas assommer SOTA sur ImageNet montrer un apprentissage machine cool. Alors le Titanic fera l'affaire.

La bibliothèque elle-même possède une API native pour Scala ( documentation ), Python API ( documentation ) et, à en juger par certains endroits du référentiel GitHub, elle aura bientôt une API pour R.
Il existe de bons exemples d'ordinateurs portables dans le projet GitHub (PySpark + Jupyter) , mais nous irons dans l'autre sens. Comme l'écrivait Dmitry Bugaychenko, si vous développez pour Spark, c'est-à-dire que vous avez toutes les raisons d'utiliser Scala pour cela, de plus, Scala vous permet de définir de manière beaucoup plus efficace et plus flexible vos propres Transformer et Estimator pour les incorporer dans SparkML Pipeline, mais la lenteur avec laquelle Numpy fonctionne Le code / pandas en UDF (appelé sur les exécutables de la JVM) a déjà été beaucoup écrit.
Dossier d'installation
L'ordinateur portable entier est disponible ici . Pour fonctionner avec le Titanic, l'image Zeppelin Docker s'exécutant localement sur un ordinateur portable avec des paramètres par défaut est suffisante pour les yeux. Docker peut être trouvé ici . La bibliothèque MMLSpark n'est pas dans Maven Central, mais dans des spark-packages, et pour l'ajouter à Zeppelin, vous devez exécuter le bloc suivant au début de l'ordinateur portable:
%spark.dep z.addRepo("bintray.com").url("http://dl.bintray.com/spark-packages/maven/") z.load("Azure:mmlspark:0.17")
Il vaut la peine de dire que la bibliothèque a une excellente compatibilité descendante: contrairement, par exemple, au XGBoost4j-spark, qui nécessite un minimum de Spark 2.3+, cette chose est entrée dans Spark 2.2.1, fourni avec l'image Zeppelin Docker, et toutes les difficultés Je ne l'ai pas remarqué.
Remarque: la plupart de la bibliothèque MMLSpark est dédiée à l'inférence de grilles sur le cluster, pour lesquelles CNTK est présent (qui, à en juger par la documentation, devrait lire des modèles cntk prêts à l'emploi) et un énorme bloc OpenCV. Nous allons nous concentrer sur des tâches plus banales et essayer de «simuler» le cas lorsque nous avons d'énormes tableaux de données tabulaires qui se trouvent dans HDFS sous la forme de .csv, de tableaux ou dans un autre format. Nous devons donc les pré-traiter et construire un modèle, alors que ces données ne rentrent pas dans la mémoire d'une machine. Par conséquent, nous effectuerons toutes les actions sur le cluster.
Lecture et analyse de l'intelligence
En général, Spark + Zeppelin n'est pas mal du tout et peut faire face à la tâche EDA, mais nous allons essayer d'étendre leurs capacités. Tout d'abord, nous importons les classes dont nous avons besoin:
- Tout de spark.sql.types pour déclarer un schéma et lire les données correctement
- Tout depuis spark.sql.functions pour accéder aux colonnes et utiliser les fonctions intégrées
- com.microsoft.ml.spark.SummarizeData , qui peut être appelé un analogue de pandas.DataFrame.describe
import com.microsoft.ml.spark.SummarizeData import org.apache.spark.sql.functions._ import org.apache.spark.sql.types._
Nous lisons notre dossier:
val titanicSchema = StructType( StructField("Passanger", ShortType) :: StructField("Survived", ShortType) :: StructField("PClass", ShortType) :: StructField("Name", StringType) :: StructField("Sex", StringType) :: StructField("Age", ShortType) :: StructField("SibSp", ShortType) :: StructField("Parch", ShortType) :: StructField("Ticket", StringType) :: StructField("Fare", FloatType) :: StructField("Cabin", StringType) :: StructField("Embarked", StringType) :: Nil ) val train = spark .read .schema(titanicSchema) .option("header", true) .csv("/mountV/titanic/train.csv")
Et maintenant, regardons les données elles-mêmes, ainsi que leur taille:
println(s"Train shape is: ${train.count} x ${train.columns.length}") train.limit(5).createOrReplaceTempView("trainHead")
Remarque: Il n'est vraiment pas nécessaire d'utiliser createOrReplaceTempView lorsque vous pouvez simplement écrire .show (5). Mais show a un problème: lorsque les données sont "larges", alors la représentation textuelle de la plaque "flotte", et rien ne devient clair du tout.
Obtenez la taille de nos données: La Train shape is: 891 x 12
Et maintenant, dans la cellule sql, nous pouvons regarder les 5 premières lignes:
%sql select * from trainHead
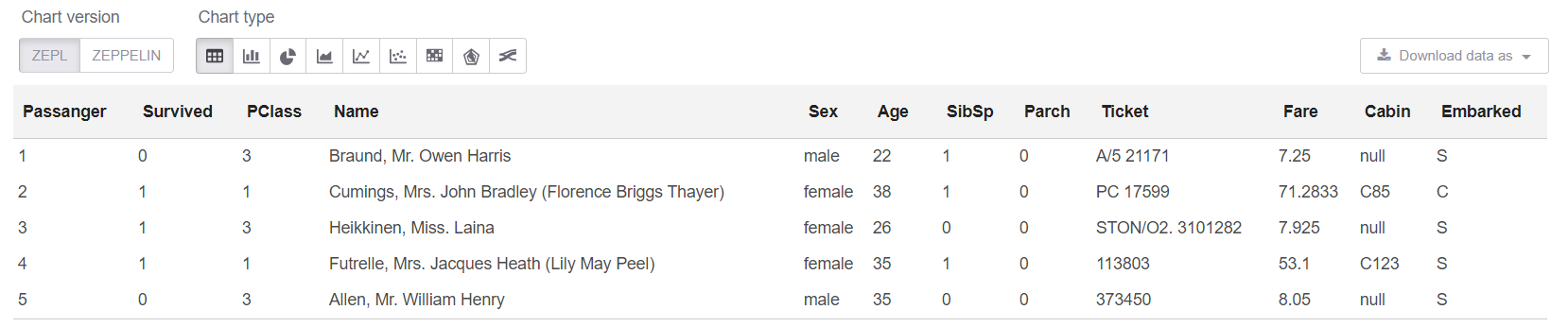
Eh bien, voyons le résumé sur notre table:
new SummarizeData() .setBasic(true) .setCounts(true) .setPercentiles(false) .setSample(true) .setErrorThreshold(0.25) .transform(train) .createOrReplaceTempView("summary")
La classe SummarizeData présente plusieurs avantages par rapport au simple Dataset.describe, car elle vous permet de compter le nombre de valeurs manquantes et uniques, et vous permet également de spécifier la précision du calcul des quantiles. Cela peut être critique pour les très gros volumes de données.

Quelques réflexions personnellesEn général, il me semblait personnellement que Odnoklassniki dans PravdaML avait une meilleure implémentation de l'analogue SummarizeData. Microsoft a opté pour la simplicité et utilise org.apache.spark.sql.functions , c'est juste que tout est commodément emballé dans une seule classe. Pour Odnoklassniki, cela est implémenté via leur VectorStatCollector , qui nécessite un code un peu plus complexe lors de l'appel (vous devez d'abord ajouter toutes les fonctionnalités à un vecteur) et peut nécessiter des opérations supplémentaires (par exemple, VectorAssembler refuse généralement de digérer DecimalType ). Mais j'ai une hypothèse basée sur mon expérience avec Spark que SummarizeData de MMLSpark pourrait planter avec des erreurs comme StackOverflow dans org.apache.spark.sql.catalyst s'il y a vraiment beaucoup de colonnes, et le graphique de calcul n'est pas petit au moment où il démarre ( bien que spécialement pour ces fans de "l'extrême" dans Spark 2.4, ils ont ajouté la possibilité de réduire l'optimiseur de graphique Catalyst ). Eh bien, il semble qu'avec un très grand nombre de colonnes, la version de Microsoft sera plus lente. Mais cela, bien sûr, doit être vérifié séparément.
Nettoyage des données
Dans le Titanic, tout est comme d'habitude - un tas de colonnes de chaînes ont des valeurs manquantes. Et une sorte de dévers dans les données (il semble que cette version particulière des données ne soit pas très spécifique) - 25 lignes à partir des valeurs manquantes. Tout d'abord, corrigez ceci:
val trainFiltered = train.filter(!(isnan(col("Survived")) || isnull(col("Survived"))))
Traitement des données de chaîne
Pour autant que je m'en souvienne, les attributs sortis des champs Name et Cabin étaient les meilleurs apportés dans le Titanic. Vous pouvez en fournir beaucoup, mais nous nous limiterons à quelques-uns, juste pour ne pas donner d'exemples de presque le même code.
Habituellement, il est pratique d'utiliser des expressions régulières pour de telles choses.
Mais nous voulons dans ce cas:
- tout a été distribué, les données ont été traitées au même endroit;
- tout a été conçu en tant que classes SpakrML Transformer ou Spark ML Estimator, afin que plus tard, il puisse être assemblé dans Pipeline.
Remarque: Pipeline, tout d'abord, nous garantit que nous appliquons toujours les mêmes transformations au train et au test, et nous permet également de détecter l'erreur de «regarder vers l'avenir» dans la validation croisée. Et cela nous donne également des capacités simples pour enregistrer, charger et prévoir à l'aide de notre pipeline.
SparkML a une classe «presque universelle» pour de telles tâches - SQLTranformer , mais l'écriture en SQL est clairement pire que l'écriture en Scala, ne serait-ce que parce qu'il est possible d'attraper la syntaxe ou des erreurs typiques lors de la compilation et de la coloration syntaxique dans Idea. Et ici MMLSpark vient à notre aide, où un UDFTransformer vraiment universel est implémenté :
import com.microsoft.ml.spark.UDFTransformer
Pour commencer, nous allons créer notre fonction de transformation, qui est très simple à la limite, mais notre objectif est maintenant de montrer le processus de création de UDFTransformer. En principe, sur la base d'exemples aussi simples, n'importe qui peut ajouter de la logique à n'importe quel niveau de complexité.
val miss = ".*miss\\..*".r val mr = ".*mr\\..*".r val mrs = ".*mrs\\..*".r val master = ".*master.*".r def convertNames(input: String): Option[String] = { Option(input).map(x => { x.toLowerCase match { case miss() => "Miss" case mr() => "Mr" case mrs() => "Mrs" case master() => "Master" case _ => "Unknown" } }) }
(Vous pouvez immédiatement voir à quel point Scala est pratique pour travailler avec des valeurs manquantes qui, soit dit en passant, sont non seulement null , mais aussi Double.NaN , mais il y a une telle blague une chose aussi rare que les omissions dans les variables BooleanType , etc.)
UserDefinedFunction maintenant notre UserDefinedFunction et créez immédiatement un Transformer basé sur lui:
val nameTransformUDF = udf(convertNames _) val nameTransformer = new UDFTransformer() .setUDF(nameTransformUDF) .setInputCol("Name") .setOutputCol("NameType")
Remarque: Dans un ordinateur portable Zeppelin, c'est toujours la même chose, mais quand tout est réuni plus tard dans le code de production, il est important que tous les UDF soient dans des classes ou des objets qui sont extends Serializable . La chose évidente que vous pouvez parfois oublier puis vous plonger pendant longtemps est ce qui ne va pas avec la lecture des longues traces de pile des erreurs Spark.
Maintenant, nous avons encore le champ Cabin . Examinons-le de plus près:

On voit qu'il y a beaucoup de valeurs manquantes, il y a des lettres, des chiffres, différentes combinaisons, etc. Prenons le nombre de cabines (s'il y en a plusieurs), ainsi que les nombres - ils ont probablement une sorte de logique, par exemple, si la numérotation se fait à une extrémité du navire, alors les cabines à l'avant avaient moins de chance. Nous allons également créer des fonctions, puis en nous basant sur UDFTransformer :
def getCabinsCount(input: String): Int = { Option(input) match { case Some(x) => x.split(" ").length case None => -1 } } val numPattern = "([az])([0-9]+)".r def getNumbersFromCabin(input: String): Int = { Option(input) match { case Some(x) => { x.split(" ")(0).toLowerCase match { case numPattern(sym, num) => Integer.parseInt(num) case _ => -1 } } case None => -2 } } val cabinsCountUDF = udf(getCabinsCount _) val numbersFromCabinUDF = udf(getNumbersFromCabin _) val cabinsCountTransformer = new UDFTransformer() .setInputCol("Cabin") .setOutputCol("CabinCount") .setUDF(cabinsCountUDF) val numbersFromCabinTransformer = new UDFTransformer() .setInputCol("Cabin") .setOutputCol("CabinNumber") .setUDF(numbersFromCabinUDF)
Commençons maintenant par les valeurs manquantes, à savoir l'âge. Tout d'abord, profitons des capacités de visualisation de Zeppelin:
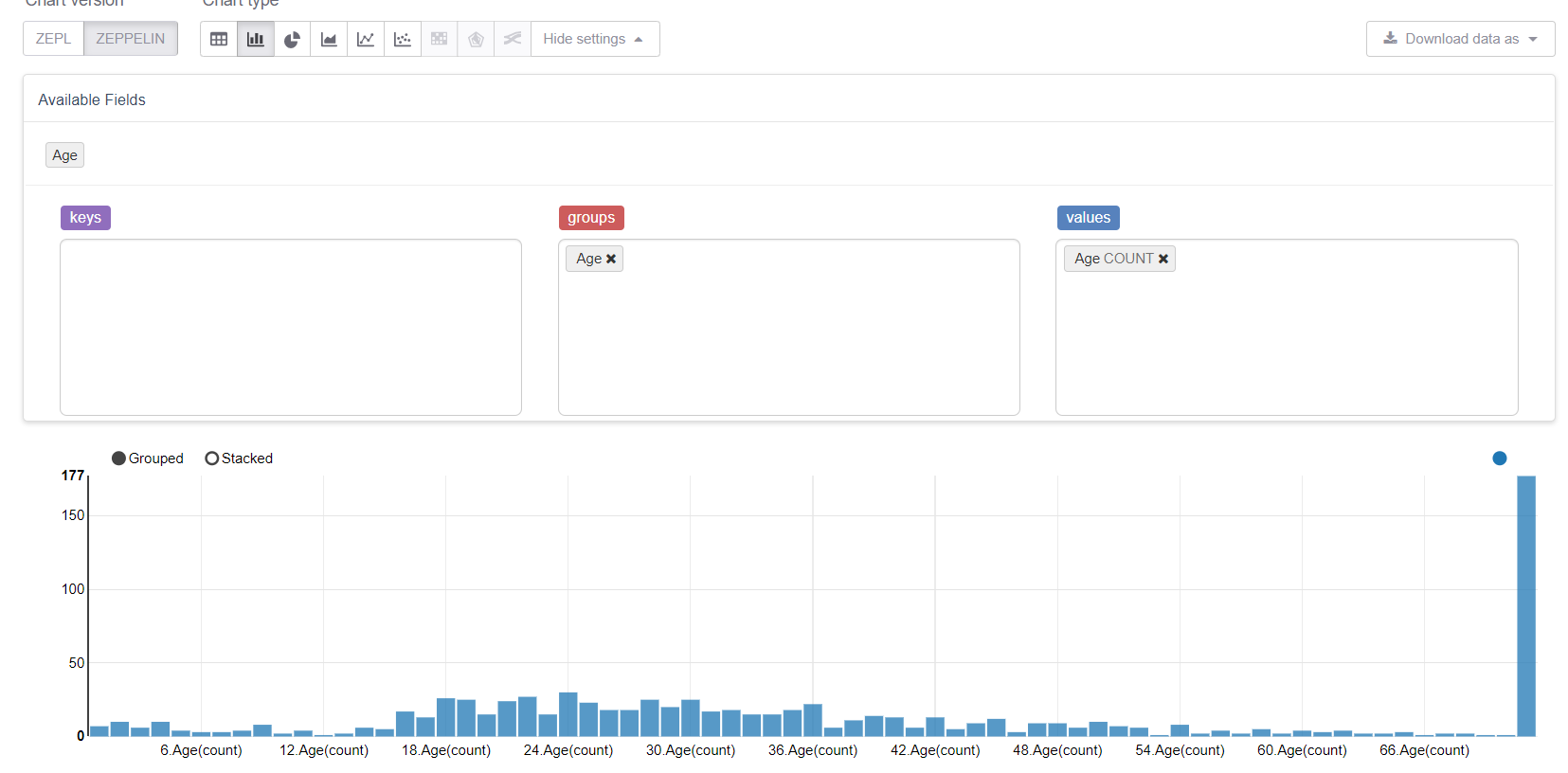
Et voyez comment les valeurs manquantes gâchent tout. Il serait logique de les remplacer par un milieu (ou médiane), mais notre objectif est de considérer toutes les fonctionnalités de la bibliothèque MMLSpark. Par conséquent, nous écrirons notre propre Estimator , qui considérera les groupes / moyennes sur l'échantillon de formation et les remplacera par les lacunes correspondantes.
Nous aurons besoin de:
import org.apache.spark.sql.{Dataset, DataFrame} import org.apache.spark.ml.{Estimator, Model} import org.apache.spark.ml.param.{Param, ParamMap} import org.apache.spark.ml.util.Identifiable import org.apache.spark.ml.util.DefaultParamsWritable import com.microsoft.ml.spark.{HasInputCol, HasOutputCol} import com.microsoft.ml.spark.ConstructorWritable import com.microsoft.ml.spark.ConstructorReadable import com.microsoft.ml.spark.Wrappable
Prenons attention à ConstructorWritable , qui simplifie considérablement la vie. Si notre Model est un modèle «entraîné» renvoyé par la méthode fit(), , qui est entièrement déterminé par son constructeur (et c'est probablement 99% des cas), alors nous ne pouvons pas du tout écrire la sérialisation avec nos mains. Cela simplifie et accélère considérablement le développement, élimine les erreurs et abaisse également le seuil d'entrée pour DataScientist et les analystes qui ne sont généralement pas des programmeurs professionnels.
Définissez notre classe Estimator . En fait, la chose la plus importante ici est la méthode d' fit , les autres sont des points techniques:
class GroupImputerEstimator(override val uid: String) extends Estimator[GroupImputerModel] with HasInputCol with HasOutputCol with Wrappable with DefaultParamsWritable { def this() = this(Identifiable.randomUID("GroupImputer")) val groupCol: Param[String] = new Param[String]( this, "groupCol", "Groupping column" ) def setGroupCol(v: String): this.type = super.set(groupCol, v) def getGroupCol: String = $(groupCol) override def fit(dataset: Dataset[_]): GroupImputerModel = { val meanDF = dataset .toDF .groupBy($(groupCol)) .agg(mean(col($(inputCol))).alias("groupMean")) .select(col($(groupCol)), col("groupMean")) new GroupImputerModel( uid, meanDF, getInputCol, getOutputCol, getGroupCol ) } override def transformSchema(schema: StructType): StructType = schema .add( StructField( $(outputCol), schema.filter(x => x.name == $(inputCol))(0).dataType ) ) override def copy(extra: ParamMap): Estimator[GroupImputerModel] = { val to = new GroupImputerEstimator(this.uid) copyValues(to, extra).asInstanceOf[GroupImputerEstimator] } }
Remarque: Je n'ai pas utilisé defaultCopy, car lorsque j'ai appelé, pour une raison quelconque, il a juré que je n'avais pas de constructeur. \ <init> (java.lang.String), bien qu'il semble que cela n'aurait pas dû se produire. Dans tous les cas, l'implémentation de la copy facile.
Vous devez maintenant implémenter Model - une classe qui décrit le modèle entraîné et implémente la méthode de transform . Nous allons le construire sur la base de la fonction coalesce intégrée dans org.apache.spark.sql.functions :
class GroupImputerModel( val uid: String, val meanDF: DataFrame, val inputCol: String, val outputCol: String, val groupCol: String ) extends Model[GroupImputerModel] with ConstructorWritable[GroupImputerModel] { val ttag: TypeTag[GroupImputerModel] = typeTag[GroupImputerModel] def objectsToSave: List[Any] = List(uid, meanDF, inputCol, outputCol, groupCol) override def copy(extra: ParamMap): GroupImputerModel = new GroupImputerModel(uid, meanDF, inputCol, outputCol, groupCol) override def transform(dataset: Dataset[_]): DataFrame = { dataset .toDF .join(meanDF, Seq(groupCol), "left") .withColumn( outputCol, coalesce(col(inputCol), col("groupMean")) .cast(IntegerType)) .drop("groupMean") } override def transformSchema (schema: StructType): StructType = schema .add( StructField(outputCol, schema.filter(x => x.name == inputCol)(0).dataType) ) }
Le dernier objet que nous devons déclarer est un Reader , que nous implémentons à l'aide de la classe MMLSpark ConstructorReadable :
object GroupImputerModel extends ConstructorReadable[GroupImputerModel]
Création de pipeline
Dans Pipeline, je voudrais montrer à la fois les classes SparkML habituelles et la chose incroyablement pratique de MMLSpark - MultiColumnAdapter , qui vous permet d'appliquer des transformateurs SparkML à plusieurs colonnes à la fois (pour référence, par exemple, StringIndexer et OneHotEncoder prennent exactement une colonne à l'entrée, ce qui les transforme annonce dans la douleur):
import org.apache.spark.ml.feature.{StringIndexer, VectorAssembler} import org.apache.spark.ml.Pipeline import com.microsoft.ml.spark.{MultiColumnAdapter, LightGBMClassifier}
Tout d'abord, nous allons déclarer quelles colonnes nous avons:
val catCols = Array("Sex", "Embarked", "NameType") val numCols = Array("PClass", "AgeNoMissings", "SibSp", "Parch", "CabinCount", "CabinNumber")
Créez maintenant un encodeur de chaînes:
val stringEncoder = new MultiColumnAdapter() .setBaseStage(new StringIndexer().setHandleInvalid("keep")) .setInputCols(catCols) .setOutputCols(catCols.map(x => x + "_freqEncoded"))
Remarque: contrairement à scikit-learn dans SparkML, StringIndexer fonctionne sur le principe de l'encodeur de fréquence, et il peut être utilisé pour spécifier une relation d'ordre (c'est-à-dire catégorie 0 <catégorie 1, et cela a du sens) - cette approche fonctionne souvent bien pour arbres décisifs.
Imputer notre Imputer :
val missingImputer = new GroupImputerEstimator() .setInputCol("Age") .setOutputCol("AgeNoMissings") .setGroupCol("Sex")
Et VectorAssembler , puisque les classificateurs SparkML sont plus à l'aise de travailler avec VectorType :
val assembler = new VectorAssembler() .setInputCols(stringEncoder.getOutputCols ++ numCols) .setOutputCol("features")
Nous allons maintenant utiliser le boost de gradient fourni avec MMLSpark - LightGBM, qui est inclus dans le "Big Three" des meilleures implémentations de cet algorithme avec XGBoost et CatBoost. Il fonctionne beaucoup plus rapidement, mieux et plus stable que l'implémentation GBM de SparkML (même en tenant compte du fait que le port JVM est toujours en développement actif):
val catColIndices = Array(0, 1, 2) val lgbClf = new LightGBMClassifier() .setFeaturesCol("features") .setLabelCol("Survived") .setProbabilityCol("predictedProb") .setPredictionCol("predictedLabel") .setRawPredictionCol("rawPrediction") .setIsUnbalance(true) .setCategoricalSlotIndexes(catColIndices) .setObjective("binary")
Remarque: LightGBM prend en charge le travail avec des variables catégorielles (presque comme catboost), nous lui avons donc indiqué à l'avance où se trouvent les attributs de catégorie dans notre vecteur, et lui-même saura quoi faire avec eux et comment les coder.
En savoir plus sur les fonctionnalités LightGBM pour Spark- Sur les nœuds exécutant RadHat LightGBM, toute version, à l'exception de la toute dernière, plantera du fait qu'il n'aime pas la version
glibc . Cela a été résolu récemment , cependant, lors de l'installation via Maven, MMLSpark extrait l'avant-dernière version de LightGBM lors de l'installation via Maven, vous devez donc ajouter la dépendance de la dernière version sur RadHat avec vos mains. - LightGBM dans son travail crée une socket sur le pilote pour la communication avec les dirigeants, et il le fait en utilisant le
new java.net.ServerSocket(0) , et donc un port aléatoire des ports éphémères du système d'exploitation est utilisé. Si la plage de ports éphémères diffère de la plage de ports ouverts par le pare-feu, alors peut brûler beaucoup Vous pouvez obtenir un effet intéressant lorsque LightGBM fonctionne parfois (lorsque j'ai choisi un bon port), et parfois non. Et il y aura des erreurs comme ConnectionTimeOut , qui peuvent également indiquer, par exemple, l'option lorsque GC se bloque sur des cadres ou quelque chose comme ça. En général, ne répétez pas mes erreurs.
Enfin, déclarons notre Pipeline:
val pipeline = new Pipeline() .setStages( Array( missingImputer, nameTransformer, cabinsCountTransformer, numbersFromCabinTransformer, stringEncoder, assembler, lgbClf ) )
La formation
Nous allons briser notre ensemble de formation en un train et un test et vérifier notre pipeline. Ici, vous pouvez simplement évaluer la commodité du pipeline, car il est complètement indépendant de la partition et garantit que nous appliquerons les mêmes transformations pour former et tester, et tous les paramètres de transformation seront appris sur le train:
val Array(trainDF, testDF) = trainFiltered.randomSplit(Array(0.8, 0.2)) println(s"Train rows: ${trainDF.count}\nTest rows: ${testDF.count}")
Pour un calcul pratique des métriques, nous utiliserons une autre classe de MMLSpark - ComputeModelStatistics :
import com.microsoft.ml.spark.ComputeModelStatistics import com.microsoft.ml.spark.metrics.MetricConstants val modelEvaluator = new ComputeModelStatistics() .setLabelCol("Survived") .setScoresCol("predictedProb") .setScoredLabelsCol("predictedLabel") .setEvaluationMetric(MetricConstants.ClassificationMetrics)
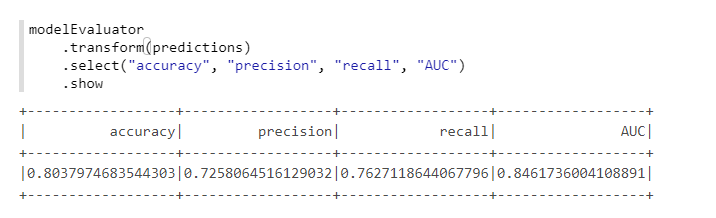
Pas mal, étant donné que nous n'avons pas modifié les paramètres par défaut.
Sélection d'hyperparamètres
Pour sélectionner des hyperparamètres dans MMLSpark, il y a une chose sympa distincte TuneHyperparameters , qui implémente une recherche aléatoire sur la grille. Cependant, malheureusement, il ne prend pas encore en charge Pipeline , nous allons donc utiliser le SparkML CrossValidator habituel:
import org.apache.spark.ml.tuning.{ParamGridBuilder, CrossValidator} import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator val paramSpace = new ParamGridBuilder() .addGrid(lgbClf.maxDepth, Array(3, 5)) .addGrid(lgbClf.learningRate, Array(0.05, 0.1)) .addGrid(lgbClf.numIterations, Array(100, 300)) .build println(s"Size of ParamsGrid: ${paramSpace.size}")
Malheureusement, je n'ai pas trouvé de moyen pratique de voir les résultats avec les paramètres sur lesquels ils ont été obtenus. Par conséquent, il est nécessaire d'utiliser des conceptions "monstrueuses":
crossValidator .getEstimatorParamMaps .zip(bestModel.avgMetrics) .foreach(x => { println( "\n" + x._1 .toSeq .foldLeft(new StringBuilder())( (a, b) => a .append(s"\n\t${b.param.name} : ${b.value}")) .toString + s"\n\tMetric: ${x._2}" ) })
Ce qui nous donne quelque chose comme ça:
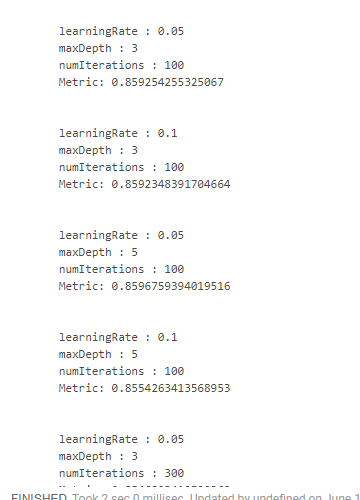
Nous avons obtenu le meilleur résultat en réduisant la vitesse d'apprentissage et en augmentant la profondeur des arbres. Sur cette base, il serait possible d'ajuster l'espace de recherche et d'arriver à un résultat encore plus optimal, mais nous n'avons tout simplement pas un tel objectif.
Conclusion
En fait, alors que MMLSpark a la version 0.17 et contient toujours des bogues distincts. Mais de toutes les extensions Spark que j'ai vues, MMLSpark a à mon avis la documentation la plus complète et le processus d'installation et de mise en œuvre le plus compréhensible. Microsoft ne l'a pas encore vraiment promu, il n'y avait qu'un rapport sur les Databricks , mais il s'agissait davantage de DeepLearning, et non des choses de routine sur lesquelles j'ai écrit.
Personnellement, dans nos tâches, cette bibliothèque m'a beaucoup aidé, me permettant de parcourir un peu moins la jungle des sources Spark et de ne pas utiliser la réflexion pour accéder aux méthodes privées [ml], et un de mes collègues a trouvé la bibliothèque presque par accident. Dans le même temps, en raison du fait que la bibliothèque est en développement actif, la structure du fichier source bouillie pleine quelque peu déroutant. Eh bien, en raison du fait qu'il n'y a pas d'exemples spéciaux ou d'autre documentation (à l'exception de scaladoc nu), au début, je devais explorer la source tout le temps.
Par conséquent, j'espère vraiment que ce mini-tutoriel (malgré toute son évidence et sa simplicité) sera utile à quelqu'un et permettra d'économiser beaucoup de temps et d'efforts!