L'article discutera des avantages de la journalisation. Je vais vous parler des journaux sur PSR. J'ajouterai quelques recommandations personnelles sur l'utilisation du niveau, du message et du contexte de l'événement enregistré. Un exemple sera donné sur la façon d'organiser la journalisation et la surveillance à l'aide d'ELK dans une application écrite en Laravel et lancée via Docker sur plusieurs instances. Je signerai une règle importante du système d'alerte. Je vais donner un exemple de script qui soulève toute la pile de surveillance avec une seule commande.
Les avantages de l'exploitation forestière
Une journalisation bien organisée permet au moins ce qui suit:
- Savoir que quelque chose ne se passe pas comme prévu (il y a des erreurs)
- Connaître les détails de l'erreur, ce qui aidera à dire avec qui et où l'erreur s'est produite, et éviter une répétition
- Sachez que tout se passe comme prévu (access.log, debug-, info-levels)
La journalisation en elle-même ne vous dira pas tout cela, mais à l'aide des journaux, il sera possible de connaître indépendamment les détails des événements ou de configurer un système de surveillance des journaux qui pourra notifier les problèmes. Si les messages dans les journaux sont accompagnés d'une quantité de contexte suffisante, cela simplifie considérablement le débogage, car vous aurez plus de données disponibles sur la situation dans laquelle l'événement s'est produit.
Quoi écrire et quoi écrire
Une partie de la communauté php a développé des recommandations pour certaines tâches d'écriture de code. L'une de ces recommandations est l' interface de l'enregistreur PSR-3 . Il décrit simplement ce dont vous avez besoin pour vous connecter. Pour cela, l' Psr\Log\LoggerInterface du package "psr / log" est développée. Lorsque vous l'utilisez, vous devez connaître les trois composantes de l'événement:
- Niveau - Importance de l'événement
- Message - texte décrivant l'événement
- Contexte - un tableau d'informations supplémentaires sur l'événement
Niveaux d'événements PSR-3
Les niveaux sont empruntés à la RFC 5424 - Le protocole Syslog, leur description approximative est la suivante:
- debug - Détails pour le débogage
- info - Evènements intéressants
- légales - Événements importants, mais pas d'erreurs
- avertissement - Cas exceptionnels, mais pas d'erreurs
- error - Erreurs d'exécution ne nécessitant pas d'intervention momentanée
- critique - Conditions critiques (le composant système n'est pas disponible, exception inattendue)
- alerte - L'action nécessite une intervention immédiate
- urgence - Le système ne fonctionne pas
Il y a une description, mais elle n'est pas toujours facile à suivre, en raison de la difficulté à déterminer l'importance de certains événements. Par exemple, dans le cadre d'une seule demande, il n'a pas été possible d'accéder à la ressource connectée. Lors de l'enregistrement de cet événement, nous ne savons pas si une telle demande a échoué, ou peut-être qu'un seul utilisateur échoue. Cela dépend si une intervention immédiate est requise ou si c'est un cas rare, elle peut attendre ou même être ignorée. Ces problèmes sont résolus dans le cadre des journaux de surveillance. Mais vous devez encore déterminer le niveau. Par conséquent, les niveaux de journalisation dans l'équipe peuvent être convenus. Un exemple:
- urgence est le niveau pour les systèmes externes qui peuvent regarder votre système et déterminer avec certitude qu'il ne fonctionne pas complètement ou que son auto-diagnostic ne fonctionne pas.
- alerte - le système lui-même peut diagnostiquer son état, par exemple, avec une tâche planifiée et, par conséquent, enregistrer un événement avec ce niveau. Il peut s'agir de vérifications des ressources connectées ou de quelque chose de spécifique, par exemple, un solde sur le compte d'une ressource externe utilisée.
- critique - un événement où une panne donne un composant système qui est très important et devrait toujours fonctionner. Cela dépend déjà beaucoup de ce que fait le système. Convient aux événements importants à découvrir rapidement, même si cela ne s'est produit qu'une seule fois.
- erreur - un événement s'est produit sur lequel, lors de la répétition rapide, vous devez signaler. Impossible de terminer l'action, qui doit être effectuée, mais cette action ne relève pas de la description de critique. Par exemple, il n'a pas été possible d'enregistrer la photo de profil d'un utilisateur à sa demande, mais le système n'est pas un service de photo de profil, mais un système de chat.
- avertissement - événements, pour une notification immédiate dont vous devez composer un nombre significatif d'entre eux sur une période de temps. Échec de l'exécution d'une action dont l'échec ne rompt rien de grave. Ce sont encore des erreurs, mais dont la correction peut attendre l'horaire de travail. Par exemple, il n'était pas possible de sauvegarder l'avatar de l'utilisateur et le système était une boutique en ligne. Une notification à leur sujet est nécessaire (à une fréquence élevée) afin de se renseigner sur les anomalies soudaines, car elles peuvent être des symptômes de problèmes plus graves.
- avis - ce sont des événements qui signalent des écarts fournis par le système qui font partie du fonctionnement normal du système. Par exemple, l'utilisateur a spécifié le mauvais mot de passe à l'entrée, l'utilisateur n'a pas entré le deuxième prénom, mais ce n'est pas nécessaire, l'utilisateur a acheté la commande pour 0 roubles, mais cela vous est fourni dans de rares cas. Une notification à leur sujet à une fréquence élevée est également nécessaire, car une forte augmentation du nombre d'écarts peut être le résultat d'une erreur qui doit être corrigée de toute urgence.
- info - événements, dont l'occurrence rapporte le fonctionnement normal du système. Par exemple, un utilisateur s'est inscrit, un utilisateur a acheté un produit, un utilisateur a laissé des commentaires. La notification pour de tels événements doit être configurée de la manière opposée: si un nombre insuffisant de tels événements s'est produit sur une période de temps, vous devez alors le notifier, car leur diminution pourrait être due à une erreur.
- debug - événements pour déboguer un processus sur le système. Lorsque vous ajoutez suffisamment de données au contexte de l'événement, vous pouvez diagnostiquer le problème ou conclure que le processus fonctionne correctement dans le système. Par exemple, un utilisateur a ouvert une page de produit et a reçu une liste de recommandations. Augmente considérablement le nombre d'événements envoyés, il est donc possible de supprimer l'enregistrement de ces événements après un certain temps. En conséquence, le nombre de ces événements en fonctionnement normal sera variable, alors la surveillance de la notification à leur sujet peut être omise.
Message d'événement
Par PSR-3, un message doit être une chaîne ou un objet avec la __toString() . De plus, selon PSR-3, la ligne de message peut contenir des espaces réservés du formulaire ”User {username} created” , qui peuvent être remplacés par des valeurs du tableau de contexte. Lorsque vous utilisez Elasticsearch et Kibana pour la surveillance, je recommande de ne pas utiliser d'espaces réservés, mais d'écrire des lignes fixes, car cela simplifiera le filtrage des événements et le contexte sera toujours là. De plus, je propose de prêter attention aux exigences supplémentaires pour le message:
- Le texte doit être court mais significatif. C'est ce qui viendra dans les alertes, et ce qui sera dans les listes d'événements qui se sont produits.
- Le texte vaut mieux être unique pour différentes parties du programme. Cela permettra à partir de l'alerte, sans regarder dans le contexte, de comprendre dans quelle partie l'événement s'est produit.
Contexte de l'événement
Le contexte d'événement pour PSR-3 est un tableau (éventuellement imbriqué) de valeurs de variable, par exemple, des ID d'entité. Le contexte peut être laissé vide si le message est clair sur l'événement. Dans le cas de la journalisation d'une exception, vous devez transmettre l'intégralité de l'exception, pas seulement getMessage() . Lorsque vous utilisez Monolog via NormalizerFormatter, les données utiles seront automatiquement extraites de l'exception et ajoutées au contexte de l'événement, y compris la trace de la pile. Autrement dit, vous avez besoin à la place
[ 'exception' => $exception->getMessage(), ]
utiliser
[ 'exception' => $exception, ]
Dans Laravel, vous pouvez saisir automatiquement les données des événements dans les événements. Cela peut être fait via le contexte de journal global (uniquement pour les exceptions infructueuses ou via report() ), ou via LogFormatter (pour tous les événements). Habituellement, les informations sont ajoutées avec l'ID de l'utilisateur actuel, la demande d'URI, IP, la demande d'UUID et similaires.
Lorsque vous utilisez Elasticsearch en tant que référentiel de journaux, n'oubliez pas qu'il utilise des types de données fixes. Autrement dit, si vous avez passé customer_id dans le contexte d'un nombre, puis lorsque vous essayez d'enregistrer un événement avec un type différent, par exemple, une chaîne (uuid), un tel message ne sera pas écrit. Les types de l'index sont fixes lors de la première réception de la valeur. Si des index sont créés tous les jours, le nouveau type ne sera enregistré que le lendemain. Mais même cela ne résoudra pas tous les problèmes, car pour Kibana les types seront mélangés et certaines des opérations associées au type ne seront pas disponibles tant qu'il n'y aura pas d'index mixtes.
Pour éviter ce problème, je vous recommande de suivre les règles:
- N'utilisez pas de noms de clé trop génériques, qui peuvent être de différents types
- Effectuez un cast explicite vers un type de valeur si vous n'êtes pas sûr de son type
Exemple: à la place
[ 'response' => $response->all(), 'customer_id' => $id, 'value' => $someValue, ]
utiliser
[ 'smsc_response_data' => json_encode($response->all()), 'customer_id' => (string) $customer_id, 'smsc_request_some_value' => (string) $someValue, ]
Appel d'un enregistreur à partir du code
Pour enregistrer rapidement un événement dans le journal, vous pouvez proposer plusieurs options. Examinons certains d'entre eux.
- Déclarez le
log() fonction globale log() et appelez-le à partir de différentes parties du programme. Cette approche présente de nombreux inconvénients. Par exemple, dans les classes où nous accédons à cette fonction, une dépendance implicite est formée. Cela devrait être évité. De plus, un tel enregistreur est difficile à configurer lorsque le système doit en avoir plusieurs différents. Un autre inconvénient, si nous parlons de travailler avec Laravel, est que nous n'utilisons pas les fonctionnalités fournies par le framework pour résoudre ce problème. - Utilisez la façade Laravel \ Log. Avec cette approche, les parties du système qui accèdent à cette façade commencent à dépendre de la charpente. Dans certaines parties du système que nous n'allons pas retirer du cadre, une telle solution est tout à fait appropriée. Par exemple, écrivez à partir de certaines instances d'une commande de console, d'une tâche en arrière-plan, d'un contrôleur. Ou quand il existe déjà une structure complexe de services, et y jeter une instance d'un enregistreur n'est pas si simple.
- Résolvez la dépendance de l'enregistreur via les assistants du framework
app() et resolve() . L'approche présente les mêmes inconvénients que l'utilisation de la façade, mais vous devez écrire un peu plus de code. - Spécifiez la dépendance de l'enregistreur dans le constructeur de la classe que cet enregistreur utilisera. En même temps, la même
LoggerInterface doit être spécifiée comme type afin de se conformer à DIP . Grâce aux frameworks de câblage automatique, les dépendances seront automatiquement résolues dans la mise en œuvre de leurs abstractions déclarées. Dans Laravel, certaines classes de dépendances peuvent être spécifiées dans une méthode distincte, au lieu d'être spécifiées dans le constructeur de la classe entière.
Où dans le code appeler l'enregistreur
Lors de l'organisation du code dans le projet, la question peut se poser dans quelle classe je devrais écrire dans le journal. Doit-il s'agir d'un service? Ou doit-il être fait d'où le service est appelé: contrôleur, tâche en arrière-plan, commande de console? Ou chaque exception devrait-elle décider quoi écrire dans le journal en utilisant sa méthode de report (Laravel)? Il n'y a pas de réponse simple à toutes les questions à la fois.
Considérez l' opportunité donnée par Laravel de déléguer à la classe d'exception la tâche de se connecter. Une exception ne peut pas savoir à quel point il est essentiel que le système détermine le niveau d'un événement. De plus, une exception n'a accès au contexte que si elle est spécifiquement ajoutée lors de l'appel de cette exception. Pour appeler la méthode de render sur une exception, vous devez soit ne pas intercepter l'exception (le gestionnaire d'erreur global sera utilisé), soit intercepter et utiliser l'aide globale report() . Cette méthode nous permet de ne pas appeler l'enregistreur PSR-3 chaque fois que nous pouvons intercepter cette exception. Mais je ne pense pas que cela vaille la peine de confier une telle responsabilité à l'exception.
Il peut sembler que nous pouvons toujours nous connecter uniquement aux services. En effet, dans certains services, vous pouvez effectuer une journalisation. Mais considérons un service qui ne dépend pas du projet et, en général, nous prévoyons de le mettre dans un package séparé. Ce service ne connaît alors pas son importance dans le projet et ne pourra donc pas déterminer le niveau de journalisation. Par exemple, un service d'intégration avec une passerelle SMS spécifique. Si nous obtenons une erreur de réseau, cela ne signifie pas que c'est assez grave. Peut-être que le système dispose d'un service d'intégration avec une autre passerelle SMS via laquelle il y aura une deuxième tentative d'envoi, puis l'erreur de la première peut être signalée comme avertissement et l'erreur de la seconde comme erreur. Ce n'est que maintenant que toutes ces intégrations doivent être appelées à partir d'un autre service, qui se connectera exactement. Il s'avère que l'erreur se trouve dans un service et nous nous connectons dans un autre. Mais parfois, nous n'avons pas de wrapper de service sur un autre service - nous l'appelons directement depuis le contrôleur. Dans ce cas, je considère qu'il est permis d'écrire dans le journal du contrôleur au lieu d'écrire un décorateur de service pour la journalisation.
Un exemple montrant l'utilisation de la dépendance et du contexte de passage:
<?php namespace App\Console\Commands; use App\Services\ExampleService; use Illuminate\Console\Command; use Psr\Log\LoggerInterface; class Example extends Command { protected $signature = 'example'; public function handle(ExampleService $service, LoggerInterface $logger) { try { $service->example(); } catch (\Exception $exception) { $logger->critical('Example error', [ 'exception' => $exception, ]); } } }
Où écrire
Considérez les options suivantes.
- Selon l' application à 12 facteurs et certaines autres recommandations, vous devez écrire stdout, stderr du runtime de l'application. Pour ce faire, vous pouvez spécifier dans le journal de configuration
php://stdout *. - Ignorez le facteur 12, docker-way et écrivez dans des fichiers. Laravel (Monolog) vous permet même de configurer la rotation des journaux. D'autres messages provenant de fichiers peuvent être collectés à l'aide de Filebeat et envoyés à Logstash pour analyse.
- Envoyez directement les journaux de l'application, par exemple via UDP pour augmenter les performances.
- Combinez des solutions. Écrivez dans des fichiers qui utilisant Filebeat seront collectés et envoyés à Logstash. Écrivez dans le conteneur stderr afin de pouvoir utiliser les commandes
docker logs et être prêt à collecter facilement les journaux de l'environnement d'orchestration de conteneurs. Dans ce cas, vous pouvez écrire certains canaux uniquement localement, certains envoyer sur le réseau.
* Dans php-fpm 7.2, lors de l'écriture des journaux sur stdout, nous obtenons "AVERTISSEMENT: [pool www] l'enfant X dit dans stdout ...", et les longs messages sont tronqués. Une solution à ce problème est ici . Il n'y a pas un tel problème dans php-fpm 7.3.
Options de format d'enregistrement:
- Lisible par l'homme (sauts de ligne, retraits, etc.)
- Lisible par machine (généralement json)
- Les deux formats à la fois: lisibles par machine dans stdout pour un routage ultérieur, lisibles par l'homme en cas de problèmes de routage soudains et de débogage rapide
L'une des options suppose que les journaux sont routés - au moins, ils sont envoyés à un seul système de traitement (stockage) des journaux pour les raisons suivantes:
- Stockage et archivage à long terme
- Tendance à grande échelle
- Système de notification d'événement flexible
Docker a la possibilité de spécifier un gestionnaire de journaux. La valeur par défaut est json-file , c'est json-file dire que le docker ajoute la sortie du conteneur au fichier json sur l'hôte. Si nous sélectionnons un gestionnaire de journaux qui enverra des enregistrements quelque part sur le réseau, nous ne pouvons plus utiliser la docker logs . Si stdout / stderr du conteneur a été choisi comme seul endroit pour enregistrer les journaux d'application, en cas de problèmes de réseau ou de problèmes avec un seul référentiel, il peut ne pas être possible d'extraire rapidement des enregistrements pour le débogage.
Nous pouvons utiliser json-file docker et Filebeat. Nous recevrons à la fois des journaux locaux et un routage supplémentaire. Il convient de noter ici est une autre caractéristique du docker. Lors de l'enregistrement d'un événement de plus de 16 Ko, le docker casse l'enregistrement avec le symbole \n , ce qui confond de nombreux collecteurs de journaux. Il y a un problème à ce sujet. Le problème de la part du docker n'a pas pu être résolu, il a donc été résolu par les collectionneurs. Avec certaines versions, Filebeat prend en charge ce comportement de docker et combine correctement les événements.
Quelle combinaison de toutes les possibilités de destinations et de formats d'enregistrement vous pouvez choisir vous-même pour votre projet.
Utilisation de Filebeat + ELK + Elastalert
En bref, le rôle de chaque service peut être décrit comme suit:
- Filebeat - collecte des événements à partir de fichiers et envoie
- Logstash - analyse les événements et envoie
- Elasticsearch - stocke les événements structurés
- Kibana - affiche les événements (graphiques, agrégations, etc.)
- Elastalert - Envoie des alertes en fonction des demandes
De plus, vous pouvez: zabbix, metricbeat, grafana et plus.
Maintenant, plus sur chacun.
Filebeat
Vous pouvez exécuter en tant que service distinct sur l'hôte, vous pouvez utiliser un conteneur Docker distinct. Pour travailler avec le flux d'événements de docker, il utilise le chemin d'hôte /var/lib/docker/containers/*/*.log . Filebeat dispose d'un large éventail d'options avec lesquelles vous pouvez définir un comportement dans diverses situations (le fichier est renommé, le fichier est supprimé, etc.). Le battement de fichier lui-même peut analyser json à l'intérieur de l'événement, mais pas json ne peut également entrer dans les événements, ce qui entraînera une erreur. Il est préférable de traiter tous les événements en un seul endroit.
Configuration des fragments pour Filebeat 6 filebeat.inputs: - type: docker containers: ids: - "*" processors: - add_docker_metadata: ~
Logstash
Capable d'accepter des événements de nombreuses sources, mais ici nous envisageons Filebeat.
Dans chaque événement, outre l'événement lui-même de stdout / stderr, il existe des métadonnées (hôte, conteneur, etc.). Il existe de nombreux filtres de traitement intégrés: analyser à intervalles réguliers, analyser json, modifier, ajouter, supprimer des champs, etc. Convient pour analyser à la fois les journaux d'application et nginx access.log dans n'importe quel format. Capable de transférer des données vers différents référentiels, mais ici nous considérons Elasticsearch.
Fragment de configuration du filtre Logstash if [status] { date { match => ["timestamp_nginx_access", "dd/MMM/yyyy:HH:mm:ss Z"] target => "timestamp_nginx" remove_field => ["timestamp_nginx_access"] } mutate { convert => { "bytes_sent" => "integer" "body_bytes_sent" => "integer" "request_length" => "integer" "request_time" => "float" "upstream_response_time" => "float" "upstream_connect_time" => "float" "upstream_header_time" => "float" "status" => "integer" "upstream_status" => "integer" } remove_field => [ "message" ] rename => { "@timestamp" => "event_timestamp" "timestamp_nginx" => "@timestamp" } } }
Elasticsearch
Elasticsearch est un outil très puissant pour un large éventail de tâches, mais dans le but de surveiller les journaux, il peut être utilisé en ne connaissant qu'un certain minimum.
Les événements enregistrés sont un document, les documents sont stockés dans des index.
Chaque index est un schéma dans lequel un type est défini pour chaque champ du document. Vous ne pouvez pas enregistrer un événement dans l'index si au moins un champ a le mauvais type.
Différents types vous permettent d'effectuer différentes opérations sur un groupe de documents (pour les nombres - somme, min, max, moyenne, etc., pour les chaînes - recherche floue, etc.).
Pour les journaux, la direction recommande généralement d'utiliser des index quotidiens - un nouvel index chaque jour.
Assurer un fonctionnement stable d'Elasticsearch avec la croissance du volume de données est une tâche qui nécessite une connaissance approfondie de cet outil. Mais une solution rapide au problème de stabilité, vous pouvez choisir de supprimer automatiquement les données obsolètes. Pour ce faire, je suggère de diviser les niveaux d'événements dans logstash à différents indices. Cela permettra de stocker plus longtemps des événements rares mais plus importants.
Extrait de configuration de la sortie Logstash output { if [fields][log_type] == "app_log" { if [level] in ["DEBUG", "INFO", "NOTICE"] { elasticsearch { hosts => "${ES_HOST}" index => "logstash-app-log-debug-%{+YYYY.MM.dd}" } } else { elasticsearch { hosts => "${ES_HOST}" index => "logstash-app-log-error-%{+YYYY.MM.dd}" } } } }
Pour supprimer automatiquement les index obsolètes, je suggère d'utiliser un programme d'Elastic Curator . Le lancement du programme est ajouté au calendrier Cron, la configuration elle-même peut être stockée dans un fichier séparé.
Un fragment de la configuration pour supprimer les index obsolètes action: delete_indices description: logstash-app-log-error options: ignore_empty_list: True filters: - filtertype: pattern kind: prefix value: logstash-app-log-error- - filtertype: age source: name direction: older timestring: '%Y.%m.%d' unit: months unit_count: 6
, Filebeat Logstash, . Elasticsearch -- , , .
Kibana
Kibana . -, Elasticsearch. .
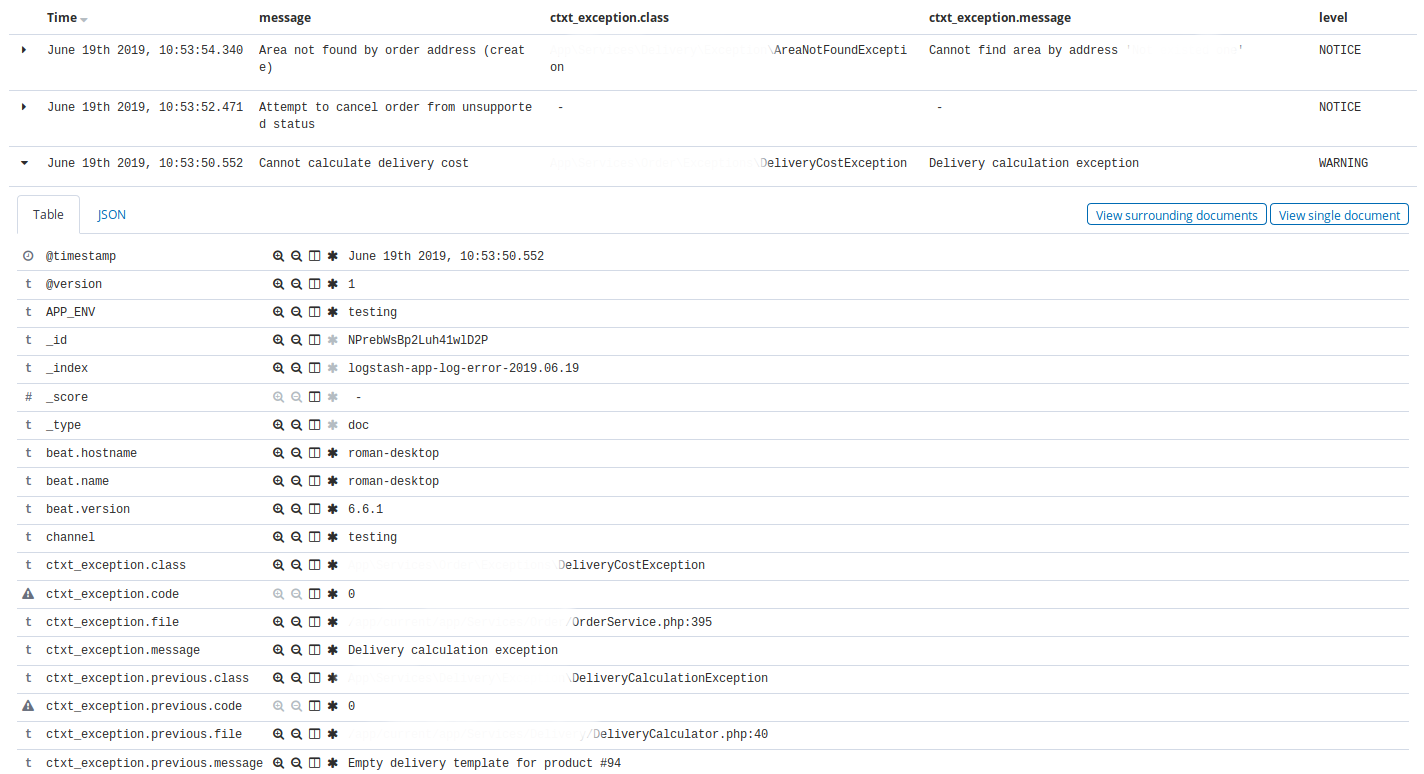
Kibana — Discovery . , Discovery app warning , time, message, exception class, host, client_id.
, Discovery nginx, 404 time, message, request, status.
Kibana , : , , . , ( ).
Elastalert
Elastalert Elasticsearch . , . , .
, (), .
:
- ALERT, EMERGENCY. — 10
- CRITICAL. — 30
- , N X M
- 10 INFO 3
- nginx 200, 201, 304 75% , 50
name: Blacklist ALERT, EMERGENCY type: blacklist index: logstash-app-* compare_key: "level" blacklist: - "ALERT" - "EMERGENCY" realert: minutes: 5 alert: - "slack"
— . , , . Kibana.
, , http- 75% , , , , . - , , , .
, , , , Kibana, .
5 . , , , , , .
, . .
Kibana . .
docker-. , , staging- production-, .
, Elastalert, . Elastalert ,
envsubst < /opt/elastalert/config.dist.yaml > /opt/elastalert/config.yaml entrypoint- , .
, , , .
Makefile build: docker build -t some-registry/elasticsearch elasticsearch docker build -t some-registry/logstash logstash docker build -t some-registry/kibana kibana docker build -t some-registry/nginx nginx docker build -t some-registry/curator curator docker build -t some-registry/elastalert elastalert push: docker push some-registry/elasticsearch docker push some-registry/logstash docker push some-registry/kibana docker push some-registry/nginx docker push some-registry/curator docker push some-registry/elastalert pull: docker pull some-registry/elasticsearch docker pull some-registry/logstash docker pull some-registry/kibana docker pull some-registry/nginx docker pull some-registry/curator docker pull some-registry/elastalert prepare: docker network create -d bridge elk-network || echo "ok" stop: docker rm -f kibana || true docker rm -f logstash || true docker rm -f elasticsearch || true docker rm -f nginx || true docker rm -f elastalert || true run-logstash: docker rm -f logstash || echo "ok" docker run -d --restart=always --network=elk-network --name=logstash -p 127.0.0.1:5001:5001 -e "LS_JAVA_OPTS=-Xms256m -Xmx256m" -e "ES_HOST=elasticsearch:9200" some-registry/logstash run-kibana: docker rm -f kibana || echo "ok" docker run -d --restart=always --network=elk-network --name=kibana -p 127.0.0.1:5601:5601 --mount source=elk-kibana,target=/usr/share/kibana/optimize some-registry/kibana run-elasticsearch: docker rm -f elasticsearch || echo "ok" docker run -d --restart=always --network=elk-network --name=elasticsearch -e "ES_JAVA_OPTS=-Xms1g -Xmx1g" --mount source=elk-esdata,target=/usr/share/elasticsearch/data some-registry/elasticsearch run-nginx: docker rm -f nginx || echo "ok" docker run -d --restart=always --network=elk-network --name=nginx -p 80:80 -v /root/elk/.htpasswd:/etc/nginx/.htpasswd some-registry/nginx run-elastalert: docker rm -f elastalert || echo "ok" docker run -d --restart=always --network=elk-network --name=elastalert --env-file=./elastalert/.env some-registry/elastalert run: prepare run-elasticsearch run-kibana run-logstash run-elastalert delete-old-indices: docker run --rm --network=elk-network -e "ES_HOST=elasticsearch:9200" some-registry/curator curator --config /curator/curator.yml /curator/actions.yml
:
- 80 nginx, basic auth Kibana
- Logstash . ssh-
- nginx
- , docker-
- , .env- nginx-
- *_JAVA_OPTS , 4GB RAM ( ES).
, xpack-.
docker-compose. , , Dockerfile-, Filebeat, Logstash, , , , , VCS.
. . , ( Laravel scheduler), , 5 . ALERT. , . , , .
Conclusion
, , , . . , - . . , , .