Le cours complet de russe se trouve sur ce lien .
Le cours d'anglais original est disponible sur ce lien .

De nouvelles conférences sont prévues tous les 2-3 jours.
Table des matières
- Entretien avec Sebastian Trun
- Présentation
- Dogs and Cats Dataset
- Images de différentes tailles
- Images couleur. Partie 1
- Images couleur. 2e partie
- Opération de convolution sur des images couleur
- L'opération de sous-échantillonnage par la valeur maximale dans les images en couleur
- CoLab: chats et chiens
- Softmax et sigmoïde
- Vérifier
- Extension d'image
- Exception
- CoLab: chiens et chats. Répétition
- Autres techniques pour empêcher le recyclage
- Exercices: classification des images en couleur
- Solution: classification des images couleur
- Résumé
Entretien avec Sebastian Trun
- Donc, aujourd'hui, nous sommes ici à nouveau, avec Sebastian et nous parlerons de recyclage. Ce sujet est très intéressant pour nous, en particulier dans les parties pratiques du cours actuel sur l'utilisation de TensorFlow.
- Sebastian, avez-vous déjà rencontré du sur-ajustement - fini, en forme? Si vous dites que vous ne l'avez pas rencontré, alors je dirai certainement que je ne peux pas vous croire!
- Ainsi, la raison du recyclage est ce que l'on appelle le compromis biais-variance (un compromis entre les valeurs du paramètre de biais et leur propagation). Un réseau de neurones dans lequel un petit nombre de poids n'est pas en mesure d'apprendre un nombre suffisant d'exemples, une situation similaire dans l'apprentissage automatique est appelée distorsion.
- Oui.
- Un réseau de neurones avec autant de paramètres peut choisir arbitrairement une solution que vous n'aimez pas, simplement à cause d'un si grand nombre de ces paramètres. Le résultat du choix d'une solution de réseau neuronal dépend de la variabilité des données sources. Ainsi, une règle simple peut être formulée: plus il y a de paramètres dans le réseau concernant la taille (quantité) des données, plus il est probable d'obtenir une solution aléatoire au lieu de la bonne. Par exemple, vous vous demandez: «Qui est l'homme dans cette pièce et qui est la femme?» Un réseau neuronal complexe peut vous dire que, par exemple, tous ceux dont le nom commence par T sont des hommes et ne se recyclent jamais. Il y a deux solutions. Le premier utilise un ensemble de données d'exclusion (une petite quantité de l'ensemble d'apprentissage pour valider la précision du modèle). Vous pouvez prendre les données, les diviser en deux parties - 90% pour la formation et 10% pour tester et effectuer la soi-disant validation croisée, où vous vérifiez la précision du modèle sur les données que le réseau de neurones n'a pas vues - dès que la valeur d'erreur commence croître après un certain cycle de formation - il est temps d'arrêter d'apprendre. La deuxième solution consiste à introduire des restrictions dans le réseau neuronal. Par exemple, pour limiter les valeurs des paramètres de déplacements et de poids, en les rapprochant de plus en plus de zéro. Plus les poids sont limités, moins le modèle sera recyclé.
- Je comprends bien que nous pouvons avoir des ensembles de données pour la formation et les tests et la validation, non?
- C'est vrai. Si vous avez un ensemble de données à valider, vous devez avoir un ensemble de données que vous n'avez jamais touché ou montré à votre réseau neuronal. Si vous avez montré au modèle un certain ensemble de données plusieurs fois, alors, bien sûr, le processus de recyclage commencera, ce qui est très mauvais pour nous.
- Peut-être vous souviendrez-vous des cas les plus intéressants lorsque votre modèle a été recyclé?
- Ah, oui ... il y a eu un tel incident dans ma première jeunesse quand je développais un réseau de neurones pour jouer aux échecs. C'était en 1993. Ce qui était intéressant, c'est qu'à partir des données d'échecs sur lesquelles le réseau neuronal était formé, le réseau a rapidement déterminé que si un expert déplace la reine au centre de l'échiquier, il y a 60% de chances de gagner. Ce qu'elle a commencé à faire était d'ouvrir le «passage» avec un pion et de déplacer la reine au centre de l'échiquier. C'était une décision si stupide pour tout joueur d'échecs, qui témoignait clairement de la reconversion du modèle.
- Génial! Nous avons donc discuté de plusieurs techniques pour améliorer nos modèles. Selon vous, quel est l'aspect le plus sous-estimé de l'apprentissage en profondeur?
- 90% de votre travail est sous-estimé, car 90% de votre travail consistera en un nettoyage des données.
- Ici, je suis complètement d'accord avec toi!
- Comme le montre la pratique, tout ensemble de données contient une sorte de déchets. Il est très difficile d'amener les données au bon type, pour les rendre cohérentes, c'est un processus très long.
- Oui, même si vous travaillez avec des ensembles de données tels que des images ou des vidéos, où, semble-t-il, toutes les informations sont déjà là, à l'intérieur, il y a toujours un besoin de prétraiter les images.
- Les seules personnes pour qui les données sont idéales sont les professeurs, car ils ont la possibilité de prétendre dans une présentation dans PowerPoint que tout est comme il se doit et que tout est parfait! En réalité, 90% de votre temps sera occupé par le nettoyage des données.
- Génial. Alors, découvrons-en plus sur le recyclage et les techniques qui nous permettront d'améliorer nos modèles d'apprentissage en profondeur.
Présentation
- salut! Et encore une fois, bienvenue au cours!
«Dans la dernière leçon, nous avons développé un petit réseau de neurones convolutionnels pour classer les images des vêtements en nuances de gris à partir du jeu de données FASHION MNIST. Nous avons vu en pratique que notre petit réseau de neurones peut classer les images entrantes avec une précision assez élevée. Cependant, dans le monde réel, nous devons travailler avec des images haute résolution et différentes tailles. L'un des grands avantages du SNA est qu'il peut tout aussi bien fonctionner avec des images en couleur. Par conséquent, nous allons commencer notre leçon actuelle en explorant le fonctionnement du SCN avec les images en couleur.
- Plus tard, à la même fréquence, vous construirez un réseau neuronal convolutif qui pourra classer des images de chats et de chiens. En route vers la mise en place d'un réseau neuronal convolutif capable de classer les images de chats et de chiens, nous apprendrons également à utiliser différentes techniques pour résoudre l'un des problèmes les plus courants des réseaux neuronaux - la reconversion. Et à la fin de cette leçon, dans la partie pratique, vous développerez votre propre réseau neuronal convolutif pour classer les images en couleur. Commençons!
Ensemble de données chats et chiens
Jusqu'à ce moment, nous ne travaillions qu'avec des images en niveaux de gris et des tailles 28x28 du jeu de données FASHION MNIST.

Dans les applications réelles, nous sommes obligés de rencontrer des images de différentes tailles, par exemple, celles illustrées ci-dessous:

Comme nous l'avons mentionné au début de cette leçon, dans cette leçon, nous développerons un réseau neuronal convolutif qui peut classer les images en couleur des chiens et des chats.
Pour mettre en œuvre nos plans, nous utiliserons des images de chats et de chiens du jeu de données Microsoft Asirra. Chaque image de cet ensemble de données est étiquetée 1 ou 0 s'il y a un chien ou un chat dans l'image, respectivement.

Malgré le fait que l'ensemble de données Microsoft Asirra contient plus de 3 millions d'images balisées de chats et de chiens, seulement 25 000 sont accessibles au public. La formation de notre réseau neuronal convolutionnel sur ces 25 000 images prendra beaucoup de temps. C'est pourquoi nous utiliserons un petit nombre d'images pour former notre réseau de neurones convolutionnels à partir des 25 000 disponibles.
Notre sous-ensemble d'images de formation comprend 2 000 pièces et 1 000 pièces d'images pour la validation du modèle. Dans l'ensemble de données de formation, 1 000 images contiennent des chats et les 1 000 autres images contiennent des chiens. Nous parlerons de l'ensemble de données à valider un peu plus loin dans cette partie de la leçon.
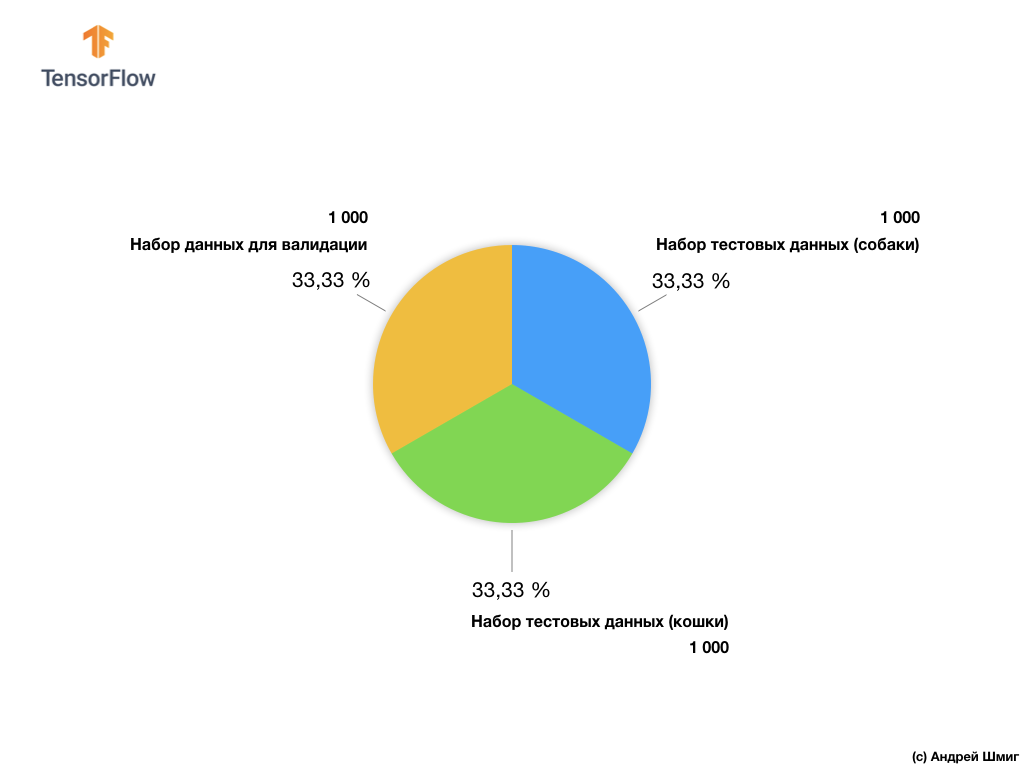
En travaillant avec cet ensemble de données, nous rencontrerons deux difficultés principales: travailler avec des images de tailles différentes et travailler avec des images en couleur.
Commençons à explorer comment travailler avec des images de différentes tailles.
Images de différentes tailles
Notre premier test sera de résoudre le problème du traitement d'images de différentes tailles. C'est parce qu'un réseau de neurones à l'entrée a besoin de données de taille fixe.
Par exemple, vous pouvez vous rappeler de nos parties précédentes en utilisant le paramètre input_shape lors de la création d'un calque Flatten :

Avant de transmettre l'image d'un élément vestimentaire à un réseau neuronal, nous l'avons convertie en un tableau 1D d'une taille fixe - 28x28 = 784 éléments (pixels). Étant donné que les images du jeu de données Fashion MNIST étaient de la même taille, le tableau unidimensionnel résultant était de la même taille et comprenait 784 éléments.
Cependant, en travaillant avec des images de différentes tailles (hauteur et largeur) et en les transformant en tableaux unidimensionnels, nous obtenons des tableaux de différentes tailles.
Étant donné que les réseaux de neurones à l'entrée nécessitent des données de la même taille, il ne suffit pas de se contenter de la conversion en un tableau unidimensionnel de valeurs de pixels.
Pour résoudre les problèmes de classification des images, nous avons toujours recours à l'une des options pour unifier les données d'entrée - réduire la taille des images à des valeurs communes (redimensionnement).
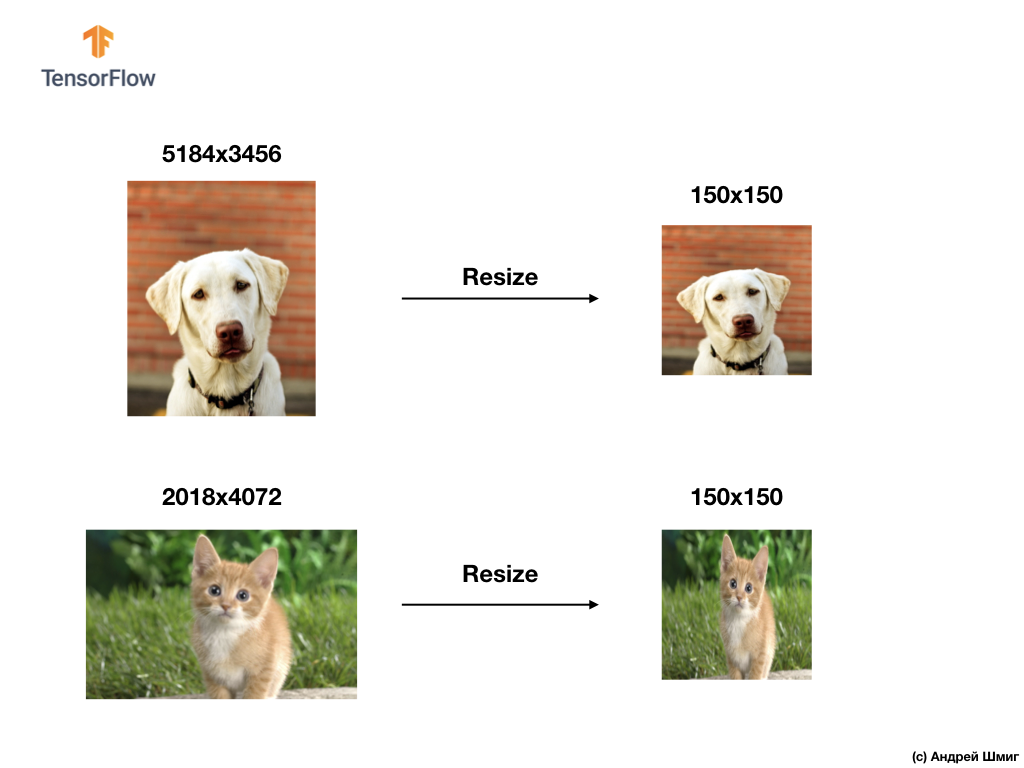
Dans ce didacticiel, nous recourrons à redimensionner toutes les images à des tailles de 150 pixels en hauteur et 150 pixels en largeur. En convertissant les images en une seule taille, nous garantissons ainsi que l'image de la bonne taille arrivera à l'entrée du réseau neuronal et, lorsqu'elle sera transférée sur une couche flatten , nous obtiendrons un tableau unidimensionnel de la même taille.
tf.keras.layers.Flatten(input_shape(150,150,1))
En conséquence, nous avons obtenu un tableau unidimensionnel composé de 150x150 = 22 500 valeurs (pixels).
Le prochain problème auquel nous serons confrontés sera celui des images couleur - couleur. Nous en parlerons dans la prochaine partie.
Images couleur. Partie 1
Afin de comprendre et de comprendre comment les réseaux de neurones convolutifs fonctionnent avec les images en couleur, nous devons approfondir le fonctionnement exact du SNA en général. Rafraîchissons ce que nous savons déjà.
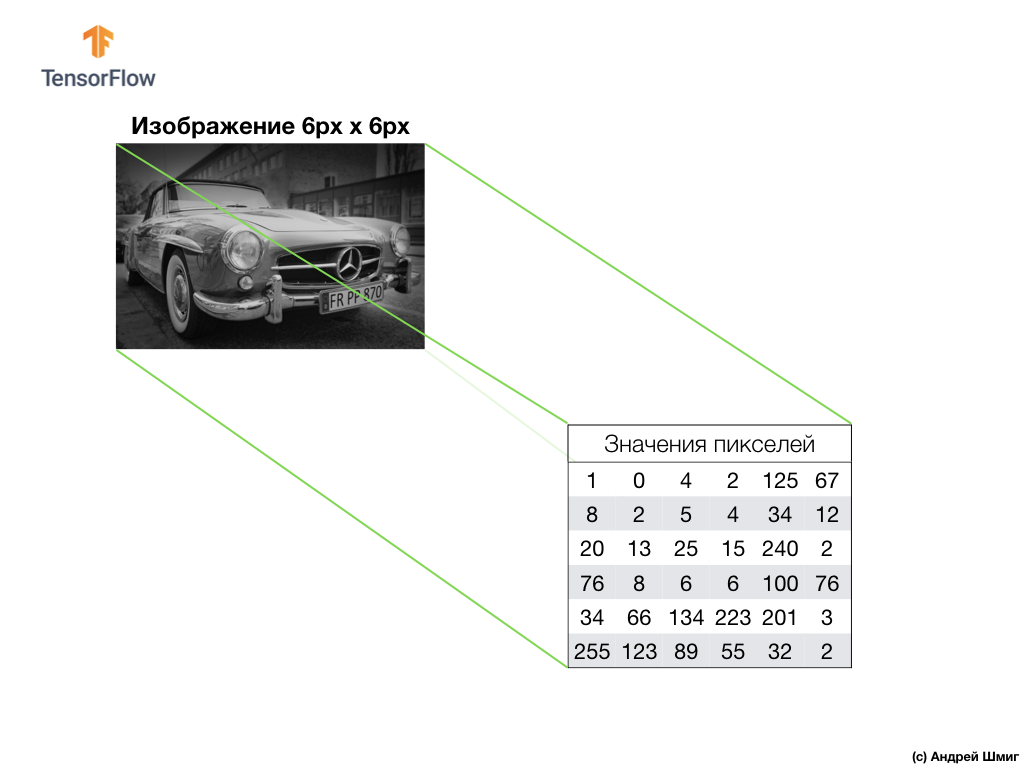
Un exemple ci-dessus est une image en niveaux de gris et comment l'ordinateur l'interprète comme un tableau bidimensionnel de valeurs de pixels.
Un exemple ci-dessous est une image, cette fois une couleur, et comment l'ordinateur l'interprète comme un tableau tridimensionnel de valeurs de pixels.
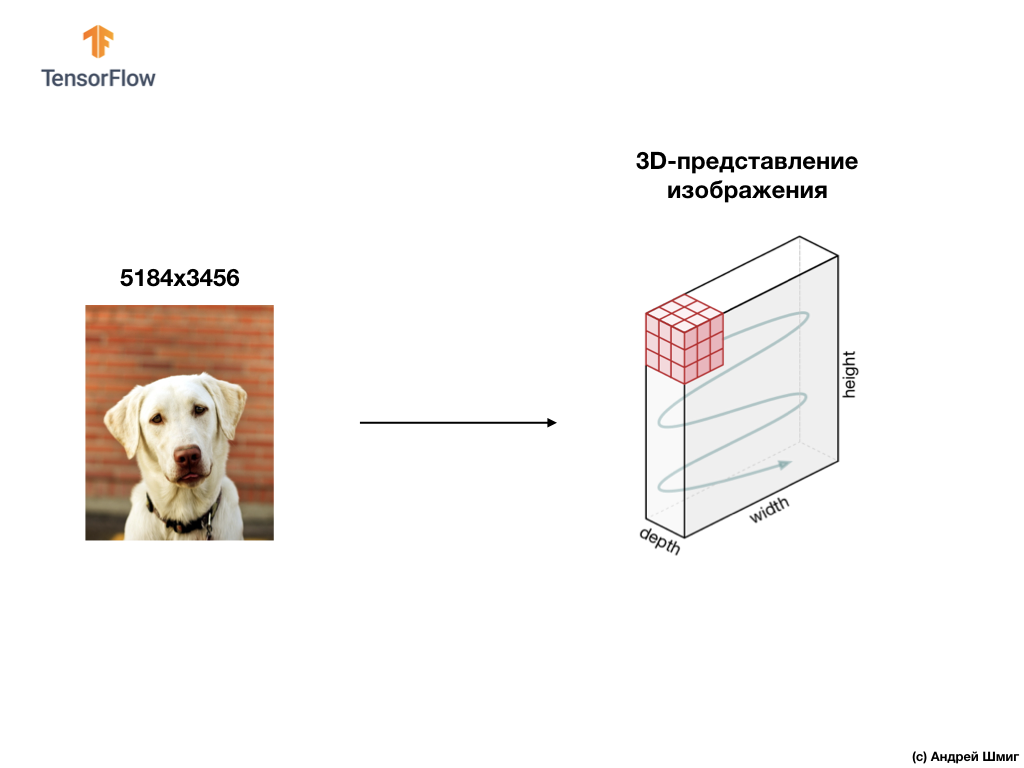
La hauteur et la largeur du réseau 3D seront déterminées par la hauteur et la largeur de l'image, et la profondeur (profondeur) détermine le nombre de canaux de couleur de l'image.
La plupart des images en couleur peuvent être représentées par trois canaux de couleur - rouge (rouge), vert (vert) et bleu (bleu).

Les images composées de canaux rouge, vert et bleu sont appelées images RVB. La combinaison de ces trois canaux donne une image couleur. Dans chacune des images RVB, chaque canal est représenté par un réseau bidimensionnel distinct de pixels.
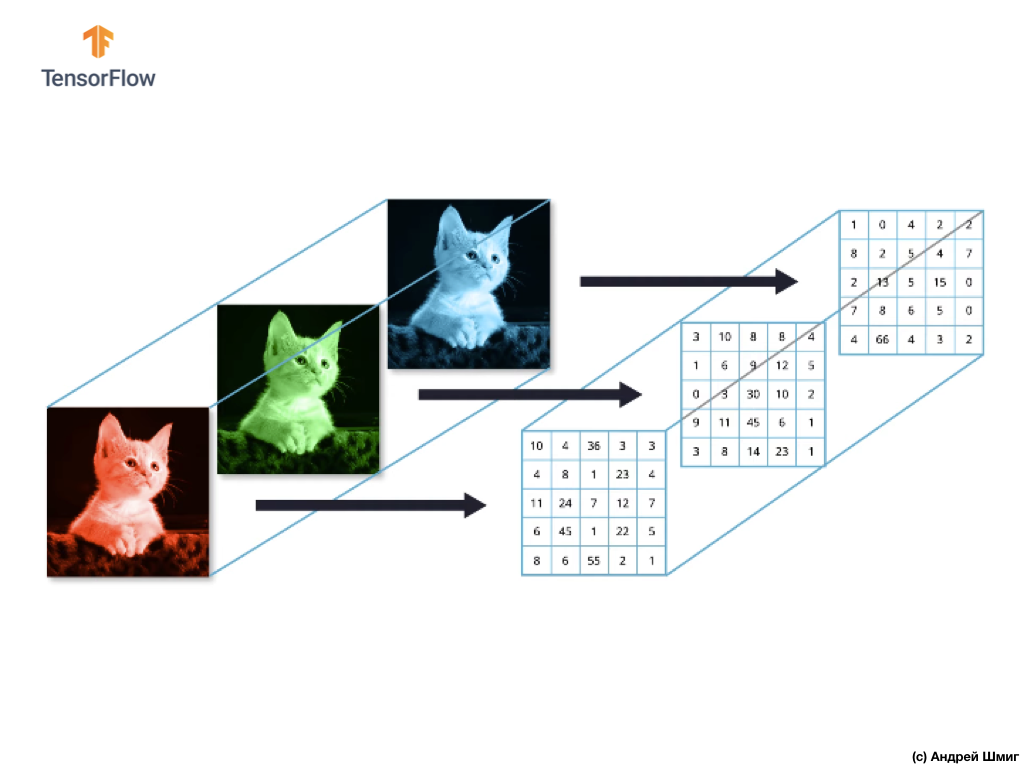
Puisque le nombre de canaux que nous avons est de trois, nous aurons donc trois tableaux bidimensionnels. Ainsi, une image couleur composée de 3 canaux de couleur aura la représentation suivante:

Images couleur. 2e partie
Ainsi, puisque notre image sera désormais composée de 3 couleurs, ce qui signifie que ce sera un tableau tridimensionnel de valeurs de pixels, alors notre code devra être modifié en conséquence.
Si vous regardez le code que nous avons utilisé dans notre dernière leçon lorsque nous avons résolu le problème de la classification des éléments de vêtements dans les images, nous pouvons voir que nous avons indiqué la dimension des données d'entrée:
model = Sequential() model.add(Conv2D(32, 3, padding='same', activation='relu', input_shape=(28,28,1)))
Les deux premiers paramètres du tuple (28,28,1) sont les valeurs de la hauteur et de la largeur de l'image. Les images du jeu de données Fashion MNIST mesuraient 28 x 28 pixels. Le dernier paramètre du tuple (28,28,1) indique le nombre de canaux de couleur. Dans le jeu de données Fashion MNIST, les images étaient uniquement dans les tons de gris - 1 canal de couleur.
Maintenant que la tâche est devenue un peu plus compliquée et que nos images de chats et de chiens sont devenues de tailles différentes (mais converties en une seule - 150x150 pixels) et contiennent 3 canaux de couleur, le tuple de valeurs devrait également être différent:
model = Sequential() model.add(Conv2D(16, 3, padding='same', activation='relu', input_shape=(150,150,3)))
Dans la partie suivante, nous verrons comment la convolution est calculée en présence de trois canaux de couleur dans l'image.
Opération de convolution sur des images couleur
Dans les leçons précédentes, nous avons appris à effectuer une opération de convolution sur des images en niveaux de gris. Mais comment effectuer une opération de convolution sur des images couleur? Commençons par répéter comment l'opération de convolution est effectuée sur les images en niveaux de gris.
Tout commence par un filtre (core) d'une certaine taille.
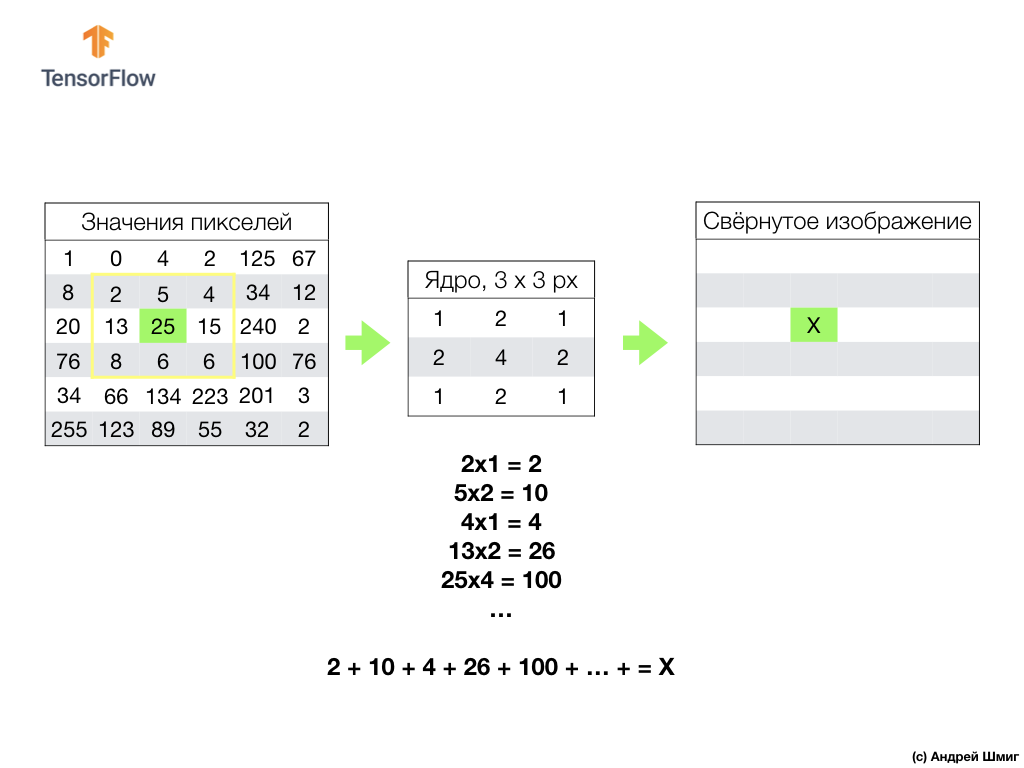
Le filtre est situé sur un pixel d'image spécifique à convertir, puis chaque valeur de filtre est multipliée par la valeur de pixel correspondante dans l'image et toutes ces valeurs sont additionnées. La valeur finale du pixel est définie dans la nouvelle image à l'endroit où se trouvait le pixel original converti. L'opération est répétée pour chaque pixel de l'image d'origine.
Il convient également de rappeler que pendant l'opération de convolution, afin de ne pas perdre d'informations aux bords de l'image, nous pouvons appliquer l'alignement et garnir les bords de l'image avec des zéros:

Voyons maintenant comment effectuer l'opération de convolution sur des images en couleur.
Tout comme lors de la conversion d'une image en nuances de gris, on commence par choisir la taille du filtre (core) d'une certaine taille.

La seule différence maintenant sera que maintenant le filtre lui-même sera en trois dimensions, et la valeur du paramètre de profondeur sera égale à la valeur du nombre de canaux de couleur dans l'image - 3 (dans notre cas, RVB). Pour chaque «couche» du canal de couleur, nous appliquerons également l'opération de convolution avec un filtre de la taille sélectionnée. Voyons comment ce sera un exemple.
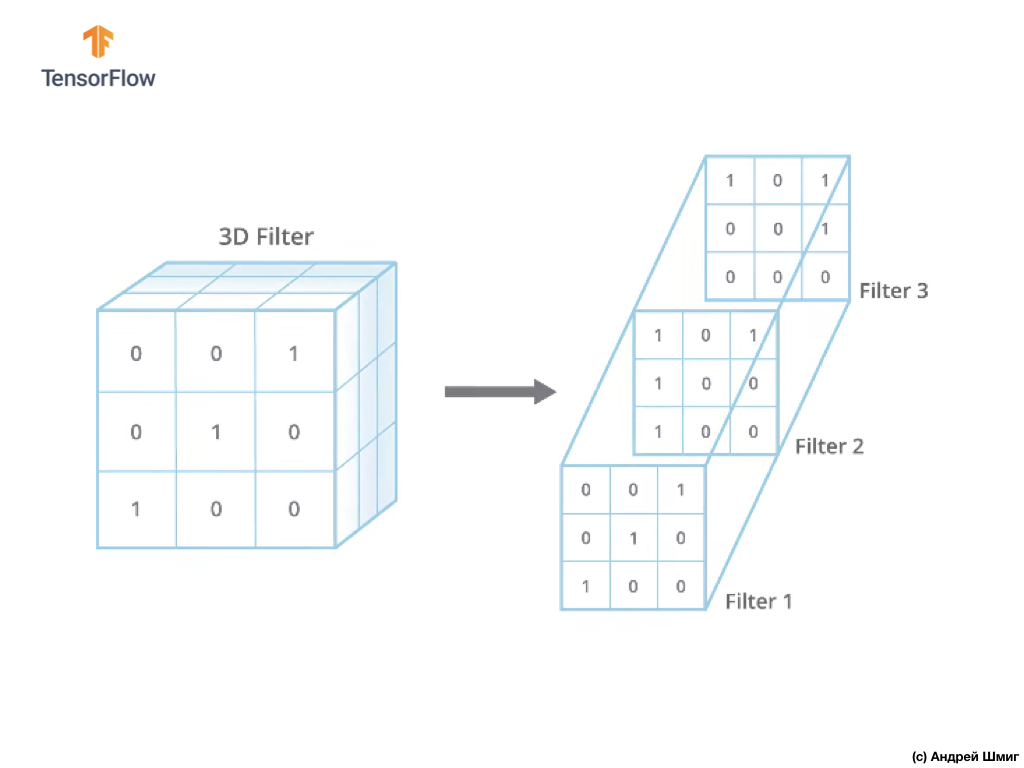
Imaginez que nous avons une image RVB et que nous voulons appliquer l'opération de convolution avec le prochain filtre 3D. Il convient de noter que notre filtre est composé de 3 filtres bidimensionnels. Par souci de simplicité, imaginons que notre image RVB mesure 5x5 pixels.

Rappelons également que chaque canal de couleur est un tableau bidimensionnel de valeurs de couleur de pixel.
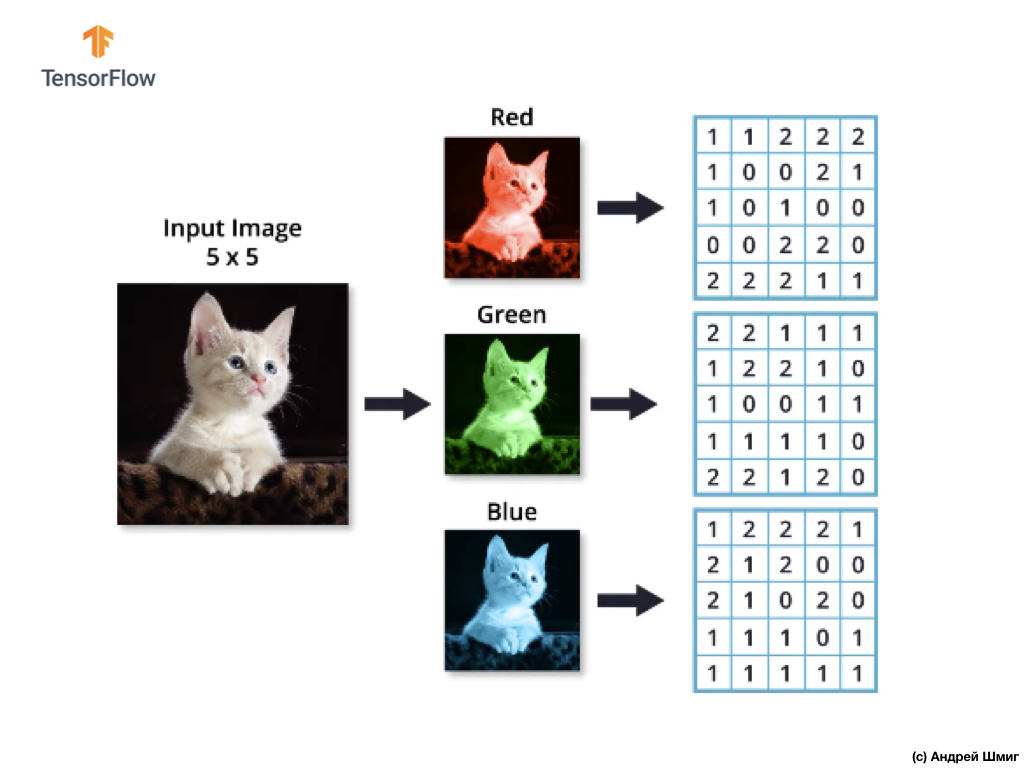
Comme pour l'opération de convolution sur des images dans des tons de gris, ainsi que sur des images en couleur, nous alignerons et compléterons l'image avec des zéros sur les bords pour éviter la perte d'informations aux bordures.
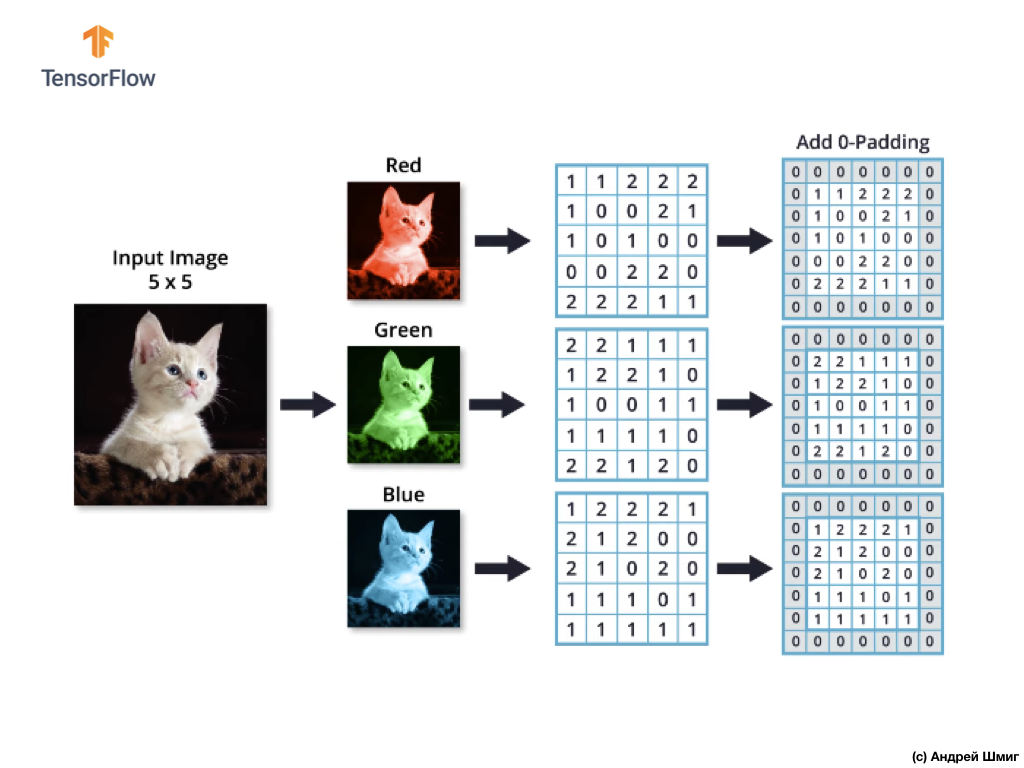
Nous sommes maintenant prêts pour l'opération de convolution!
Le mécanisme de convolution pour les images en couleur sera similaire au processus que nous avons effectué avec les images en niveaux de gris. La seule différence entre les opérations effectuées sur les images en niveaux de gris et en couleur est que l'opération de convolution doit maintenant être effectuée 3 fois pour chaque canal de couleur.
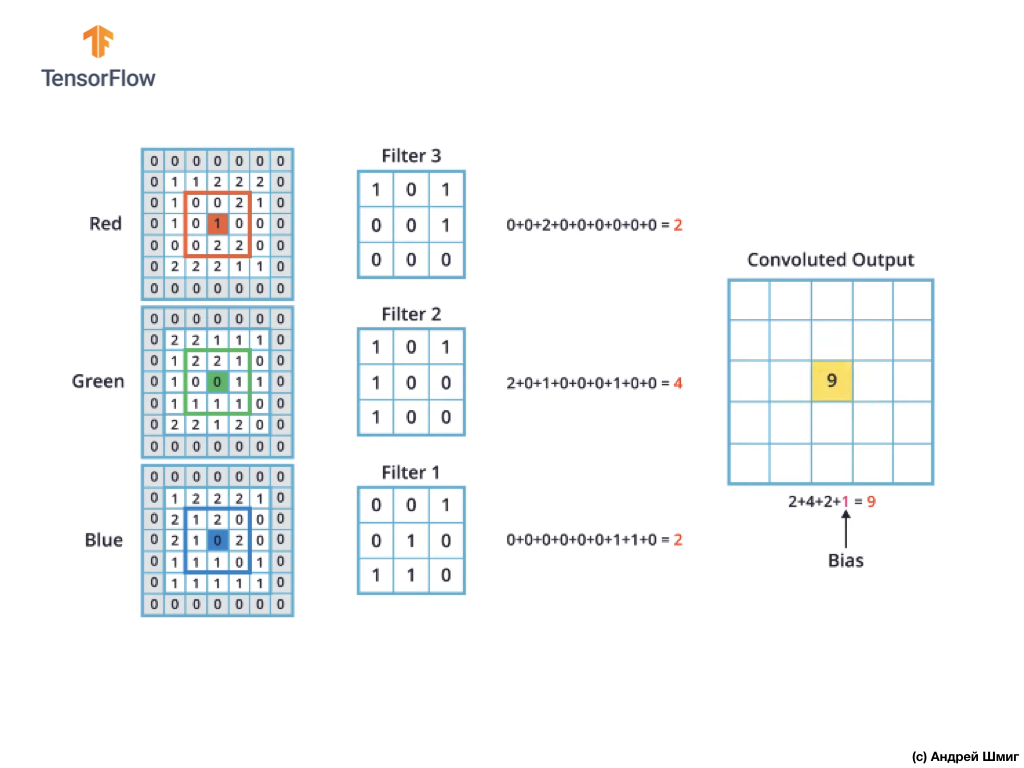
Ensuite, après avoir effectué l'opération de convolution sur chaque canal de couleur, additionnez les trois valeurs obtenues et ajoutez-y 1 (la valeur standard utilisée pour effectuer des opérations de ce type). La nouvelle valeur résultante est fixée à la même position dans la nouvelle image, position dans laquelle se trouvait le pixel converti actuel.
Nous effectuons une opération de conversion similaire (une opération de convolution) pour chaque pixel de notre image d'origine et pour chaque canal de couleur.
Dans cet exemple particulier, l'image résultante a la même taille en hauteur et en largeur que notre image RVB d'origine.
Comme vous pouvez le voir, l'application de l'opération de convolution avec un seul filtre 3D entraîne une seule valeur de sortie.
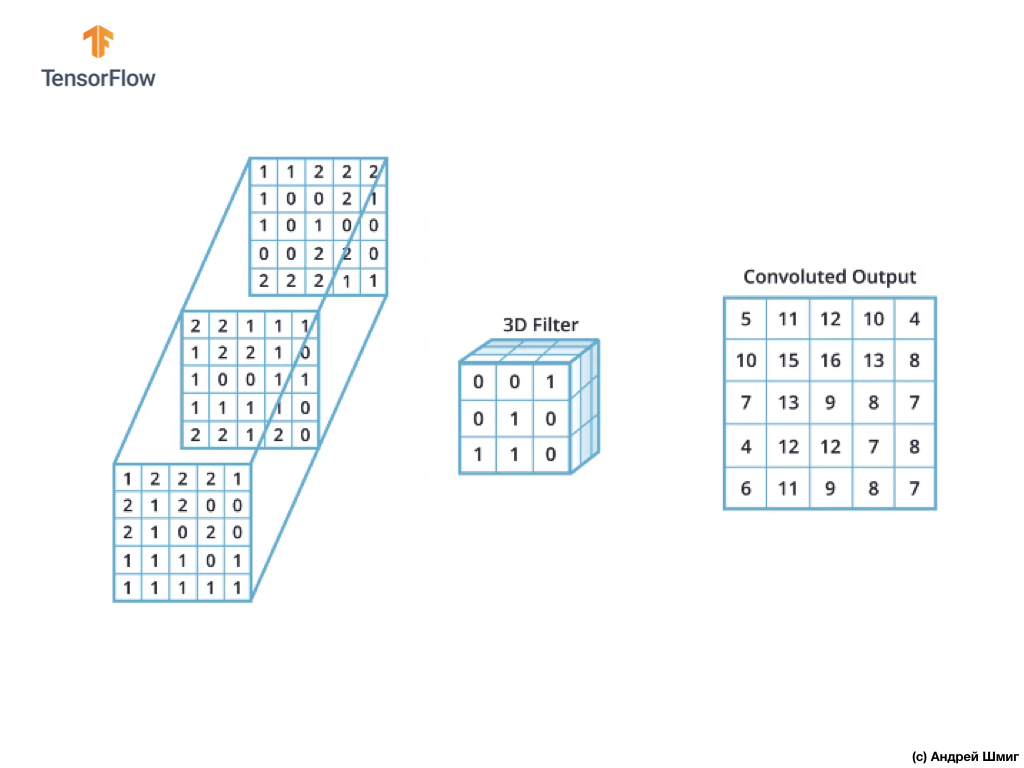
Cependant, lorsque vous travaillez avec des réseaux de neurones convolutifs, il est courant d'utiliser plusieurs filtres 3D. Si nous utilisons plus d'un filtre 3D, le résultat sera plusieurs valeurs de sortie - chaque valeur est le résultat d'un filtre.
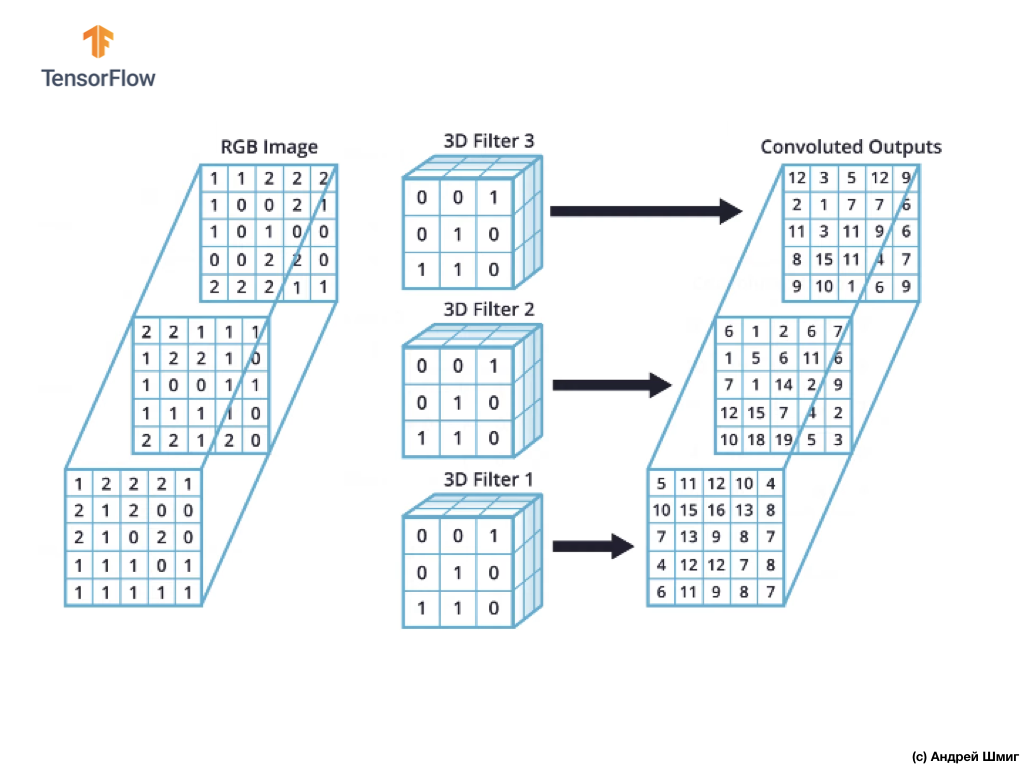
Dans notre exemple ci-dessus, puisque nous utilisons 3 filtres, la représentation 3D résultante aura une profondeur de 3 - chaque couche correspondra à la valeur de sortie de la conversion d'un filtre au-dessus de l'image avec tous ses canaux de couleur.
Si, par exemple, au lieu de 3 filtres, nous décidions d'utiliser 16, la représentation 3D de sortie contiendrait 16 couches de profondeur.
Dans le code, nous pouvons contrôler le nombre de filtres créés en passant la valeur appropriée pour le paramètre filters :
tf.keras.layers.Conv2D(filters, kernel_size, ...)
Nous pouvons également spécifier la taille du filtre via le paramètre kernel_size . Par exemple, pour créer 3 filtres de taille 3x3, comme c'était le cas dans notre exemple ci-dessus, nous pouvons écrire le code comme suit:
tf.keras.layers.Conv2D(3, (3,3), ...)
N'oubliez pas que lors de la formation du réseau neuronal convolutionnel, les valeurs des filtres 3D seront mises à jour pour minimiser la valeur de la fonction de perte.
Maintenant que nous savons comment effectuer l'opération de convolution sur des images en couleur, il est temps de comprendre comment appliquer l'opération de sous-échantillonnage au résultat maximal par la valeur maximale (le même regroupement maximal).
L'opération de sous-échantillonnage par la valeur maximale dans les images en couleur
Voyons maintenant comment effectuer l'opération de sous-échantillonnage à la valeur maximale dans les images en couleur. En fait, l'opération de sous-échantillonnage par la valeur maximale fonctionne de la même manière qu'elle fonctionne avec des images dans des tons de gris avec une légère différence - l'opération de sous-échantillonnage doit maintenant être appliquée à chaque représentation de sortie que nous avons reçue à la suite de l'application de filtres. Regardons un exemple.
Pour simplifier, imaginons que notre vue de sortie ressemble à ceci:
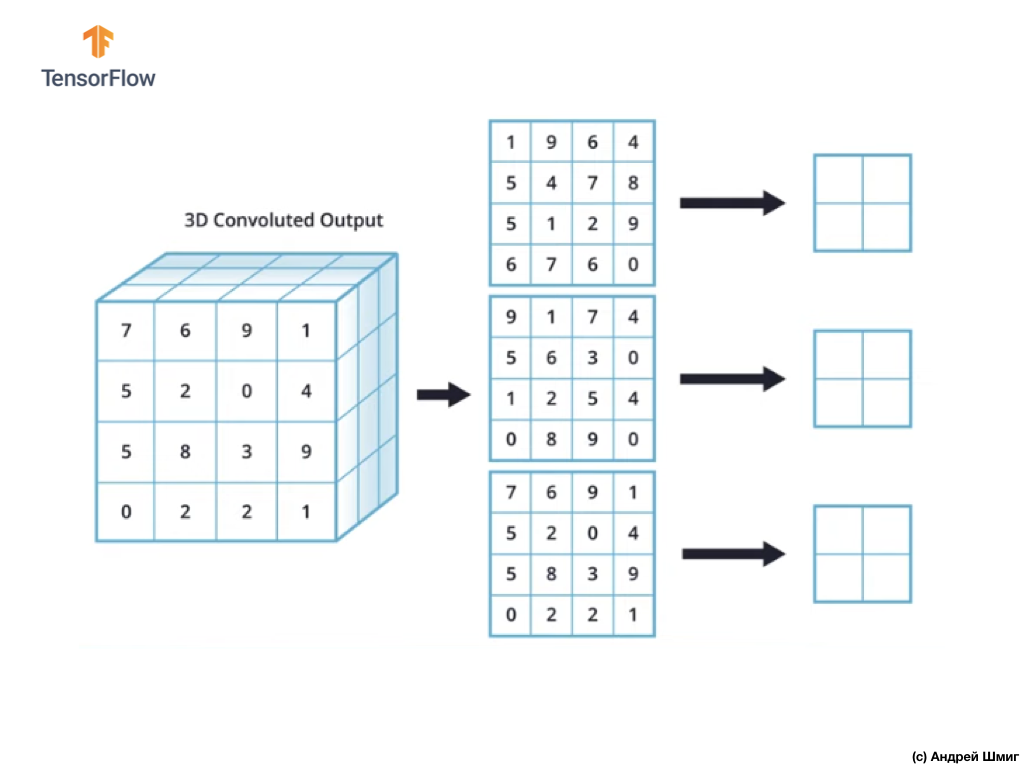
Comme précédemment, nous utiliserons un noyau 2x2 et l'étape 2 pour effectuer l'opération de sous-échantillonnage à la valeur maximale. L'opération de sous-échantillonnage par la valeur maximale commence par «l'installation» d'un noyau 2x2 dans le coin supérieur gauche de chaque représentation de sortie (la représentation qui a été obtenue après l'application de l'opération de convolution).

Nous pouvons maintenant démarrer l'opération de sous-échantillonnage à la valeur maximale. Par exemple, dans notre première représentation de sortie, les valeurs suivantes sont tombées dans le noyau 2x2 - 1, 9, 5, 4. Puisque la valeur maximale dans ce noyau est 9, c'est elle qui est envoyée à la nouvelle représentation de sortie. Une opération similaire est répétée pour chaque représentation d'entrée.
Par conséquent, nous devrions obtenir le résultat suivant:

Après avoir effectué l'opération de sous-échantillonnage par la valeur maximale, le résultat est 3 tableaux bidimensionnels, chacun étant 2 fois plus petit que la représentation d'entrée d'origine.
Ainsi, dans ce cas particulier, lors de l'exécution de l'opération de sous-échantillonnage par la valeur maximale sur la représentation d'entrée tridimensionnelle, nous obtenons une représentation de sortie tridimensionnelle de la même profondeur, mais avec les valeurs de hauteur et de largeur moitié des valeurs initiales.
C'est donc toute la théorie dont nous aurons besoin pour poursuivre nos travaux. Voyons maintenant comment cela fonctionne dans le code!
CoLab: chats et chiens
CoLab original en anglais est disponible à ce lien .
CoLab en russe est disponible sur ce lien .
Dans ce tutoriel, nous verrons comment catégoriser les images de chats et de chiens. Nous allons développer un classificateur d'images en utilisant le modèle tf.keras.Sequential et utiliser tf.keras.Sequential pour charger les données.
Idées à couvrir dans cette partie:
Nous allons acquérir une expérience pratique dans le développement d'un classificateur et développer une compréhension intuitive des concepts suivants:
- Création d'un modèle de flux de données ( pipelines d'entrée de données ) à l'aide de la classe
tf.keras.preprocessing.image.ImageDataGenerator (Comment travailler efficacement avec des données sur disque en interaction avec le modèle?) - Recyclage - qu'est-ce que c'est et comment le déterminer?
Avant de commencer ...
Avant de démarrer le code dans l'éditeur, nous vous recommandons de réinitialiser tous les paramètres dans Runtime -> Tout réinitialiser dans le menu supérieur. Une telle action aidera à éviter les problèmes de manque de mémoire, si vous avez travaillé en parallèle ou travaillez avec plusieurs éditeurs.
Importer des packages
Commençons par importer les packages dont vous avez besoin:
os - lire des fichiers et des structures de répertoires;numpy - pour certaines opérations matricielles en dehors de TensorFlow;matplotlib.pyplot - traçage et affichage d'images à partir d'un ensemble de données de test et de validation.
from __future__ import absolute_import, division, print_function, unicode_literals import os import matplotlib.pyplot as plt import numpy as np
Importer TensorFlow :
import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
Chargement des données
Nous commençons le développement de notre classificateur en chargeant un ensemble de données. L'ensemble de données que nous utilisons est une version filtrée de l'ensemble de données Dogs vs Cats du service Kaggle (au final, cet ensemble de données est fourni par Microsoft Research).
Dans le passé, CoLab et moi-même utilisions un ensemble de données du module de données TensorFlow lui-même, ce qui est extrêmement pratique pour le travail et les tests. Dans ce CoLab, cependant, nous utiliserons la classe tf.keras.preprocessing.image.ImageDataGenerator pour lire les données du disque. Par conséquent, nous devons d'abord télécharger l'ensemble de données Dog VS Cats et le décompresser.
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip' zip_dir = tf.keras.utils.get_file('cats_and_dogs_filterted.zip', origin=_URL, extract=True)
L'ensemble de données que nous avons téléchargé a la structure suivante:
cats_and_dogs_filtered |__ train |______ cats: [cat.0.jpg, cat.1.jpg, cat.2.jpg ...] |______ dogs: [dog.0.jpg, dog.1.jpg, dog.2.jpg ...] |__ validation |______ cats: [cat.2000.jpg, cat.2001.jpg, cat.2002.jpg ...] |______ dogs: [dog.2000.jpg, dog.2001.jpg, dog.2002.jpg ...]
Pour obtenir une liste complète des répertoires, vous pouvez utiliser la commande suivante:
zip_dir_base = os.path.dirname(zip_dir) !find $zip_dir_base -type d -print
En conséquence, nous obtenons quelque chose de similaire:
/root/.keras/datasets /root/.keras/datasets/cats_and_dogs_filtered /root/.keras/datasets/cats_and_dogs_filtered/train /root/.keras/datasets/cats_and_dogs_filtered/train/dogs /root/.keras/datasets/cats_and_dogs_filtered/train/cats /root/.keras/datasets/cats_and_dogs_filtered/validation /root/.keras/datasets/cats_and_dogs_filtered/validation/dogs /root/.keras/datasets/cats_and_dogs_filtered/validation/cats
Attribuez maintenant les bons chemins aux répertoires avec les ensembles de données pour la formation et la validation des variables:
base_dir = os.path.join(os.path.dirname(zip_dir), 'cats_and_dogs_filtered') train_dir = os.path.join(base_dir, 'train') validation_dir = os.path.join(base_dir, 'validation') train_cats_dir = os.path.join(train_dir, 'cats') train_dogs_dir = os.path.join(train_dir, 'dogs') validation_cats_dir = os.path.join(validation_dir, 'cats') validation_dogs_dir = os.path.join(validation_dir, 'dogs')
Comprendre les données et leur structure
Voyons combien d'images de chats et de chiens nous avons dans les ensembles de données de test et de validation (répertoires).
num_cats_tr = len(os.listdir(train_cats_dir)) num_dogs_tr = len(os.listdir(train_dogs_dir)) num_cats_val = len(os.listdir(validation_cats_dir)) num_dogs_val = len(os.listdir(validation_dogs_dir)) total_train = num_cats_tr + num_dogs_tr total_val = num_cats_val + num_dogs_val
print(' : ', num_cats_tr) print(' : ', num_dogs_tr) print(' : ', num_cats_val) print(' : ', num_dogs_val) print('--') print(' : ', total_train) print(' : ', total_val)
La sortie du dernier bloc sera la suivante:
: 1000 : 1000 : 500 : 500 -- : 2000 : 1000
Définition des paramètres du modèle
Pour plus de commodité, nous placerons l'installation des variables dont nous avons besoin pour le traitement des données et la formation des modèles dans une annonce distincte:
BATCH_SIZE = 100
Préparation des données
Avant que les images puissent être utilisées comme entrée pour notre réseau, elles doivent être converties en tenseurs avec des valeurs à virgule flottante. Liste des étapes à suivre pour ce faire:
- Lire des images à partir du disque
- Décoder le contenu de l'image et convertir au format souhaité en tenant compte du profil RVB
- Convertir en tenseurs avec des valeurs à virgule flottante
- Normaliser les valeurs du tenseur de l'intervalle de 0 à 255 à l'intervalle de 0 à 1, car les réseaux de neurones fonctionnent mieux avec de petites valeurs d'entrée.
Heureusement, toutes ces opérations peuvent être effectuées à l'aide de la classe tf.keras.preprocessing.image.ImageDataGenerator .
Nous pouvons faire tout cela en utilisant plusieurs lignes de code:
train_image_generator = ImageDataGenerator(rescale=1./255) validation_image_generator = ImageDataGenerator(rescale=1./255)
Après avoir défini des générateurs pour un ensemble de données de test et de validation, la méthode flow_from_directory chargera les images du disque, normalisera les données et redimensionnera les images avec une seule ligne de code:
train_data_gen = train_image_generator.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE,IMG_SHAPE), class_mode='binary')
Conclusion:
Found 2000 images belonging to 2 classes.
Générateur de données de validation:
val_data_gen = validation_image_generator.flow_from_directory(batch_size=BATCH_SIZE, directory=validation_dir, shuffle=False, target_size=(IMG_SHAPE,IMG_SHAPE), class_mode='binary')
Conclusion:
Found 1000 images belonging to 2 classes.
Visualisez les images de l'ensemble d'entraînement.
Nous pouvons visualiser des images d'un ensemble de données de formation en utilisant matplotlib :
sample_training_images, _ = next(train_data_gen)
La fonction next renvoie un bloc d'images de l'ensemble de données. Un bloc est un tuple de (plusieurs images, plusieurs étiquettes) . Pour le moment, nous allons supprimer les étiquettes, car nous n'en avons pas besoin - nous nous intéressons aux images elles-mêmes.
plotImages(sample_training_images[:5])
Exemple de sortie (2 images au lieu des 5):

Création de modèle
Nous décrivons le modèle
Le modèle se compose de 4 blocs de convolution, après chacun desquels il y a un bloc avec une couche de sous-échantillon. Ensuite, nous avons une couche entièrement connectée avec 512 neurones et une relu activation relu . Le modèle donnera une distribution de probabilité pour deux classes - chiens et chats - en utilisant softmax .
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(IMG_SHAPE, IMG_SHAPE, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(2, activation='softmax') ])
Compilation de modèles
Comme précédemment, nous utiliserons l'optimiseur adam . Nous utilisons sparse_categorical_crossentropy comme fonction de perte. Nous voulons également surveiller la précision du modèle à chaque itération de formation, nous passons donc la valeur de accuracy au paramètre metrics :
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Vue modèle
Jetons un coup d'œil à la structure de notre modèle par niveaux en utilisant la méthode de résumé :
model.summary()
Conclusion:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 148, 148, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 72, 72, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 34, 34, 128) 73856 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 15, 15, 128) 147584 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0 _________________________________________________________________ flatten (Flatten) (None, 6272) 0 _________________________________________________________________ dense (Dense) (None, 512) 3211776 _________________________________________________________________ dense_1 (Dense) (None, 2) 1026 ================================================================= Total params: 3,453,634 Trainable params: 3,453,634 Non-trainable params: 0
!
( ImageDataGenerator ) fit_generator fit :
EPOCHS = 100 history = model.fit_generator( train_data_gen, steps_per_epoch=int(np.ceil(total_train / float(BATCH_SIZE))), epochs=EPOCHS, validation_data=val_data_gen, validation_steps=int(np.ceil(total_val / float(BATCH_SIZE))) )
:
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8,8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label=' ') plt.plot(epochs_range, val_acc, label=' ') plt.legend(loc='lower right') plt.title(' ') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label=' ') plt.plot(epochs_range, val_loss, label=' ') plt.legend(loc='upper right') plt.title(' ') plt.savefig('./foo.png') plt.show()
Conclusion:
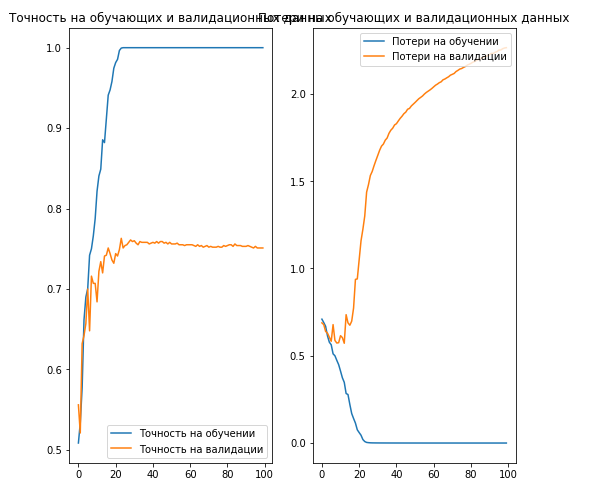
, 70% ( ).
. , .
… .
... et appel à l'action standard - inscrivez-vous, mettez un plus et partagez :)
YouTube
Télégramme
VKontakte