
Le terme Big Data est gâché par l'exagération fantastique moderne de nouvelles choses. Alors que l'IA asservit les gens et que la blockchain construit une économie idéale - les mégadonnées vous permettront de tout savoir sur tout le monde et de voir l'avenir.
Mais la réalité, comme toujours, est plus ennuyeuse et pragmatique. Il n'y a pas de magie dans les mégadonnées - comme il n'y en a nulle part - il y a simplement tellement d'informations et de connexions entre les différentes données qu'il faut trop de temps pour traiter et analyser tout à l'ancienne.
De nouvelles méthodes font leur apparition. De nouvelles professions les accompagnent. Le doyen
du département d'analyse des Big Data de GeekBrains Sergey Shirkin a expliqué quel genre de profession ils étaient, où ils étaient nécessaires, ce qu'ils devaient faire et ce qu'ils devaient pouvoir faire. Quels outils sont utilisés et combien paient-ils généralement aux spécialistes?
Qu'est-ce que le Big Data?
La question «comment appeler les mégadonnées» est plutôt confuse. Même dans les revues scientifiques, les descriptions diffèrent. Quelque part, des millions d'observations sont considérées comme des données «normales», et ailleurs, des centaines de milliers sont appelées grandes, car chacune des observations a mille signes. Par conséquent, ils ont décidé de diviser conditionnellement les données en trois parties - petite, moyenne et grande - selon le principe le plus simple: le volume qu'elles occupent.
Les petites données représentent quelques gigaoctets. Moyen - tout sur un téraoctet. Les mégadonnées concernent un pétaoctet. Mais cela n'a pas dissipé la confusion. Par conséquent, le critère est encore plus simple: tout ce qui ne tient pas sur le même serveur est du big data.
Les petites, moyennes et grandes données ont des principes de fonctionnement différents. Les mégadonnées sont généralement stockées dans un cluster sur plusieurs serveurs à la fois. Pour cette raison, même des actions simples sont plus compliquées.
Par exemple, une tâche simple consiste à trouver la valeur moyenne d'une quantité. S'il s'agit de petites données, nous additionnons et divisons simplement par la quantité. Et dans les mégadonnées, nous ne pouvons pas collecter toutes les informations de tous les serveurs à la fois. C'est compliqué. Souvent, vous n'avez pas besoin d'extraire les données pour vous-même, mais envoyez un programme distinct à chaque serveur. Après le travail de ces programmes, des résultats intermédiaires sont formés et la valeur moyenne est déterminée par eux.
 Sergey Shirkin
Sergey ShirkinQuelles entreprises de Big Data
Le premier avec le big data a commencé à fonctionner avec les opérateurs mobiles et les moteurs de recherche. Les moteurs de recherche sont devenus de plus en plus des requêtes, et le texte est plus lourd que les chiffres. Travailler avec un paragraphe de texte prend plus de temps qu'avec une transaction financière. L'utilisateur s'attend à ce que le moteur de recherche termine la demande en une fraction de seconde - il est inacceptable qu'il fonctionne même pendant une demi-minute. Par conséquent, les moteurs de recherche ont commencé à travailler avec la parallélisation lorsqu'ils travaillaient avec des données.
Un peu plus tard, divers organismes financiers et détaillants se sont joints. Les transactions elles-mêmes ne sont pas si volumineuses, mais les mégadonnées apparaissent en raison du grand nombre de transactions.
La quantité de données augmente du tout. Par exemple, les banques avaient beaucoup de données auparavant, mais elles n'avaient pas toujours besoin de principes de travail, comme pour les grandes. Ensuite, les banques ont commencé à travailler davantage avec les données clients. Ils ont commencé à proposer des dépôts, des prêts et des tarifs différents, et ils ont commencé à analyser les transactions de plus près. Cela nécessitait déjà des moyens rapides de travailler.
Désormais, les banques veulent analyser non seulement les informations internes, mais aussi les informations externes. Ils veulent recevoir des données du même commerce de détail, ils veulent savoir sur quoi une personne dépense de l'argent. Sur la base de ces informations, ils essaient de faire des offres commerciales.
Maintenant, toutes les informations sont liées les unes aux autres. Commerce de détail, banques, opérateurs de télécommunications et même moteurs de recherche - tout le monde s'intéresse désormais aux données des autres.
Ce qu'un spécialiste du Big Data devrait être
Étant donné que les données sont situées sur un cluster de serveurs, une infrastructure plus complexe est utilisée pour travailler avec eux. Cela impose un lourd fardeau à la personne qui travaille avec elle - le système doit être très fiable.
Rendre un serveur fiable est facile. Mais quand il y en a plusieurs, la probabilité de chute augmente proportionnellement au nombre, et la responsabilité de l'ingénieur de données qui travaille avec ces données augmente également.
L'analyste doit comprendre qu'il peut toujours recevoir des données incomplètes ou même incorrectes. Il a écrit le programme, a fait confiance à ses résultats, puis a découvert qu'en raison de la chute d'un serveur sur mille, une partie des données était déconnectée et toutes les conclusions étaient incorrectes.
Prenons, par exemple, une recherche de texte. Disons que tous les mots sont classés par ordre alphabétique sur plusieurs serveurs (si nous parlons très simplement et conditionnellement). Et l'un d'eux s'est déconnecté, tous les mots de la lettre «K» ont disparu. La recherche a cessé de donner le mot «Cinéma». Toutes les nouvelles de l'actualité disparaissent, et l'analyste fait une fausse conclusion que les gens ne sont plus intéressés par les cinémas.
Par conséquent, un spécialiste des mégadonnées devrait connaître les principes de travail des niveaux les plus bas - serveurs, écosystèmes, planificateurs de tâches - aux programmes de plus haut niveau - bibliothèques d'apprentissage automatique, analyse statistique, etc. Il doit comprendre les principes du fer, du matériel informatique et de tout ce qui est configuré dessus.
Pour le reste, vous devez tout savoir de la même manière que lorsque vous travaillez avec de petites données. Nous avons besoin de mathématiques, nous devons pouvoir programmer, et nous connaissons particulièrement bien les algorithmes de l'informatique distribuée, pour pouvoir les appliquer aux principes habituels de travail avec les données et l'apprentissage automatique.
Quels outils sont utilisés
Comme les données sont stockées sur le cluster, une infrastructure spéciale est nécessaire pour travailler avec. L'écosystème le plus populaire est Hadoop. De nombreux systèmes différents peuvent y travailler: bibliothèques spéciales, planificateurs, outils d'apprentissage automatique, et bien plus encore. Mais tout d'abord, ce système est nécessaire pour faire face à de grandes quantités de données dues à l'informatique distribuée.
Par exemple, nous recherchons le tweet le plus populaire parmi les données cassées sur un millier de serveurs. Sur un serveur, nous ferions juste une table et c'est tout. Ici, nous pouvons faire glisser toutes les données vers nous-mêmes et les recompter. Mais ce n'est pas vrai, car depuis très longtemps.
Par conséquent, il existe un Hadoop avec des paradigmes Map Reduce et le framework Spark. Au lieu de tirer des données pour eux-mêmes, ils envoient des sections de programme à ces données. Le travail va en parallèle, en mille fils. Ensuite, nous obtenons une sélection de milliers de serveurs sur la base desquels vous pouvez choisir le tweet le plus populaire.
Map Reduce est un paradigme plus ancien; Spark est plus récent. Avec son aide, les données sont extraites des clusters et des modèles d'apprentissage automatique y sont intégrés.
Quels métiers existent dans le domaine du big data
Les deux professions principales sont les analystes et les ingénieurs de données.
L'analyste travaille principalement avec des informations. Il s'intéresse aux données tabulaires, il est engagé dans les modèles. Ses responsabilités incluent l'agrégation, la purification, l'addition et la visualisation des données. Autrement dit, l'analyste est le lien entre les informations brutes et les affaires.
L'analyste a deux principaux domaines de travail. Premièrement, il peut transformer les informations reçues, tirer des conclusions et les présenter de manière compréhensible.
La seconde est que les analystes développent des applications qui fonctionneront et produiront automatiquement le résultat. Par exemple, faites quotidiennement des prévisions sur le marché des valeurs mobilières.
L'ingénieur de données est une spécialité de niveau inférieur. Il s'agit d'une personne qui doit assurer le stockage, le traitement et la livraison des informations à l'analyste. Mais là où il y a de l'approvisionnement et du nettoyage - leurs responsabilités peuvent se chevaucher.
L'ingénieur des données obtient tout le travail acharné. Si les systèmes tombent en panne ou si l'un des serveurs a disparu du cluster, il se connecte. C'est un travail très responsable et stressant. Le système peut s'arrêter le week-end et après les heures de bureau, et l'ingénieur doit prendre des mesures rapides.
Ce sont deux professions principales, mais il y en a d'autres. Ils apparaissent lorsque des algorithmes de calcul parallèle sont ajoutés aux tâches liées à l'intelligence artificielle. Par exemple, un ingénieur PNL. Il s'agit d'un programmeur engagé dans le traitement du langage naturel, en particulier dans les cas où vous avez besoin non seulement de trouver des mots, mais de saisir la signification du texte. Ces ingénieurs écrivent des programmes pour les chatbots et les systèmes conversationnels, les assistants vocaux et les centres d'appels automatisés.
Il y a des situations où il faut classer des milliards d'images, modérer, filtrer les excès et en trouver une similaire. Ces professions se chevauchent davantage avec la vision par ordinateur.
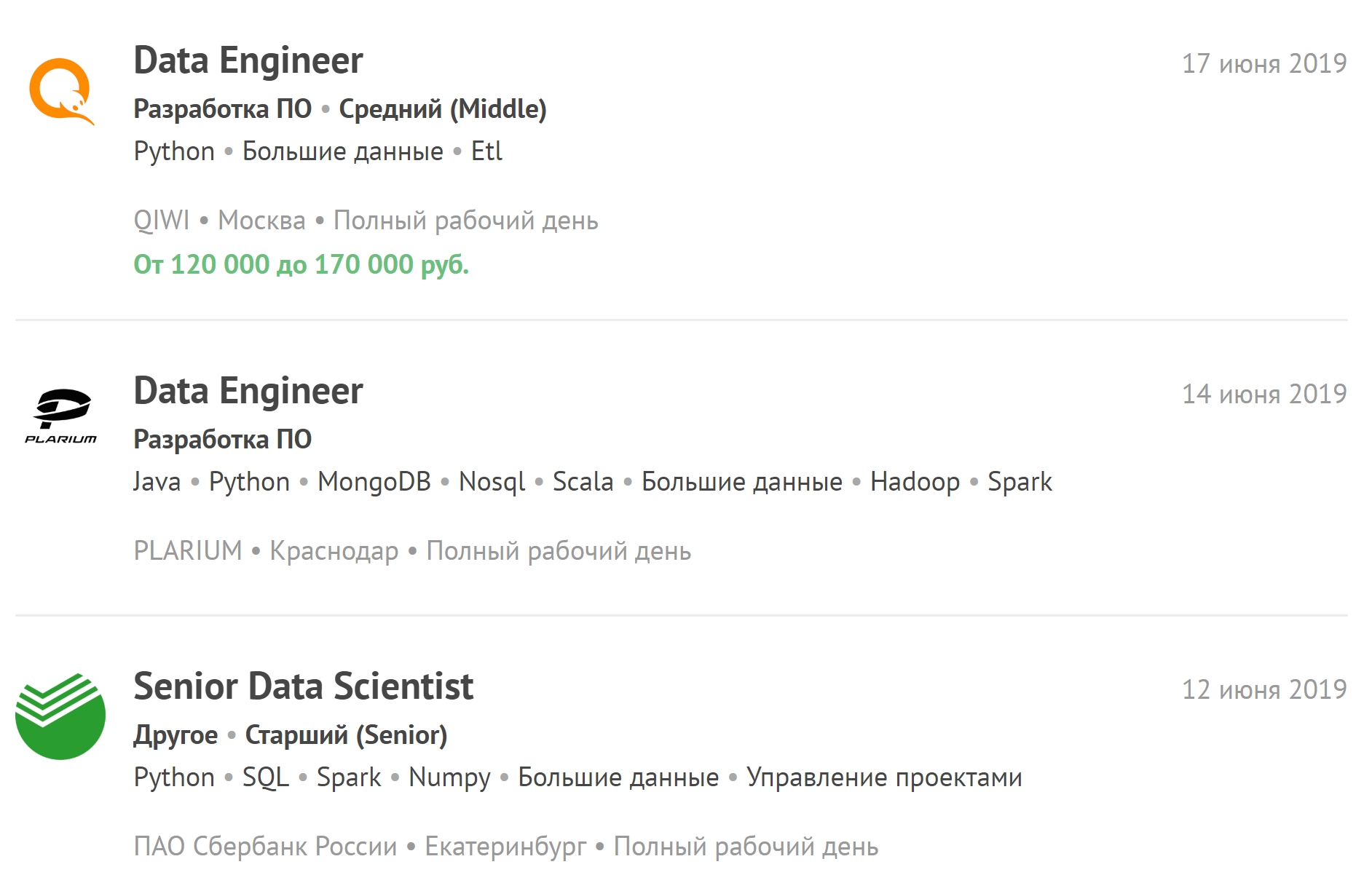
Vous pouvez consulter les dernières offres d'emploi liées au Big Data et vous abonner à de nouvelles offres d'emploi.
Combien de temps dure la formation
Nous étudions depuis un an et demi. Ils sont divisés en six trimestres. Dans certains, l'accent est mis sur la programmation, dans d'autres - sur le travail avec des bases de données et dans le troisième - sur les mathématiques.
En revanche, par exemple, de la faculté d'IA, il y a moins de mathématiques. L'accent n'est pas mis sur l'analyse mathématique et l'algèbre linéaire. La connaissance des algorithmes de calcul distribué est plus nécessaire que les principes de la matanalyse.
Mais un an et demi ne suffit pour un vrai travail avec le big data que si la personne a de l'expérience avec des données ordinaires et en général en informatique. Il est recommandé aux étudiants restants après l'obtention du diplôme de travailler avec des données petites et moyennes. Ce n'est qu'après cela que les spécialistes pourront travailler avec des grands. Après la formation, vous devez travailler en tant que scientifique des données - appliquer l'apprentissage automatique sur différentes quantités de données.
Lorsqu'une personne obtient un emploi dans une grande entreprise - même si elle a de l'expérience - le plus souvent, elle ne sera pas autorisée à utiliser immédiatement les mégadonnées, car le prix d'une erreur y est beaucoup plus élevé. Les erreurs dans les algorithmes peuvent ne pas être détectées immédiatement, ce qui entraînera des pertes importantes.
Quel salaire est jugé adéquat pour les spécialistes du big data
Maintenant, il y a une très grande pénurie de personnel parmi les ingénieurs de données. Le travail est difficile, beaucoup de responsabilités incombent à une personne, beaucoup de stress. Par conséquent, un spécialiste ayant une expérience moyenne reçoit environ deux cent mille. Junior - de cent à deux cents.
Un analyste de données peut avoir un salaire de départ légèrement inférieur. Mais il n'y a pas de travail en plus du temps de travail, et il ne sera pas appelé en dehors des heures de travail en raison de cas d'urgence.

Selon le cultivateur de salaires «My Circle», le salaire moyen des spécialistes dont les professions sont associées aux mégadonnées est de 139 400 roubles . Un quart des spécialistes gagnent plus de 176 000 roubles. Un dixième - plus de 200 000 roubles.
Comment se préparer aux entretiens
Pas besoin de se plonger dans un seul sujet. Lors des entretiens, ils posent des questions sur les statistiques, l'apprentissage automatique, la programmation. Ils peuvent poser des questions sur les structures de données, les algorithmes et les cas de la vie réelle: le serveur est tombé en panne, un accident s'est produit - comment y remédier? Il peut y avoir des questions sur le sujet - quelque chose qui est plus proche des affaires.
Et si une personne est trop profonde dans un calcul et qu'elle n'a pas fait une simple tâche de programmation lors de l'entretien, les chances de trouver un emploi sont réduites. Il vaut mieux avoir un niveau moyen dans chaque direction que de bien se montrer dans l'une et échouer complètement dans l'autre.
Il y a une liste de questions posées dans 80% des entretiens. S'il s'agit d'apprentissage automatique, ils poseront certainement des questions sur la descente de gradient. Si statistiques - vous devrez parler de tests de corrélation et d'hypothèses. La programmation est susceptible de donner une petite tâche de complexité moyenne. Et vous pouvez facilement mettre la main sur des tâches - il suffit de les résoudre davantage.
Où acquérir de l'expérience par vous-même
Python peut être tiré sur
Pitontutyu , travailler avec la base de données - sur
SQL-EX . Il existe des tâches pour lesquelles, en pratique, ils apprennent à faire des demandes.
Mathématiques supérieures -
Mathprofi . Vous pouvez y obtenir des informations claires sur l'analyse mathématique, les statistiques et l'algèbre linéaire. Et si ça ne va pas avec le programme scolaire, c'est
youclever.org .
L'informatique distribuée ne fonctionnera qu'en pratique. Premièrement, cela nécessite une infrastructure, et deuxièmement, les algorithmes peuvent rapidement devenir obsolètes. Maintenant, quelque chose de nouveau apparaît constamment.
Quelles sont les tendances discutées par la communauté
Un autre domaine se renforce progressivement, ce qui peut entraîner une augmentation rapide de la quantité de données - l'Internet des objets (IoT). Des données de ce type proviennent des capteurs d'appareils connectés en réseau, et le nombre de capteurs au début de la prochaine décennie devrait atteindre des dizaines de milliards.
Les appareils sont très différents - des appareils électroménagers aux véhicules et machines industrielles, dont le flux continu d'informations nécessitera une infrastructure supplémentaire et un grand nombre de spécialistes hautement qualifiés. Cela signifie que dans un avenir proche, il y aura une pénurie aiguë d'ingénieurs de données et d'analystes de Big Data.