
La communauté moderne des développeurs est désormais plus que jamais soumise à la mode et aux tendances, et cela est particulièrement vrai pour le monde du développement front-end. Nos cadres et nos nouvelles pratiques sont la principale valeur, et la plupart des CV, des offres d'emploi et des programmes de conférence consistent à les répertorier. Et bien que le développement d'idées et d'outils ne soit pas négatif en soi, en raison du désir constant des développeurs de suivre les tendances insaisissables, nous avons commencé à oublier l'importance des connaissances théoriques générales sur l'architecture d'application.
La prévalence de la valeur de réglage sur la connaissance de la théorie et des meilleures pratiques a conduit au fait que la plupart des nouveaux projets ont aujourd'hui un niveau de maintenance extrêmement faible, créant ainsi des inconvénients importants pour les développeurs (la complexité constamment élevée de l'étude et de la modification du code) et pour les clients (taux bas et coût de développement élevé).
Afin d'influencer au moins d'une manière ou d'une autre la situation actuelle, je voudrais aujourd'hui vous expliquer ce qu'est une bonne architecture, comment elle s'applique aux interfaces Web et, surtout, comment elle évolue au fil du temps.
NB : Comme exemples dans l'article, seuls les cadres que l'auteur a traités directement seront utilisés, et une attention particulière sera accordée à React et Redux ici. Mais, malgré cela, bon nombre des idées et des principes décrits ici sont de nature générale et peuvent être plus ou moins correctement projetés sur d'autres technologies de développement d'interface.Architecture pour les nuls
Commençons par le terme lui-même. En termes simples, l'architecture de tout système est la définition de ses composants et le schéma d'interaction entre eux. Il s'agit d'une sorte de fondement conceptuel au-dessus duquel la mise en œuvre sera construite ultérieurement.
La tâche de l'architecture est de satisfaire aux exigences externes du système conçu. Ces exigences varient d'un projet à l'autre et peuvent être assez spécifiques, mais dans le cas général elles visent à faciliter les processus de modification et d'extension des solutions développées.
Quant à la qualité de l'architecture, elle s'exprime généralement dans les propriétés suivantes:
-
Accompagnement : la prédisposition déjà mentionnée du système à étudier et à modifier (la difficulté de détecter et de corriger les erreurs, d'étendre les fonctionnalités, d'adapter la solution à un autre environnement ou conditions)
-
Remplaçabilité : la possibilité de modifier la mise en œuvre de n'importe quel élément du système sans affecter les autres éléments
-
Testabilité : la capacité de vérifier le bon fonctionnement de l'élément (la capacité de contrôler l'élément et d'observer son état)
-
Portabilité : la capacité de réutiliser un élément dans d'autres systèmes
-
Facilité d'utilisation : le degré global de commodité du système lorsqu'il est utilisé par l'utilisateur final
Une mention distincte est également faite de l'un des principes clés de la construction d'une architecture de qualité: le principe de
séparation des préoccupations . Elle consiste dans le fait que tout élément du système doit être exclusivement responsable d'une seule tâche (appliquée, accessoirement, au code d'application: voir
principe de responsabilité unique ).
Maintenant que nous avons une idée du concept d'architecture, voyons quels modèles de conception architecturale peuvent nous offrir dans le contexte des interfaces.
Les trois mots les plus importants
MVC (Model-View-Controller) est l'un des modèles de développement d'interface les plus connus, dont le concept clé est de diviser la logique d'interface en trois parties distinctes:
1.
Modèle - est responsable de la réception, du stockage et du traitement des données
2.
Vue - responsable de la visualisation des données
3.
Contrôleur - contrôle le modèle et la vue
Ce modèle comprend également une description du schéma d'interaction entre eux, mais ici, cette information sera omise du fait qu'après un certain temps, le grand public a été présenté avec une modification améliorée de ce modèle appelé MVP (Model-View-Presenter), qui ce schéma original interaction grandement simplifiée:
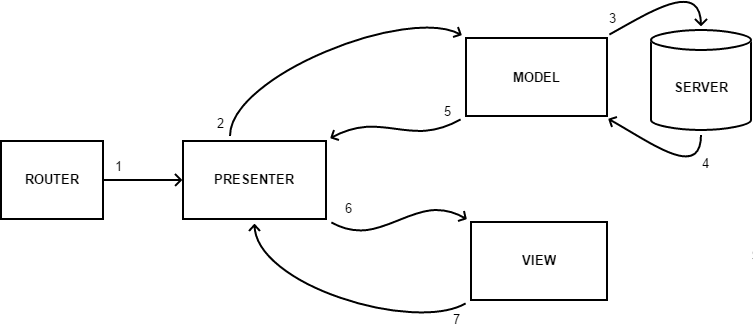
Comme nous parlons spécifiquement des interfaces Web, nous avons utilisé un autre élément assez important qui accompagne généralement la mise en œuvre de ces modèles - un routeur. Sa tâche est de lire l'URL et d'appeler les présentateurs qui lui sont associés.
Le schéma ci-dessus fonctionne comme suit:
1. Le routeur lit l'URL et appelle le présentateur associé
2-5. Le présentateur se tourne vers Model et en obtient les données nécessaires.
6. Le présentateur transfère les données du modèle vers la vue, ce qui implémente sa visualisation.
7. Lors de l'interaction de l'utilisateur avec l'interface, View en informe le présentateur, ce qui nous ramène au deuxième point
Comme la pratique l'a montré, MVC et MVP ne sont pas une architecture idéale et universelle, mais ils font encore une chose très importante - ils indiquent trois domaines de responsabilité clés, sans lesquels aucune interface ne peut être implémentée sous une forme ou une autre.
NB: Dans l'ensemble, les concepts de contrôleur et de présentateur signifient la même chose, et la différence de nom n'est nécessaire que pour différencier les modèles mentionnés, qui ne diffèrent que dans la mise en œuvre des communications .MVC et rendu serveur
Malgré le fait que MVC est un modèle pour implémenter un client, il trouve également son application sur le serveur. De plus, c'est dans le cadre du serveur qu'il est le plus simple de démontrer les principes de son fonctionnement.
Dans les cas où il s'agit de sites d'informations classiques, où la tâche du serveur web est de générer des pages HTML pour l'utilisateur, MVC nous permet également d'organiser une architecture d'application assez concise:
- Le routeur lit les données de la requête HTTP reçue
(GET / user-profile / 1) et appelle le contrôleur associé
(UsersController.getProfilePage (1))- Le contrôleur appelle le modèle pour obtenir les informations nécessaires de la base de données
(UsersModel.get (1))- Le contrôleur transmet les données reçues à View
(View.render ('users / profile', user)) et en reçoit le balisage HTML, qui les retransmet au client
Dans ce cas, View est généralement implémenté comme suit:
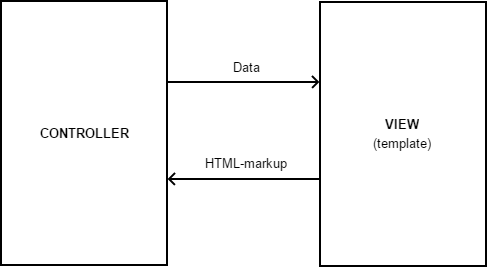
const templates = { 'users/profile': ` <div class="user-profile"> <h2>{{ name}}</h2> <p>E-mail: {{ email }}</p> <p> Projects: {{#each projects}} <a href="/projects/{{id}}">{{name}}</a> {{/each}} </p> <a href=/user-profile/1/edit>Edit</a> </div> ` }; class View { render(templateName, data) { const htmlMarkup = TemplateEngine.render(templates[templateName], data); return htmlMarkup; } }
NB: Le code ci-dessus est intentionnellement simplifié pour être utilisé comme exemple. Dans les projets réels, les modèles sont exportés vers des fichiers séparés et passent par l'étape de compilation avant utilisation (voir Handlebars.compile () ou _.template () ).Ici, les moteurs dits de modèle sont utilisés, qui nous fournissent des outils pour une description pratique des modèles de texte et des mécanismes pour y substituer des données réelles.
Une telle approche de la mise en œuvre de View démontre non seulement une séparation idéale des responsabilités, mais fournit également un degré élevé de testabilité: pour vérifier l'exactitude de l'affichage, il nous suffit de comparer la ligne de référence avec la ligne que nous avons obtenue du moteur de modèle.
Ainsi, en utilisant MVC, nous obtenons une architecture presque parfaite, où chacun de ses éléments a un objectif très spécifique, une connectivité minimale et également un niveau élevé de testabilité et de portabilité.
Quant à l'approche avec la génération de balisage HTML à l'aide d'outils serveur, en raison du faible UX, cette approche a progressivement commencé à être remplacée par SPA.
Backbone et MVP
Backbone.js a été l'un des premiers frameworks à apporter pleinement la logique d'affichage au client. L'implémentation de Router, Presenter et Model est assez standard, mais la nouvelle implémentation de View mérite notre attention:

const UserProfile = Backbone.View.extend({ tagName: 'div', className: 'user-profile', events: { 'click .button.edit': 'openEditDialog', }, openEditDialog: function(event) {
De toute évidence, la mise en œuvre de la cartographie est devenue beaucoup plus compliquée - l'écoute des événements du modèle et du DOM, ainsi que la logique de leur traitement, a été ajoutée à la normalisation élémentaire. De plus, pour afficher les changements dans l'interface, il est hautement souhaitable de ne pas restituer complètement la vue, mais de faire un travail plus fin avec des éléments DOM spécifiques (généralement en utilisant jQuery), ce qui nécessitait d'écrire beaucoup de code supplémentaire.
En raison de la complication générale de l'implémentation de View, ses tests sont devenus plus compliqués - puisque maintenant nous travaillons directement avec l'arborescence DOM, pour les tests, nous devons utiliser des outils supplémentaires qui fournissent ou émulent l'environnement du navigateur.
Et les problèmes avec la nouvelle implémentation de View ne se sont pas arrêtés là:
En plus de ce qui précède, il est assez difficile à utiliser imbriqué dans chaque autre vue. Au fil du temps, ce problème a été résolu avec l'aide de
Regions dans
Marionette.js , mais avant cela, les développeurs devaient inventer leurs propres astuces pour résoudre ce problème plutôt simple et souvent survenu.
Et le dernier. Les interfaces ainsi développées étaient prédisposées aux données désynchronisées - puisque tous les modèles existaient isolés au niveau de différents présentateurs, puis lors du changement de données dans une partie de l'interface, ils ne se mettaient généralement pas à jour dans une autre.
Mais, malgré ces problèmes, cette approche était plus que viable, et le développement mentionné précédemment de Backbone sous la forme de
Marionette peut toujours être appliqué avec succès pour le développement de SPA.
Réagir et annuler
C'est difficile à croire, mais au moment de sa sortie initiale,
React.js a suscité beaucoup de scepticisme parmi la communauté des développeurs. Ce scepticisme était si grand que pendant longtemps le texte suivant a été publié sur le site officiel:
Donnez-lui cinq minutes
React défie beaucoup de sagesse conventionnelle, et à première vue, certaines idées peuvent sembler folles.
Et cela malgré le fait que, contrairement à la plupart de ses concurrents et prédécesseurs, React n'était pas un cadre à part entière et n'était qu'une petite bibliothèque pour faciliter l'affichage des données dans le DOM:
React est une bibliothèque JavaScript pour créer des interfaces utilisateur par Facebook et Instagram. Beaucoup de gens choisissent de penser à React comme le V dans MVC.
Le concept principal que React nous offre est le concept d'un composant, qui, en fait, nous offre une nouvelle façon d'implémenter View:
class User extends React.Component { handleEdit() {
React était incroyablement agréable à utiliser. Parmi ses avantages indéniables figuraient à ce jour:
1)
Déclaration et réactivité . Il n'est plus nécessaire de mettre à jour manuellement le DOM lors de la modification des données affichées.
2)
La composition des composants . Construire et explorer l'arborescence de View est devenu une action complètement élémentaire.
Mais, malheureusement, React a un certain nombre de problèmes. L'un des plus importants est le fait que React n'est pas un framework à part entière et, par conséquent, ne nous offre aucun type d'architecture d'application ou d'outils à part entière pour sa mise en œuvre.
Pourquoi est-ce écrit en défauts? Oui, parce que maintenant React est la solution la plus populaire pour développer des applications Web (
preuve ,
une autre preuve et une autre preuve ), c'est un point d'entrée pour les nouveaux développeurs front-end, mais en même temps n'offre ni ne promeut aucun l'architecture, ni les approches et les meilleures pratiques pour la construction d'applications complètes. De plus, il invente et promeut ses propres approches personnalisées comme
HOC ou
Hooks , qui ne sont pas utilisées en dehors de l'écosystème React. Par conséquent, chaque application React résout les problèmes typiques à sa manière et ne le fait généralement pas de la manière la plus correcte.
Ce problème peut être démontré à l'aide de l'une des erreurs les plus courantes des développeurs React, qui consiste en l'abus de composants:
Si le seul outil dont vous disposez est un marteau, tout commence à ressembler à un clou.
Avec leur aide, les développeurs résolvent une gamme de tâches complètement impensable qui vont bien au-delà de la portée de la visualisation des données. En fait, avec l'aide de composants, ils implémentent absolument tout - des
requêtes multimédias du CSS au
routage .
React et Redux
Le rétablissement de l'ordre dans la structure des applications React a été grandement facilité par l'apparition et la vulgarisation de
Redux . Si React est une vue de MVP, Redux nous a proposé une variante assez pratique de Model.
L'idée principale de Redux est le transfert de données et la logique de travailler avec elles dans un seul entrepôt de données centralisé - le soi-disant magasin. Cette approche résout complètement le problème de duplication et de désynchronisation des données, dont nous avons parlé un peu plus tôt, et offre également de nombreuses autres commodités, qui incluent, entre autres, la facilité d'étudier l'état actuel des données dans l'application.
Une autre caractéristique tout aussi importante est le mode de communication entre le Store et les autres parties de l'application. Au lieu d'accéder directement au magasin ou à ses données, il nous est proposé d'utiliser les soi-disant actions (objets simples décrivant l'événement ou la commande), qui fournissent un faible niveau de
couplage lâche entre le magasin et la source de l'événement, augmentant ainsi considérablement le degré de maintenabilité du projet. Ainsi, Redux oblige non seulement les développeurs à utiliser des approches architecturales plus correctes, mais vous permet également de profiter de divers avantages de la recherche d'
événements - maintenant, dans le processus de débogage, nous pouvons facilement afficher l'historique des actions dans l'application, leur impact sur les données et, si nécessaire, toutes ces informations peuvent être exportées , ce qui est également extrêmement utile lors de l'analyse des erreurs de production.
Le schéma général de l'application utilisant React / Redux peut être représenté comme suit:
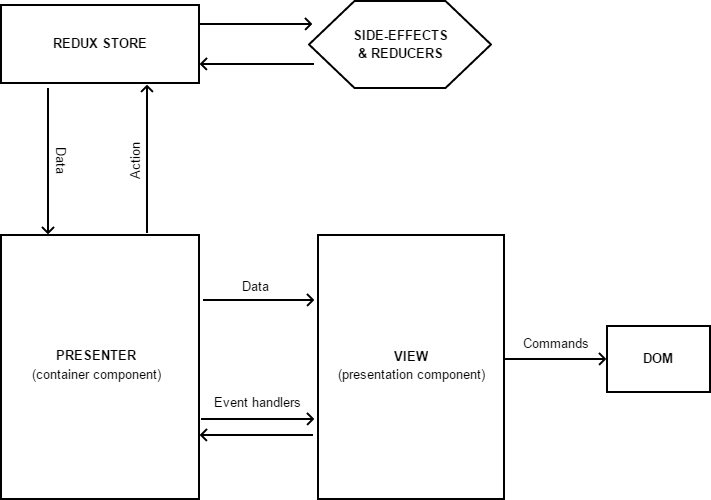
Les composants React sont toujours responsables de l'affichage des données. Idéalement, ces composants doivent être propres et fonctionnels, mais si nécessaire, ils peuvent bien avoir un état local et une logique associée (par exemple, pour implémenter le masquage / affichage d'un élément spécifique ou le prétraitement de base d'une action utilisateur).
Lorsqu'un utilisateur effectue une action dans l'interface, le composant appelle simplement la fonction de gestionnaire correspondante, qu'il reçoit de l'extérieur avec les données à afficher.
Les composants dits conteneurs agissent en tant que présentateurs pour nous - ce sont eux qui exercent un contrôle sur les composants d'affichage et leur interaction avec les données. Ils sont créés à l'aide de la fonction de
connexion , qui étend les fonctionnalités du composant qui lui est transmis, en ajoutant un abonnement pour modifier les données dans le magasin et en nous permettant de déterminer les données et les gestionnaires d'événements qui doivent lui être transmis.
Et si tout est clair avec les données ici (nous mappons simplement les données du stockage aux «accessoires» attendus), alors je voudrais m'attarder sur les gestionnaires d'événements plus en détail - ils envoient non seulement des actions au magasin, mais peuvent également contenir une logique supplémentaire pour le traitement de l'événement - par exemple, inclure la création de branches, effectuer des redirections automatiques et effectuer tout autre travail spécifique au présentateur.
Un autre point important concernant les composants de conteneur: du fait qu'ils sont créés via le HOC, les développeurs décrivent assez souvent les composants d'affichage et les composants de conteneur dans un seul module et exportent uniquement le conteneur. Ce n'est pas la bonne approche, car pour la possibilité de tester et de réutiliser le composant d'affichage, il doit être complètement séparé du conteneur et de préférence retiré dans un fichier séparé.
Eh bien, la dernière chose que nous n'avons pas encore envisagée est le magasin. Il nous sert d'implémentation plutôt spécifique du modèle et se compose de plusieurs composants: State (un objet contenant toutes nos données), Middleware (un ensemble de fonctions qui prétraitent toutes les Actions reçues), Reducer (une fonction qui modifie les données dans State) et certains ou un gestionnaire d'effets secondaires chargé d'exécuter des opérations asynchrones (accès à des systèmes externes, etc.).
Le problème le plus courant ici est la forme de notre État. Officiellement, Redux ne nous impose aucune restriction et ne donne aucune recommandation quant à ce que devrait être cet objet. Les développeurs peuvent y stocker absolument toutes les données (y compris l'
état des formulaires et des
informations du routeur ), ces données peuvent être de tout type (il n'est
pas interdit de stocker même des fonctions et des instances d'objets) et ont n'importe quel niveau d'imbrication. En fait, cela conduit à nouveau au fait que d'un projet à l'autre, nous obtenons une approche complètement différente de l'utilisation de l'État, ce qui provoque une fois de plus une certaine confusion.
Pour commencer, nous convenons que nous n'avons pas à conserver absolument toutes les données d'application dans l'État - cela est clairement
indiqué par la documentation . Bien que le stockage d'une partie des données à l'intérieur de l'état des composants crée certains inconvénients lors de la navigation dans l'historique des actions pendant le processus de débogage (l'état interne des composants reste toujours inchangé), le transfert de ces données à l'État crée encore plus de difficultés - cela augmente considérablement sa taille et nécessite la création de plus Actions et réducteurs.
En ce qui concerne le stockage de toute autre donnée locale dans State, nous avons généralement affaire à une configuration d'interface générale, qui est un ensemble de paires clé-valeur. Dans ce cas, nous pouvons facilement le faire avec un objet simple et un réducteur pour celui-ci.
Et si nous parlons de stockage de données provenant de sources externes, alors sur la base du fait que dans le développement d'interfaces dans la grande majorité des cas, nous avons affaire à un CRUD classique, alors pour stocker des données à partir du serveur, il est logique de traiter l'État comme un SGBDR: les clés sont le nom et derrière eux se trouvent des tableaux d'objets chargés (
sans imbrication ) et des informations facultatives (par exemple, le nombre total d'enregistrements sur le serveur pour créer la pagination). La forme générale de ces données doit être la plus uniforme possible - cela nous permettra de simplifier la création de réducteurs pour chaque type de ressource:
const getModelReducer = modelName => (models = [], action) => { const isModelAction = modelActionTypes.includes(action.type); if (isModelAction && action.modelName === modelName) { switch (action.type) { case 'ADD_MODELS': return collection.add(action.models, models); case 'CHANGE_MODEL': return collection.change(action.model, models); case 'REMOVE_MODEL': return collection.remove(action.model, models); case 'RESET_STATE': return []; } } return models; };
Eh bien, un autre point que je voudrais aborder dans le contexte de l'utilisation de Redux est la mise en œuvre des effets secondaires.
Tout d'abord, oubliez complètement
Redux Thunk - la transformation des actions proposées par lui en fonctions avec effets secondaires, bien que ce soit une solution de travail, mais elle mélange les concepts de base de notre architecture et réduit à néant ses avantages.
Redux Saga nous offre une approche beaucoup plus correcte de la mise en œuvre des effets secondaires, bien qu'il y ait des questions concernant sa mise en œuvre technique.
Ensuite - essayez d'unifier autant que possible vos effets secondaires qui accèdent au serveur. Comme le formulaire d'état et les réducteurs, nous pouvons presque toujours implémenter la logique de création de requêtes vers le serveur à l'aide d'un seul gestionnaire. Par exemple, dans le cas de l'API RESTful, cela peut être réalisé en écoutant des actions généralisées comme:
{ type: 'CREATE_MODEL', payload: { model: 'reviews', attributes: { title: '...', text: '...' } } }
... et en créant sur eux les mêmes requêtes HTTP généralisées:
POST /api/reviews { title: '...', text: '...' }
En suivant consciemment tous les conseils ci-dessus, vous pouvez obtenir, sinon une architecture idéale, au moins près d'elle.
Un avenir radieux
Le développement moderne des interfaces Web a vraiment franchi une étape importante et nous vivons maintenant à une époque où une partie importante des principaux problèmes ont déjà été résolus d'une manière ou d'une autre. Mais cela ne signifie pas du tout qu'à l'avenir il n'y aura pas de nouvelles révolutions.
Si vous essayez de regarder vers l'avenir, nous verrons très probablement ce qui suit:
1. Approche par composants sans JSXLe concept de composants s'est avéré extrêmement efficace et, très probablement, nous verrons leur vulgarisation encore plus grande. Mais JSX lui-même peut et doit mourir. Oui, c'est vraiment très pratique à utiliser, mais, néanmoins, ce n'est ni un standard généralement accepté ni un code JS valide. Les bibliothèques d'implémentation d'interfaces, aussi performantes soient-elles, ne doivent pas inventer de nouvelles normes, qui doivent ensuite être implémentées à maintes reprises dans toutes les boîtes à outils de développement possibles.
2. Conteneurs d'État sans ReduxL'utilisation d'un entrepôt de données centralisé, proposé par Redux, a également été une solution extrêmement réussie et devrait à l'avenir devenir une sorte de norme dans le développement des interfaces, mais son architecture interne et sa mise en œuvre pourraient bien subir certaines modifications et simplifications.
3. Amélioration de l'interchangeabilité des bibliothèquesJe crois qu'avec le temps, la communauté des développeurs front-end réalisera les avantages de maximiser l'interchangeabilité des bibliothèques et cessera de s'enfermer dans leurs petits écosystèmes. Tous les composants des applications - routeurs, conteneurs d'état, etc. - devraient être extrêmement universels et leur remplacement ne devrait pas nécessiter une refactorisation en masse ou une réécriture de l'application à partir de zéro.
Pourquoi tout ça?
Si nous essayons de généraliser les informations présentées ci-dessus et de les réduire à une forme plus simple et plus courte, alors nous obtenons quelques points assez généraux:
- Pour réussir le développement d'applications, la connaissance du langage et du framework ne suffit pas, il convient de prêter attention aux éléments théoriques généraux: architecture d'application, meilleures pratiques et modèles de conception.
"La seule constante est le changement." Les approches du travail du sol et du développement continueront de changer, de sorte que les grands projets à longue durée de vie doivent accorder une attention appropriée à l'architecture - sans elle, l'introduction de nouveaux outils et pratiques sera extrêmement difficile.
Et c'est probablement tout pour moi. Un grand merci à tous ceux qui ont trouvé la force de lire l'article jusqu'au bout. Si vous avez des questions ou des commentaires, je vous invite à commenter.