
Il y a quelque temps, nous avons effectué une surveillance sans agent et des alarmes. Il s'agit d'un analogue de CloudWatch dans AWS avec une API compatible. Nous travaillons maintenant sur les équilibreurs et la mise à l'échelle automatique. Mais bien que nous ne fournissions pas un tel service - nous proposons à nos clients de le faire eux-mêmes, en utilisant notre surveillance et nos balises (AWS Resource Tagging API) comme une simple découverte de service comme source de données. Nous allons montrer comment faire cela dans ce post.
Un exemple d'une infrastructure minimale d'un simple service Web: DNS -> 2 équilibreurs -> 2 backend. Cette infrastructure peut être considérée comme le minimum nécessaire pour un fonctionnement et une maintenance à haute disponibilité. Pour cette raison, nous ne «compresserons» pas davantage cette infrastructure, ne laissant par exemple qu'un seul backend. Mais je voudrais augmenter le nombre de serveurs principaux et les réduire à deux. Ce sera notre tâche. Tous les exemples sont disponibles dans le référentiel .
Infrastructure de base
Nous ne nous attarderons pas en détail sur la configuration de l'infrastructure ci-dessus, nous montrerons seulement comment la créer. Nous préférons déployer l'infrastructure à l'aide de Terraform. Il permet de créer rapidement tout ce dont vous avez besoin (VPC, sous-réseau, groupe de sécurité, machines virtuelles) et de répéter cette procédure encore et encore.
Script pour augmenter l'infrastructure de base:
main.tfvariable "ec2_url" {} variable "access_key" {} variable "secret_key" {} variable "region" {} variable "vpc_cidr_block" {} variable "instance_type" {} variable "big_instance_type" {} variable "az" {} variable "ami" {} variable "client_ip" {} variable "material" {} provider "aws" { endpoints { ec2 = "${var.ec2_url}" } skip_credentials_validation = true skip_requesting_account_id = true skip_region_validation = true access_key = "${var.access_key}" secret_key = "${var.secret_key}" region = "${var.region}" } resource "aws_vpc" "vpc" { cidr_block = "${var.vpc_cidr_block}" } resource "aws_subnet" "subnet" { availability_zone = "${var.az}" vpc_id = "${aws_vpc.vpc.id}" cidr_block = "${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}" } resource "aws_security_group" "sg" { name = "auto-scaling" vpc_id = "${aws_vpc.vpc.id}" ingress { from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] } ingress { from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = ["${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"] } ingress { from_port = 8080 to_port = 8080 protocol = "tcp" cidr_blocks = ["${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } } resource "aws_key_pair" "key" { key_name = "auto-scaling-new" public_key = "${var.material}" } resource "aws_instance" "compute" { count = 5 ami = "${var.ami}" instance_type = "${count.index == 0 ? var.big_instance_type : var.instance_type}" key_name = "${aws_key_pair.key.key_name}" subnet_id = "${aws_subnet.subnet.id}" availability_zone = "${var.az}" security_groups = ["${aws_security_group.sg.id}"] } resource "aws_eip" "pub_ip" { instance = "${aws_instance.compute.0.id}" vpc = true } output "awx" { value = "${aws_eip.pub_ip.public_ip}" } output "haproxy_id" { value = ["${slice(aws_instance.compute.*.id, 1, 3)}"] } output "awx_id" { value = "${aws_instance.compute.0.id}" } output "backend_id" { value = ["${slice(aws_instance.compute.*.id, 3, 5)}"] }
Il semble que toutes les entités décrites dans cette configuration doivent être comprises par l'utilisateur moyen des nuages modernes. Les variables spécifiques à notre cloud et pour une tâche spécifique sont déplacées vers un fichier distinct - terraform.tfvars:
terraform.tfvars ec2_url = "https://api.cloud.croc.ru" access_key = "project:user@customer" secret_key = "secret-key" region = "croc" az = "ru-msk-vol51" instance_type = "m1.2small" big_instance_type = "m1.large" vpc_cidr_block = "10.10.0.0/16" ami = "cmi-3F5B011E"
Lancez Terraform:
terraform appliquer yes yes | terraform apply -var client_ip="$(curl -s ipinfo.io/ip)/32" -var material="$(cat <ssh_publick_key_path>)"
Configuration de la surveillance
Les VM lancées ci-dessus sont automatiquement surveillées par notre cloud. Ces données de surveillance seront la source d'informations pour une future mise à l'échelle automatique. En nous appuyant sur certaines métriques, nous pouvons augmenter ou diminuer la puissance.
La surveillance dans notre cloud vous permet de configurer des alarmes selon différentes conditions pour différentes métriques. C'est très pratique. Nous n'avons pas besoin d'analyser les métriques à aucun intervalle et de prendre une décision - cela se fera par la surveillance du cloud. Dans cet exemple, nous utiliserons des alarmes pour les métriques du processeur, mais dans notre surveillance, elles peuvent également être configurées pour des métriques telles que: utilisation du réseau (vitesse / pps), utilisation du disque (vitesse / iops).
cloudwatch put-metric-alarm export CLOUDWATCH_URL=https://monitoring.cloud.croc.ru for instance_id in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $CLOUDWATCH_URL \ cloudwatch put-metric-alarm \ --alarm-name "scaling-low_$instance_id" \ --dimensions Name=InstanceId,Value="$instance_id" \ --namespace "AWS/EC2" --metric-name CPUUtilization --statistic Average \ --period 60 --evaluation-periods 3 --threshold 15 --comparison-operator LessThanOrEqualToThreshold; done for instance_id in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $CLOUDWATCH_URL \ cloudwatch put-metric-alarm\ --alarm-name "scaling-high_$instance_id" \ --dimensions Name=InstanceId,Value="$instance_id" \ --namespace "AWS/EC2" --metric-name CPUUtilization --statistic Average\ --period 60 --evaluation-periods 3 --threshold 80 --comparison-operator GreaterThanOrEqualToThreshold; done
Description de certains paramètres qui peuvent être incompréhensibles:
--profile - profil des paramètres aws-cli, décrit dans ~ / .aws / config. En règle générale, différentes clés d'accès sont définies dans différents profils.
--dimensions - le paramètre détermine pour quelle ressource l'alarme sera créée, dans l'exemple ci-dessus - pour l'instance avec l'identifiant de la variable $ instance_id.
--namespace - espace de noms à partir duquel la métrique de surveillance sera sélectionnée.
--metric-name - le nom de la mesure de surveillance.
--statistic - le nom de la méthode d'agrégation de valeurs métriques.
--period - intervalle de temps entre les événements de collecte de valeurs de surveillance.
--evaluation-periodes - le nombre d'intervalles requis pour déclencher une alarme.
--threshold - valeur de seuil métrique pour évaluer l'état d'alarme.
--comparison-operator - une méthode qui est utilisée pour évaluer la valeur d'une métrique par rapport à une valeur de seuil.
Dans l'exemple ci-dessus, deux alarmes sont créées pour chaque instance d'arrière-plan. Scaling-low- <instance-id> passe en état d'alarme lorsque le processeur se charge à moins de 15% pendant 3 minutes. Scaling-high- <instance-id> passe en état d'alarme lorsque le processeur se charge à plus de 80% pendant 3 minutes.
Personnalisation des balises
Après avoir configuré la surveillance, nous sommes confrontés à la tâche suivante - la découverte des instances et de leurs noms (découverte de service). Nous devons en quelque sorte comprendre le nombre d'instances de backend que nous avons maintenant lancées, et nous devons également connaître leurs noms. Dans un monde en dehors du cloud, par exemple, le consul et le modèle de consul conviendraient bien pour générer une configuration d'équilibrage. Mais il y a des balises dans notre cloud. Les balises nous aideront à classer les ressources. En demandant des informations pour une balise spécifique (descriptions-balises), nous pouvons comprendre le nombre d'instances que nous avons actuellement dans le pool et leur identifiant. Par défaut, un identifiant d'instance unique est utilisé comme nom d'hôte. Grâce au DNS interne fonctionnant à l'intérieur du VPC, ces identifiants / noms d'hôtes se résolvent en instances IP internes.
Nous définissons des balises pour les instances d'arrière-plan et les équilibreurs:
ec2 create-tags export EC2_URL="https://api.cloud.croc.ru" aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "<awx_instance_id>" \ --tags Key=env,Value=auto-scaling Key=role,Value=awx for i in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "$i" \ --tags Key=env,Value=auto-scaling Key=role,Value=backend ; done; for i in <haproxy_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "$i" \ --tags Key=env,Value=auto-scaling Key=role,Value=haproxy; done;
Où:
--resources - une liste des identifiants de ressources sur lesquels les balises seront définies.
--tags est une liste de paires clé-valeur.
Un exemple de description de balises est disponible dans la documentation CROC Cloud.
Configuration de mise à l'échelle automatique
Maintenant que le cloud surveille et que nous savons comment utiliser les balises, nous ne pouvons interroger que l'état des alarmes configurées pour leur déclenchement. Ici, nous avons besoin d'une entité qui sera engagée dans des tâches de surveillance, de surveillance et de lancement périodiques pour créer / supprimer des instances. Divers outils d'automatisation peuvent être appliqués ici. Nous utiliserons AWX. AWX est une version open-source de la tour commerciale Ansible , un produit pour la gestion centralisée de l'infrastructure Ansible. La tâche principale est de lancer périodiquement notre playbook ansible.
Un exemple de déploiement AWX est disponible sur la page wiki du référentiel officiel. La configuration AWX est également décrite dans la documentation Ansible Tower. Pour qu'AWX commence à exécuter des playbooks personnalisés, vous devez le configurer en créant les entités suivantes:
- Identifiants de trois types:
- Identifiants AWS - pour autoriser les opérations liées au CROC Cloud.
- Informations d'identification de la machine - clés ssh pour accéder aux instances nouvellement créées.
- Informations d'identification SCM - pour autorisation dans le système de contrôle de version. - Project est une entité qui va pousser le référentiel git du playbook.
- Scripts - script d'inventaire dynamique pour ansible.
- L'inventaire est une entité qui invoquera le script d'inventaire dynamique avant de lancer le playbook.
- Modèle - configuration d'un appel Playbook spécifique, composé d'un ensemble d'informations d'identification, d'un inventaire et d'un playbook de Project.
- Workflow - une séquence d'appels aux playbooks.
Le processus de mise à l'échelle automatique peut être divisé en deux parties:
- scale_up - crée une instance lorsqu'au moins une alarme haute est déclenchée;
- scale_down - arrêt d'une instance si une alarme basse a fonctionné pour elle.
Dans le cadre de la partie scale_up, vous aurez besoin de:
- Interrogez le service de surveillance du cloud sur la présence d'alarmes hautes dans l'état Alarme;
- arrêtez scale_up plus tôt que prévu si toutes les alarmes hautes sont à l'état "OK";
- créer une nouvelle instance avec les attributs nécessaires (balise, sous-réseau, security_group, etc.);
- créer des alarmes hautes et basses pour une instance en cours d'exécution;
- configurer notre application dans une nouvelle instance (dans notre cas ce sera juste nginx avec une page de test);
- mettez à jour la configuration haproxy, effectuez un rechargement afin que les requêtes commencent à aller vers la nouvelle instance.
create-instance.yaml --- - name: get alarm statuses describe_alarms: region: "croc" alarm_name_prefix: "scaling-high" alarm_state: "alarm" register: describe_alarms_query - name: stop if no alarms fired fail: msg: zero high alarms in alarm state when: describe_alarms_query.meta | length == 0 - name: create instance ec2: region: "croc" wait: yes state: present count: 1 key_name: "{{ hostvars[groups['tag_role_backend'][0]].ec2_key_name }}" instance_type: "{{ hostvars[groups['tag_role_backend'][0]].ec2_instance_type }}" image: "{{ hostvars[groups['tag_role_backend'][0]].ec2_image_id }}" group_id: "{{ hostvars[groups['tag_role_backend'][0]].ec2_security_group_ids }}" vpc_subnet_id: "{{ hostvars[groups['tag_role_backend'][0]].ec2_subnet_id }}" user_data: | #!/bin/sh sudo yum install epel-release -y sudo yum install nginx -y cat <<EOF > /etc/nginx/conf.d/dummy.conf server { listen 8080; location / { return 200 '{"message": "$HOSTNAME is up"}'; } } EOF sudo systemctl restart nginx loop: "{{ hostvars[groups['tag_role_backend'][0]] }}" register: new - name: create tag entry ec2_tag: ec2_url: "https://api.cloud.croc.ru" region: croc state: present resource: "{{ item.id }}" tags: role: backend loop: "{{ new.instances }}" - name: create low alarms ec2_metric_alarm: state: present region: croc name: "scaling-low_{ item.id }}" metric: "CPUUtilization" namespace: "AWS/EC2" statistic: Average comparison: "<=" threshold: 15 period: 300 evaluation_periods: 3 unit: "Percent" dimensions: {'InstanceId':"{{ item.id }}"} loop: "{{ new.instances }}" - name: create high alarms ec2_metric_alarm: state: present region: croc name: "scaling-high_{{ item.id }}" metric: "CPUUtilization" namespace: "AWS/EC2" statistic: Average comparison: ">=" threshold: 80.0 period: 300 evaluation_periods: 3 unit: "Percent" dimensions: {'InstanceId':"{{ item.id }}"} loop: "{{ new.instances }}"
Dans create-instance.yaml, ce qui se passe est: créer une instance avec les paramètres corrects, marquer cette instance et créer les alarmes nécessaires. Le script d'installation et de configuration de nginx est également transmis via les données utilisateur. Les données utilisateur sont traitées par le service cloud-init, qui permet une configuration flexible de l'instance au démarrage sans recourir à d'autres outils d'automatisation.
Dans update-lb.yaml, le fichier /etc/haproxy/haproxy.cfg est recréé sur l'instance haproxy et le service de rechargement haproxy:
update-lb.yaml - name: update haproxy configs template: src: haproxy.cfg.j2 dest: /etc/haproxy/haproxy.cfg - name: add new backend host to haproxy systemd: name: haproxy state: restarted
Où haproxy.cfg.j2 est le modèle de fichier de configuration du service haproxy:
haproxy.cfg.j2 # {{ ansible_managed }} global log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy stats timeout 30s user haproxy group haproxy daemon defaults log global mode http option httplog option dontlognull timeout connect 5000 timeout client 50000 timeout server 50000 frontend loadbalancing bind *:80 mode http default_backend backendnodes backend backendnodes balance roundrobin option httpchk HEAD / {% for host in groups['tag_role_backend'] %} server {{hostvars[host]['ec2_id']}} {{hostvars[host]['ec2_private_ip_address']}}:8080 check {% endfor %}
Étant donné que l'option httpchk est définie dans la section backend haproxy, le service haproxy interrogera automatiquement les états des instances backend et équilibrera uniquement le trafic entre les contrôles d'intégrité antérieurs.
Dans la partie scale_down, vous avez besoin de:
- vérifier l'état d'alarme basse;
- terminer prématurément le jeu s'il n'y a pas d'alarmes basses dans l'état "Alarme";
- mettre fin à toutes les instances pour lesquelles une alarme basse est dans la classe Alarm;
- interdire la terminaison de la dernière paire d'instances, même si leurs alarmes sont à l'état Alarme;
- supprimez les instances que nous avons supprimées de la configuration de l'équilibreur de charge.
destroy-instance.yaml - name: look for alarm status describe_alarms: region: "croc" alarm_name_prefix: "scaling-low" alarm_state: "alarm" register: describe_alarms_query - name: count alarmed instances set_fact: alarmed_count: "{{ describe_alarms_query.meta | length }}" alarmed_ids: "{{ describe_alarms_query.meta }}" - name: stop if no alarms fail: msg: no alarms fired when: alarmed_count | int == 0 - name: count all described instances set_fact: all_count: "{{ groups['tag_role_backend'] | length }}" - name: fail if last two instance remaining fail: msg: cant destroy last two instances when: all_count | int == 2 - name: destroy tags for marked instances ec2_tag: ec2_url: "https://api.cloud.croc.ru" region: croc resource: "{{ alarmed_ids[0].split('_')[1] }}" state: absent tags: role: backend - name: destroy instances ec2: region: croc state: absent instance_ids: "{{ alarmed_ids[0].split('_')[1] }}" - name: destroy low alarms ec2_metric_alarm: state: absent region: croc name: "scaling-low_{{ alarmed_ids[0].split('_')[1] }}" - name: destroy high alarms ec2_metric_alarm: state: absent region: croc name: "scaling-high_{{ alarmed_ids[0].split('_')[1] }}"
Dans destroy-instance.yaml, les alarmes sont supprimées, l'instance et son tag sont arrêtés et les conditions interdisant l'arrêt des instances récentes sont vérifiées.
Nous supprimons explicitement les balises après la suppression d'instances, car après la suppression d'une instance, les balises qui lui sont associées sont supprimées et reportées et sont disponibles pendant une minute supplémentaire.
AWX
Définition des tâches, des modèles
L'ensemble de tâches suivant créera les entités nécessaires dans AWX:
awx-configure.yaml --- - name: Create tower organization tower_organization: name: "scaling-org" description: "scaling-org organization" state: present - name: Add tower cloud credential tower_credential: name: cloud description: croc cloud api creds organization: scaling-org kind: aws state: present username: "{{ croc_user }}" password: "{{ croc_password }}" - name: Add tower github credential tower_credential: name: ghe organization: scaling-org kind: scm state: present username: "{{ ghe_user }}" password: "{{ ghe_password }}" - name: Add tower ssh credential tower_credential: name: ssh description: ssh creds organization: scaling-org kind: ssh state: present username: "ec2-user" ssh_key_data: "{{ lookup('file', 'private.key') }}" - name: Add tower project tower_project: name: "auto-scaling" scm_type: git scm_credential: ghe scm_url: <repo-name> organization: "scaling-org" scm_branch: master state: present - name: create inventory tower_inventory: name: dynamic-inventory organization: "scaling-org" state: present - name: copy inventory script to awx copy: src: "{{ role_path }}/files/ec2.py" dest: /root/ec2.py - name: create inventory source shell: | export SCRIPT=$(tower-cli inventory_script create -n "ec2-script" --organization "scaling-org" --script @/root/ec2.py | grep ec2 | awk '{print $1}') tower-cli inventory_source create --update-on-launch True --credential cloud --source custom --inventory dynamic-inventory -n "ec2-source" --source-script $SCRIPT --source-vars '{"EC2_URL":"api.cloud.croc.ru","AWS_REGION": "croc"}' --overwrite True - name: Create create-instance template tower_job_template: name: "create-instance" job_type: "run" inventory: "dynamic-inventory" credential: "cloud" project: "auto-scaling" playbook: "create-instance.yaml" state: "present" register: create_instance - name: Create update-lb template tower_job_template: name: "update-lb" job_type: "run" inventory: "dynamic-inventory" credential: "ssh" project: "auto-scaling" playbook: "update-lb.yaml" credential: "ssh" state: "present" register: update_lb - name: Create destroy-instance template tower_job_template: name: "destroy-instance" job_type: "run" inventory: "dynamic-inventory" project: "auto-scaling" credential: "cloud" playbook: "destroy-instance.yaml" credential: "ssh" state: "present" register: destroy_instance - name: create workflow tower_workflow_template: name: auto_scaling organization: scaling-org schema: "{{ lookup('template', 'schema.j2')}}" - name: set scheduling shell: | tower-cli schedule create -n "3min" --workflow "auto_scaling" --rrule "DTSTART:$(date +%Y%m%dT%H%M%SZ) RRULE:FREQ=MINUTELY;INTERVAL=3"
L'extrait précédent créera un modèle pour chacun des playbooks ansibles utilisés. Chaque modèle configure le lancement d'un playbook avec un ensemble d'informations d'identification et d'un inventaire définis.
Pour créer un canal pour les appels aux playbooks, vous autoriserez le modèle de workflow. La configuration du flux de travail pour la mise à l'échelle automatique est présentée ci-dessous:
schema.j2 - failure_nodes: - id: 101 job_template: {{ destroy_instance.id }} success_nodes: - id: 102 job_template: {{ update_lb.id }} id: 103 job_template: {{ create_instance.id }} success_nodes: - id: 104 job_template: {{ update_lb.id }}
Le modèle précédent montre le diagramme de workflow, c'est-à-dire séquence d'exécution du modèle. Dans ce workflow, chaque étape suivante (success_nodes) ne sera effectuée que si la précédente est terminée avec succès. Une représentation graphique du flux de travail est montrée dans l'image:
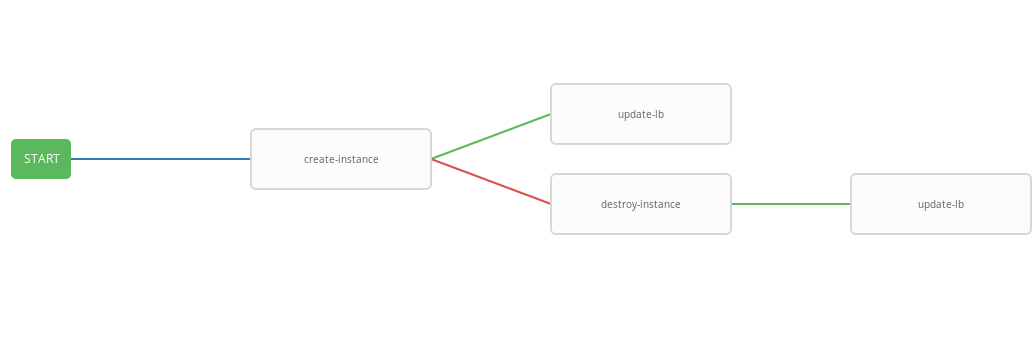
En conséquence, un flux de travail généralisé a été créé qui exécute le playbook create-instace et, selon l'état d'exécution, les playbooks destroy-instance et / ou update-lb. Le flux de travail intégré est pratique à exécuter selon un calendrier donné. Le processus de mise à l'échelle automatique démarrera toutes les trois minutes, le lancement et l'arrêt des instances en fonction de l'état de l'alarme.
Test de travail
Vérifiez maintenant le fonctionnement du système configuré. Tout d'abord, installez l'utilitaire wrk pour l'analyse comparative http.
installation de wrk ssh -A ec2-user@<aws_instance_ip> sudo su - cd /opt yum groupinstall 'Development Tools' yum install -y openssl-devel git git clone https://github.com/wg/wrk.git wrk cd wrk make install wrk /usr/local/bin exit
Nous utiliserons la surveillance du cloud pour surveiller l'utilisation des ressources d'instance pendant le chargement:
surveillance function CPUUtilizationMonitoring() { local AWS_CLI_PROFILE="<aws_cli_profile>" local CLOUDWATCH_URL="https://monitoring.cloud.croc.ru" local API_URL="https://api.cloud.croc.ru" local STATS="" local ALARM_STATUS="" local IDS=$(aws --profile $AWS_CLI_PROFILE --endpoint-url $API_URL ec2 describe-instances --filter Name=tag:role,Values=backend | grep -i instanceid | grep -oE 'i-[a-zA-Z0-9]*' | tr '\n' ' ') for instance_id in $IDS; do STATS="$STATS$(aws --profile $AWS_CLI_PROFILE --endpoint-url $CLOUDWATCH_URL cloudwatch get-metric-statistics --dimensions Name=InstanceId,Value=$instance_id --namespace "AWS/EC2" --metric CPUUtilization --end-time $(date --iso-8601=minutes) --start-time $(date -d "$(date --iso-8601=minutes) - 1 min" --iso-8601=minutes) --period 60 --statistics Average | grep -i average)"; ALARMS_STATUS="$ALARMS_STATUS$(aws --profile $AWS_CLI_PROFILE --endpoint-url $CLOUDWATCH_URL cloudwatch describe-alarms --alarm-names scaling-high-$instance_id | grep -i statevalue)" done echo $STATS | column -s ',' -o '|' -N $(echo $IDS | tr ' ' ',') -t echo $ALARMS_STATUS | column -s ',' -o '|' -N $(echo $IDS | tr ' ' ',') -t } export -f CPUUtilizationMonitoring watch -n 60 bash -c CPUUtilizationMonitoring
Le script précédent, une fois toutes les 60 secondes, prend des informations sur la valeur moyenne de la métrique CPUUtilization pour la dernière minute et interroge l'état des alarmes pour les instances d'arrière-plan.
Vous pouvez maintenant exécuter wrk et regarder l'utilisation des ressources des instances backend sous charge:
wrk run ssh -A ec2-user@<awx_instance_ip> wrk -t12 -c100 -d500s http://<haproxy_instance_id> exit
La dernière commande lancera le benchmark pendant 500 secondes, en utilisant 12 threads et en ouvrant 100 connexions http.
Au fil du temps, le script de surveillance doit montrer que pendant le benchmark, la valeur statistique de la métrique CPUUtilization augmente jusqu'à atteindre 300%. 180 secondes après le début de l'indice de référence, l'indicateur StateValue doit passer à l'état d'alarme. Toutes les deux minutes, le workflow de mise à l'échelle automatique démarre. Par défaut, l'exécution parallèle du même workflow est interdite. Autrement dit, toutes les deux minutes, une tâche d'exécution d'un flux de travail sera ajoutée à la file d'attente et ne sera lancée qu'une fois la précédente terminée. Ainsi, pendant le travail de wrk, il y aura une augmentation constante des ressources jusqu'à ce que les alarmes hautes de toutes les instances de backend passent à l'état OK. Une fois terminé, le workflow wrk scale_down met fin à toutes les instances backend sauf deux.
Exemple de sortie d'un script de surveillance:
suivi des résultats # start test i-43477460 |i-AC5D9EE0 "Average": 0.0 | "Average": 0.0 i-43477460 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok" # start http load i-43477460 |i-AC5D9EE0 "Average": 267.0 | "Average": 111.0 i-43477460 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok" # alarm state i-43477460 |i-AC5D9EE0 "Average": 267.0 | "Average": 282.0 i-43477460 |i-AC5D9EE0 "StateValue": "alarm"| "StateValue": "alarm" # two new instances created i-1E399860 |i-F307FB00 |i-43477460 |i-AC5D9EE0 "Average": 185.0 | "Average": 215.0 | "Average": 245.0 | i-1E399860 |i-F307FB00 |i-43477460 |i-AC5D9EE0 "StateValue": "insufficient_data"| "StateValue": "insufficient_data"| "StateValue": "alarm"| "StateValue": "alarm" # only two instances left after load has been stopped i-935BAB40 |i-AC5D9EE0 "Average": 0.0 | "Average": 0.0 i-935BAB40 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok"
Toujours dans le CROC Cloud, vous pouvez afficher les graphiques utilisés dans le post de surveillance sur la page d'instance dans l'onglet correspondant.
Afficher les alarmes est disponible sur la page de surveillance de l'onglet alarmes.
Conclusion
La mise à l'échelle automatique est un scénario assez populaire, mais, malheureusement, il n'est pas encore dans notre cloud (mais seulement pour l'instant). Cependant, nous avons beaucoup d'API puissantes pour faire des choses similaires et bien d'autres, en utilisant des outils populaires, presque standard, comme Terraform, ansible, aws-cli et autres.