Mes amis, bon après-midi!
Nous continuons la série de publications «sans coupures» sur des projets liés au développement, souvent avec le préfixe «web». Parlons aujourd'hui des tests de résistance. Le problème est que souvent, ni le client ni le chef de projet ne comprennent pourquoi il est nécessaire, quels risques il peut réduire, comment l'organiser et comment, et cela, je pense, est difficile, d'interpréter ses résultats au profit de l'entreprise. On verse du café et c'est parti ...
Pourquoi tester en charge un projet Web?
Le fait est que même si les autotests sont toujours en cours d'écriture dans certains projets Web pour maintenir la qualité, peu de personnes sont impliquées dans le contrôle des performances au stade du développement. Il est très rare de voir un projet web avec à la fois des autotests et des benchmarks de code. Plus souvent et pour des raisons raisonnables, les heuristiques suivantes sont respectées lors du développement, qui présentent un bon rapport bénéfice / coût:
- les requêtes à MySQL (nous utiliserons cette base de données populaire comme exemple) passent par une API assez adéquate qui utilise des index (bien que nous ne voyions pas exactement comment les index sont utilisés par le planificateur, quelle est leur cardinalité)
- les résultats de l'exécution des requêtes de base de données et des morceaux de code lourds sont mis en cache
- le développeur a vérifié 3,14 fois la construction de la page Web dans le navigateur et si cela ne ralentit pas l'œil, alors tout va bien
L'heuristique fonctionne souvent bien, mais plus le projet est gros et lourd, plus le quelque chose
peut mal tourner avec une probabilité exponentiellement croissante.
Prenez la mise en cache. Lors du développement, il n'y a souvent pas de temps pour réfléchir à la fréquence de reconstruction du cache. Mais en vain. Si la reconstruction d'un cache, par exemple, un catalogue de produits, prend beaucoup de temps et que le cache est réinitialisé lorsqu'un produit est ajouté, la mise en cache fera plus de mal que de bien.
C'est pourquoi, en passant, il n'est pas recommandé d'utiliser le cache de requête MySQL intégré, qui souffre d'un problème similaire: si vous modifiez au moins un enregistrement de table, le cache de table est complètement réinitialisé (imaginez une table de 100k lignes et l'absurdité de la situation devient évidente).
Une situation similaire avec les requêtes MySQL. Si les requêtes sont exécutées par des index, alors, en général, les requêtes seront exécutées ... "plus rapidement". Vous pouvez croire que le temps d'exécution de ces requêtes dépend logarithmiquement de la quantité de données (O (log (n))). Mais dans la pratique, il s'avère souvent que certaines requêtes affectent d'autres, en utilisant en même temps les sous-systèmes généraux de la base de données (tri sur un disque qui commence à ralentir) et vous ne pouvez pas le prédire immédiatement.
De plus, souvent pendant le chargement, des fonctionnalités intéressantes du système d'exploitation sont révélées, en particulier un débordement de la gamme de ports clients TCP / IP sortants lors d'un travail intensif avec memcached. Ou apache est obstrué par des demandes de traitement d'image, car lors de la configuration, ils ont oublié de configurer leur traitement par le serveur proxy de mise en cache nginx.
Parfois, ils oublient d'installer dans MySQL le chemin des tables temporaires sur un disque qui mappe les données à la RAM ("/ dev / shm"), à cause de quoi, lorsque la charge augmente, le serveur de base de données s'arrête à partir de tri intensifs.
De plus, lorsque des données sont ajoutées au projet Web, dans un volume proche du combat, les requêtes et les algorithmes commencent à afficher agressivement leur «notation O»: si le cartésien est invisible pour une petite quantité de données, puis lorsque le volume de combat apparaît, le serveur de base de données devient rouge à cause de la tension.
Il y a beaucoup plus d'exemples, arrêtons-nous pour l'instant. La principale chose à comprendre est que les tests de charge sont nécessaires. Parce qu'il est très coûteux, très long et économiquement peu pratique de prévoir à l'avance toutes les options possibles pour «freiner» un système Web de taille moyenne.
Comment identifier les cibles des tests de résistance?
Ici, il est important de comprendre ce qui vous montre, à vous et au client, le niveau de qualité du système Web pendant les tests de résistance. Il n'y a rien de mieux que des exemples concrets de cibles de tests de résistance, bonnes et mauvaises:
- A fait 1 million de visites. Temps moyen de création d'une page Web = 1 sec. Qu'est-ce que cela montre? Rien. Combien de temps les tests de charge ont-ils duré? Le temps d'exécution d'une seule demande peut être de 1 ms ou 600 secondes, et il n'est pas clair quelles proportions sont plus grandes. Et combien d'erreurs étaient présentes (la réponse nginx dans le style "Erreur 50x") n'est pas claire non plus :-)
- A fait 1 million de visites. Temps de construction de la page Web médian = 1 sec, le nombre d'erreurs HTTP est de 0,5% Qu'est-ce que cela montre? Jusqu'à présent, un peu utile, mais en mieux. La part des erreurs inadéquates que le client peut attraper, nous savons déjà que c'est génial et vous pouvez commencer à vous préparer et à aller à la pharmacie. La médiane est une métrique plus résistante aux «valeurs aberrantes» que la moyenne (estimation plus «robuste»), elle est donc sans aucun doute meilleure que la moyenne arithmétique. Mais rendons les mesures encore plus utiles.
- 1 million de visites ont été effectuées par jour. 25% des coups ont été faits en moins de 10 ms, 50% des coups ont été faits en moins de 1 seconde (c'est la médiane ou 50 centile), 75% des coups ont été faits en moins de 1,5 seconde, 95% des coups ont été faits en moins de 5 sec et le nombre d'erreurs HTTP est de 0,5% C'est tout! Nous voyons la proportion d'erreurs inadéquates que le client peut détecter, mais nous voyons également la proportion de demandes qui sont exécutées au-delà d'un certain seuil.
Comme vous pouvez le voir, le choix de métriques adéquates pour évaluer la vitesse d'un projet Web lors des tests de charge est très, très important. Il n'y a qu'un seul principe - les mesures doivent être absolument claires à la fois pour le client et pour vous, et pour montrer clairement et clairement la qualité. En fait, la mesure la plus évidente et la plus correcte est la distribution de la vitesse de traitement des appels dans le temps. Si vous réussissez à le faire lors de vos tests de résistance, ce sera super. De plus, vous pouvez comparer 2 stress tests par la nature de la distribution des hits de temps et voir comment cela s'est amélioré et où. La visualisation, c'est le pouvoir!
Rien n'est clair: centiles, médianes, quantiles, brouillons, distribution ...
Tout est simple! Maintenant, je vais dessiner et montrer dans un bel environnement pour l'analyse des données: cahier Jupyter / Python.
Disons que 10 visites ont été effectuées sur le site Web avec un tel délai en millisecondes:
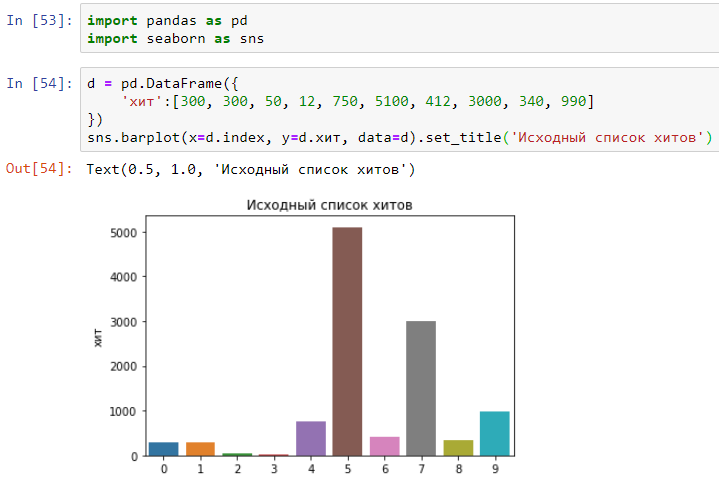
Triez maintenant le temps nécessaire pour terminer les hits dans l'ordre croissant:

Nous sommes à un pas de la compréhension des médian, 25e et 75e centels. Tout est simple - nous divisons le graphique en deux et au milieu il y aura une «médiane» (numéro 1 sur le graphique). Le premier trimestre du graphique correspondra au 25e centile (numéro 2 sur le graphique) et le troisième trimestre correspondra au 75e centile (numéro 3 sur le graphique). En conséquence, d'autres centiles sont obtenus (ou, comme on les appelle aussi, quantiles) - 90, 95, 99, etc.:
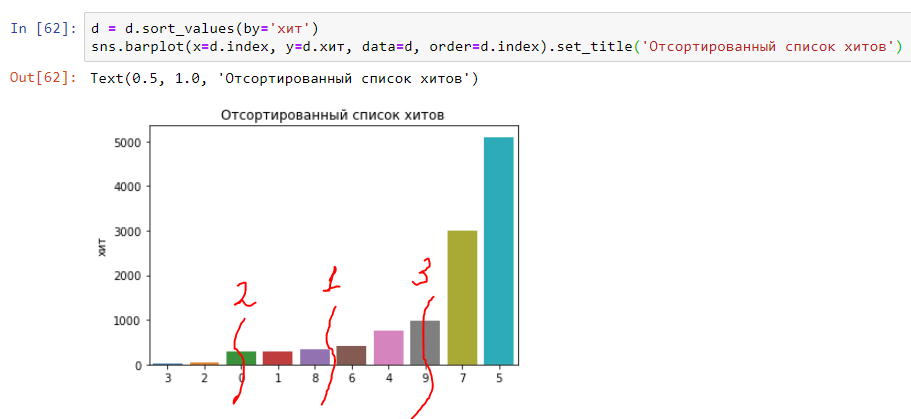
Et il ressemblera à la distribution (histogramme) sur la durée d'exécution des hits ci-dessus. Comme vous pouvez le voir, tout est très clair et simple:
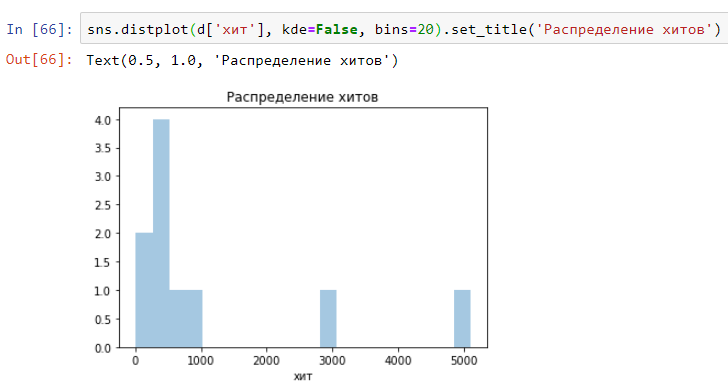
Et c'est ainsi que vous pouvez rapidement créer une distribution (histogramme) basée sur le journal des demandes de test de charge. Modifiez votre format de journal:
Et vous obtenez quelque chose comme ça:

J'espère que maintenant tout est devenu clair et en place. Sinon, demandez dans les commentaires.
Temps de test de résistance
Les gens demandent souvent - combien de temps devrait durer le test de charge d'un projet Web? Il existe une heuristique simple - dans le système d'exploitation, les tâches souvent planifiées sont effectuées une fois par jour: sauvegardes, rotation des journaux, etc., par conséquent, le temps pour effectuer des tests de charge ne doit pas être inférieur à, correctement, une journée. Si le projet Web est basé sur Bitrix, la plate-forme a également de nombreuses tâches planifiées et il est conseillé de charger le système Web pendant au moins une journée.
Équilibrage de charge
Si vous avez déjà un site Web exploité, vous pouvez, oui, en prendre les journaux de visite et charger le nouveau système Web en les utilisant. Mais souvent, ils résolvent le problème du chargement uniquement du système Web développé. Pour planifier l'équilibrage de charge, le modèle de division des chaînes de visites potentielles en sites est souvent un bon choix. Par exemple:
- Accueil - Actualités - Actualité détaillée = 50%
- Accueil - Aperçu du catalogue - Catalogue détaillé = 30%
- Catalogue détaillé - Aperçu du catalogue - Catalogue détaillé = 15%
- Résultats de recherche - catalogue détaillé = 5%
Dans le logiciel de création d'une charge (nous utilisons souvent Jmeter), de nombreux flux de charge sont créés pour chaque chaîne de sorte que, en tenant compte de l'intervalle entre les hits de la chaîne, le nombre total de hits de chaque chaîne par unité de temps soit corrélé comme suit: 50%, 30%, 15%, 5% .
Le calcul des intervalles et des flux de charge est facile à faire dans Excel ou sur une feuille avec un crayon.
Structure de la chaîne de charge
Il est important de considérer les caractéristiques du cycle de vie de l'utilisateur du système Web. Souvent, les utilisateurs se connectent puis se rendent sur le site Web. Pour ce faire, vous devez placer les actions menant à l'autorisation au début de la chaîne de charge:
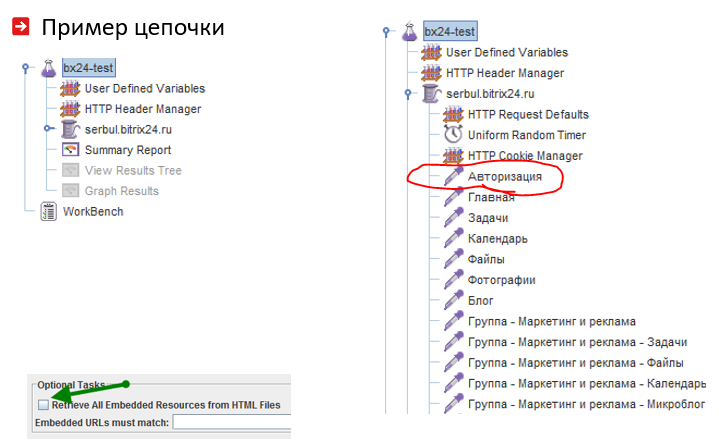
Il est clair pour le cheval qu'il est impossible de tirer une seule page détaillée du catalogue pendant les tests de résistance, il est donc utile de lire et de faire pivoter leur liste à partir du fichier CSV:

Entre les hits, bien sûr, vous devez faire des pauses aléatoires - nous nous rapprochons donc de la charge créée par les vrais utilisateurs. N'oubliez pas d'enregistrer et de renvoyer les valeurs des cookies au serveur:

Les variables globales des chaînes de charge, y compris leur nombre de threads, sont faciles à configurer. Certaines variables globales peuvent ensuite être utilisées à différents endroits des chaînes de charge:


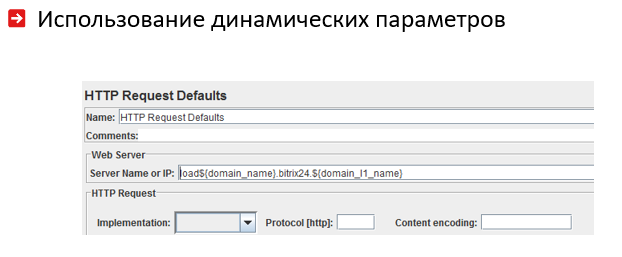
Comment mettre fin aux tests de résistance en toute sécurité?
Dans la pratique, presque toujours, le test de charge dans les premières minutes ou heures plante le système web, tout commence à fumer, puis brûle, le site ne s'ouvre pas, MySQL tombe dans un swap et ne se permet pas de se connecter, LA sur les serveurs approche 100, les développeurs commencent à s'exécuter avec les mots «cela n'aurait pas dû arriver», et les administrateurs système avec un sourire narquois répondent généralement «il y a de la justice dans la vie!» et commencez à boire de la bière dans la salle des serveurs.
Mais pour comprendre pourquoi tout est tombé et ce qu'il faut réparer, afin de montrer au client les résultats d'un test de charge «réussi» en une journée, vous devez d'abord activer l'enregistrement des principales mesures de la vie du système d'exploitation - c'est facile à faire dans les produits gratuits de la classe munun / cacti.
Je vais énumérer ce qui se produit le plus souvent lors de l'effondrement d'un système Web et comment cela peut être résolu.
Tout d'abord, le serveur web apache ou php-fpm est "encombré" de requêtes:

Le plus souvent, cela se produit en raison de l'effondrement de MySQL - le nombre de flux de requêtes suspendus augmente:

Quelle en est la raison? Souvent d'en haut, ils oublient de restreindre le nombre de flux apache ou de requête à MySQL, ce qui provoque le décrochage des applications de la RAM dans un échange lent avec des convulsions:
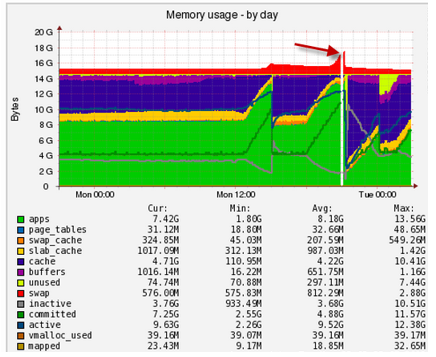
Ici, vous pouvez voir l'activité soudaine lorsque vous travaillez avec un échange, vous devez comprendre qui est tombé dans l'échange et où:
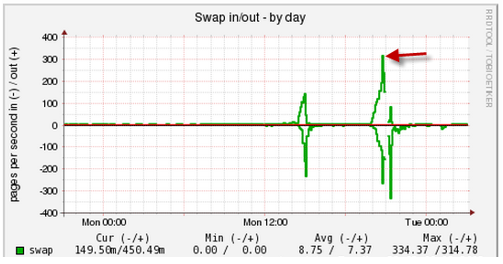
Cependant, le problème est parfois du côté du sous-système de disque lent. Dans ce cas, LA augmente fortement et le pourcentage d'utilisation du disque approche 100 (graphique inférieur droit):


De toute évidence, je n'ai révélé qu'une partie de la chose la plus intéressante qui puisse commencer avec un projet Web pendant les tests de résistance. Mais l'essentiel est de définir la bonne direction et de construire le bon processus. Demandez dans les commentaires ce qui est apparu pendant le chargement, je vais essayer de vous aider.
Interprétation des résultats des tests de résistance
Habituellement, après 5 à 10 redémarrages et ajustements, les tests de charge commencent leur vol et se terminent avec succès. Par conséquent, vous devriez avoir un ensemble de ces journaux à peu près pour une analyse plus approfondie:
- journal des demandes à nginx avec l'heure de la demande du client (dans ce cas ce sera le logiciel de chargement), l'heure du proxy de nginx à apache / php-fpm
- journal des erreurs nginx
- journal des demandes apache / php-fpm avec le temps de traitement des demandes et l'état de la réponse HTTP
- journal des erreurs apache / php-fpm
- Journal lent MySQL
- Journal des erreurs MySQL
De plus, il devrait y avoir des graphiques analytiques au cours de la dernière journée sur l'utilisation du processeur, des disques, de MySQL, de la RAM, des travailleurs apache, etc. (voir ci-dessus des exemples de graphiques munin).
Avec ces artefacts, vous pouvez, à l'aide d'un simple script awk au début de la publication, créer des distributions (histogrammes) sur ces journaux et calculer le nombre et les types d'erreurs HTTP. En fait, vous pouvez générer un rapport sur le succès des tests de résistance sur ce contenu qui est très volumineux et utile pour les affaires et la prise de décision:
Pendant la journée a fait 1 million de visites. 25% des hits ont été effectués en moins de 50 ms, 50% des hits ont été effectués en moins de 0,5 sec (médiane), 75% des hits ont été effectués en moins de 1 sec, 95% des hits ont été effectués en moins de 5 sec, le nombre d'erreurs HTTP - 0,01%. Données de test: catalogue, utilisateurs, actualités, articles ont été inondés dans un volume proche de celui attendu. Un développeur s'est suicidé.
Chaînes de charge:
Accueil - Actualités - Actualité détaillée = 50%
Accueil - Aperçu du catalogue - Catalogue détaillé = 30%
Catalogue détaillé - Aperçu du catalogue - Catalogue détaillé = 15%
Résultats de recherche - catalogue détaillé = 5%
Tableaux d'utilisation des ressources du serveur:
...
Il s'agit d'un bon rapport compréhensible sur les tests de charge du système Web. Pour les amateurs de douleur aiguë, vous pouvez toujours recommander lors des tests de charge d'inclure chaque minute d'import-export de données vers un site Web à partir de systèmes de classe SAP, 1C, etc. et des connexions synchrones sur des sockets TCP / IP avec des services d'échange externes, par exemple, des crypto-monnaies :-)
Mais, pour être honnête, si l'importation-exportation est effectuée avec soin et honnêteté, les tests de charge et dans ces conditions montreront des chiffres acceptables pour les entreprises.
D'où viennent les tests de résistance?
Soit dit en passant, oui, nous n'avons pas souligné ce moment. Pour des raisons triviales, le manque d'équilibre entre les travailleurs nginx - apache - mysql apparaît généralement. C'est-à-dire les travailleurs ne sont pas limités par le haut, par conséquent, 500 travailleurs (chacun parfois 100 Mo chacun) peuvent immédiatement monter dans apache et 500 threads avec des demandes arriveront immédiatement à MySQL - ce qui provoquera une augmentation des erreurs HTTP 50x et un éventuel effondrement.
Ici, il est recommandé de limiter le nombre de travailleurs apache / php-fpm au nombre qui tient dans la RAM et, de même, de limiter le nombre de threads dans MySQL pour se protéger contre le débordement de la RAM disponible. L'idée est simple - laissez les clients attendre devant nginx, cela peut ralentir un peu sur les sockets TCP / IP asynchrones et non bloquants, qui «cassent» immédiatement dans apache / MySQL.
Parmi les raisons les plus gênantes, il pourrait y avoir un PHP segfault. Dans ce cas, vous devez activer la collecte coredump et utiliser gdb pour voir pourquoi cela se produit. Dans la plupart des cas, le problème peut être contourné par la mise à jour / configuration de PHP.
Ce qui reste dans les coulisses
Il y a des rumeurs persistantes selon lesquelles le frontend moderne pour le web a si activement vécu sa vie que les tests de charge classiques du backend présentés dans ce post ne couvrent plus tous les risques possibles de geler la construction d'une page web dans les entrailles d'Angular / React / Vue.js - donc
n'utilisez pas une face avant lourde et opaque, peu testée, vous pouvez, si nécessaire, adapter les chaînes de charge à cette situation.
Dans tous les cas, si les résultats des tests de résistance du back-end ont montré de bons chiffres et que le site Web continue de ralentir dans le navigateur, il est déjà clair qui "frapper le visage rouge d'airain" :-)
Sérieusement, dans les prochains articles, nous espérons couvrir ce sujet important.
Résumé et conclusions
Total - rien n'est compliqué dans l'organisation et la réalisation de tests de charge d'un système Web utile pour le développement et les affaires.
Des tests de charge, correctement organisés, doivent toujours être effectués - sinon il y a un risque de rencontrer des problèmes majeurs pendant les opérations de combat, qui ne peuvent pas être éliminés en quelques jours.
Pour effectuer des tests de résistance, il est important d'attirer non seulement des développeurs, mais également des experts des systèmes d'exploitation et des administrateurs système expérimentés en matériel, puis les problèmes de "tomber dans un échange" ou de "déborder de la plage locale d'adresses IP" ne provoqueront pas de saignement des yeux et d'évanouissement.
Bonne chance mes amis et posez des questions dans les commentaires!