Nous percevons le processeur central comme le «cerveau» d'un ordinateur, mais qu'est-ce que cela signifie vraiment? Que se passe-t-il exactement à l'intérieur des milliards de transistors qui font fonctionner un ordinateur? Dans notre nouvelle mini-série de quatre articles, nous examinerons le processus de création de l'architecture du matériel informatique et parlerons des principes de son fonctionnement.
Dans cette série, nous parlerons de l'architecture informatique, de la conception de cartes processeur, de la VLSI (intégration à très grande échelle), de la fabrication de puces et des tendances futures dans le domaine de la technologie informatique. Si vous vouliez comprendre les détails des processeurs, il est préférable de commencer l'étude avec cette série d'articles.
Nous commencerons par une explication de très haut niveau de ce que fait le processeur et de la façon dont les blocs de construction se connectent à une structure fonctionnelle. En particulier, nous prendrons en compte les cœurs de processeur, la hiérarchie de la mémoire, la prédiction de branche, etc. Tout d'abord, nous devons donner une définition simple de ce que fait le CPU. L'explication la plus simple: le processeur suit un ensemble d'instructions pour effectuer une certaine opération sur un grand nombre de données entrantes. Par exemple, il peut être en train de lire une valeur dans la mémoire, puis de l'ajouter à une autre valeur, et enfin d'enregistrer le résultat en mémoire à une adresse différente. Cela peut être quelque chose de plus compliqué, par exemple, la division de deux nombres, si le résultat du calcul précédent est supérieur à zéro.
Les programmes, comme un système d'exploitation ou un jeu, sont eux-mêmes des séquences d'instructions que le CPU doit exécuter. Ces instructions sont chargées à partir de la mémoire et exécutées l'une après l'autre dans un simple processeur jusqu'à la fin du programme. Les développeurs de logiciels écrivent des programmes dans des langages de haut niveau, tels que C ++ ou Python, mais le processeur ne peut pas les comprendre. Il ne comprend que les uns et les zéros, nous devons donc en quelque sorte représenter le code dans ce format.
Les programmes sont compilés dans un ensemble d'instructions de bas niveau appelé
langage d'assemblage , qui fait partie de l'architecture du jeu d'instructions (ISA). Il s'agit d'un ensemble d'instructions que le CPU doit comprendre et exécuter. Certains des ISA les plus courants sont x86, MIPS, ARM, RISC-V et PowerPC. De la même manière que la syntaxe pour écrire une fonction en C ++ diffère de la fonction qui effectue la même action en Python, chaque ISA a sa propre syntaxe différente.
Ces normes ISA peuvent être divisées en deux catégories principales: de longueur fixe et variable. ISA RISC-V utilise des instructions de longueur fixe, ce qui signifie qu'un nombre prédéterminé de bits dans chaque instruction détermine le type de l'instruction. En x86, tout est différent, il utilise des instructions de longueur variable. Dans x86, les instructions peuvent être encodées de différentes manières avec différents nombres de bits pour différentes parties. En raison de cette complexité, le décodeur d'instructions du processeur x86 est généralement la partie la plus complexe de l'ensemble du périphérique.
Les instructions de longueur fixe permettent un décodage simple en raison d'une structure constante, mais limitent le nombre total d'instructions pouvant être prises en charge par ISA. Alors que les versions populaires de l'architecture RISC-V contiennent environ 100 instructions et qu'elles sont toutes open source, l'architecture x86 est propriétaire et personne ne sait combien d'instructions elle contient. On pense généralement qu'il existe plusieurs milliers d'instructions x86, mais personne ne publie le nombre exact. Malgré les différences entre les ISA, ils ont en fait tous les mêmes fonctionnalités de base.
Un exemple de quelques instructions RISC-V. L'opcode de droite fait 7 bits et détermine le type d'instruction. De plus, chaque instruction contient des bits qui définissent les registres utilisés et les fonctions exécutées. Les instructions de l'assembleur sont donc divisées en code binaire afin que le processeur les comprenne.Nous sommes maintenant prêts à allumer l'ordinateur et à démarrer l'exécution des programmes. L'exécution de l'instruction comporte plusieurs parties de base, qui sont divisées en plusieurs étapes du processeur.
La première étape est le transfert des instructions de la mémoire au processeur pour démarrer l'exécution. Dans la deuxième étape, l'instruction est décodée afin que le CPU puisse comprendre de quel type d'instruction il s'agit. Il existe de nombreux types, notamment les instructions arithmétiques, les instructions de branchement et les instructions de mémoire. Une fois que la CPU a découvert le type d'instruction qu'elle exécute, les opérandes de l'instruction sont extraits de la mémoire ou des registres internes de la CPU. Si vous souhaitez ajouter le nombre A et le nombre B, vous ne pouvez pas ajouter tant que vous ne connaissez pas les valeurs de A et B. La plupart des processeurs modernes sont 64 bits, c'est-à-dire que la taille de chaque valeur de données est de 64 bits.
64 bits est la largeur du registre du processeur, du canal de données et / ou de l'adresse mémoire. Pour les utilisateurs ordinaires, cela signifie la quantité d'informations qu'un ordinateur peut traiter à la fois, et cela est mieux compris par rapport à un parent d'architecture plus jeune - un processeur 32 bits. L'architecture 64 bits peut traiter deux fois plus de bits d'informations à la fois (64 bits contre 32).Après avoir reçu les opérandes pour l'instruction, le processeur les transfère à l'étape d'exécution, où l'opération est effectuée sur les données entrantes. Cela peut être l'ajout de nombres, l'exécution de manipulations logiques avec des nombres ou simplement la transmission de nombres sans les modifier. Après avoir calculé le résultat, un accès à la mémoire peut être nécessaire pour le stocker, ou le processeur peut simplement stocker la valeur dans l'un de ses registres internes. Après avoir enregistré le résultat, la CPU met à jour l'état des différents éléments et passe à l'instruction suivante.
Cette explication, bien sûr, est grandement simplifiée, et la plupart des processeurs modernes divisent ces plusieurs étapes en 20 ou même plus petites étapes pour augmenter l'efficacité. Cela signifie que bien que le processeur démarre et se termine avec plusieurs instructions à chaque cycle, l'exécution d'une instruction du début à la fin peut prendre 20 cycles ou plus. Un tel modèle est généralement appelé pipeline ("pipeline", généralement traduit en russe par "convoyeur"), car il faut du temps pour remplir le pipeline de liquide et terminer son passage, mais après le remplissage, le débit (sortie de données) sera constant.
Un exemple de convoyeur à 4 étages. Les rectangles multicolores indiquent des instructions indépendantes les unes des autres.Le cycle complet de l'instruction est un processus très soigneusement coordonné, mais toutes les instructions ne peuvent pas être exécutées en même temps. Par exemple, l'ajout est très rapide et la division ou le chargement à partir de la mémoire peut prendre des milliers de cycles. Au lieu d'arrêter l'intégralité du processeur jusqu'à la fin d'une instruction lente, la plupart des processeurs modernes les exécutent avec un changement dans l'ordre. Autrement dit, ils déterminent laquelle des instructions est la plus avantageuse à exécuter pour le moment et tamponnent les autres instructions qui ne sont pas encore prêtes. Si l'instruction en cours n'est pas encore prête, le processeur peut avancer dans le code pour voir si quelque chose d'autre est prêt.
En plus de s'exécuter avec une séquence de changements, les processeurs modernes utilisent une technologie appelée
architecture superscalaire . Cela signifie qu'à tout moment, le processeur exécute simultanément un grand nombre d'instructions à chaque étape du pipeline. Il peut également s'attendre à ce que des centaines d'autres démarrent leur exécution, et afin de pouvoir exécuter plusieurs instructions simultanément à l'intérieur des processeurs, il existe plusieurs copies de chaque étape du pipeline. Si le processeur voit que deux instructions sont prêtes à être exécutées et qu'il n'y a aucune dépendance entre elles, il n'attend pas qu'elles soient terminées séparément, mais les exécute simultanément. Une implémentation populaire de cette architecture est appelée multithreading simultané (SMT) et est également appelée Hyper-Threading. Les processeurs Intel et AMD prennent désormais en charge les SMT double face, tandis qu'IBM a développé des puces qui prennent en charge jusqu'à huit SMT.
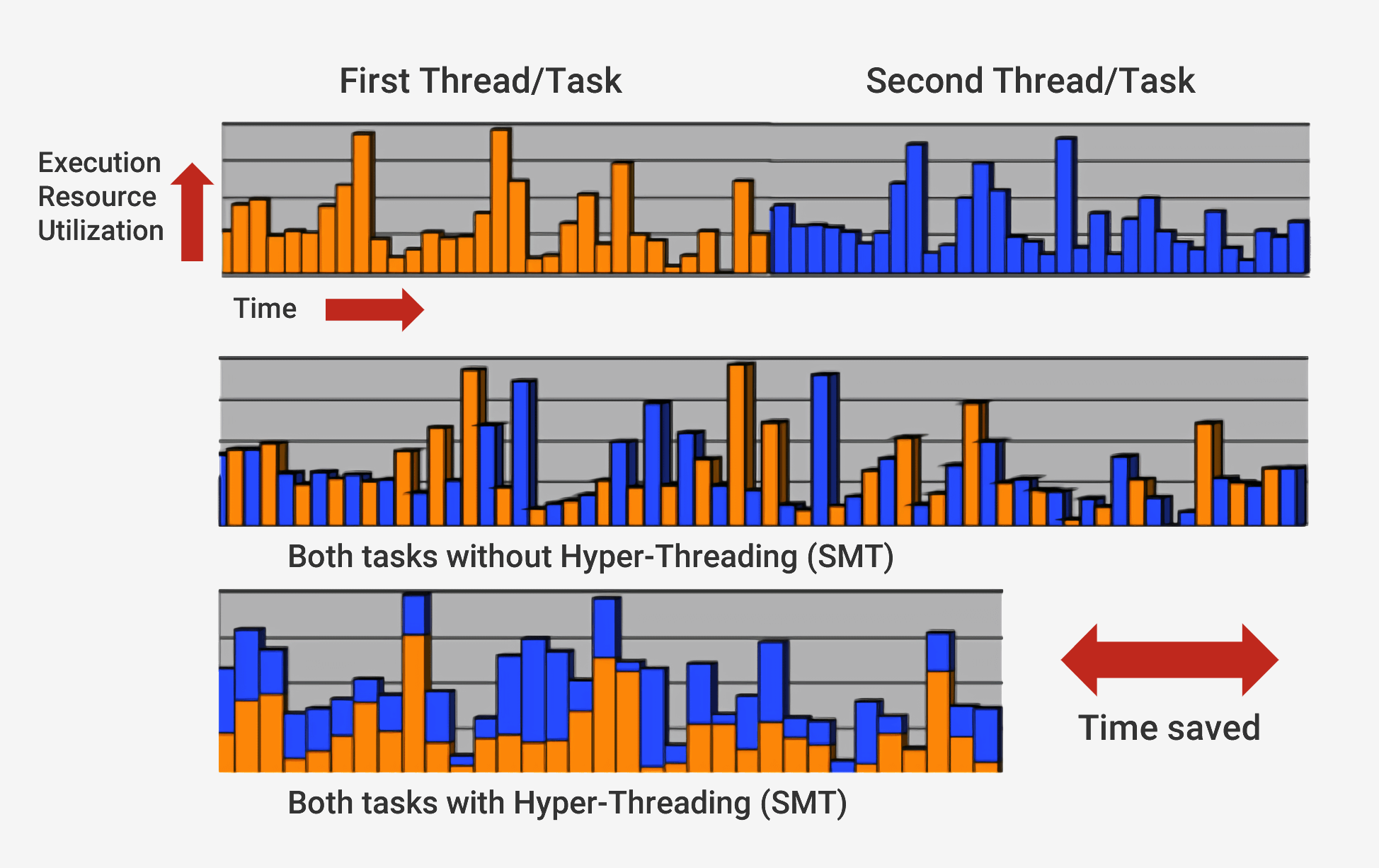
Pour terminer cette exécution soigneusement coordonnée, le processeur, en plus du noyau de base, possède de nombreux éléments supplémentaires. Le processeur possède des centaines de modules distincts, chacun ayant une fonction spécifique, mais nous ne considérerons que les bases. Les plus importants et les plus rentables sont les caches et le prédicteur des transitions. Il y a d'autres structures supplémentaires que nous ne considérerons pas: réorganiser les tampons, enregistrer les tables renommées et les stations de sauvegarde.
Le besoin de caches peut parfois prêter à confusion, car ils stockent des données, comme la RAM ou le SSD. Mais les caches diffèrent en termes de latence et de vitesse d'accès. Même si la mémoire RAM est extrêmement rapide, elle est beaucoup plus lente que ce dont le CPU a besoin. Des centaines de cycles peuvent être nécessaires pour répondre avec le transfert de données RAM, et le processeur n'aura rien à faire pour le moment. Et s'il n'y a pas de données dans la RAM, cela peut prendre des dizaines de milliers de cycles pour y accéder depuis le SSD. Sans caches, les processeurs s'arrêteraient constamment.
Les processeurs ont généralement trois niveaux de cache qui composent la soi-disant
hiérarchie de la mémoire . Le cache L1 est le plus petit et le plus rapide, L2 est au milieu et L3 est le plus grand et le plus lent de tous les caches. Au-dessus des caches de la hiérarchie se trouvent de petits registres qui stockent la seule valeur de données lors des calculs. Par ordre de grandeur, ces registres sont les périphériques de stockage les plus rapides du système. Lorsque le compilateur convertit un programme de haut niveau en langage assembleur, il détermine la meilleure façon d'utiliser ces registres.
Lorsque le CPU demande des données à la mémoire, il vérifie d'abord si ces données sont déjà stockées dans le cache L1. Si c'est le cas, vous pouvez y accéder en quelques cycles seulement. S'ils ne sont pas là, le processeur vérifie L2, puis le cache L3. Les caches sont implémentés de telle manière qu'en général, ils sont transparents pour le noyau. Le noyau demande simplement des données à l'adresse mémoire spécifiée, et le niveau dans la hiérarchie auquel il existe y répond. Lors du passage à des niveaux ultérieurs dans la hiérarchie de la mémoire, la taille et les retards augmentent généralement de plusieurs ordres de grandeur. En fin de compte, si le CPU ne trouve pas de données dans l'un des caches, il accède à la mémoire principale (RAM).
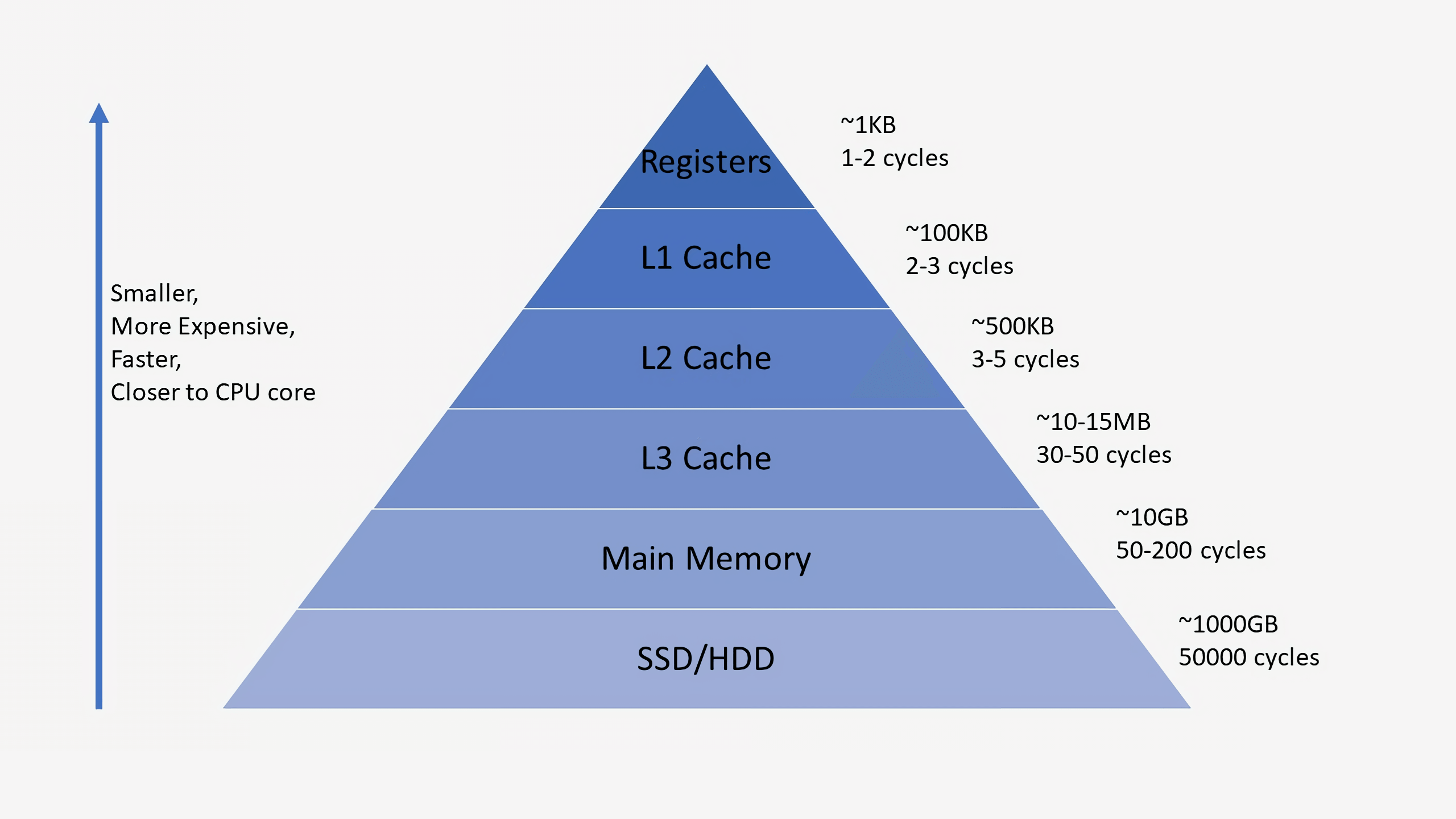
Dans un processeur standard, chaque cœur possède deux caches L1: un pour les données et un pour les instructions. Les caches L1 ont généralement une capacité totale d'environ 100 kilo-octets et la taille varie considérablement en fonction de la génération de la puce et du processeur. De plus, chaque cœur possède généralement son propre cache L2, bien que dans certaines architectures, il puisse être commun à deux cœurs. Les caches L2 mesurent généralement plusieurs centaines de kilo-octets. Enfin, il existe un seul cache L3 commun à tous les cœurs, avec une taille de l'ordre de dizaines de mégaoctets.
Lorsque le processeur exécute le code, les instructions et les valeurs de données les plus fréquemment utilisées sont mises en cache. Cela accélère considérablement l'exécution, car le processeur n'a pas besoin d'aller constamment dans la mémoire principale pour les données nécessaires. Dans les deuxième et troisième parties de la série, nous parlerons davantage de la façon dont ces systèmes de mémoire sont mis en œuvre.
En plus des caches, l'un des blocs de construction les plus importants d'un processeur moderne est un
prédicteur de transition précis. Les instructions de transition (branchement) sont similaires aux constructions if pour le processeur. Un ensemble d'instructions est exécuté si la condition est vraie et l'autre si elle est fausse. Par exemple, nous devons comparer deux nombres, et s'ils sont égaux, effectuer une fonction, et s'ils ne sont pas égaux, en effectuer une autre. Ces instructions de branchement sont extrêmement courantes et peuvent représenter environ 20% de toutes les instructions d'un programme.
À première vue, il semble que ces instructions de branchement ne devraient pas poser de problèmes, mais leur bonne exécution peut être très difficile pour le processeur. À tout moment, le processeur peut être en train d'exécuter simultanément dix ou vingt instructions, il est donc très important de savoir
quelles instructions exécuter. Il peut falloir 5 cycles pour déterminer que l'instruction en cours est une transition et 10 autres cycles pour déterminer si la condition est vraie. À ce stade, le processeur peut déjà commencer à exécuter des dizaines d'instructions supplémentaires, sans même savoir si ces instructions conviennent vraiment à l'exécution.
Pour contourner ce problème, tous les processeurs hautes performances modernes utilisent une technique appelée spéculation. Cela signifie que le processeur garde une trace des instructions de branchement et se demande si la branche conditionnelle sera exécutée ou non. Si la prédiction est correcte, le processeur a déjà commencé à exécuter les instructions suivantes, ce qui augmente les performances. Si la prédiction est incorrecte, le processeur arrête l'exécution, supprime toutes les instructions incorrectes qu'il a commencé à exécuter et redémarre à partir du point correct.
Ces prédicteurs de branche font partie des types les plus simples d'apprentissage automatique car le prédicteur étudie le comportement des branches lors de l'exécution. S'il prédit trop souvent incorrectement, il commence à apprendre le bon comportement. Des décennies de recherche sur les techniques de prédiction de transition ont abouti à une précision de prédiction de plus de 90% dans les processeurs modernes.
Bien que l'anticipation offre une énorme augmentation des performances, car le processeur peut exécuter des instructions qui sont déjà prêtes, au lieu d'attendre dans la file d'attente l'exécution, il crée également des failles de sécurité. La célèbre attaque Spectre exploite des bogues pour prévoir et anticiper les transitions. L'attaquant utilise du code spécialement sélectionné pour forcer le processeur à exécuter le code de manière proactive, ce qui entraîne une fuite de valeurs de la mémoire. Pour éviter les fuites de données, il a fallu refaire la conception de certains aspects de l'anticipation, ce qui a entraîné une légère baisse des performances.
Au cours des dernières décennies, l'architecture utilisée dans les processeurs modernes a parcouru un long chemin. L'innovation et le développement d'une structure bien pensée ont conduit à une productivité accrue et à une utilisation plus optimale du matériel. Cependant, les développeurs des processeurs centraux gardent soigneusement les secrets de leurs technologies, nous ne pouvons donc pas savoir exactement ce qui se passe à l'intérieur d'eux. Cependant, les principes fondamentaux des processeurs sont standardisés pour toutes les architectures et modèles. Intel peut ajouter ses ingrédients secrets pour augmenter la part des accès au cache, et AMD peut ajouter un prédicteur de transition amélioré, mais les processeurs des deux sociétés effectuent la même tâche.
Dans ce premier aperçu et examen, nous avons couvert les bases du fonctionnement des processeurs. Dans la partie suivante, nous vous expliquerons comment développer les composants qui composent les processeurs, parlerons des éléments logiques, des fréquences d'horloge, de la gestion de l'alimentation, des circuits, etc.
Lecture recommandée