Salut Je m'appelle Vitaliy Kostousov, je travaille dans l'équipe de Global Tech Heroes, et aujourd'hui je vais vous parler du support - l'un des composants les plus importants de tout service. Vous pouvez faire une excellente application avec des images sympas et parfois des robots de discussion en plaisantant de manière adéquate. Vous pouvez vider ouvertement, tout d'abord en offrant aux clients un service à faible coût. Vous pouvez louer une merveilleuse SMM-box pour laquelle vous n'aurez pas honte et qui n'aura pas à être changé aussi souvent qu'un comptable dans les années 90.
Mais tout cela peut trébucher en l'absence d'un support sain pour votre service. Et une assistance dans un sens global - de la résolution des problèmes des utilisateurs à la garantie de la fonctionnalité des logiciels et du matériel. Eh bien, sérieusement, combien de temps les gens utiliseront-ils l'application qui a été stupide pendant quelques semaines, mais les développeurs n'ont toujours pas répondu normalement aux problèmes, le service d'assistance n'est pas abonné avec des réponses robotiques, et pouvez-vous écouter de la musique classique gratuitement dans le centre d'appels?

Comme nous avons tout organisé, ce que nous utilisons dans notre travail pour détecter les problèmes et les résoudre, combien d'entre nous et tout le reste sont sous la coupe.
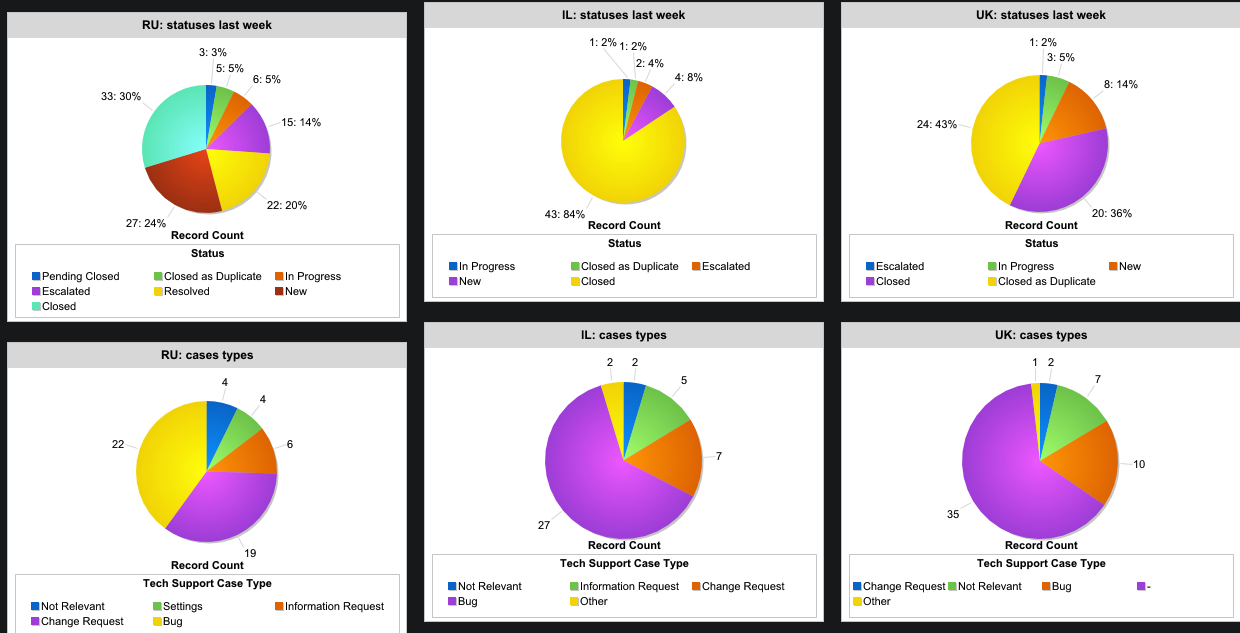
Nous travaillons maintenant dans 3 pays: la Russie, le Royaume-Uni et Israël, et nous avons des centaines de milliers d'utilisateurs actifs, les entreprises à elles seules plus de 20 000. Il y a suffisamment de demandes quotidiennes pour nos applications. Et il y a des chauffeurs et des demandes d'eux. Et aussi les systèmes internes et la surveillance. Tout cela devrait fonctionner et bien fonctionner. Pour ce faire, nous avons une équipe de support technique mondiale appelée à l'intérieur «Tech Heroes» - équipes de R&D, opérateurs d'escalade et ingénieurs, ainsi que Global Incident Manager. Et c'est ce à quoi ils sont confrontés dans leur travail.
Équipe et utilisateurs
Faites immédiatement une réservation que les utilisateurs finaux de notre équipe désignent non seulement les clients et chauffeurs prioritaires (privés et entreprises), mais aussi les services marketing, support et nos services internes. Bien sûr, ils écrivent pour prendre en charge soit en utilisant l'application, soit sur les réseaux sociaux. Si le problème est de nature technique, la tâche à l'intérieur de SalesForce nous revient immédiatement. Ils peuvent écrire non seulement sur l'application et la qualité de son travail dans son ensemble ou sur certaines fonctions en particulier, mais aussi sur la performance des services internes de l'entreprise. Il y a plus de 1000 employés de Gett qui posent des questions sur les logiciels de travail, l'organisation des processus.
Notre équipe est composée de 8 personnes réparties dans trois pays - Israël, la Grande-Bretagne et la Russie. Un spécialiste de la Russie travaille à distance, ses responsabilités incluent le travail avec les processus opérationnels: le suivi et la modification de nos principaux services. Les sept autres sont engagés dans des problèmes opérationnels, et bien d'autres: tests, bogues, spécifications, résolvent rapidement les appels provenant de spécialistes et de gestionnaires opérationnels, et surveillent également toutes nos bases de données, services et microservices. Cette équipe traite tous les billets, quel que soit le pays d'arrivée. Pour la plupart, vous devez travailler avec des problèmes locaux, mais il arrive qu'il y ait un bug sérieux dans le travail des services globaux, puis le travail passe en mode Global.
Vous devez également tenir compte du fait que nous avons beaucoup de clients B2B dans le monde - le système a des paramètres très flexibles et la possibilité d'intégration commerciale avec les services de l'entreprise. Autrement dit, il y a beaucoup plus de classes de voitures que les utilisateurs privés du service ne voient. Il est important de comprendre que tout cela affecte à la fois le fonctionnement des services et le nombre d'opérations transactionnelles. Le segment B2B peut utiliser un compte personnel sur le site Web de l'entreprise.
Logiciels
Il existe plusieurs systèmes pour travailler avec des tickets sur le marché qui ont déjà prouvé leur utilité: LiveAgent, ZenDesk, ZohoDesk et autres. Vous pouvez choisir selon votre convenance, vous pouvez par habitude, vous pouvez - à partir du type de logiciel avec lequel vos collègues travaillent, afin de ne pas bloquer un tas de couches et de béquilles (qui doivent également être prises en charge et terminées). Par conséquent, nous travaillons pour SalesForce, car il est utilisé par les principaux domaines opérationnels de l'entreprise (ventes et support). Cela vous permet de suivre l'état de chaque cas du côté de son créateur. Il y a une hiérarchisation automatique des cas en fonction des thèmes des appels. SalesForce est également intégré à Jira, et si une tâche est créée ou qu'un bogue est introduit dans le développement, son état est également affiché dans le cas. C'est ainsi que nous réalisons une communication transparente entre le support et le développement.
 SalesForce, cliquable
SalesForce, cliquableUn système d'application dédié vous permet de suivre le SLA pour chaque billet qui nous parvient.
Billets et demandes
Plus précisément, notre équipe est engagée dans le travail de l'application elle-même (pour les conducteurs et les passagers), les microservices avec lesquels les spécialistes opérationnels travaillent, ainsi que les tests et la surveillance. De plus, il y a toujours des demandes de nouveaux rapports et de suivi, qui peuvent être utiles à des collègues d'autres départements. Dans le même temps, une certaine surveillance est strictement réservée à notre équipe, si elles concernent exclusivement les paramètres techniques des services et des bases de données. Une partie de la surveillance nous envoie des alertes, à l'équipe responsable et au support. Si le problème est lié, par exemple, à l'application du pilote, le support répondra beaucoup plus rapidement et notifiera les pilotes si nécessaire. Ainsi, le timing de l'information est réduit à quelques minutes.
Suivi
Nous avons beaucoup de surveillance. Dès que l'un d'eux fonctionne, qu'il s'agisse de newrelic (services système en hausse), grafana (surveillance de scénarios spécifiques), datadog (disponibilité de l'infrastructure), nous recevons immédiatement une notification dans Slack et nous recevons un appel à son tour (grâce à pagerduty). Et pour une certaine période, une personne est nommée. Comme cela se produit automatiquement, il est probable que cette personne en particulier soit actuellement indisponible ou n'a tout simplement pas répondu, alors l'appel sera renvoyé plus loin dans la chaîne.
Lorsque les alertes sont déclenchées, nous revérifions les performances des systèmes et découvrons la cause de la panne (ou l'augmentation de la charge, ou un grand nombre d'événements ou d'appels, ici qui voleront). Si nous comprenons que le problème est dans une sorte de problème et doit être résolu, alors nous envoyons une lettre à des groupes de distribution spéciaux pour les spécialistes opérationnels.
Par conséquent, nous sommes toujours en ligne.
Gestion des incidents
Si votre entreprise fournit des services, la gestion des incidents n'est nulle part. Nous travaillons selon ce schéma:
- Détection rapide des problèmes.
- Notification du problème des personnes responsables.
- Notification des parties prenantes à tous les niveaux. Autrement dit, nous parlons du problème aux entreprises, afin que tout le monde là-bas comprenne exactement comment ces problèmes affectent les entreprises et les bénéfices.
- Maintenir une transparence maximale du travail.
- Analyse obligatoire des causes profondes. Après tout, il a les origines du problème et le suivant peut être évité. C'est plus rapide et plus utile que de le résoudre à nouveau au deuxième tour.
Le but est de connaître les problèmes à zéro stade. C'est à ce moment-là que vous avez découvert le problème en tant qu'employé fournissant la capacité de travail. Pas quand le client vous a informé d'elle. Par conséquent, nous utilisons activement la boîte à outils APM (Application Performance Monitoring). Je vais les exprimer une fois de plus.
NewRelic- Surveillance de tous nos microservices et passerelles
- Erreurs 50x, 4xx
- Redis apdex
- DB Apdex
 NewRelic, cliquableGrafana
NewRelic, cliquableGrafana Surveillance des événements (indique clairement ce qui a cessé de fonctionner exactement ou le comportement est différent de la normale).
 Grafana, cliquableDataDog
Grafana, cliquableDataDog . Surveillance des composants matériels de notre système (bases de données, équilibreurs de charge).
 DataDog, cliquableAirbrake
DataDog, cliquableAirbrake Exceptions de code pour les applications / microservices (il existe une liste d'exceptions, par exemple, lors de l'exécution de code ou de requêtes dans la base de données, si quelque chose ne va pas et qu'il figure sur la liste - nous le suivons).
Kibana - surveillance des journaux de microservices / applications (pilote / client).
Et pour que tout fonctionne non seulement pour la détection, mais aussi pour la notification en temps opportun (immédiatement, le plus rapide - le mieux), tout cela est lié à un certain nombre de canaux de notification, de Slack et
PagerDuty aux bonnes vieilles notifications par courrier électronique. Par conséquent, toute l'équipe sera immédiatement informée de toute anomalie. Les alertes peuvent être envoyées à différents canaux. La surveillance critique pour le fonctionnement des applications envoie toujours des alertes à l'équipe de support technique et de manière sélective aux canaux des équipes de développement responsables d'une fonctionnalité / d'un service spécifique. Tout cela contribue à optimiser le temps de réponse.
Des difficultés sont survenues à l'étape suivante, lorsque, après avoir trouvé un problème, vous deviez en informer rapidement la personne responsable du service. Et ce n'est pas si simple à faire s'il y a beaucoup de processus et de microservices, ce qui signifie qu'il n'y en a pas moins responsables. Et l'alerte peut arriver tard dans la nuit, quand vous voulez quelque chose, mais vous ne déterminez simplement pas qui est responsable de quoi.
Par conséquent, nous avons créé un répertoire pratique répertoriant tous les propriétaires de services (généralement dans toute l'entreprise). Comme la pratique l'a montré, cela seul nous a permis de réduire le temps de résolution de chaque incident d'environ 20%.
La meilleure recette pour une catastrophe en cours dans ce cas est de laisser l'incident sans personne en charge.
Il y a une personne spéciale, Global Incident Manager, qui sert de plaque tournante pour les incidents graves. Il est engagé dans la surveillance et la modification des systèmes de base pour éliminer les erreurs pouvant conduire aux os de l'entreprise, et est responsable devant les hauts responsables de l'entreprise, leur fournissant des rapports détaillés sur l'analyse des causes profondes.
Par conséquent, en bref, le processus de gestion des incidents lui-même ressemble à ceci:
- Nous déterminons les causes de l'incident.
- Nous trouvons le responsable.
- Nous coordonnons les efforts avec lui pour résoudre le problème le plus rapidement possible.
- Nous prenons toutes les décisions nécessaires lors de l'incident.
- Nous en informons l'entreprise, lui apportons tous les problèmes.
- Lorsque la poussière est dispersée, nous commençons l'analyse des causes profondes, RCA (Root Cause Analysis).
Nous construisons des rapports d'incidents à Jira, il existe un module correspondant,
Incidents , nous y avons ajouté un certain nombre de champs supplémentaires.
Il y a seulement trois étapes de RCA.
1. RCA initialIl s'agit de la description de niveau supérieur de la cause du problème (qu'il s'agisse d'un problème avec la base de données, ou avec l'infrastructure, ou avec le code). Ce rapport est préparé par l'officier de soutien qui a géré l'incident. Le rapport doit être rempli dans les 24 heures suivant la fin de l'incident.
2. R&D RCALa partie la plus importante du processus doit être achevée dans les 48 heures suivant la fin de l'incident. Voici déjà une analyse technique complète de la cause profonde - pourquoi cela s'est produit, pourquoi il n'a pas été trouvé (testeurs négligés ou il n'y a pas de surveillance appropriée), y a-t-il une chance que cela se reproduise et que faire pour éviter que cela ne se reproduise.
3. ActionsSur la base du deuxième paragraphe, les sous-tâches correspondantes sont formées, l'incident reste ouvert jusqu'à la fermeture de la dernière de ces sous-tâches. Personne ne veut que cette tâche prenne un kanban pendant longtemps, donc cela motive à tout résoudre plus rapidement.
C'est ainsi que chez Gett, nous gérons les incidents.
Chiffres et technologies
Nous travaillons, bien sûr, 24/7 avec un SLA de 99,99%. La pile principale que nous avons sur GoLang / Ruby, cela donne la vitesse nécessaire pour traiter des algorithmes complexes. Il y a plus de 150 microservices au total, et tous sont également sur GoLang et Ruby. Nous utilisons MySQL, Postgres et Presto comme bases de données. Nous avons du stockage sur AWS.
La charge la plus grave sur nos services tombe sur les vacances du Nouvel An et les 2 semaines précédentes. La condition des concurrents affecte également, par exemple, l'un d'eux a abandonné l'application, ce qui signifie que nos machines seront appelées plus souvent.
Il existe également des pics de travail interne qui affectent les utilisateurs finaux. Par exemple, lorsque nous mettons à jour la base de données ou effectuons des travaux techniques du côté des fournisseurs et des vendeurs, ou déployons de nouveaux services pour la production (pas le vendredi, oui), ou nous commandons des fonctionnalités qui affectent immédiatement un grand nombre d'utilisateurs ou de transactions.
Nous sommes aussi des personnes, et il arrive parfois que des paramètres incorrects ou une intervention manuelle conduisent à des erreurs de fonctionnement, nous avons donc développé un plan pour ce cas:

Non, pas ça. Ici:
- Nous vérifions les données dans les services, les journaux et les audits.
- Nous testons et réalisons des opérations de mise à jour sur Scrum.
- Nous préparons une tâche pour l'équipe et suivons l'exécution de la tâche en production.
Si vous êtes intéressé par des détails, n'hésitez pas à poser des questions dans les commentaires, nous vous répondrons ici ou dans un article détaillé séparé.