
Définissons d'abord le concept de «file d'attente».
Prenez en considération le type de file d'attente
«FIFO» (premier
entré , premier sorti). Si vous prenez la valeur de
Wikipedia - "c'est un type de données abstrait avec la discipline d'accès aux éléments." En bref, cela signifie que nous ne pouvons pas obtenir de données de celui-ci dans un ordre aléatoire, mais uniquement récupérer ce qui est arrivé en premier.
Ensuite, vous devez décider pourquoi ils sont nécessaires?
1. Pour les opérations différées. Un exemple classique est le traitement d'image. Par exemple, un utilisateur a téléchargé une image sur le site que nous devons traiter, cette opération prend beaucoup de temps, l'utilisateur ne veut pas attendre autant. Par conséquent, nous chargeons l'image, puis la transférons dans la file d'attente. Et il sera traité lorsqu'un «travailleur» le recevra.
2. Pour gérer les charges de pointe. Par exemple, il y a une partie du système qui provoque parfois beaucoup de trafic et qui ne nécessite pas de réponse instantanée. En option, générer des rapports. Lancer cette tâche dans la file d'attente - nous donnons la possibilité de la gérer avec une charge uniforme sur le système.
3. Évolutivité. Et probablement la raison la plus importante, la file d'attente permet
évoluer. Cela signifie que vous pouvez afficher plusieurs services pour le traitement en parallèle, ce qui augmentera considérablement la productivité.
Voyons maintenant les problèmes auxquels nous serons confrontés si nous créons nous-mêmes la file d'attente:
1. Accès parallèle. Un seul gestionnaire peut prendre un message dans une file d'attente. Autrement dit, si en même temps deux services demandent des messages, chacun d'eux doit renvoyer un ensemble unique de messages. Sinon, il s'avère qu'un message est traité deux fois. Ce qui pourrait être lourd.
2. Le mécanisme de déduplication. Le service doit disposer d'un système qui protège la file d'attente des doublons. Il peut y avoir une situation dans laquelle un même ensemble de données sera envoyé à la file d'attente par hasard deux fois. En conséquence, nous traiterons la même chose deux fois. Ce qui est encore lourd.
3. Mécanisme de gestion des erreurs. Disons que notre service a pris trois messages de la file d'attente. Il en a traité deux avec succès en envoyant des demandes de suppression de la file d'attente. Et le troisième qu'il n'a pas pu traiter et est mort. Un message en cours de traitement n'est pas disponible pour les autres services. Et il ne doit pas rester éternellement en cours de traitement. Un tel message doit être transmis à un autre gestionnaire par une logique. Un exemple de mise en œuvre de cette logique sera bientôt envisagé en utilisant AWS SQS (Simple Queue Service) comme exemple.
Amazon Web Services - Service de file d'attente simple
Voyons maintenant comment SQS résout ces problèmes et ce qu'il peut faire.
1. Accès parallèle. Dans la file d'attente, vous pouvez définir le paramètre de
délai d'expiration de la
visibilité . Il détermine la durée maximale du traitement d'un message. Par défaut, c'est
30 secondes. Lorsqu'un service récupère un message, il est transféré à l'état
«En vol» pendant 30 secondes. Si pendant ce temps il n'y avait pas de commande pour supprimer ce message de la file d'attente, il revient au début et le service suivant peut le recevoir à nouveau pour traitement.
Petit travail de shemka.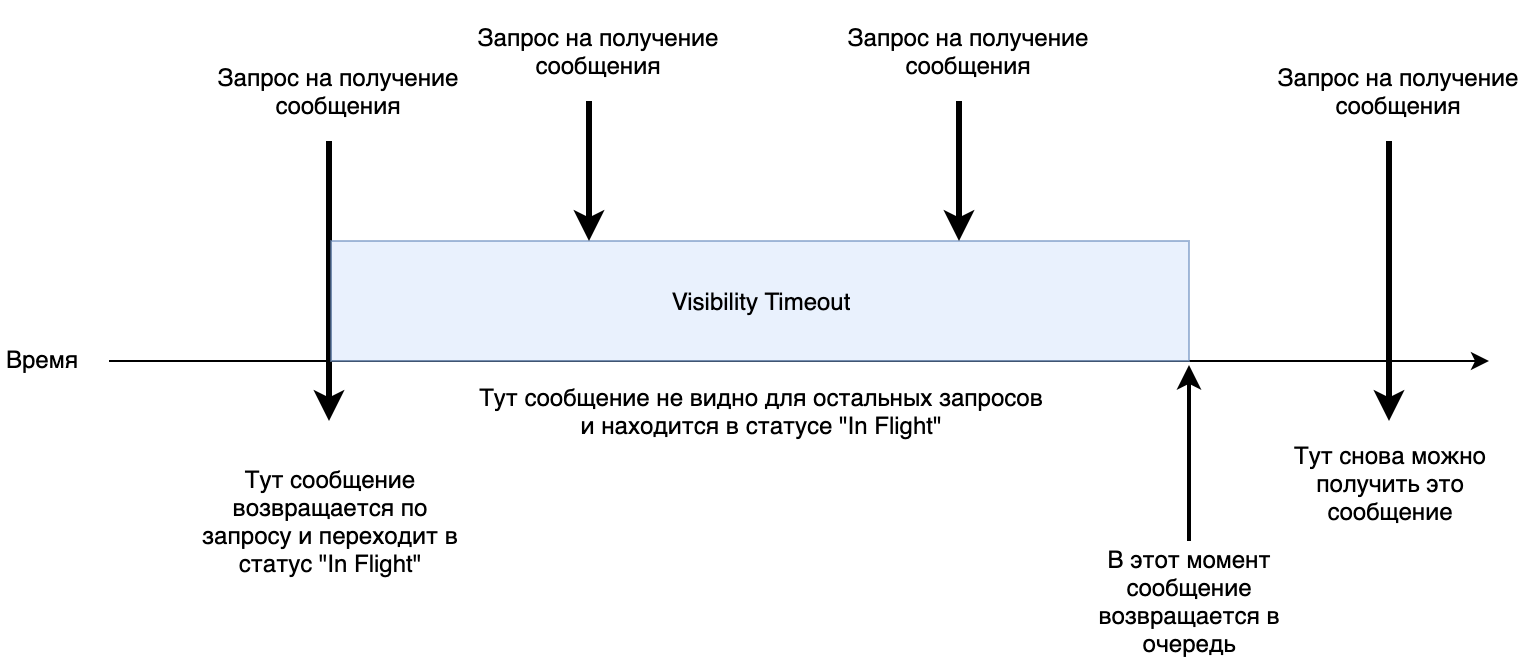
Remarque: soyez prudent. Dans certains cas, SQS peut envoyer un message en double (article "Livraison au moins une fois"). Par conséquent, votre service doit être idempotent pour le traitement.
2. Mécanisme de gestion des erreurs. Dans SQS, vous pouvez configurer le deuxième tour pour les messages "morts" (Dead Letter Queue). Autrement dit, ceux qui n'ont pas pu traiter notre service seront envoyés dans une file d'attente distincte, dont vous pouvez disposer à votre discrétion. Vous pouvez également définir après quoi le nombre de tentatives infructueuses le message ira dans la file d'attente "morte". Une tentative ayant échoué correspond à l'expiration du "délai d'expiration de la visibilité". Autrement dit, si aucune demande de suppression n'a été envoyée pendant ce temps, un tel message sera considéré comme non traité et retournera dans la file d'attente principale ou ira aux "morts".
3. Déduplication des messages. SQS dispose également d'un système de protection en double. Chaque message a un
«ID de déduplication» , SQS ne mettra pas en file d'attente un message avec
répété «Id de déduplication» pendant 5 minutes. Vous devez spécifier un «ID de déduplication» dans chaque message ou activer la génération d'ID basée sur le contenu. Cela signifie qu'un hachage généré en fonction de votre contenu entrera dans l '«ID de déduplication». Le paramètre
"Déduplication basée sur le contenu". En savoir plus sur la déduplicationRemarque: soyez prudent si vous envoyez deux messages identiques dans les 5 minutes et que la «déduplication basée sur le contenu» est activée . SQS n'ajoutera pas de deuxième message à la file d'attente.
Remarque: soyez prudent, par exemple, si la connexion est perdue sur l'appareil et qu'il ne reçoit pas de réponse et envoie ensuite une deuxième demande après 5 minutes, un doublon sera créé.
4. Long scrutin. Long sondage . SQS prend en charge ce type de connexion avec un délai maximal de 20 secondes. Ce qui nous permet d'économiser sur le trafic et les "saccades" du service.
5. Mesures. Amazon fournit également des métriques de file d'attente détaillées. Tels que le nombre de messages reçus / envoyés / supprimés, la taille en Ko de ces messages, etc. Vous pouvez également connecter SQS au service de journalisation CloudWatch. Là, vous pouvez voir encore plus. Là aussi, vous pouvez configurer les soi-disant
«alarmes» et vous pouvez configurer des actions pour tous les événements.
En savoir plus sur la connexion à SQS. Et la
documentation CloudWatch
Voyons maintenant les paramètres de la file d'attente:
Les principaux:
Délai de visibilité par défaut - le nombre de secondes / minutes / heures pendant lesquelles le message après réception ne sera pas visible pour la réception. Le temps de traitement maximum est de 12 heures.
Période de rétention des messages - le nombre de secondes / minutes / heures / jours, ce qui signifie combien de temps les messages non traités seront stockés dans la file d'attente. Maximum - 14 jours.
Taille maximale des messages
- taille maximale des messages en Ko. La valeur est comprise entre 1 Ko et 256 Ko.
Délai de livraison - vous pouvez définir le délai de livraison d'un message à la file d'attente. De 0 seconde à 15 minutes (En fait, les messages seront dans la file d'attente, mais ne seront pas visibles pour recevoir).
Recevoir le temps d'attente des messages - temps, durée de la connexion si nous utilisons «Interrogation longue» pour recevoir de nouveaux messages.
Déduplication basée sur le contenu - l' indicateur, s'il est défini sur true, un «ID de déduplication» sera ajouté à chaque message sous la forme d'un hachage SHA-256 généré à partir du contenu.
Paramètres de file d'attente morte
Utiliser la stratégie de redirection - un indicateur, s'il est défini, les messages seront redirigés après plusieurs tentatives.
Dead Letter Queue - le nom de la file d'attente "morte" à laquelle les messages bruts seront envoyés.
Maximum de réceptions - le nombre de tentatives de traitement infructueuses, après quoi le message sera envoyé à la file d'attente "morte"
Remarque: Notez également que nous pouvons envoyer tous les paramètres principaux avec chaque message séparément. Par exemple, chaque message individuel peut avoir son propre délai de visibilité ou délai de livraison.
Maintenant, un peu sur les messages eux-mêmes et leurs propriétés:
Un message a plusieurs paramètres:
1. Corps du message - n'importe quel texte
2. L'ID du groupe de messages est quelque chose comme une balise, un canal, requis pour tous les messages. Chacun de ces groupes est garanti d'être traité en mode FIFO.
3. ID de déduplication de message - chaîne pour identifier les doublons. Si le mode "Déduplication basée sur le contenu" est défini, le paramètre est facultatif.
Il existe également des attributs de message
Les attributs se composent d'un nom, d'un type et d'une valeur.
1. Nom - chaîne
2. Type - il existe plusieurs types: chaîne, nombre, binaire. Le type vient simplement sous forme de chaîne, et il est possible d'ajouter un suffixe au type. Dans ce cas, le type viendra avec ce suffixe à travers le point, par exemple string.example_postfix
3. Valeur - chaîne
Remarque: veuillez noter que le nombre maximal d'attributs est de 10 Détails
PS: cet article fournit une brève description de la file d'attente, ainsi qu'un peu sur les capacités et la mécanique de SQS. L'article suivant sera consacré à
AWS Lambda , puis à leur partage pratique.