Qu'est-ce qui est important pour une équipe de développement qui commence tout juste à construire un système d'apprentissage automatique? Architecture, composants, capacités de test utilisant l'intégration et les tests unitaires, réalisez un prototype et obtenez les premiers résultats. Et suite à l'évaluation de l'apport de main-d'œuvre, la planification de l'élaboration et de la mise en œuvre.
Cet article se concentrera sur le prototype. Qui a été créé quelque temps après avoir parlé avec le chef de produit: pourquoi ne pas «toucher» au Machine Learning? En particulier, la PNL et l'analyse des sentiments?
"Pourquoi pas?" Ai-je répondu. Pourtant, je fais du développement backend depuis plus de 15 ans, j'aime travailler avec les données et résoudre les problèmes de performances. Mais je devais encore découvrir «à quelle profondeur le terrier du lapin».
Sélectionnez les composants
Afin de décrire en quelque sorte l'ensemble des composants qui implémentent la logique de notre noyau ML, regardons un exemple simple de la mise en œuvre de l'analyse des sentiments, l'un des nombreux disponibles sur GitHub.
Un exemple d'analyse des sentiments en Pythonimport collections import nltk import os from sklearn import ( datasets, model_selection, feature_extraction, linear_model ) def extract_features(corpus): '''Extract TF-IDF features from corpus'''
L'analyse de tels exemples est un défi distinct pour le développeur.
Seulement 45 lignes de code et 4 (quatre, Karl!) Blocs logiques à la fois:
- Téléchargement des données pour la formation du modèle (lignes 25-26)
- Préparation des données téléchargées - extraction d'entités (lignes 31 à 34)
- Création et formation d'un modèle (lignes 36-39)
- Test d'un modèle formé et sortie des résultats (lignes 41-45)
Chacun de ces points mérite un article distinct. Et cela nécessite certainement une inscription dans un module séparé. Au moins pour les besoins des tests unitaires.
Séparément, il convient de souligner les éléments de la préparation des données et de la formation des modèles.
Dans chacune des façons de rendre le modèle plus précis, des centaines d'heures de travail scientifique et d'ingénierie sont investies.
Heureusement, afin de démarrer rapidement avec la PNL, il existe une solution toute faite - les
bibliothèques NLTK et
TextBlob . Le second est un wrapper sur NLTK qui fait la corvée - fait l'extraction des fonctionnalités de l'ensemble de formation, puis forme le modèle à la première demande de classification.
Mais avant de former le modèle, vous devez préparer des données pour celui-ci.
Préparation des données
Télécharger les données
Si nous parlons du prototype, le chargement des données à partir d'un fichier CSV / TSV est élémentaire. Vous appelez simplement la fonction
read_csv depuis la bibliothèque pandas:
import pandas as pd data = pd.read_csv(data_path, delimiter)
Mais ce ne seront pas des données prêtes à l'emploi dans le modèle.
Tout d'abord, si nous ignorons un peu le format csv, il est facile de s'attendre à ce que chaque source fournisse des données avec ses propres caractéristiques, et donc nous avons besoin d'une sorte de préparation des données dépendante de la source. Même pour le cas le plus simple d'un fichier CSV, pour simplement l'analyser, nous devons connaître le délimiteur.
De plus, vous devez déterminer quelles entrées sont positives et lesquelles sont négatives. Bien entendu, ces informations sont indiquées dans l'annotation aux jeux de données que nous voulons utiliser. Mais le fait est que dans un cas, le signe de pos / neg est 0 ou 1, dans l'autre, c'est un vrai / faux logique, dans le troisième, c'est juste une chaîne pos / neg, et dans certains cas, un tuple d'entiers de 0 à 5 Ce dernier est pertinent pour le cas de la classification multiclasse, mais qui a dit qu'un tel ensemble de données ne pouvait pas être utilisé pour la classification binaire? Il vous suffit d'identifier correctement la frontière des valeurs positives et négatives.
Je voudrais essayer le modèle sur différents ensembles de données, et il est nécessaire qu'après la formation, le modèle renvoie le résultat dans un seul format. Et pour cela, ses données hétérogènes doivent être réunies sous une forme unique.
Donc, il y a trois fonctions dont nous avons besoin au stade du chargement des données:
- La connexion à la source de données est pour CSV, dans notre cas, elle est implémentée à l'intérieur de la fonction read_csv;
- Prise en charge des fonctionnalités de format;
- Préparation préliminaire des données.
Voici à quoi cela ressemble dans le code.
import numpy as np
La classe
CsvSentimentDataLoader a été
créée , laquelle dans le constructeur est transmise le chemin vers csv, le séparateur, les noms du texte et les attributs de classification, ainsi qu'une liste de valeurs qui conseillent la valeur positive du texte.
Le chargement lui-même se produit dans la méthode
load_data .
Nous divisons les données en ensembles de test et de formation
Ok, nous avons téléchargé les données, mais nous devons toujours les diviser en ensembles de formation et de test.
Cela se fait avec la fonction
train_test_split de la bibliothèque
sklearn . Cette fonction peut prendre beaucoup de paramètres en entrée, déterminant comment exactement cet ensemble de données sera divisé en train et test. Ces paramètres affectent de manière significative la formation et les ensembles de tests résultants, et il nous sera probablement utile de créer une classe (appelons-la SimpleDataSplitter) qui gérera ces paramètres et agrégera l'appel à cette fonction.
from sklearn.model_selection import train_test_split
Désormais, cette classe inclut l'implémentation la plus simple qui, lorsqu'elle est divisée, ne prendra en compte qu'un seul paramètre: le pourcentage d'enregistrements à prendre comme ensemble de test.
Jeux de données
Pour former le modèle, j'ai utilisé des jeux de données disponibles gratuitement au format CSV:
Et pour le rendre encore plus pratique, pour chacun des ensembles de données, j'ai créé une classe qui charge les données du fichier CSV correspondant et les divise en ensembles de formation et de test.
import os import collections import logging from web.data.loaders import CsvSentimentDataLoader from web.data.splitters import SimpleDataSplitter, TdIdfDataSplitter log = logging.getLogger() class AmazonAlexaDataset(): def __init__(self): self.file_path = os.path.normpath(os.path.join(os.path.dirname(__file__), 'amazon_alexa/train.tsv')) self.delim = '\t' self.text_attr = 'verified_reviews' self.rate_attr = 'feedback' self.pos_rates = [1] self.data = None self.train = None self.test = None def load_data(self): loader = CsvSentimentDataLoader(self.file_path, self.delim, self.text_attr, self.rate_attr, self.pos_rates) splitter = SimpleDataSplitter(self.text_attr, self.rate_attr, test_part_size=.3) self.data = loader.load_data() x_train, x_test, y_train, y_test = splitter.split_data(self.data) self.train = [x for x in zip(x_train, y_train)] self.test = [x for x in zip(x_test, y_test)]
Oui, pour le chargement des données, il s'est avéré un peu plus de 5 lignes de code dans l'exemple d'origine.
Mais il est désormais possible de créer de nouveaux ensembles de données en jonglant avec les sources de données et en formant des algorithmes de préparation des ensembles.
De plus, les composants individuels sont beaucoup plus pratiques pour les tests unitaires.
Nous formons le modèle
Le modèle apprend depuis un certain temps. Et cela doit être fait une fois, au début de l'application.
À ces fins, un petit wrapper a été créé qui vous permet de télécharger et de préparer les données, ainsi que de former le modèle au moment de l'initialisation de l'application.
class TextBlobWrapper(): def __init__(self): self.log = logging.getLogger() self.is_model_trained = False self.classifier = None def init_app(self): self.log.info('>>>>> TextBlob initialization started') self.ensure_model_is_trained() self.log.info('>>>>> TextBlob initialization completed') def ensure_model_is_trained(self): if not self.is_model_trained: ds = SentimentLabelledDataset() ds.load_data()
Nous obtenons d'abord des données de formation et de test, puis nous procédons à l'extraction des fonctionnalités, et enfin nous formons le classificateur et vérifions la précision sur l'ensemble de test.
Test
Lors de l'initialisation, nous obtenons un journal, à en juger par lequel, les données ont été téléchargées et le modèle a été formé avec succès. Et entraîné avec une très bonne précision (pour commencer) - 0,8878.
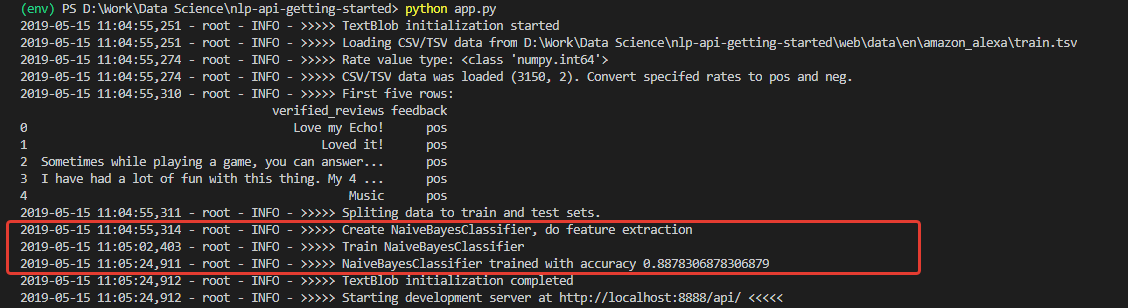
Ayant reçu de tels chiffres, j'étais très enthousiaste. Mais ma joie, malheureusement, n'a pas été longue. Le modèle formé sur cet ensemble est un optimiste impénétrable et, en principe, n'est pas en mesure de reconnaître les commentaires négatifs.
La raison en est dans les données de l'ensemble de formation. Le nombre d'avis positifs dans l'ensemble est supérieur à 90%. En conséquence, avec une précision du modèle d'environ 88%, les avis négatifs tombent simplement dans les 12% attendus de classifications incorrectes.
En d'autres termes, avec un tel ensemble de formation, il est tout simplement impossible de former le modèle à reconnaître les commentaires négatifs.
Pour vraiment m'en assurer, j'ai fait un test unitaire qui exécute la classification séparément pour 100 phrases positives et 100 phrases négatives d'un autre ensemble de données - pour les tests, j'ai pris l'
ensemble de
données Sentiment Labeled Sentences de l'Université de Californie.
@loggingtestcase.capturelogs(None, level='INFO') def test_classifier_on_separate_set(self, logs): tb = TextBlobWrapper() # Going to be trained on Amazon Alexa dataset ds = SentimentLabelledDataset() # Test dataset ds.load_data() # Check poisitives true_pos = 0 data = ds.data.to_numpy() seach_mask = np.isin(data[:, 1], ['pos']) data = data[seach_mask][:100] for e in data[:]: # Model train will be performed on first classification call r = tb.do_sentiment_classification(e[0]) if r == e[1]: true_pos += 1 self.assertLessEqual(true_pos, 100) print(str.format('\n\nTrue Positive answers - {} of 100', true_pos))
L'algorithme pour tester la classification des valeurs positives est le suivant:
- Télécharger les données de test;
- Prenez 100 messages étiquetés «pos»
- Nous exécutons chacun d'eux à travers le modèle et comptons le nombre de résultats corrects
- Affichez le résultat final dans la console.
De même, un décompte est effectué pour les commentaires négatifs.
Comme prévu, tous les commentaires négatifs ont été reconnus comme positifs.
Et si vous entraînez le modèle sur l'ensemble de données utilisé pour les tests -
Sentiment étiqueté ? Là, la répartition des commentaires négatifs et positifs est exactement de 50 à 50.
Modifiez le code et testez, exécutez Quelque chose déjà. La précision réelle de 200 entrées provenant d'un ensemble tiers est de 76%, tandis que la précision de la classification des commentaires négatifs est de 79%.
Bien sûr, 76% le feront pour un prototype, mais pas assez pour la production. Cela signifie que des mesures supplémentaires seront nécessaires pour améliorer la précision de l'algorithme. Mais c'est un sujet pour un autre rapport.
Résumé
Premièrement, nous avons obtenu une application avec une douzaine de classes et plus de 200 lignes de code, ce qui est légèrement plus que l'exemple d'origine de 30 lignes. Et vous devez être honnête - ce ne sont que des indices sur la structure, la première clarification des limites de la future application. Prototype.
Et ce prototype a permis de réaliser à quel point la distance entre les approches du code est du point de vue des spécialistes du Machine Learning et du point de vue des développeurs d'applications traditionnelles. Et c'est, à mon avis, la principale difficulté pour les développeurs qui décident d'essayer le machine learning.
La prochaine chose qui peut mettre un débutant dans une stupeur - les données ne sont pas moins importantes que le modèle sélectionné. Cela a été clairement démontré.
De plus, il reste toujours la possibilité qu'un modèle formé sur certaines données se montre inadéquatement sur d'autres, ou à un moment donné sa précision commencera à se dégrader.
En conséquence, des mesures sont nécessaires pour surveiller l'état du modèle, la flexibilité lors de l'utilisation des données, les capacités techniques pour ajuster l'apprentissage à la volée. Et ainsi de suite.
Quant à moi, tout cela doit être pris en compte lors de la conception de l'architecture et des processus de développement des bâtiments.
En général, le "trou du lapin" était non seulement très profond, mais aussi extrêmement habilement posé. Mais d'autant plus intéressant pour moi, en tant que développeur, d'étudier ce sujet à l'avenir.