
Il y a trois ans, j'ai écrit
un article sur la bibliothèque DI pour la langue Swift. À partir de ce moment, la bibliothèque a beaucoup changé et est devenue la
meilleure concurrente digne
de ce genre de Swinject, la dépassant à bien des égards. L'article est consacré aux capacités de la bibliothèque, mais a également des considérations théoriques. Alors, qui sont intéressés par les sujets DI, DIP, IoC, ou qui fait un choix entre Swinject et Swinject, je demande une coupe:
Qu'est-ce que DIP, IoC et avec quoi mange-t-il?
Théorie du DIP et de l' IoC
La théorie est l'un des éléments les plus importants de la programmation. Oui, vous pouvez écrire du code sans éducation, mais malgré cela, les programmeurs lisent constamment des articles, sont intéressés par diverses pratiques, etc. Autrement dit, d'une manière ou d'une autre, j'acquiert des connaissances théoriques afin de les mettre en pratique.
L'un des sujets que les gens aiment demander pour des entretiens est
SOLIDE . Aucun article ne parle de lui du tout, ne vous inquiétez pas. Mais nous avons besoin d'une lettre, car elle est étroitement liée à ma bibliothèque. Il s'agit de la lettre «D» - Principe d'inversion de dépendance.
Le principe d'inversion de dépendance stipule:
- Les modules de niveau supérieur ne doivent pas dépendre de modules de niveau inférieur. Les deux types de modules doivent dépendre d'abstractions.
- Les abstractions ne devraient pas dépendre des détails. Les détails doivent dépendre des abstractions.
Beaucoup de gens supposent à tort que s'ils utilisent des protocoles / interfaces, ils adhèrent automatiquement à ce principe, mais ce n'est pas entièrement vrai.
La première déclaration dit quelque chose sur les dépendances entre les modules - les modules doivent dépendre des abstractions. Attendez, qu'est-ce que l'abstraction? - Il vaut mieux se demander non pas ce qu'est l'abstraction, mais qu'est-ce que l'abstraction? Autrement dit, vous devez comprendre ce qu'est le processus, et le résultat de ce processus sera une abstraction.
L'abstraction est une distraction dans le processus de cognition des parties, propriétés, relations non essentielles afin de mettre en évidence des signes essentiels et réguliers.
Le même objet, selon les objectifs, peut avoir différentes abstractions. Par exemple, la machine du point de vue du propriétaire a les propriétés importantes suivantes: couleur, élégance, commodité. Mais du point de vue du mécanicien, tout est quelque peu différent: marque, modèle, modification, kilométrage, participation à un accident. Deux abstractions différentes pour un objet viennent d'être nommées - la machine.
Notez que dans Swift, il est habituel d'utiliser des protocoles pour les abstractions, mais ce n'est pas une exigence. Personne ne prend la peine de créer une classe, d'allouer un ensemble de méthodes publiques à partir de celle-ci et de laisser les détails de l'implémentation privés. En termes d'abstraction, rien n'est cassé. Nous devons nous rappeler la thèse importante - «l'abstraction n'est pas liée à la langue» - c'est un processus qui se produit constamment dans notre tête, et comment cela est transféré au code n'est pas si important. Ici, nous pouvons également mentionner l'
encapsulation , comme exemple de ce qui est associé au langage. Chaque langue a ses propres moyens pour la fournir. Sur Swift, ce sont des classes, des champs d'accès et des protocoles; sur les interfaces Obj-C, les protocoles et la séparation des fichiers h et m.
la deuxième affirmation est plus intéressante, car elle est ignorée ou mal comprise. Il parle de l'interaction des abstractions avec les détails, et quels sont les détails? Il y a une idée fausse selon laquelle les détails sont des classes qui implémentent des protocoles - oui, c'est vrai, mais pas complet. Vous devez comprendre que les détails ne sont pas liés aux langages de programmation - le langage C n'a ni protocoles ni classes, mais ce principe agit également sur lui. Il est difficile pour moi d'expliquer théoriquement ce qu'est la capture, je vais donc donner deux exemples, puis essayer de prouver pourquoi le deuxième exemple est plus correct.
Supposons qu'il y ait une voiture de classe et un moteur de classe. Il se trouve que nous devons les connecter - la machine contient un moteur. En tant que programmeurs compétents, nous sélectionnons le moteur de protocole, implémentons le protocole et transmettons l'implémentation du protocole à la classe de la machine. Tout semble aller bien - maintenant vous pouvez facilement remplacer l'implémentation du moteur et ne pas penser que quelque chose va casser. Ensuite, un mécanicien moteur est ajouté au circuit. Il s'intéresse aux caractéristiques du moteur complètement différentes de la voiture. Nous étendons le protocole et il contient maintenant un ensemble de fonctionnalités plus important qu'au départ. L'histoire se répète pour le propriétaire de la voiture, pour les moteurs qui produisent en usine, etc.
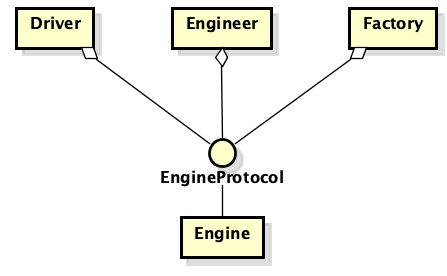
Mais où est l'erreur de raisonnement? Le problème est que la connexion décrite, malgré la disponibilité des protocoles, est en fait un «détail» - un «détail». Plus précisément, sous quel nom et où se situe le protocole du moteur.
Considérez maintenant l'autre
bonne option.
Comme auparavant, il existe deux classes - moteur et voiture. Comme auparavant, ils doivent être connectés. Mais maintenant, nous annonçons le protocole «Car Engine» ou «Heart of a Car». Nous y plaçons uniquement les caractéristiques dont la voiture a besoin pour le moteur. Et nous plaçons le protocole non pas à côté de son implémentation «moteur», mais à côté de la machine. De plus, si nous avons besoin d'un mécanicien, nous devrons créer un autre protocole et l'implémenter dans le moteur. Il semble que rien n'a changé, mais l'approche est radicalement différente - la question n'est pas tant dans les noms, mais à qui appartiennent les protocoles et à quoi le protocole appartient - une «abstraction» ou un «détail».
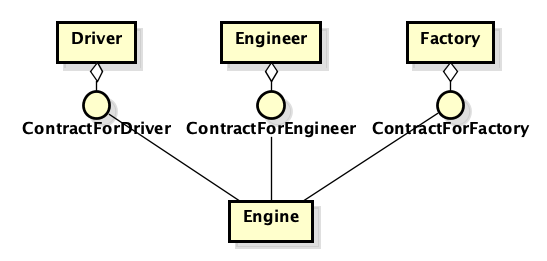
Tirons maintenant une analogie avec un autre cas, car ces arguments peuvent ne pas être évidents.
Il y a un backend et certaines fonctionnalités sont nécessaires. Le backend nous donne une grande méthode qui contient un tas de données, et dit - "vous avez besoin de ces 3 champs sur 1000"
Petite histoireBeaucoup peuvent dire que cela ne se produit pas. Et ils auront relativement raison - il arrive que le backend soit écrit séparément pour l'application mobile. Il se trouve que j'ai travaillé pour une entreprise où le backend est un service avec une histoire de 10 ans qui, entre autres, est lié à l'API de l'État. Pour de nombreuses raisons, il n'était pas habituel pour l'entreprise d'écrire une méthode distincte pour le mobile, et j'ai dû utiliser ce qui était. Et il y avait une merveilleuse méthode avec une centaine de paramètres à la racine, et certains d'entre eux étaient des dictionnaires imbriqués. Imaginez maintenant 100 paramètres, dont 20% ont des paramètres imbriqués, et dans chaque paramètre imbriqué, il y a 20 à 30 autres paramètres qui ont tous la même imbrication. Je ne me souviens pas exactement, mais le nombre de paramètres a dépassé 800 pour les objets simples, et pour les objets complexes, il pourrait être supérieur à 1000.
Sonne pas très bien, non? Habituellement, le backend écrit une méthode pour des tâches spécifiques pour le frontend, et le frontend est le client / utilisateur de ces méthodes. Hmm ... Mais si vous y réfléchissez, le backend est le moteur et le frontend est la voiture - la machine a besoin de certaines caractéristiques du moteur, et non pas le moteur doit avoir les caractéristiques de la voiture. Alors pourquoi, malgré cela, nous continuons d'écrire le protocole Engine et de le rapprocher de l'implémentation du moteur, et non de la machine? Tout dépend de l'échelle - dans la plupart des programmes iOS, il est très rare d'avoir à étendre les fonctionnalités à tel point qu'une telle solution devient un problème.
Et puis qu'est-ce que DI
Il y a une substitution de concepts - DI n'est pas une abréviation pour DIP, mais une abréviation complètement différente, malgré le fait qu'elle recoupe très étroitement avec DIP. DI est une injection de dépendance ou une injection de dépendance, pas une inversion. Inversion explique comment les classes et les protocoles doivent interagir les uns avec les autres, et l'implémentation vous indique d'où les obtenir. En général, vous pouvez l'implémenter de différentes manières - en commençant par les dépendances: constructeur, propriété, méthode; se terminant par ceux qui les créent et comment ce processus est automatisé. Les approches sont différentes mais, à mon avis, les plus pratiques sont les conteneurs pour l'injection de dépendance. En bref, leur sens se résume à une règle simple: nous informons le conteneur où et comment l'implémenter et après cela, tout est implémenté indépendamment. Cette approche correspond à la «mise en œuvre réelle des dépendances» - c'est lorsque les classes dans lesquelles les dépendances sont introduites ne savent rien de comment cela se produit, c'est-à-dire qu'elles sont passives.
Dans de nombreux langages, l'approche suivante est utilisée pour cette implémentation: Dans les classes / fichiers individuels, les règles d'implémentation sont décrites à l'aide de la syntaxe du langage, après quoi elles sont compilées et implémentées automatiquement. Il n'y a pas de magie - rien ne se passe automatiquement, seules les bibliothèques sont étroitement intégrées aux moyens de base du langage, et surchargent les méthodes de création. Donc, pour Swift / Obj-C, il est généralement admis que le point de départ est l'UIViewController, et les bibliothèques peuvent facilement s'intégrer dans le ViewController créé à partir du Storyboard. Certes, si vous n'utilisez pas le Storyboard, vous devrez effectuer une partie du travail avec des stylos.
Oh oui, j'ai presque oublié - la réponse à la question principale, "pourquoi en avons-nous besoin?" Sans aucun doute, vous pouvez vous-même prendre en charge l'injection de dépendance, tout prescrire avec des stylos. Mais des problèmes surviennent lorsque les graphiques deviennent volumineux - vous devez mentionner beaucoup de connexions entre les classes, le code commence à grandir beaucoup. Par conséquent, les bibliothèques qui implémentent automatiquement des dépendances récursives (et même cycliques) prennent ce soin sur elles-mêmes et, en prime, contrôlent leur durée de vie. Autrement dit, la bibliothèque ne fait rien de plus que le naturel - elle simplifie simplement la vie du développeur. Certes, ne pensez pas que vous pouvez écrire une telle bibliothèque en une journée - c'est une chose d'écrire au stylet toutes les dépendances pour un cas particulier, c'est une autre chose d'apprendre à un ordinateur à l'implémenter universellement et correctement.
Histoire de la bibliothèque
L'histoire ne serait pas complète si je ne la racontais pas brièvement. Si vous suivez la bibliothèque de la version bêta, elle ne sera pas si intéressante pour vous, mais pour ceux qui la verront pour la première fois, je pense qu'il vaut la peine de comprendre comment elle est apparue et quels objectifs l'auteur a suivis (c'est-à-dire moi).
La bibliothèque était mon deuxième projet, que j'ai décidé, à des fins d'auto-éducation, d'écrire en swift. Avant cela, j'ai réussi à écrire un enregistreur, mais je ne l'ai pas téléchargé dans le domaine public - c'est de mieux en mieux.
Mais avec DI, l'histoire est plus intéressante. Quand j'ai commencé à le faire, je n'ai pu trouver qu'une seule bibliothèque sur Swift - Swinject. A cette époque, elle avait 500 étoiles et des bugs que les cycles ne sont pas normalement traités. J'ai regardé tout cela et ... Mon comportement est mieux décrit par ma phrase préférée «Et ensuite Ostap a souffert» - J'ai parcouru 5-6 langues, regardé ce qui est dans ces langues, lu des articles sur ce sujet et réalisé que cela pouvait être mieux fait. Et maintenant, après presque trois ans, je peux dire avec confiance que l'objectif a été atteint, en ce moment DITranquillity est le meilleur de ma vision du monde.
Comprenons ce qu'est une bonne bibliothèque DI:
- Il devrait fournir toutes les implémentations de base: constructeur, propriétés, méthodes
- Cela ne devrait pas affecter le code d'entreprise.
- Elle devrait décrire clairement ce qui n'a pas fonctionné.
- Elle doit comprendre à l'avance où il y a des erreurs, pas au moment de l'exécution.
- Il doit être intégré aux outils de base (Storyboard)
- Il doit avoir une syntaxe concise et concise.
- Elle doit tout faire rapidement et efficacement.
- (Facultatif) Il doit être hiérarchique
Ce sont ces principes que j'essaie d'adhérer tout au long du développement de la bibliothèque.
Caractéristiques et avantages de la bibliothèque
Tout d'abord, un lien vers le référentiel:
github.com/ivlevAstef/DITranquillityLe principal avantage concurrentiel, qui est assez important pour moi, est que la bibliothèque parle d'erreurs de démarrage. Après avoir démarré l'application et appelé la fonction souhaitée, tous les problèmes, existants et potentiels, seront signalés. C'est précisément le sens du nom de la bibliothèque «calme» - en fait, après avoir démarré le programme, la bibliothèque garantit que toutes les dépendances requises existeront et qu'il n'y aura pas de cycles insolubles. Dans les endroits où il y a ambiguïté, la bibliothèque avertira qu'il peut y avoir des problèmes potentiels.
Cela me semble très bien. Il n'y a pas de plantage pendant l'exécution du programme, si le programmeur a oublié quelque chose, cela sera immédiatement signalé.
Une fonction de journal est utilisée pour décrire les problèmes, que je recommande fortement d'utiliser. La journalisation a 4 niveaux: erreur, avertissement, info, verbeux. Les trois premiers sont assez importants. Ce dernier n'est pas si important - il écrit tout ce qui se passe - quel objet a été enregistré, quel objet a commencé à être introduit, quel objet a été créé, etc.
Mais ce n'est pas tout ce que la bibliothèque peut se vanter:
- Sécurité totale des threads - toute opération peut être effectuée à partir de n'importe quel thread et tout fonctionnera. La plupart des gens n'en ont pas besoin, donc en termes de sécurité des threads, un travail a été fait pour optimiser la vitesse d'exécution. Mais la bibliothèque des concurrents, malgré les promesses, tombe si vous commencez à vous inscrire et à recevoir un objet en même temps
- Vitesse d'exécution rapide. Sur un véritable appareil, DITranquillity est deux fois plus rapide que son concurrent. Vrai sur le simulateur, la vitesse d'exécution est presque équivalente. Lien de test
- Petite taille - la bibliothèque pèse moins que Swinject + SwinjectStoryboad + SwinjectAutoregistration, mais surpasse cet ensemble de capacités
- Une note concise et concise, bien que provoquant une dépendance
- Hiérarchie. Pour les grands projets, qui se composent de nombreux modules, c'est un très gros avantage, car la bibliothèque est capable de trouver les classes nécessaires par distance du module actuel. Autrement dit, si vous avez votre propre implémentation d'un protocole dans chaque module, alors dans chaque module, vous obtiendrez l'implémentation souhaitée sans aucun effort
Démonstration
Et donc commençons. Comme la dernière fois le projet sera considéré:
SampleHabr . Je n'ai pas spécifiquement commencé à changer l'exemple - vous pouvez donc comparer comment tout a changé. Et l'exemple montre de nombreuses fonctionnalités de la bibliothèque.
Juste au cas où, pour qu'il n'y ait pas de malentendu, puisque le projet est affiché, il utilise de nombreuses fonctionnalités. Mais personne ne prend la peine d'utiliser la bibliothèque de manière simplifiée - téléchargé, créé un conteneur, enregistré quelques classes, utilisez le conteneur.
Nous devons d'abord créer un cadre (facultatif):
public class AppFramework: DIFramework {
Et au début du programme, créez votre propre conteneur, avec l'ajout de ce framework:
let container = DIContainer()
Storyboard
Ensuite, vous devez créer un écran de base. Habituellement, les storyboards sont utilisés pour cela, et dans cet exemple, je vais l'utiliser, mais personne ne se soucie d'utiliser UIViewControllers.
Pour commencer, nous devons enregistrer un Storyboard. Pour ce faire, créez une «partie» (facultative - vous pouvez écrire tout le code dans le framework) avec le Storyboard enregistré dedans:
import DITranquillity class AppPart: DIPart { static func load(container: DIContainer) { container.registerStoryboard(name: "Main", bundle: nil) .lifetime(.single)
Et ajoutez une pièce à AppFramework:
container.append(part: AppPart.self)
Comme vous pouvez le voir, la bibliothèque a une syntaxe pratique pour enregistrer Storyboard, et je recommande fortement de l'utiliser. En principe, vous pouvez écrire du code équivalent sans cette méthode, mais il sera plus volumineux et ne pourra pas prendre en charge StoryboardReferences. Autrement dit, ce Storyboard ne fonctionnera pas d'un autre.
Maintenant, la seule chose qui reste est de créer un Storyboard et d'afficher l'écran de démarrage. Cela se fait dans AppDelegate, après avoir vérifié le conteneur:
window = UIWindow(frame: UIScreen.main.bounds)
La création d'un Storyboard à l'aide d'une bibliothèque n'est pas beaucoup plus compliquée que d'habitude. Dans cet exemple, le nom pourrait être manquant, car nous n'avons qu'un seul Storyboard - la bibliothèque aurait deviné que vous l'aviez en tête. Mais dans certains projets, il y a beaucoup de storyboards, alors ne manquez plus le nom.
Presenter et ViewController
Accédez à l'écran lui-même. Nous ne chargerons pas le projet avec des architectures complexes, mais nous utiliserons le MVP habituel. De plus, je suis tellement paresseux que je ne créerai pas de protocole pour un présentateur. Le protocole sera un peu plus tard pour une autre classe, ici il est important de montrer comment enregistrer et lier Presenter et ViewController.
Pour ce faire, ajoutez le code suivant à AppPart:
container.register(YourPresenter.init) container.register(YourViewController.self) .injection(\.presenter)
Ces trois lignes nous permettront d'enregistrer deux classes et d'établir une connexion entre elles.
Les personnes curieuses peuvent se demander - pourquoi la syntaxe de Swinject dans une bibliothèque séparée est-elle la principale du projet? La réponse réside dans les objectifs - grâce à cette syntaxe, la bibliothèque stocke tous les liens à l'avance, plutôt que de les calculer au moment de l'exécution. Cette syntaxe vous donne accès à de nombreuses fonctionnalités qui ne sont pas disponibles pour d'autres bibliothèques.
Nous démarrons l'application, et tout fonctionne, toutes les classes sont créées.
Les données
Eh bien, maintenant nous devons ajouter une classe et un protocole pour recevoir des données du serveur:
public protocol Server { func get(method: String) -> Data? } class ServerImpl: Server { init(domain: String) { ... } func get(method: String) -> Data? { ... } }
Et pour la beauté, nous allons créer une classe DI ServerPart distincte pour le serveur, dans laquelle nous l'enregistrons. Permettez-moi de vous rappeler que cela n'est pas nécessaire et peut être enregistré directement dans le conteneur, mais nous ne cherchons pas de moyens simples :)
import DITranquillity class ServerPart: DIPart { static func load(container: DIContainer) { container.register{ ServerImpl(domain: "https:
Dans ce code, tout n'est pas aussi transparent que dans les précédents et nécessite une clarification. Tout d'abord, à l'intérieur du registre de fonction, une classe est créée avec un paramètre passé.
Deuxièmement, il y a la fonction `as` - elle dit que la classe sera accessible par un autre type - le protocole. L'étrange fin de cette opération sous la forme de {{$ 0} `fait partie du nom` check: `. Autrement dit, ce code garantit que ServerImpl est un successeur de Server. Mais il existe une autre syntaxe: `as (Server.self)` qui fera de même, mais sans vérification. Pour voir ce que le compilateur produira dans les deux cas, vous pouvez supprimer l'implémentation du protocole.
Il peut y avoir plusieurs fonctions «as» - cela signifie que le type est disponible sous l'un de ces noms. J'attire votre attention sur le fait qu'il s'agira d'un seul enregistrement, ce qui signifie que si la classe est un singleton, la même instance sera disponible pour tout type spécifié.
En principe, si vous souhaitez vous protéger de la possibilité de créer une classe par type d'implémentation, ou si vous n'êtes pas encore habitué à cette syntaxe, vous pouvez écrire:
container.register{ ServerImpl(domain: "https://github.com/") as Server }
Ce sera un équivalent, mais sans la possibilité de spécifier plusieurs types distincts.
Vous pouvez maintenant implémenter le serveur dans Presenter, pour cela nous allons corriger Presenter pour qu'il accepte le serveur:
class YourPresenter { init(server: Server) { ... } }
Nous démarrons le programme, et il tombe sur les fonctions `validate` dans AppDelegate, avec le message que le type` Server` n'a pas été trouvé, mais il est requis par` YourPresenter`. Quoi de neuf? Veuillez noter que l'erreur s'est produite au début de l'exécution du programme, et non un post factum. Et la raison est assez simple - ils ont oublié d'ajouter «ServerPart» à «AppFramework»:
container.append(part: ServerPart.self)
Nous commençons - tout fonctionne.
Enregistreur
Avant cela, il y avait une connaissance des opportunités qui ne sont pas très impressionnantes et beaucoup l'ont. Il y aura maintenant une démonstration que les autres bibliothèques sur Swift ne savent pas comment.
Un
projet distinct
a été créé sous l'enregistreur.
Tout d'abord, comprenons ce qui sera un enregistreur. À des fins éducatives, nous ne ferons pas un système trompé, donc l'enregistreur est un protocole avec une méthode et plusieurs implémentations:
public protocol Logger { func log(_ msg: String) } class ConsoleLogger: Logger { func log(_ msg: String) { ... } } class FileLogger: Logger { init(file: String) { ... } func log(_ msg: String) { ... } } class ServerLogger: Logger { init(server: String) { ... } func log(_ msg: String) { ... } } class MainLogger: Logger { init(loggers: [Logger]) { ... } func log(_ msg: String) { ... } }
Au total, nous avons:
- Protocole public
- 3 implémentations d'enregistreur différentes, chacune écrivant dans un endroit différent
- Un enregistreur central qui appelle la fonction de journalisation pour tout le monde
Le projet a créé «LoggerFramework» et «LoggerPart». Je n'écrirai pas leur code, mais je n'écrirai que les éléments internes de `LoggerPart`:
container.register{ ConsoleLogger() } .as(Logger.self) .lifetime(.single) container.register{ FileLogger(file: "file.log") } .as(Logger.self) .lifetime(.single) container.register{ ServerLogger(server: "http://server.com/") } .as(Logger.self) .lifetime(.single) container.register{ MainLogger(loggers: many($0)) } .as(Logger.self) .default() .lifetime(.single)
Nous avons déjà vu les 3 premières inscriptions, et la dernière pose question.
Un paramètre est passé à l'entrée. Un exemple similaire a déjà été montré lors de la création du présentateur, bien qu'il y ait un enregistrement abrégé - la méthode `init` vient d'être utilisée, mais personne ne prend la peine d'écrire comme ceci:
container.register { YourPresenter(server: $0) }
S'il y avait plusieurs paramètres, alors on pourrait utiliser «$ 1», «$ 2», «$ 3», etc. jusqu'au 16.
Mais ce paramètre appelle la fonction `many`. Et ici, le plaisir commence. Il y a deux modificateurs `many` et` tag` dans la bibliothèque.
Texte masquéIl existe un troisième modificateur `arg`, mais il n'est pas sûr
Le modificateur `many` indique que vous devez obtenir tous les objets correspondant au type souhaité. Dans ce cas, le protocole Logger est attendu, donc toutes les classes qui héritent de ce protocole seront trouvées et créées, à une exception près - elle-même, c'est-à-dire de manière récursive. Il ne se créera pas lors de l'initialisation, bien qu'il puisse le faire en toute sécurité lorsqu'il est implémenté via une propriété.
L'étiquette, à son tour, est un type distinct qui doit être spécifié à la fois lors de l'utilisation et lors de l'enregistrement. Autrement dit, les balises sont des critères supplémentaires s'il n'y a pas suffisamment de types de base.
Vous pouvez en savoir plus à ce sujet:
ModificateursLa présence de modificateurs, en particulier `many ', rend la bibliothèque meilleure que les autres. Par exemple, vous pouvez implémenter le modèle Observer à un niveau complètement différent. En raison de ces 4 lettres, dans le projet, il a été possible de supprimer 30 à 50 lignes de code de chaque observateur du projet et de résoudre le problème avec la question - où et quand les objets devraient-ils être ajoutés à l'observable. Clear business n'est pas la seule application, mais elle est importante.
Eh bien, nous terminerons la présentation des fonctionnalités en introduisant un enregistreur dans YourPresenter:
container.register(YourPresenter.init) .injection { $0.logger = $1 }
Ici, par exemple, il est écrit un peu différemment qu'auparavant - cela se fait pour un exemple d'une syntaxe différente.
Veuillez noter que la propriété de l'enregistreur est facultative:
internal var logger: Logger?
Et cela n'apparaît pas dans la syntaxe de la bibliothèque. Contrairement à la première version, maintenant toutes les opérations pour le type habituel, facultatif et forcé facultatif se ressemblent. De plus, la logique à l'intérieur est différente - si le type est facultatif et n'est pas enregistré dans le conteneur, le programme ne se bloquera pas, mais continuera son exécution.
Résumé
Les résultats sont similaires à la dernière fois, seule la syntaxe est devenue plus courte et plus fonctionnelle.
Ce qui a été examiné:
Que peut faire d'autre la bibliothèque:
Plans
Tout d'abord, il est prévu de passer à la vérification du graphe au stade de la compilation, c'est-à-dire une intégration plus étroite avec le compilateur. Il existe une implémentation préliminaire utilisant SourceKitten, mais une telle implémentation a de sérieuses difficultés avec l'inférence de type, il est donc prévu de passer à ast-dump - en swift5, elle est devenue opérationnelle sur de grands projets. Ici, je tiens à remercier
Nekitosss pour l'énorme contribution dans ce sens.
Deuxièmement, je voudrais m'intégrer aux services de visualisation. Ce sera un projet légèrement différent, mais étroitement lié à la bibliothèque. À quoi ça sert? Maintenant, la bibliothèque stocke le graphique complet des connexions, c'est-à-dire qu'en théorie, tout ce qui est enregistré dans la bibliothèque peut être affiché sous forme de diagramme de classe / composant UML. Et ce serait bien de voir parfois ce schéma.
Cette fonctionnalité est prévue en deux parties - la première vous permettra d'ajouter une API pour obtenir toutes les informations, et la seconde est déjà l'intégration avec différents services.
L'option la plus simple consiste à afficher un graphique de liens sous forme de texte, mais je n'ai pas vu d'options lisibles - si oui, suggérez des options dans les commentaires.
WatchOS - Je n'écris pas moi-même de projets pour eux. Pour sa vie, il n'a écrit qu'une seule fois, puis petit. Mais je voudrais faire une intégration étroite, comme avec le Storyboard.
C'est tout merci de votre attention. J'espère vraiment avoir des commentaires et des réponses à l'enquête.
À propos de moiIvlev Alexander Evgenievich - senior / chef d'équipe dans l'équipe iOS. Je travaille dans le commerce depuis 7 ans, sous iOS 4,5 ans - avant cela, j'étais développeur C ++. Mais l'expérience de programmation totale est de plus de 15 ans - à l'école, j'ai fait la connaissance de ce monde incroyable et j'ai été tellement emporté par lui qu'il y a eu une période où j'ai échangé des jeux , de la nourriture, des toilettes, un rêve pour écrire du code. Selon l'un de mes articles, vous pouvez deviner que je suis une ancienne Olympiade - en conséquence, il ne m'a pas été difficile d'écrire un travail compétent avec des graphiques. Spécialité - Systèmes de mesure de l'information, et à une époque j'étais obsédé par le multithreading et le parallélisme - oui, j'écris du code dans lequel je fais des hypothèses et des bugs sur des sujets similaires, mais je comprends les zones à problèmes et comprends parfaitement où vous pouvez négliger le mutex, et où pas la peine.