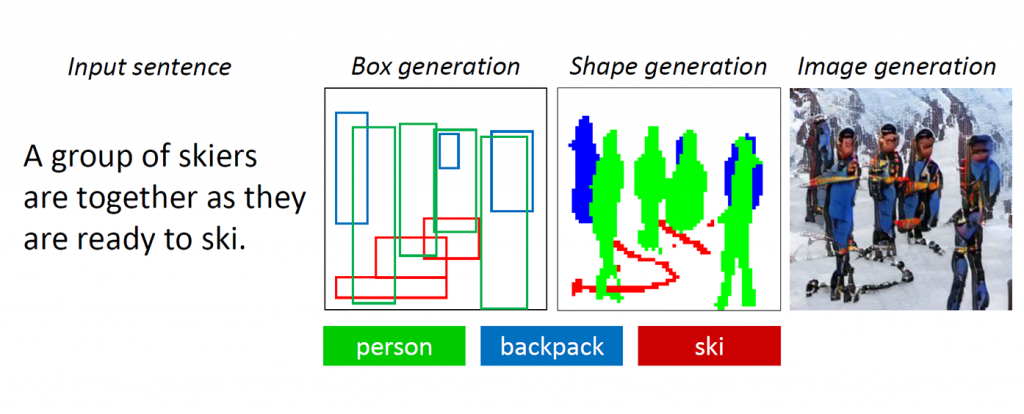
Si on vous demandait de dessiner une image de plusieurs personnes en tenue de ski, debout dans la neige, il y a de fortes chances que vous commenciez par un contour de trois ou quatre personnes raisonnablement positionnées au centre de la toile, puis esquissez dans les skis sous leur les pieds. Bien que cela n'ait pas été spécifié, vous pourriez décider d'ajouter un sac à dos à chacun des skieurs pour empanner avec les attentes de ce que les skieurs porteraient. Enfin, vous rempliriez soigneusement les détails, peignant peut-être leurs vêtements en bleu, des écharpes en rose, le tout sur un fond blanc, rendant ces personnes plus réalistes et s'assurant que leur environnement correspond à la description. Enfin, pour rendre la scène plus vivante, vous pouvez même esquisser des pierres brunes qui dépassent dans la neige pour suggérer que ces skieurs sont dans les montagnes.
Maintenant, il y a un bot qui peut faire tout ça.
La nouvelle technologie d'IA en cours de développement chez Microsoft Research AI peut comprendre une description en langage naturel, esquisser une disposition de l'image, synthétiser l'image, puis affiner les détails en fonction de la disposition et des mots individuels fournis. En d'autres termes, ce bot peut générer des images à partir de descriptions textuelles de sous-titres de scènes quotidiennes. Ce mécanisme délibéré a produit une amélioration significative de la qualité d'image générée par rapport à la technique de pointe précédente pour la génération de texte en image pour des scènes quotidiennes compliquées, selon les résultats des tests standard de l'industrie rapportés dans « Object-driven Text- to-Image Synthesis via Adversarial Training », qui sera publié ce mois-ci à Long Beach, en Californie, lors de la Conférence IEEE 2019 sur la vision par ordinateur et la reconnaissance des formes (CVPR 2019). Il s'agit d'un projet de collaboration entre Pengchuan Zhang , Qiuyuan Huang et Jianfeng Gao de Microsoft Research AI , Lei Zhang de Microsoft, Xiaodong He de JD AI Research et Wenbo Li et Siwei Lyu de l'Université d'Albany, SUNY (tandis que Wenbo Li travaillait comme stagiaire chez Microsoft Research AI).
Il existe deux principaux défis intrinsèques au problème des robots de dessin basés sur la description. La première est que de nombreux types d'objets peuvent apparaître dans les scènes de tous les jours et que le bot devrait être capable de les comprendre et de les dessiner tous. Les méthodes précédentes de génération de texte en image utilisent des paires image-légende qui ne fournissent qu'un signal de supervision à grain très grossier pour générer des objets individuels, ce qui limite leur qualité de génération d'objet. Dans cette nouvelle technologie, les chercheurs utilisent l'ensemble de données COCO qui contient des étiquettes et des cartes de segmentation pour 1,5 million d'instances d'objets à travers 80 classes d'objets communes, permettant au bot d'apprendre à la fois le concept et l'apparence de ces objets. Ce signal supervisé à grain fin pour la génération d'objets améliore considérablement la qualité de génération de ces classes d'objets courantes.
Le deuxième défi réside dans la compréhension et la génération des relations entre plusieurs objets dans une même scène. Un grand succès a été obtenu en générant des images qui ne contiennent qu'un seul objet principal pour plusieurs domaines spécifiques, tels que les visages, les oiseaux et les objets communs. Cependant, la génération de scènes plus complexes contenant plusieurs objets avec des relations sémantiquement significatives entre ces objets reste un défi important dans la technologie de génération de texte en image. Ce nouveau robot de dessin a appris à générer la disposition des objets à partir de modèles de co-occurrence dans l'ensemble de données COCO pour ensuite générer une image conditionnée sur la disposition pré-générée.
Génération d'images attentives orientées objet
Au cœur du bot de dessin de Microsoft Research AI se trouve une technologie connue sous le nom de Generative Adversarial Network, ou GAN. Le GAN se compose de deux modèles d'apprentissage automatique - un générateur qui génère des images à partir de descriptions textuelles et un discriminateur qui utilise des descriptions textuelles pour juger de l'authenticité des images générées. Le générateur tente d'obtenir de fausses images devant le discriminateur; le discriminateur, d'autre part, ne veut jamais être dupe. En travaillant ensemble, le discriminateur pousse le générateur vers la perfection.
Le robot de dessin a été formé sur un ensemble de données de 100 000 images, chacune avec des étiquettes d'objets saillants et des cartes de segmentation et cinq légendes différentes, permettant aux modèles de concevoir des objets individuels et des relations sémantiques entre les objets. Le GAN, par exemple, apprend à quoi devrait ressembler un chien en comparant des images avec et sans descriptions de chiens.

Figure 1: une scène complexe avec plusieurs objets et relations.
Les GAN fonctionnent bien lors de la génération d'images contenant un seul objet saillant, comme un visage humain, des oiseaux ou des chiens, mais la qualité stagne avec des scènes quotidiennes plus complexes, une telle scène décrite comme «Une femme portant un casque monte à cheval» (voir la figure 1.) En effet, ces scènes contiennent plusieurs objets (femme, casque, cheval) et de riches relations sémantiques entre elles (femme portant un casque, femme chevauchant un cheval). Le bot doit d'abord comprendre ces concepts et les placer dans l'image avec une mise en page significative. Après cela, un signal plus supervisé capable d'enseigner la génération d'objet et la génération de mise en page est requis pour remplir cette tâche de compréhension du langage et de génération d'image.
Au fur et à mesure que les humains dessinent ces scènes compliquées, nous décidons d'abord des principaux objets à dessiner et faisons une mise en page en plaçant des boîtes englobantes pour ces objets sur la toile. Ensuite, nous nous concentrons sur chaque objet, en vérifiant à plusieurs reprises les mots correspondants qui décrivent cet objet. Pour capturer ce trait humain, les chercheurs ont créé ce qu'ils ont appelé un GAN attentif orienté objet, ou ObjGAN, pour modéliser mathématiquement le comportement humain de l'attention centrée sur l'objet. ObjGAN fait cela en décomposant le texte d'entrée en mots individuels et en faisant correspondre ces mots à des objets spécifiques de l'image.
Les humains vérifient généralement deux aspects pour affiner le dessin: le réalisme des objets individuels et la qualité des correctifs d'image. ObjGAN imite également ce comportement en introduisant deux discriminateurs - un discriminateur par objet et un discriminateur par patch. Le discriminateur par objet essaie de déterminer si l'objet généré est réaliste ou non et si l'objet est cohérent avec la description de la phrase. Le discriminateur par patch essaie de déterminer si ce patch est réaliste ou non et si ce patch est cohérent avec la description de la phrase.
Travaux connexes: visualisation de l'histoire
Des modèles de génération de texte en image à la pointe de la technologie peuvent générer des images d'oiseaux réalistes sur la base d'une description en une seule phrase. Cependant, la génération de texte en image peut aller bien au-delà de la synthèse d'une seule image basée sur une phrase. Dans « StoryGAN: A Sequential Conditional GAN for Story Visualization », Jianfeng Gao de Microsoft Research, avec Zhe Gan, Jingjing Liu et Yu Cheng de Microsoft Dynamics 365 AI Research, Yitong Li, David Carlson et Lawrence Carin de Duke University, Yelong Shen de Tencent AI Research et Yuexin Wu de l'Université Carnegie Mellon vont plus loin et proposent une nouvelle tâche, appelée Story Visualization. Étant donné un paragraphe de plusieurs phrases, une histoire complète peut être visualisée, générant une séquence d'images, une pour chaque phrase. C'est une tâche difficile, car le robot de dessin n'est pas seulement nécessaire pour imaginer un scénario qui correspond à l'histoire, modéliser les interactions entre les différents personnages apparaissant dans l'histoire, mais il doit également être en mesure de maintenir la cohérence globale entre les scènes et les personnages dynamiques. Ce défi n'a été relevé par aucune méthode de génération d'images ou de vidéos.
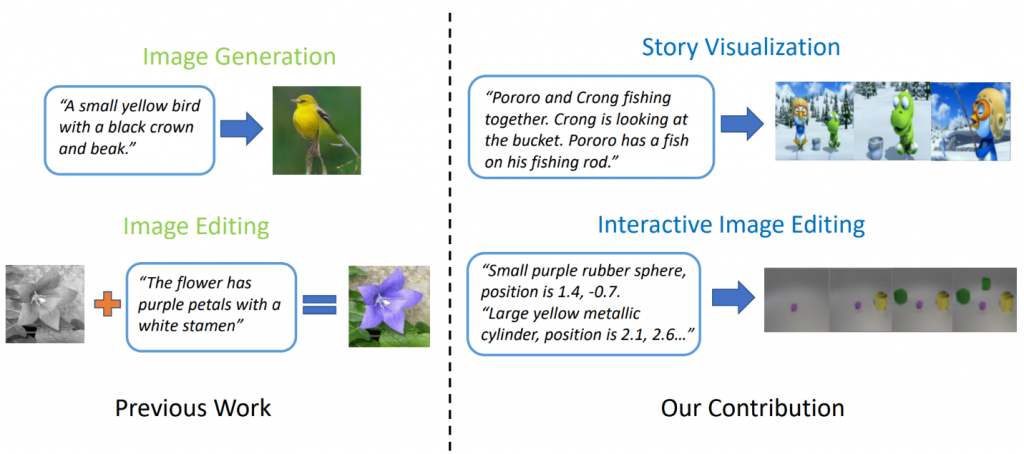
Figure 2: Visualisation de l'histoire vs génération d'image simple.
Les chercheurs ont mis au point un nouveau modèle de génération de séquence histoire-image, StoryGAN, basé sur le cadre séquentiel GAN conditionnel. Ce modèle est unique en ce qu'il se compose d'un encodeur de contexte profond qui suit dynamiquement le flux de l'histoire, et de deux discriminateurs au niveau de l'histoire et de l'image pour améliorer la qualité de l'image et la cohérence des séquences générées. StoryGAN peut également être naturellement étendu pour l'édition d'image interactive, où une image d'entrée peut être éditée séquentiellement sur la base des instructions de texte. Dans ce cas, une séquence d'instructions utilisateur servira d'entrée «histoire». En conséquence, les chercheurs ont modifié les ensembles de données existants pour créer les ensembles de données CLEVR-SV et Pororo-SV, comme le montre la figure 2.
Applications pratiques - une histoire vraie
La technologie de génération de texte en image pourrait trouver des applications pratiques agissant comme une sorte d'assistant de croquis pour les peintres et les décorateurs d'intérieur, ou comme un outil pour la retouche photo à commande vocale. Avec plus de puissance de calcul, les chercheurs imaginent la technologie générant des films d'animation basés sur des scénarios, augmentant le travail des cinéastes d'animation en supprimant une partie du travail manuel impliqué.
Pour l'instant, les images générées sont encore loin d'être photo-réalistes. Les objets individuels révèlent presque toujours des défauts, tels que des visages flous et / ou des bus aux formes déformées. Ces défauts indiquent clairement qu'un ordinateur, et non un être humain, a créé les images. Néanmoins, la qualité des images ObjGAN est nettement meilleure que les images GAN les meilleures de leur catégorie précédente et sert de jalon sur la voie vers une intelligence générique de type humain qui augmente les capacités humaines.
Pour que les IA et les humains partagent le même monde, chacun doit avoir un moyen d'interagir avec l'autre. Le langage et la vision sont les deux modalités les plus importantes pour que les humains et les machines interagissent. La génération de texte en image est une tâche importante qui fait progresser la recherche en intelligence multimodale en vision du langage.
Les chercheurs qui ont créé ce travail passionnant ont hâte de partager ces résultats avec les participants au CVPR de Long Beach et d'entendre ce que vous pensez. En attendant, n'hésitez pas à consulter leur code open-source pour ObjGAN et StoryGAN sur GitHub